
浅析String
浅析String
String的设计结构:
首先我们看一下
String的源码
public final class String
implements java.io.Serializable,
Comparable<String>, CharSequence {
/** The value is used for character
storage. */
private final char value[];
…
}
源码特点:
1,String是一个对象
2,String被final修饰,
3,String内部维护的是final char[]
1,2构建String的基本特点,只能被初始化一次
3的特点防止了通过String的引用修改String的内部实际值.
这三个特点构建了String对象的基本特点.,这样设计的特点保证了Stirng的唯一性.
为什么String需要唯一性不可变性呢?
因为安全和高效,可以在多线程中共享时而不要任何的同步处理,更因其不可变性而显的更加高效.
不可变性的另一个问题:占用空间
String的使用率非常之高,但是String是不可变的,代表着每次创建一个String都会new一个新的对象,当需要大量的String时候,就会占用很大的内存空间,消耗应用性能.
Java是如何解决String这种不可变性的问题
这也是我写这篇文章的重点,理解了Java是如何解决String这种不可变性的问题,也就理解的String.
其实理解这个问题也很简单,我们只需要理解常量池的概念就就行了:
每次我们使用String常量时,实际上jvm会到String常量池中找到对应的常量,如果有就返回对应的引用,如果没有就创建出一个新的常量并将其引用返回.
我们来看一个例子:
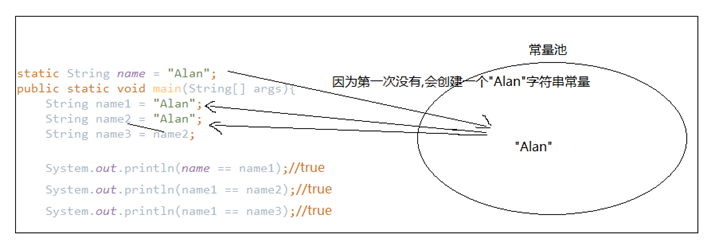
由上图可以看出,这样的设计解决了大部分的内存空间以及性能的消耗.
另一用优化的策略(预处理):
java文件在编译期间不仅会把final基本数据的类型表达式运算成一个值,同时也会把使用+拼接的字符串最终也会拼接成一个字符串
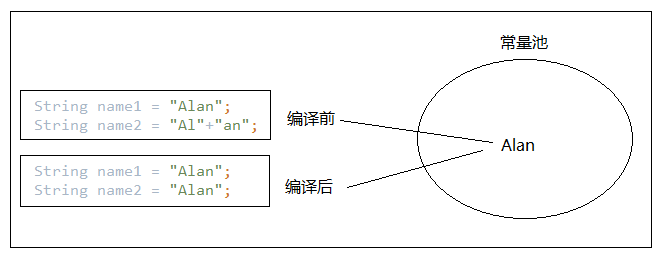
以上情况指向了同一个地址值,下面我们来看一下,地址值不同的案例:
第一种:通过new Stirng()的方式主动分配新地址:
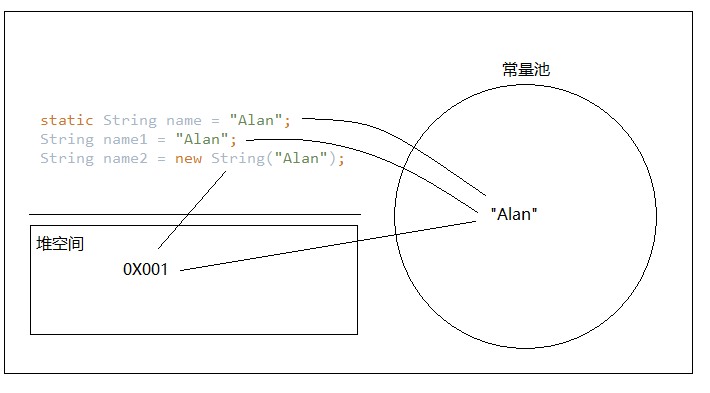
name2通过new一定会创建一个新的引用,但是其内部还是引用常量池中的”Alan”,所以这里有两个对象引用:new String()的和”Alan”
第二种:编译期间无法确定值
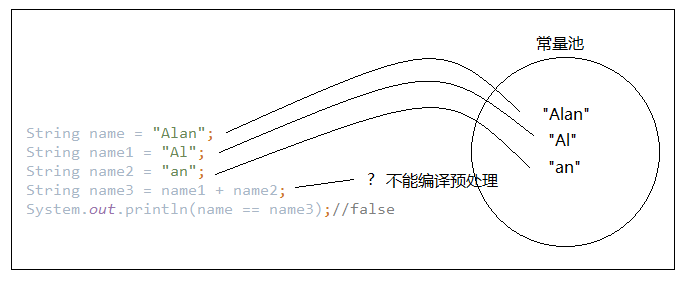
一下也是编译时期无法确定的组合:
String name3 = “Al”+name2;
String name3 = “Al”+new String(“an”);
总结:
/**
* Author:Alan
*
* @Date: 2018-04-26 20:51:40
*/
public class Main {
static String name = "Alan";
public static void main(String[] args){
String name0 = "Alan";
String name1 = "Al";
String name2 = "an";
String name3 = name1 + name2;
System.out.println(name0 == name3);//false
System.out.println(name0 == "Al"+name2);//false
System.out.println(name == name0);//true
System.out.println(name0 == "Alan");//true
System.out.println(name0 == "Al"+"an");//true
}
}
