Kubernetes 入门与安装部署
一、简介
参考:Kubernetes 官方文档、Kubernetes中文社区 | 中文文档
Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化,拥有一个庞大且快速增长的生态系统。
为什么Kubernetes如此有用?
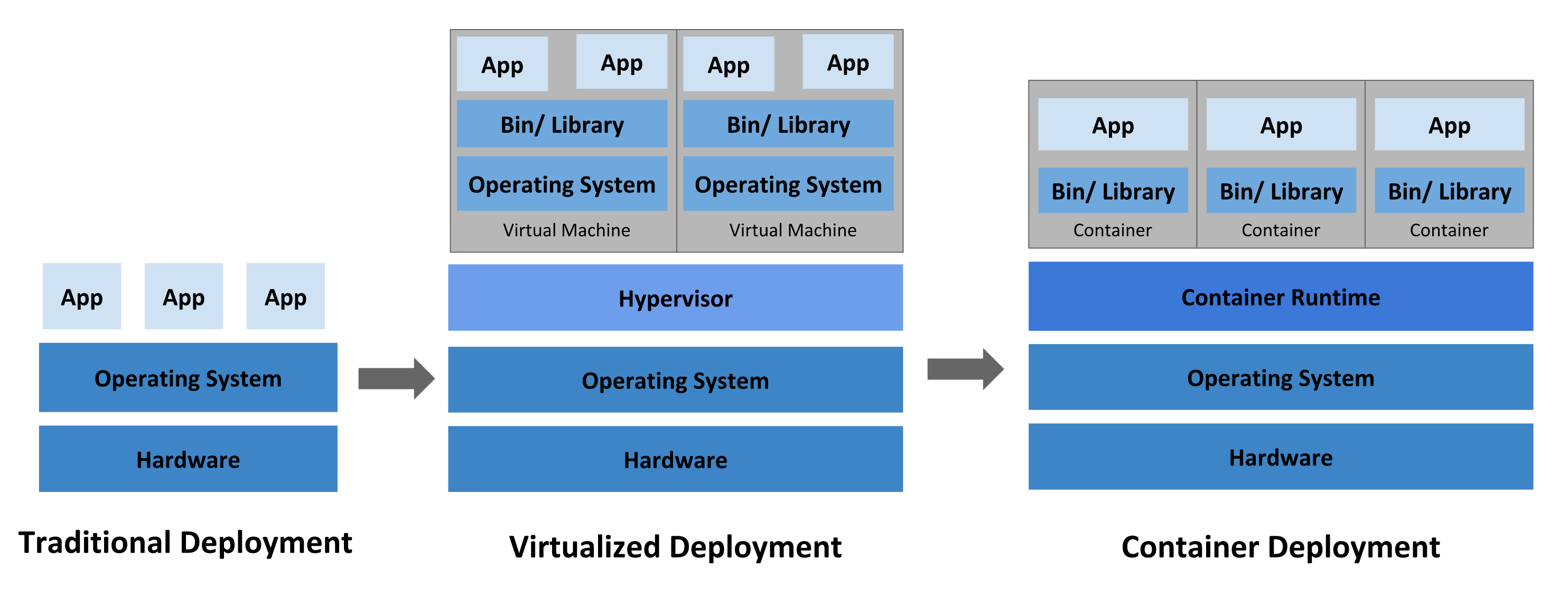
传统部署时代: 早期,组织在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况,结果可能导致其他应用程序的性能下降。一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展,并且组织维护许多物理服务器的成本很高。
虚拟化部署时代: 作为解决方案,引入了虚拟化功能,它允许您在单个物理服务器的 CPU 上运行多个虚拟机(VM)。虚拟化功能允许应用程序在 VM 之间隔离,并提供安全级别,因为一个应用程序的信息不能被另一应用程序自由地访问。
因为虚拟化可以轻松地添加或更新应用程序、降低硬件成本等等,所以虚拟化可以更好地利用物理服务器中的资源,并可以实现更好的可伸缩性。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代: 容器类似于 VM,但是它们具有轻量级的隔离属性,可以在应用程序之间共享操作系统(OS)。因此,容器被认为是轻量级的。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。由于它们与基础架构分离,因此可以跨云和 OS 分发进行移植。
容器因具有许多优势而变得流行起来,下面列出了容器的一些好处:
-
敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
-
持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),提供可靠且频繁的容器镜像构建和部署。
-
关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像,从而将应用程序与基础架构分离。
-
可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
-
跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
-
云和操作系统分发的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、Google Kubernetes Engine 和其他任何地方运行。
-
以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
-
松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分,并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
-
资源隔离:可预测的应用程序性能。
-
资源利用:高效率和高密度。
Kubernetes能做什么?
容器是打包和运行应用程序的好方式。在生产环境中,您需要管理运行应用程序的容器,并确保不会停机。例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 的救援方法!Kubernetes 为您提供了一个可弹性运行分布式系统的框架。Kubernetes 会满足您的扩展要求、故障转移、部署模式等。例如,Kubernetes 可以轻松管理系统的 Canary 部署。
Kubernetes 为您提供:
-
服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果到容器的流量很大,Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 -
存储编排
Kubernetes 允许您自动挂载您选择的存储系统,例如本地存储、公共云提供商等。 -
自动部署和回滚
您可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态更改为所需状态。例如,您可以自动化 Kubernetes 来为您的部署创建新容器,删除现有容器并将它们的所有资源用于新容器。 -
自动二进制打包
Kubernetes 允许您指定每个容器所需 CPU 和内存(RAM)。当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。 -
自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 -
密钥与配置管理
Kubernetes 允许您存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。您可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥。
二、搭建Kubernetes集群
如何搭建?
参考:睿云智合 图形化Kubernetes集群部署工具、和我一步步部署 kubernetes 集群
我这里是根据睿云智合一步一步搭建的,它提供了图形化界面,适合初学者搭建一个环境
搭建一个Kubernetes集群(整个组件的基础设施包含k8s集群等各种监控运维组件)需要如下节点信息:
| 序号 | 主机名 | 角色 | CPU | 内存 | OS | 部署组件 |
|---|---|---|---|---|---|---|
| 1 | breeze-deploy | 部署节点 | 4核 | 8G | CentOS-7.6-x64 | docker/docker-compose/breeze |
| 2 | k8s-master01 | k8s主节点 | 4核 | 16G | CentOS-7.6-x64 | docker/master组件/etcd/haproxy/keepalive/prometheus |
| 3 | k8s-master02 | k8s主节点 | 4核 | 16G | CentOS-7.6-x64 | docker/master组件/etcd/haproxy/keepalive/prometheus |
| 4 | k8s-master03 | k8s主节点 | 4核 | 16G | CentOS-7.6-x64 | docker/master组件/etcd/haproxy/keepalive/prometheus |
| 5 | k8s-worker01 | k8s工作节点 | 8核 | 32G | CentOS-7.6-x64 | docker/worker组件/prometheus/grafana/altermanager |
| 6 | k8s-worker02 | k8s工作节点 | 8核 | 32G | CentOS-7.6-x64 | docker/worker组件/prometheus/grafana/altermanager |
| 7 | k8s-worker03 | k8s工作节点 | 8核 | 32G | CentOS-7.6-x64 | docker/worker组件/prometheus/grafana/altermanager |
| 8 | k8s-worker04 | k8s工作节点 | 8核 | 32G | CentOS-7.6-x64 | docker/worker组件/prometheus/grafana/altermanager |
| 9 | k8s-worker05 | k8s工作节点 | 8核 | 32G | CentOS-7.6-x64 | docker/worker组件/prometheus/grafana/altermanager |
| 10 | k8s-worker06 | k8s工作节点 | 8核 | 32G | CentOS-7.6-x64 | docker/worker组件/prometheus/grafana/altermanager |
| 11 | harbor | 镜像仓库节点 | 4核 | 16G | CentOS-7.6-x64 | harbor |
| 12 | VIP | 3台k8s master节点的高可用虚拟浮动IP地址 |
master组件:kube-apiserver、kube-controller-manager、kube-scheduler
worker组件:kubelet、kube-proxy
备注:
- 适合的操作系统:RHEL/CentOS: 7.4/7.5/7.6/7.7/7.8、Ubuntu 16/18
- 部署节点请尽量保证其为裸机,配置最低为2核4G
- 磁盘每个节点都尽量大一点60G+
- 为了保证K8S的高可用性,需要为所有的master节点绑定一个VIP
本人在本地采用虚拟机部署方式如下(不推荐):
| 主机名 | 角色 | IP | OS | CPU | 内存 | 磁盘 | 部署组件 |
|---|---|---|---|---|---|---|---|
| breeze-deploy | 部署节点 | 192.168.47.130 | CentOS-7.8-x64 | 2核 | 2G | 20G | docker/docker-compose/breeze |
| k8s-master01 | k8s主节点 | 192.168.47.131 | CentOS-7.8-x64 | 2核 | 4G | 20G | k8s master组件/etcd |
| k8s-worker01 | k8s工作节点 | 192.168.47.132 | CentOS-7.8-x64 | 2核 | 4G | 20G | k8s worker组件/prometheus |
| harbor | 镜像仓库节点 | 192.168.47.133 | CentOS-7.8-x64 | 2核 | 2G | 20G | harbor |
遇到的问题
-
Kubernetes创建Pod时从Harbor仓库拉取镜像出现‘没有权限’
生成的登录的信息
$ docker login --username=admin 192.168.47.133 # 登录镜像仓库 $ cat ~/.docker/config.json # 登录后生成的登录信息存放于该文件 $ cat ~/.docker/config.json | base64 -w 0 # 使用base64加密生成密钥创建harbor-secret.yaml文件,内容如下:
apiVersion: v1 kind: Secret metadata: name: adminsecret # 密钥名称 data: .dockerconfigjson: *** # 输入上面生产的密钥 type: kubernetes.io/dockerconfigjson生成Secret对象
$ kubectl create -f harbor-secret.yam # 创建Secret对象然后在Pod的模板文件中添加
spec: imagePullSecrets: - name: adminsecret # 拉取镜像时使用 adminsecret Secret 对象 -
如果Harbor镜像仓库所在节点的磁盘满了,会导致Harbor页面无法登录
先对该节点进行扩容,参考centos虚拟机扩展磁盘空间(经历无数坑,血一样总结,史上最全)并结合评论区对该节点进行扩容
因为上面需要先关闭虚拟机,所以需要再重新启动Harbor
$ find / -name docker-compose.yml # 找到 Harbor 的配置文件后进入该目录 $ docker-compose down # 关闭 Harbor $ ./prepare # 进行准备工作,创建相应的配置文件 $ docker-compose up -d # 以后台方式启动 Harbor
三、Pod
Pod是Kubernetes创建或部署的最小/最简单的基本单位,一个Pod代表集群上正在运行的一个进程。
一个Pod封装一个应用容器(也可以有多个容器),存储资源、一个独立的网络IP以及管理控制容器运行方式的策略选项。Pod代表部署的一个单位:Kubernetes中单个应用的实例,它可能由单个容器或多个容器共享组成的资源。
3.1 配置示例
apiVersion: v1 # 1.9.0 之前的版本使用 apps/v1beta2,可通过命令 kubectl api-versions 查看
kind: Pod # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: nginx # 资源的名字,在同一个namespace中必须唯一
labels:
app: nginx1.19.1 # 标签
spec: # 模板的规范
containers:
- name: nginx # 容器的名字
image: 192.168.47.133/dwzq-info/nginx:v1.19.1 # 容器的镜像地址
imagePullPolicy: IfNotPresent
# IfNotPresent:默认值,本地有则使用本地镜像,不拉取,如果不存在则拉取
# Always:总是拉取
# Never:只使用本地镜像,从不拉取
ports:
- name: http
containerPort: 8085 # 对service暴露端口
resources: # 资源限制标签
requests: # 创建pod时向k8s请求的资源大小
memory: "64Mi"
cpu: "250m"
limits: # 运行中pod的最大资源空间
memory: "64Mi"
cpu: "250m"
restartPolicy: OnFailure
# Always:当容器停止,总是重建容器(默认)
# OnFailure:当容器异常退出(退出状态码非0)时才重启容器
# Never:从不重启容器
imagePullSecrets: # 因为我需要从harbor私库拉取镜像,需要配置密钥,'adminsecret'是我已经创建好的
- name: adminsecret
3.2 创建pod的流程
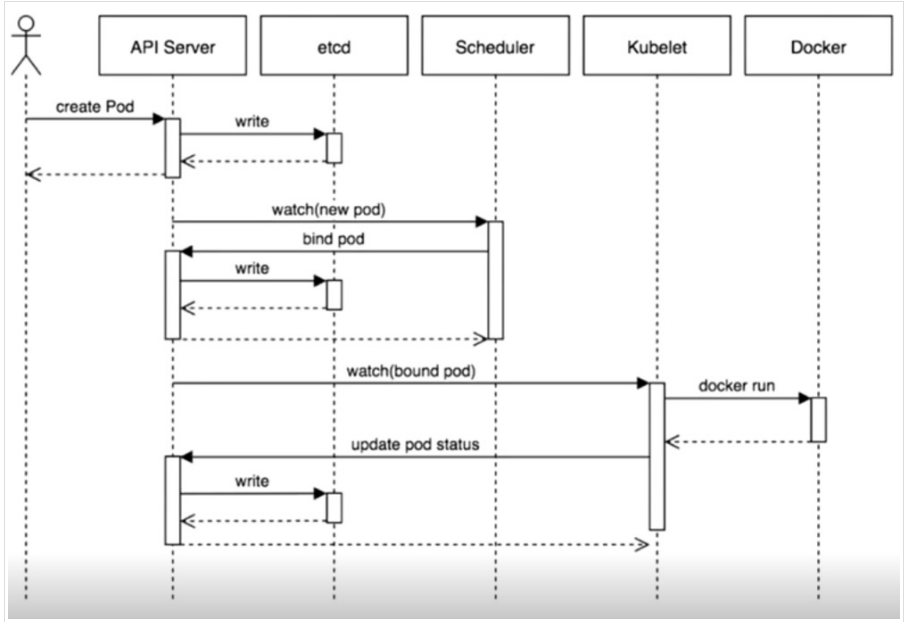 描述:
描述:
- 客户端通过kubectl命令,或者通过API Server的Restful API(支持json和yaml格式)发起创建一个Pod请求;
- API Server处理用户请求,存储Pod信息数据到etcd集群中;
- Scheduler调度器通过API Server查看未绑定的Pod,尝试为Pod进行分配主机,通过调度算法选择主机后,绑定到这台机器上并且把调度信息写入etcd集群;
- Kubelet根据调度结果执行Pod创建操作,成功后将信息通过API Server更新到etcd集群中;
- 整个Pod创建过程完成,每个组件都在于API Server进行交互,API Server就是k8s集群的中间者,组件之间的协同者,是一个集群访问入口
3.3 控制器
-
ReplicaSet
代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。
ReplicaSet主要三个组件组成:- 用户期望的pod副本数量
- 标签选择器,判断哪个pod归自己管理
- 当现存的pod数量不足,会根据pod资源模板进行新建帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment。
-
Deployment
工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置。 -
DaemonSet
用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务,比如ingress,elk.服务是无状态的,服务必须是守护进程。参考文章:https://www.cnblogs.com/xzkzzz/p/9553321.html -
Job
只要任务或程序运行完成就立即退出,不需要重启或重建。 参考文章:https://blog.csdn.net/bbwangj/article/details/82011610 -
Cronjob
周期性任务控制,执行后就退出, 不需要持续后台运行, 参考文章:https://blog.csdn.net/bbwangj/article/details/82867830 -
StatefulSet
管理有状态应用,比如redis,mysql
3.4 常用命令
$ kubectl create -f pod.yaml # 创建Pod资源
$ kubectl get pods nginx-pod # 查看pods
$ kubectl describe pod/nginx # 查看pod描述
$ kubectl apply -f pod.yaml # 更新资源
$ kubectl delete -f pod.yaml # 删除资源
$ kubectl delete pods nginx-pod # 删除资源
$ kubectl logs -f pod/nginx # 查看日志
$ kubectl exec -it pod/nginx /bin/bash # 进入容器
四、Deployment
- 使用Deployment来创建ReplicaSet(升级版的ReplicationController),ReplicaSet在后台创建pod。检查启动状态,看它是成功还是失败。
- 通过更新Deployment的PodTemplateSpec字段来声明Pod的新状态。这会创建一个新的ReplicaSet,Deployment会按照控制的速率将pod从旧的ReplicaSet移动到新的ReplicaSet中。
- 如果当前状态不稳定,回滚到之前的Deployment revision。每次回滚都会更新Deployment的revision。
- 扩容Deployment以满足更高的负载。
- 暂停Deployment来应用PodTemplateSpec的多个修复,然后恢复上线。
- 根据Deployment 的状态判断上线是否hang住了。
- 清除旧的不必要的ReplicaSet
4.1 配置示例
apiVersion: apps/v1 # 1.9.0之前的版本使用 apps/v1beta2,可通过命令 kubectl api-versions 查看
kind: Deployment # 指定创建资源的角色/类型
metadata: # 资源的元数据/属性
name: nginx-deployment # 资源的名字,在同一个namespace中必须唯一
namespace: default # 命名空间,默认为default
labels:
app: nginx1.19.0 # 标签
spec:
replicas: 3 # 副本数量3
strategy:
rollingUpdate: # 由于replicas为3,则整个升级,pod个数在2-4个之间
maxSurge: 1 # 滚动升级时会先启动1个pod
maxUnavailable: 1 # 滚动升级时允许的最大Unavailable的pod个数
selector: # 定义标签选择器,部署需要管理的pod(带有该标签的的会被管理)需在pod 模板中定义
matchLabels:
app: nginx1.19.0
template: # 从这里开始是Pod的定义
metadata:
labels: # Pod的label
app: nginx1.19.0
spec: # 模板的规范
containers:
- name: nginx # 容器的名字
image: 192.168.47.133/dwzq-info/nginx:v1.19.0 # 容器的镜像地址
# command: [ "/bin/sh","-c","cat /etc/config/path/to/special-key" ] # 启动命令
args: # 启动参数
- '-storage.local.retention=$(STORAGE_RETENTION)'
- '-storage.local.memory-chunks=$(STORAGE_MEMORY_CHUNKS)'
- '-config.file=/etc/prometheus/prometheus.yml'
- '-alertmanager.url=http://alertmanager:9093/alertmanager'
- '-web.external-url=$(EXTERNAL_URL)'
# 如果command和args均没有写,那么用Docker默认的配置。
# 如果command写了,但args没有写,那么Docker默认的配置会被忽略而且仅仅执行.yaml文件的command(不带任何参数的)。
# 如果command没写,但args写了,那么Docker默认配置的ENTRYPOINT的命令行会被执行,但是调用的参数是.yaml中的args。
# 如果如果command和args都写了,那么Docker默认的配置被忽略,使用.yaml的配置。
imagePullPolicy: IfNotPresent
# IfNotPresent:默认值,本地有则使用本地镜像,不拉取,如果不存在则拉取
# Always:总是拉取
# Never:只使用本地镜像,从不拉取
livenessProbe:
# 表示container是否处于live状态。如果LivenessProbe失败,将会通知kubelet对应的container不健康了,
# 随后kubelet将kill掉container,并根据RestarPolicy进行进一步的操作。
# 默认情况下LivenessProbe在第一次检测之前初始化值为Success,
# 如果container没有提供LivenessProbe,则也认为是Success;
# readinessProbe:如果检查失败,Kubeneres会把Pod从service endpoints中剔除。
httpGet:
path: / # 如果没有心跳检测接口就为/
port: 8080
scheme: HTTP
initialDelaySeconds: 60 # 启动后延时多久开始运行检测
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
ports:
- name: http
containerPort: 8085 # 对service暴露端口
resources: # CPU内存限制
requests:
cpu: 2
memory: 2048Mi
limits:
cpu: 2
memory: 2048Mi
env: # 通过环境变量的方式,直接传递pod=自定义Linux OS环境变量
- name: LOCAL_KEY # 本地Key
value: value
- name: CONFIG_MAP_KEY # 局策略可使用configMap的配置Key,
valueFrom:
configMapKeyRef:
name: special-config # configmap中找到name为special-config
key: special.type # 找到name为special-config里data下的key
volumeMounts: # 挂载volumes中定义的磁盘
- name: log-cache
mount: /tmp/log
- name: sdb # 普通用法,该卷跟随容器销毁,挂载一个目录
mountPath: /data/media
- name: nfs-client-root # 直接挂载硬盘方法,如挂载下面的nfs目录到/mnt/nfs
mountPath: /mnt/nfs
- name: rbd-pvc # 高级用法第2中,挂载PVC(PresistentVolumeClaim)
volumes: # 定义磁盘给上面volumeMounts挂载
- name: log-cache
emptyDir: {}
- name: sdb # 挂载宿主机上面的目录
hostPath:
path: /any/path/it/will/be/replaced
- name: nfs-client-root # 供挂载NFS存储类型
nfs:
server: hostaddr # NFS服务器地址
path: /opt/public # showmount -e 看一下路径
- name: rbd-pvc # 挂载PVC磁盘
persistentVolumeClaim:
claimName: rbd-pvc1 # 挂载已经申请的PVC磁盘
4.2 相关使用
创建
$ kubectl create -f deployment.yaml --record # --record 为True,在annotation中记录当前命令创建或者升级了该资源,如查看在每个Deployment revision中执行了哪些命令
$ kubectl get deployments -n default -o wide # 获取Deployments信息
$ kubectl get rs -n default -o wide # 获取Replica Set信息,名字总是<Deployment的名字>-<pod template的hash值>
$ kubectl get pods -n default -o wide --show-labels # 获取Pod信息
更新
注意: Deployment的rollout当且仅当Deployment的pod template(例如.spec.template)中的label更新或者镜像更改时被触发。其他更新,例如扩容Deployment不会触发rollout。
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 # 更新镜像
$ kubectl edit deployment/nginx-deployment # 或使用edit命令来编辑Deployment模板,保存后即更新
$ kubectl rollout status deployment/nginx-deployment # 查看rollout状态
回退
$ kubectl describe deployment # 查看状态
$ kubectl rollout history deployment/nginx-deployment # 检查Deployment升级的历史记录
$ kubectl rollout history deployment/nginx-deployment --revision=1 # 查看某个revision的详细信息
$ kubectl rollout undo deployment/nginx-deployment # 回退当前的rollout到之前的版本
$ kubectl rollout undo deployment/nginx-deployment --to-revision=1 # 回退当前的rollout到某个历史版本
扩容
$ kubectl scale deployment nginx-deployment --replicas 3 # 扩容,指定运行的副本
# 基于当前Pod的CPU利用率选择最少和最多的Pod数(需启用horizontal pod autoscaling)
$ kubectl autoscale deployment nginx-deployment --min=10 --max=15 --cpu-percent=80
暂停和恢复
$ kubectl get deployment # 查看deployment列表(default namespace)
$ kubectl rollout pause deployment/nginx-deployment # 暂停deployment
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.19.1 # 更新镜像
# 恢复之前可以多次进行更新操作,在恢复之前更新过程不会产生任何影响(前提是已暂停)
$ kubectl rollout resume deployment/nginx-deployment # 恢复deployment
五、StatefulSet
StatefulSet 是Kubernetes中的一种控制器,在很多的分布式应用场景中,他们各个实例之间往往会有对应的关系,例如:主从、主备。还有数据存储类应用,它的多个实例,往往会在本地磁盘存一份数据,而这些实例一旦被杀掉,即使重建起来,实例与数据之间关系也会丢失,而这些实例有不对等的关系,实例与外部存储有依赖的关系的应用,被称作“有状态应用”。StatefulSet与Deployment相比,相同于他们管理相同容器规范的Pod,不同的是,StatefulSet为Pod创建一个持久的标识符,他可以在任何编排的时候得到相同的标识符。
说明:进行下述操作前请先准备好2个1G的PersistentVolumes存储卷
5.1 配置示例
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
type: "ClusterIP" # 默认服务类型
ports:
- port: 80
name: web
selector:
app: nginx
clusterIP: "None" # 创建 Headless Service
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: k8s.gcr.io/nginx-slim:0.8
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates: # 生成PVC
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 1Gi
六、Service
Kubernetes Pod 是有生命周期的。 它们可以被创建,而且销毁之后不会再启动。 如果您使用 Deployment 来运行您的应用程序,则它可以动态创建和销毁 Pod。
每个 Pod 都有自己的 IP 地址,但是在 Deployment 中,在同一时刻运行的 Pod 集合可能与稍后运行该应用程序的 Pod 集合不同。
这导致了一个问题: 如果一组 Pod(称为“后端”)为群集内的其他 Pod(称为“前端”)提供功能, 那么前端如何找出并跟踪要连接的 IP 地址,以便前端可以使用工作量的后端部分?
Kubernetes Service,一个 Pod 的逻辑分组(Endpoint),一种可以访问它们的策略(负载均衡),通常称为微服务,这一组 Pod 能够被 Service 访问(服务发现,支持环境变量和DNS模式),通常是通过 Label Selector。
6.1 配置示例
apiVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: default
spec:
selector: # 指定标签 app:nginx1.19.0 来进行对Pod进行关联(也就是上面Deployment配置里labels定义的标签 )
app: nginx1.19.0
ports:
- protocol: TCP
port: 8085 # 需要暴露的集群端口(service暴露的)
targetPort: 8085 # 容器的端口(后端容器提供服务的端口)
nodePort: 30000 # 映射到物理机的端口(30000-32767),不填则随机映射
type: NodePort
映射到物理机的端口范围为:30000-32767
暴露的端口在Node节点上由kube-proxy来启动并监听的,可通过
kube-proxy是如何代理访问到容器的呢?
因为kube-proxy在启动的时候通过--proxy-mode=ipvs可以指定底层内核代理模式,默认是iptables进行代理转发,kube-proxy通过这两种模式来进行代理转发,kube-proxy通过这两种模式来代理直接对外提供服务。
6.2 服务类型
Service类型:ClusterIP(默认)、NodePort、LoadBalancer、ExternalName
-
ClusterIP
通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部(同namespace内的pod)可以访问,不对外提供访问服务,这也是默认的服务类型。 -
NodePort
通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。 NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。 通过请求: ,可以从集群的外部访问一个 NodePort 服务。 -
LoadBalancer
使用云提供商的负载局衡器,可以向外部暴露服务。 外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务,适用于云平台,AWS默认支持。
6.3 常用命令
kubectl get service -o wide # service可以使用缩写svc,-n指定命名空间,默认default
kubectl describe service nginx-service
6.4 代理模式
userspace模式
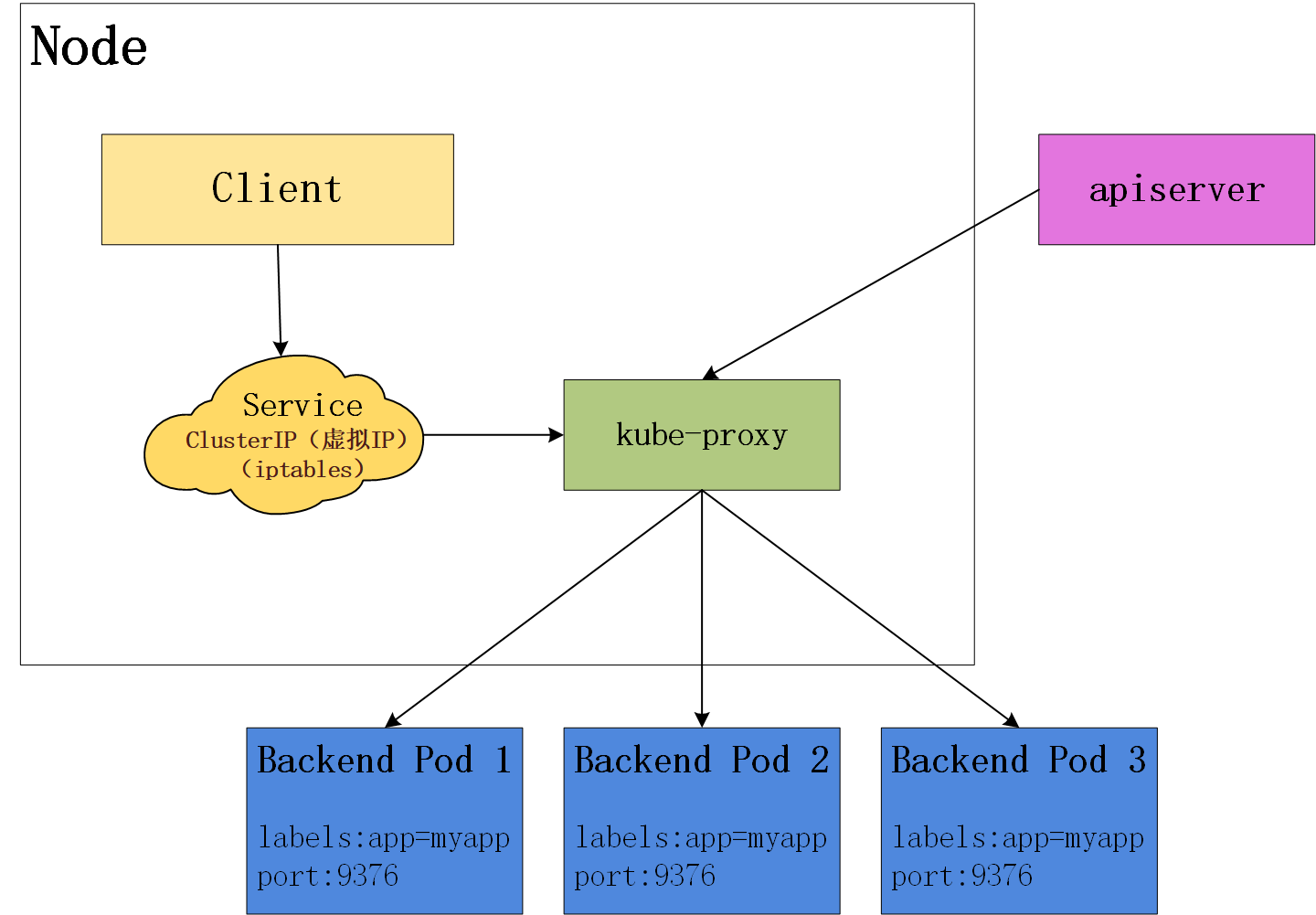
这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会在本地 Node 上打开一个端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的 Backend Pods 中的某个上面(如 Endpoints 所报告的一样)。 使用哪个 Backend Pod,是基于 Service 的 SessionAffinity 来确定的。 最后,它安装 iptables 规则,捕获到达该 Service 的 ClusterIP(虚拟 IP)和 Port 的请求,并重定向到代理端口,代理端口再代理请求到 Backend Pod。
网络返回的结果是,任何到达 Service 的 IP:Port 的请求,都会被代理到一个合适的 backend,不需要客户端知道关于 Kubernetes、Service、或 Pod 的任何信息。
默认的策略是,通过 round-robin 算法来选择 backend Pod。 实现基于客户端 IP 的会话亲和性,可以通过设置 service.spec.sessionAffinity 的值为 "ClientIP" (默认值为 "None")。
iptables模式
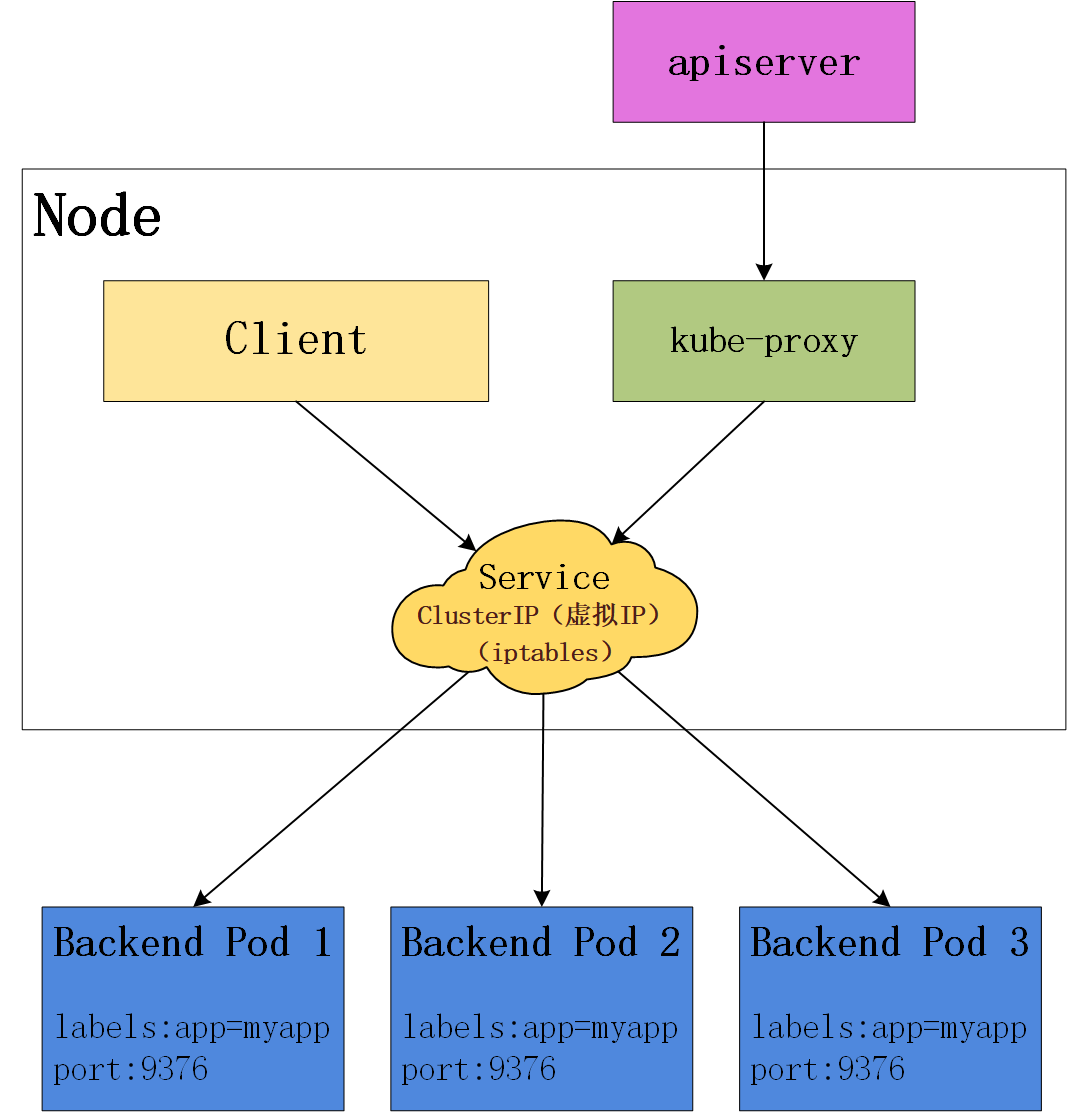
这种模式,kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会安装 iptables 规则,从而捕获到达该 Service 的 ClusterIP(虚拟 IP)和端口的请求,进而将请求重定向到 Service 的一组 Backend Pod 中的某个上面。 对于每个 Endpoints 对象,它也会安装 iptables 规则,这个规则会选择一个 Backend Pod。
默认的策略是,随机选择一个 backend。 实现基于客户端 IP 的会话亲和性,可以将 service.spec.sessionAffinity 的值设置为 "ClientIP" (默认值为 "None")。
和 userspace 代理类似,网络返回的结果是,任何到达 Service 的 IP:Port 的请求,都会被代理到一个合适的 backend,不需要客户端知道关于 Kubernetes、Service、或 Pod 的任何信息。 这应该比 userspace 代理更快、更可靠。然而,不像 userspace 代理,如果初始选择的 Pod 没有响应,iptables 代理能够自动地重试另一个 Pod,所以它需要依赖 readiness probes。
IPVS模式
在 ipvs 模式下,kube-proxy监视Kubernetes服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。 该控制循环可确保IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到一组 Backend Pod 中的某个上面。
IPVS代理模式基于类似于 iptables 模式的 netfilter 挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS提供了更多选项来平衡后端Pod的流量。 提供如下调度算法:
rr: round-robinlc: least connection (smallest number of open connections)dh: destination hashingsh: source hashingsed: shortest expected delaynq: never queue
说明:
要在 IPVS 模式下运行 kube-proxy,必须在启动 kube-proxy 之前使 IPVS Linux 在节点上可用。
当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。
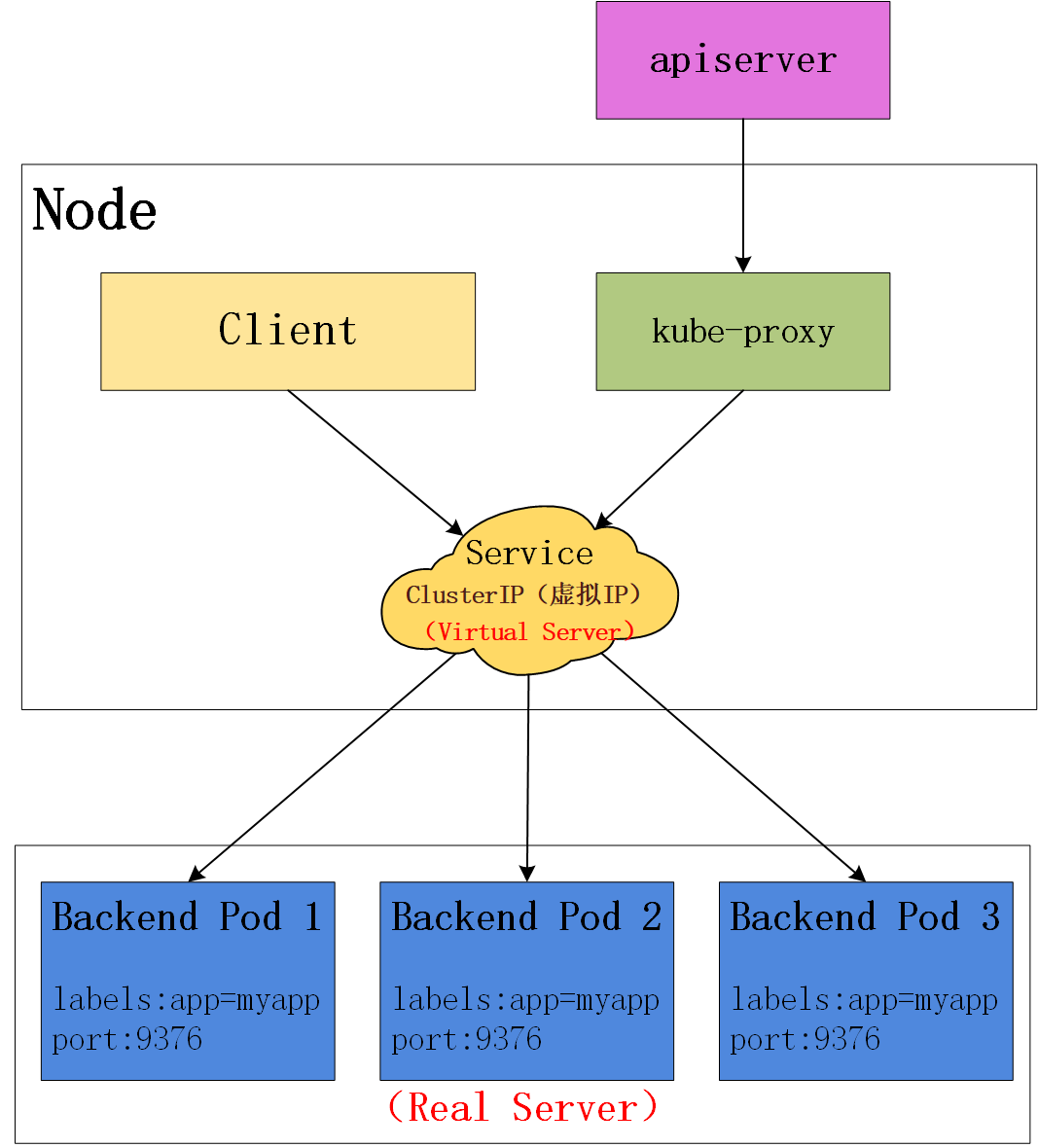
在这些代理模型中,绑定到服务IP的流量: 在客户端不了解Kubernetes或服务或Pod的任何信息的情况下,将Port代理到适当的后端。 如果要确保每次都将来自特定客户端的连接传递到同一 Pod, 则可以通过将 service.spec.sessionAffinity 设置为 "ClientIP" (默认值是 "None"),来基于客户端的 IP 地址选择会话关联。
您还可以通过适当设置 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 来设置最大会话停留时间。 (默认值为 10800 秒,即 3 小时)。
七、Ingress
Ingress公开了从集群外部到集群内服务(Service)的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。
internet
|
[ Ingress ]
--|-----|--
[ Services ]
可以将 Ingress 配置为服务提供外部可访问的 URL、负载均衡流量、终止 SSL/TLS,以及提供基于名称的虚拟主机等能力。 Ingress 控制器 通常负责通过负载均衡器来实现 Ingress,尽管它也可以配置边缘路由器或其他前端来帮助处理流量。
你必须具有 Ingress 控制器才能满足 Ingress 的要求。 仅创建 Ingress 资源本身没有任何效果。
你可能需要部署 Ingress 控制器,例如 ingress-nginx。 你可以从许多 Ingress 控制器 中进行选择。
理想情况下,所有 Ingress 控制器都应符合参考规范。但实际上,不同的 Ingress 控制器操作略有不同。
示例
foo.bar.com -> 192.168.47.131 -> / foo service1:4200
/ bar service2:8080
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ingress-example
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: service1
servicePort: 4200
- path: /bar
backend:
serviceName: service2
servicePort: 8080
八、日志收集
进行中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号