
索引 B+Tree ; 新建索引 类型方法 BTREE 或 HASH
万物 归于算法 数据结构;理解更深刻
如:索引->B+Tree->最左匹配原则;左模糊查询不走索引
索引 B+ tree 平衡多路查找树+链表
叶子节点链表 支持 范围查询走索引 不过放在组合索引最后一个 知道开始的节点 结束的节点 直接取出一段链表
所以 同样范围的查询 > < between 比 in 效率的高 应该
q&a:为啥不用 二叉 ?可能单从数据结构来看 时间复杂度 空间复杂度 平均查找时间 二叉更优 (待研究)但是 具体问题 具体分析 多路 减少层数 减少磁盘io
1. 【强制】业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
说明:不要以为唯一索引影响了 insert 速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,
即使在应用层做了非常完善的校验控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
// 唯一索引查找更快 因为查到第一个就不继续查了 和limit 一样 查够了 就停止查了
// 唯一索引查找更快 因为查到第一个就不继续查了 和limit 一样 查够了 就停止查了
6. 【推荐】利用覆盖索引来进行查询操作,避免回表。
说明:如果一本书需要知道第 11 章是什么标题,会翻开第 11 章对应的那一页吗?目录浏览一下就好,这
个目录就是起到覆盖索引的作用。
正例:能够建立索引的种类分为主键索引、唯一索引、普通索引三种,而覆盖索引只是一种查询的一种效
果,用 explain 的结果,extra 列会出现:using index。
https://blog.csdn.net/hao65103940/article/details/89032538
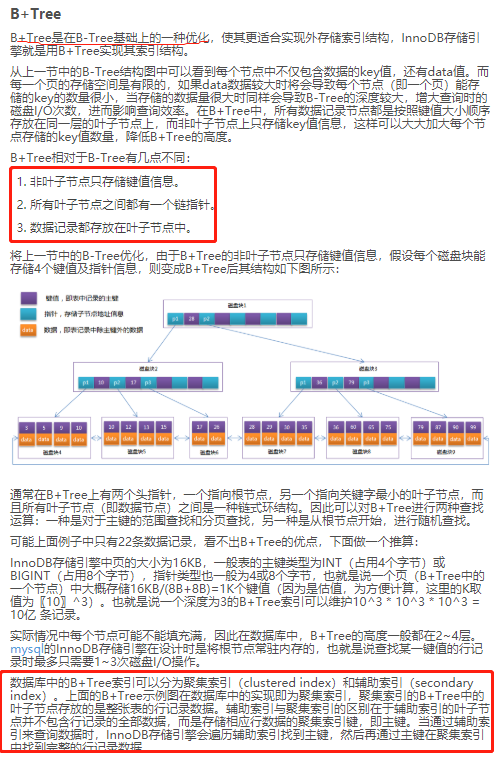
B Tree 平衡树
何为平衡树
https://blog.csdn.net/qq_33060405/article/details/78510121
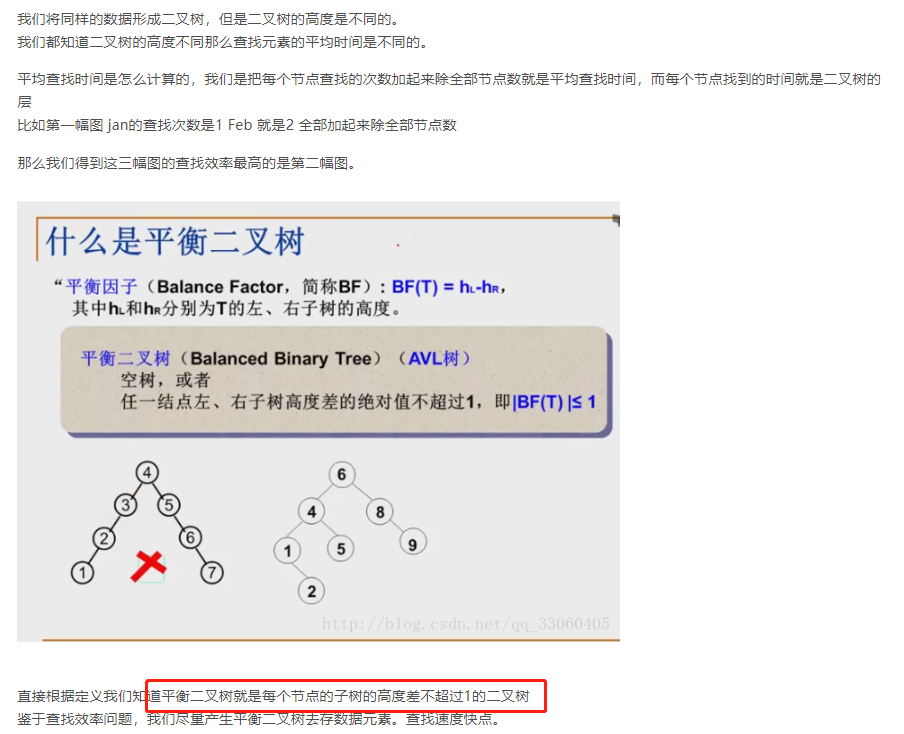
扩展:自平衡树 红黑树
jdk 1.8 HashMap 数据结构由 数组+链表 改为 数组+链表/红黑树
插入时:判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作
删除时:删除元素首先是要找到 桶的位置,然后如果是链表,则进行链表遍历,找到需要删除的元素后,进行删除;如果是红黑树,也是进行树的遍历,找到元素删除后,进行平衡调节,注意,当红黑树的节点数小于 6 时,会转化成链表。

时间复杂度 空间复杂度 平均查找时间 时间空间的取舍 现在一般相对空间 时间更稀缺 所以 一般选择 可以 牺牲空间换取时间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号