libsvm 用在 婚介数据集中 预测 用户配对
分类前具备的数据集:
书本第九章数据集(训练集):agesonly.csv和matchmaker.csv。
agesonly.csv 格式是: 男年龄,女年龄,是否匹配成功
24,30,1
30,40,1
22,49,0
43,39,1
matchmaker.csv数据格式是: 年龄,是否抽烟,想要孩子,兴趣列表,地址 , 年龄,是否抽烟,想要孩子,兴趣列表,地址 , 是否匹配成功。
数据每一行是两个人的个人信息和最终是否匹配
39,yes,no,skiing:knitting:dancing,220 W 42nd St New York NY, 43,no,yes,soccer:reading:scrabble,824 3rd Ave New York NY,0
23,no,no,football:fashion,102 1st Ave New York NY, 30,no,no,snowboarding:knitting:computers:shopping:tv:travel,151 W 34th St New York NY,1
46,no,yes,skiing:reading:knitting:writing:shopping,154 7th Ave New York NY,19,no,no,dancing:opera:travel,1560 Broadway New York NY,0
36,yes,yes,skiing:knitting:camping:writing:cooking,151 W 34th St New York NY,29,no,yes,art:movies:cooking:scrabble,966 3rd Ave New York NY,1
27,no,no,snowboarding:knitting:fashion:camping:cooking,27 3rd Ave New York NY,19,yes,yes,football:computers:writing,14 E 47th St New York NY,0
我们要做的分类是:给出任何两个人是否匹配成功 0 或1 的结果
分类步骤:
一、加载数据,将excel形式数据 加载成 行格式
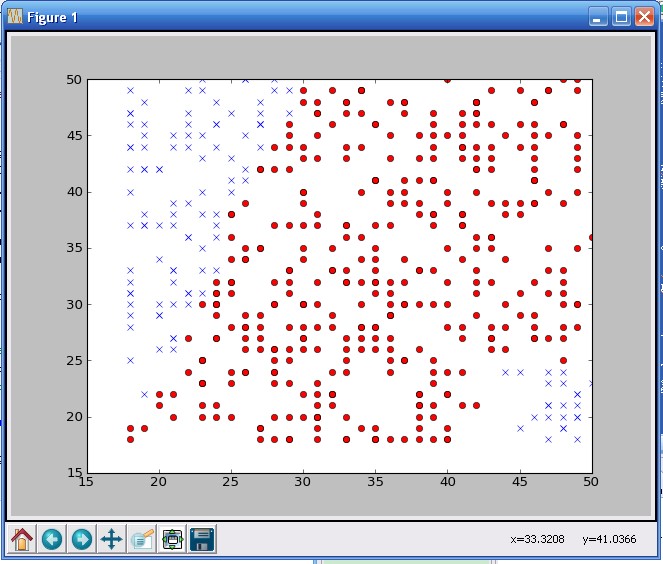
二、用matplotlib 图示化 刚刚加载的数据
三、 实现一个线性分类器:并预测
四、将两个婚介数据集 全部转换成数值数据
五、 对数据进行缩放处理
六、非线性分类,引入核函数
七、把svm应用到婚介数据集中
下面具体细说步骤:
一、加载数据,将exceld形式数据 加载成 数据结构 行格式
将婚介数据每一行都定义成一个类,类具备profiledata 和 ismatch 两个属性:profiledata表示人物信息,ismatch表示两个人是否匹配成成功。
以后处理上面两个数据集ageonly.csv和matchmaker.csv 或新来的预测行,都说先转成行,行再转成类格式。
class defineMatchoneRow: ''' 此类作用是:定义已经转换成行格式的 媒介数据的属性变量,该类就只有一个方法__init__,定义两个变量:data和match. data表示人物信息,match表示两个人是否匹配成成功 #这里定义数据的一行。 ''' def __init__(self, listRow): #传入去的是数组列表 self.profiledata = listRow[0:len(listRow)-1] #使用切片复制:根据数据文件内容,媒介信息就是0到倒数第二个。倒数第一个信息是表示二人是否匹配对了。 self.ismatch = int(listRow[len(listRow)-1]) #这里一定要转换成int()类型,若不转换,则是string类型。会完全影响下面的图片输出结果。这一步非常重要。 def loadmatchdata(filepath): ''' 读filepath两个数据集文件,读成行格式。 返回:rows。 其中rows有两个属性,一个属性是profiledata,存的是二人个人信息,另一个属性是match表示二人是否匹配成功 ''' rows = [] for line in file(filepath): terms = line.split(',') row = defineMatchoneRow(terms) #定义数据的一行。 注意row就是一个类definematchrow。 rows.append( row) #将这个数据集信息(profiledata,ismatch)加入到了rows去。 rows里的每个元素是一个类 #rows.append((matchrow.profiledata , matchrow.ismatch)) #也可以以元组形式将媒介数据加入rows去 return rows
print "加载agesonly.csv数据集" agesonly = loadmatchdata( "agesonly.csv")
二、图示化刚刚加载的数据
将第一步从excel转换而来的行数据,进行可视化 ,以图显示出数据。显示出男女媒介匹配情况。
用到matplotlib第三方库,可对某些变量可视化。
最后返回一张图。
matplotlib(是取代matlab的工具)安装步骤如下:
先装numpy,再装matplotlab.
去官方网站下载matplotlab与python相对的exe,点击运行即可。一步搞掂
''' 定义可视化数据函数 ''' from pylab import * def plotagematches(rows): xdm,ydm=[r.profiledata[0] for r in rows if r.ismatch==1], [r.profiledata[1] for r in rows if r.ismatch==1] xdn,ydn=[r.profiledata[0] for r in rows if r.ismatch==0], [r.profiledata[1] for r in rows if r.ismatch==0] plot(xdm,ydm,'ro') #表示red 以0型显示 匹配成功 这部分数据 plot(xdn,ydn,'bx') #表示blue 以x型显示 双方不匹配 这部分数据 show() #读agesonly.csv文件,将年龄匹配信息图示化: agesonly = loadmatchdata( "agesonly.csv") #matchmaker = loadmatchdata( "matchmaker.csv") for i in range(len(agesonly)): print agesonly[i].ismatch print "对ageonly.csv文件图示化:" plotagematches( agesonly )
将agesonly.csv图示化:
三、 在用svm分类器之前,先实现一个线性分类器:并用这个线性分类器 预测 试验
完成一个线性分类器:
工作原理: (关键词: 每个类的均值点 )
寻找每个分类中所有数据的平均值,并构造一个代表该分类中心位置的点。(凡是有涉及到代表点的,一定是要用字典,字典的key表示类别,value表示均值点。 分类一定要经常用字典),
然后判断距离哪个中心点位置最近 来对新的坐标点进行分类.(用点积距离作比较距离)
问题:
1.这个线性分类器用哪个数据集呢?
答:用agesonly. 因为matchmaker.csv 很多属性还没量化。agesonly是纯数值数据,所以先用它作试验
2.怎样构造每个类的代表点呢?
答:代表点即是均值点。凡是有涉及到代表点的,一定是要用字典,字典的key表示类别,value表示均值点。 分类一定要经常用字典
步骤(1):得到agesonly数据集所有坐标的分类(一个坐标就是数据集一行)
(2):计算每个分类包含的坐标总个数
(3):计算坐标总和除以坐标个数 即等于 均值点
3.如何判断新的坐标 与均值点的距离(见dpclassify函数)
用向量点积作为距离衡量。而不用欧式距离或pearson距离。
4. 向量点积怎么做衡量的??
实现代码时,注意“=”赋值符号是否要用切片[:]!!!
def linearTrain(datarows): ''' 该函数输入要训练的数据,返回一个列表avgs,包含所有分类的均值点
datarows 有两个属性:data列表和ismatch整数变量。 将语料进行分类训练,应该用字典。
''' #用字典表示每个类的总坐标数和总坐标值 average = {} count = {} for r in datarows: # c表示分类 c = r.ismatch #初始化字典 average.setdefault(c , [0.0]* len(r.profiledata)) #最后取的是data的长度,这里长度是2 。所以这里value相当于是[0.0,0.0] count.setdefault(c , 0) data = average[c] #用”=“,则表示data改变,average[c]也会改变。所以一定要小心!! 赋值的时候是要浅赋值还是深赋值 data[0] += float(r.profiledata[0]) #数组data的第一个元素 data[1] += float( r.profiledata[1]) # average[c] = profiledata #因为上面用的是”=“,则表示data改变,average[c]也会改变。所以这句话写了也等于没写。所以一定要小心!! 赋值的时候是要浅赋值还是深赋值 #记录每个类的坐标总数 count[c] += 1 #坐标总和除以总个数,等到平均值 for cl,avg in average.items(): #这种形式,c1和avg改变了都会直接跟着改变average的值。 for i in range(len(avg)): avg[i]/=count[cl] return average def dotproduct(v,ve): ''' 该方法实现点积:传入的是两个向量v=(a0,a1,a2...) ,ve=(b1,b2,b3...) 则v*ve = a0*b0 + a1*b1 +... ''' return sum([v[i]*ve[i] for i in range(len(v)) ]) def dpclassify(newpoint,avgs): ''' 该方法是根据点积结果来作为分类的距离。 传入参数:newpoint表示将要分类的点,是坐标(x,y),avgs表示当前所有分类的均值点.其中avgs是字典,key为婚介匹配分类0或1,value表示各类对应的均值点 返回的是:newpoint对应的类别. 分类点积公式:class = sign( x*m0 - x * m1 +( m0*mo -m1*m1)/2 ) 其中x表示newpoint 为什么公式是这样的?
''' b = (dotproduct(avgs[1],avgs[1]) -dotproduct(avgs[0], avgs[0]) ) /2 y = dotproduct( newpoint,avgs[0]) -dotproduct(newpoint, avgs[1]) + b if y>0: return 0 #为什么y>0表示匹配类型0呢,表示不匹配呢?因为y表示正弦sin,夹角大于90度为正?? else: return 1 from Aloaddata import * avgs = linearTrain(agesonly)
print " 线性分类训练,得到各分类对应的均值点是:(字典key表示是否匹配分类,value表示各类对应的均值):" print avgs #print avgs[1] print "\n输入如下新的预测点,根据点积结果,来预测分类结果:" print dpclassify([30,25], avgs) print dpclassify([25,40], avgs) print dpclassify([48,40], avgs)
运行结果是:
线性分类训练,得到各分类对应的均值点是:(字典key表示是否匹配分类,value表示各类对应的均值): {0: [26.914529914529915, 35.888888888888886], 1: [35.480417754569189, 33.015665796344649]} 输入如下新的预测点,根据点积结果,来预测分类结果: 1 0 1
四、将两个婚介数据集 全部转换成数值数据
matchmaker.csv数据文本包含了数值数据和分类数据,应该全部数值量化它
补充:决策树可以处理数值数据和分类数据(yes,no)。但其他分类器只能处理数值型分类器。所以其他分类器如svm,一定要将数据转成数值类型!!!
分类数据举例:
1.如”是否“问题这类数据,转换成数值类型 见yesnodata函数
2.将兴趣字符数据转换成数值类型interestmatchcount 函数:传入参数是两个人的兴趣列表,返回的是相同兴趣个数。
在数据集里记录人们的兴趣爱好,最简单方法是将每一种可能的兴趣爱好都视单独的数值变量,如果人们具备某一项兴趣,则设为1,否则为0. 假设对一个人一个人单独处理,这样做最合理。 但在媒介数据集中,要处理的是一对一对的人, 所以更直观方法是将具备共同兴趣爱好的数据视为变量
3. 计算两个人的地址距离,用yahoo map的API来计算 两个人居住地址距离(计算居住地址的经度和纬度)
def yesnodata(v):
''' 将分类数据如”是否“问题这类数据,转换成数值类型 ''' if v =="yes" :return 1 elif v =="no" :return -1 else: return 0 def interestmatchcount(interest1,interest2): ''' 本函数:将兴趣字符数据转换成数值类型。传入参数是两个人的兴趣列表 ''' #将兴趣列表分隔,list1和list2都表示兴趣数组 list1 = interest1.split(":") list2 = interest2.split(":") count =0 for i in list1: if i in list2: count +=1 return count ''' 下面用yahoo的map的API来计算 两个人居住地址距离(计算居住地址的经度和纬度) ''' yahookey="YOUR API KEY" from xml.dom.minidom import parseString from urllib import urlopen,quote_plus loc_cache={} def getlocation(address): if address in loc_cache: return loc_cache[address] data=urlopen('http://api.local.yahoo.com/MapsService/V1/'+\ 'geocode?appid=%s&location=%s' % (yahookey,quote_plus(address))).read() doc=parseString(data) lat=doc.getElementsByTagName('Latitude')[0].firstChild.nodeValue long=doc.getElementsByTagName('Longitude')[0].firstChild.nodeValue loc_cache[address]=(float(lat),float(long)) return loc_cache[address] def milesdistance(a1,a2): lat1,long1=getlocation(a1) lat2,long2=getlocation(a2) latdif=69.1*(lat2-lat1) longdif=53.0*(long2-long1) return (latdif**2+longdif**2)**.5 def loadnumericaldata(): ''' #将Aloadmatchdata模块的数据集传进来,等会全部数据类型都转成数值类型 这里先调用了在模块A中,已经将excel格式转换成数据结构形式的数据oldrows。 一行数值数据分布是:7个特征: newrow = [28.0 , -1 ,-1 ,26.0,-1,1,2] 年龄d[0]),yesnodata,yesnodata(d[2]),年龄(d[5]),yesnodata(d[6]),yesnodata(d[7]), interestmatchcount(d[3], d[8]), row.ismatch ] ''' oldrows = loadmatchdata("matchmaker.csv") newrows = [] for row in oldrows: d = row.profiledata #将每一行的数据的所有数据类型转换成数值类型 data = [float(d[0]),yesnodata(d[1]),yesnodata(d[2]), float(d[5]),yesnodata(d[6]),yesnodata(d[7]), interestmatchcount(d[3], d[8]), # milesdistance(d[4], d[9]), row.ismatch ] #将data转换成defineMatchoneRow 类 classinstance = defineMatchoneRow(data) #这样新的rows列表每个元素都是一个类类型。有data和ismatch两个属性 newrows.append(classinstance) return newrows ##单独运行此模块时,将下面注释去掉即可 ##获取整个matchmaker.csv数据集转换后的数值数据 numericalset = loadnumericaldata() #print " 输出matchmaker.csv第一行数据全部转换成的数值数据:" ##help(numericalset[0]) #print numericalset[0].profiledata
print numericalset[0].ismatch
五、 对数据进行缩放处理
把所有数据缩放到一个尺度,从而使每个变量上的差值具有可比性。
通过确定每个变量的最大最小值,对数据进行缩放,使最小值为0,最大值为1。
缩放具体方法:
先找出所有变量各自对应的最小值,并从该变量所有数值中减去这个最小值,从而将值域范围
调到0起点,函数随后将调整后的结果除以最大最小值之差,从而将所有数据转换成0到1之间的值。
from CLinearClassification import linearTrain, dpclassify
def scaledata(rows): '''
对数值数据(全部数据要转为数值类型才可调用此函数)进行缩放处理
并且函数里再定义一个函数,用来缩放一行的数据。这个函数中的函数可以用在预测数据输入中
这里 函数里也定义了一个函数 scalelineinput.表示对单独一行进行缩放处理的函数 ''' newrows = [] #找出每个变量的所有数值里的最值 lowest = [99999999.0]*len(rows[0].profiledata) highest = [-99999999.0]*len(rows[0].profiledata) for r in rows: d = r.profiledata for i in range(len(d)): if d[i]< lowest[i]: lowest[i] = d[i] if d[i] > highest[i]: highest[i] = d[i] def scalelineinput(d): '''
对数据进行缩放处理 用一个函数代替,使该行的值得数值范围变为0到1。 这里的d仍然是r.profiledata ''' return [(d[i]-lowest[i])/(highest[i]-lowest[i]) for i in range(len(lowest))] #也可以直接写缩放处理,不用上面缩放函数。数值范围变为0到1 for r in rows: d = r.profiledata[:] #用切片赋值,则下面的d改变了也不会影响到原来的rows的数据 for i in range(len(d)): d[i] -= lowest[i] d[i] /= float(highest[i]-lowest[i]) classinstance = defineMatchoneRow(d + [r.ismatch] ) #这里一定要在r.ismatch加上“[]”号,不然类型不匹配,是出错的。这样最难找出原因。 newrows.append(classinstance ) return newrows ,scalelineinput from DswitchDatatoNumericalData import * #对matchmaker.cscv文件数值数据进行缩放处理 scaledset ,lineScaleFunction = scaledata(numericalset) avgs = linearTrain(scaledset)
print " 对对matchmaker.cscv文件数值数据集缩放处理之后的均值点是:\n",avgs print " \n没缩放之前的数值数据第一行数据是:\n",numericalset[0].profiledata print " \n缩放之后的数值数据第一行数据:\n", scaledset[0].profiledata print "\n dpclassify点积函数传入参数:newpoint表示将要分类的点的坐标(x,y),avgs表示当前所有分类的均值点" print dpclassify(lineScaleFunction(numericalset[0].profiledata),avgs)
#print "到此为止,都是实现线性分类器。核函数还没开始"
输出结果是:
对对matchmaker.cscv文件数值数据集缩放处理之后的均值点是: {0: [0.44512959866220736, 0.1705685618729097, 0.0, 0.0, 0.0, 0.0, 0.0], 1: [0.5475746268656716, 0.17910447761194029, 0.0, 0.0, 0.0, 0.0, 0.0]} 没缩放之前的数值数据第一行数据是: [39.0, 1, -1, 43.0, -1, 1, 0] 缩放之后的数值数据第一行数据: [0.65625, 1.0, 0.0, 0.78125, 0.0, 1.0, 0.0] dpclassify点积函数传入参数:newpoint表示将要分类的点的坐标(x,y),avgs表示当前所有分类的均值点 1
六、进入非线性分类,引入核函数
从此步开始 ,才开始处理matchmaker.csv转换后的数值数据集,将个人profiledata信息进行预测了
核函数的思想同样也是利用点积运算,它用一个新的函数来取代原来的点积函数,当借助某个映射函数,将数据 第一次 变换到更高纬度的坐标空间时,新函数将返回高纬度坐标内的点积结果。 这里写径向基函数Radial-basis function: rbf函数与点积类似,它接受两个向量作为输入参数和一个gamma参数,返回一个标量值。 (调整gamma参数可得到一个针对给定数据集的最佳线性分离) 与点积不同的是,rbf函数式非线性的,所以它能将数据映射到更复杂的空间 因为线性分类器要求我们需要一个新的函数求坐标变换后的空间与均值点的距离 但无法直接这样计算,前人发现规律: 先对一组向量 求均值,再计算 均值与向量A 的点积结果 ,与
先对向量A 与 该组向量中的每个向量 求点积 ,再计算均值,效果是等效的。 所以不需对尝试分类的两个坐标点求点积来计算某个分类的均值点,而是计算某个坐标点与分类中其他每个坐标点之间的点积或径向基函数的结果,再对他们求均值。见nonlinearclassify函数
from pylab import * from DswitchDatatoNumericalData import numericalset def rbf(v1,v2,gamma=20): ''' rbf函数与点积类似,它接受两个向量作为输入参数和一个gamma参数, 返回一个rbf标量值。 (调整gamma参数可得到一个针对给定数据集的最佳线性分离) 与点积不同的是,rbf函数式非线性的,所以它能将数据映射到更复杂的空间 ''' dv = [float(v1[i])- float(v2[i]) for i in range(len(v1))] length = veclength(dv) # 这里的math是从numpy那里来的,是from pylab import *得到的。 这里**是表示指数。**后面的是指数的右上角数 return math.e**(-gamma * length) def veclength(v): ''' 计算一个向量的长度 ''' #注意sum(v)函数的参数是一个列表。此外**是表示指数。是from pylab import *得到的。 return sum([i*i for i in v ])**0.5 def getoffset(rows , gamma = 10): ''' 这函数是返回偏移量,为非线性分类器准备。(偏移量有何用??) 因为核函数会转换空间,偏移量offeset参数,会在转化后空间中发生改变, 在计算过程中会很费时,所以预先为某个数据集计算一次偏移量,然后每次调用nonlinearclassify将其传入 ''' #将匹配和不匹配的数据行分开 list0 = [] list1 = [] for row in rows: if row.ismatch ==0: list0.append(row.profiledata) else: list1.append(row.profiledata) #定义婚介匹配和不匹配的移位.两个for都是同一个list0或list1相乘 sumclassify0 = sum(sum( [rbf(v1, v2, gamma) for v1 in list0 ] )for v2 in list0) sumclassify1 = sum(sum( [rbf(v1, v2, gamma) for v1 in list1 ] )for v2 in list1) return (1.0 / len(list1)**2 ) * sumclassify1 - (1.0 / len(list0)**2 ) * sumclassify0 def nonLinearClassify(point,rows,offset,gamma=10): ''' 传入的参数是:要预测的点point,和已有的训练数据集rows,以及数据集偏移量offset.调整gamma参数可得到一个针对给定数据集的最佳线性分离)
为什么需要计算数据的偏移量呢??
''' #定义每个类别的rbf值总和 sumclassify0 = 0.0 sumclassify1 = 0.0 #定义每个类别的实例个数 countclassfiy0 = 0 countclassfiy1 = 0 for row in rows: if row.ismatch == 0 : sumclassify0 += rbf(point , row.profiledata ,gamma) countclassfiy0 += 1 else : sumclassify1 +=rbf(point, row.profiledata, gamma) countclassfiy1 += 1 y = (1.0/countclassfiy0) * sumclassify0 - (1.0/countclassfiy1)*sumclassify1 + offset if y > 0: return 0 #为什么y>0返回0? else : return 1 #from Aloaddata import agesonly #offset = getoffset(agesonly) #print "#只考虑年龄因素,调用agesonly.csv: #print nonLinearClassify([48,20], agesonly ,offset) #分类器已经识别了年龄差距大,不会成功匹配 print "调用matchmaker.csv训练数据集,使用其缩放处理过后的数值数据集scaledset:\n" from EScaleTheDataNormalizing import * scaledsetoffset = getoffset(scaledset) print " \n建立新预测数据:男士不想要小孩,女士想要:预测分类是:" newrow = [28.0 , -1 ,-1 ,26.0,-1,1,2] #新数据格式:年龄d[0]),yesnodata,yesnodata(d[2]),年龄(d[5]),yesnodata(d[6]),yesnodata(d[7]),interestmatchcount(d[3], d[8]), print nonLinearClassify(lineScaleFunction(newrow), scaledset, scaledsetoffset) print " \n建立新预测数据:男士想要小孩,女士想要:预测分类是:" newrow = [28.0 , -1 ,1 ,26.0,-1,1,2] #新数据格式:男年龄28,抽烟-1,要孩子1,女年龄26,抽烟-1,要孩子1, 共同兴趣项目数2 print nonLinearClassify(lineScaleFunction(newrow), scaledset, scaledsetoffset)
核函数预测结果是:
调用matchmaker.csv训练数据集,使用其缩放处理过后的数值数据集scaledset:
建立新预测数据:男士不想要小孩,女士想要:预测分类是:
0
建立新预测数据:男士想要小孩,女士想要:预测分类是:
1
七、把svm应用到婚介数据集中
安装libsvm2.89 +Python2.6 (具体python+libsvm安装件上一篇博文)
步骤: 1. 先将数据集scaledset转换成svm_model所要求的列表元组:格式是:前面是分类,后面是数据 2. 选用RBF核函数,模型训练,预测。 3. 预测可以自动写预测数据,也可以用libsvm自带的cros_validation功能自动计算训练集的准确率
用svm自带的交叉验证会将 据集自动划分成训练集和测试集,训练集自动构造出训练模型,测试集对模型进行测试。
该函数接受一个参数n,将数据集拆分成n个子集,函数每次将一个子集作为测试集,并利用所有其他子集对模型进行训练,最后返回一个分类结果列表,我们可以将该分类结果列表和最初的列表对比
from EScaleTheDataNormalizing import * from svm import * #先将数据集scaledset转换成svm_model所要求的列表元组:格式是:前面是分类,后面是数据 classifyanswers,inputs = [ r.ismatch for r in scaledset] ,[r.profiledata for r in scaledset] #选用RBF核函数: param = svm_parameter(kernel_type = RBF ) #param = svm_parameter(kernel_type = POLY) #param = svm_parameter(kernel_type = SIGMOID) #param = svm_parameter(kernel_type = PRECOMPUTED) prob = svm_problem(classifyanswers , inputs) #模型训练 m = svm_model(prob , param) #预测 print " \n建立新预测数据:男士不想要小孩,女士想要:预测分类是:" newrow = [28.0 , -1 ,-1 ,26.0,-1,1,2] #新数据格式:年龄d[0]),yesnodata,yesnodata(d[2]),年龄(d[5]),yesnodata(d[6]),yesnodata(d[7]),interestmatchcount(d[3], d[8]), print m.predict(lineScaleFunction(newrow)) #先要将这一行新预测数据缩放处理,所以lineScaleFunction print " \n建立新预测数据:男士想要小孩,女士想要:预测分类是:" newrow = [28.0 , -1 ,1 ,26.0,-1,1,2] #新数据格式:男年龄28,抽烟-1,要孩子1,女年龄26,抽烟-1,要孩子1, 共同兴趣项目数2 print m.predict(lineScaleFunction(newrow))
''' 下面使用svm自动提供了交叉验证功能:------------------------- ''' classifypreditiones = cross_validation(prob, param, 4) #将训练集分成4个子集,每个子集轮流作为测试集。这个参数n会影响到正确率的,当n=10,该实验准确率为85.6 print '交叉验证自动生成的数据预测结果是:\n',classifypreditiones #计算预测正确的个数 print "数据的行数一共是有:\n",len(classifyanswers) print '预测正确的个数有:' rightdata = [ 1 for i in range(len(classifyanswers)) if classifyanswers[i] == classifypreditiones[i]] print sum(rightdata) print "预测错误的个数有:" print sum([ abs (classifyanswers[i]-classifypreditiones[i]) for i in range(len(classifyanswers)) ]) print "所以svm准确率是: " ,float(sum(rightdata))/len(classifyanswers)*100,"%"
运行结果是:
建立新预测数据:男士不想要小孩,女士想要:预测分类是: 0.0 建立新预测数据:男士想要小孩,女士想要:预测分类是: 1.0 交叉验证自动生成的数据预测结果是: [0.0, 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, ........ ] 数据的行数一共是有: 500 预测正确的个数有: 417 预测错误的个数有: 83.0 所以svm准确率是: 83.4 % 不同核函数对比结果: 最终用RBF核函数 svm结果只有83.4%准确率 最终用POLY多项式核函数 svm结果只有73.6%准确率 最终用PRECOMPUTED核函数或SIGMOID核函数, svm结果都是只有59.8%准确率 综上,核函数最好效果的还是RBF, 准确率为83.5%

 浙公网安备 33010602011771号
浙公网安备 33010602011771号