
kafka学习指南(总结版)
版本介绍
目前最新版本为2.3(20190808更新)。demo搭建可参见https://www.orchome.com/6,收发消息测试可见https://www.cnblogs.com/yoyo1216/p/14024427.html。
从使用上来看,以0.9为分界线,0.9开始不再区分高级(相当于mysql binlog的GTID,只需要跟topic打交道,服务器自动管理偏移量和负载均衡)/低级消费者API(相当于mysql binlog的文件+position,直接和分区以及偏移量打交道)。同时,0.9版本增加了kafka connect,相当于提供了一个封装好直接采用其它源同步数据(主要是批量模式)的框架,有利有弊吧,门槛低、让一般开发更依赖kafka。
从兼容性上来看,以0.8.x为分界线,0.8.x不兼容以前的版本。
总体拓扑架构
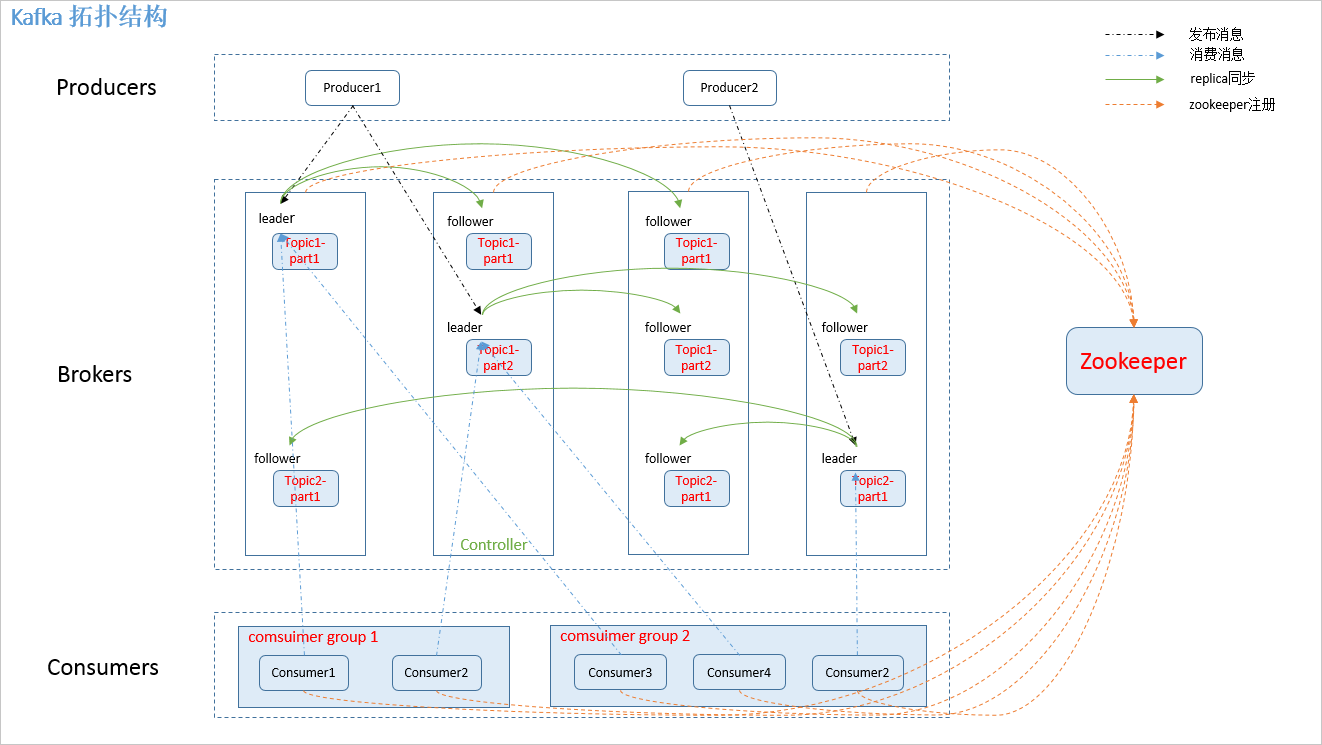
从上可知:
0、一个kafka集群由N个broker组成,至少一个(单机),其中一个broker是controller(其职责见下文);集群中包含很多topic,topic可以分区,每个分区可以配置多个副本,每个副本肯定在不同的broker,其中一个副本为leader(写),其它为follower,可用于读(跟couchbase架构是一样的)。
1、生产者不需要访问zookeeper(0.8.x版本的kafka consumer直连zk得到偏移量信息,之后的版本直接从cluster获取,所以这两个版本的API并不兼容,上图是0.8x的结构,0.9.x以及之后略有失真)。
2、消费者fetch消息、生产者发布消息总是向leader节点发请求,不会发送给follower(broker之间,而不是broker和客户端之间协调复制)。
3、和rocketmq一样,为了线性提高性能,每个topic被分为partition(跟数据库的分库分表一样的道理,对业务而言透明,属于技术策略,不是业务策略。分区可以轮询,也可以基于消息的key应用分区算法。),每个partition只能被相同消费组的任何一个成员消费(所以如果topic中的message不要求有序消费的话,partition是在大流量下提升性能的关键机制),topic的中分区parition的数量(默认是1)可通过./kafka-topics.sh –zookeeper localhost:2181 -alter –partitions 5 –topic userService修改,可以进入 /tmp/kafka-logs 目录下进行查看,其合理值的设置可以参考https://blog.csdn.net/kwengelie/article/details/51150114。
4、kafka 0.8.x使用zk存储每个consumer-group在每个topic的每个partition中的点位(每个消息都有一个offset,且在分区内单调递增),0.9版本开始存储在专门的topic中,该topic名为"__consumer_offset",这样consumer-group+topic就确定了点位,便于随时可恢复运行,采用日志压缩存储,也就是仅存储每个key的最新值,而非所有。
5、每个topic本地有一个local log,broker会持续顺序写入。
6、每条消息可以有key,也可以没有。有的话,用于确定消息发往哪个parition,否则就是轮询机制,java中是对key应用hash(实际为了重复消费的问题,一般会设置key),每个分区内的记录是保证有序的,所以选择合适的key能够将串行转为并行,这个需要非常理解业务逻辑要求,很多时候,严格递增并非必须(OLTP更是如此,可以根据产品、客户、商家、甚至某一次活动),只是实现简单而已。需要记住的是:是生产者而非broker决定去哪个分区。
7、在replicas模式下,一致性遵循的是全一致性模式,而非过半模式,如下:

ISRs见下文所述。一个topic中的不同parition可以为不同broker中的leader,这种模式可以提高性能,因为读写都是leader负责。committed记录所在的截止位置也成为高水位"High Watermark"。虽然使用角度不直接care,但是partition是HA和扩展性的真正落地之处。
kafka自身整体架构

这里要提及的是controller,其中一个broker会被作为controller,controller主要负责处理kafka集群范围内的事件,包括leader选举、topic变化、paritions副本数跟踪、broker的变化等,主要和zk通信,这根zk的主节点还不同,更像是Hadoop的nameserver,只负责元数据的全局管理。
kafka controller架构如下:

其职责可以参考https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Controller+Internals。对controller工作原理的解析,可以参考https://www.cnblogs.com/huxi2b/p/6980045.html,这篇文章总结的还是比较到位的。
综合起来,kafka的核心要素包括:brokers(所有的进程都是broker), topics, logs, partitions, controller, message, cluster。
broker内部机制

消息发送过程

消息发送支持同步和异步模式,默认是异步模式,可以缓冲一定数量的消息,如果消息生成的速度超过了发送的速度,则调用者会阻塞。参见https://www.cnblogs.com/litaiqing/p/6892703.html。在rabbitmq中,默认也是异步发送模式,但是如果缓冲区满了,则会报错而不会阻塞。
那客户端是怎么知道哪个broker是leader呢?因为每个broker都缓存了元数据,所以在连接初始建立的时候,客户端可以从任何一个broker获取每个topic的元数据信息,如下:

消息消费过程

核心高级API(不允许用户控制消费者和broker的交互过程)
- ConsumerConnector
- KafkaStream
- ConsumerConfig
低级API则允许控制各个交互过程,比如从哪里开始读以及在客户端维护点位,rocketmq实现其实采用的就是高层和底层结合的API,也就是kafka 0.9之后合并的api版本。
底层API的主要接口是SimpleConsumer。
消费者group和partition的关系

每个消费者group会记录自己在每个分区中的消费进度(该信息记录在专门的topic log中,见上文)。一个分区只能由被每个消费者group中的任意一个消费者成员消费,因为一般情况下微服务都是集群部署,所以这会导致N-1个微服务节点中的topic listener空跑,这是需要注意的,但是如果当前消费者所在的服务挂了,kafka会自动选择其中一个剩下的consumer,但是如果已经消费但是ack未被kafka收到,其它consumer接管时就会重复消费,要注意幂等。想要一个topic被消费者group中的成员并行消费的话,就需要配置不低于集群成员数的partition。简单的说,就是管理粒度是消费者组(在其他MQ中称订阅者)和topic,底层消息接收粒度分区和消费者。
不仅集群微服务可以从多partition受益,单JVM也可以收益,只要启动多个独立的线程,每个线程都作为topic的consumer就可以并发处理,这主要用于SMP服务器的时候,所以当消息处理需要一定时间或消息TPS大的时候,都应该使用多parition。
几个关键的消息点位
消息堆积是消费滞后(Lag)的一种表现形式,消息中间件服务端中所留存的消息与消费掉的消息之间的差值即为消息堆积量,也称之为消费滞后(Lag)量。对于Kafka而言,消息被发送至Topic中,而Topic又分成了多个分区(Partition),每一个Partition都有一个预写式的日志文件,虽然Partition可以继续细分为若干个段文件(Segment),但是对于上层应用来说可以将Partition看成最小的存储单元(一个由多个Segment文件拼接的“巨型文件”)。每个Partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到Partition中。

上图中有四个概念:
1.LogStartOffset:表示一个Partition的起始位移,初始为0,虽然消息的增加以及日志清除策略的影响,这个值会阶段性的增大。
2.ConsumerOffset:消费位移,表示Partition的某个消费者消费到的位移位置。
3.HighWatermark:简称HW,代表消费端所能“观察”到的Partition的最高日志位移,HW大于等于ConsumerOffset的值。
4.LogEndOffset:简称LEO, 代表Partition的最高日志位移,其值对消费者不可见。比如在ISR(In-Sync-Replicas)副本数等于3的情况下(如下图所示),消息发送到Leader A之后会更新LEO的值,Follower B和Follower C也会实时拉取Leader A中的消息来更新自己,HW就表示A、B、C三者同时达到的日志位移,也就是A、B、C三者中LEO最小的那个值。由于B、C拉取A消息之间延时问题(这就涉及到发送可靠性问题,见下文),所以HW必然不会一直与Leader的LEO相等,即LEO>=HW。 所以,实际可能是这样的:

要计算Kafka中某个消费者的滞后量很简单,首先看看其消费了几个Topic,然后针对每个Topic来计算其中每个Partition的Lag,每个Partition的Lag计算就显得非常的简单了,参考下图:

由图可知消费Lag=HW - ConsumerOffset。
ISRs
ISR是指当前同步副本集中的成员,如果leader失败,其中一个ISR会被选为的新的leader。
Topic Log Compaction
kafka的topic log会持续增长,所以为了保持稳定,应该定期回收。这涉及到两方面:消息的key是否会相同,它们的策略是不同的。Log Compaction主要用于key会相同的情况,也就是非UUID作为消息的键,否则就没有意义了。其机制是根据消息保留的时间或文件大小来删除key相同的历史value,如下所示:

可知,历史版本被清了。启用compact后,topic log分为了head和tail部分,只有tail的才会被压缩,但是删除还要根据其它配置决定,如下。


kafka参数min.compaction.lag.ms控制消息至少过多久才会被压缩,delete.retention.ms控制多久会被删除,log.cleanup.policy=compact控制启用压缩,所以消费者只要在此之内进行消费,就可以保证至少看到最新记录(因为producer可能又写入了,所以至少会看到最新,也许更多)。
消息保留时长
每个topic可以基于时间或topic log的大小声明消息的保留时间,由下列参数决定:
| 属性名 | 含义 | 默认值 |
|---|---|---|
| log.cleanup.polict | 日志清理保存的策略只有delete和compact两种 | delete |
| log.retention.hours | 日志保存的时间,可以选择hours,minutes和ms | 168(7day) |
| log.retention.bytes | 删除前日志文件允许保存的最大值(任意一个达到都会执行删除) | -1 |
| log.segment.delete.delay.ms | 日志文件被真正删除前的保留时间 | 60000 |
| log.cleanup.interval.mins | 每隔一段时间多久调用一次清理的步骤 | 10 |
| log.retention.check.interval.ms | 周期性检查是否有日志符合删除的条件(新版本使用) | 300000 |
ACK一致性级别
生产者(现在面试,我们都问如何保证发出的消息不丢失)可以通过ack设置数据一致性要求(和mysql机制类似)。ack=0(不需要ACK,至多一次), ack=all(ISR中的所有副本(由参数min.insync.replicas,默认1,建议ack=all时设置为2且小于replication.factor的值)都写入成功才算成功,所以跟quorum/raft类似,至少2个防止leader挂了丢失数据), ack=1(leader成功即可)。
可以通过在producer properties中设置,如下:
早期版本的生产者不支持“精确一次”的概念,从Kafka 0.11.0支持精确一次投递概念,它是通过引入生产者消息幂等+原子事务概念实现的,可以参考https://dzone.com/articles/exactly-once-semantics-with-apache-kafka-1(据官方测试,性能只下降了5%)。
这个参数除了影响一致性外,还会影响消息的乱序性。参数max.in.flight.requests.per.connection控制着一个 Producer同时可以发送的未收到确认的消息数量。如果max.in.flight.requests.per.connection数量大于1,那么可能发送了message1后,在没有收到确认前就发送了message2,此时 message1发送失败后触发重试,而 message2直接发送成功,就造成了Broker上消息的乱序。max.in.flight.requests.per.connection的默认值为5。
消息发送和消费语义
在发送端,kafka支持至少一次(绝大部分),精确一次(消费端未做幂等保护的三方服务,kafka 0.11后支持)和至多一次(行情)。精确一次是通过kafka服务端的幂等实现的,
enable.idempotence 配置项表示是否使用幂等性。当 enable.idempotence配置为 true时,acks必须配置为all。并且建议max.in.flight.requests.per.connection 的值小于 5。
在消费者层面,kafka支持至多一次和至少一次两种模式。
To implement “at-most-once” consumer reads a message, then saves its offset in the partition by sending it to the broker, and finally process the message. The issue with “at-most-once” is a consumer could die after saving its position but before processing the message. Then the consumer that takes over or gets restarted would leave off at the last position and message in question is never processed.
To implement “at-least-once” the consumer reads a message, process messages, and finally saves offset to the broker. The issue with “at-least-once” is a consumer could crash after processing a message but before saving last offset position. Then if the consumer is restarted or another consumer takes over, the consumer could receive the message that was already processed. The “at-least-once” is the most common set up for messaging, and it is your responsibility to make the messages idempotent, which means getting the same message twice will not cause a problem (two debits).
To implement “exactly once” on the consumer side, the consumer would need a two-phase commit between storage for the consumer position, and storage of the consumer’s message process output. Or, the consumer could store the message process output in the same location as the last offset.
kafka仅支持前两种(至多一次或者至少一次)消费者ACK,第三种(精确一次)需要用户自己实现,一般大家都是用第二种+幂等来实现,也就是消费者自身的一致性,通过幂等+ACK保证,就不重复阐述了。
通过如下可以保证手工管理ack提交:
props.put("enable.auto.commit", "false");
try {
while (running) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.offset() + ": " + record.value());
try {
consumer.commitSync();
} catch (CommitFailedException e) {
// application specific failure handling
}
}
} finally {
consumer.close();
}
在自动提交模式下,提交间隔由auto.commit.interval.ms确定。各种提交模式的使用可以参考https://www.confluent.io/blog/tutorial-getting-started-with-the-new-apache-kafka-0-9-consumer-client/。
Kafka的生态

MirrorMaker是kafka集群之间同步的组件,本质上是一个生产者+消费者,如下:

如上所示,它已经到V2版本(要求kafka 2.4),V2相比V1而言,最重要的是解决了两个集群之间消费者点位的自动换算问题,而不需要依赖于kafka的时间戳来计算(这一步非常关键,否则灾备切换成本过高、且容易出错)。内部架构如下:

上图在实际部署中其实是不太正确的,consumer(应用)肯定是两个机房都部署了,且双活存在。这时候就有个问题了,__consumer_offset和业务topic本身到达的先后问题。如果业务先,__consumer_offset后,那么灾备中心的应用读取到的就是老的offset,这样就会重复消费。如果__consumer_offset先,也有个问题,超过了实际的长度,则会重置为实际的offset,后到的业务topic也会被重复消费。所以作为应用消费者这里,幂等极为重要,其次作为topic设计者,确定message的key唯一非常重要。如果延时太大,导致的问题可能是大量的重复消息要丢弃,进而影响RTO。
除此之外,Kafka包括所有MQ在灾备时还存在一个很严重的问题,依赖于MQ实现最终一致性的破坏,通常对于最终一致性,依赖MQ可以极大的提升可靠性和性能、并解耦微服务,如果消息丢了,那么意味着最终一致性的破坏,需要依赖于微服务间的对账机制。
Kafka REST Proxy and Confluent Schema Registry

kafka在zk中的存储
为了显示方便,LZ设置了chroot为localKakfa,如下:

各个zk节点的含义如下示意图所示(之前版本的kafka,consumer-offset也维护在zk中),其中kafka01就是chroot,在kafka的server.properties中设置,加载zookeeper.connect后即可。如zookeeper.connect=localhost:2181/localKafka。

kafka监控管理
主流的几种kafka监控程序分别为:
- 1、Kafka Web Conslole,从https://github.com/claudemamo/kafka-web-console下载源码编译,https://pan.baidu.com/s/1cJ2OefPqlxfWzTHElG6AjA 下载编译好的,提取码:f8xz,如果是测试和开发、为了排查方便,推荐使用它,其缺陷参见https://blog.csdn.net/qq_33314107/article/details/81099091。
[root@node1 bin]# sh kafka-web-console
Play server process ID is 4154
[info] play - database [default] connected at jdbc:h2:file:play
[warn] play - Your production database [default] needs evolutions!
INSERT INTO settings (key_, value) VALUES ('PURGE_SCHEDULE', '0 0 0 ? * SUN *');
INSERT INTO settings (key_, value) VALUES ('OFFSET_FETCH_INTERVAL', '30');
[warn] play - Run with -DapplyEvolutions.default=true if you want to run them automatically (be careful)
Oops, cannot start the server.
@74e0p173o: Database 'default' needs evolution!
at play.api.db.evolutions.EvolutionsPlugin$$anonfun$onStart$1$$anonfun$apply$1.apply$mcV$sp(Evolutions.scala:484)
at play.api.db.evolutions.EvolutionsPlugin.withLock(Evolutions.scala:507)
at play.api.db.evolutions.EvolutionsPlugin$$anonfun$onStart$1.apply(Evolutions.scala:461)
at play.api.db.evolutions.EvolutionsPlugin$$anonfun$onStart$1.apply(Evolutions.scala:459)
at scala.collection.immutable.List.foreach(List.scala:318)
at play.api.db.evolutions.EvolutionsPlugin.onStart(Evolutions.scala:459)
at play.api.Play$$anonfun$start$1$$anonfun$apply$mcV$sp$1.apply(Play.scala:88)
at play.api.Play$$anonfun$start$1$$anonfun$apply$mcV$sp$1.apply(Play.scala:88)
at scala.collection.immutable.List.foreach(List.scala:318)
at play.api.Play$$anonfun$start$1.apply$mcV$sp(Play.scala:88)
at play.api.Play$$anonfun$start$1.apply(Play.scala:88)
at play.api.Play$$anonfun$start$1.apply(Play.scala:88)
at play.utils.Threads$.withContextClassLoader(Threads.scala:18)
at play.api.Play$.start(Play.scala:87)
at play.core.StaticApplication.<init>(ApplicationProvider.scala:52)
at play.core.server.NettyServer$.createServer(NettyServer.scala:243)
at play.core.server.NettyServer$$anonfun$main$3.apply(NettyServer.scala:279)
at play.core.server.NettyServer$$anonfun$main$3.apply(NettyServer.scala:274)
at scala.Option.map(Option.scala:145)
at play.core.server.NettyServer$.main(NettyServer.scala:274)
at play.core.server.NettyServer.main(NettyServer.scala)
第一次启动时要加个参数:
./kafka-web-console -DapplyEvolutions.default=true
- 2、Kafka Manager,也不错,yahoo开发的,可用来监控流量。
链接:https://pan.baidu.com/s/1YMj-9HzoJLKDEY5C47aOlQ
提取码:hhhr
- 3、KafkaOffsetMonitor
- 4、Kafdrop,新开发的,参见https://github.com/HomeAdvisor/Kafdrop。
- 补充:最新github上最活跃的为kafka ui
以我们生产一般使用的KafkaOffsetMonitor为例,KafkaOffsetMonitor是Kafka的一款客户端消费监控工具,用来实时监控Kafka服务的Consumer以及它们所在的Partition中的Offset,我们可以浏览当前的消费者组,并且每个Topic的所有Partition的消费情况都可以一目了然。KafkaOffsetMonitor托管在Github上,可以通过Github下载。下载地址:https://github.com/quantifind/KafkaOffsetMonitor/releases,也可以从baidu网盘下载(内网的话,要使用这个,否则会缺少从cdn加载的js)。
可以通过java -cp KafkaOffsetMonitor-assembly-0.2.0.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --zk 10.20.30.10:2181 --port 8088 --refresh 10.seconds --retain 2.days启动,各配置含义可以参考github。


Kafka Rebalance机制(重要)
常见问题
活锁
kafka如何支持rabbitmq的订阅模式
通过设置不同的消费者组实现,只要在消息被清理之前,可以从任意位置开始。
如何通过java api获取所有topic?
kafka服务端什么情况下会踢掉消费者?
max.poll.interval.ms参数用于指定consumer两次poll的最大时间间隔(默认5分钟),如果超过了该间隔consumer client会主动向coordinator发起LeaveGroup请求,触发rebalance;然后consumer重新发送JoinGroup请求
properties.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 10000);
return new KafkaConsumer<>(properties);
09:34:46,858 [kafka-coordinator-heartbeat-thread | group1] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Member consumer-group1-1-da40b0d7-9dda-484d-9722-b512bf351c56 sending LeaveGroup request to coordinator 192.168.1.8:9092 (id: 2147483645 rack: null) due to consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records. 09:34:47,979 [main] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Failing OffsetCommit request since the consumer is not part of an active group 09:34:47,979 [main] WARN org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Synchronous auto-commit of offsets {topic1-1=OffsetAndMetadata{offset=0, leaderEpoch=null, metadata=''}, topic1-0=OffsetAndMetadata{offset=4, leaderEpoch=0, metadata=''}} failed: Offset commit cannot be completed since the consumer is not part of an active group for auto partition assignment; it is likely that the consumer was kicked out of the group. 09:34:47,979 [main] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Giving away all assigned partitions as lost since generation has been reset,indicating that consumer is no longer part of the group 09:34:47,979 [main] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Lost previously assigned partitions topic1-1, topic1-0 09:34:47,979 [main] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] (Re-)joining group 09:34:48,058 [main] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Join group failed with org.apache.kafka.common.errors.MemberIdRequiredException: The group member needs to have a valid member id before actually entering a consumer group 09:34:48,058 [main] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] (Re-)joining group 09:34:48,058 [main] INFO org.apache.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Finished assignment for group at generation 22: {consumer-group1-1-32cfa301-a26c-4f3a-b270-9bb1bbc51fef=Assignment(partitions=[topic1-0, topic1-1])} 09:34:48,058 [main] INFO org.apache.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-group1-1, groupId=group1] Successfully joined group with generation 22
所以实际应用中,消费到的数据处理时长不宜超过max.poll.interval.ms,否则会触发rebalance。如果处理消费到的数据耗时,可以尝试通过减小max.poll.records的方式减小单次拉取的记录数(默认是500条),考虑到gc、cpu过载上下文切换等各种因素,因确保处理每批次处理的消息花费的时间不大于max.poll.interval.ms的50%。
消费和如何一次性订阅多个topic?
它适合所有topic具有相同的语义范围时,可通过this.consumer.subscribe(Arrays.asList(topic));订阅多个主题。比如缓存通常要求每个应用实例都消费、所以ip+port+app.group+app.version作为consumer-group-id比较合适,否则app.group+app.version作为consumer-group-id更合适。

========命令行脚本是kafka主要的管理工具,和其他中间件或数据库的cli性质是一样的。
如何查看所有的topic?
[root@hs-test-10-20-30-16 bin]# ./kafka-topics.sh --list --zookeeper 10.20.30.17:2191
__consumer_offsets
hs_ta_channel_Metadata
hsta_channelprocess20100513_aop-YOGA - marked for deletion
hsta_channelprocess20100514_aop-TA4 - marked for deletion
hsta_channelprocess20100530_aop-TA4
hsta_channelprocess20200118_aop-YOGA
hsta_channelprocessnull - marked for deletion
和连接--bootstrap-server出来的结果不一样,如下:
[root@ta5host bin]# ./kafka-topics.sh --list --bootstrap-server 10.20.30.17:9092 __consumer_offsets hs_ta_channel_Metadata uft_individual_1 uft_individual_1_oracle uft_inst_1 uft_inst_1_oracle uft_spliter_1_oracle uft_spliter_2_oracle uft_splitter_1 uft_trade_1 uft_trade_1_bar uft_trade_1_oracle uft_trade_1_oracle_bar uft_trade_2_oracle uft_trade_2_oracle_bar
是不是哪里不对???
前者和kafka-manager的监控结果是一样的,毕竟连接的是同一个zk。

要想知道哪些kafka集群连接本zk,可以通过netstat -ano | grep 2191找到客户端。
查看特定topic的配置?
[root@hs-test-10-20-30-11 kafka]# bin/kafka-topics.sh --zookeeper 10.20.30.10:2181 --topic global --describe
Topic:global PartitionCount:1 ReplicationFactor:1 Configs:
Topic: global Partition: 0 Leader: 0 Replicas: 0 Isr: 0
[root@hs-test-10-20-30-10 bin]# ./kafka-topics.sh --bootstrap-server localhost:9092 --topic hs_ta_channel_Metadata --describe Topic:hs_ta_channel_Metadata PartitionCount:1 ReplicationFactor:1 Configs:min.insync.replicas=1,segment.bytes=1073741824,max.message.bytes=10485760 Topic: hs_ta_channel_Metadata Partition: 0 Leader: 0 Replicas: 0 Isr: 0
如何删除topic?
删除kafka topic及其数据,严格来说并不是很难的操作。但是,往往给kafka 使用者带来诸多问题。项目组之前接触过多个开发者,发现都会偶然出现无法彻底删除kafka的情况。本文总结多个删除kafka topic的应用场景,总结一套删除kafka topic的标准操作方法。
step1:
如果需要被删除topic 此时正在被程序 produce和consume,则这些生产和消费程序需要停止。
因为如果有程序正在生产或者消费该topic,则该topic的offset信息一致会在broker更新。调用kafka delete命令则无法删除该topic。
同时,需要设置 auto.create.topics.enable = false,默认设置为true。如果设置为true,则produce或者fetch 不存在的topic也会自动创建这个topic。这样会给删除topic带来很多意向不到的问题。
所以,这一步很重要,必须设置auto.create.topics.enable = false,并认真把生产和消费程序彻底全部停止。
step2:
server.properties 设置 delete.topic.enable=true
如果没有设置 delete.topic.enable=true,则调用kafka 的delete命令无法真正将topic删除,而是显示(marked for deletion)
step3:
调用命令删除topic:
./bin/kafka-topics --delete --zookeeper 【zookeeper server:port】 --topic 【topic name】
step4:
删除kafka存储目录(server.properties文件log.dirs配置,默认为"/data/kafka-logs")相关topic的数据目录。
注意:如果kafka 有多个 broker,且每个broker 配置了多个数据盘(比如 /data/kafka-logs,/data1/kafka-logs ...),且topic也有多个分区和replica,则需要对所有broker的所有数据盘进行扫描,删除该topic的所有分区数据。
一般而言,经过上面4步就可以正常删除掉topic和topic的数据。但是,如果经过上面四步,还是无法正常删除topic,则需要对kafka在zookeeer的存储信息进行删除。具体操作如下:
(注意:以下步骤里面,kafka在zk里面的节点信息是采用默认值,如果你的系统修改过kafka在zk里面的节点信息,则需要根据系统的实际情况找到准确位置进行操作)
step5:
找一台部署了zk的服务器,使用命令:
bin/zkCli.sh -server 【zookeeper server:port】
登录到zk shell,然后找到topic所在的目录:ls /brokers/topics,找到要删除的topic,然后执行命令:
rmr /brokers/topics/【topic name】
即可,此时topic被彻底删除。
如果topic 是被标记为 marked for deletion,则通过命令 ls /admin/delete_topics,找到要删除的topic,然后执行命令:
rmr /admin/delete_topics/【topic name】
备注:
网络上很多其它文章还说明,需要删除topic在zk上面的消费节点记录、配置节点记录,比如:
rmr /consumers/【consumer-group】
rmr /config/topics/【topic name】
其实正常情况是不需要进行这两个操作的,如果需要,那都是由于操作不当导致的。比如step1停止生产和消费程序没有做,step2没有正确配置。也就是说,正常情况下严格按照step1 -- step5 的步骤,是一定能够正常删除topic的。
step6:
完成之后,调用命令:
./bin/kafka-topics.sh --list --zookeeper 【zookeeper server:port】
查看现在kafka的topic信息。正常情况下删除的topic就不会再显示。
但是,如果还能够查询到删除的topic,则重启zk和kafka即可。
如何查看所有的消费者组?
新的方式,也就是不是使用基于zk的客户端(kafka.consumer.Consumer.createJavaConsumerConnector、内部是bootstrap)。
[root@hs-test-10-20-30-11 kafka]# bin/kafka-consumer-groups.sh --new-consumer --bootstrap-server 10.20.30.11:9092 --list
Note: This will only show information about consumers that use the Java consumer API (non-ZooKeeper-based consumers).
老的方式:基于zk的客户端(kafka.javaapi.consumer.ZookeeperConsumerConnector,已经deprecated)。
[root@hs-test-10-20-30-11 kafka]# bin/kafka-consumer-groups.sh --zookeeper 10.20.30.10:2181 --list
Note: This will only show information about consumers that use ZooKeeper (not those using the Java consumer API).
AAA
TA50-Aggr-Logger-ConsumerGroup
console-consumer-23104
console-consumer-37858
查看一个消费者组的消费点位
[root@hs-test-10-20-30-10 bin]# ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --all-topics --group tabase-service-10.20.30.10:8383 TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID hs_ta_channel_Metadata 0 4 4 0 consumer-1-b8c4c0c5-dbf3-4a55-8a9d-fda9d7b00c17 /10.20.30.10 consumer-1 [root@hs-test-10-20-30-10 bin]# ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --all-topics --group tabase-10.20.30.10:8080 TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID hs_ta_channel_Metadata 0 4 4 0 consumer-1-1681831e-8c97-48bc-9c8d-21f2f7667aa9 /10.20.30.10 consumer-1
[root@hs-test-10-20-30-10 bin]# ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --all-topics --group tabase-10.20.30.10:8080 --verbose --state COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS 10.20.30.10:9092 (0) range Stable 1
生产者连接的时候报了下列错误
WARN [Producer clientId=console-producer] Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
有两个原因:1、kafka没有启动;2、连接串使用了非conf/server.properties里面的LISTENERS参数的值。
log4j-kafka配置
增加jar包依赖:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>0.11.0.3</version> </dependency>
配置log4j2.xml,如下:
logger增加kafka appender。
<Root level="INFO" additivity="false"> <AppenderRef ref="Console"/> <AppenderRef ref="KAFKA"/> <AppenderRef ref="app_error" /> </Root>
增加kafka appender。
<Appenders> <!-- 输出错误日志到Kafka --> <Kafka name="KAFKA" topic="bomp"> <ThresholdFilter level="error" onMatch="DENY" onMismatch="NEUTRAL"/> <ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/> <PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss,SSS}:%4p %t (%F:%L) - %m%n" /> <Property name="bootstrap.servers">10.20.30.11:9092</Property> </Kafka> </Appenders>
这样log4j配置kafka就完成了。对于c++,可以使用librdkafka库,https://docs.confluent.io/2.0.0/clients/librdkafka/index.html,后续会专门出文讲解。
相关异常
消费者报:
2018-09-17 14:10:07.768 WARN 130400 --- [r-finder-thread] kafka.client.ClientUtils$ : Fetching topic metadata with correlation id 0 for topics [Set(test)] from broker [BrokerEndPoint(0,10.20.30.11,9092)] failed
java.nio.channels.ClosedChannelException: null
at kafka.network.BlockingChannel.send(BlockingChannel.scala:112) ~[kafka_2.12-0.11.0.3.jar:na]
at kafka.producer.SyncProducer.liftedTree1$1(SyncProducer.scala:80) ~[kafka_2.12-0.11.0.3.jar:na]
at kafka.producer.SyncProducer.doSend(SyncProducer.scala:79) ~[kafka_2.12-0.11.0.3.jar:na]
at kafka.producer.SyncProducer.send(SyncProducer.scala:124) ~[kafka_2.12-0.11.0.3.jar:na]
at kafka.client.ClientUtils$.fetchTopicMetadata(ClientUtils.scala:61) [kafka_2.12-0.11.0.3.jar:na]
at kafka.client.ClientUtils$.fetchTopicMetadata(ClientUtils.scala:96) [kafka_2.12-0.11.0.3.jar:na]
at kafka.consumer.ConsumerFetcherManager$LeaderFinderThread.doWork(ConsumerFetcherManager.scala:72) [kafka_2.12-0.11.0.3.jar:na]
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:64) [kafka_2.12-0.11.0.3.jar:na]
解决方法:在server.properties里面设置下advertised.host.name,重启试试看。参考https://stackoverflow.com/questions/30606447/kafka-consumer-fetching-metadata-for-topics-failed
zk日志中报:
2018-10-08 14:13:28,297 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100147743c10000 type:setData cxid:0xc8 zxid:0x53 txntype:-1 reqpath:n/a Error Path:/config/topics/uft_trade Error:KeeperErrorCode = NoNode for /config/topics/uft_trade
2018-10-08 14:13:28,302 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100147743c10000 type:create cxid:0xc9 zxid:0x54 txntype:-1 reqpath:n/a Error Path:/config/topics Error:KeeperErrorCode = NodeExists for /config/topics
解决方法:待排查。
spring boot kafka客户端在某虚拟机服务器(物理机一直运行未发生)上运行一段时间后,瞬间cpu system 80-90%,大量下列日志:
2018-10-09 13:54:57,713 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 2682ms for sessionid 0x100175687960002 2018-10-09 13:54:57,904 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 2672ms for sessionid 0x100175687960004 2018-10-09 13:54:58,621 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 2675ms for sessionid 0x100175687960003 2018-10-09 13:54:57,232 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 2700ms for sessionid 0x100175687960007 2018-10-09 13:55:09,812 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 2672ms for sessionid 0x100175687960004, closing socket connection and attempting reconn ect 2018-10-09 13:55:02,942 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 2702ms for sessionid 0x100175687960008 2018-10-09 13:55:09,755 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 2675ms for sessionid 0x100175687960003, closing socket connection and attempting reconn ect 2018-10-09 13:55:09,789 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 2682ms for sessionid 0x100175687960002, closing socket connection and attempting reconn ect 2018-10-09 13:55:18,677 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 2675ms for sessionid 0x100175687960005 2018-10-09 13:55:11,752 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 20016ms for sessionid 0x100175687960001 2018-10-09 13:55:17,709 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 2678ms for sessionid 0x100175687960006 2018-10-09 13:55:12,779 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 2700ms for sessionid 0x100175687960007, closing socket connection and attempting reconn ect 2018-10-09 13:55:20,634 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 2702ms for sessionid 0x100175687960008, closing socket connection and attempting reconn ect 2018-10-09 13:55:22,178 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 20016ms for sessionid 0x100175687960001, closing socket connection and attempting recon nect 2018-10-09 13:58:10,244 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:58:10,240 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:58:10,241 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:58:10,240 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 2675ms for sessionid 0x100175687960005, closing socket connection and attempting reconn ect 2018-10-09 13:58:10,243 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 2678ms for sessionid 0x100175687960006, closing socket connection and attempting reconn ect 2018-10-09 13:58:11,107 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:58:40,384 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:58:40,383 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:58:40,379 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:58:40,378 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:58:40,378 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:58:40,377 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:59:22,082 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 13:59:22,084 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 13:59:22,099 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 13:59:22,108 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 13:59:22,130 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:59:23,382 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:59:23,412 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 13:59:23,412 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 13:59:23,443 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=500 watcher=org.I0Itec.zkclient.ZkClient@8646db9 2018-10-09 13:59:23,411 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960001 has expired 2018-10-09 13:59:32,474 INFO ZkClient:713 - zookeeper state changed (Disconnected) 2018-10-09 13:59:23,404 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960007 has expired 2018-10-09 13:59:23,390 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 13:59:32,477 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=500 watcher=org.I0Itec.zkclient.ZkClient@4671e53b 2018-10-09 13:59:23,390 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960008 has expired 2018-10-09 13:59:23,390 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 13:59:32,477 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=500 watcher=org.I0Itec.zkclient.ZkClient@6a1aab78 2018-10-09 13:59:23,389 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960004 has expired 2018-10-09 13:59:32,417 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:59:23,380 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:59:23,446 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=30000 watcher=org.I0Itec.zkclient.ZkClient@dc24521 2018-10-09 13:59:41,829 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960004 has expired, closing socket connection 2018-10-09 13:59:41,832 INFO ZkClient:936 - Waiting for keeper state SyncConnected 2018-10-09 13:59:41,829 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960008 has expired, closing socket connection 2018-10-09 13:59:41,831 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 13:59:41,830 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960007 has expired, closing socket connection 2018-10-09 13:59:41,830 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960001 has expired, closing socket connection 2018-10-09 13:59:41,860 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 13:59:42,585 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 13:59:42,810 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 13:59:42,835 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:31,813 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 48978ms for sessionid 0x100175687960002 2018-10-09 14:00:31,825 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 49644ms for sessionid 0x100175687960005 2018-10-09 14:00:31,825 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 49644ms for sessionid 0x100175687960005, closing socket connection and attempting recon nect 2018-10-09 14:00:31,827 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 49968ms for sessionid 0x100175687960006 2018-10-09 14:00:31,827 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 49968ms for sessionid 0x100175687960006, closing socket connection and attempting recon nect 2018-10-09 14:00:31,842 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 50011ms for sessionid 0x100175687960003 2018-10-09 14:00:31,868 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 50011ms for sessionid 0x100175687960003, closing socket connection and attempting recon nect 2018-10-09 14:00:31,853 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 48978ms for sessionid 0x100175687960002, closing socket connection and attempting recon nect 2018-10-09 14:00:31,885 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:31,886 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:31,887 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:31,887 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:31,907 INFO ClientCnxn:519 - EventThread shut down for session: 0x100175687960001 2018-10-09 14:00:31,907 INFO ClientCnxn:519 - EventThread shut down for session: 0x100175687960008 2018-10-09 14:00:31,908 INFO ClientCnxn:519 - EventThread shut down for session: 0x100175687960004 2018-10-09 14:00:31,944 INFO ClientCnxn:519 - EventThread shut down for session: 0x100175687960007 2018-10-09 14:00:33,391 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:33,396 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:33,424 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 1336ms for sessionid 0x0 2018-10-09 14:00:33,430 INFO ClientCnxn:1299 - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x10017568796000b, negotiated timeout = 30000 2018-10-09 14:00:33,517 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:33,516 INFO ZkClient:713 - zookeeper state changed (SyncConnected) 2018-10-09 14:00:34,399 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:34,354 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 1336ms for sessionid 0x0, closing socket connection and attempting reconnect 2018-10-09 14:00:34,433 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:34,475 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:34,476 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:34,485 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 968ms for sessionid 0x0 2018-10-09 14:00:34,488 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 968ms for sessionid 0x0, closing socket connection and attempting reconnect 2018-10-09 14:00:37,472 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:37,484 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:37,487 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:37,488 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:37,489 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:37,479 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960006 has expired 2018-10-09 14:00:37,495 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960006 has expired, closing socket connection 2018-10-09 14:00:37,447 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 14:00:37,479 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 14:00:37,519 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=500 watcher=org.I0Itec.zkclient.ZkClient@69b0fd6f 2018-10-09 14:00:37,519 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=500 watcher=org.I0Itec.zkclient.ZkClient@4a87761d 2018-10-09 14:00:37,446 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960005 has expired 2018-10-09 14:00:37,519 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960005 has expired, closing socket connection 2018-10-09 14:00:37,765 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 14:00:37,780 INFO ZkClient:713 - zookeeper state changed (Expired) 2018-10-09 14:00:37,780 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960003 has expired 2018-10-09 14:00:37,791 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960003 has expired, closing socket connection 2018-10-09 14:00:38,194 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=500 watcher=org.I0Itec.zkclient.ZkClient@3aeaafa6 2018-10-09 14:00:37,995 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 507ms for sessionid 0x0 2018-10-09 14:00:52,148 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 507ms for sessionid 0x0, closing socket connection and attempting reconnect 2018-10-09 14:00:38,198 INFO ZooKeeper:438 - Initiating client connection, connectString= sessionTimeout=500 watcher=org.I0Itec.zkclient.ZkClient@491cc5c9 2018-10-09 14:00:52,141 INFO ClientCnxn:519 - EventThread shut down for session: 0x100175687960006 2018-10-09 14:00:52,128 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:52,154 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:52,126 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:00:52,179 INFO ClientCnxn:876 - Socket connection established to localhost/127.0.0.1:2181, initiating session 2018-10-09 14:00:38,010 WARN ClientCnxn:1285 - Unable to reconnect to ZooKeeper service, session 0x100175687960002 has expired 2018-10-09 14:00:52,231 INFO ClientCnxn:1154 - Unable to reconnect to ZooKeeper service, session 0x100175687960002 has expired, closing socket connection 2018-10-09 14:00:52,683 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 504ms for sessionid 0x0 2018-10-09 14:05:12,238 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:05:12,176 INFO ClientCnxn:1032 - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error) 2018-10-09 14:08:21,078 INFO ClientCnxn:519 - EventThread shut down for session: 0x100175687960002 2018-10-09 14:05:12,113 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 259911ms for sessionid 0x10017568796000b 2018-10-09 14:08:21,107 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 259911ms for sessionid 0x10017568796000b, closing socket connection and attempting reco nnect 2018-10-09 14:05:12,098 INFO ClientCnxn:519 - EventThread shut down for session: 0x100175687960003 2018-10-09 14:00:52,677 WARN ClientCnxn:1108 - Client session timed out, have not heard from server in 501ms for sessionid 0x0 2018-10-09 14:08:21,107 INFO ClientCnxn:1156 - Client session timed out, have not heard from server in 501ms for sessionid 0x0, closing socket connection and attempting reconnect
经大概看了下帖子https://blog.csdn.net/xjping0794/article/details/77784171的内容,查看该段时间系统io,确实很高,高达50%,如下:
14时00分28秒 sda 3062.38 922268.58 670.77 301.38 5.17 1.71 0.16 49.44 14时00分28秒 ol-root 3111.77 922266.41 495.79 296.54 5.29 1.70 0.16 49.43 14时00分28秒 ol-swap 22.04 2.09 174.24 8.00 0.13 5.80 0.15 0.33 14时11分16秒 sda 5432.75 1537105.34 768.61 283.07 19.06 3.53 0.17 91.53 14时11分16秒 ol-root 5513.26 1537106.56 731.82 278.93 19.55 3.54 0.17 91.52 14时11分16秒 ol-swap 5.07 4.68 35.87 8.00 0.01 2.27 0.19 0.10 14时11分16秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util 14时20分01秒 sda 2784.00 795332.59 462.60 285.85 10.89 3.93 0.18 50.09 14时20分01秒 ol-root 2827.44 795311.85 414.30 281.43 11.18 3.95 0.18 50.07 14时20分01秒 ol-swap 6.96 12.98 42.72 8.00 0.05 7.80 0.18 0.12 14时30分01秒 sda 3.13 12.42 59.59 23.04 0.00 0.57 0.44 0.14
但是这段时间没有东西特别在运行,这就比较奇怪了,那会儿一下子也忘了用iotop看下是哪个进程所致。上述帖子提到的几点是:
关于ZK日志存放,官网给出如下建议:
Having a dedicated log devicehas a large impact on throughput and stable latencies. It is highly recommenedto dedicate a log device and set dataLogDir to point to a directory on thatdevice, and then make sure to point dataDir to a directory not residing on thatdevice.
在ZOO.CFG中增加:
forceSync=no
默认是开启的,为避免同步延迟问题,ZK接收到数据后会立刻去讲当前状态信息同步到磁盘日志文件中,同步完成后才会应答。将此项关闭后,客户端连接可以得到快速响应(这一点在有BMU的服务器上问题不大)。
再看下zk服务器的日志,差不多时间开始出现大量CancelledKeyException:
2018-10-09 13:56:36,712 [myid:] - INFO [SyncThread:0:NIOServerCnxn@1040] - Closed socket connection for client /127.0.0.1:14926 which had sessionid 0x100175687960008 2018-10-09 13:56:43,857 [myid:] - INFO [SyncThread:0:NIOServerCnxn@1040] - Closed socket connection for client /127.0.0.1:14924 which had sessionid 0x100175687960006 2018-10-09 13:56:49,783 [myid:] - INFO [SyncThread:0:NIOServerCnxn@1040] - Closed socket connection for client /127.0.0.1:14919 which had sessionid 0x100175687960001 2018-10-09 13:56:49,816 [myid:] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@236] - Ignoring unexpected runtime exception java.nio.channels.CancelledKeyException at sun.nio.ch.SelectionKeyImpl.ensureValid(SelectionKeyImpl.java:73) at sun.nio.ch.SelectionKeyImpl.readyOps(SelectionKeyImpl.java:87) at org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:205) at java.lang.Thread.run(Thread.java:748) 2018-10-09 13:58:54,331 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23459 2018-10-09 13:58:54,377 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23459, probably expired 2018-10-09 13:58:54,401 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /192.168.223.137:23485 2018-10-09 13:58:54,441 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /192.168.223.137:23494 2018-10-09 13:58:56,314 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1040] - Closed socket connection for client /192.168.223.137:23459 which had sessionid 0x10017 5687960000 2018-10-09 13:58:56,336 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23485 2018-10-09 13:58:56,392 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23485, probably expired 2018-10-09 13:58:57,890 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /192.168.223.137:23497 2018-10-09 13:58:59,480 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1040] - Closed socket connection for client /192.168.223.137:23485 which had sessionid 0x10017 5687960000 2018-10-09 13:59:00,383 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23494 2018-10-09 13:59:00,910 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23494, probably expired 2018-10-09 13:59:02,140 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /192.168.223.137:23507 2018-10-09 13:59:03,286 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23497 2018-10-09 13:59:03,671 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1040] - Closed socket connection for client /192.168.223.137:23494 which had sessionid 0x10017 5687960000 2018-10-09 13:59:03,905 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23497, probably expired 2018-10-09 13:59:05,341 [myid:] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@236] - Ignoring unexpected runtime exception java.nio.channels.CancelledKeyException at sun.nio.ch.SelectionKeyImpl.ensureValid(SelectionKeyImpl.java:73) at sun.nio.ch.SelectionKeyImpl.readyOps(SelectionKeyImpl.java:87) at org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:205) at java.lang.Thread.run(Thread.java:748) 2018-10-09 13:59:06,862 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /192.168.223.137:23511 2018-10-09 13:59:10,044 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23507 2018-10-09 13:59:10,267 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1040] - Closed socket connection for client /192.168.223.137:23497 which had sessionid 0x10017 5687960000 2018-10-09 13:59:10,285 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23507, probably expired 2018-10-09 13:59:10,286 [myid:] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@236] - Ignoring unexpected runtime exception java.nio.channels.CancelledKeyException at sun.nio.ch.SelectionKeyImpl.ensureValid(SelectionKeyImpl.java:73) at sun.nio.ch.SelectionKeyImpl.readyOps(SelectionKeyImpl.java:87) at org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:205) at java.lang.Thread.run(Thread.java:748) 2018-10-09 13:59:10,287 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1040] - Closed socket connection for client /192.168.223.137:23507 which had sessionid 0x10017 5687960000 2018-10-09 13:59:10,287 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23511 2018-10-09 13:59:10,287 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23511, probably expired 2018-10-09 13:59:10,313 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /192.168.223.137:23519 2018-10-09 13:59:10,313 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1040] - Closed socket connection for client /192.168.223.137:23511 which had sessionid 0x10017 5687960000 2018-10-09 13:59:10,314 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@215] - Accepted socket connection from /192.168.223.137:23524 2018-10-09 13:59:10,314 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23519 2018-10-09 13:59:10,314 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23519, probably expired 2018-10-09 13:59:10,315 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@941] - Client attempting to renew session 0x100175687960000 at /192.168.223.137:23524 2018-10-09 13:59:10,315 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxn@1040] - Closed socket connection for client /192.168.223.137:23519 which had sessionid 0x10017 5687960000 2018-10-09 13:59:10,316 [myid:] - INFO [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:ZooKeeperServer@686] - Invalid session 0x100175687960000 for client /192.168.223.137:23524, probably expired 2018-10-09 13:59:10,321 [myid:] - WARN [NIOServerCxn.Factory:0.0.0.0/0.0.0.0:2181:NIOServerCnxnFactory@236] - Ignoring unexpected runtime exception java.nio.channels.CancelledKeyException at sun.nio.ch.SelectionKeyImpl.ensureValid(SelectionKeyImpl.java:73) at sun.nio.ch.SelectionKeyImpl.readyOps(SelectionKeyImpl.java:87) at org.apache.zookeeper.server.NIOServerCnxnFactory.run(NIOServerCnxnFactory.java:205) at java.lang.Thread.run(Thread.java:748)
上述帖子中提到在3.4.8中修复,我们用的3.4.12。进一步查找,有些提及写日志延迟很大,例如“fsync-ing the write ahead log in SyncThread:0 took 8001ms which will adversely effect operation latency. See the ZooKeeper troubleshooting guide ”但是日志中并没有看到该告警。决定加上forceSync=no试试看,参考https://www.jianshu.com/p/73eec030db86。
至于日志中的超时时间有长、有短,这是tickTime有关,可以解释,不做详细说明。
zk日志中大量下列错误信息:
id:0x9d zxid:0x42 txntype:-1 reqpath:n/a Error Path:/config/topics Error:KeeperErrorCode = NodeExists for /config/topics 2018-10-09 12:01:07,918 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100175687960000 type:create cx id:0xa5 zxid:0x45 txntype:-1 reqpath:n/a Error Path:/brokers/topics/uft_individual/partitions/0 Error:KeeperErrorCode = NoNode for /brokers/topics/uft_individual/partitions/0 2018-10-09 12:01:07,921 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100175687960000 type:create cx id:0xa6 zxid:0x46 txntype:-1 reqpath:n/a Error Path:/brokers/topics/uft_individual/partitions Error:KeeperErrorCode = NoNode for /brokers/topics/uft_individual/partitions 2018-10-09 12:01:17,740 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100175687960000 type:setData c xid:0xaf zxid:0x4a txntype:-1 reqpath:n/a Error Path:/config/topics/uft_splitter Error:KeeperErrorCode = NoNode for /config/topics/uft_splitter 2018-10-09 12:01:17,741 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100175687960000 type:create cx id:0xb0 zxid:0x4b txntype:-1 reqpath:n/a Error Path:/config/topics Error:KeeperErrorCode = NodeExists for /config/topics 2018-10-09 12:01:17,753 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100175687960000 type:create cx id:0xb8 zxid:0x4e txntype:-1 reqpath:n/a Error Path:/brokers/topics/uft_splitter/partitions/0 Error:KeeperErrorCode = NoNode for /brokers/topics/uft_splitter/partitions/0 2018-10-09 12:01:17,754 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100175687960000 type:create cx id:0xb9 zxid:0x4f txntype:-1 reqpath:n/a Error Path:/brokers/topics/uft_splitter/partitions Error:KeeperErrorCode = NoNode for /brokers/topics/uft_splitter/partitions 2018-10-09 12:01:35,671 [myid:] - INFO [ProcessThread(sid:0 cport:2181)::PrepRequestProcessor@653] - Got user-level KeeperException when processing sessionid:0x100175687960000 type:setData c xid:0xc2 zxid:0x53 txntype:-1 reqpath:n/a Error Path:/config/topics/cres_global Error:KeeperErrorCode = NoNode for /config/topics/cres_global
参考https://github.com/mesos/kafka/issues/136,可是kafka服务一直正常启动着啊(对比启动日志也可以看出确实已经启动了)。https://stackoverflow.com/questions/34393837/zookeeper-kafka-error-keepererrorcode-nodeexists还有一个原因,是因为zk的data未删除的原因,可我们是全新安装过一会也有这个问题。最后查看https://stackoverflow.com/questions/43559328/got-user-level-keeperexception-when-processing,如下:
The message you see is not an error yet. It is a potential exception raised by Zookeeper that original object making a request has to handle.
When you start a fresh Kafka, it gets a bunch of NoNode messages. It's normal because some paths don't exist yet. At the same time, you get also NodeExists messages as the path exists already.
Example: Error:KeeperErrorCode = NoNode for /config/topics/test It's because Kafka sends a request to Zookeeper for this path. But it doesn't exist. That's OK, because you are trying to create it. So, you see "INFO" from Zookeeper but no error from Kafka. Once Kafka gets this message, it tries to create your topic. To do so, it needs to access a path in Zookeeper for topics. So, it sends a request and gets an error NodeExists for /config/topics. Again, it's normal and Kafka ignores the message.
Long story short, these are all non-issue messages and you should skip them. If it bothers you, change logging configuration of Zookeeper (it's not recommended though).
其实就是提示性信息,不用管它就好了,kafka会直接忽略该信息。
编译不报错,启动时报下列错误:
java.lang.NoSuchMethodError:
org.apache.kafka.clients.consumer.KafkaConsumer.subscribe原因:编译依赖的kafka client版本和运行时不一致如0.9.1和0.11.0,典型的例如间接依赖,对比下编译依赖的版本和运行时打出来的版本。
客户端警告:
[WARN] consumer-0-C-1 org.apache.kafka.clients.NetworkClient$DefaultMetadataUpdater.handleCompletedMetadataResponse(NetworkClient.java:846) Error while fetching metadata with correlation id 105 : {hs:ta:channel:Metadata=INVALID_TOPIC_EXCEPTION}
解决方法:主题名不能包含:字符。
客户端错误
Exception in thread "CDC-Kafka-[hsta.cdcRecord_F6]-Consumer-1" Exception in thread "CDC-Kafka-[hsta.cdcRecord_F7]-Consumer-1" org.apache.kafka.common.errors.WakeupException
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.maybeTriggerWakeup(ConsumerNetworkClient.java:487)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:278)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:236)
解决方法:
客户端错误
org.apache.kafka.common.protocol.types.SchemaException: Error reading field 'correlation_id': java.nio.BufferUnderflowException
at org.apache.kafka.common.protocol.types.Schema.read(Schema.java:71)
at org.apache.kafka.common.requests.ResponseHeader.parse(ResponseHeader.java:53)
at org.apache.kafka.clients.NetworkClient.handleCompletedReceives(NetworkClient.java:435)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:265)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.clientPoll(ConsumerNetworkClient.java:320)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:213)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:193)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.awaitMetadataUpdate(ConsumerNetworkClient.java:134)
at org.apache.kafka.clients.consumer.internals.AbstractCoordinator.ensureCoordinatorKnown(AbstractCoordinator.java:184)
at org.apache.kafka.clients.consumer.KafkaConsumer.pollOnce(KafkaConsumer.java:886)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:853)
首先检查,确保配置正确,比如是不是连接到了正确的kafka版本,其次客户端的版本是不是比server高。
客户端错误:
[] 2020-01-09 13:35:19 [32026] [ERROR] consumer-0-C-1 org.springframework.kafka.listener.KafkaMessageListenerContainer$ListenerConsumer.run(KafkaMessageListenerContainer.java:692) Container exception
org.apache.kafka.common.errors.InvalidTopicException: Invalid topics: [hs:ta:channel:Metadata]
解决方法:主题名不能包含:字符。
kafka后台启动方式
默认情况下,执行
./kafka-server-start.sh ../config/server.properties的时候,进程是前台模式的,意味着关掉控制台,kafka就停了。所以需要加-daemon选项以后台模式启动。如下:
./kafka-server-start.sh -daemon ../config/server.properties
提交失败
- 1、保证consumer的消费性能足够快
- 2、尽量让consumer逻辑幂等
- 3、通过配置优化解决重复消费
- 4、不单单做好消息积压的监控,还要做消息消费速度的监控(前后两次offset比较)
我们使用的Kafka的api, 调用的是KafkaConsumer的poll方法,该方法调用了pollOnce方法,该方法又调用了ConsumerCoordinator 的poll方法,该方法的最后调用了自动offset同步的方法,关键就在这个方法,这个方法只有在poll的时候才会调用,如果数据处理时间操过poll的最大时间,就会导致本文开始的错误,而不能提交offset.
消费慢的各种问题
https://blog.csdn.net/qq_16681169/article/details/101081656
https://blog.csdn.net/qq_40384985/article/details/90675986
https://blog.csdn.net/qq_34894188/article/details/80554570
问题
[2018-10-14 21:20:28,860] INFO [Consumer clientId=consumer-1, groupId=console-consumer-28334] Discovered group coordinator wxoddc2nn1:9092 (id: 2147483647 rack: null) (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
https://www.jianshu.com/p/0e7e38c98d13 解决方法
kafka:为什么说Kafka使用磁盘比内存快(这个结论本质上是说不正确的,为什么呢?因为它的机制是连续读写为主,因此只是把活丢给了OS的页面缓存而已,mongodb亦如此。你可以说这个决定不一定比自己做差,但是说磁盘比内存快就有点过了)
Kafka最核心的思想是使用磁盘,而不是使用内存,可能所有人都会认为,内存的速度一定比磁盘快,我也不例外。
在看了Kafka的设计思想,查阅了相应资料再加上自己的测试后,发现磁盘的顺序读写速度(Cassandra, LevelDB, RocksDB也都是这种策略)和内存持平。
而且Linux对于磁盘的读写优化也比较多,包括read-ahead和write-behind,磁盘缓存等。
如果在内存做这些操作的时候,一个是JAVA对象的内存开销很大,另一个是随着堆内存数据的增多,JAVA的GC时间会变得很长,而利用OS的page cache,gc的开销就节省了不少(JNI是否也可以达到类似效果???,起码netty中的ByteBuffer及Unsafe一大部分是的)。
使用磁盘操作有以下几个好处:
- 磁盘缓存由Linux系统维护,减少了java程序员的不少工作。
- 磁盘顺序读写速度超过内存随机读写。
- JVM的GC效率低,内存占用大。
- 系统冷启动后,磁盘缓存依然可用。
优化
- 消息删除方面,使用实时标记代替删除。
- 发送方面,使用批量发送代替实时发送。
- 在jvm方面,默认kafka用的是cms gc,可以考虑g1垃圾回收期,调整为:-server -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:InitiatingHeapOccupancyPercent=35 -XX:+DisableExplicitGC -Djava.awt.headless=true
其他关键实践
Kafka uses tombstones instead of deleting records right away
❖ Kafka producers support record batching. by the size of records and auto-flushed based on time
❖ Batching is good for network IO throughput.
❖ Batching speeds up throughput drastically
消费者剔除的控制参数
With Kafka consumers pull data from brokers replica.lag.time.max.ms > lag时,leader就把follow从ISRs踢掉,所以要及时小批量poll()消费,不要大批量。
选举控制
默认情况下,如果非所有副本都在ISR中,Kafka在所有ISR成员都宕机时,是否可以将ISR以外的副本成员拿来做leader,由参数unclean.leader.election.enable控制,其默认值不同版本取值不同。

如果为false的话,Kafka会等着ISR成员活过来再选主。如果为true,则直接非ISR成员会抢占成为leader。假设后来原来的leader副本恢复,成为了新的follower副本,准备向新的leader副本同步消息,但是它发现自身的LEO比leader副本的LEO还要大。Kafka中有一个准则,follower副本的LEO是不能够大于leader副本的,所以新的follower副本就需要截断日志至leader副本的LEO处,这样原来的消息就有可能会丢失。从Kafka 0.11.0.0版本开始将此参数从true设置为false,可以看出Kafka的设计者偏向于可靠性,如果能够容忍uncleanLeaderElection场景带来的消息丢失和不一致,可以将此参数设置为之前的老值——true。
Outside of using a single ensemble(协调器,zookeeper) for multiple Kafka clusters, it is not recommended
to share the ensemble with other applications, if it can be avoided. Kafka is sensitive
to Zookeeper latency and timeouts, and an interruption in communications with the
ensemble will cause the brokers to behave unpredictably. This can easily cause multiple
brokers to go offline at the same time, should they lose Zookeeper connections,
which will result in offline partitions. It also puts stress on the cluster controller,
which can show up as subtle errors long after the interruption has passed, such as
when trying to perform a controlled shutdown of a broker. Other applications that
can put stress on the Zookeeper ensemble, either through heavy usage or improper
operations, should be segregated to their own ensemble.
Kafka与MQTT
不同于rabbitmq、active mq,kafka默认不支持MQTT协议,如果希望现有和rabbitmq通过MQTT对接的应用无缝切换,要么自己写gateway,要么借用三方插件,比较正统的主要有https://www.confluent.io/connector/kafka-connect-mqtt/,https://www.infoq.cn/article/fdbcrh6I*9ajCWLvippC
参考
- https://my.oschina.net/u/3853586/blog/3138825(相关总结性概念,还不错)
- https://kafka.apache.org/documentation(single page模式)
- http://cloudurable.com/blog/kafka-architecture/index.html
- https://cwiki.apache.org/confluence/display/KAFKA/
- http://cloudurable.com/ppt/4-kafka-detailed-architecture.pdf
- Learning Apache Kafka Second Edition (针对0.8.x版本)
- Kafka: The Definitive Guide(针对0.9.x版本)
- https://cwiki.apache.org/confluence/display/KAFKA/Kafka+papers+and+presentations
- https://www.iteblog.com/archives/2605.html(32 道常见的 Kafka 面试题你都会吗)
- https://www.confluent.io/resources/?_ga=2.259543491.831483530.1575092374-1512510254.1571457212(如果说percona server是依托mysql的主要商业版公司的话,confluent则是依托kafka的商业公司)
- https://www.jianshu.com/p/d2cbaae38014(kafka运维天坑,版本有点老,0.9.1系列的,但是针对服务器的一些问题值得参考下)
相关最佳实践参考:
- https://dzone.com/articles/20-best-practices-for-working-with-apache-kafka-at
Scala参考:
flink,akka都是使用Scala开发,感觉Scala和Lua、go这三小众语言在大型软件领域占有了一席之地,有兴趣可以了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号