multilabel of sklearn
multilabel
https://scikit-learn.org/stable/modules/multiclass.html#multilabel-classification
多标记, 对于一个样本数据, 多个可能的标签。
例如, 一段文本或者视频, 可能关于 宗教 政治 金融 教育 其中之一,或者多个, 或者全部。
多个标签之间可能又关系, 也可能是独立的, 分别有不同的模型。
标签独立的 可以使用 MultiOutputClassifier
Multilabel classification (closely related to multioutput classification) is a classification task labeling each sample with
mlabels fromn_classespossible classes, wheremcan be 0 ton_classesinclusive. This can be thought of as predicting properties of a sample that are not mutually exclusive. Formally, a binary output is assigned to each class, for every sample. Positive classes are indicated with 1 and negative classes with 0 or -1. It is thus comparable to runningn_classesbinary classification tasks, for example withMultiOutputClassifier. This approach treats each label independently whereas multilabel classifiers may treat the multiple classes simultaneously, accounting for correlated behavior among them.For example, prediction of the topics relevant to a text document or video. The document or video may be about one of ‘religion’, ‘politics’, ‘finance’ or ‘education’, several of the topic classes or all of the topic classes.
形象解释
https://towardsdatascience.com/building-a-multi-label-text-classifier-using-bert-and-tensorflow-f188e0ecdc5d
对于天气特征, 如果是多分类(multiclass), 天气可能是 晴天 阴天 雨 雪 等之一, 天气预报只负责较粗略的特征。
对于详细的天气特征, 例如 有没有太阳、 有没有云、 有没有月亮, 则可以是其中之一, 也可以有多个, 这个就是多标签。
In a multi-label classification problem, the training set is composed of instances each can be assigned with multiple categories represented as a set of target labels and the task is to predict the label set of test data e.g.,
- A text might be about any of religion, politics, finance or education at the same time or none of these.
- A movie can be categorized into action, comedy and romance genre based on its summary content. There is possibility that a movie falls into multiple genres like romcoms [romance & comedy].
How is it different from multi-class classification problem?
In Multi-class classification each sample is assigned to one and only one label: a fruit can be either an apple or a pear but not both at the same time. Let us consider an example of three classes C= [“Sun, “Moon, Cloud”]. In multi-class each sample can belong to only one of C classes. In multi-label case each sample can belong to one or more than one class.

图像标签
https://towardsdatascience.com/approaches-to-multi-label-classification-1cf981ff2108
例如一副照片中, 有多个物体, 需要给标注多个标签, 选用模型的时候,也需要模型支持多标签 mulitilabel(也是多输出 multiouput)。
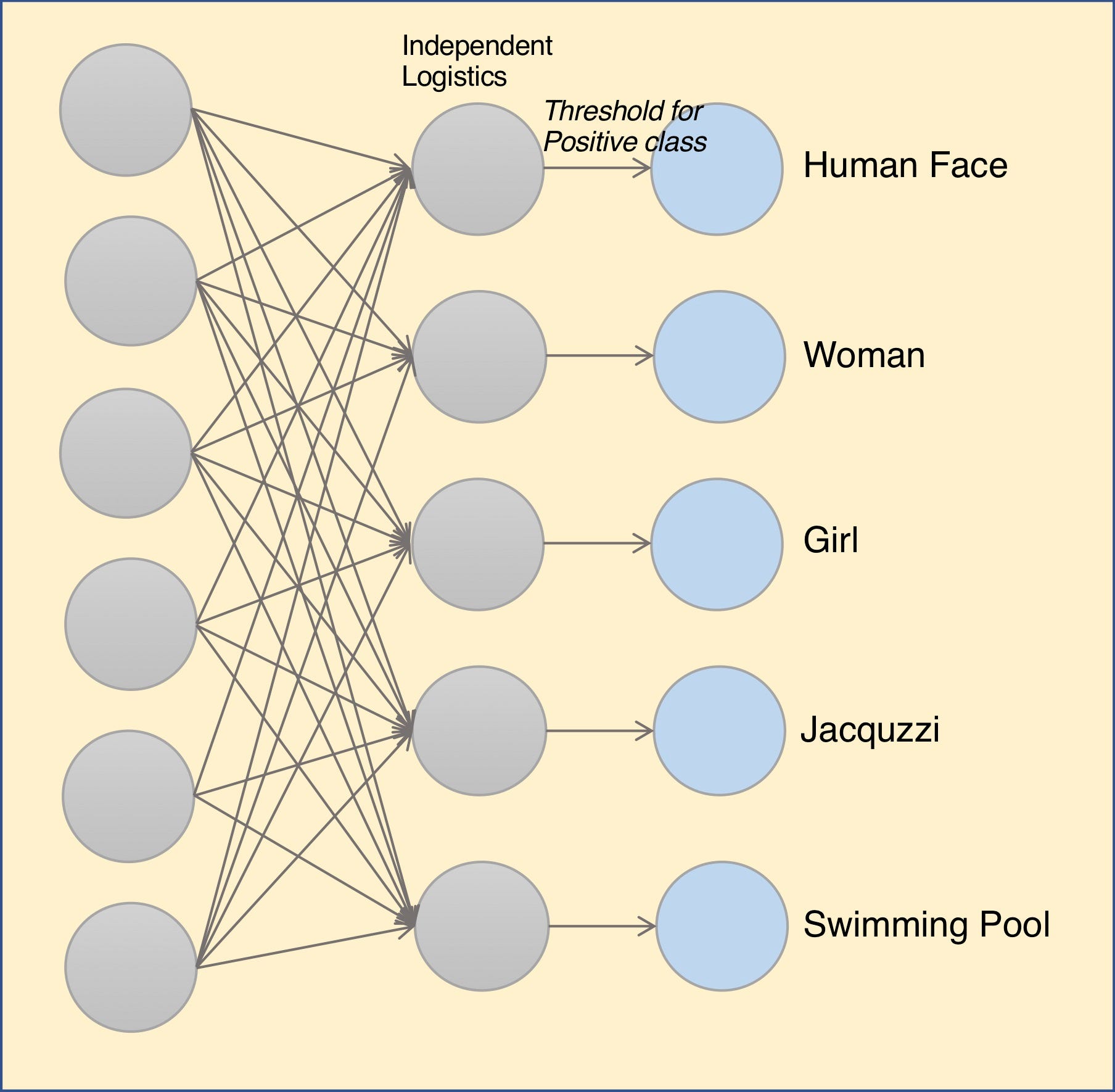
A multi-label classification for an image deals with a situation where an image can belong to more than one class. For example the below image has a train, woman, girl and Jacuzzi all in the same photo.
Photo Credit: Open Image Dataset V4 (License)
There are multiple ways to solve this problem. The first approach is that of binary classification. In this approach we can use ‘k’ independent binary classifiers corresponding to k classes in our data.
This approach the final layer is consists of k independent sigmoid (logistics) activation. The class prediction is based on a threshold value of the logistics layer.
This approach is easy to understand and train. However, this approach has a deficiency. There are semantic relation between the labels which we are ignoring. For example ‘Human Face’ and Woman are related. And so are Human Face and Girl.

Target format
对标签输出的目标, 是个矩阵, 每列表示一个标签。
矩阵如果很是稀疏, 可以使用系数矩阵存储。
A valid representation of multilabel
yis an either dense or sparse binary matrix of shape(n_samples, n_classes). Each column represents a class. The1’s in each row denote the positive classes a sample has been labeled with. An example of a dense matrixyfor 3 samples:>>> y = np.array([[1, 0, 0, 1], [0, 0, 1, 1], [0, 0, 0, 0]]) >>> print(y) [[1 0 0 1] [0 0 1 1] [0 0 0 0]]Dense binary matrices can also be created using
MultiLabelBinarizer. For more information, refer to Transforming the prediction target (y).An example of the same
yin sparse matrix form:>>> y_sparse = sparse.csr_matrix(y) >>> print(y_sparse) (0, 0) 1 (0, 3) 1 (1, 2) 1 (1, 3) 1
MultiOutputClassifier
https://scikit-learn.org/stable/modules/generated/sklearn.multioutput.MultiOutputClassifier.html#sklearn.multioutput.MultiOutputClassifier
对于不支持多标签/目标分类的模型, 可以通过这个分类器外壳,组装成支持多标签的分类器。
其实现原理, 是对于多标签的每一列, 即每一个目标, 单独构建一个分类器。 那么几个标签,就需要几个独立的模型。
Multi target classification
This strategy consists of fitting one classifier per target. This is a simple strategy for extending classifiers that do not natively support multi-target classification
Multilabel classification support can be added to any classifier with
MultiOutputClassifier. This strategy consists of fitting one classifier per target. This allows multiple target variable classifications. The purpose of this class is to extend estimators to be able to estimate a series of target functions (f1,f2,f3…,fn) that are trained on a single X predictor matrix to predict a series of responses (y1,y2,y3…,yn).
>>> from sklearn.datasets import make_classification >>> from sklearn.multioutput import MultiOutputClassifier >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.utils import shuffle >>> import numpy as np >>> X, y1 = make_classification(n_samples=10, n_features=100, n_informative=30, n_classes=3, random_state=1) >>> y2 = shuffle(y1, random_state=1) >>> y3 = shuffle(y1, random_state=2) >>> Y = np.vstack((y1, y2, y3)).T >>> n_samples, n_features = X.shape # 10,100 >>> n_outputs = Y.shape[1] # 3 >>> n_classes = 3 >>> forest = RandomForestClassifier(random_state=1) >>> multi_target_forest = MultiOutputClassifier(forest, n_jobs=-1) >>> multi_target_forest.fit(X, Y).predict(X) array([[2, 2, 0], [1, 2, 1], [2, 1, 0], [0, 0, 2], [0, 2, 1], [0, 0, 2], [1, 1, 0], [1, 1, 1], [0, 0, 2], [2, 0, 0]])
MultiOutputClassifier Example
https://www.datatechnotes.com/2020/03/multi-output-classification-with-multioutputclassifier.html
code
from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix from sklearn.metrics import roc_auc_score from sklearn.metrics import classification_report from sklearn.datasets import make_multilabel_classification from sklearn.svm import SVC from sklearn.multioutput import MultiOutputClassifier x, y = make_multilabel_classification(n_samples=5000, n_features=10, n_classes=2, random_state=0) for i in range(10): print(x[i]," => ", y[i]) xtrain, xtest, ytrain, ytest=train_test_split(x, y, train_size=0.95, random_state=0) print(len(xtest)) svc = SVC(gamma="scale") model = MultiOutputClassifier(estimator=svc) print(model) model.fit(xtrain, ytrain) print(model.score(xtrain, ytrain)) yhat = model.predict(xtest) auc_y1 = roc_auc_score(ytest[:,0],yhat[:,0]) auc_y2 = roc_auc_score(ytest[:,1],yhat[:,1]) print("ROC AUC y1: %.4f, y2: %.4f" % (auc_y1, auc_y2)) cm_y1 = confusion_matrix(ytest[:,0],yhat[:,0]) cm_y2 = confusion_matrix(ytest[:,1],yhat[:,1]) print(cm_y1) print(cm_y2) cr_y1 = classification_report(ytest[:,0],yhat[:,0]) cr_y2 = classification_report(ytest[:,1],yhat[:,1]) print(cr_y1) print(cr_y2)
output
[ 5. 11. 8. 7. 7. 9. 0. 8. 5. 5.] => [1 1]
[1. 2. 6. 1. 6. 8. 1. 9. 3. 8.] => [0 1]
[8. 3. 7. 6. 4. 7. 0. 4. 7. 6.] => [1 1]
[3. 4. 9. 4. 3. 7. 0. 2. 7. 8.] => [1 1]
[ 8. 7. 10. 8. 7. 4. 1. 4. 10. 9.] => [1 1]
[ 6. 5. 10. 5. 5. 3. 7. 6. 1. 9.] => [0 0]
[ 7. 4. 13. 6. 5. 4. 1. 4. 5. 10.] => [1 1]
[ 5. 2. 3. 14. 10. 4. 2. 0. 6. 12.] => [1 0]
[10. 3. 1. 5. 7. 9. 3. 3. 4. 3.] => [0 0]
[ 5. 4. 9. 5. 8. 10. 0. 8. 3. 9.] => [0 1]
250
MultiOutputClassifier(estimator=SVC())
0.8688421052631579
ROC AUC y1: 0.9206, y2: 0.9202
[[ 80 8]
[ 11 151]]
[[ 77 9]
[ 9 155]]
precision recall f1-score support
0 0.88 0.91 0.89 88
1 0.95 0.93 0.94 162
accuracy 0.92 250
macro avg 0.91 0.92 0.92 250
weighted avg 0.92 0.92 0.92 250
precision recall f1-score support
0 0.90 0.90 0.90 86
1 0.95 0.95 0.95 164
accuracy 0.93 250
macro avg 0.92 0.92 0.92 250
weighted avg 0.93 0.93 0.93 250
ClassifierChain
https://scikit-learn.org/stable/modules/generated/sklearn.multioutput.ClassifierChain.html#sklearn.multioutput.ClassifierChain
MultiOutputClassifier类型的分类器, 是基于标签独立的假设。
但是现实生活中, 往往标签数据之间是具有相关性的, 除非使用PCA之列工具,进行分解成独立不相关的更少列的数据。
ClassifierChain 就是面向这种标签之间存在相关性的情况。
有多少个标签就有多少个分类器, 但是分类器是具有顺序的, 第一个分类器输出的第一个标签预测值, 此值会和样本数据一同送入 第二个模型的输入。
A multi-label model that arranges binary classifiers into a chain.
Each model makes a prediction in the order specified by the chain using all of the available features provided to the model plus the predictions of models that are earlier in the chain.
Classifier chains (see
ClassifierChain) are a way of combining a number of binary classifiers into a single multi-label model that is capable of exploiting correlations among targets.For a multi-label classification problem with N classes, N binary classifiers are assigned an integer between 0 and N-1. These integers define the order of models in the chain. Each classifier is then fit on the available training data plus the true labels of the classes whose models were assigned a lower number.
When predicting, the true labels will not be available. Instead the predictions of each model are passed on to the subsequent models in the chain to be used as features.
Clearly the order of the chain is important. The first model in the chain has no information about the other labels while the last model in the chain has features indicating the presence of all of the other labels. In general one does not know the optimal ordering of the models in the chain so typically many randomly ordered chains are fit and their predictions are averaged together.
>>> from sklearn.datasets import make_multilabel_classification >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.model_selection import train_test_split >>> from sklearn.multioutput import ClassifierChain >>> X, Y = make_multilabel_classification( ... n_samples=12, n_classes=3, random_state=0 ... ) >>> X_train, X_test, Y_train, Y_test = train_test_split( ... X, Y, random_state=0 ... ) >>> base_lr = LogisticRegression(solver='lbfgs', random_state=0) >>> chain = ClassifierChain(base_lr, order='random', random_state=0) >>> chain.fit(X_train, Y_train).predict(X_test) array([[1., 1., 0.], [1., 0., 0.], [0., 1., 0.]]) >>> chain.predict_proba(X_test) array([[0.8387..., 0.9431..., 0.4576...], [0.8878..., 0.3684..., 0.2640...], [0.0321..., 0.9935..., 0.0625...]])
ClassifierChain--形象解释
https://towardsdatascience.com/multi-label-text-classification-5c505fdedca8
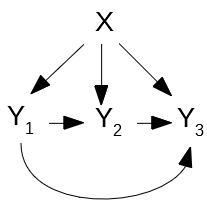
Classifier chain model learns classifiers as in binary relevance method. However, all classifiers are linked in a chain.
Fig. 4 Classifier Chain rule
- Firstly, all the features (X1, X2, …, Xm) are used to predict y1.
- Then, all the features (X1, X2, …, Xm, y1) are used to predict y2
- Finally, (X1, X2, …, Xm, y1, y2) are applied to predict y3
The order in which labels are predicted has large impact on the results.
┌────────────────────────────┬──────────────────────────┐
│ Advantages │ Disadvantages │
├────────────────────────────┼──────────────────────────┤
│ - label correlation taken │ - accuracy heavily │
│ into consideration │ depends on the order │
│ - acceptable computational │ - for n labels there │
│ complexity │ are n! possible orders │
└────────────────────────────┴──────────────────────────┘
multilabel 学习专用库
https://towardsdatascience.com/multi-label-text-classification-5c505fdedca8
http://scikit.ml/
Multi-Label Classification in Python
Scikit-multilearn is a BSD-licensed library for multi-label classification that is built on top of the well-known scikit-learn ecosystem.
pip install scikit-multilearn
MultiLabelBinarizer
https://scikit-learn.org/stable/tutorial/basic/tutorial.html#model-persistence
With multilabel outputs, it is similarly possible for an instance to be assigned multiple labels:
>>> from sklearn.preprocessing import MultiLabelBinarizer >>> y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]] >>> y = MultiLabelBinarizer().fit_transform(y) >>> classif.fit(X, y).predict(X) array([[1, 1, 0, 0, 0], [1, 0, 1, 0, 0], [0, 1, 0, 1, 0], [1, 0, 1, 0, 0], [1, 0, 1, 0, 0]])In this case, the classifier is fit upon instances each assigned multiple labels. The
MultiLabelBinarizeris used to binarize the 2d array of multilabels tofitupon. As a result,predict()returns a 2d array with multiple predicted labels for each instance.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号