
神经网络
一、简单介绍
作为深度学习的基础。下面展示了只有两层的神经网络和具有一个隐层的神经网络。

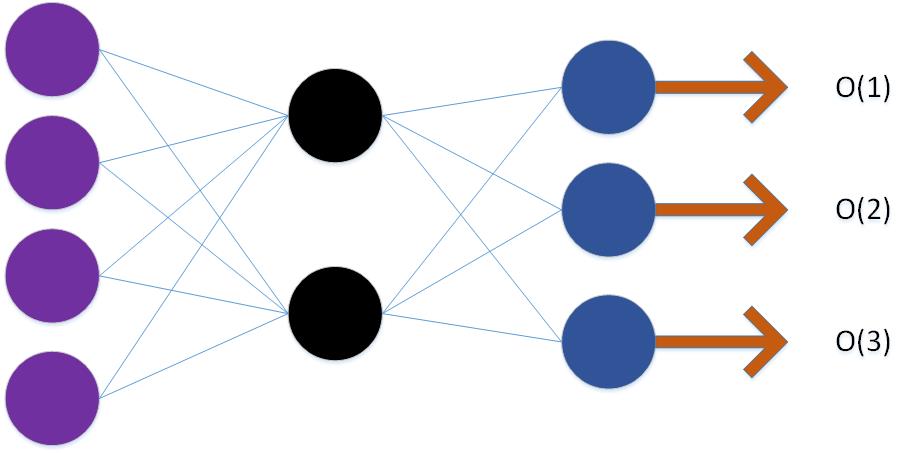
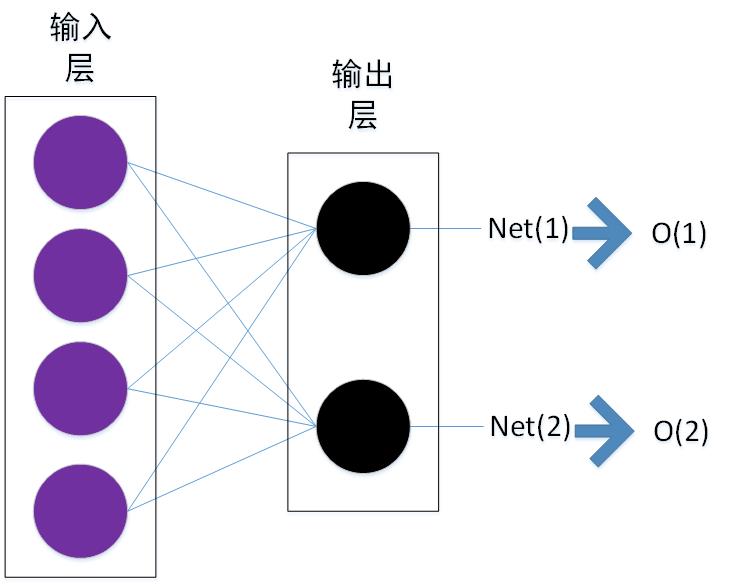
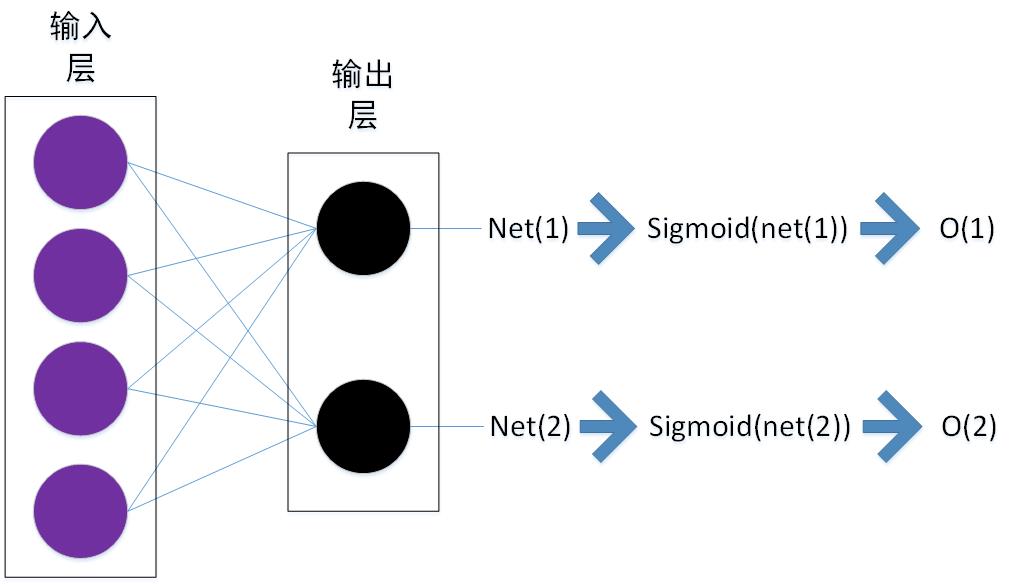
上面的网络展示了一个只有两层的net,输出使用了线性的输出的方式。ANN当中对于线性的输出进行了进一步的变换使用了sigmoid函数对其进行了非线性变换。
上述$Net(i)$的定义为第i个神经元的所有输入的加权和,即
$Net(i)=\sum_{j=1}^{4}w_{j,i}*x_{j,i}$
这里的$w_{j,i}$的定义是第i个神经元的第j个输入的权重,相应的输入是$x_{j,i}$
sigmoid函数的定义如下:
$sigmoid(net(i))=\frac{e^{net(i)}}{1+e^{net(i)}}$
二、推导
如何对神经网络进行训练,我们定义损失函数为
$E=\frac{1}{2}\sum_{i=1}^{N}(label_{i}-O_{i})^{2}$
我们尝试使用梯度下降法对它进行优化,从而得到所有的权值。
$\frac{\partial{E}}{\partial{w_{j,i}}}$
根据上面的介绍,实际上$w_{j,i}$是通过$net(i)$作用于后面的整个网络的,所以先对$net(i)$求偏导
$\frac{\partial{E}}{\partial{w_{j,i}}} = \frac{\partial{E}}{\partial{net(i)}} \frac{\partial{net(i)}}{\partial{w_{j,i}}}$
由于net(i)是$w_{j,i}$的函数,于是
$\frac{\partial{net(i)}} {\partial{w_{j,i}}}=x_{j,i}$
现在问题变成了如何来求$\frac{\partial{E}}{\partial{net(i)}}$
分为两种情况来考虑。
第一种:当前神经元对应的是输出层
和上面思考的方式类似,$net(i)$是通过后面的sigmoid函数作用于整个网络的,所以
$\frac{\partial{E}}{\partial{net(i)}} = \frac{\partial{E}}{\partial{O_{i}}} \frac{\partial{O_{i}}}{\partial{net(i)}}$
上面的O_{i}实际上就是sigmoid函数的输出值,关于sigmoid函数的求导有一个非常有意思的地方,它的导数就是他的输出的函数,即
$\frac{\partial{O_{i}}}{\partial{net(i)}} = O_{j}*(1-O_{j})$
从损失函数可以得到
$\frac{\partial{E}}{\partial{O_{i}}} = t_{i}-O_{i}$
这样我们得到了上面的偏导数
我们定义这个偏导数为$\delta(i)$
第二种:当前神经元对应的是隐层
如果是隐层,类似于上面的分析$net(i)$是通过后面的sigmoid函数的输出作用于整个网络的,这里和前面的不同时可能有多个输出。
posted on 2020-03-29 18:09 lightblueme 阅读(161) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号