机器学习数据编排工具--dagster
DAGSTER
https://github.com/dagster-io/dagster
Dagster is a data orchestrator for machine learning, analytics, and ETL
dagster是一种数据编排工具,为了机器学习,数据分析 和 ETL处理。
Dagster lets you define pipelines in terms of the data flow between reusable, logical components, then test locally and run anywhere.
让用户定义管线,使用逻辑组件 和 逻辑组件之间的数据流。
With a unified view of pipelines and the assets they produce, Dagster can schedule and orchestrate Pandas, Spark, SQL, or anything else that Python can invoke.
能调度和编排 Pandas Spark Sql等python可以调用的组件。
Dagster is designed for data platform engineers, data engineers, and full-stack data scientists.
是为数据平台工程师、数据工程师、全栈数据科学家设计。
Building a data platform with Dagster makes your stakeholders more independent and your systems more robust.
使用dagster构建数据平台,使你的利益相关者更加独立,系统更加健壮。
Developing data pipelines with Dagster makes testing easier and deploying faster.
组件
This installs two modules:
- Dagster: the core programming model and abstraction stack; stateless, single-node, single-process and multi-process execution engines; and a CLI tool for driving those engines.
- Dagit: the UI for developing and operating Dagster pipelines, including a DAG browser, a type-aware config editor, and a live execution interface.
样例
from dagster import execute_pipeline, pipeline, solid @solid def get_name(_): return 'dagster' @solid def hello(context, name: str): context.log.info('Hello, {name}!'.format(name=name)) @pipeline def hello_pipeline(): hello(get_name())
DAG来源
https://www.cnblogs.com/en-heng/p/5085690.html
DAG常用语管理工作流。
有向无环图(Directed Acyclic Graph, DAG)是有向图的一种,字面意思的理解就是图中没有环。常常被用来表示事件之间的驱动依赖关系,管理任务之间的调度。拓扑排序是对DAG的顶点进行排序,使得对每一条有向边(u, v),均有u(在排序记录中)比v先出现。亦可理解为对某点v而言,只有当v的所有源点均出现了,v才能出现。
下图给出有向无环图的拓扑排序:
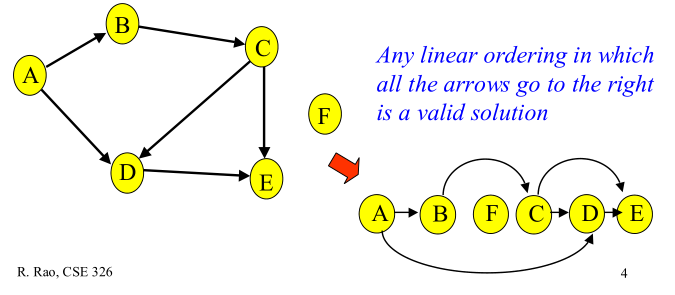
拓扑序列计算
https://github.com/hansrajdas/algorithms/blob/master/Level-3/topological_sort.py
#!/usr/bin/python # Date: 2017-12-30 # # Description: # Find linear topological order of a directed acyclic graph(DAG). # # Approach: # Topological order of DAG is such that if in a graph there is a edge from # u to v then in topological order, u should be before v. # Topological sort is not possible if graph is not DAG. # Performed using DFS and stack. # # Applications: Used for dependent job scheduling like makefiles. # # Reference: # https://www.geeksforgeeks.org/topological-sorting/ # # Complexity: O(V + E) import collections class Graph(object): """Implement methods to manage graph and find its topological order.""" def __init__(self): """Initialises a dictionary to store adjacency list of each vertex.""" self.graph = collections.defaultdict(list) def add_edge(self, start, end): """Adds an edge to graph, updates adjacency list of source vertex.""" self.graph[start].append(end) def topological_sort_util(self, current_node, visited, stack): """Performs DFS to find the topological ordering from the current node.""" visited[current_node] = True for adjacent_vertex in self.graph[current_node]: if self.graph.has_key(adjacent_vertex) and not visited[adjacent_vertex]: self.topological_sort_util(adjacent_vertex, visited, stack) else: if adjacent_vertex not in stack: stack.append(adjacent_vertex) stack.append(current_node) def topological_sort(self): """Finds topological ordering of DAG 'self'.""" # Maintain topological order in stack. stack = [] visited = {v : False for v in self.graph} for vertex in self.graph: if not visited[vertex]: self.topological_sort_util(vertex, visited, stack) stack.reverse() print(stack) g = Graph() g.add_edge(5, 2) g.add_edge(5, 0) g.add_edge(4, 0) g.add_edge(4, 1) g.add_edge(2, 3) g.add_edge(3, 1) g.topological_sort() # Output: [5, 4, 0, 2, 3, 1] g1 = Graph() g1.add_edge(5, 2) g1.add_edge(6, 2) g1.topological_sort() # Output: [6, 5, 2]
对机器学习过程改造
https://github.com/fanqingsong/machine_learning_workflow_on_dagster
把学习过程分成三个逻辑单元,并使用数据流关系连接
(1)数据读取
(2)训练模型
(3)预测测试
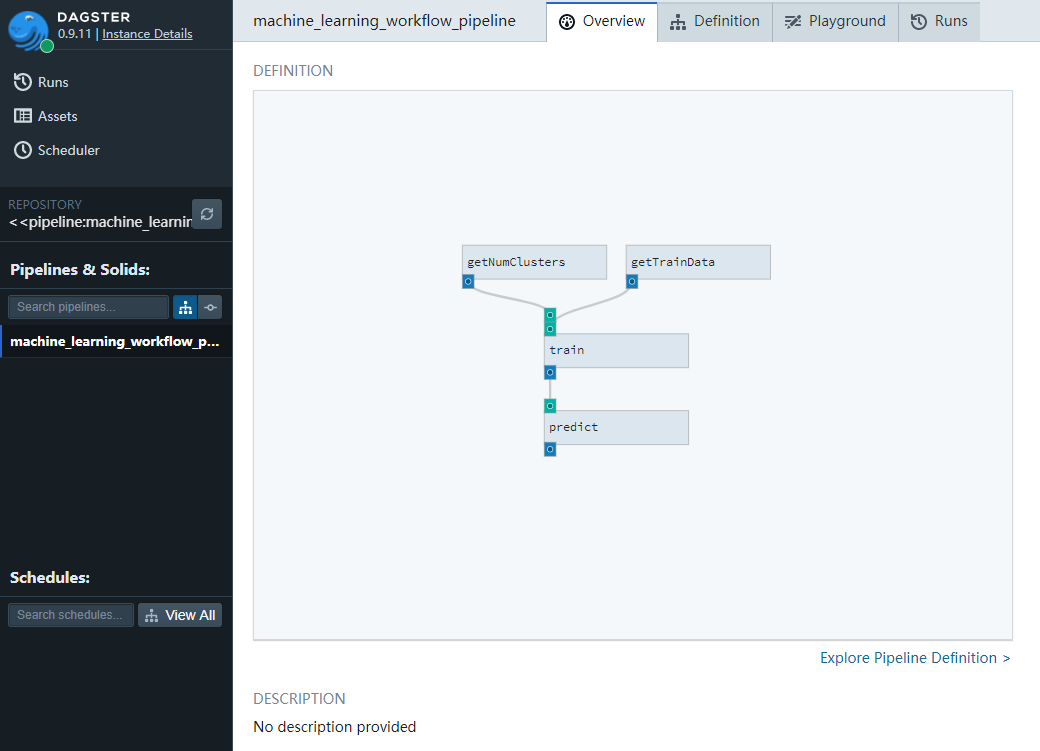
from csv import reader from sklearn.cluster import KMeans import joblib from dagster import ( execute_pipeline, make_python_type_usable_as_dagster_type, pipeline, repository, solid, ) # Load a CSV file def load_csv(filename): file = open(filename, "rt") lines = reader(file) dataset = list(lines) return dataset # Convert string column to float def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # Convert string column to integer def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i for row in dataset: row[column] = lookup[row[column]] return lookup def getRawIrisData(): # Load iris dataset filename = 'iris.csv' dataset = load_csv(filename) print('Loaded data file {0} with {1} rows and {2} columns'.format(filename, len(dataset), len(dataset[0]))) print(dataset[0]) # convert string columns to float for i in range(4): str_column_to_float(dataset, i) # convert class column to int lookup = str_column_to_int(dataset, 4) print(dataset[0]) print(lookup) return dataset @solid def getTrainData(context): dataset = getRawIrisData() trainData = [ [one[0], one[1], one[2], one[3]] for one in dataset ] context.log.info( "Found {n_cereals} trainData".format(n_cereals=len(trainData)) ) return trainData @solid def getNumClusters(context): return 3 @solid def train(context, numClusters, trainData): print("numClusters=%d" % numClusters) model = KMeans(n_clusters=numClusters) model.fit(trainData) # save model for prediction joblib.dump(model, 'model.kmeans') return trainData @solid def predict(context, irisData): # test saved prediction model = joblib.load('model.kmeans') # cluster result labels = model.predict(irisData) print("cluster result") print(labels) @pipeline def machine_learning_workflow_pipeline(): trainData = getTrainData() numClusters = getNumClusters() trainData = train(numClusters, trainData) predict(trainData) if __name__ == "__main__": result = execute_pipeline( machine_learning_workflow_pipeline ) assert result.success
图工具
在数据分析领域,也可以使用networkx来做图关系分析。包括DAG图。
https://github.com/networkx/networkx
NetworkX is a Python package for the creation, manipulation, and study of the structure, dynamics, and functions of complex networks.
>>> import networkx as nx >>> G = nx.Graph() >>> G.add_edge('A', 'B', weight=4) >>> G.add_edge('B', 'D', weight=2) >>> G.add_edge('A', 'C', weight=3) >>> G.add_edge('C', 'D', weight=4) >>> nx.shortest_path(G, 'A', 'D', weight='weight') ['A', 'B', 'D']
https://mungingdata.com/python/dag-directed-acyclic-graph-networkx/
Directed Acyclic Graphs (DAGs) are a critical data structure for data science / data engineering workflows. DAGs are used extensively by popular projects like Apache Airflow and Apache Spark.
This blog post will teach you how to build a DAG in Python with the networkx library and run important graph algorithms.
Once you’re comfortable with DAGs and see how easy they are to work with, you’ll find all sorts of analyses that are good candidates for DAGs. DAGs are just as important as data structures like dictionaries and lists for a lot of analyses.
import networkx as nx graph = nx.DiGraph() graph.add_edges_from([("root", "a"), ("a", "b"), ("a", "e"), ("b", "c"), ("b", "d"), ("d", "e")]) nx.shortest_path(graph, 'root', 'e') # => ['root', 'a', 'e'] nx.dag_longest_path(graph) # => ['root', 'a', 'b', 'd', 'e'] list(nx.topological_sort(graph)) # => ['root', 'a', 'b', 'd', 'e', 'c']
图数据库
https://neo4j.com/docs/operations-manual/current/introduction/
Neo4j is the world’s leading graph database. Its architecture is designed for optimal management, storage, and traversal of nodes and relationships. The database takes a property graph approach, which is beneficial for both traversal performance and operations runtime. Neo4j offers dedicated memory management and memory-efficient operations.
https://zhuanlan.zhihu.com/p/126219777
1)Neovis.js
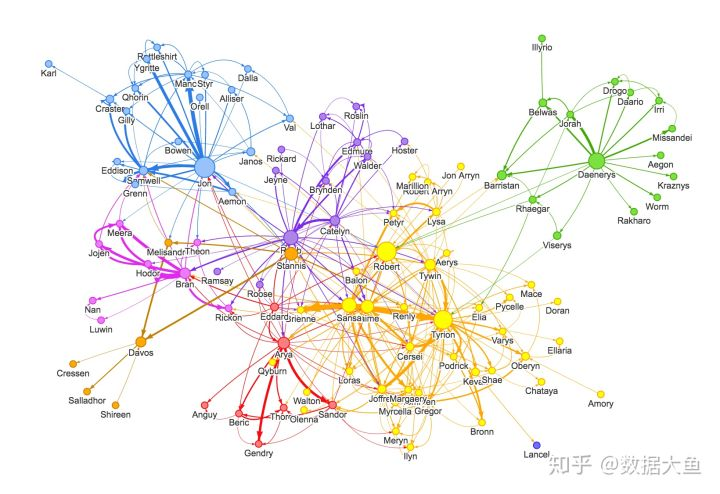
该库旨在将JavaScript可视化和Neo4j无缝集成。与Neo4j的连接非常简单明了,并且由于它是在Neo4j的属性图模型的基础上构建的,因此 Neovis 的数据格式与数据库保持一致。在单个配置对象中定义基于标签、属性、节点和关系的自定义和着色样式。Neovis.js无需编写Cypher即可使用,并且可以使用最少的JavaScript集成到您的项目中。Neovis库是 Neo4j Labs 项目之一,要了解有关Neo4j Labs的更多信息,请访问 Neo4j Labs。
您还可以将此库与 Neo4j 中的图算法库结合使用,以对可视化进行样式设置,使其与诸如PageRank、中心性、社区检测等算法的结果保持一致。下面,我们看到 neovis.js 呈现游戏人物权力相互作用的图可视化,并使用 Neo4j 的PageRank和社区检测算法,增强应用的可视化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号