
lightdb full page write原理、增量检查点特性及稳定性测试
checkpoint是一个数据库事件,它将已修改的数据从高速缓存刷新到磁盘,并更新控制文件和数据文件,此时会有大量的I/O写操作。
在PostgreSQL中,检查点(后台)进程执行检查点;当发生下列情况之一时,其进程将启动:
- 检查点间隔时间由checkpoint_timeout设置(默认间隔为300秒(5分钟))
- 在9.5版或更高版本中,pg_xlog中WAL段文件的总大小(在10版或更高版本中为pg_WAL)已超过参数max_WAL_size的值(默认值为1GB(64个16MB文件))。
- PostgreSQL服务器在smart或fast模式下关闭。
- 手动checkpoint。
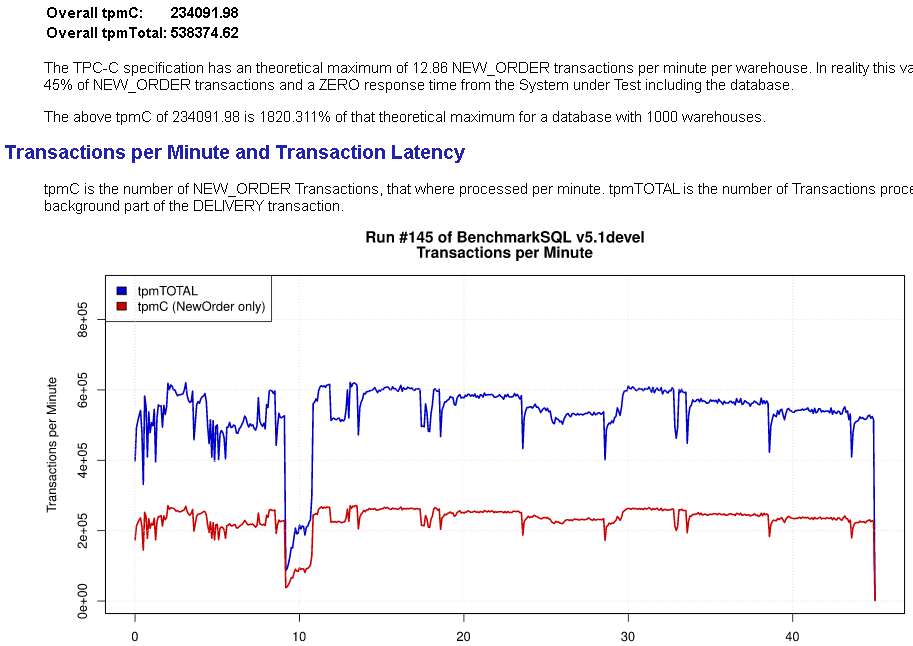
从lightdb 23.2开始,实验性的引入了对增量检查点的支持,24.1修复了一个潜在特定情况下的cpu 100%缺陷,24.2版卡正式可生产可用。启用增量检查点后,运行曲线如下:
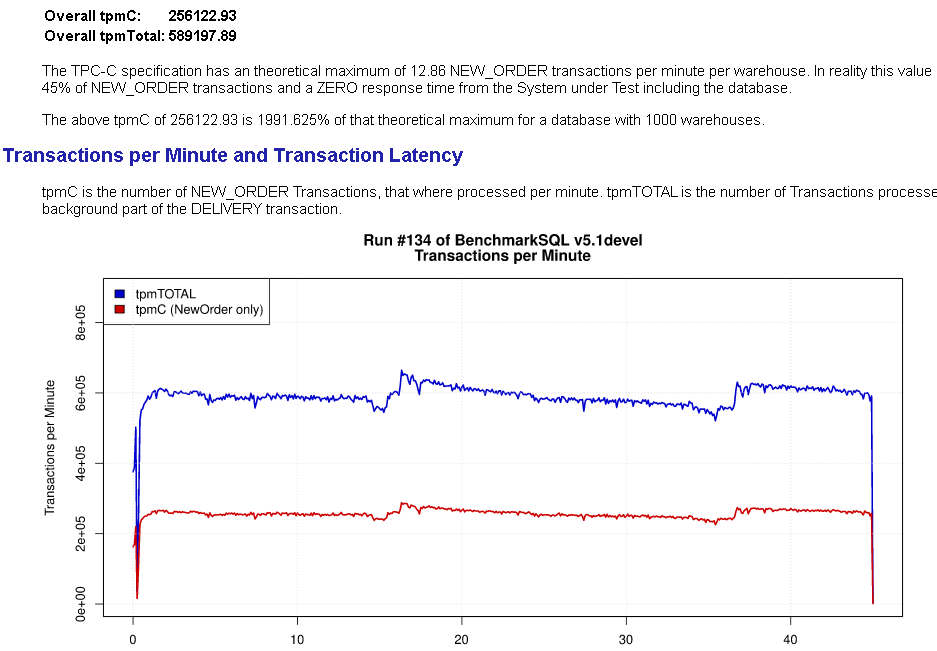
虽然通过优化相关参数,也能达到比较接近的效果,但是完全依赖于DBA和精细调优的结果。而采用增量检查点,该过程完全自动化了,大大提升了数据库的自治性。
其由下列参数控制:
- enable_incremental_checkpoint,是否启用增量检查点,默认:off
- incre_checkpoint_timeout:增量检查点模式下检查点的触发间隔
- log_pagewriter:是否在PageWriter内打印日志
- enable_candidate_buf_usage_count:是否在管理页面空闲队列时考虑页面的usage count
- enable_double_write=off ,是否启用双写,默认:off。如果未启用增量检查点,该参数无效。双写和FPI只需要开启一个即可,但是如果关闭了FPI,则无法在从节点进行物理备份,所以增量检查点仍然具有限制。
- dw_file_num:双写文件的数量,默认2。初始化后,不能修改。否则启动时会报错。
2023-08-17 13:42:34.362800T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: starting LightDB 13.8-23.2 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit
2023-08-17 13:42:34.363020T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: listening on IPv4 address "0.0.0.0", port 18888
2023-08-17 13:42:34.363055T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: listening on IPv6 address "::", port 18888
2023-08-17 13:42:34.363908T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: listening on Unix socket "/tmp/.s.LIGHTDB.18888"
2023-08-17 13:42:34.365239T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: [Batch flush] Found a valid batch meta file info: dw_file_num = 2, dw_file_size = 32MB
2023-08-17 13:42:34.365476T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: [Batch flush] Found a valid batch meta file info: dw_file_num = 2, dw_file_size = 32MB
2023-08-17 13:42:34.365588T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: [Batch flush] Open batch flush file global/lt_dw_0, fd = 12
2023-08-17 13:42:34.365650T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: [Batch flush] Found a valid batch file header: [dwn 3646, start 1004]
2023-08-17 13:42:34.365738T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: [Batch flush] Open double write global/lt_dw_0 done, fd = 12
2023-08-17 13:42:34.365765T,,,,,postmaster,,00000,2023-08-17 13:42:34 CST,0,70806,LOG: [Batch flush] Open batch flush file global/lt_dw_1, fd = 13
2023-08-17 13:42:34.365778T,,,,,postmaster,,XX000,2023-08-17 13:42:34 CST,0,70806,PANIC: Read file error
- dw_file_size: 每个双写文件的大小,默认256MB
- max_io_capacity:用户预估的磁盘I/O带宽
- pagewriter_thread_num:PageWriter子进程的数量,默认2
- pagewriter_sleep:PageWriter刷页的间隔
推荐:主节点做实时备份,开启增量检查点+高可用,关闭full_page_write(因为底层存储通常支持扇区为单位的原子性,所以evict导致数据块被刷出、写入4KB/8KB/16KB到os的时候,很可能写了几个扇区后发生宕机,此时磁盘中并不是一个完整的页,启动时,pg实例会通过wal重放进行恢复,所以逻辑上没问题,这个就是刚刚初始化实例后的过程。那为什么checkpoint后第一次DML需要fpi呢,因为系统能起来,一定是wal重放干净了,此时但是内存中的每个块数据和磁盘并不一定一致,因为重放不一定会写磁盘(这个是和第一次初始化的差异),成功做了checkpoint后,到开始checkpoint点位置为止,磁盘和内存中的数据肯定是一致的(即使内存更新一点也没问题,因为checkpint期间做的变更的wal在checkpoint开始之后,他不会被删除),所以checkpoint之前的日志是不需要的。在checkpoint之后,假设做了一个update修改了一个块,同时又很快,内存紧张,修改的块被evict到磁盘,evict一半的时候,os宕机了,此时磁盘中的块是错乱的,此时checkpoint之后的实例并没有从头重放的所有wal,所以pg系统后,基于错乱的块重放update的wal,因为磁盘中的块错乱,所以重放也是错误的。而又fpi,因为update的时候,会完整的块写入到了wal,所以即使磁盘错乱,fpi会整个覆盖块,从而保证了机器错乱后的正确性,所以fpi就是定时给磁盘中的块打个基线的用途)。由于pg备节点做实时备份要求必须开启full_page_write(其实本质上跟备节点无关,是basebackup自动开启的fpi检查),所以如果是备节点备份,则开启增量检查点会打折扣(因为相当于fpi写了两边,doublewrite+fpi)。虽然zfs可以关闭full_page_write支持防止裂页,但是同样备节点备份存在这个限制,同时因为需要从启动后第一个检查点开始恢复,对wal空间大小会有膨胀作用,所以还是得需要增量检查点。
带了增量检查点的启动过程差异
启动时,先做double write文件的重放,然后做wal重放。和checkpoint后的恢复一样,第一次块的update做fpi重放,然后才是具体的wal日志重放。
-
mysql double write相关资料
https://topic.alibabacloud.com/a/a-brief-analysis-of-mysql-double-write_1_41_30037467.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号