MyBatis 源码分析 - MyBatis初始化(三)之 SQL 初始化(上)
参考 知识星球 中 芋道源码 星球的源码解析,一个活跃度非常高的 Java 技术社群,感兴趣的小伙伴可以加入 芋道源码 星球,一起学习😄
该系列文档是本人在学习 Mybatis 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释(Mybatis源码分析 GitHub 地址、Mybatis-Spring 源码分析 GitHub 地址、Spring-Boot-Starter 源码分析 GitHub 地址)进行阅读
MyBatis 版本:3.5.2
MyBatis-Spring 版本:2.0.3
MyBatis-Spring-Boot-Starter 版本:2.1.4
该系列其他文档请查看:《精尽 MyBatis 源码分析 - 文章导读》
MyBatis的初始化
在MyBatis初始化过程中,大致会有以下几个步骤:
-
创建
Configuration全局配置对象,会往TypeAliasRegistry别名注册中心添加Mybatis需要用到的相关类,并设置默认的语言驱动类为XMLLanguageDriver -
加载
mybatis-config.xml配置文件、Mapper接口中的注解信息和XML映射文件,解析后的配置信息会形成相应的对象并保存到Configuration全局配置对象中 -
构建
DefaultSqlSessionFactory对象,通过它可以创建DefaultSqlSession对象,MyBatis中SqlSession的默认实现类
因为整个初始化过程涉及到的代码比较多,所以拆分成了四个模块依次对MyBatis的初始化进行分析:
- 《MyBatis初始化(一)之加载mybatis-config.xml》
- 《MyBatis初始化(二)之加载Mapper接口与XML映射文件》
- 《MyBatis初始化(三)之SQL初始化(上)》
- 《MyBatis初始化(四)之SQL初始化(下)》
由于在MyBatis的初始化过程中去解析Mapper接口与XML映射文件涉及到的篇幅比较多,XML映射文件的解析过程也比较复杂,所以才分成了后面三个模块,逐步分析,这样便于理解
初始化(三)之SQL初始化(上)
在前面的MyBatis初始化相关文档中已经大致讲完了MyBatis初始化的整个流程,其中遗漏了一部分,就是在解析<select /> <insert /> <update /> <delete />节点的过程中,是如何解析SQL语句,如何实现动态SQL语句,最终会生成一个org.apache.ibatis.mapping.SqlSource对象的,对于这烦琐且易出错的过程,我们来看看MyBatis如何实现的?
我们回顾org.apache.ibatis.builder.xml.XMLStatementBuilder的parseStatementNode()解析 Statement 节点时,通过下面的方法创建对应的SqlSource对象
// 创建对应的 SqlSource 对象,保存了该节点下 SQL 相关信息
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
langDriver是从Configuration全局配置对象中获取的默认实现类,对应的也就是XMLLanguageDriver,在Configuration初始化的时候设置的
public Configuration() {
languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class);
languageRegistry.register(RawLanguageDriver.class);
}
主要包路径:org.apache.ibatis.scripting、org.apache.ibatis.builder、org.apache.ibatis.mapping
主要涉及到的类:
-
org.apache.ibatis.scripting.xmltags.XMLLanguageDriver:语言驱动接口的默认实现,创建ParameterHandler参数处理器对象和SqlSource资源对象 -
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder:继承 BaseBuilder 抽象类,负责将SQL脚本(XML或者注解中定义的SQL语句)解析成SqlSource(DynamicSqlSource或者RawSqlSource)资源对象 -
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.NodeHandler:定义在XMLScriptBuilder内部的一个接口,用于处理MyBatis自定义标签(<if /> <foreach />等),生成对应的SqlNode对象,不同的实现类处理不同的标签 -
org.apache.ibatis.scripting.xmltags.DynamicContext:解析动态SQL语句时的上下文,用于解析SQL时,记录动态SQL处理后的SQL语句,内部提供ContextMap对象保存上下文的参数 -
org.apache.ibatis.scripting.xmltags.SqlNode:SQL Node接口,每个XML Node会解析成对应的SQL Node对象,通过上下文可以对动态SQL进行逻辑处理,生成需要的结果 -
org.apache.ibatis.scripting.xmltags.OgnlCache:用于处理Ognl表达式
语言驱动接口的实现类如下图所示:
LanguageDriver
org.apache.ibatis.scripting.LanguageDriver:语言驱动接口,代码如下:
public interface LanguageDriver {
/**
* Creates a {@link ParameterHandler} that passes the actual parameters to the the JDBC statement.
* 创建 ParameterHandler 对象
*
* @param mappedStatement The mapped statement that is being executed
* @param parameterObject The input parameter object (can be null)
* @param boundSql The resulting SQL once the dynamic language has been executed.
* @return 参数处理器
* @author Frank D. Martinez [mnesarco]
* @see DefaultParameterHandler
*/
ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql);
/**
* Creates an {@link SqlSource} that will hold the statement read from a mapper xml file.
* It is called during startup, when the mapped statement is read from a class or an xml file.
* 创建 SqlSource 对象,从 Mapper XML 配置的 Statement 标签中,即 <select /> 等。
*
* @param configuration The MyBatis configuration
* @param script XNode parsed from a XML file
* @param parameterType input parameter type got from a mapper method or specified in the parameterType xml attribute. Can be null.
* @return SQL 资源
*/
SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType);
/**
* Creates an {@link SqlSource} that will hold the statement read from an annotation.
* It is called during startup, when the mapped statement is read from a class or an xml file.
* 创建 SqlSource 对象,从方法注解配置,即 @Select 等。
*
* @param configuration The MyBatis configuration
* @param script The content of the annotation
* @param parameterType input parameter type got from a mapper method or specified in the parameterType xml attribute. Can be null.
* @return SQL 资源
*/
SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType);
}
定义了三个方法:
-
createParameterHandler:获取 ParameterHandler 参数处理器对象 -
createSqlSource:创建 SqlSource 对象,解析 Mapper XML 配置的 Statement 标签中,即<select /> <update /> <delete /> <insert /> -
createSqlSource:创建 SqlSource 对象,从方法注解配置,即 @Select 等
XMLLanguageDriver
org.apache.ibatis.scripting.xmltags.XMLLanguageDriver:语言驱动接口的默认实现,代码如下:
public class XMLLanguageDriver implements LanguageDriver {
@Override
public ParameterHandler createParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
// 创建 DefaultParameterHandler 对象
return new DefaultParameterHandler(mappedStatement, parameterObject, boundSql);
}
/**
* 用于解析 XML 映射文件中的 SQL
*
* @param configuration The MyBatis configuration
* @param script XNode parsed from a XML file
* @param parameterType input parameter type got from a mapper method or
* specified in the parameterType xml attribute. Can be
* null.
* @return SQL 资源
*/
@Override
public SqlSource createSqlSource(Configuration configuration, XNode script, Class<?> parameterType) {
// 创建 XMLScriptBuilder 对象,执行解析
XMLScriptBuilder builder = new XMLScriptBuilder(configuration, script, parameterType);
return builder.parseScriptNode();
}
/**
* 用于解析注解中的 SQL
*
* @param configuration The MyBatis configuration
* @param script The content of the annotation
* @param parameterType input parameter type got from a mapper method or
* specified in the parameterType xml attribute. Can be
* null.
* @return SQL 资源
*/
@Override
public SqlSource createSqlSource(Configuration configuration, String script, Class<?> parameterType) {
// issue #3
// <1> 如果是 <script> 开头,表示是在注解中使用的动态 SQL
if (script.startsWith("<script>")) {
// <1.1> 创建 XPathParser 对象,解析出 <script /> 节点
XPathParser parser = new XPathParser(script, false, configuration.getVariables(), new XMLMapperEntityResolver());
return createSqlSource(configuration, parser.evalNode("/script"), parameterType);
} else {
// issue #127
// <2.1> 变量替换
script = PropertyParser.parse(script, configuration.getVariables());
// <2.2> 创建 TextSqlNode 对象
TextSqlNode textSqlNode = new TextSqlNode(script);
if (textSqlNode.isDynamic()) { // <2.3.1> 如果是动态 SQL ,则创建 DynamicSqlSource 对象
return new DynamicSqlSource(configuration, textSqlNode);
} else { // <2.3.2> 如果非动态 SQL ,则创建 RawSqlSource 对象
return new RawSqlSource(configuration, script, parameterType);
}
}
}
}
实现了LanguageDriver接口:
-
创建
DefaultParameterHandler默认参数处理器并返回 -
解析 XML 映射文件中的 SQL,通过创建
XMLScriptBuilder对象,调用其parseScriptNode()方法解析 -
解析注解定义的 SQL
- 如果是
<script>开头,表示是在注解中使用的动态 SQL,将其转换成 XNode 然后调用上述方法,不了解的可以看看MyBatis三种动态SQL配置方式 - 先将注解中定义的 SQL 中包含的变量进行转换,然后创建对应的 SqlSource 对象
- 如果是
RawLanguageDriver
org.apache.ibatis.scripting.defaults.RawLanguageDriver:继承了XMLLanguageDriver,在的基础上增加了是否为静态SQL语句的校验,也就是判断创建的 SqlSource 是否为 RawSqlSource 静态 SQL 资源
XMLScriptBuilder
org.apache.ibatis.scripting.xmltags.XMLScriptBuilder:继承 BaseBuilder 抽象类,负责将 SQL 脚本(XML或者注解中定义的 SQL )解析成 SqlSource 对象
构造方法
public class XMLScriptBuilder extends BaseBuilder {
/**
* 当前 SQL 的 XNode 对象
*/
private final XNode context;
/**
* 是否为动态 SQL
*/
private boolean isDynamic;
/**
* SQL 的 Java 入参类型
*/
private final Class<?> parameterType;
/**
* NodeNodeHandler 的映射
*/
private final Map<String, NodeHandler> nodeHandlerMap = new HashMap<>();
public XMLScriptBuilder(Configuration configuration, XNode context) {
this(configuration, context, null);
}
public XMLScriptBuilder(Configuration configuration, XNode context, Class<?> parameterType) {
super(configuration);
this.context = context;
this.parameterType = parameterType;
initNodeHandlerMap();
}
private void initNodeHandlerMap() {
nodeHandlerMap.put("trim", new TrimHandler());
nodeHandlerMap.put("where", new WhereHandler());
nodeHandlerMap.put("set", new SetHandler());
nodeHandlerMap.put("foreach", new ForEachHandler());
nodeHandlerMap.put("if", new IfHandler());
nodeHandlerMap.put("choose", new ChooseHandler());
nodeHandlerMap.put("when", new IfHandler());
nodeHandlerMap.put("otherwise", new OtherwiseHandler());
nodeHandlerMap.put("bind", new BindHandler());
}
}
在构造函数中会初始化 NodeHandler 处理器,分别用于处理不同的MyBatis自定义的XML标签,例如<if /> <where /> <foreach />等标签
parseScriptNode方法
parseScriptNode()方法将 SQL 脚本(XML或者注解中定义的 SQL )解析成 SqlSource 对象,代码如下:
public SqlSource parseScriptNode() {
// 解析 XML 或者注解中定义的 SQL
MixedSqlNode rootSqlNode = parseDynamicTags(context);
SqlSource sqlSource;
if (isDynamic) {
// 动态语句,使用了 ${} 也算
sqlSource = new DynamicSqlSource(configuration, rootSqlNode);
} else {
sqlSource = new RawSqlSource(configuration, rootSqlNode, parameterType);
}
return sqlSource;
}
- 通过调用
parseDynamicTags(XNode node)方法,将解析 SQL 成MixedSqlNode对象,主要是将一整个 SQL 解析成一系列的 SqlNode 对象 - 如果是动态SQL语句,使用了MyBatis自定义的XML标签(
<if />等)或者使用了${},则封装成DynamicSqlSource对象 - 否则就是静态SQL语句,封装成
RawSqlSource对象
parseDynamicTags方法
parseDynamicTags()将 SQL 脚本(XML或者注解中定义的 SQL )解析成MixedSqlNode对象,代码如下:
protected MixedSqlNode parseDynamicTags(XNode node) {
// <1> 创建 SqlNode 数组
List<SqlNode> contents = new ArrayList<>();
/*
* <2> 遍历 SQL 节点中所有子节点
* 这里会对该节点内的所有内容进行处理然后返回 NodeList 对象
* 1. 文本内容会被解析成 '<#text></#text>' 节点,就算一个换行符也会解析成这个
* 2. <![CDATA[ content ]]> 会被解析成 '<#cdata-section>content</#cdata-section>' 节点
* 3. 其他动态<if /> <where />
*/
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
// 当前子节点
XNode child = node.newXNode(children.item(i));
// <2.1> 如果类型是 Node.CDATA_SECTION_NODE 或者 Node.TEXT_NODE 时
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE // <![CDATA[ ]]>节点
|| child.getNode().getNodeType() == Node.TEXT_NODE) { // 纯文本
// <2.1.1> 获得内容
String data = child.getStringBody("");
// <2.1.2> 创建 TextSqlNode 对象
TextSqlNode textSqlNode = new TextSqlNode(data);
if (textSqlNode.isDynamic()) { // <2.1.2.1> 如果是动态的 TextSqlNode 对象,也就是使用了 '${}'
// 添加到 contents 中
contents.add(textSqlNode);
// 标记为动态 SQL
isDynamic = true;
} else { // <2.1.2.2> 如果是非动态的 TextSqlNode 对象,没有使用 '${}'
// <2.1.2> 创建 StaticTextSqlNode 添加到 contents 中
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628 <2.2> 如果类型是 Node.ELEMENT_NODE
// <2.2.1> 根据子节点的标签,获得对应的 NodeHandler 对象
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler == null) { // 获得不到,说明是未知的标签,抛出 BuilderException 异常
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
// <2.2.2> 执行 NodeHandler 处理
handler.handleNode(child, contents);
// <2.2.3> 标记为动态 SQL
isDynamic = true;
}
}
// <3> 创建 MixedSqlNode 对象
return new MixedSqlNode(contents);
}
<1> 创建 SqlNode 数组 contents,用于保存解析 SQL 后的一些列 SqlNode 对象
<2> 获取定义的 SQL 节点中所有子节点,返回一个 NodeList 对象,这个对象中包含了该 SQL 节点内的所有信息,然后逐个遍历子节点
1. 其中文本内容会被解析成`<#text></#text>`节点,就算一个换行符也会解析成这个
2. `<![CDATA[ ]]>` 会被解析成 `<#cdata-section></#cdata-section>` 节点
3. 还有其他MyBatis自定义的标签`<if /> <where />`等等
<2.1> 如果子节点是<#text />或者<#cdata-section />类型
<2.1.1> 获取子节点的文本内容
<2.1.2> 创建 TextSqlNode 对象
<2.1.2.1> 调用 TextSqlNode 的 isDynamic() 方法,点击去该进去看看就知道了,如果文本中使用了${},则标记为动态 SQL 语句,将其添加至 contents 数组中
<2.1.2.2> 否则就是静态文本内容,创建对应的 StaticTextSqlNode 对象,将其添加至 contents 数组中
<2.2> 如果类型是 Node.ELEMENT_NODE 时,也就是 MyBatis 的自定义标签
<2.2.1> 根据子节点的标签名称,获得对应的 NodeHandler 对象
<2.2.2> 执行NodeHandler的handleNode方法处理该节点,创建不通类型的 SqlNode 并添加到 contents 数组中,如何处理的在下面讲述
<2.2.3> 标记为动态 SQL 语句
<3> 最后将创建 contents 封装成 MixedSqlNode 对象
NodeHandler
XMLScriptBuilder的内部接口,用于处理MyBatis自定义标签,接口实现类如下图所示:

代码如下:
private interface NodeHandler {
/**
* 处理 Node
*
* @param nodeToHandle 要处理的 XNode 节点
* @param targetContents 目标的 SqlNode 数组。实际上,被处理的 XNode 节点会创建成对应的 SqlNode 对象,添加到 targetContents 中
*/
void handleNode(XNode nodeToHandle, List<SqlNode> targetContents);
}
这些 NodeHandler 实现类都定义在 XMLScriptBuilder 内部,用于处理不同标签,我们逐个来看
BindHandler
实现了NodeHandler接口,<bind />标签的处理器,代码如下:
/**
* <bind />元素允许你在 OGNL 表达式(SQL语句)以外创建一个变量,并将其绑定到当前的上下文
*/
private class BindHandler implements NodeHandler {
public BindHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析 name、value 属性
final String name = nodeToHandle.getStringAttribute("name");
final String expression = nodeToHandle.getStringAttribute("value");
// 创建 VarDeclSqlNode 对象
final VarDeclSqlNode node = new VarDeclSqlNode(name, expression);
targetContents.add(node);
}
}
-
获取
<bind />标签的name和value属性 -
根据这些属性创建一个
VarDeclSqlNode对象 -
添加到
targetContents集合中
例如这样配置:
<select id="selectBlogsLike" resultType="Blog">
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG
WHERE title LIKE #{pattern}
</select>
TrimHandler
实现了NodeHandler接口,<trim />标签的处理器,代码如下:
private class TrimHandler implements NodeHandler {
public TrimHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// <1> 解析内部的 SQL 节点,成 MixedSqlNode 对象
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// <2> 获得 prefix、prefixOverrides、"suffix"、suffixOverrides 属性
String prefix = nodeToHandle.getStringAttribute("prefix");
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
String suffix = nodeToHandle.getStringAttribute("suffix");
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
// <3> 创建 TrimSqlNode 对象
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}
-
继续调用
parseDynamicTags方法解析<if />标签内部的子标签节点,嵌套解析,生成MixedSqlNode对象 -
获得
prefix、prefixOverrides、suffix、suffixOverrides属性 -
根据上面获取到的属性创建
TrimSqlNode对象 -
添加到
targetContents集合中
WhereHandler
实现了NodeHandler接口,<where />标签的处理器,代码如下:
private class WhereHandler implements NodeHandler {
public WhereHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析内部的 SQL 节点,成 MixedSqlNode 对象
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 创建 WhereSqlNode 对象
WhereSqlNode where = new WhereSqlNode(configuration, mixedSqlNode);
targetContents.add(where);
}
}
- 继续调用
parseDynamicTags方法解析<where />标签内部的子标签节点,嵌套解析,生成MixedSqlNode对象 - 创建
WhereSqlNode对象,该对象继承了TrimSqlNode,自定义前缀(WHERE)和需要删除的前缀(AND、OR等) - 添加到
targetContents集合中
SetHandler
实现了NodeHandler接口,<set />标签的处理器,代码如下:
private class SetHandler implements NodeHandler {
public SetHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析内部的 SQL 节点,成 MixedSqlNode 对象
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
SetSqlNode set = new SetSqlNode(configuration, mixedSqlNode);
targetContents.add(set);
}
}
- 继续调用
parseDynamicTags方法解析<set />标签内部的子标签节点,嵌套解析,生成MixedSqlNode对象 - 创建
SetSqlNode对象,该对象继承了TrimSqlNode,自定义前缀(SET)和需要删除的前缀和后缀(,) - 添加到
targetContents集合中
ForEachHandler
实现了NodeHandler接口,<foreach />标签的处理器,代码如下:
private class ForEachHandler implements NodeHandler {
public ForEachHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析内部的 SQL 节点,成 MixedSqlNode 对象
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 获得 collection、item、index、open、close、separator 属性
String collection = nodeToHandle.getStringAttribute("collection");
String item = nodeToHandle.getStringAttribute("item");
String index = nodeToHandle.getStringAttribute("index");
String open = nodeToHandle.getStringAttribute("open");
String close = nodeToHandle.getStringAttribute("close");
String separator = nodeToHandle.getStringAttribute("separator");
// 创建 ForEachSqlNode 对象
ForEachSqlNode forEachSqlNode = new ForEachSqlNode(configuration, mixedSqlNode, collection, index, item, open, close, separator);
targetContents.add(forEachSqlNode);
}
}
- 继续调用
parseDynamicTags方法解析<foreach />标签内部的子标签节点,嵌套解析,生成MixedSqlNode对象 - 获得 collection、item、index、open、close、separator 属性
- 根据这些属性创建
ForEachSqlNode对象 - 添加到
targetContents集合中
IfHandler
实现了NodeHandler接口,<if />标签的处理器,代码如下:
private class IfHandler implements NodeHandler {
public IfHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析内部的 SQL 节点,成 MixedSqlNode 对象
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
// 获得 test 属性
String test = nodeToHandle.getStringAttribute("test");
// 创建 IfSqlNode 对象
IfSqlNode ifSqlNode = new IfSqlNode(mixedSqlNode, test);
targetContents.add(ifSqlNode);
}
}
- 继续调用
parseDynamicTags方法解析<if />标签内部的子标签节点,嵌套解析,生成MixedSqlNode对象 - 获得 test 属性
- 根据这个属性创建
IfSqlNode对象 - 添加到
targetContents集合中
OtherwiseHandler
实现了NodeHandler接口,<otherwise />标签的处理器,代码如下:
private class OtherwiseHandler implements NodeHandler {
public OtherwiseHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
// 解析内部的 SQL 节点,成 MixedSqlNode 对象
MixedSqlNode mixedSqlNode = parseDynamicTags(nodeToHandle);
targetContents.add(mixedSqlNode);
}
}
- 继续调用
parseDynamicTags方法解析<otherwise />标签内部的子标签节点,嵌套解析,生成MixedSqlNode对象 - 添加到
targetContents集合中,需要结合ChooseHandler使用
ChooseHandler
实现了NodeHandler接口,<choose />标签的处理器,代码如下:
private class ChooseHandler implements NodeHandler {
public ChooseHandler() {
// Prevent Synthetic Access
}
@Override
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
List<SqlNode> whenSqlNodes = new ArrayList<>();
List<SqlNode> otherwiseSqlNodes = new ArrayList<>();
// 解析 `<when />` 和 `<otherwise />` 的节点们
handleWhenOtherwiseNodes(nodeToHandle, whenSqlNodes, otherwiseSqlNodes);
// 获得 `<otherwise />` 的节点,存在多个会抛出异常
SqlNode defaultSqlNode = getDefaultSqlNode(otherwiseSqlNodes);
// 创建 ChooseSqlNode 对象
ChooseSqlNode chooseSqlNode = new ChooseSqlNode(whenSqlNodes, defaultSqlNode);
targetContents.add(chooseSqlNode);
}
private void handleWhenOtherwiseNodes(XNode chooseSqlNode, List<SqlNode> ifSqlNodes,
List<SqlNode> defaultSqlNodes) {
List<XNode> children = chooseSqlNode.getChildren();
for (XNode child : children) {
String nodeName = child.getNode().getNodeName();
NodeHandler handler = nodeHandlerMap.get(nodeName);
if (handler instanceof IfHandler) { // 处理 `<when />` 标签的情况
handler.handleNode(child, ifSqlNodes);
} else if (handler instanceof OtherwiseHandler) { // 处理 `<otherwise />` 标签的情况
handler.handleNode(child, defaultSqlNodes);
}
}
}
private SqlNode getDefaultSqlNode(List<SqlNode> defaultSqlNodes) {
SqlNode defaultSqlNode = null;
if (defaultSqlNodes.size() == 1) {
defaultSqlNode = defaultSqlNodes.get(0);
} else if (defaultSqlNodes.size() > 1) {
throw new BuilderException("Too many default (otherwise) elements in choose statement.");
}
return defaultSqlNode;
}
}
-
先逐步处理
<choose />标签的<when />和<otherwise />子标签们,通过组合 IfHandler 和 OtherwiseHandler 两个处理器,实现对子节点们的解析 -
如果存在
<otherwise />子标签,则抛出异常 -
根据这些属性创建
ChooseSqlNode对象 -
添加到
targetContents集合中
DynamicContext
org.apache.ibatis.scripting.xmltags.DynamicContext:解析动态SQL语句时的上下文,用于解析SQL时,记录动态SQL处理后的SQL语句,内部提供ContextMap对象保存上下文的参数
构造方法
public class DynamicContext {
/**
* 入参保存在 ContextMap 中的 Key
*
* {@link #bindings}
*/
public static final String PARAMETER_OBJECT_KEY = "_parameter";
/**
* 数据库编号保存在 ContextMap 中的 Key
*
* {@link #bindings}
*/
public static final String DATABASE_ID_KEY = "_databaseId";
static {
// <1.2> 设置 OGNL 的属性访问器
OgnlRuntime.setPropertyAccessor(ContextMap.class, new ContextAccessor());
}
/**
* 上下文的参数集合,包含附加参数(通过`<bind />`标签生成的,或者`<foreach />`标签中的集合的元素等等)
*/
private final ContextMap bindings;
/**
* 生成后的 SQL
*/
private final StringJoiner sqlBuilder = new StringJoiner(" ");
/**
* 唯一编号。在 {@link org.apache.ibatis.scripting.xmltags.XMLScriptBuilder.ForEachHandler} 使用
*/
private int uniqueNumber = 0;
public DynamicContext(Configuration configuration, Object parameterObject) {
// <1> 初始化 bindings 参数
if (parameterObject != null && !(parameterObject instanceof Map)) {
// 构建入参的 MetaObject 对象
MetaObject metaObject = configuration.newMetaObject(parameterObject);
// 入参类型是否有对应的类型处理器
boolean existsTypeHandler = configuration.getTypeHandlerRegistry().hasTypeHandler(parameterObject.getClass());
bindings = new ContextMap(metaObject, existsTypeHandler);
} else {
bindings = new ContextMap(null, false);
}
// <2> 添加 bindings 的默认值
bindings.put(PARAMETER_OBJECT_KEY, parameterObject);
bindings.put(DATABASE_ID_KEY, configuration.getDatabaseId());
}
}
| 类型 | 属性 | 说明 |
|---|---|---|
| ContextMap | bindings | 上下文的参数集合,包含附加参数(通过<bind />标签生成的,或者<foreach />标签解析参数保存的),以及几个默认值 |
| StringJoiner | sqlBuilder | 保存本次解析后的SQL,每次添加字符串以空格作为分隔符 |
| int | uniqueNumber | 唯一编号,在ForEachHandler处理节点时需要用到,生成唯一数组作为集合中每个元素的索引(作为后缀) |
- 初始化
bindings参数,创建 ContextMap 对象- 根据入参转换成MetaObject对象
- 在静态代码块中,设置OGNL的属性访问器,OgnlRuntime 是
OGNL库中的类,设置ContextMap对应的访问器是ContextAccessor类
- 往
bindings中添加几个默认值:_parameter> 入参对象,_databaseId-> 数据库标识符
ContextMap
DynamicContext的内部静态类,继承HashMap,用于保存解析动态SQL语句时的上下文的参数集合,代码如下:
static class ContextMap extends HashMap<String, Object> {
private static final long serialVersionUID = 2977601501966151582L;
/**
* parameter 对应的 MetaObject 对象
*/
private final MetaObject parameterMetaObject;
/**
* 是否有对应的类型处理器
*/
private final boolean fallbackParameterObject;
public ContextMap(MetaObject parameterMetaObject, boolean fallbackParameterObject) {
this.parameterMetaObject = parameterMetaObject;
this.fallbackParameterObject = fallbackParameterObject;
}
@Override
public Object get(Object key) {
String strKey = (String) key;
if (super.containsKey(strKey)) {
return super.get(strKey);
}
if (parameterMetaObject == null) {
return null;
}
if (fallbackParameterObject && !parameterMetaObject.hasGetter(strKey)) {
return parameterMetaObject.getOriginalObject();
} else {
// issue #61 do not modify the context when reading
return parameterMetaObject.getValue(strKey);
}
}
}
重写了 HashMap 的 get(Object key) 方法,增加支持对 parameterMetaObject 属性的访问
ContextAccessor
DynamicContext的内部静态类,实现 ognl.PropertyAccessor 接口,上下文访问器,代码如下:
static class ContextAccessor implements PropertyAccessor {
@Override
public Object getProperty(Map context, Object target, Object name) {
Map map = (Map) target;
// 优先从 ContextMap 中,获得属性
Object result = map.get(name);
if (map.containsKey(name) || result != null) {
return result;
}
// <x> 如果没有,则从 PARAMETER_OBJECT_KEY 对应的 Map 中,获得属性
Object parameterObject = map.get(PARAMETER_OBJECT_KEY);
if (parameterObject instanceof Map) {
return ((Map) parameterObject).get(name);
}
return null;
}
@Override
public void setProperty(Map context, Object target, Object name, Object value) {
Map<Object, Object> map = (Map<Object, Object>) target;
map.put(name, value);
}
@Override
public String getSourceAccessor(OgnlContext arg0, Object arg1, Object arg2) {
return null;
}
@Override
public String getSourceSetter(OgnlContext arg0, Object arg1, Object arg2) {
return null;
}
}
在DynamicContext的静态代码块中,设置OGNL的属性访问器,设置了ContextMap.class的属性访问器为ContextAccessor
这里方法的入参中的target,就是 ContextMap 对象
-
在重写的
getProperty方法中,先从 ContextMap 里面获取属性值(可以回过去看下ContextMap的get方法) -
没有获取到则获取
PARAMETER_OBJECT_KEY属性的值,如果是 Map 类型,则从这里面获取属性值
回看 DynamicContext 的构造方法,细品一下😄😄😄,先从Map中获取属性值,没有获取到则从parameterObject入参对象中获取属性值
SqlNode
org.apache.ibatis.scripting.xmltags.SqlNode:SQL Node接口,每个XML Node会解析成对应的SQL Node对象,通过上下文可以对动态SQL进行逻辑处理,生成需要的结果
实现类如下图所示:
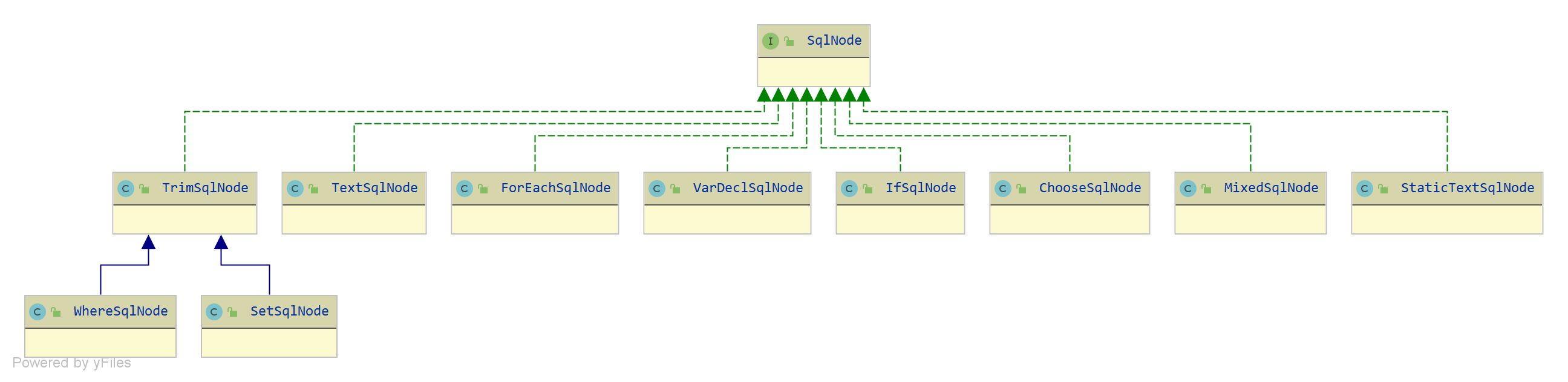
代码如下:
public interface SqlNode {
/**
* 应用当前 SQLNode 节点
*
* @param context 正在解析 SQL 语句的上下文
* @return 是否应用成功
*/
boolean apply(DynamicContext context);
}
因为在解析SQL语句的时候我们需要根据入参来处理不同的SqlNode,通过其apply(DynamicContext context)方法应用SqlNode节点,将节点转换成相应的SQL
我们来看看它的实现类是如何处理相应的SQL Node的
VarDeclSqlNode
org.apache.ibatis.scripting.xmltags.VarDeclSqlNode:实现 SqlNode 接口,<bind /> 标签对应的 SqlNode 实现类,代码如下:
public class VarDeclSqlNode implements SqlNode {
/**
* 变量名称
*/
private final String name;
/**
* 表达式
*/
private final String expression;
public VarDeclSqlNode(String var, String exp) {
name = var;
expression = exp;
}
@Override
public boolean apply(DynamicContext context) {
// 获取该表达式转换后结果
final Object value = OgnlCache.getValue(expression, context.getBindings());
// 将该结果与变量名称设置到解析 SQL 语句的上下文中,这样接下来的解析过程中可以获取到 name 的值
context.bind(name, value);
return true;
}
}
-
通过
OGNL表达式expression从DynamicContext上下文的ContextMap中获取转换后的结果,OgnlCache在后面讲到 -
将
name与转换后的结果绑定到DynamicContext上下文中,后续处理其他节点可以获取到
TrimSqlNode
org.apache.ibatis.scripting.xmltags.TrimSqlNode:实现 SqlNode 接口,<trim/> 标签对应的 SqlNode 实现类
构造方法
public class TrimSqlNode implements SqlNode {
/**
* MixedSqlNode,包含该<if />节点内所有信息
*/
private final SqlNode contents;
/**
* 前缀,行首添加
*/
private final String prefix;
/**
* 后缀,行尾添加
*/
private final String suffix;
/**
* 需要删除的前缀,例如这样定义:'AND|OR'
* 注意空格,这里是不会去除的
*/
private final List<String> prefixesToOverride;
/**
* 需要删除的后缀,例如我们这样定义:',|AND'
* 注意空格,这里是不会去除的
*/
private final List<String> suffixesToOverride;
private final Configuration configuration;
public TrimSqlNode(Configuration configuration, SqlNode contents, String prefix, String prefixesToOverride,
String suffix, String suffixesToOverride) {
this(configuration, contents, prefix, parseOverrides(prefixesToOverride), suffix, parseOverrides(suffixesToOverride));
}
protected TrimSqlNode(Configuration configuration, SqlNode contents, String prefix, List<String> prefixesToOverride,
String suffix, List<String> suffixesToOverride) {
this.contents = contents;
this.prefix = prefix;
this.prefixesToOverride = prefixesToOverride;
this.suffix = suffix;
this.suffixesToOverride = suffixesToOverride;
this.configuration = configuration;
}
}
在构造方法中解析<trim />标签的属性,其中调用了parseOverrides方法将|作为分隔符分隔该字符串并全部大写,生成一个数组,相关属性可查看上面的注释
apply方法
@Override
public boolean apply(DynamicContext context) {
// <1> 创建 FilteredDynamicContext 对象
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
// <2> 先解析 <trim /> 节点中的内容,将生成的 SQL 先存放在 FilteredDynamicContext 中
boolean result = contents.apply(filteredDynamicContext);
/*
* <3> 执行 FilteredDynamicContext 的应用
* 对上一步解析到的内容进行处理
* 处理完成后再将处理后的 SQL 拼接到 DynamicContext 中
*/
filteredDynamicContext.applyAll();
return result;
}
-
通过装饰器模式将
context装饰成FilteredDynamicContext对象 -
因为
<trim />标签中定义了内容或者其他标签,都会解析成相应的SqlNode,保存在contents中(MixedSqlNode)所以这里需要先应用内部的SqlNode,转换后的SQL会先保存在FilteredDynamicContext中
-
对
FilteredDynamicContext中的SQL进行处理,也就是添加前后缀,去除前后缀的处理逻辑,然后将处理后的SQL拼接到context中
FilteredDynamicContext
TrimSqlNode的私有内部类,继承了DynamicContext类,对<trim />标签逻辑的实现,代码如下:
private class FilteredDynamicContext extends DynamicContext {
/**
* 装饰的 DynamicContext 对象
*/
private DynamicContext delegate;
/**
* 是否 prefix 已经被应用
*/
private boolean prefixApplied;
/**
* 是否 suffix 已经被应用
*/
private boolean suffixApplied;
/**
* StringBuilder 对象
*
* @see #appendSql(String)
*/
private StringBuilder sqlBuffer;
public FilteredDynamicContext(DynamicContext delegate) {
super(configuration, null);
this.delegate = delegate;
this.prefixApplied = false;
this.suffixApplied = false;
this.sqlBuffer = new StringBuilder();
}
public void applyAll() {
// <1> 去除前后多余的空格,生成新的 sqlBuffer 对象
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
// <2> 全部大写
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
// <3> 应用 TrimSqlNode 的 trim 逻辑
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
@Override
public Map<String, Object> getBindings() {
return delegate.getBindings();
}
@Override
public void bind(String name, Object value) {
delegate.bind(name, value);
}
@Override
public int getUniqueNumber() {
return delegate.getUniqueNumber();
}
@Override
public void appendSql(String sql) {
sqlBuffer.append(sql);
}
@Override
public String getSql() {
return delegate.getSql();
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
// prefixesToOverride 非空,先删除
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
// prefix 非空,再添加
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
private void applySuffix(StringBuilder sql, String trimmedUppercaseSql) {
if (!suffixApplied) {
suffixApplied = true;
// suffixesToOverride 非空,先删除
if (suffixesToOverride != null) {
for (String toRemove : suffixesToOverride) {
if (trimmedUppercaseSql.endsWith(toRemove) || trimmedUppercaseSql.endsWith(toRemove.trim())) {
int start = sql.length() - toRemove.trim().length();
int end = sql.length();
sql.delete(start, end);
break;
}
}
}
// suffix 非空,再添加
if (suffix != null) {
sql.append(" ");
sql.append(suffix);
}
}
}
}
逻辑并不复杂,大家可以看下
WhereSqlNode
org.apache.ibatis.scripting.xmltags.WhereSqlNode:继承了TrimSqlNode类,<where /> 标签对应的 SqlNode 实现类,代码如下:
public class WhereSqlNode extends TrimSqlNode {
/**
* 也是通过 TrimSqlNode ,这里定义需要删除的前缀
*/
private static List<String> prefixList = Arrays.asList("AND ", "OR ", "AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
// 设置前缀和需要删除的前缀
super(configuration, contents, "WHERE", prefixList, null, null);
}
}
基于TrimSqlNode类,定义了需要添加的前缀为WHERE和需要删除的前缀AND和OR
SetSqlNode
org.apache.ibatis.scripting.xmltags.SetSqlNode:继承了TrimSqlNode类,<set /> 标签对应的 SqlNode 实现类,代码如下:
public class SetSqlNode extends TrimSqlNode {
/**
* 也是通过 TrimSqlNode ,这里定义需要删除的前缀
*/
private static final List<String> COMMA = Collections.singletonList(",");
public SetSqlNode(Configuration configuration,SqlNode contents) {
// 设置前缀、需要删除的前缀和后缀
super(configuration, contents, "SET", COMMA, null, COMMA);
}
}
基于TrimSqlNode类,定义了需要添加的前缀为SET、需要删除的前缀,和需要删除的后缀,
ForeachNode
org.apache.ibatis.scripting.xmltags.ForeachNode:实现 SqlNode 接口,<foreach /> 标签对应的 SqlNode 实现类
其中apply(DynamicContext context)方法的处理逻辑饶了我半天,大家可以仔细看一下
构造方法
public class ForEachSqlNode implements SqlNode {
/**
* 集合中元素绑定到上下文中 key 的前缀
*/
public static final String ITEM_PREFIX = "__frch_";
/**
* 表达式计算器
*/
private final ExpressionEvaluator evaluator;
/**
* 需要遍历的集合类型,支持:list set map array
*/
private final String collectionExpression;
/**
* MixedSqlNode,包含该<where />节点内所有信息
*/
private final SqlNode contents;
/**
* 开头
*/
private final String open;
/**
* 结尾
*/
private final String close;
/**
* 每个元素以什么分隔
*/
private final String separator;
/**
* 集合中每个元素的值
*/
private final String item;
/**
* 集合中每个元素的索引
*/
private final String index;
private final Configuration configuration;
public ForEachSqlNode(Configuration configuration, SqlNode contents, String collectionExpression, String index,
String item, String open, String close, String separator) {
this.evaluator = new ExpressionEvaluator();
this.collectionExpression = collectionExpression;
this.contents = contents;
this.open = open;
this.close = close;
this.separator = separator;
this.index = index;
this.item = item;
this.configuration = configuration;
}
}
对每个属性进行赋值,参考每个属性上面的注释
apply方法
@Override
public boolean apply(DynamicContext context) {
// 获取入参
Map<String, Object> bindings = context.getBindings();
/*
* <1> 获得遍历的集合的 Iterable 对象,用于遍历
* 例如配置了 collection 为以下类型
* list:则从入参中获取到 List 集合类型的属性的值
* array:则从入参中获取到 Array 数组类型的属性的值,会转换成 ArrayList
* map:则从入参中获取到 Map 集合类型的属性的值
*/
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
if (!iterable.iterator().hasNext()) {
// 集合中没有元素则无需遍历
return true;
}
boolean first = true;
// <2> 添加 open 到 SQL 中
applyOpen(context);
int i = 0;
for (Object o : iterable) {
// <3> 记录原始的 context 对象,下面通过两个装饰器对他进行操作
DynamicContext oldContext = context;
// <4> 生成一个 context 装饰器
if (first || separator == null) {
context = new PrefixedContext(context, "");
} else {
// 设置其需要添加的前缀为分隔符
context = new PrefixedContext(context, separator);
}
// <5> 生成一个唯一索引值
int uniqueNumber = context.getUniqueNumber();
// Issue #709
// <6> 绑定到 context 中
if (o instanceof Map.Entry) {
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
/*
* 和下面同理,只不过索引是 Map 的 key
*/
applyIndex(context, mapEntry.getKey(), uniqueNumber);
applyItem(context, mapEntry.getValue(), uniqueNumber);
} else {
/*
* 绑定当前集合中当前元素的索引到当前解析 SQL 语句的上下文中
*
* 1. 'index' -> i
*
* 2. __frch_'index'_uniqueNumber -> i
*/
applyIndex(context, i, uniqueNumber);
/*
* 绑定集合中当前元素的值到当前解析 SQL 语句的上下文中
*
* 1. 'item' -> o
*
* 2. __frch_'item'_uniqueNumber -> o
*
*/
applyItem(context, o, uniqueNumber);
}
/*
* 再装饰一下 PrefixedContext -> FilteredDynamicContext
*
* 前者进行前缀的添加,第一个元素添加后设置为已添加标记,后续不在添加
* 后者将<foreach />标签内的"#{item}"或者"#{index}"替换成上面我们已经绑定的数据:"#{__frch_'item'_uniqueNumber}"或者"#{__frch_'index'_uniqueNumber}"
*
* <7> 进行转换,将<foreach />标签内部定义的内容进行转换
*/
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
if (first) { // <8> 判断 prefix 是否已经插入
first = !((PrefixedContext) context).isPrefixApplied();
}
// <9> 恢复原始的 context 对象,因为目前 context 是装饰器
context = oldContext;
i++;
}
// <10> 添加 close 到 SQL 中
applyClose(context);
// <11> 移除 index 和 item 对应的绑定
context.getBindings().remove(item);
context.getBindings().remove(index);
return true;
}
private void applyIndex(DynamicContext context, Object o, int i) {
if (index != null) {
context.bind(index, o);
context.bind(itemizeItem(index, i), o);
}
}
private void applyItem(DynamicContext context, Object o, int i) {
if (item != null) {
context.bind(item, o);
context.bind(itemizeItem(item, i), o);
}
}
private void applyOpen(DynamicContext context) {
if (open != null) {
context.appendSql(open);
}
}
private void applyClose(DynamicContext context) {
if (close != null) {
context.appendSql(close);
}
}
private static String itemizeItem(String item, int i) {
return ITEM_PREFIX + item + "_" + i;
}
-
获得需要遍历的集合 Iterable 对象,调用
ExpressionEvaluator的evaluateIterable(String expression, Object parameterObject)方法,根据表达式从参数中获取集合对象- 先通过
OgnlCache根据Ognl表达式从上下文的ContextMap中获取转换后的结果,OgnlCache在后面会讲到 - 如果是Array数组类型,则转换成ArrayList集合后返回
- 如果是Map类型,则调用Map.Entry的集合
- 先通过
-
如果定义了
open属性,则先拼接到SQL中 -
开始遍历集合 Iterable 对象,先记录
context原始对象为oldContext,因为接下来需要对其进行两次装饰,而这里会再次进入 -
创建一个
PrefixedContext对象,装饰context,主要是对集合中的每个元素添加separator分隔符 -
生成一个唯一索引值,也就是DynamicContext的
uniqueNumber++,这样集合中每个元素都有一个唯一索引了 -
将集合中的当前元素绑定到上下文中,会保存以下信息:
applyIndex:如果配置了index属性,则将当前元素的索引值绑定到上下文的ContextMap中,保存两个数据:-
'index'-> i,其中'index'就是我们在<foreach />标签中配置的index属性,i就是当前元素在集合中的索引 -
__frch_'index'_uniqueNumber-> i
applyItem:如果配置了item属性,则将当前元素绑定到上下文的ContextMap中,保存两个数据:'item'-> o,其中'item'就是我们在<foreach />标签中配置的item属性,o就是当前元素对象__frch_'item'_uniqueNumber-> o
-
-
再将
PrefixedContext对象装饰成FilteredDynamicContext对象然后应用
<foreach />标签内部的SqlNode节点们主要是替换我们在
<foreach />标签中定义的内容,替换成上面第6步绑定的数据的key值,这样就可以获取到该key对应的value了例如:将
<foreach />标签内的#{item}或者#{index}替换成第6步已经绑定的数据的key值#{__frch_'item'_uniqueNumber}或者#{__frch_'index'_uniqueNumber},然后拼接到SQL中 -
判断是否添加了
open前缀,添加了则遍历时不用再添加前缀 -
恢复原始的
oldContext对象,因为目前context是装饰器,然后继续遍历 -
如果定义了
close属性,则拼接到SQL中 -
从上下文的ContextMap中移除第
6步绑定的第1条数据
第6步中,如果是Map类型,i对应的就是key值,o对应的就是value值,为什么两个方法都需要保存第1条数据?
因为<foreach />标签中可能还有其他的标签,例如<if />标签,它的判断条件中可能需要用到当前元素或者索引值,而表达式中使用了'index'或者'item',那么就需要从上下文中获取到对应的值了
那么接下来我们来看看内部定义的两个类:PrefixedContext和FilteredDynamicContext
PrefixedContext
ForeachNode的内部类,继承了DynamicContext,用于应用<foreach />标签时添加分隔符
重写了appendSql方法,逻辑比较简单,判断是否需要添加分隔符,代码如下:
private class PrefixedContext extends DynamicContext {
/**
* 装饰的 DynamicContext 对象
*/
private final DynamicContext delegate;
/**
* 需要添加的前缀
*/
private final String prefix;
/**
* 是否已经添加
*/
private boolean prefixApplied;
public PrefixedContext(DynamicContext delegate, String prefix) {
super(configuration, null);
this.delegate = delegate;
this.prefix = prefix;
this.prefixApplied = false;
}
public boolean isPrefixApplied() {
return prefixApplied;
}
@Override
public Map<String, Object> getBindings() {
return delegate.getBindings();
}
@Override
public void bind(String name, Object value) {
delegate.bind(name, value);
}
@Override
public void appendSql(String sql) {
if (!prefixApplied && sql != null && sql.trim().length() > 0) {
delegate.appendSql(prefix);
prefixApplied = true;
}
delegate.appendSql(sql);
}
@Override
public String getSql() {
return delegate.getSql();
}
@Override
public int getUniqueNumber() {
return delegate.getUniqueNumber();
}
}
FilteredDynamicContext
ForeachNode的私有静态内部类,继承了DynamicContext,用于应用<foreach />标签时替换内部的#{item}或者#{index},
重写了appendSql方法,代码如下:
private static class FilteredDynamicContext extends DynamicContext {
/**
* 装饰的对象
*/
private final DynamicContext delegate;
/**
* 集合中当前元素的索引
*/
private final int index;
/**
* <foreach />定义的 index 属性
*/
private final String itemIndex;
/**
* <foreach />定义的 item 属性
*/
private final String item;
public FilteredDynamicContext(Configuration configuration, DynamicContext delegate, String itemIndex, String item, int i) {
super(configuration, null);
this.delegate = delegate;
this.index = i;
this.itemIndex = itemIndex;
this.item = item;
}
@Override
public Map<String, Object> getBindings() {
return delegate.getBindings();
}
@Override
public void bind(String name, Object value) {
delegate.bind(name, value);
}
@Override
public String getSql() {
return delegate.getSql();
}
@Override
public void appendSql(String sql) {
GenericTokenParser parser = new GenericTokenParser("#{", "}", content -> {
// 如果在`<foreach />`标签下的内容为通过item获取元素,则替换成`__frch_'item'_uniqueNumber`
String newContent = content.replaceFirst("^\\s*" + item + "(?![^.,:\\s])", itemizeItem(item, index));
/*
* 如果在`<foreach />`标签中定义了index属性,并且标签下的内容为通过index获取元素
* 则替换成`__frch_'index'_uniqueNumber`
*/
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^\\s*" + itemIndex + "(?![^.,:\\s])", itemizeItem(itemIndex, index));
}
/*
* 返回`#{__frch_'item'_uniqueNumber}`或者`#{__frch_'index'_uniqueNumber}`
* 因为在前面已经将集合中的元素绑定在上下文的ContextMap中了,所以可以通过上面两个key获取到对应元素的值
* 例如绑定的数据:
* 1. __frch_'item'_uniqueNumber = 对应的元素值
* 2. __frch_'index'_uniqueNumber = 对应的元素值的索引
*/
return "#{" + newContent + "}";
});
delegate.appendSql(parser.parse(sql));
}
@Override
public int getUniqueNumber() {
return delegate.getUniqueNumber();
}
}
-
创建一个GenericTokenParser对象
parser,用于处理#{} -
创建一个TokenHandler处理器,大致的处理逻辑:
- 如果在
<foreach />标签下的内容为通过item获取元素,则替换成__frch_'item'_uniqueNumber - 如果在
<foreach />标签中定义了index属性,并且标签下的内容为通过index获取元素,则替换成__frch_'index'_uniqueNumber - 返回
#{__frch_'item'_uniqueNumber}或者#{__frch_'index'_uniqueNumber},因为在前面已经将集合中的元素绑定在上下文的ContextMap中了,所以可以通过上面两个key获取到对应元素的值
- 如果在
-
调用
parser进行解析,使用第2创建处理器进行处理,然后将转换后的结果拼接到SQL中
IfSqlNode
org.apache.ibatis.scripting.xmltags.IfSqlNode:实现 SqlNode 接口,<if /> 标签对应的 SqlNode 实现类,代码如下:
public class IfSqlNode implements SqlNode {
/**
* 表达式计算器
*/
private final ExpressionEvaluator evaluator;
/**
* 判断条件的表达式
*/
private final String test;
/**
* MixedSqlNode,包含该<if />节点内所有信息
*/
private final SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
this.evaluator = new ExpressionEvaluator();
}
@Override
public boolean apply(DynamicContext context) {
// <1> 判断是否符合条件
if (evaluator.evaluateBoolean(test, context.getBindings())) {
// <2> 解析该<if />节点中的内容
contents.apply(context);
return true;
}
// <3> 不符合
return false;
}
}
-
调用
ExpressionEvaluator的evaluateBoolean(String expression, Object parameterObject)方法,根据表达式从参数中获取结果- 先通过
OgnlCache根据Ognl表达式从上下文的ContextMap中获取转换后的结果,OgnlCache在后面会讲到 - 如果是Boolean,则转换成Boolean类型返回
- 如果是Number类型,则判断是否不等于 0
- 其他类则判断是否不等于null
- 先通过
-
根据第
1步的结果判断是否应用<if />标签内的SqlNode节点们
ChooseSqlNode
org.apache.ibatis.scripting.xmltags.ChooseSqlNode:实现 SqlNode 接口,<choose /> 标签对应的 SqlNode 实现类,代码如下:
public class ChooseSqlNode implements SqlNode {
/**
* <otherwise /> 标签对应的 SqlNode 节点
*/
private final SqlNode defaultSqlNode;
/**
* <when /> 标签对应的 SqlNode 节点数组
*/
private final List<SqlNode> ifSqlNodes;
public ChooseSqlNode(List<SqlNode> ifSqlNodes, SqlNode defaultSqlNode) {
this.ifSqlNodes = ifSqlNodes;
this.defaultSqlNode = defaultSqlNode;
}
@Override
public boolean apply(DynamicContext context) {
// <1> 先判断 <when /> 标签中,是否有符合条件的节点。
// 如果有,则进行应用。并且只因应用一个 SqlNode 对象
for (SqlNode sqlNode : ifSqlNodes) {
if (sqlNode.apply(context)) {
return true;
}
}
// <2> 再判断 <otherwise /> 标签,是否存在
// 如果存在,则进行应用
if (defaultSqlNode != null) {
defaultSqlNode.apply(context);
return true;
}
// <3> 返回都失败
return false;
}
}
- 先应用
<choose />下的所有<when />标签所对应的IfSqlNode,有一个应用成功则返回true - 如果所有的
<when />都不满足条件,则应用<otherwise />标签下的内容所对应的SqlNode
StaticTextSqlNode
org.apache.ibatis.scripting.xmltags.StaticTextSqlNode:实现 SqlNode 接口,用于保存静态文本,逻辑比较简单,直接拼接文本,代码如下:
public class StaticTextSqlNode implements SqlNode {
/**
* 静态内容
*/
private final String text;
public StaticTextSqlNode(String text) {
this.text = text;
}
@Override
public boolean apply(DynamicContext context) {
// 直接往正在解析 SQL 语句的上下文的 SQL 中添加该内容
context.appendSql(text);
return true;
}
}
TextSqlNode
org.apache.ibatis.scripting.xmltags.TextSqlNode:实现了 SqlNode 接口,用于处理${},注入对应的值,代码如下:
public class TextSqlNode implements SqlNode {
/**
* 动态文本
*/
private final String text;
/**
* 注入时的过滤器
*/
private final Pattern injectionFilter;
public TextSqlNode(String text) {
this(text, null);
}
public TextSqlNode(String text, Pattern injectionFilter) {
this.text = text;
this.injectionFilter = injectionFilter;
}
public boolean isDynamic() {
// <1> 创建 DynamicCheckerTokenParser 对象
DynamicCheckerTokenParser checker = new DynamicCheckerTokenParser();
// <2> 创建 GenericTokenParser 对象
GenericTokenParser parser = createParser(checker);
// <3> 执行解析,如果存在 '${ }',则 checker 会设置 isDynamic 为true
parser.parse(text);
// <4> 判断是否为动态文本
return checker.isDynamic();
}
@Override
public boolean apply(DynamicContext context) {
// <1> 创建 BindingTokenParser 对象
// <2> 创建 GenericTokenParser 对象
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
// <3> 执行解析
// <4> 将解析的结果,添加到 context 中
context.appendSql(parser.parse(text));
return true;
}
private GenericTokenParser createParser(TokenHandler handler) {
return new GenericTokenParser("${", "}", handler);
}
private static class BindingTokenParser implements TokenHandler {
private DynamicContext context;
/**
* 注入时的过滤器
*/
private Pattern injectionFilter;
public BindingTokenParser(DynamicContext context, Pattern injectionFilter) {
this.context = context;
this.injectionFilter = injectionFilter;
}
@Override
public String handleToken(String content) {
// 从上下文中获取入参对象,在DynamicContext的构造方法中可以看到为什么可以获取到
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
} else if (SimpleTypeRegistry.isSimpleType(parameter.getClass())) {
context.getBindings().put("value", parameter);
}
// 使用 OGNL 表达式,获得对应的值
Object value = OgnlCache.getValue(content, context.getBindings());
String srtValue = value == null ? "" : String.valueOf(value); // issue #274 return "" instead of "null"
// 使用过滤器进行过滤
checkInjection(srtValue);
return srtValue;
}
private void checkInjection(String value) {
if (injectionFilter != null && !injectionFilter.matcher(value).matches()) {
throw new ScriptingException("Invalid input. Please conform to regex" + injectionFilter.pattern());
}
}
}
}
在XML文件中编写SQL语句时,如果使用到了${}作为变量时,那么会生成TextSqlNode对象,可以回看XMLScriptBuilder的parseDynamicTags()方法
在MyBatis处理SQL语句时就会将
${}进行替换成对应的参数,存在SQL注入的安全性问题而
#{}就不一样了,MyBatis会将其替换成?占位符,通过java.sql.PreparedStatement进行预编译处理,不存在上面的问题
- 创建GenericTokenParser对象
parser,用于处理${},设置的Token处理器为BindingTokenParser - 执行解析,我们可以看到BindingTokenParser的
handleToken(String content)方法- 从上下文中获取入参对象,在DynamicContext的构造方法中可以看到为什么可以获取到
- 在将入参对象绑定到上下文中,设置key为"value",为什么这么做呢??没有仔细探究,可能跟
OGNL相关,感兴趣的小伙伴可以探讨一下😈 - 使用 OGNL 表达式,从上下文中获得
${}中内容对应的值,如果为null则设置为空字符串 - 使用注入过滤器对注入的值过滤
- 将解析后的结果拼接到SQL中
MixedSqlNode
org.apache.ibatis.scripting.xmltags.MixedSqlNode:实现 SqlNode 接口,用于保存多个SqlNode对象
因为一个SQL语句会被解析成多个SqlNode,且内部还会嵌套多个,所以使用MixedSqlNode进行保存,代码如下:
public class MixedSqlNode implements SqlNode {
/**
* 动态节点集合
*/
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
// 逐个应用
contents.forEach(node -> node.apply(context));
return true;
}
}
OgnlCache
org.apache.ibatis.scripting.xmltags.OgnlCache:用于处理Ognl表达式
在上面SqlNode的apply方法中,使用到的逻辑判断时获取表达式的结果则需要通过OgnlCache来进行解析
对OGNL不了解的小伙伴可以看下这篇文章:Ognl表达式基本原理和使用方法
代码如下:
public final class OgnlCache {
/**
* OgnlMemberAccess 单例,用于修改某个对象的成员为可访问
*/
private static final OgnlMemberAccess MEMBER_ACCESS = new OgnlMemberAccess();
/**
* OgnlClassResolver 单例,用于创建 Class 对象
*/
private static final OgnlClassResolver CLASS_RESOLVER = new OgnlClassResolver();
/**
* 表达式的缓存的映射
*
* KEY:表达式 VALUE:表达式的缓存 @see #parseExpression(String)
*/
private static final Map<String, Object> expressionCache = new ConcurrentHashMap<>();
private OgnlCache() {
// Prevent Instantiation of Static Class
}
public static Object getValue(String expression, Object root) {
try {
/*
* <1> 创建 OgnlContext 对象,设置 OGNL 的成员访问器和类解析器,设置根元素为 root 对象
* 这里是调用 OgnlContext 的s etRoot 方法直接设置根元素,可以通过 'user.id' 获取结果
* 如果是通过 put 方法添加的对象,则取值时需要使用'#',例如 '#user.id'
*/
Map context = Ognl.createDefaultContext(root, MEMBER_ACCESS, CLASS_RESOLVER, null);
/*
* <2> expression 转换成 Ognl 表达式
* <3> 根据 Ognl 表达式获取结果
*/
return Ognl.getValue(parseExpression(expression), context, root);
} catch (OgnlException e) {
throw new BuilderException("Error evaluating expression '" + expression + "'. Cause: " + e, e);
}
}
/**
* 根据表达式构建一个 Ognl 表达式
*
* @param expression 表达式,例如<if test="user.id > 0"> </if>,那这里传入的就是 "user.id > 0"
* @return Ognl 表达式
* @throws OgnlException 异常
*/
private static Object parseExpression(String expression) throws OgnlException {
Object node = expressionCache.get(expression);
if (node == null) {
node = Ognl.parseExpression(expression);
expressionCache.put(expression, node);
}
return node;
}
}
getValue方法:根据Ognl表达式从Object中获取结果
-
创建 OgnlContext 对象,设置 OGNL 的成员访问器和类解析器,设置根元素为
root对象 -
将创建
expression转换成 Ognl 表达式,缓存起来 -
根据 Ognl 表达式从
root对象中获取结果
总结
本文讲述的是XML映射文件中的<select /> <insert /> <update /> <delete />节点内的SQL语句如何被解析的
在XMLLanguageDriver语言驱动类中,通过XMLScriptBuilder对该到节点的内容进行解析,创建相应的SqlSource资源对象
在其解析的过程会根据不同的NodeHandler节点处理器对MyBatis自定义的标签(<if /> <foreach />等)进行处理,生成相应的SqlNode对象,最后将所有的SqlNode对象存放在MixedSqlNode中
解析的过程中会判断是否为动态的SQL语句,包含了MyBatis自定义的标签或者使用了${}都是动态的SQL语句,动态的SQL语句创建DynamicSqlSource对象,否则创建RawSqlSource对象
那么关于SqlSource是什么其实这里还不是特别了解,由于其涉及到的篇幅并不少,所以另起一篇文档《MyBatis初始化(四)之SQL初始化(下)》进行分析
参考文章:芋道源码《精尽 MyBatis 源码分析》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号