
python:根据小说名称爬取电子书
简介
上一章节小编用python爬取了“斗罗大陆”单本小说,经过周末马不停蹄、加班加点、抓耳挠腮的搬砖。终于在今天,经过优化处理后,一款基于python爬虫来爬取千千小说网站的程序出来了,主要功能有以下几点:
- 根据需要,输入想要查看的页数,查询页数内的所有小说。
- 展示小说ID序号及小说名称。
- 输入小说ID,进行对应的下载。
- 下载完毕后,进行持久化存储到文件夹。
下面,开始展示成果吧,哈哈哈哈:
页数查询结果显示

下载书籍输入ID及进度展示

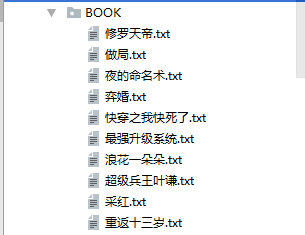
文件夹储存展示
第一步,导包
import os
from lxml import etree
from pathlib import Path
from requests import Session
具体使用可以参考上一章《python:爬取“斗罗大陆”电子书》 哦~
第二步,判断存储文件夹
def is_exists(book_name):
"""
判断存储路径是否存在,不存在就新建
:param book_name: 书籍名称
:return:
"""
base_dir = Path(__file__).parent.joinpath("BOOK")
if not os.path.exists(base_dir):
os.mkdir(base_dir)
return base_dir.joinpath(book_name)
依旧是新建文件……
第三步,封装一个公共方法
def request_url(url, is_text: bool = False):
"""
请求url,直接定义的get请求
:param url:
:param is_text: 判断数据是返回解析的数据还是原始的数据
:return:
"""
s = Session()
def encoding_gbk(r):
"""
转码
:param r:
:return:
"""
r.encoding = "gbk"
return etree.HTML(r.text)
s.headers.update({
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36"
})
response = s.get(url=url)
return encoding_gbk(response) if is_text else etree.HTML(response.text)
- s=Session():可以理解成类似浏览器
- encoding_gbk(r):局部函数看,进行转码操作
- s.headers.update:是更新headers头
- return 根据判断返回转码的数据或是已解析的数据
第四步,分析待爬目标处理URL
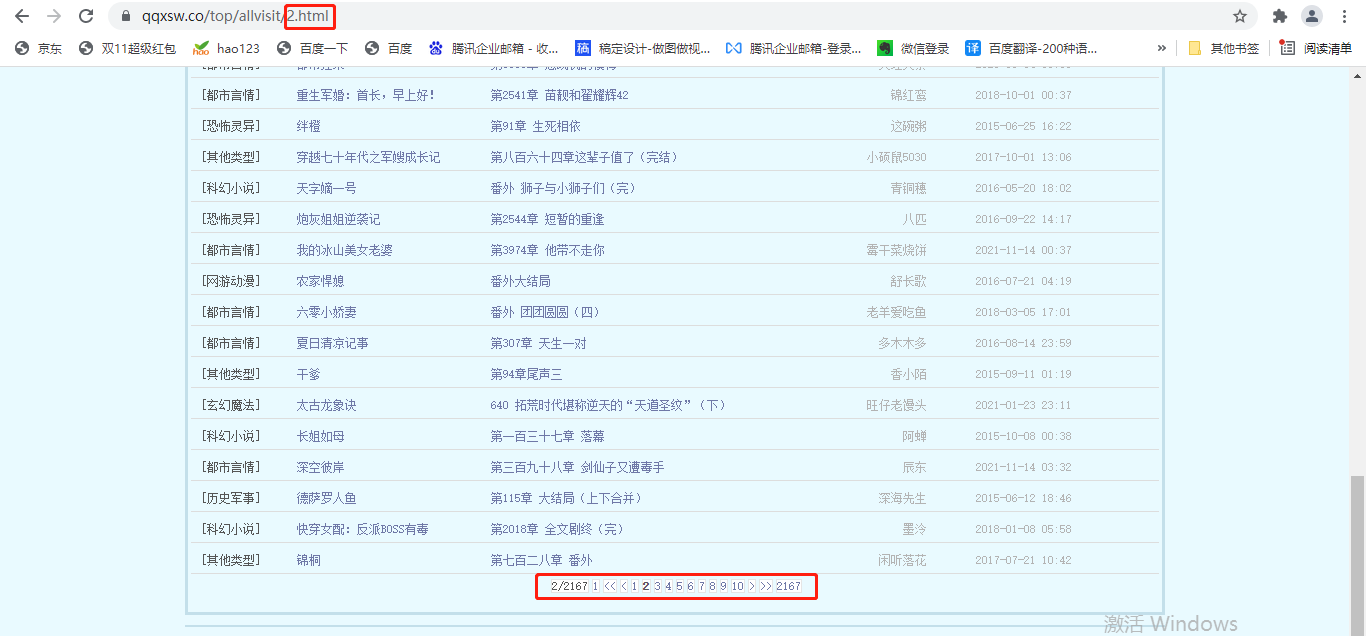
看页面,注意观察到第一页的URL为https://www.qqxsw.co/top/allvisit/,当查看第二页、第三页…时候的URL时,后面就多了个页数+.html,例如第二页的URL值是这样的https://www.qqxsw.co/top/allvisit/2.html。于是,小编得出这样的一个想法:URL=https://www.qqxsw.co/top/allvisit/页数.html。
封装一个函数,开始进行处理.....
def page_num_url(page: int):
"""
排行榜链接
获取自定义分页url列表
:param page: 页码
:return:
"""
time_url = "https://www.qqxsw.co/top/allvisit/"
page_url_list = []
for num in range(1, page + 1):
# 拼接分页地址,并插入列表
page_url_list.append(time_url + str(num) + ".html")
return page_url_list
这里也可以改成定义一个起始页数、一个结束页数,这样就更方便查询了,小伙伴们可以试试哈。
第五步,处理页数和所有小说的URL

启用万能工具F12,指定定位到小说名称,然后….小编惊喜的看到,可以通过获取href的属性值就可以直接获取完整的小说目录URL(终于不用拼接了呀),同理,通过title属性值就能得到小说名称,nice!!!!
为了能一一对应展示出小说名称及URL,小编这里把它们存到了字典里,方便后面取….(老实说,但是实现的时候因为不熟练也不太好取),代码封装如下:
def article_url_list(page: int):
"""
获取完整小说URL列表
:param page: 页码
:return:
"""
article_list = []
for url in page_num_url(page):
response = request_url(url=url, is_text=True)
span_list = response.xpath('//div[@class="novelslistss"]/li/span[@class="s2"]')
# 获取所有的小说url、名称
for span in span_list:
url_list = span.xpath("./a/@href")
article_name_list = span.xpath("./a/@title")
if len(url_list) & len(article_name_list) > 0:
dic_list = {
"url": url_list[0],
"name": article_name_list[0]
}
article_list.append(dic_list)
return article_list
第六步,展示之前查询页码的所有的ID及书籍名称
之前存储的字典,现在可以用上了…通过遍历之前字典的索引值及书籍名称,控制台进行展示。
def show_name(page: int):
"""
显示书籍名称及索引值
:param page: 页码
:return:
"""
for i in article_url_list(page):
# 打印索引编码和书籍名称
print(f"编号:{article_url_list(page).index(i)} - 书籍名称:{i['name']}")
第七步,指定ID下载,取出小说名称用于后续调用
def download_url(number: int, page: int):
"""
指定ID下载,返回具体书籍url
:param number:
:param page:
:return:
"""
return article_url_list(page)[number]["url"]
def txt_name(number: int, page: int):
"""
返回书籍名称
:param number:
:param page:
:return:
"""
return article_url_list(page)[number]["name"]
第八步,小说下载存储处理
def download_article(number: int, page: int):
"""
小说存储下载处理
:param number:
:param page:
:return:
"""
def handle_():
# 封面目录页
response = request_url(url=download_url(number, page))
# 提取章节url
url_list = []
for dd in response.xpath('//div[@id="list"]/dl/dd'):
detail_url_list = dd.xpath("./a/@href")
if len(detail_url_list) > 0:
url_list.append(detail_url_list[0])
return url_list
# 处理详情页
with open(is_exists(f"{txt_name(number, page)}.txt"), "w+", encoding="utf-8") as fp:
# 循环去重,转回列表并排序的数据
for page_url in sorted(list(set(handle_()))):
detail_url = download_url(number, page) + page_url
response = request_url(url=detail_url, is_text=True)
detail_name = response.xpath('//div[@class="bookname"]/h1/text()')[0]
detail_data = response.xpath('//div[@id="content"]/text()')
# 列表转字符串,然后持久化存储数据
fp.write(detail_name + "\n" + "".join(detail_data) + "\n")
print(detail_name, "下载成功!!")
print("全部下载成功!!!!!")
第九步,运行
集合一个入口函数,直接调用运行即可:
def main():
"""
主运行入口
:param page:
:param number:
:return:
"""
page = int(input("请输入要查询的页数:"))
number = int(input("下载的书籍序号:"))
print("*" * 15, "存在以下可下载书籍", "*" * 15)
show_name(page)
print("*" * 42)
article_url_list(page)
print(txt_name(number, page), "正在下载,请稍等....")
download_article(number, page)
if __name__ == '__main__':
main()
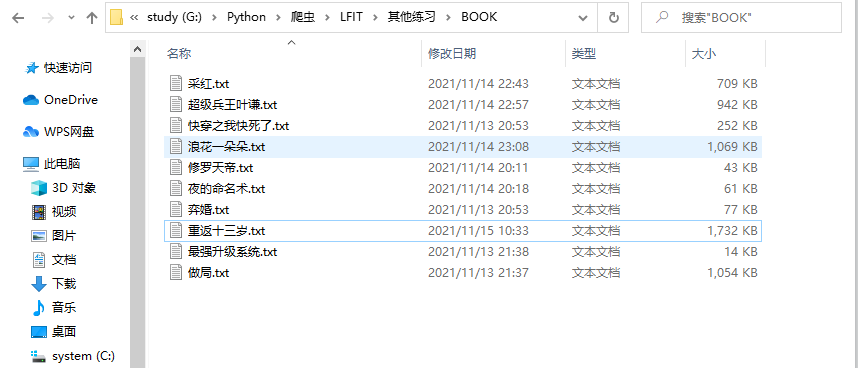
搞定!!!!现在给大家展示一下小编用这个下载器下载的小说吧~
第十步,总结感悟
小编爬虫还在提升中,有很多不成熟的地方,在实现整个功能的时候也发现了封装不当导致代码凌乱的问题,在这次代码里有以下2点感觉比较难处理:
- 小说名称与URL的存入和取出,建议打印出来后对照着来调试取值会快很多。
- input的使用位置存放的不好,后来经过和小伙伴的谈论后进行了重新修改,代码整体舒服多了。
以上总结或许能帮助到你,或许帮助不到你,但还是希望能帮助到你,如有疑问、歧义,直接私信留言会及时修正发布;非常期待你的点赞和分享哟,谢谢!
未完,待续…
一直都在努力,希望您也是!
微信搜索公众号:就用python
作者:梁莉莉|编辑排版:李 锋


 浙公网安备 33010602011771号
浙公网安备 33010602011771号