CUDA
CUDA Refresher: The CUDA Programming Model
https://developer.nvidia.com/blog/cuda-refresher-cuda-programming-model/
To execute any CUDA program, there are three main steps:
- Copy the input data from host memory to device memory, also known as host-to-device transfer.
- Load the GPU program and execute, caching data on-chip for performance.
- Copy the results from device memory to host memory, also called device-to-host transfer.
CUDA Refresher: Getting started with CUDA
https://developer.nvidia.com/blog/cuda-refresher-getting-started-with-cuda/
Advancements in science and business drive an insatiable demand for more computing resources and acceleration of workloads. Parallel programming is a profound way for developers to accelerate their applications. However, it has some common challenges.
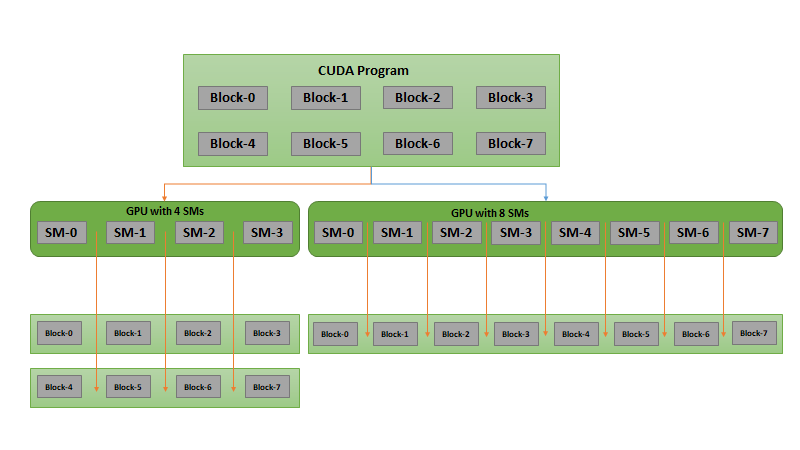
The first challenge is to simplify parallel programming to make it easy to program. Easy programming attracts more developers and motivates them to port many more applications on parallel processors. The second challenge is to develop application software that transparently scales its parallelism to leverage the increasing number of processor cores with GPUs
An Easy Introduction to CUDA C and C++
https://developer.nvidia.com/blog/easy-introduction-cuda-c-and-c/
Given the heterogeneous nature of the CUDA programming model, a typical sequence of operations for a CUDA C program is:
- Declare and allocate host and device memory.
- Initialize host data.
- Transfer data from the host to the device.
- Execute one or more kernels.
- Transfer results from the device to the host.
#include <stdio.h> __global__ void saxpy(int n, float a, float *x, float *y) { int i = blockIdx.x*blockDim.x + threadIdx.x; if (i < n) y[i] = a*x[i] + y[i]; } int main(void) { int N = 1<<20; float *x, *y, *d_x, *d_y; x = (float*)malloc(N*sizeof(float)); y = (float*)malloc(N*sizeof(float)); cudaMalloc(&d_x, N*sizeof(float)); cudaMalloc(&d_y, N*sizeof(float)); for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice); cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice); // Perform SAXPY on 1M elements saxpy<<<(N+255)/256, 256>>>(N, 2.0f, d_x, d_y); cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost); float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = max(maxError, abs(y[i]-4.0f)); printf("Max error: %f\n", maxError); cudaFree(d_x); cudaFree(d_y); free(x); free(y); }
https://developer.nvidia.com/blog/even-easier-introduction-cuda/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号