
hashCode equals ==
参考:https://mp.weixin.qq.com/s/aDDotZphhDRCWV4nAZbwhQ
1 作用
用来对比两个对象是否相等一致 ①效率 ②可靠性
2 区别
因为重写的equals()里一般比较的比较全面比较复杂,这样效率就比较低,而利用hashCode()进行对比,则只要生成一个hash值进行比较就可以了,效率很高。
hashCode()并不是完全可靠,哈希冲突
3 使用的注意事项
3.1 大量的并且快速的对象对比一般使用的hash容器,HashSet,HashMap,HashTable
(以下 比较方式 可查看HashMap put方法验证)
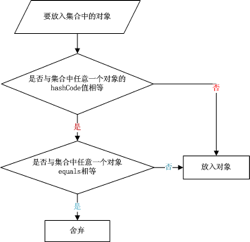
3.2 如果我们只是平时想对比两个对象 是否一致,则只重写一个equals(),然后利用equals()去对比也行的。
equals vs ==
当 equals 没重写时 equals 就是 == 比较两个对象 是否指向同一内存地址
public boolean equals(Object obj) {
return (this == obj);
}
equals & hashCode
从equals来看
1、that equal objects must have equal hash codes. 即:equals -> true hashCode 一定 ==
2、equals -> false hashCode 可能相同(hash冲突 However, the
programmer should be aware that producing distinct integer results
for unequal objects may improve the performance of hash tables. )
从hashCode来看
1、hashCode == ->equals true||false (可能真的是同一个对象 可能hashCode冲突)
2、hashCode != ->equals false
equals
* Indicates whether some other object is "equal to" this one.
* <p>
* The {@code equals} method implements an equivalence relation
* on non-null object references
* The {@code equals} method for class {@code Object} implements
* the most discriminating possible equivalence relation on objects;
* that is, for any non-null reference values {@code x} and
* {@code y}, this method returns {@code true} if and only
* if {@code x} and {@code y} refer to the same object
* ({@code x == y} has the value {@code true}).
* Object的equals实现: 最具有辨别力(其hashCode可能会有冲突的现象)的2个
*非空引用 的等价性比较
*也就是说,未重写时,只有x,y都是同一个对象的引用时(指向同一个对象),返回的才是true
* Note that it is generally necessary to override the {@code hashCode}
* method whenever this method is overridden, so as to maintain the
* general contract for the {@code hashCode} method, which states
* that equal objects must have equal hash codes.
hashCode
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
// hash tables : HashTable HashSet HashMap
* As much as is reasonably practical, the hashCode method defined
* by class {@code Object} does return distinct integers for
* distinct objects. (The hashCode may or may not be implemented
* as some function of an object's memory address at some point
* in time.)
// 没重写 返回的是 对象某一时刻内存地址hash后的一个code (某一时刻 比如GC 时 使用标记-复制算法时 某些对象的内存地址会变化 对应着 hashCode也会变)
<li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* If two objects are equal according to the {@code equals(Object)}
* method, then calling the {@code hashCode} method on each of
* the two objects must produce the same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link java.lang.Object#equals(java.lang.Object)}
* method, then calling the {@code hashCode} method on each of the
* two objects must produce distinct integer results. However, the
* programmer should be aware that producing distinct integer results
* for unequal objects may improve the performance of hash tables.
hashCode & HashMap
参考:https://blog.csdn.net/qq_38182963/article/details/78940047
源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// ^:异或 >>>:无符号右移 为啥要这样搞 后面研究下
重写hashCode时注意事项
重写hashCode方法时除了上述一致性约定,还有以下几点需要注意:
(1)返回的hash值是int型的,防止溢出。
(2)不同的对象返回的hash值应该尽量不同。(为了hashMap等集合的效率问题)
(3)《Java编程思想》中提到一种情况
“设计hashCode()时最重要的因素就是:无论何时,对同一个对象调用hashCode()都应该产生同样的值。如果在讲一个对象用put()添加进HashMap时产生一个hashCdoe值,而用get()取出时却产生了另一个hashCode值,那么就无法获取该对象了。所以如果你的hashCode方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,hashCode()方法就会生成一个不同的散列码”。
所以 自定义的对象 作为hash的key时 必须重写hashCode
即使不是值比较 用原生的hashCode也是不安全的
hashCode 返回的是 对象某一时刻内存地址hash后的一个code (某一时刻 比如GC 时 使用标记-复制算法时 某些对象的内存地址会变化 对应着 hashCode也会变) hash的key也会变化 以前put的 就get不出来了
实际应用:研究这些原理的应用价值(阿里规范 关于)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号