
第24题:反转链表
题目描述
输入一个链表,反转链表后,输出新链表的表头。
测试用例
// 输入的链表有多个结点 void Test1() { ListNode* pNode1 = CreateListNode(1); ListNode* pNode2 = CreateListNode(2); ListNode* pNode3 = CreateListNode(3); ListNode* pNode4 = CreateListNode(4); ListNode* pNode5 = CreateListNode(5); ConnectListNodes(pNode1, pNode2); ConnectListNodes(pNode2, pNode3); ConnectListNodes(pNode3, pNode4); ConnectListNodes(pNode4, pNode5); ListNode* pReversedHead = Test(pNode1); DestroyList(pReversedHead); } // 输入的链表只有一个结点 void Test2() { ListNode* pNode1 = CreateListNode(1); ListNode* pReversedHead = Test(pNode1); DestroyList(pReversedHead); } // 输入空链表 void Test3() { Test(nullptr); }
考点
1.提前想好测试用例,进行单元测试,设计时间>>编码时间,写出鲁棒代码。
思路
1.防止链表断裂,准备三个指针,保存上一个节点,当前节点,下一个节点。
2.反转链表的头节点是原链表的尾节点,尾节点就是next为nullptr的节点。

第一遍
ListNode* ReverseList(ListNode* pHead)
{
//1.鲁棒1:空链表返回nullptr
if (!pHead)
return nullptr;
//2.定义三个指针pPre,pNode,pNext和ReverseHead
ListNode* pNode = pHead;
ListNode* pPre = nullptr;
ListNode* pNext = nullptr;
ListNode* ReverseHead = nullptr;
//3.while(pNode)
while (pNode)
{
//3.1 记录下个节点
pNext = pNode->m_pNext;
//3.2 如果是尾节点,更新ReverseHead = pNode;
if (!pNext)
ReverseHead = pNode;
//3.3 反转节点
pNode->m_pNext = pPre;
//3.4 更新pPre,pNode
pPre = pNode;
pNode = pNext;
}
//4.返回ReverseHead
return ReverseHead;
}第二遍
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* ReverseList(ListNode* pHead) {
//1.链表为空
if(!pHead)
return nullptr;
//2.定义前中后三个指针,新链表的表头
ListNode* pPre = nullptr;
ListNode* pNode = pHead;
ListNode* pNext = nullptr;
ListNode* reverseNode = nullptr;
//3.while pNode存在时
while(pNode)
{
//3.1.防止断开,保存pNext
pNext= pNode->next;
//3.2.如果是原链表尾节点,pNext为空,更新reverseNode为pNode
if(!pNext)
reverseNode=pNode;
//3.3反转
pNode->next=pPre;
//3.4.更新pPre,pNode
pPre= pNode;
pNode=pNext;
}
//4.返回reverseNode
return reverseNode ;
}
};扩展题目
用递归实现链表的反转
我们知道迭代是从前往后依次处理,直到循环到链尾;而递归恰恰相反,首先一直迭代到链尾也就是递归基判断的准则,然后再逐层返回处理到开头。
总结来说,链表翻转操作的顺序对于迭代来说是从链头往链尾,而对于递归是从链尾往链头。
我们再来看看递归实现链表翻转的实现,前面非递归方式是从前面数1开始往后依次处理,而递归方式则恰恰相反,它先循环找到最后面指向的数5,然后从5开始处理依次翻转整个链表。
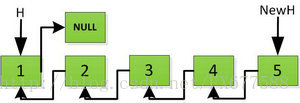
首先指针H迭代到底如下图所示,并且设置一个新的指针作为翻转后的链表的头。由于整个链表翻转之后的头就是最后一个数,所以整个过程NewH指针一直指向存放5的地址空间。
然后H指针逐层返回的时候依次做下图的处理,将H指向的地址赋值给H->next->next指针,并且一定要记得让H->next =NULL,也就是断开现在指针的链接,否则新的链表形成了环,下一层H->next->next赋值的时候会覆盖后续的值。
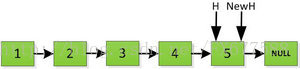
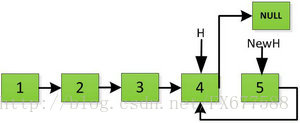
继续返回操作:
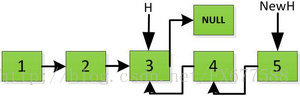
上图第一次如果没有将存放4空间的next指针赋值指向NULL,第二次H->next->next=H,就会将存放5的地址空间覆盖为3,这样链表一切都大乱了。接着逐层返回下去,直到对存放1的地址空间处理。
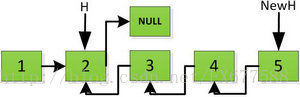
返回到头:
//递归
ListNode* ReverseList(ListNode* pHead)
{
//1.结束条件 : 如果空链表,或者 只有一个节点,返回pHead
if (!pHead || !(pHead->m_pNext))
return pHead;
//2.新链表的头节点 :递归下一个节点,递归到最后一个节点时,返回最后一个节点
ListNode* ReverseHead = ReverseList(pHead->m_pNext);
//3.反转,pNode->next->next=pNode
pHead->m_pNext->m_pNext = pHead;
//4.并将原链表的pNode->next设为空,断开
pHead->m_pNext = nullptr;
//5.返回新链表的头节点
return ReverseHead;
}
递归的方法其实是非常巧的,它利用递归走到链表的末端,然后再更新每一个node的next 值 ,实现链表的反转。而newhead 的值没有发生改变,为该链表的最后一个结点,所以,反转后,我们可以得到新链表的head。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号