从IO的角度深入理解Select、Poll、Epoll的区别推理
近期刚学习IO多路复用的知识,还有看了django和flask框架WSGIServer的源码,对源码中使用的selector模块比较好奇,也就去稍微深入看了一下个方面资料和相关视频及底层实现,梳理出这篇文章。
一、Python中起高可用socket服务端的常用三种方式
在初始我们写一个socket服务端, 如果要供多人同时连接使用的话,有几大方式如在接收消息部分使用多线程,使用协程, 或者是多进程实现socket服务端 。
socket客户端实现, 用于连接测试服务端
import socket
import time
sc = socket.socket()
sc.connect(('127.0.0.1', 8000))
while True:
sc.send(b'hello word')
data = sc.recv(1024)
print(data)
time.sleep(1)
1)多进程实现socket服务端
import socket
from multiprocessing import Process
import time
sc = socket.socket()
sc.bind(('127.0.0.1', 8000))
sc.listen(5)
sc.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
def recv_data(conn):
while True:
data = conn.recv(1024)
if data:
print(data)
conn.sendall(data.upper())
while True:
conn, addr = sc.accept()
if conn:
Process(target=recv_data, args=(conn,)).start()
time.sleep(1)
使用多进程实现socket服务端的优缺点
优点:解决单进程单线程无法多客户端连接的问题
缺点:开多进程消耗的资源比较大,并且操作系统多进程数量有限制
2)多线程实现socket服务端
# 多线程socket服务端
import socket import threading import time sc = socket.socket() sc.bind(('127.0.0.1', 8000)) sc.listen(5) sc.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) def recv_data(conn): while True: data = conn.recv(1024) if data: print(data) conn.sendall(data.upper()) while True: conn, addr = sc.accept() if conn: threading.Thread(target=recv_data, args=(conn,)).start() time.sleep(1)
使用多线程实现socket服务端的优缺点
优点: 可以满足多客户端连接,实现简单, 比多进程更小的资源的消耗
缺点: 开多线程耗资源,且线程间的切换有性能消耗,不能无限开
3)使用协程实现socket服务端
import time
import socket
import gevent
from gevent import monkey
monkey.patch_all()
sc = socket.socket()
sc.bind(('127.0.0.1', 8000))
sc.listen(5)
sc.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
def recv_data(conn):
while True:
data = conn.recv(1024)
if data:
print(data)
conn.sendall(data.upper())
while True:
conn, addr = sc.accept()
if conn:
gevent.spawn(recv_data, conn)
time.sleep(1)
使用协程实现socket服务端优缺点:
优点: 协程是微线程,多个协程在一个线程内切换,占用资源最少,并且在socket这种IO密集型的服务中效率很高,有时速度优于多线程socket实现
缺点:比起多进程和多线程实现是基本没有缺点,唯一是无法利用多CPU,在计算密集型服务时吃力
以上三种socket服务端的实现方式都存在的缺点是,如果有1W个连接时,单次就会有1W次IO操作,会有操作系统层面的1W次系统调用,会有比较大的系统调用切换的消耗,这就引出我们的IO多路复用。
二、IO多路复用之Select、Poll、Epoll及其区别
1)Select和Poll和Epoll的用法
其实Select和Poll的区别不大,唯一区别是Select对有最大连接数限制1024这个数字是可以修改的,而Poll是基于链表结构的没有最大连接数限制。
import selectors
import socket
select = selectors.DefaultSelector()
def recv_data(conn, mask):
data = conn.recv(1024)
if data:
print(data)
conn.sendall(data.upper())
else:
select.unregister(conn)
conn.close()
def accept(sc, mask):
conn, addr = sc.accept()
conn.setblocking(False)
select.register(conn, selectors.EVENT_READ, recv_data)
sc = socket.socket()
sc.bind(('127.0.0.1', 8000))
sc.listen(5)
sc.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sc.setblocking(False)
select.register(sc, selectors.EVENT_READ, accept) # epoll的话相当于向内核开辟一个空间放文件描述符
while True:
read = select.select(timeout=1) # 相当于遍历文件描述符
for key, mask in read:
callback = key.data
callback(key.fileobj, mask)
由于我们使用的python自带的selectors模块,代码中 select = selectors.DefaultSelector() 会根据操作系统的不同实例化合适的Select或者Poll或者Epoll。
我们知道很多时刻操作系统的进程和线程的调度策略为: 时间片轮转调度,也就是每个线程在时间片内被cpu调度执行,根据这基础我们进行分析,假设我们有1w个线程并发执行(不是并行哦)这样单位时间内就会调度操作系统内核交互1W次,也就产生了1W次IO,如果把这1W次IO变成1次IO,那性能是不是提升很多,而select和epoll就是这样做的,它把这1W个文件描述符(或者理解成调用)放到一个数组或者链表中,一次传递给操作系统内核,然后内核内的线程去循环这个数组,去执行相应的指令,然后执行完毕后,操作系统用户态再拿回这个文件描述符数组,然后遍历取其中的结果,这样就从1W次IO变成了1次IO了。
多线程下的IO模型
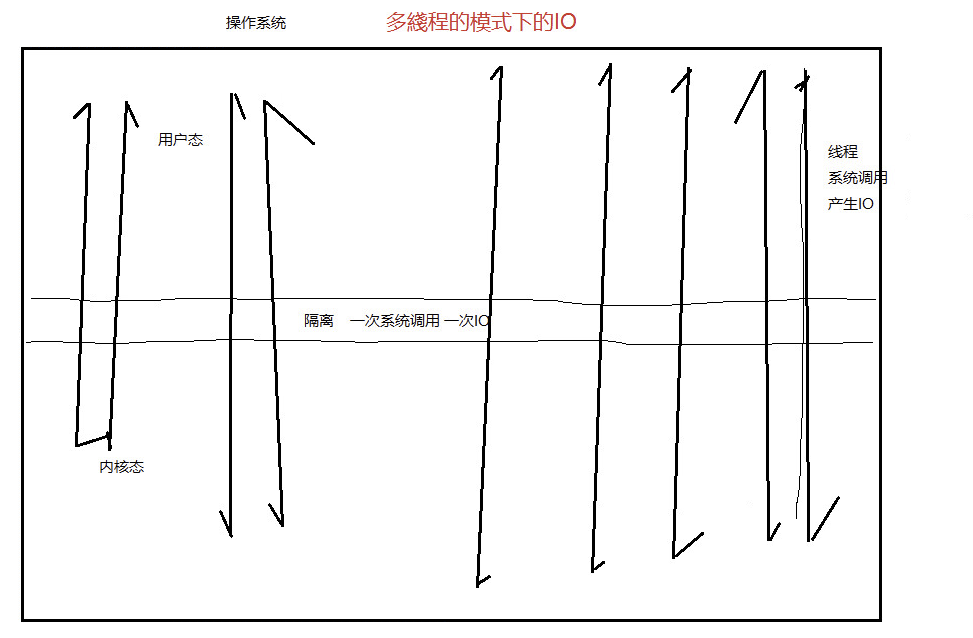
select和poll下IO图解

我们先说select和epoll的优缺点:
优点: 可以减少操作系统用户态和内核态IO的次数,统一监控多个IO操作,然后遍历获取结果。
缺点: 每次都要传递一个大的数组列表, 还有每次都要多数组列表进行遍历获得结果。
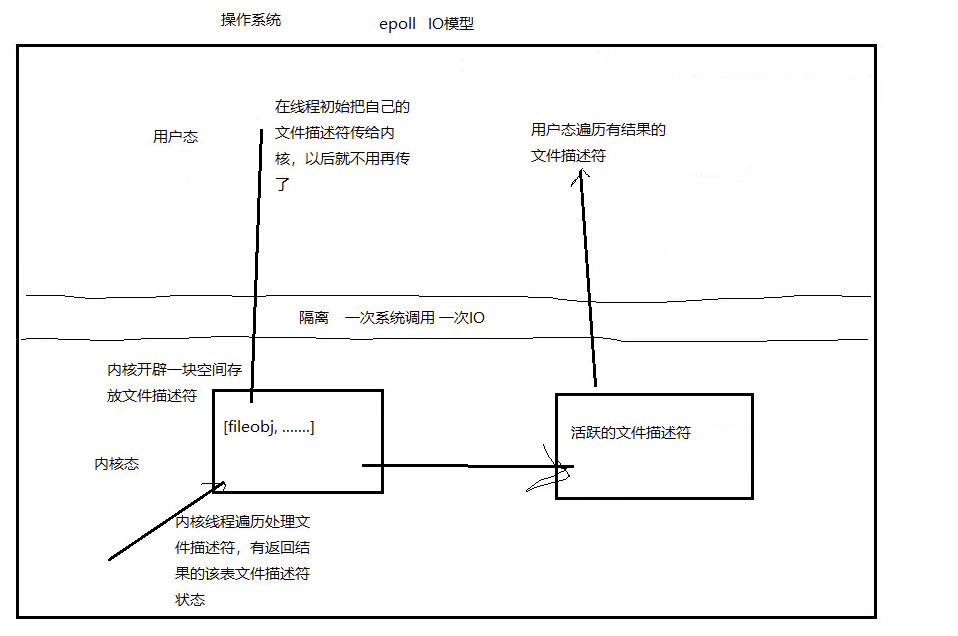
所以在上述缺点的情况下Epoll诞生了:
epoll会在操作系统内核中开辟一个空间,然后每次系统调用就会把新的文件描述,传递给内核(只传递一次),然后内核会开另一个线程去监控内核中的文件描述符,在有返回结果后,它会结果返回放到另一个空间(文件描述符活跃),此时用户态只会遍历活跃状态的文件描述符,这样用空间换时间效率提升,主要体现在:内核多个线程并发处理文件描述符,每次只遍历活跃的文件描述符。
epoll IO模型
至此告一段落,后续还需补充挺多东西,如果操作系统的IO知识:
1、操作系统IO知识,什么是用户态,内核态
2、操作系统进程线程的调度策略
3、操作系统的系统调用、中断和异常
4、还有select函数底层实现 可以在linux中用man函数调用查看解释
5、什么是文件描述符,操作系统中一切皆文件
等等一些列操作系统方面的知识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号