
awk实例
本文旨在通过一个数据转换为SQL语句的实例,快速回顾awk的功能和语义
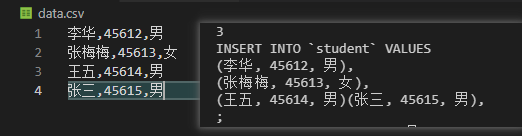
在data.csv中有以下4行数据,现要将其生成sql语句,将数据插入到student表中
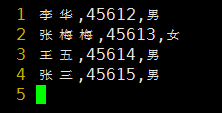
下面是awk程序
// @file sqlGen
BEGIN { FS="," # 设置字段分隔符
print "INSERT INTO `student` VALUES" } # 打印SQL语句
{
if(NF != 0)
printf "('%s', %d, '%s')", $1, $2, $3 # 格式化输出数据字段 '%s'
if(NR != lines)
print ","
}
END { print ";" }
从下面结果中可以看到,获得了正确的sql语句
不要忘了SQL语句中字符串的引号''!!!
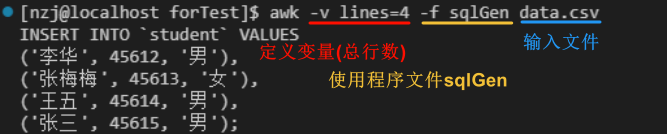
程序结构分析
awk程序由规则构成
下面黄色的BEGIN/END rule是在awk程序启动时(在所有输入读取之前)/结束时(在所有输入读取完毕之后)触发的规则
这两个规则只会被执行一次
而中间绿色的规则,则是对于匹配成功的记录触发的
可以看到该条绿色的规则,省略了匹配的模式,这意味着将对所有记录执行该规则中的动作
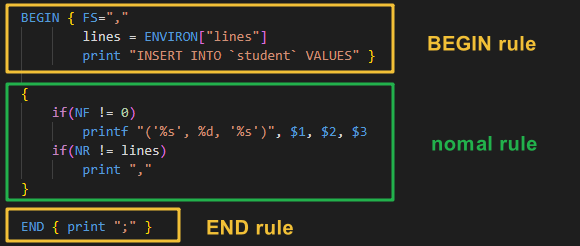
加入到shell脚本
下面是优化过的,鲁棒性高的版本,防止了wc统计与数据行数不匹配的bug
_file="data.csv"
sed -i /^$/d "$_file" # 删除多余空行
export lines=`sed -n $= "$_file"` # 将行数导出为环境变量
awk '
BEGIN { FS="," # 设置字段分隔符
lines = ENVIRON["lines"] # 初始化文件行数变量
print "INSERT INTO `student` VALUES" } # 打印SQL语句
{
if(NF != 0)
printf "(\x27%s\x27, %d, \x27%s\x27)", $1, $2, $3 # 格式化输出数据字段
if(NR != lines)
print ","
}
END { print ";" }
' data.csv
单引号
'需要使用ASCII的数值进行转换了
可能的bug
set和export的区别?
- 使用
wc命令统计行数
wc -l data.csv | awk 'print $1'
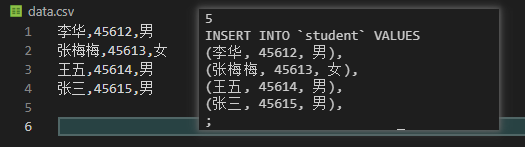
使用wc命令统计行数出现bug的原因是,wc统计的是换行符的个数,这意味着这并不总是等于行数
这种情况下,存在4个换行符,与实际数据行数相同,可以生成正确结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号