Java集合类初探
目录
概述
Java中基本的常用的集合类,主要包含:
- List
- Set
- Queue
- Map
这几种类型的继承关系如图: 图片引自——Collection 和 Map的继承体系

其中 List、Queue 和 Set 继承自 Collection 接口,这三种集合的结构都比较简单,都是普通的元素的集合,而 Map 相对复杂一点,是键值对(key-value)的结构。
Iterable和Iterator


Iterable
Iterable 接口是 Collection 接口的“超类”,也就是说 Iterable 接口是 List、Set、Queue 这类简单集合的顶级接口,看下 Iterable 接口有些啥:

Iterable 接口包含三个方法:
- iterator() 返回一个迭代器用于迭代、遍历集合;
- forEach(Consumer<? super T>) 增强型for循环,配合 lambda 表达式食用更香;
- spliterator() 同样返回一个迭代器,该迭代器是“可分割迭代器”,为并行遍历集合而设计。
Iterable 接口的 forEach() 和 spliterator() 方法是用 default 关键字修饰的,接口里包含了方法的默认实现。
Iterator
Iterator 也是一个接口,用于集合的遍历:

- hasNext() 是否还有下一个元素,用于控制集合的遍历的结束;
- next() 返回一个元素,游标往后移。
- remove() 去除当前的元素(最近一次调用 next() 返回的元素)。想要在遍历集合时删除元素,需要用到 Iterator 迭代器和该方法。
- forEachRemaining(Consumer<? super E>) 对剩下的元素(即尚未被遍历到的元素)进行某些操作。和 Iterable 接口的 forEach() 有点类似。
Collection
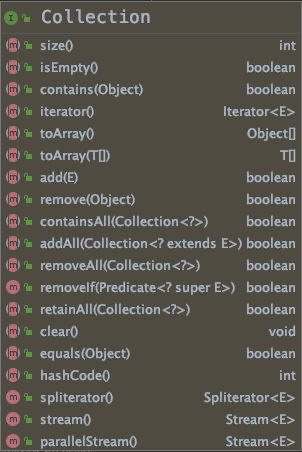
Collection 接口包含了集合的基本的增删查操作。既然是集合,那么以下基本方法是非常必要的:
- 获取集合大小: size();
- 添加元素: add();
- 移除元素: remove();
- 判断包含: contains();
- 判断元素是否相等: equals();
为了增加可用性,又加多了几个方法:
-
isEmpty() 判空,少写几句 "collection.size()==0";
-
containsAll() 判断是否包含另一个集合里的所有元素;
-
toArray()、toArray(T[]) 把集合转化为数组;
-
clear() 清除所有元素;
-
removeIf() 条件删除;
-
stream() 流操作;
-
removeAll() 取补集,把另一个集合也包含的元素去除;
-
addAll() 把另一个集合的元素添加进来,相当于取并集;
-
retainAll() 取交集,把另一个集合也包含的元素保留下来;
-
stream()、parrallelStream() 流操作、并行流操作。
List
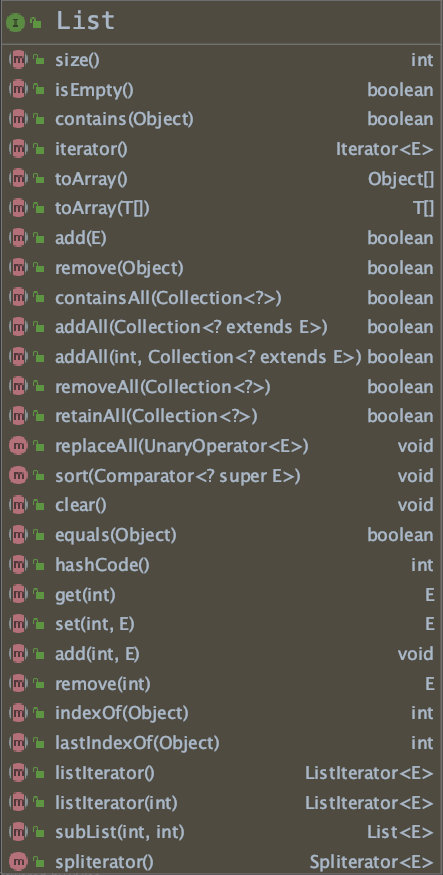
List 中文译作“清单、列表”,List 是有序的,是按照一定的顺序来存储元素的,既然是有序的集合,就应该可以通过“游标”来进行访问,因此,List 在 Collection 的基础上添加了通过游标访问元素,或通过元素获取游标的方法:
-
get(int);
-
add(int, E);
-
remove(int);
-
indexOf(Object);
-
subList(int, int);通过游标截取子序列。
-
lastIndexOf(Object); 因为 List 是有序的,所以可以通过“游标”确定唯一的元素,因此 List 是允许集合中包含相同(相等)的多个元素的,lastIndexOf(Object) 可以用来在集合包含多个相同元素时,获取该元素最后出现的位置。
除此之外,List 还加上了 Collection 没有的“改”操作,实现了集合的“增删查改”:
- set(int, E); 替换某个位置的元素,既然是替换,前提条件是该位置含有元素。
因为 List 是有序集合,因此给 List 加上排序操作是可取的:
- sort(Comparator<? super E>);
在List接口中有一个 “ListIerator()”的方法,该方法返回一个 ListIterator 对象。

ListIterator 继承了 Iterator 接口,提供了 previous 操作,以及与游标相关的 nextIndex() 和 previousIndex()。
Queue

Queue(队列)是一种特殊的线性表,有的时候我们会因为业务需求,需要一个“规定容量的Queue”,这时,如果队列满了却又要添加元素,该采取怎样的策略,或者队列为空时调用remove该如何处理,这是需要考虑的。Queue 继承了 Collection,又提供了几个自己的方法:
-
offer(E): 队尾添加元素,与 add 对应,当队列已满时返回false, add()方法这种情况下则会抛出异常。
-
poll(): 查询并删除队头元素,与 remove 对应,当队列为空时,不会像 remove 那样抛出异常,而是会返回 null;
-
element(): 查询队头元素但不删除,与 peek 对应,队列为空时抛出异常。
-
peek(): 查询队头元素但不删除,队列为空时返回 null;
Set
Set 中文是“一组、一套”的意思。与 List 相比,Set 没有 List 的“列表、清单”的“列”的语义。Set 是无序的。 Set 与 Collection 在语义以及属性上最为接近,Set 继承了 Collection 的方法,没有自己新添加的方法,如下所示:

Set 是没有 List 的 Index 的概念的,List 可以用 index 唯一确定一个元素,Map 可以用 key 唯一确定一个元素,而 Set 只能靠自身来唯一确定一个元素,所以 Set 里面的元素是不能重复的。正因为 Set 这一特性,可以使用 Set 给集合去重。
Map
在词典中,Map 作动词时是“映射”的意思,key-value,key 映射到 value,可以通过 key 来获取 value。Map 和 Iterable 一样是顶级接口。Map 接口 UML 图如下:
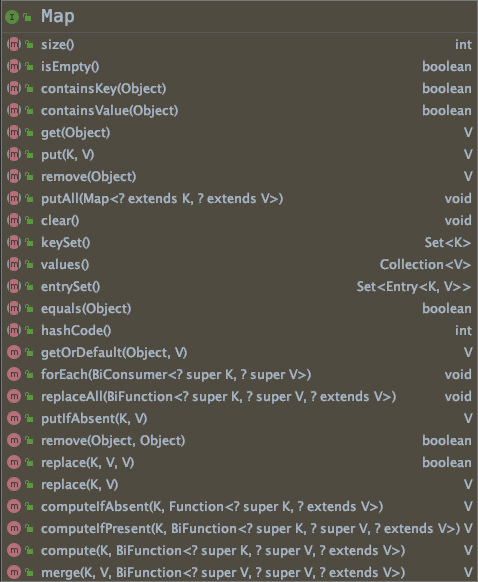
虽然 Map 是一个顶级接口,但是 Map 和 Set、List、Queue应该是同一层级的接口,它们的方法很多是类似的(功能上)。
基本的增删查改:
- size();
- isEmpty();
- containsKey();
- containsValue();
- get();
- put();
- remove();
- putAll();
- clear();
- replace()
键和值的遍历:
-
keySet(): 返回 key 的 Set 集合,因为 Map 靠 key 来唯一确定一个元素,所以 Map 的 key 是不能重复的,自然地,返回的 key 集合是一个 Set;
-
values(): value 的值不会影响到 Map 的结构,value 是可以重复的,也是可以为 null 的,所以返回的 value 集合应该是一个 Collection;
-
entrySet: 该方法返回的是 Entry 的 Set 集合, Entry 是 Map 的内部接口,可把其看作一对键值对的组合:
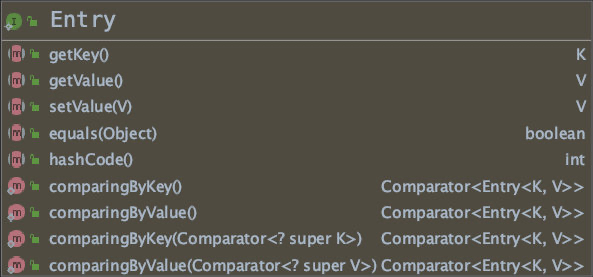
其它的方法:
-
getOrDefault(Object, V): 如果找到 key 为 object 的键值对,则返回其 value, 否则返回自己传入的 V;
-
putIfAbsent(K, V): 与 put(K, V) 对应,如果 Map 中已经包含 key 为 K 的键值对或键值对的值为空,put(K, V) 方法会用 V 覆盖原来的值;而 putIfAbsent(K, V)方法仅返回现在的值,不覆盖;当 Map 中不存在 key 为 k 的键值对时,put 和 putIfAbsent 都会添加新的元素。 概况说就是如果指定的键尚未映射(映射即关联,就是 key 和 value 的关联关系, value 为 null 也视为未映射或者说未关联),将其与给定值相关联并返回 null ,否则返回当前值。
-
compute(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction): 传一个BiFunction 对象进去实现值的“计算”,此处的“计算”应该是指“操作”,不仅仅是指算术上的“计算”。这与 VueJS 的“计算属性”有点类似。可以通过该方法实现 Map 数据的转换、数据的统计。
BiFunction是一个接口,关键方法和说明如下图所示,可配合 lambda 表达式,是函数式编程的思想。

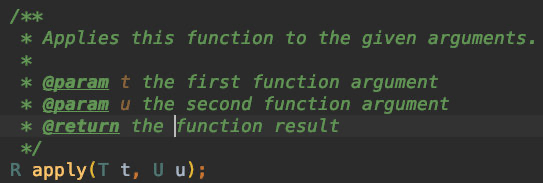

-
computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction): 同 putIfAbsent 一样,如果 key 未映射( value 为 null 也视为未映射),则尝试使用给定的映射函数计算其值,并将其输入到此映射中(即设置 value )。
-
computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction): Present 与 Absent 相反,前者是“存在”的意思,后者是“不在”的意思,顾名思义,该方法是在指定的 key 在 Map 中存在映射时,则尝试计算给定key 及其当前值的新值。
-
merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction): merge 其实与 compute 这几个方法的作用是一样的,对 key 映射的 value 值进行变换,只是该方法多提供了一个参数 “V value”,相当于用这个参数的 value 和 key 所对应的 value 结合(merge)起来一起变换;
比如想要让 Map 中存储的学生的年龄加“1”,使用 computer 的话,可以在函数里写定参数“1”;使用 merge 的话,可以在调用 merge 方法时把“1”传进去。这时,如果需求变了,年龄不是加“1”,而是加“2”,使用compute 方法的话需要到方法里面改这个“1”(magic num);而使用 merge 的话只需要在方法调用时改参数,不用改其它代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号