Linux shell 脚本常用指南
常用语法
变量
#!/bin/bash
# 字符串
USER_NAME="shell"
# 数字
AGE=25
echo ${USER_NAME}
echo ${AGE}数组
#!/bin/bash
# 普通数组定义
USER_IDS=(1 2 3 4)
echo ${USER_IDS[0]}
echo ${USER_IDS[1]}
echo ${USER_IDS[2]}
echo ${USER_IDS[3]}
USER_IDS[0]=-1
echo ${USER_IDS[0]}
# 关联数组定义
declare -A USER_MAP=(["zhangsan"]="this is zhangsan" ["lisi"]="this is lisi")
echo ${USER_MAP["zhangsan"]}
echo ${USER_MAP["lisi"]}
USER_MAP["zhangsan"]="zhangsan change"
echo ${USER_MAP["zhangsan"]}流程控制
if else
[]写法(推荐)
if [ "$a" -gt "$b" ]; then
echo "yes"
fi
#多个条件写法
if [ "$a" -gt "$b" ] && [ "$a" -gt "$b" ] ; then
echo "yes"
fi(())写法
if (( a > b )); then
...
fi判断条件表
字符串判断 含义
-n str1 当串的长度大于0时为真(串非空)
-z str1 当串的长度为0时为真(空串)
$a = $b 判断a与b两个字符串是否相等
$a != $b 判断a与b两个字符串不相等
数字的判断
int1 -eq int2 两数相等为真
int1 -ne int2 两数不等为真
int1 -gt int2 int1大于int2为真
int1 -ge int2 int1大于等于int2为真
int1 -lt int2 int1小于int2为真
int1 -le int2 int1小于等于int2为真
文件的判断
-r file 用户可读为真(助记:read)
-w file 用户可写为真(助记:write)
-x file 用户可执行为真
-f file 文件为普通文件为真
-c file 文件为字符特殊文件为真
-b file 文件为块特殊文件为真
-d file 文件为目录为真
-s file 文件大小非0时为真
-t file 当文件描述符(默认为1)指定的设备为终端时为真
-a FILE 如果 FILE 存在则为真。
-p FILE 如果 FILE 存在且是一个名字管道(F如果O)则为真
-L FILE 如果 FILE 存在且是一个符号连接则为真
-S FILE 如果 FILE 存在且是一个套接字则为真
复杂逻辑判断
-a 与
-o 或
! 非for
user_ids=(1 2 3 4)
for loop in ${user_ids[@]}
do
echo ${loop}
done
for(( i=0;i<=5;i++ ))
do
echo $i
donewhile
#!/bin/bash
sum=1
while(( ${sum}<=5 ))
do
echo ${sum}
sum=`expr ${sum} + 1`
done函数
一个加法函数
function sum(){
res=`expr $1 + $2`
echo ${res}
}
sum 1 3传递参数
#!/bin/bash
echo "Shell 传递参数实例!";
echo "执行的文件名:$0";
echo "第一个参数为:$1";
echo "第二个参数为:$2";
echo "第三个参数为:$3";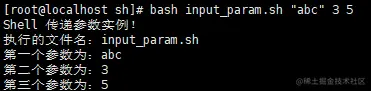
输入\输出
| 命令 | 说明 |
|---|---|
| command > file | 将输出重定向到 file。 |
| command < file | 将输入重定向到 file。 |
| command >> file | 将输出以追加的方式重定向到 file。 |
| n > file | 将文件描述符为 n 的文件重定向到 file。 |
| n >> file | 将文件描述符为 n 的文件以追加的方式重定向到 file。 |
| n >& m | 将输出文件 m 和 n 合并。 |
| n <& m | 将输入文件 m 和 n 合并。 |
| << tag | 将开始标记 tag 和结束标记 tag 之间的内容作为输入。 |
linux三剑客grep、sed、awk
grep查找命令
下面的案例都是用/etc/passwd文件来演示的
常用指令
| 指令 | 说明 |
|---|---|
| -A | 除了匹配行,额外显示该行之后的N行 |
| -B | 除了匹配行,额外显示该行之前的N行 |
| -C | 除了匹配行,额外显示该行前后的N行 |
| -c | 统计匹配的行数 |
| -e | 实现多个选项间的逻辑 or 关系 |
| -E | 支持扩展的正则表达式 |
| -F | 相当于 fgrep |
| -i | 忽略大小写 |
| -n | 显示匹配的行号 |
| -o | 仅显示匹配到的字符串 |
| -q | 安静模式,不输出任何信息,脚本中常用 |
| -s | 不显示错误信息 |
| -v | 显示不被匹配到的行 |
| -w | 显示整个单词 |
| --color | 以颜色突出显示匹配到的字符串 |
把包含root的行过滤出来
grep "root" /etc/passwd
# 忽略大小写过滤
grep -i "root" /etc/passwd正则匹配固定开头和结尾的行
# 匹配root开头的行
grep "^root" /etc/passwd
# 匹配/bin/bash结尾的行
grep "/bin/bash$" /etc/passwd把匹配root的行以及下边两行显示出来
grep -A "root" /etc/passwd过滤root关键字,并输出行号
grep -n "root" /etc/passwd删除空行
grep -v "^$" /etc/passwd过滤包含root或者hzh的行
grep -e "root" -e "hzh" /etc/passwd其他复杂用法
# 在当前目录递归查询
grep -r "font".
# (显示行号,且以单词严格匹配)
grep -rnw "font" .
# 在递归的过程中排除某些目录
grep -rnw --exclude-dir={.git,svn} "font"awk命令
awk是一种处理文本文件的语言,是一个强大的文本分析工具,下面使用/etc/passwd文件作案例。
基本命令格式
awk '{pattern + action}' <file>pattern表示在数据中要查找的内容,action表示要执行的一系列命令
默认空格(一个或多个)分割数据
$1、$2 ... $n 表示第一个字段、第二个字段... 第n个字段
awk '{print $2, $4, $6}' /etc/passwd指定分隔符
指定:或,为分隔符
awk -F ':|,' '{print $2, $4, $6}' /etc/passwd正则分隔符,指定空格或者,号,一个或多个为分隔符
awk -F'[ |,]+' '{print $1}' awk.txt内置变量
除了 $1、$2 ... $n,awk 还有一些内置变量,常用的如下:
| 变量 | 描述 |
|---|---|
| $0 | 表示当前整行,1表示第一个字段,1表示第一个字段,2表示第二个字段,$n 表示第n个字段; |
| NR | 表示当前已读的行数 |
| NF | 表示当前行被分割的列数,NF表示最后一个字段,NF-1 表示倒数第二个字段; |
| FILENAME | 表示当前文件的名称 |
条件判断
判断第三列大于10的显示整行
awk -F ' |,' '$3 > 10 {print $0}' awk.txt正则匹配行
匹配包含hzh的行并输出
awk '/hzh/{print $0}' awk.txt匹配00结尾的并输出
awk '/00$/{print $0}' awk.txtsed命令
sed 主要是用来将数据进行选取、替换、删除、新増的命令。
语法
sed [选项] '[动作]' 文件名
选项
| 选项 | 含义 |
|---|---|
| -e | 该选项会将其后跟的脚本命令添加到已有的命令中 |
| -f | 该选项会将其后文件中的脚本命令添加到已有的命令中 |
| -n | 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出 |
| -i | 此选项会直接修改源文件,要慎用 |
字符串替换
基本格式
sed 's/pattern/replacement/flags' /etc/passwdflags取值表
| flags标记 | 功能 |
|---|---|
| n | 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换,例如,一行中有 3 个 A,但用户只想替换第二个 A,这是就用到这个标记 |
| g | 对数据中所有匹配到的内容进行替换,如果没有 g,则只会在第一次匹配成功时做替换操作。例如,一行数据中有 3 个 A,则只会替换第一个 A; |
| p | 会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。 |
| w file | 将缓冲区中的内容写到指定的 file 文件中; |
| & | 用正则表达式匹配的内容进行替换; |
| \n | 匹配第 n 个子串,该子串之前在 pattern 中用 () 指定。 |
| \ | 转义(转义替换部分包含:&、\ 等)。 |
替换第几次出现的匹配模式
下面的语句替换hello,替换每一行中第二次出现
sed 's/hello/happy/2' sed.txt替换所有匹配的字符串
如果sed变为sed -i 则表示修改源文件且不输出
sed 's/hello/happy/g' sed.txt删除指定行
- 删除第
2,3行 -
sed '2,3d' sed.txt - 删除第
1-3行 -
sed '/1/,/3/d' sed.txt - 删除第
2行开始的所有内容 -
sed '2,$d' sed.txt
在指定行新增
- 在第
2行后追加 -
sed '2a\append line' sed.txt - 在第
2行前新增 -
sed '2i\pre line' sed.txt
替换指定行
sed '2c\replace line' sed.txt三剑客取JSON字符串中的指定key
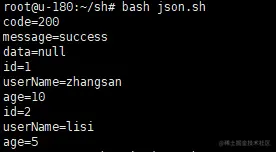
#!/bin/bash
result_json='{"code":200,"message":"success","data":null}'
# 取出code
code=`echo ${result_json} | sed 's/\\\"/"/g' | grep -Po '"code":"?\K.*?(?=,|})'`
echo "code=${code}"
message=`echo ${result_json} | sed 's/\\\"/"/g' | grep -Po '"message":"?\K.*?(?=,|}|")'`
echo "message=${message}"
data=`echo ${result_json} | sed 's/\\\"/"/g' | grep -Po '"data":"?\K.*?(?=,|}|")'`
echo "data=${data}"
result_json='{"code":200,"message":"success","data":[{"id":1,"userName":"zhangsan","age":10},{"id":2,"userName":"lisi","age":5}]}'
# 取data中的id、userName、age
id=`echo ${result_json} | sed 's/,/EOF\n/g' | grep -Po '"id":"?\K.*?(?=,|}|EOF)' | sed -n 1p`
echo "id=${id}"
userName=`echo ${result_json} | sed 's/,/EOF\n/g' | grep -Po '"userName":"?\K.*?(?=,|"|}|EOF)' | sed -n 1p`
echo "userName=${userName}"
age=`echo ${result_json} | sed 's/,/EOF\n/g' | grep -Po '"age":"?\K.*?(?=,|}|EOF)' | sed -n 1p`
echo "age=${age}"
id=`echo ${result_json} | sed 's/,/EOF\n/g' | grep -Po '"id":"?\K.*?(?=,|}|EOF)' | sed -n 2p`
echo "id=${id}"
userName=`echo ${result_json} | sed 's/,/EOF\n/g' | grep -Po '"userName":"?\K.*?(?=,|"|}|EOF)' | sed -n 2p`
echo "userName=${userName}"
age=`echo ${result_json} | sed 's/,/EOF\n/g' | grep -Po '"age":"?\K.*?(?=,|}|EOF)' | sed -n 2p`
echo "age=${age}"- 运行结果
sed 's/\\\"/"/g'- 该语句是替换字符串中的
\"替换为" grep -Po '"code":"?\K.*?(?=,|})'该语句是取指定key,后面的值,这里取的是code后面的,:?标识匹配0个或1个,*?(?=,|})表示以什么结尾,最少匹配,匹配到第一个接结束,且字符串不会包含在我们想要的结果中,sed -n 2p取第几行的意思-
注意点
-
单引号
'',和双引号"" -
单引号
'' - 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
-
双引号
"" - 双引号里可以有变量
- 双引号里可以出现转义字符
-
shell脚本中获取当前绝对路径 fork_sub.sh-
#!/bin/bash BASE_PATH=$(cd `dirname $0`;pwd) echo ${BASE_PATH}$开头的一些指令含义shell复制代码$0:这个程式的执行名字。 $n:这个程式的第 n 个参数值,n=1…9。 $*:这个程式的所有参数,此选项参数可超过 9 个。 $#:这个程式的参数个数。 $$:这个程式的 PID(脚本运行的当前进程 ID 号) $!:执行上一个背景指令的 PID (后台运行的最后一个进程的进程 ID 号) $?:执行上一个指令的返回值 (显示最后命令的退出状态。0 表示没有错误,其他任何值表明有错误) $-:显示 shell 使用的当前选项,与 set 命令功能相同。
shell脚本调用其他shell脚本的三种方式fork模式fork 是最普通的, 就是直接在脚本里面用 path/to/foo.sh 来调用foo.sh 这个脚本,比如如果是 foo.sh 在当前目录下,就是 ./foo.sh。运行的时候 terminal 会新开一个子 Shell 执行脚本 foo.sh,子 Shell 执行的时候, 父 Shell 还在。子 Shell 执行完毕后返回父 Shell。 子 Shell 从父 Shell 继承环境变量,但是子 Shell 中的环境变量不会带回父 Shell
fork.sh
#!/bin/bash echo "fork模式" user_name="zhangsan" export user_name ./fork_sub.sh echo ${user_name} echo "fork执行完毕" fork_sub.sh-
#!/bin/bash echo "输出user_name=${user_name}" user_name="张三变了"- 输出结果
[root@localhost exec]# bash fork.sh fork模式 输出user_name=zhangsan zhangsan fork执行完毕 -
exec模式exec与fork不同,不需要新开一个子Shell来执行被调用的脚本. 被调用的脚本与父脚本在同一个 Shell 内执行。但是使用exec调用一个新脚本以后, 父脚本中exec行之后的内容就不会再执行了。这是exec 和 source的区别.
source模式与
fork的区别是不新开一个子Shell来执行被调用的脚本,而是在同一个Shell中执行. 所以被调用的脚本中声明的变量和环境变量, 都可以在主脚本中进行获取和使用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?