
lightdb/postgresql中plpgsql、函数与操作符、表达式及其内部实现
PG_PROC
PG_OPERATOR
pg_opclass用于定义索引上的相关操作符,一般来说是同一类数据类型。pg_opfamiliy定义了相互兼容的数据类型的操作符,关系见https://www.postgresql.org/docs/9.1/catalog-pg-opclass.html。pg 8.3引入pg_opfamilies,原因:Create "operator families" to improve planning of queries involving cross-data-type comparisons (Tom)
https://www.postgresql.org/docs/current/btree-behavior.html
https://www.postgresql.org/docs/current/indexes-opclass.html
PG_LANGUAGE
对于操作符表达式, 在PostgreSQL 数据库中操作符实际都转成了对应的函数。
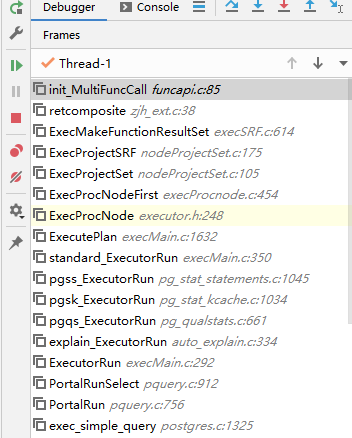
到执行期,也就是ExecMakeTableFunctionResult/ExecMakeFunctionResultSet阶段,函数信息fcinfo/flinfo及函数指针都已经确定。
表达式实现
https://www.postgresql.org/docs/current/sql-expressions.html#SYNTAX-EXPRESS-EVAL
plpgsql实现
初始化
编译
默认情况下,除非存储过程(函数无此特例)是SQL语言编写的,否则编译发生在第一次调用(函数总是在第一次执行时编译)时,pl_comp()函数。
就理论而言,在语法解析为数据结构这个过程,语句表达式可以使用深度优先二叉树遍历实现(每个节点保存节点类型、操作数和值、也可能还包括操作数,也就是left/right),二叉树一般使用递归实现,递归性能较低,可以将其转换为数组来平面化(关键在于如何表示,PG做了实现)。对于SQL语句来说,不管硬编码、绑定变量还是字段、函数、表达式、聚合函数、分析函数这一步都是一样的。因为在targetlist已经全部数组、表达式化。包括case when xxx=ssss then; case xxx when sss then; between and; interval '';语句和表达式都可用二叉树来实现计算。
因为GLR(bison默认,flex and bison第九章,可以向前查看无限个记号)或LALR(1)(Look-Ahead Left Reversed,bison也支持)或两路并行 正常会向前找一个符号,所以可以为操作符指定优先级,这样就可以转换为深度优先树(逆波兰可以解决括号问题,不用括号就解决优先级问题,但是不适合人工阅读,适合机器表示)。
调用
在analyze语义分析阶段,会确定函数信息并设置fcinfo/flinfo的固定部分,如函数名、函数指针。如下:
> FuncnameGetCandidates C++ (gdb) lt_func_get_detail C++ (gdb) ParseFuncOrColumn C++ (gdb) transformFuncCall C++ (gdb) transformExprRecurse C++ (gdb) transformExpr C++ (gdb) transformRangeFunction C++ (gdb) transformFromClauseItem C++ (gdb) transformFromClause C++ (gdb) transformSelectStmt C++ (gdb) transformStmt C++ (gdb) transformTopLevelStmt C++ (gdb) parse_analyze C++ (gdb) pg_analyze_and_rewrite C++ (gdb) exec_simple_query C++ (gdb) PostgresMain C++ (gdb) BackendRun C++ (gdb) BackendStartup C++ (gdb) ServerLoop C++ (gdb) PostmasterMain C++ (gdb) main C++ (gdb)
其中函数地址在fn_addr属性中。在lookup_C_func函数中设置,如下:
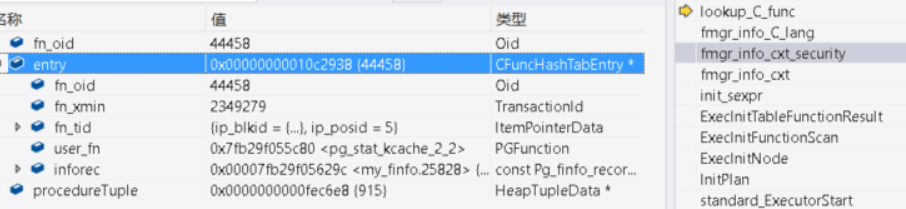

那函数地址第一次是如何加载到哈希中的呢?
完成
异常清理
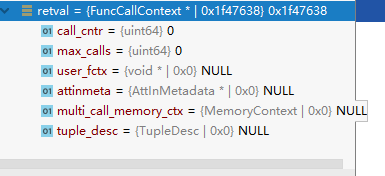
/*------------------------------------------------------------------------- * Support struct to ease writing Set Returning Functions (SRFs) *------------------------------------------------------------------------- * * This struct holds function context for Set Returning Functions. * Use fn_extra to hold a pointer to it across calls */ typedef struct FuncCallContext { /* * Number of times we've been called before * * call_cntr is initialized to 0 for you by SRF_FIRSTCALL_INIT(), and * incremented for you every time SRF_RETURN_NEXT() is called. */ uint64 call_cntr; /* * OPTIONAL maximum number of calls * * max_calls is here for convenience only and setting it is optional. If * not set, you must provide alternative means to know when the function * is done. */ uint64 max_calls; /* * OPTIONAL pointer to miscellaneous user-provided context information * * user_fctx is for use as a pointer to your own struct to retain * arbitrary context information between calls of your function. */ void *user_fctx; /* * OPTIONAL pointer to struct containing attribute type input metadata * * attinmeta is for use when returning tuples (i.e. composite data types) * and is not used when returning base data types. It is only needed if * you intend to use BuildTupleFromCStrings() to create the return tuple. */ AttInMetadata *attinmeta; /* * memory context used for structures that must live for multiple calls * * multi_call_memory_ctx is set by SRF_FIRSTCALL_INIT() for you, and used * by SRF_RETURN_DONE() for cleanup. It is the most appropriate memory * context for any memory that is to be reused across multiple calls of * the SRF. */ MemoryContext multi_call_memory_ctx; /* * OPTIONAL pointer to struct containing tuple description * * tuple_desc is for use when returning tuples (i.e. composite data types) * and is only needed if you are going to build the tuples with * heap_form_tuple() rather than with BuildTupleFromCStrings(). Note that * the TupleDesc pointer stored here should usually have been run through * BlessTupleDesc() first. */ TupleDesc tuple_desc; } FuncCallContext;
对于非跨调用(上下文无关,通常是标量函数)函数,其实例如下:
FmgrInfo:函数信息
TupleDesc:记录定义
HeapTuple:记录
从C字符串构建记录元祖extern HeapTuple BuildTupleFromCStrings(AttInMetadata *attinmeta, char **values);,具体实现在heap_form_tuple,如下:
/* * heap_form_tuple * construct a tuple from the given values[] and isnull[] arrays, * which are of the length indicated by tupleDescriptor->natts * * The result is allocated in the current memory context. */ HeapTuple heap_form_tuple(TupleDesc tupleDescriptor, Datum *values, bool *isnull)
/* * heap_fill_tuple * Load data portion of a tuple from values/isnull arrays * * We also fill the null bitmap (if any) and set the infomask bits * that reflect the tuple's data contents. * * NOTE: it is now REQUIRED that the caller have pre-zeroed the data area. */ void heap_fill_tuple(TupleDesc tupleDesc, Datum *values, bool *isnull, char *data, Size data_size, uint16 *infomask, bits8 *bit)
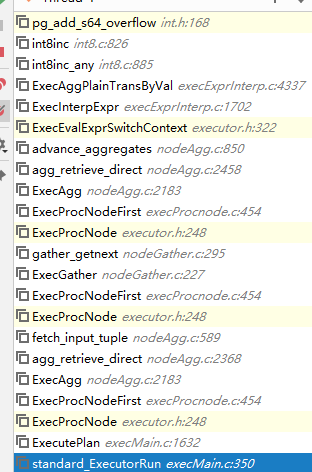
generate_series的实现及返回集合类型
CREATE OR REPLACE FUNCTION fibonacci_seq(num integer) RETURNS SETOF integer AS $$ DECLARE a int := 0; b int := 1; BEGIN IF (num <= 0) THEN RETURN; END IF; RETURN NEXT a; LOOP EXIT WHEN num <= 1; RETURN NEXT b; num = num - 1; SELECT b, a + b INTO a, b; END LOOP; END; $$ language plpgsql;
zjh@postgres-# (SELECT fibonacci_seq(3)); fibonacci_seq --------------- 0 1 1 (3 rows)
-- 虽然这种模式有点怪,但是因为设计问题,PL/PGSQL无法支持类似RETURN a,b,c语法。
CREATE FUNCTION permutations(INOUT a int, INOUT b int, INOUT c int) RETURNS SETOF RECORD AS $$ BEGIN RETURN NEXT; SELECT b,c INTO c,b; RETURN NEXT; SELECT a,b INTO b,a; RETURN NEXT; SELECT b,c INTO c,b; RETURN NEXT; SELECT a,b INTO b,a; RETURN NEXT; SELECT b,c INTO c,b; RETURN NEXT; END; $$ LANGUAGE plpgsql; zjh@postgres=# SELECT * FROM permutations(1, 2, 3); a | b | c ---+---+--- 1 | 2 | 3 1 | 3 | 2 3 | 1 | 2 3 | 2 | 1 2 | 3 | 1 2 | 1 | 3 (6 rows)
zjh@postgres=# CREATE OR REPLACE FUNCTION permutations2(a int, b int, c int) RETURNS SETOF abc AS $$ BEGIN RETURN NEXT a,b,c; END; $$ LANGUAGE plpgsql; CREATE FUNCTION zjh@postgres=# zjh@postgres=# zjh@postgres=# select * from permutations2(1,2,3); ERROR: query "SELECT a,b,c" returned 3 columns CONTEXT: PL/pgSQL function permutations2(integer,integer,integer) line 3 at RETURN NEXT
因为generate_series是使用c语言实现的,其结构和plpgsql实现类似。
调试pl/pgsql代码
目前来说,主要几个plpgsql debugger插件实现,https://github.com/OmniDB/plpgsql_debugger,plugin_debugger(EDB写)。主流的pg ide包括dbeaver,pgadmin 4,navicat都支持,lightdb 22.4正式版内置了plugin_debugger,二次发行版dbeaver也开箱即用的支持plpgsql和pgorasql的调试。
另外,和oracle里面一样,pg也支持打印调用堆栈,可参见https://www.cybertec-postgresql.com/en/debugging-pl-pgsql-get-stacked-diagnostics/。
PL/pgSQL的实现
PL/pgSQL存储过程示例https://blog.csdn.net/kmblack1/article/details/92786900。
由于plpgsql支持事务(存储过程支持,函数不支持)、表达式和语句采用表达式引擎实现、执行SQL语句基于SPI实现,因此要了解或pl/pgsql的实现,需要先熟悉事务快照,表达式以及SPI的实现机制,不然会有大量的盲区。
编译、校验、执行、语言。
SQL执行引擎、PL/pgSQL引擎(无单独的表达式解析器)。
在postgresql中,PL/pgSQL过程、函数的执行有点类似Javascript和python,会话第一次加载(这事挺麻烦,为了确保没问题,还得先调用一遍,如果是很复杂的存储过程,会导致需要大量的准备过程。注:SQL过程会在创建的时候会进行编译)的时候会进行语法解析、语义解析等,然后生成内存中的结构,下次执行的时候就直接执行缓存的内存指令结构(由于最终会通过plXXXsql过程性解析器编译为类表达式引擎中执行plpgsql中的指令,其实现通常性能变动较大,因此性能通常不如c编写的函数)。具体可参见https://www.postgresql.org/docs/13/plpgsql-implementation.html、https://www.percona.com/live/19/sites/default/files/slides/Introduction%20to%20PL_pgSQL%20Development%20-%20FileId%20-%20187790.pdf。
zjh@postgres=# CREATE OR REPLACE FUNCTION ambiguous(parameter varchar) RETURNS zjh@postgres-# integer AS $$ zjh@postgres$# DECLARE retval integer; zjh@postgres$# BEGIN zjh@postgres$# INSERT INTO parameter (parameter) VALUES (parameter) RETURNING id zjh@postgres$# INTO retval; zjh@postgres$# RETURN retval; zjh@postgres$# END zjh@postgres$# $$ zjh@postgres-# language plpgsql; CREATE FUNCTION zjh@postgres=# zjh@postgres=# SELECT ambiguous ('parameter'); ERROR: relation "parameter" does not exist LINE 1: INSERT INTO parameter (parameter) VALUES (parameter) RETURNI... ^ QUERY: INSERT INTO parameter (parameter) VALUES (parameter) RETURNING id CONTEXT: PL/pgSQL function ambiguous(character varying) line 4 at SQL statement
表达式的核心设计架构
表达式引擎相比函数,实现起来并不是那么直接,核心设计模式在于:为了提升运行时的性能,因为表达式通常对每行记录执行一次,而递归层次深的函数无论资源消耗还是性能都比普通迭代的要弱,所以,在PG中,表达式被设计为:解析的时候,向下递归、嵌套函数列表;表达式初始化的时候,一样由外向内递归、深度优先二叉树转换为array,具体在
游标、跨事务游标 https://www.cybertec-postgresql.com/en/declare-cursor-in-postgresql-or-how-to-reduce-memory-consumption/、https://www.postgresql.org/docs/10/sql-declare.html,游标选项对应的宏定义
#define CURSOR_OPT_BINARY 0x0001 /* BINARY */
#define CURSOR_OPT_SCROLL 0x0002 /* SCROLL explicitly given */
#define CURSOR_OPT_NO_SCROLL 0x0004 /* NO SCROLL explicitly given */
#define CURSOR_OPT_INSENSITIVE 0x0008 /* INSENSITIVE */
#define CURSOR_OPT_HOLD 0x0010 /* WITH HOLD */
/* these planner-control flags do not correspond to any SQL grammar: */
#define CURSOR_OPT_FAST_PLAN 0x0020 /* prefer fast-start plan */
#define CURSOR_OPT_GENERIC_PLAN 0x0040 /* force use of generic plan */
#define CURSOR_OPT_CUSTOM_PLAN 0x0080 /* force use of custom plan */
#define CURSOR_OPT_PARALLEL_OK 0x0100 /* parallel mode OK */
https://wiki.postgresql.org/wiki/Debugging_the_PostgreSQL_grammar_(Bison)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号