
C中级 数据序列化简单使用和讨论 (二)
引言 - 一种更好的方式
其实不管什么语言, 开发框架都会遇到序列化问题. 序列化可以理解为A 和 B 交互的一种协议.
很久以前利用 printf 和 scanf 的协议实现过一套序列化问题.
本文在上面基础上运用一种新的尝试. 具体的思路是 利用编译器对结构的统一内存编码方式.
具体实现通过进出栈宏 #pragma pack(push, 1) ... #pragma pack(pop) 设置结构体编译器的编码方式.
#pragma pack(push, 1) struct person { int id; char sex; int age; char name[65]; double high; double weight; }; #pragma pack(pop)
当编译器解析 struct person 的时候, 采用1字节对齐. 保证结构体编解析后二进制数据是一样的(VS 和 GCC测试过).
这是不同系统间通信的不变量之一. 通过这种序列化的思路. 不妨设计一个验证的Demo如下
window 生产者代码
// 设置数据, 开始写到测试文件中,再去读取 struct person per = { 1, 1, 19, "simplec王志", 179.0, 70.1 }; // 这里开始写数据到文件中. const char * path = "person.txt"; FILE * txt = fopen(path, "wb"); if (NULL == txt) exit(EXIT_FAILURE); fwrite(&per, sizeof(struct person), 1, txt); fclose(txt);
linux 使用者代码
const char * path = "person.txt"; FILE * txt = fopen(path, "rb"); if (NULL == txt) exit(EXIT_FAILURE); struct person np; fread(&np, sizeof(struct person), 1, txt); printf("[%d, %d, %d, %s, %lf, %lf]\n", np.id, np.sex, np.age, np.name, np.high, np.weight); fclose(txt);
实际运行的结果展示.

不知道你是否感到好奇, 为啥最终结果不对呢. 这就扯出了, 编程开发中所有老鸟都必须要面对的坑. "编码统一的坑".
为了将问题表述的更明白, 再来个Demo. sizeofname.c
#include <stdio.h> #include <wchar.h>
int main(int argc, char * argv[]) { // 系统默认编码, 一共 2 + 3 + 7 + 1 = 13 个 字符 char as[] = "王志 - simplec"; // 采用宽字节, 2字节表示一个字符 wchar_t bs[] = L"王志 - simplec"; // 采用UTF-8编码, 重要 ☆ char cs[] = u8"王志 - simplec"; printf("sizeof as = %zu.\n", sizeof as); printf("sizeof bs = %zu.\n", sizeof bs); printf("sizeof cs = %zu.\n", sizeof cs); return 0; }
在window 上运行结果如下, 我的系统默认是gbk编码(ascii码扩充版). 如果装英文版window默认是utf-8.
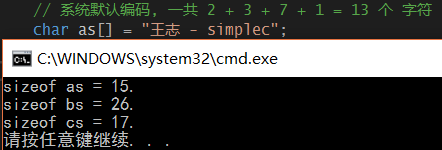
中间扯个淡. 我的VS设置中默认是 unix utf-8 有 BOM 文件编码格式. 详细配置可以参照这篇博客 - Visual Studio 默认保存为UTF8编码
在linux上测试结果如下, linux默认UTF-8编码

通过上面你也可以看出来, 主要问题是编码不一致导致了乱码. 最终使fread解析出错. 那么随后就开始解决这个问题.
前言总结
1. #pragma pack(push, 1) ... #pragma pack(pop) 是一种 C/C++ 系统间直接序列化的一种高效手段
2. 系统编码推荐统一采用 UTF-8. linux 默认就是, window 中文版是gbk.
下面将提出一种编码统一的方案. 到这里基本可以了, 后面可以选看. O(∩_∩)O哈哈~
前言 - 需要一些帮助,刚好我已经做了
以前有个GNU 的 libiconv 跨平台的库可以解决不同平台的编码问题. 其最近版本对window不再提供直接支持了.
这里我将其继续拉取到window上了搞了一通,最终生成libiconv.lib. 具体可以看下面项目
libiconv-for-window https://github.com/wangzhione/libiconv-for-window
工程详细的配置步骤如下
======================================================================== 静态库:libiconv for window 项目概述 ======================================================================== ///////////////////////////////////////////////////////////////////////////// 当前移植项目基于 GNU 项目 libiconv-1.15 | http://www.gnu.org/software/libiconv/ 移植到平台 window 10 14393.953 | Visual Studio 2017 项目发起人 : simplec - wz | wangzhione@163.com ///////////////////////////////////////////////////////////////////////////// 具体操作思路: 1. 从官网下载资源 libiconv压缩包, 并解压 [xxx = 解压后的详细path] 2. 在 $(ProjectDir) 项目目录下, 新建 include 目录 2.1 将压缩包中 xxx/include/iconv.h.build.in 复制到 include 目录下, 并重名为 iconv.h 2.2 将 xxx/onfig.h.in 复制到 include 下, 名为 config.h 2.3 将 xxx/lib 下 所有 *.h and *.def 文件复制到 include 目录下 2.4 将 xxx/libcharset/include/localcharset.h.build.in 复制到 include 目录下, 并改名 3. 将 xxx/libcharset/lib/localcharset.c 拷贝到 $(ProjectDir) 目录下 4. 将 xxx/lib/iconv.c 拷贝到 $(ProjectDir) 目录下 5. 将 localcharset.c iconv.c iconv.h localcharset.h config.h 添加到项目中 6. VC++ 目录 -> 包含目录 add [$(ProjectDir)include] 进去 7. C/C++ -> 预处理器 -> add _CRT_SECURE_NO_WARNINGS 去掉不安全的调用 8. 常规 -> 生成目标名 -> 改成 libiconv , Debug下为 libiconvd 详细编译修改步骤: 1. iconv.h 修改 1.1 25 - 29 行 删掉, 30行删除无效宏 1.2 55 - 61 行 删掉 1.3 后面所有的 LIBICONV_DLL_EXPORTED 删掉 , 可以用全部替换 1.4 把后面所有的 @ICONV_CONST@ 删掉 1.4.1 全局删除 ICONV_CONST 1.5 后面遇到 @xxx@ 大段大段的删除 1.6 详细参照我最终的文件底版 1.7 将这个文件编码改成 UTF-8 有 BOM 模式, 我是用NotePad++转换的 2. localcharset.c 修改 2.1 79 - 83 行 删掉 3. localcharset.h 修改 3.1 20 - 26 行删除 3.2 31 行 无效宏删除 4. config.h 修改 4.1 28 - 30 行 删除, 回归 EILSEQ 5. 解决百个警告 5.1 我这个代码可以做1.15 window lib 库源码项目集 /////////////////////////////////////////////////////////////////////////////
通过上面操作, 基本上window上libiconv 项目就搞定差不多了. 后面简单扯个淡. iconv 一共有下面常用的三个接口
/* Allocates descriptor for code conversion from encoding ‘fromcode’ to encoding ‘tocode’. */ extern iconv_t iconv_open (const char* tocode, const char* fromcode); /* Converts, using conversion descriptor ‘cd’, at most ‘*inbytesleft’ bytes starting at ‘*inbuf’, writing at most ‘*outbytesleft’ bytes starting at ‘*outbuf’. Decrements ‘*inbytesleft’ and increments ‘*inbuf’ by the same amount. Decrements ‘*outbytesleft’ and increments ‘*outbuf’ by the same amount. */ extern size_t iconv (iconv_t cd, char* * inbuf, size_t *inbytesleft, char* * outbuf, size_t *outbytesleft); /* Frees resources allocated for conversion descriptor ‘cd’. */ extern int iconv_close (iconv_t cd);
上面函数英文解释的很详细, 更加详细的可以参看编码实现细节.
再扯一点的是, iconv 的 outbytesleft 输出的是 inbuf 接口已经转换的编码字节数.
说真的iconv linux上提供的接口设计很丑陋, 很恶心. linux的信号软中断, 真的是强奸我们的代码.
后面也提供了一个不是很漂亮的sciconv.h 帮助接口
#ifndef _H_SIMPLEC_SCICONV #define _H_SIMPLEC_SCICONV #include <iconv.h> #include <stdbool.h> // // iconv for window helper // by simplec wz // // // si_isutf8 - 判断当前字符串是否是utf-8编码 // in : 待检测的字符串 // return : true表示确实utf8编码, false不是 // extern bool si_isutf8(const char * in); // // si_iconv - 将字符串 in 转码, from 码 -> to 码 // in : 待转码的字符串 // len : 字符数组长度 // from : 初始编码字符串 // to : 转成的编码字符串 // rlen : 返回转换后字符串长度, 传入NULL表示不需要 // return : 返回转码后的串, 需要自己销毁 // extern char * si_iconv(const char * in, const char * from, const char * to, size_t * rlen); // // si_iconv - 将字符串数组in 转码, 最后还是放在in数组中. // in : 字符数组 // from : 初始编码字符串 // to : 转成的编码字符串 // return : void // extern void si_aconv(char in[], const char * from, const char * to); // // si_gbktoutf8 - 将字符串数组in, 转成utf8编码 // in : 字符数组 // len : 字符数组长度 // return : void // extern void si_gbktoutf8(char in[]); // // si_utf8togbk - 将字符串数组in, 转成gbk编码 // in : 字符数组 // len : 字符数组长度 // return : void // extern void si_utf8togbk(char in[]); #endif
方便协助开发. 到这里万事具备了.下面就开始搞了.
正文 - 解决国际化(编码)问题
上面已经解决了库的问题. 那我们开始搞一个demo 试试吧. 我们还是用上面的window生产者代码搞搞.
#include <stdio.h>
#include <stdlib.h>
#include <sciconv.h>
#pragma pack(push, 1)
struct person {
int id;
char sex;
int age;
char name[65];
double high;
double weight;
};
#pragma pack(pop)
//
// 测试数据序列化新思路,采用位对齐
//
int main(int argc, char * argv[]) {
// 设置数据, 开始写到测试文件中,再去读取
struct person per = {
1, 1, 19, "simplec王志", 179.0, 70.1
};
// 打印一下数据
printf("[%d, %d, %d, %s, %lf, %lf]\n",
per.id, per.sex, per.age, per.name, per.high, per.weight);
// 这里开始写数据到文件中.
const char * path = "person.txt";
FILE * txt = fopen(path, "wb+");
if (NULL == txt)
exit(EXIT_FAILURE);
si_gbktoutf8(per.name);
fwrite(&per, sizeof(struct person), 1, txt);
fclose(txt);
return EXIT_SUCCESS;
}
上传person.txt 到 linux上测试一下. linux 测试详细代码如下 personread.c
#include <stdio.h> #include <stdlib.h> #include <iconv.h> #pragma pack(push, 1) struct person { int id; char sex; int age; char name[65]; double high; double weight; }; #pragma pack(pop) // // 测试数据序列化新思路,采用位对齐 // int main(int argc, char * argv[]) { struct person np; // 这里开始写数据到文件中. const char * path = "person.txt"; FILE * txt = fopen(path, "rb"); if (NULL == txt) exit(EXIT_FAILURE); fread(&np, sizeof(struct person), 1, txt); fclose(txt); // 打印一下数据 printf("[%d, %d, %d, %s, %lf, %lf]\n", np.id, np.sex, np.age, np.name, np.high, np.weight); return EXIT_SUCCESS; }
最终实验结果一切正常, 欧耶OY

到这里解决方案的内容已经搞定了. 感兴趣的同学可以多看看关于上面 libiconv for window github 源码.
后记 - 下一步工作
错误是难免的, 这里多是讨论互相交流. 毕竟全部用国外的协议和标准. 感觉可惜 哈哈 ψ(*`ー´)ψ. 欢迎指正.
歌声与微笑 - http://music.163.com/#/m/song?id=395677&userid=16529894


