从RocksDBStateBackend讲述Flink的State机制
1.前言
之前几篇文章都是围绕Rocksdb状态后端引申出来的一系列问题,本文主要介绍一下Rocksdb作为状态后端的一些技术细节,以及Flink的状态抽象是如何设计的,为开发一个新的状态后端做指导。
本文基于Flink 1.8.2,目前Flink版本处于一种快速变化的过程,所以可能不适用于高版本,但仍有借鉴意义。
2.结构
Flink的状态定义都在flink-runtime包下,路径是org.apache.flink.runtime.state,里面有若干子模块,可以看见分成filesystem(文件状态后端),heap(通用的内存操作结构),memory(内存状态后端),metainfo(状态的元数据描述),ttl(状态过期清除的一些设置)。其他包的根节点类都是一些状态的抽象定义,包括抽象状态后端,抽象key状态后端,抽象快照策略,checkpoint触发listener,checkpoint存储,checkpoint流等等,总的来说就是状态后端,checkpoint保存,restore恢复,keyGroup和其他的一些相关内容。
RocksdbStateBackend不是Flink内置的状态,需要在pom.xml中引入flink-statebackend-rocksdb_${scala.version},其包结构也十分简单:操作rocksdb的迭代器封装,恢复,快照和基本状态后端实现类。
3.RocksDB
3.1 快照
快照就是当前瞬间的一个状态保存,这个基本上就是配合checkpoint使用的了。
- 接口是:SnapshotStrategy,只有一个方法,snapshot,参数是checkpointId, timestamp, checkpointStreamFactory,checkpointOptions。
该方法调用地方主要是AbstractStreamOperator的snapshotState,看名称可以理解是在某个时间点,保存某次checkpoint的数据,streamFactory提供了快照数据输出的流,用于持久化数据,在CheckpointStorage.resolveCheckpointStorageLocation的时候,会创建这个对象,保证提供了输出流。
- 抽象类是:AbstractSnapshotStrategy,其没有做任何操作,只提供了日志输出,日志输出需要描述字段,限制了一下接口泛型。
- Rocksdb继承了AbstractSnapshotStrategy,也是一个抽象类:RocksDBSnapshotStrategyBase,同时其实现了CheckpointListener接口。
构造函数需要父类的描述,rocksdb对象,key序列化器,keyGroup的范围及前缀,recovery配置,和kvState的元数据,资源控制。其没有什么复杂的逻辑,如果kvState没有,直接返回成功,否则交给子类做处理。
结果对象是SnapshotResult,里面有jobManagerOwnedSnapshot和taskLocalSnapshot,都是继承了StateObject
- 实现类有两个,一个是RocksFullSnapshotStrategy,另一个是RocksIncrementalSnapshotStrategy。全量快照用于savepoint,以及未开启增量模式的checkpoint,增量快照自然是用于增量模式的checkpoint。具体创建可以看方法RocksDBKeyedStateBackendBuilder.initializeSavepointAndCheckpointStrategies.
- RocksFullSnapshotStrategy的描述字段是Asynchronous incremental RocksDB snapshot,不知道是不是打错了-.-. 和增量快照一样。其notifyCheckpointComplete方法啥也没做,具体快照步骤是:
- 如果允许本地恢复且类型不是SAVEPOINT(state.backend.local-recovery默认是false不允许),会调用CheckpointStreamWithResultProvider.createDuplicatingStream,否则调用CheckpointStreamWithResultProvider.createSimpleStream,后者一般是默认选择。所以,使用本地恢复的区别在于两种不同的方式,前者会输出一份到本地恢复的文件夹,后者只会输出到streamFactory提供的输出目的地。
- 复制kvState的元数据,不同的元数据有不同的实现,类型看StateMetaInfoSnapshot,存在KEYVALUE,OPERATOR,BROADCAST,PRIORITY_QUEUE.
- 然后从资源控制获取令牌,看ResourceGuard的逻辑可以看到,其要close必须所有的令牌都被close了,是一种保护措施了。
- 最后得到rocksdb的一个snapshot对象。
- 根据上面步骤得到的对象,生成SnapshotAsynchronousPartCallable,最后执行toAsyncSnapshotFutureTask,返回一个RunnableFuture对象,执行逻辑都在callInternal()方法里面
- 先创建KeyGroupOffset对象,获取checkpoint输出流提供者,然后注册到snapshotCloseableRegistry,这样最后关闭的时候会关闭流。然后调用writeSnapshotToOutputStream写入数据,最后判断关闭。
- 写入数据流,先创建每个kvState对应的元数据,并提供编号,会为每个元数据创建一个rocksdb的列族迭代器,flink使用的rocksdb时,每个state都是一个列族。然后会写入一些必要信息,操作都是在KeyedBackendSerializationProxy.write中,是否压缩,写入key之类的,最后写入元数据的快照。第二步就是写入状态的真实数据了,用的就是第一步生成的每个rocksdb列族的迭代器,其会使用RocksStatesPerKeyGroupMergeIterator将所有的kvState数据按照顺序包装成一个迭代器,这样操作方便,顺序与之前写入的元数据基本相同,除非没有可迭代的内容。https://developer.aliyun.com/article/667562?spm=a2c6h.13262185.0.0.3d747e185enfna 这篇文章介绍了keyGroup的概念,写入也会按组的方式设置相关数据。
- RocksIncrementalSnapshotStrategy是增量式快照,具体步骤如下:
- 准备本地临时文件夹,然后使用rocksdb的checkpoint,写入临时文件,获取状态元数据备份
- 写入全量元数据到目标输出流,上传当前此次checkpoint产生的sst文件。后面就没啥内容了
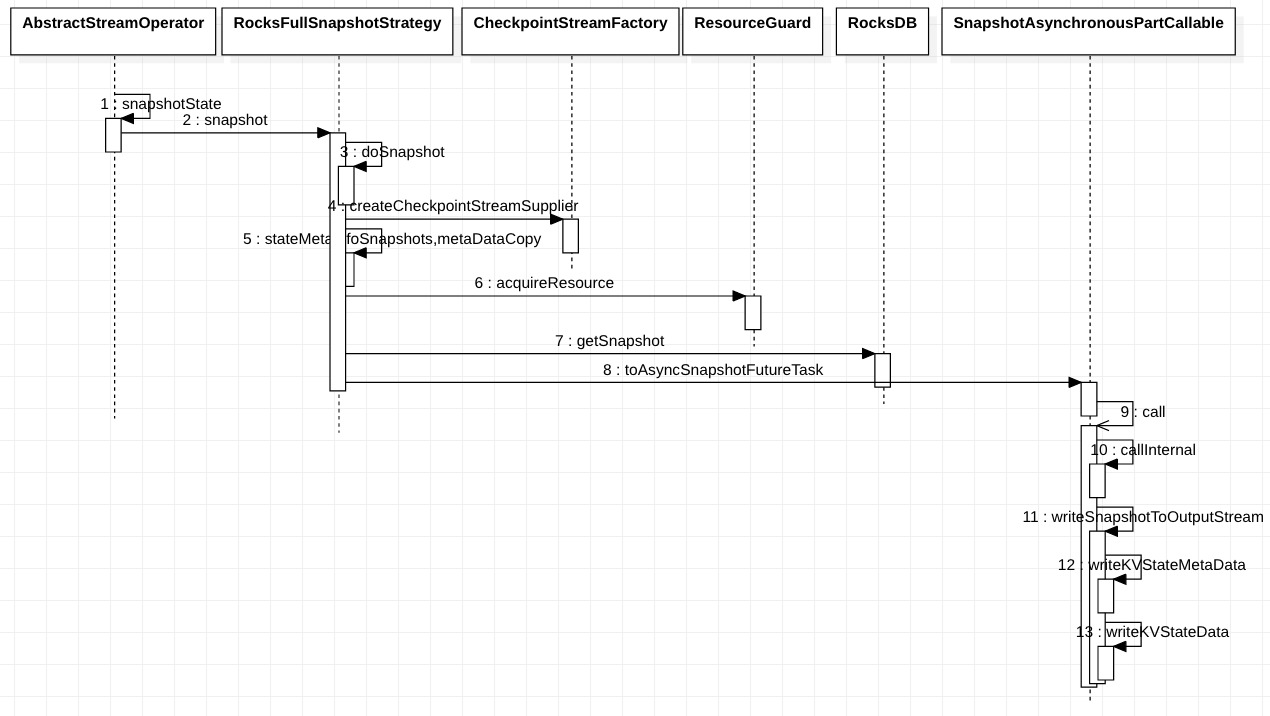
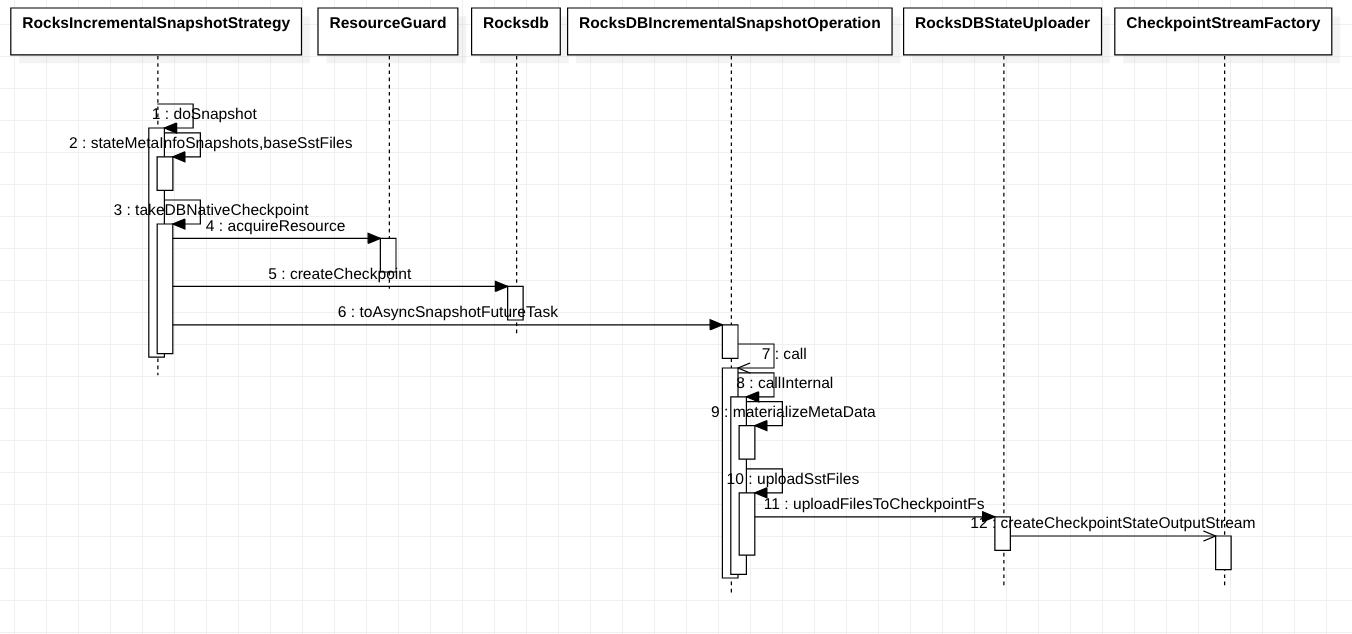
上图就是全量快照和增量快照的一个时序图了。起点都是streamOperator触发快照函数,选择对应的快照策略。全量快照是通过rocksdb的snapshot进行的,会将其放入readOptions,先通过快照获取rocksdb的迭代器和元数据信息,元数据直接写入StreamFactory提供的输出流,再通过迭代器写出rocksdb的KV数据。增量快照是通过rocksdb提供的checkpoint写入本地的磁盘文件夹,然后异步的将这些文件上传到StreamFactory提供的输出流中,对于增量快照而言,需要保证每次checkpoint的数据都上传了,且没有重复,所以多了一个lastCompletedCheckpoint的值,本次checkpoint会进行比较最后一次的sst文件,防止重复上传。
3.2 恢复
恢复就是快照的一个逆过程了。
- 接口定义:RestoreOperation,只有一个方法restore,进行恢复,返回恢复结果。
- Rocksdb接口:RocksDBRestoreOperation,限制了返回类型。
- 抽象类:AbstractRocksDBRestoreOperation,主要提供了打开rocksdb,读取元数据的方法,注册列族的方法。
- RocksDBNoneRestoreOperation,最简单的恢复方法,不恢复,从0开始积累数据,重新创建rocksdb数据库
- RocksDBFullRestoreOperation,全量数据恢复方法,打开rocksdb,遍历restoreStateHandles,一个个进行恢复。其实也就是逆过程。
- RocksDBIncrementalRestoreOperation,增量数据恢复,这里的逻辑有点复杂,判断是否需要Rescaling,条件有两个满足一个即可,restoreStateHandles数量是否>1,第一个keyStateHandler的keygroup是否与恢复的相符。
- 不需要重新调整,判断是从远程恢复还是本地恢复了,先恢复最后一次checkpoint的状态,远程的会从远处拉取文件到本地,然后再按本地的方式进行恢复。读取元数据,获取列族信息,将文件拷贝到rocksdb的数据库路径,打开rocksdb,注册列族等
- 需要重新调整,会先判断一个最合适用于恢复的KeyedStateHandle,判断标准在RocksDBIncrementalCheckpointUtils的STATE_HANDLE_EVALUATOR中,需要目标的keyGroup数量占现有的keyedStateHandler的75%。如果找到了就用这个进行恢复,没找到简单的打开数据库。然后就要开始修复缺少了的keyGroupRange数据了,找到目标的开始键前缀和结束键前缀。从远程拉取所有文件,遍历进行查找需要的key的数据,批量写入rocksdb。增量式就这样恢复了需要的内容。
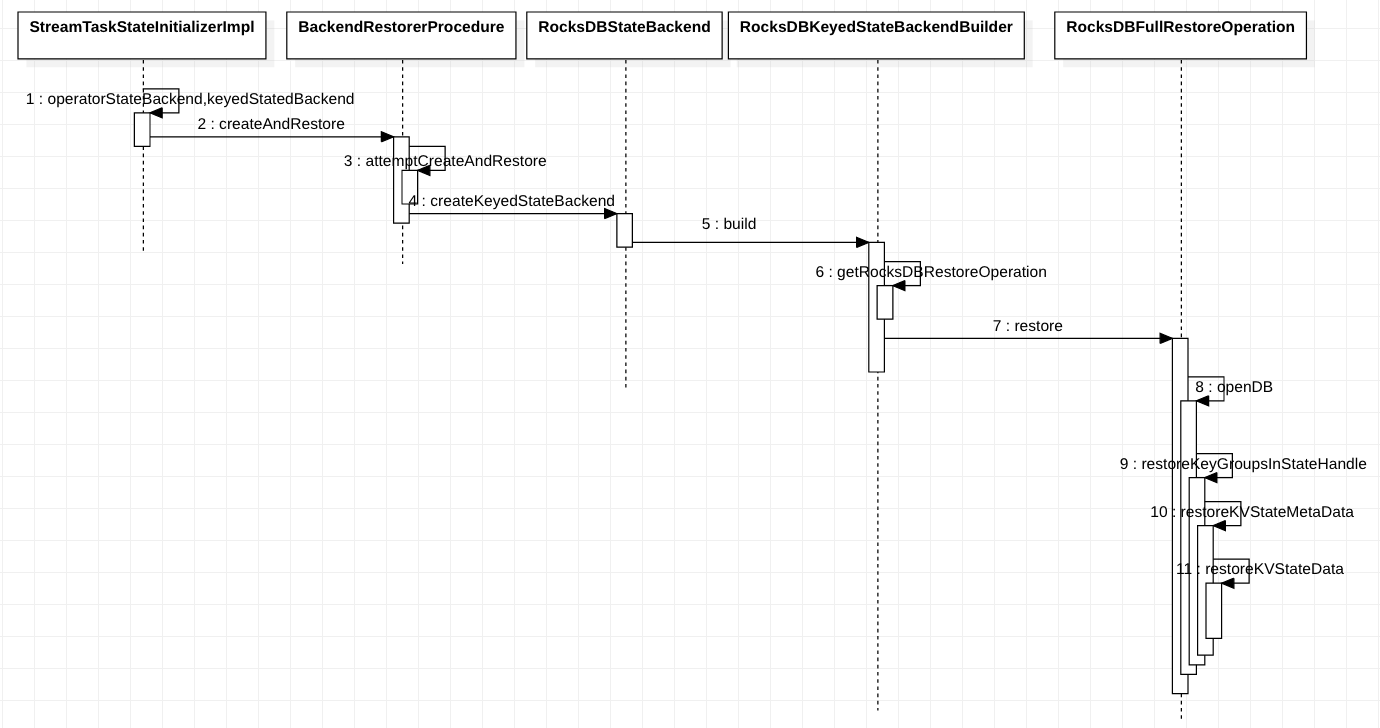
上图是全量恢复的图了,StreamTaskStateInitializerImpl会提供一个需要恢复的KeyedStateHandle集合,然后创建想对应的状态后端,创建过程中会打开Rocksdb数据库,通过KeyedStateHandler提供的输入流读取数据,先恢复元数据,然后恢复写入rocksdb的状态。增量状态恢复是差不多的,所以没有使用时序图,描述见上面,其需要判断是否调整keygroup。重点是keyedStateHandler是哪里来的,其通过TaskStateManager绑定固定的operatorID,所以恢复的时候这个值需要固定。通过jobmanager获取state和最后一次checkpoint信息,恢复状态。
3.3 状态过期
在文章《由Rocksdb状态后端引出的Tree的应用》中简单的介绍了LSM树的一些特性,可以了解到LSM树是无法修改数据的,意味着也无法删除,唯一能够操作的地方就是compact的时候,可以将不要的数据丢弃。
Flink中Rocksdb的状态清除也十分简单,主要逻辑在RocksDbTtlCompactFiltersManager中,通过类RocksDBOperationUtils调用。就是在每次创建列族描述的时候,开启了ttl就为每个state注册一个FlinkCompactionFilterFactory,这个类在rocksdb里面,是rocksdb的java版实现提供给flink设置的,后面会为每个state对应的FlinkCompactionFilterFactory配置ttl参数,这样rocksdb就可以清理state了。
3.4 状态流程
RocksDBStateBackend也没有太多的内容了,剩下的类可以快速分个类:
- 核心类:
- AbstractRocksDBState
- RocksDBKeyedStateBackend
- RocksDBKeyedStateBackendBuilder
- RocksDBStateBackend
- RocksDBStateBackendFactory
- 配置类:
- DefaultConfigurableOptionsFactory:配置工厂类,顾名思义,专门生成配置对象的类
- PredefinedOptions:一些预定义的配置,方便快速设置:DEFAULT(默认使用),SPINNING_DISK_OPTIMIZED(机械硬盘优化),SPINNING_DISK_OPTIMIZED_HIGH_MEM(内存充足时的机械硬盘优化),FLASH_SSD_OPTIMIZED(固态硬盘优化)这四种。默认参数在RocksDBOptions中有显示:state.backend.rocksdb.predefined-options
- RocksDBConfigurableOptions:一些可配置的参数
- RocksDBNativeMetricOptions:可开启的rocksdb的监控项配置,默认全部未开启
- RocksDBOptions:一些全局配置,并非详细的配置项,更多与Flink有关
- RocksDBProperty:rocksdb的jni相关参数
- 需要实现的类:
- RocksDBAggregatingState
- RocksDBFoldingState
- RocksDBListState
- RocksDBMapState
- RocksDBReducingState
- RocksDBValueState
- 功能类:
- RocksDBCachingPriorityQueueSet:内存的优先队列,于RocksDBPriorityQueueSetFactory创建。InternalTimeServiceManager使用。
- RocksDBPriorityQueueSetFactory:提供的rocksdb的TIMER_SERVICE_FACTORY,默认使用的是内存,选择rocksdb这个生效,其创建的是RocksDBCachingPriorityQueueSet。
- RocksDBIncrementalCheckpointUtils:增量式状态后端的工具类
- RocksDBKeySerializationUtils:处理键的序列化工具类
- RocksDBNativeMetricMonitor:rocksdb的监控指标管理
- RocksDBOperationUtils:操作rocksdb的工具类
- RocksDBSerializedCompositeKeyBuilder:封装了序列化组合件的相关方法
- RocksDBSnapshotTransformFactoryAdaptor:一个装饰器
- RocksDBStateDataTransfer:传输的线程配置
- RocksDBStateDownloader:下载保存的状态文件(增量状态)
- RocksDBStateUploader:上传保存的状态文件(增量状态)
- RocksDBWriteBatchWrapper:批量写入封装
- RocksIteratorWrapper:rocksdb的迭代器封装,做接口隔离
以上就是rocksdb的一个基本组成了,要学习主要是从statebackend需要实现的方法来看,然后这些方法具体在什么位置调用的。resolveCheckpoint就是由jobMaster操控的,要不是手动触发,要不是停止任务时需要进行savepoint。createCheckpointStorage是在Task的run方法,invoke调用的,生成的是checkpointStorage对象,这个对象是用于上面快照提供StreamFactory用的。看rocksdb会被大量的文件路径迷惑,只有createCheckpointStorage这个是提供给checkpoint使用的路径(可以在StreamTask中查找到相关方法),其他的路径是本地存储rocksdb文件使用的,另外是临时存储jni文件使用的。operatorStatebackend使用的依旧是flink自带的DefaultOperatorStateBackend,只有keyedStateBackend才是rocksdb开发的。
Rocksdb的状态后端基本就到此结束,主要包含的内容和一些逻辑介绍的差不多了,剩下就是Flink是执行checkpoint的细节问题,这里留一个之前一直迷惑的问题:关于内存设置的迷惑,不清楚的可以先看《Flink内存设置思路》。Flink1.8按照查找到的资料来看,rocksdb使用的是non-heap内存,对于容器启动1.8只有堆和非堆,两个参数加起来占满了整个容器。但是对于1.10而言,其除了堆和非堆,还有很大一块未分配的内存,解释是用于native内存,这块不归jvm管理,rocksdb使用的就是这块内存。这就存在一个疑问了,1.8为什么使用的是非堆内存而1.10就是native内存呢,这两者有什么变化吗?
看MapState等的执行操作,发现依旧是使用native方法,将序列化后的字符串放入。但是看依赖可以发现依赖了不同版本的frocksdbjni.
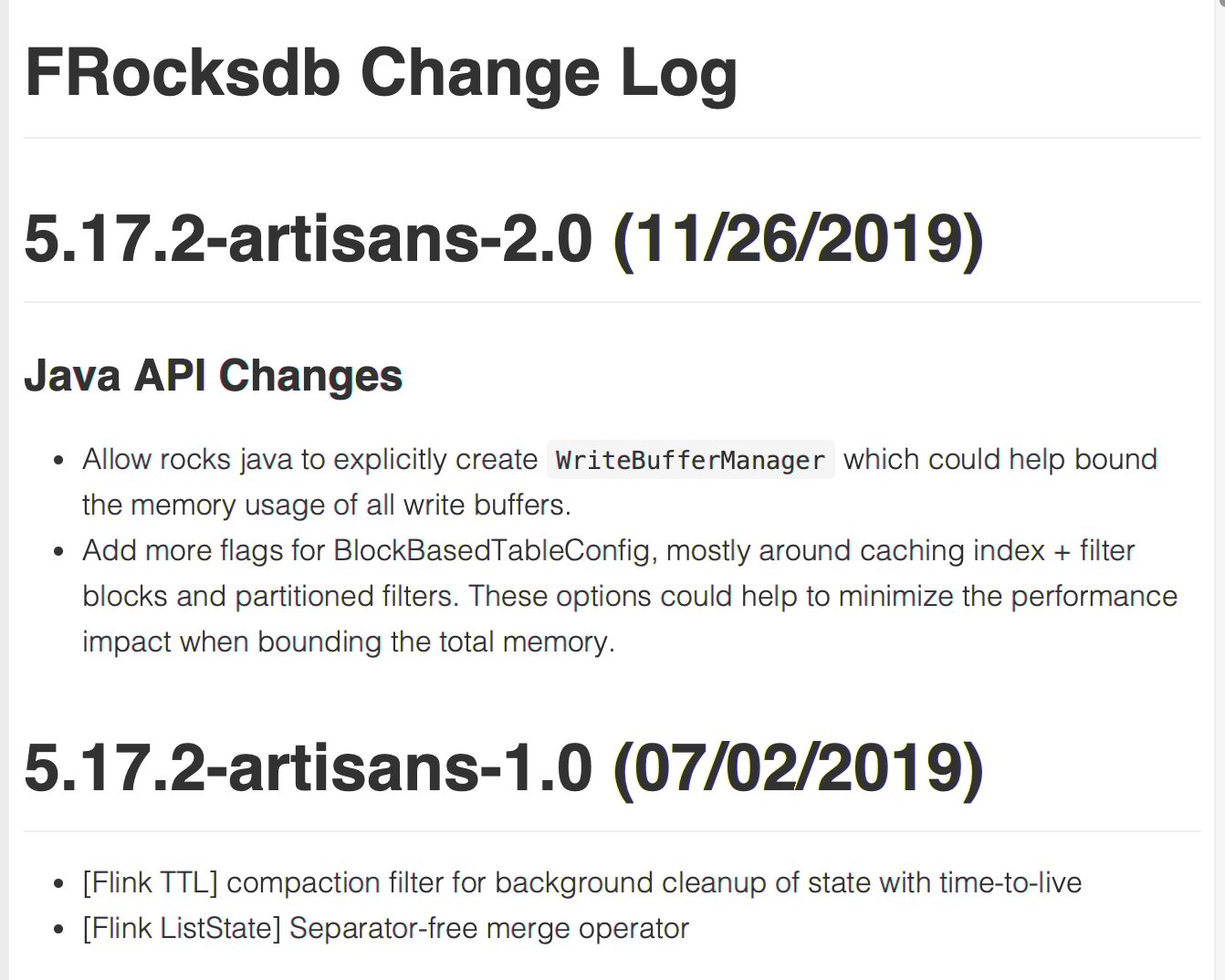
可以看见1.10版本的rocksdb在jni层面提供了java可以干涉的配置项。实际1.10版本多了配置类RocksDBMemoryConfiguration,其都被RocksDBOperationUtils使用。对于1.10和1.8版本,可以发现1.10版本新增了allocateSharedCachesIfConfigured方法,其会生成一个RocksDBSharedResources对象,里面就包含了图片中所说的writeBufferManager,然后这个对象会被包装成resourceContainer,被keyedStateBackend持有。主要影响的位置在ResourceContainer的getColumnOptions方法,如果存在资源管控,就会设置columnOptions。也就是为column进行参数设置,其他的都没有发生变化,在jni内部处理逻辑上产生的影响。剩下jni层为什么1.8是non-heap,1.10是native就没有继续深入了,上面是一个内存管控的问题,如果有哪位知道最初的那个问题,可以留言,或者说有其他解释。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号