
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
https://blog.vllm.ai/2023/06/20/vllm.html
LLMs promise to fundamentally change how we use AI across all industries. However, actually serving these models is challenging and can be surprisingly slow even on expensive hardware. Today we are excited to introduce vLLM, an open-source library for fast LLM inference and serving. vLLM utilizes PagedAttention, our new attention algorithm that effectively manages attention keys and values. vLLM equipped with PagedAttention redefines the new state of the art in LLM serving: it delivers up to 24x higher throughput than HuggingFace Transformers, without requiring any model architecture changes.
vLLM has been developed at UC Berkeley and deployed at Chatbot Arena and Vicuna Demo for the past two months. It is the core technology that makes LLM serving affordable even for a small research team like LMSYS with limited compute resources. Try out vLLM now with a single command at our GitHub repository.
https://arxiv.org/abs/2309.06180
High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2)
http://cncc.bingj.com/cache.aspx?q=vllm&d=4538921862332244&mkt=en-US&setlang=en-US&w=kCbRK1lZINsQEH4tJdltWDyg-VtMiMe7
Why is serving LLM so challenging?
Computational Resources
Due to the fact that LLM has numerous parameters to perform a prediction, which could start with the 7B parameter and then go up to 321B, deploying this model may require an intensive resource and a lot of optimization rather than using a traditional method to deploy a machine learning model.
Latency
When a sentence or token is complicated, the process takes several minutes to compute a result for the client, which may cause an issue on a large scale or in real-world business. For instance, a company may apply LLM with a product Q&A chatbot, which has a slow response to each question, which could cause frustration for the user. Therefore, applying some method to reduce the latency would be a good practice.
Cost
In a large-scale system or with multiple LLMs in the system, which would consume a lot of budget for the application since LLMs use large resources to process, as a MLE, finding a way to utilize a resource would bring a financial benefit to the system. For instance, lower the cost per request.
What is vLLM?
This project is from UC Berkeley’s students, who have a passion to optimize serving performance in LLMs. Many systems spend a lot of resources on serving LLMs. However, it has a poor response time when using a simple method to deploy it. As a result, vLLM’s team proposes a new method to solve this issue by using the OS’s virtual memory design, which could improve LLM serving performance around 24 times while using half the memory of the GPU compared with the traditional method. To integrate into your system, vLLM provides a simple interface that lets machine learning engineers (MLE) develop it via a Python interface, which you could integrate into your system without using fancy packages or dependencies.
https://blog.monsterapi.ai/blogs/what-is-vllm-and-how-to-implement-it/
Serving large language models (LLMs) in production environments poses significant challenges, including high memory consumption, latency issues, and the need for efficient resource management. These challenges often result in suboptimal performance and scalability problems, hindering the deployment of LLMs in real-world applications.
vLLM addresses these challenges by optimizing memory management and dynamically adjusting batch sizes, ensuring efficient execution and improved throughput for large language models.
What is the Core Idea of vLLM?
The core idea of vLLM (Virtual Large Language Model) is to optimize the serving and execution of large language models (LLMs) by utilizing efficient memory management techniques. Here are the key aspects:
- Optimized Memory Management: vLLM uses sophisticated memory allocation and management strategies to maximize the utilization of available hardware resources. This allows for the efficient execution of large language models without running into memory bottlenecks.
- Dynamic Batching: vLLM dynamically adjusts the batch sizes and sequences to better fit the memory and compute capacity of the hardware. This flexibility leads to improved throughput and reduced latency during inference.
- Modular Design: The architecture of vLLM is designed to be modular, allowing for easy integration with various hardware accelerators and scaling across multiple devices or clusters.
- Efficient Resource Utilization: By managing resources such as CPU, GPU, and memory more effectively, vLLM can serve larger models and handle more simultaneous requests, making it suitable for production environments where scalability and performance are critical.
- Seamless Integration: vLLM aims to integrate seamlessly with existing machine learning frameworks and libraries, providing a user-friendly interface for deploying and serving large language models in various applications.
Overall, the core idea of vLLM is to enhance the performance, scalability, and efficiency of large language model deployment through advanced memory and resource management techniques.
How to Use vLLM?
We will now walk you through the steps to effectively use vLLM for serving large language models (LLMs) in production. We'll cover integration, configuration, deployment, and maintenance steps.
For those looking for a quicker alternative, we also introduce a ready-to-use service leveraging vLLM at the end of this topic.
Here’s a step-wise Workflow for Using vLLM:
Integration and Configuration:
https://developer.nvidia.com/blog/cuda-refresher-cuda-programming-model/
Option 1: Self-Configuration:
- Integrate vLLM into your existing machine learning framework or library (e.g., PyTorch, TensorFlow) by following the provided installation and setup guidelines.
- Configure memory management settings and adjust batching strategies, including batch size and sequence length, to match your hardware resources and optimize performance.
- Load your pre-trained large language model (LLM) into vLLM, ensuring it is properly initialized and ready for inference tasks.
Option 2: vLLM Docker Container:
- Use the ready-to-use vLLM Docker container for a simplified setup.
- Follow the instructions to pull the Docker image, configure the necessary settings, and deploy your LLM within the container environment.
Here’s an example command for running a vLLM docker container with Mistral 7B LLM:
docker run --runtime nvidia --gpus all \ -v ~/.cache/huggingface:/root/.cache/huggingface \ --env "HUGGING_FACE_HUB_TOKEN=<secret>" \ -p 8000:8000 \ --ipc=host \ vllm/vllm-openai:latest \ --model mistralai/Mistral-7B-v0.1You may find more details on docker deployments on vLLM’s official docs.
Understanding vLLM for Increasing LLM Throughput
https://www.e2enetworks.com/blog/understanding-vllm-for-increasing-llm-throughput
vLLM 版本选定
https://docs.vllm.ai/en/v0.5.0/getting_started/installation.html
目前支持 CUDA版本 12.1 和 11.8.
首先使用 nvidia-smi 查看当前的CUDA版本号,然后选择安装方式。
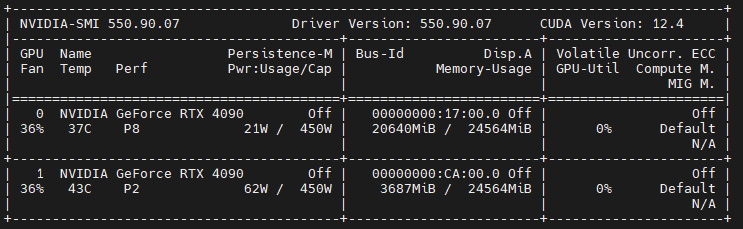
使用conda避免一些依赖c库文件冲突。
# (Recommended) Create a new conda environment.
conda create -n myenv python=3.9 -y
conda activate myenv
# Install vLLM with CUDA 12.1.
pip install vllm
vllm num of gpu block
https://docs.vllm.ai/en/latest/models/engine_args.html
模型启动过程中,如果遇到 out of memory, 但是实际显存充足的情况,按照提示需要调整这个参数
[--use-v2-block-manager]
[--num-lookahead-slots NUM_LOOKAHEAD_SLOTS] [--seed SEED]
[--swap-space SWAP_SPACE] [--cpu-offload-gb CPU_OFFLOAD_GB]
[--gpu-memory-utilization GPU_MEMORY_UTILIZATION]
[--num-gpu-blocks-override NUM_GPU_BLOCKS_OVERRIDE]
[--max-num-batched-tokens MAX_NUM_BATCHED_TOKENS]
[--max-num-seqs MAX_NUM_SEQS] [--max-logprobs MAX_LOGPROBS]
[--disable-log-stats]
[--quantization {aqlm,awq,deepspeedfp,fp8,marlin,gptq_marlin_24,gptq_marlin,gptq,squeezellm,compressed-tensors,bitsandbytes,None}]
[--rope-scaling ROPE_SCALING] [--rope-theta ROPE_THETA]
此参数用于控制推理过程中生成序列的kv缓存个数
https://blog.vllm.ai/2023/06/20/vllm.html
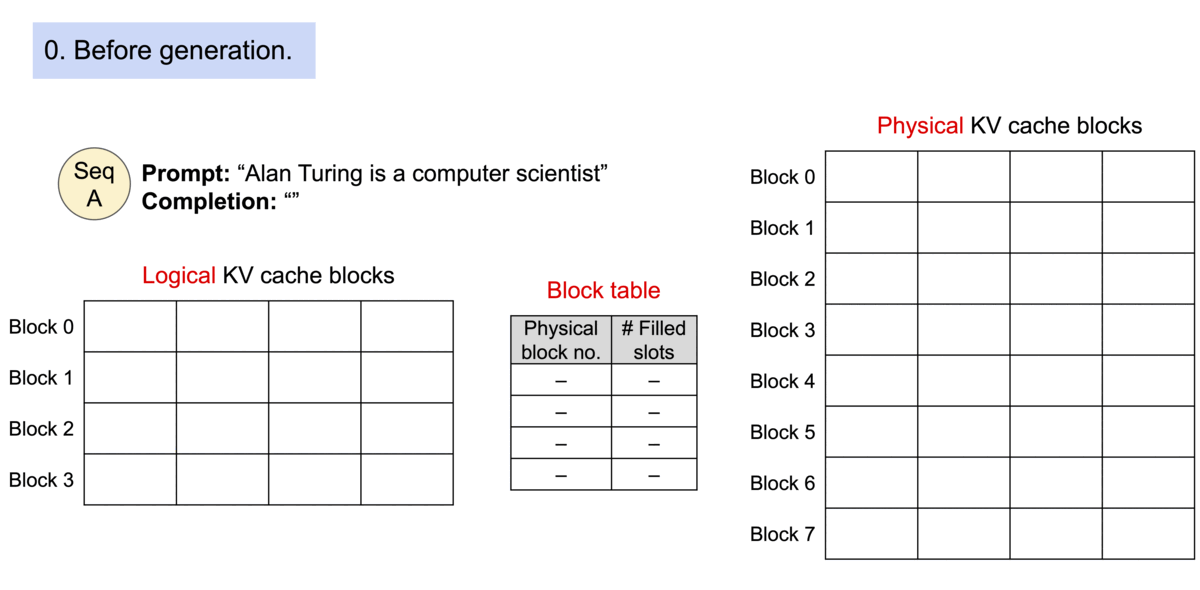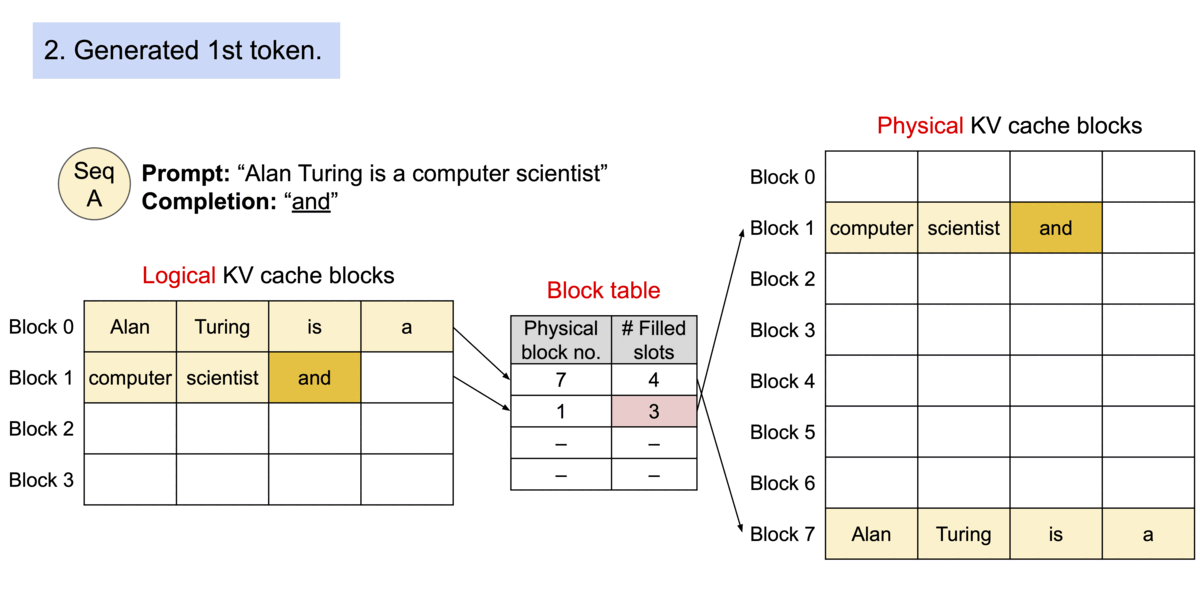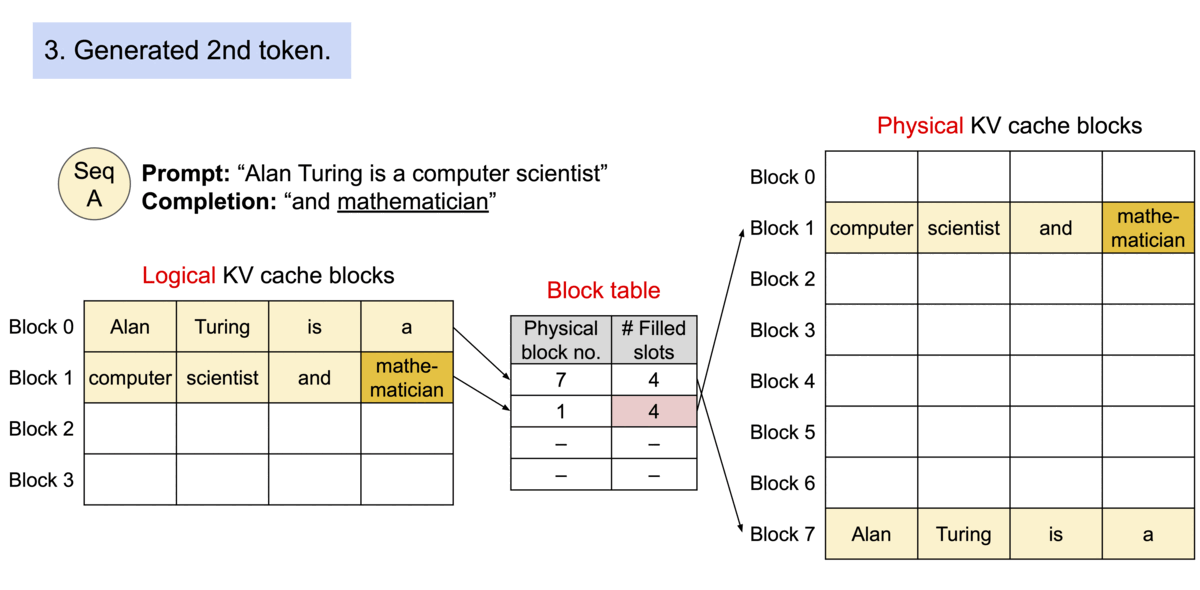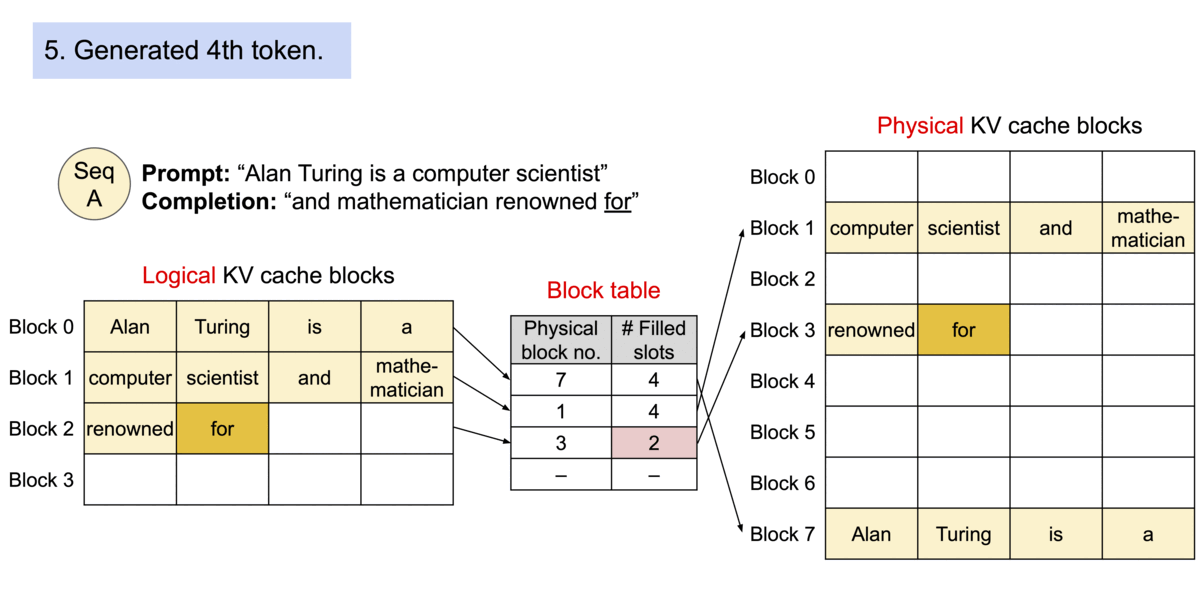
中文解释:
https://www.cnblogs.com/marsggbo/p/18091670
https://www.cnblogs.com/lemonzhang/p/17843336.html
跟CUDA中block不是一个概念。
https://developer.nvidia.com/blog/cuda-refresher-cuda-programming-model/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号