statistical learning -- Model selection of sklearn
Model selection
https://scikit-learn.org/stable/tutorial/statistical_inference/model_selection.html#score-and-cross-validated-scores
模型选择,包括两个部分:
(1)选择不同类型的estimator, 即模型本身。
(2)选择模型的参数。
choosing estimators and their parameters
Score, and cross-validated scores
单个模型可以通过模型的 score 接口, 评估模型的好坏。
score的值越大, 则性能越好。
性能的评估跟数据相关, 一般为了得到更好的预测精度的度量, 可以使用KFold方法。
As we have seen, every estimator exposes a
scoremethod that can judge the quality of the fit (or the prediction) on new data. Bigger is better.>>> from sklearn import datasets, svm >>> X_digits, y_digits = datasets.load_digits(return_X_y=True) >>> svc = svm.SVC(C=1, kernel='linear') >>> svc.fit(X_digits[:-100], y_digits[:-100]).score(X_digits[-100:], y_digits[-100:]) 0.98To get a better measure of prediction accuracy (which we can use as a proxy for goodness of fit of the model), we can successively split the data in folds that we use for training and testing:
>>> import numpy as np >>> X_folds = np.array_split(X_digits, 3) >>> y_folds = np.array_split(y_digits, 3) >>> scores = list() >>> for k in range(3): ... # We use 'list' to copy, in order to 'pop' later on ... X_train = list(X_folds) ... X_test = X_train.pop(k) ... X_train = np.concatenate(X_train) ... y_train = list(y_folds) ... y_test = y_train.pop(k) ... y_train = np.concatenate(y_train) ... scores.append(svc.fit(X_train, y_train).score(X_test, y_test)) >>> print(scores) [0.934..., 0.956..., 0.939...]This is called a
KFoldcross-validation.
Cross-validation generators
https://scikit-learn.org/stable/tutorial/statistical_inference/model_selection.html#cross-validation-generators
实际上sklearn提供了 校验验证的工具。
KFold工具,可以将数据进行K等份划分,并生成 训练集 和 验证集合。
Scikit-learn has a collection of classes which can be used to generate lists of train/test indices for popular cross-validation strategies.
They expose a
splitmethod which accepts the input dataset to be split and yields the train/test set indices for each iteration of the chosen cross-validation strategy.This example shows an example usage of the
splitmethod.
>>> from sklearn.model_selection import KFold, cross_val_score >>> X = ["a", "a", "a", "b", "b", "c", "c", "c", "c", "c"] >>> k_fold = KFold(n_splits=5) >>> for train_indices, test_indices in k_fold.split(X): ... print('Train: %s | test: %s' % (train_indices, test_indices)) Train: [2 3 4 5 6 7 8 9] | test: [0 1] Train: [0 1 4 5 6 7 8 9] | test: [2 3] Train: [0 1 2 3 6 7 8 9] | test: [4 5] Train: [0 1 2 3 4 5 8 9] | test: [6 7] Train: [0 1 2 3 4 5 6 7] | test: [8 9]
然后使用 列表生成式 计算每种等份 模型训练和验证score。
The cross-validation can then be performed easily:
>>> [svc.fit(X_digits[train], y_digits[train]).score(X_digits[test], y_digits[test]) ... for train, test in k_fold.split(X_digits)] [0.963..., 0.922..., 0.963..., 0.963..., 0.930...
实际上这个工作,可以使用 cross_val_score 工具完成。
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
The cross-validation score can be directly calculated using the
cross_val_scorehelper. Given an estimator, the cross-validation object and the input dataset, thecross_val_scoresplits the data repeatedly into a training and a testing set, trains the estimator using the training set and computes the scores based on the testing set for each iteration of cross-validation.By default the estimator’s
scoremethod is used to compute the individual scores.Refer the metrics module to learn more on the available scoring methods.
>>> cross_val_score(svc, X_digits, y_digits, cv=k_fold, n_jobs=-1)
array([0.96388889, 0.92222222, 0.9637883 , 0.9637883 , 0.93036212])
n_jobs可以控制多少个进程同时运行, 来执行交叉验证工作, 如果为 -1 则表示使用尽量多的CPU。
同时也可以使用 scoring参数来指定计算那种类型的得分值。
n_jobs=-1means that the computation will be dispatched on all the CPUs of the computer.Alternatively, the
scoringargument can be provided to specify an alternative scoring method.>>> cross_val_score(svc, X_digits, y_digits, cv=k_fold, ... scoring='precision_macro') array([0.96578289, 0.92708922, 0.96681476, 0.96362897, 0.93192644])
交叉验证示例
https://scikit-learn.org/stable/auto_examples/exercises/plot_cv_diabetes.html#sphx-glr-auto-examples-exercises-plot-cv-diabetes-py
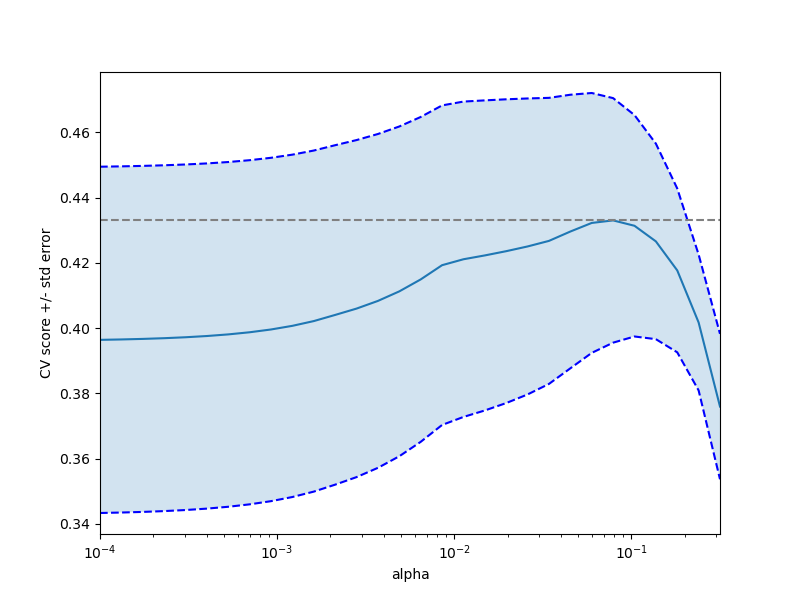
此示例针对 Lasso 模型, 做超参选择分析。
随着alpha参数的递增, 交叉验证的分数则先增后降。此参数应该选择中间值。
Cross-validation on diabetes Dataset Exercise
A tutorial exercise which uses cross-validation with linear models.
print(__doc__) import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.linear_model import LassoCV from sklearn.linear_model import Lasso from sklearn.model_selection import KFold from sklearn.model_selection import GridSearchCV X, y = datasets.load_diabetes(return_X_y=True) X = X[:150] y = y[:150] lasso = Lasso(random_state=0, max_iter=10000) alphas = np.logspace(-4, -0.5, 30) tuned_parameters = [{'alpha': alphas}] n_folds = 5 clf = GridSearchCV(lasso, tuned_parameters, cv=n_folds, refit=False) clf.fit(X, y) scores = clf.cv_results_['mean_test_score'] scores_std = clf.cv_results_['std_test_score'] plt.figure().set_size_inches(8, 6) plt.semilogx(alphas, scores) # plot error lines showing +/- std. errors of the scores std_error = scores_std / np.sqrt(n_folds) plt.semilogx(alphas, scores + std_error, 'b--') plt.semilogx(alphas, scores - std_error, 'b--') # alpha=0.2 controls the translucency of the fill color plt.fill_between(alphas, scores + std_error, scores - std_error, alpha=0.2) plt.ylabel('CV score +/- std error') plt.xlabel('alpha') plt.axhline(np.max(scores), linestyle='--', color='.5') plt.xlim([alphas[0], alphas[-1]]) # ############################################################################# # Bonus: how much can you trust the selection of alpha? # To answer this question we use the LassoCV object that sets its alpha # parameter automatically from the data by internal cross-validation (i.e. it # performs cross-validation on the training data it receives). # We use external cross-validation to see how much the automatically obtained # alphas differ across different cross-validation folds. lasso_cv = LassoCV(alphas=alphas, random_state=0, max_iter=10000) k_fold = KFold(3) print("Answer to the bonus question:", "how much can you trust the selection of alpha?") print() print("Alpha parameters maximising the generalization score on different") print("subsets of the data:") for k, (train, test) in enumerate(k_fold.split(X, y)): lasso_cv.fit(X[train], y[train]) print("[fold {0}] alpha: {1:.5f}, score: {2:.5f}". format(k, lasso_cv.alpha_, lasso_cv.score(X[test], y[test]))) print() print("Answer: Not very much since we obtained different alphas for different") print("subsets of the data and moreover, the scores for these alphas differ") print("quite substantially.") plt.show()
output
Answer to the bonus question: how much can you trust the selection of alpha? Alpha parameters maximising the generalization score on different subsets of the data: [fold 0] alpha: 0.05968, score: 0.54209 [fold 1] alpha: 0.04520, score: 0.15523 [fold 2] alpha: 0.07880, score: 0.45193 Answer: Not very much since we obtained different alphas for different subsets of the data and moreover, the scores for these alphas differ quite substantially.
Grid-search
https://scikit-learn.org/stable/tutorial/statistical_inference/model_selection.html#grid-search
对于使用交叉验证来进行超参的选择, sklearn提供了一个工具, 来自动实现, 在超参集合上,分别进行学习, 最后选择最大得分模型的工具。
GridSearchCV 类似网格搜索, 但是其返回值本身也是一个 模型, 表示最后选择的模型。
scikit-learn provides an object that, given data, computes the score during the fit of an estimator on a parameter grid and chooses the parameters to maximize the cross-validation score. This object takes an estimator during the construction and exposes an estimator API:
>>> from sklearn.model_selection import GridSearchCV, cross_val_score >>> Cs = np.logspace(-6, -1, 10) >>> clf = GridSearchCV(estimator=svc, param_grid=dict(C=Cs), ... n_jobs=-1) >>> clf.fit(X_digits[:1000], y_digits[:1000]) GridSearchCV(cv=None,... >>> clf.best_score_ 0.925... >>> clf.best_estimator_.C 0.0077... >>> # Prediction performance on test set is not as good as on train set >>> clf.score(X_digits[1000:], y_digits[1000:]) 0.943...
Cross-validated estimators
https://scikit-learn.org/stable/tutorial/statistical_inference/model_selection.html#cross-validated-estimators
交叉验证用于选择超参是更加有效的, 在基于算法的算法基础上。
所以有一些模型自身就提供校验验证模型, 例如 lassoCV
Cross-validation to set a parameter can be done more efficiently on an algorithm-by-algorithm basis. This is why, for certain estimators, scikit-learn exposes Cross-validation: evaluating estimator performance estimators that set their parameter automatically by cross-validation:
>>> from sklearn import linear_model, datasets >>> lasso = linear_model.LassoCV() >>> X_diabetes, y_diabetes = datasets.load_diabetes(return_X_y=True) >>> lasso.fit(X_diabetes, y_diabetes) LassoCV() >>> # The estimator chose automatically its lambda: >>> lasso.alpha_ 0.00375...
These estimators are called similarly to their counterparts, with ‘CV’ appended to their name.
N折交叉验证的作用
https://zhuanlan.zhihu.com/p/113623623
用途一:模型选择
交叉验证最关键的作用是进行模型选择,也可以称为超参数选择。
在这种情况下,数据集需要划分成训练集、验证集、测试集三部分,训练集和验证集的划分采用N折交叉的方式。很多人会把验证集和测试集搞混,如果是这种情况,必须明确地区分验证集和测试集。
- 验证集是在训练过程中用于检验模型的训练情况,从而确定合适的超参数;
- 测试集是在训练结束之后,测试模型的泛化能力。
具体的过程是,首先在训练集和验证集上对多种模型选择(超参数选择)进行验证,选出平均误差最小的模型(超参数)。选出合适的模型(超参数)后,可以把训练集和验证集合并起来,在上面重新把模型训练一遍,得到最终模型,然后再用测试集测试其泛化能力。
对这种类型的交叉验证比较有代表性的解释有:台大李宏毅的《机器学习》课程、李飞飞的《CS231N计算机视觉》课程等。
台大李宏毅《机器学习》课程 Lec2 ”where does the error come from“
交叉验证的另一个用途,就是模型是确定的,没有多个候选模型需要选,只是用交叉验证的方法来对模型的performance进行评估。
这种情况下,数据集被划分成训练集、测试集两部分,训练集和测试集的划分采用N折交叉的方式。这种情况下没有真正意义上的验证集,个人感觉这种方法叫做”交叉测试“更合理...
相比于传统的模型评估的方式(划分出固定的训练集和测试集),交叉验证的优势在于:避免由于数据集划分不合理而导致的问题,比如模型在训练集上过拟合,这种过拟合不是可能不是模型导致的,而是因为数据集划分不合理造成的。这种情况在用小规模数据集训练模型时很容易出现,所以在小规模数据集上用交叉验证的方法评估模型更有优势。
对这种类型的交叉验证比较有代表性的解释有:周志华《机器学习》。
周志华《机器学习》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号