
KNN:原理及python线性扫描实现
目录
#导入相关的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import mglearn
import warnings
warnings.filterwarnings('ignore')
K—NN算法
输入:
- 训练数据集
- 实例特征向量x。
输出:实例x所属的类别y。
- 根据给定的距离度量,找出距离x最近的k个点。
- 根据预设的分类决策规则(如多数表决),决定x的类别y。
可以看出,K近邻算法的三要素分别为:k值、距离度量方法、分类决策规则。k近邻没有显式的学习过程。
mglearn.plots.plot_knn_classification(n_neighbors=3)

上图给出了K-NN算法的示例,五角星测试集数据点根据离各自最近的三个训练集点进行投票而分类。
K近邻模型
距离度量
- \(L_p距离\):
- 欧式距离:\(p=2\)
- 曼哈顿距离:\(p=1\)
- \(p=\infty\)
证明:
令
则
而显然
故
原命题得证
k值的选择
K值的选择会对K近邻法的结果产生重大影响,如果选择较小的K值,就相当于用较小的邻域中的训练实例进行预测,“学习"的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用。但缺点是“学习"的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰巧是噪声,预剥就会出错。换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合。
如果选择较大的K值,就相当于用较大邻域中的训练实例进行预测。其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。K值的增大就意味着整体的模型变得简单,如果k=N,那么无论输入实例是什么,都将简单地预判它属于在训练实例中最多的类,这时,模型过于简单,完全忽略训练实例中的大量有用信息,是不可取的。在应用中,K值一般取一个比较小的数值,可采用参数搜索选取最优的K值。
分类决策规则
通常采用多数表决法。
KNN的sklearn使用
K-NN分类使用距离目标点最近的K个点的类别来进行“投票”,得票数多的类别将被标记为预测类别。
- KNN算法的线性扫描算法:
对于每一个在测试集中的数据点:
- 计算目标的数据点(需要分类的数据点)与该数据点的距离
- 将距离排序:从小到大
- 选取前K个最短距离
- 选取这K个中最多的分类类别
- 返回该类别来作为目标数据点的预测值
由于线性扫描算法需要计算每一个点到待预测点的距离,复杂度较大,还有很多其他的数据结构来存储数据,以减少计算次数,提高搜索效率,如kd树等。
下面使用sklearn应用K近邻算法:
#导入数据集
from sklearn.model_selection import train_test_split
X,y = mglearn.datasets.make_forge()
print('自变量前五行:\n{}'.format(X[:5]))
print('因变量:{}'.format(y))
自变量前五行:
[[ 9.96346605 4.59676542]
[11.0329545 -0.16816717]
[11.54155807 5.21116083]
[ 8.69289001 1.54322016]
[ 8.1062269 4.28695977]]
因变量:[1 0 1 0 0 1 1 0 1 1 1 1 0 0 1 1 1 0 0 1 0 0 0 0 1 0]
from sklearn.neighbors import KNeighborsClassifier
X_train,X_test,y_train,y_test = train_test_split(X,y,stratify=y,random_state=42)
KNC = KNeighborsClassifier(n_neighbors=5).fit(X_train,y_train)
KNC.predict(X_test),y_test
(array([1, 0, 1, 0, 0, 0, 0]), array([1, 0, 1, 1, 0, 0, 0]))
print('训练集精度:{}'.format(KNC.score(X_train,y_train)))
print('测试集精度:{}'.format(KNC.score(X_test,y_test)))
训练集精度:0.9473684210526315
测试集精度:0.8571428571428571
在这里,train_test_split函数将输入的X,y划分为四部分,X_train,y_train,X_test,y_test,参数stratify=y表示在测试集与训练集划分时,各个部分的数据类型与y中两种类别的数据比例相同,防止分配不均影响模型性能。random_state参数限定了每次运行划分函数都获得同样的结果。因此,影响最终模型精度的因素有:
1)每次数据划分时,划分到不同组别的数据不同。
2)模型参数,即选择的最近邻数量不同。
第一项在训练模型时使用交叉验证的方式尽量降低随机性对模型的影响,下面将通过调整参数n_neigbors调整模型精度。
#本例使用乳腺癌数据演示KNN模型调参
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train,X_test,y_train,y_test = train_test_split(cancer.data,cancer.target,stratify = cancer.target,random_state = 66)
training_accuracy=[]
test_accuracy = []
for i in range(1,11):
KNC = KNeighborsClassifier(n_neighbors=i).fit(X_train,y_train)
training_accuracy.append(KNC.score(X_train,y_train))
test_accuracy.append(KNC.score(X_test,y_test))
plt.plot(range(1,11),training_accuracy,label = 'training_accuracy')
plt.plot(range(1,11),test_accuracy,label='test_accuracy')
plt.xlabel('n_neighbors')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
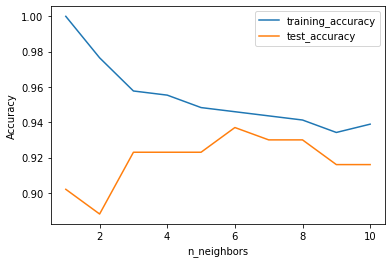
从上图可以看出,当近邻数为6时,模型具有最大泛化精度。
KNN的python实现
使用KNN实现约会网站配对效果改进
如下所示数据来自于某约会网站,根据每年获得的飞行常客里程数、玩视频游戏所耗时间百分比、每周消费的冰淇淋公升数三个特征对配对者进行预测,预测结果有三类,不喜欢、稍喜欢、很喜欢。
path = './data/datingTestSet.txt'
data = pd.read_csv(path, '\t',header=None)
data.head()
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 14488 | 7.153469 | 1.673904 | smallDoses |
| 1 | 26052 | 1.441871 | 0.805124 | didntLike |
| 2 | 75136 | 13.147394 | 0.428964 | didntLike |
| 3 | 38344 | 1.669788 | 0.134296 | didntLike |
| 4 | 72993 | 10.141740 | 1.032955 | didntLike |
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
def createDataSet():
group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
def read_data(path, sep):
'''
读取csv文件
:param path: 文件路径
:param sep: 分隔符
:return: 读取到的数据
'''
data = pd.read_csv(path, sep=sep, header=None)
return data
def MinMaxScalar(dataSet):
'''
最大最小值标准化。
:param dataSet: 输入的dataframe
:return: 标准化之后的ndarray
'''
minVec = dataSet.min()
maxVec = dataSet.max()
range = maxVec - minVec
scalarMat = dataSet - np.tile(minVec, (dataSet.shape[0], 1))
scalarMat = scalarMat/range
return scalarMat.values
def classifier0(inX, dataSet, labels, k):
'''
分类器,用于预测输入向量的标签
:param inX: 待分类向量(样本点)
:param dataSet: 训练集
:param labels: 训练集标签
:param k: 最近邻数量
:return: 输入待分类向量的预测标签
'''
diffMatrics = np.tile(inX, (dataSet.shape[0], 1)) - dataSet
sqDiffMat = diffMatrics**2
distanceMat = sqDiffMat.sum(axis=1)
rank = distanceMat.argsort()
countDict = {}
for i in range(k):
label = labels[rank[i]]
countDict[label] = countDict.get(label, 0) + 1
sortedCountDict = sorted(countDict.items(), key=lambda x:x[1],reverse=True)
return sortedCountDict[0][0]
def predict(X_train, X_test, y_train, k):
'''
对输入向量矩阵进行预测
:param X_train: 训练集
:param X_test: 待预测矩阵
:param y_train: 训练集标签
:param k: 最近邻数量
:return:输入矩阵的预测标签向量
'''
y_pre = np.zeros(len(X_test))
for i in range(len(X_test)):
# print(f'i:{X_test[i]}')
label = classifier0(X_test[i], X_train, y_train, k)
y_pre[i] = label
return y_pre
def score(y_test, y_pre):
'''
错误率评估
:param y_test: 待预测数据标签真实值
:param y_pre: 待预测数据预测标签
:return: 预测正确率
'''
return sum(y_test == y_pre)/y_test.shape[0]
def main():
path = './data/datingTestSet.txt'
data = read_data(path, '\t')
X_origion = data.iloc[:, :-1]
y = data.iloc[:, -1]
y = y.apply(lambda x:2 if x == 'largeDoses' else 1 if x=='smallDoses' else 0)
X = MinMaxScalar(X_origion)
X_train = X[:int(X.shape[0]*0.7), :]
X_test = X[int(X.shape[0]*0.7):, :]
y_train = y[:int(len(y)*0.7)]
y_test = y[int(len(y)*0.7):]
y_pre = predict(X_train, X_test, y_train,10)
print(f'自定义KNN:{score(y_test.values, y_pre)}')
kN = KNeighborsClassifier(10).fit(X_train, y_train)
print(f'sklearnKNN:{kN.score(X_test,y_test)}')
if __name__ == '__main__':
main()
自定义KNN:0.9633333333333334
sklearnKNN:0.9633333333333334
手写信息识别系统
本次使用的数据是一些txt文件,每个文件中存储了一个手写数字矩阵,矩阵由\(0,1\)构成,大小为\(32 \times 32\)。首先,将每个文件读入,并将\(32\times32\)矩阵展开为\(1\times1024\)的向量,作为数据集的一行。然后将所有向量合并成特征矩阵,标签由txt文件名称获取。
import os
import numpy as np
import pandas as pd
import knn
def get_vector(filepath):
'''
将文本文件转化为向量
:param filepath:文件路径
:return: 数字向量
'''
vec = pd.read_csv(filepath, header=None)[0].str.split('', expand=True).iloc[:, 1:33].values.reshape((1, -1))
return vec
def get_data(dirPath):
'''
读取数据集
:param dirPath: 数据所在文件夹
:return: 数据集特征矩阵,数据集标签
'''
dirlist = os.listdir(dirPath)
length = len(dirlist)
DataMat = np.zeros((length, 1024))
labels = np.zeros(length)
for i in range(length):
vec = get_vector(dirPath+dirlist[i])
DataMat[i] = vec
label = dirlist[i].split('_')[0]
labels[i] = label
return DataMat, labels
def main():
trainPath = './data/digits/trainingDigits/'
testPath = './data/digits/testDigits/'
X_train, y_train = get_data(testPath)
X_test, y_test = get_data(testPath)
y_pre = knn.predict(X_train, X_test, y_train, 10)
print(knn.score(y_test, y_pre))
# print(a, b)
if __name__ == '__main__':
main()
0.9841437632135307
小结:
K值的选择
之前有提到,可以通过交叉验证的方法选择K合适的K值。
选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
距离的度量
欧式距离
曼哈顿距离
闵可夫斯基距离(Minkowski Distance)
可以看出,欧式距离和曼哈顿距离分别是闵可夫斯基距离中p为2、1时的特殊距离。
- 优缺点及参数
优点:
-
理论成熟,思想简单,既可以用来做分类也可以用来做回归
-
可用于非线性分类
-
训练时间复杂度比支持向量机之类的算法低,仅为O(n)
-
和朴素贝叶斯之类的算法比,对数据没有假设,准确度高,对异常点不敏感
-
由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合
-
该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分
缺点:
-
计算量大,尤其是特征数非常多的时候
-
样本不平衡的时候,对稀有类别的预测准确率低
-
KD树,球树之类的模型建立需要大量的内存
-
使用懒散学习方法,基本上不学习,导致预测时速度比起逻辑回归之类的算法慢
-
相比决策树模型,KNN模型可解释性不强
主要参数:KNeiborsClassifier(n_neighbors),距离度量方法。

