python爬取图片
Python 抓取网页中的图片
Ps:目标网站为千图网,如有需求,请购买正版,该项目仅用于学习交流使用。
分析目标
1.分析网页的请求信息,将请求头加上,主要是防止反爬。这里需要注意的是它的content-type。
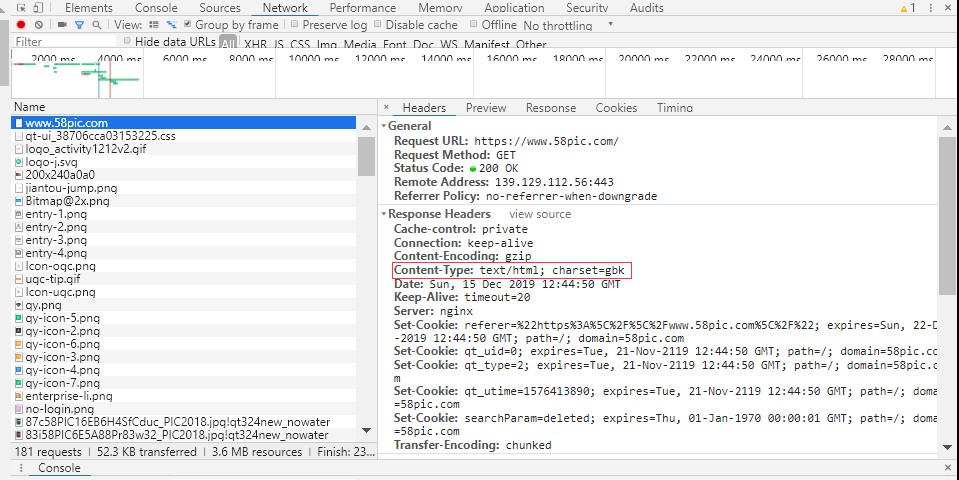
2.分析元素内容,获取相应的目标。
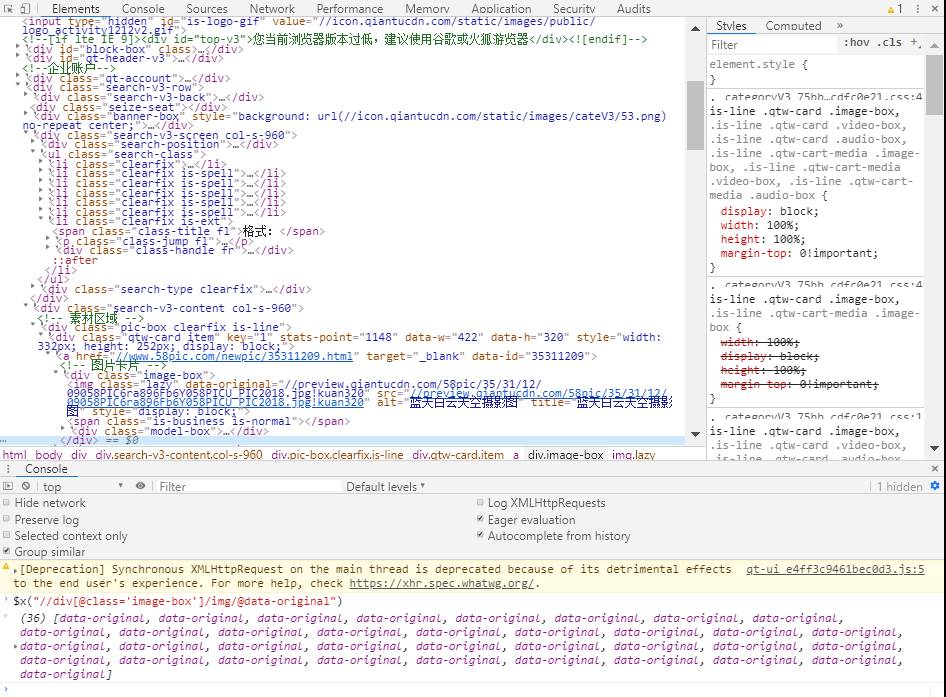
3.需要分析一下url

代码工程
分析号目标后就可以着手写了
python代码:
import requests from lxml import etree import os # 抓取图片 class Spider_qt(object): def __init__(self, pageNo, pageCount): # 反扒 self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/74.0.3729.131 Safari/537.36", "Referer": "https://www.58pic.com/" } self.get_page(pageNo, pageCount) # 获取页面 def get_page(self, pageNo, pageCount): for i in range(pageNo, pageNo + pageCount): print("===============================开始抓取第%s页===============================" % i) r = requests.get("https://www.58pic.com/piccate/53-0-0-p" + str(i) + ".html", headers=self.headers) page = etree.HTML(r.content.decode('gbk')) self.get_images(page) # 获取图片 def get_images(self, page): # xpath解析 image_url = page.xpath("///div[@class='image-box']/img/@data-original") image_alt = page.xpath("//div[@class='image-box']/img/@alt") for url, alt in zip(image_url, image_alt): url = "http:" + url file_name = alt + ".jpg" save_path = "F:\\python\\spider\\images\\qt\\" if not os.path.exists(save_path): os.makedirs(save_path) file_save_path = save_path + file_name r = requests.get(url, headers=self.headers) print("正在抓取:" + file_name) try: with open(file_save_path, 'wb') as f: f.write(r.content) except: print("===============================抓取错误===============================") def main(): pageNo = int(input("请输入下载开始页:")) pageCount = int(input("请输入需要下载的页数:")) Spider_qt(pageNo, pageCount) if __name__ == '__main__': main()
效果:
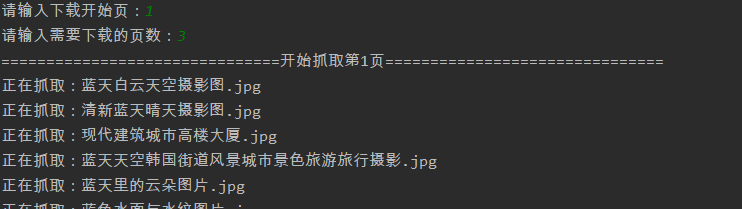

Ps:需要注意的是如果没有requests和lxml需要下载的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号