Nonebot2插件:非酋Plus,换卡池也改变不了的命
本文是上一篇 文章 的延伸,嗯
大概就是把前面没写好的其他功能都放上过来
其实是刚刚学会初步使用selenium练习一下qqqqq
代码丑陋功能冗杂性能占满,请轻点骂
广告
感觉随着zhenxun的热度没了确实看的群新人变少好多。又要看404群大佬互相讨论看不懂的问题了学无止境啊~
404群(720053992) 顺带给prts打广告,如果经常使用prts的话不妨去支持下网站维护费用
-1.前置题外话
本篇主要就是作者初步学习尝试selenium的副产物(?)
实现的依旧是mrfz的抽卡,只不过尝试适配一下池子更换,限定抽取。
所以会缩略一部分前面一篇文章提到过的内容,没看的先去阅读一下前文
大概就这么多,嗯
学不懂啊
0.tools
- selenium库——本次代码的核心库,用于模拟浏览器并进行一系列模拟操作
- lxml库——通过xpath快速定位需要找的元素
- json——输出成本地文件
- loguru——只是方便的日志输出第三方库,不是很需要
- xpath语法——至少得理解
1.Spider
首先还是选取的prts.wiki,毕竟功能太完善了
其他小广告
关于游戏内部的一些数据其实不太需要爬prts,github上有大佬按各个服务器整理了不同的游戏数据点我快速跳转
只是纯变量+非常长,里面的内容也很多,对于不是很需要的来说直接爬wiki就好
里面最方便的是对于每个干员都给了基础信息,描述,一些数值,还有技能专精材料
目前还没用到慢慢放着阅读了
prts对于卡池有专门的卡池一览 的页面,因此对于我们的爬取也十分方便了。
注意到mrfz的卡池分为常规卡池(常驻双up毒池)和限时卡池(在这里指常驻角色单up卡池/定向寻访/新年必new池/限定寻访卡池)
prts上也针对这两个卡池给了不同的页面
对于限时卡池,点进去之后发现很贴心的直接给出了所有的干员数据,因此只需要直接requests.get一下,然后用xpath找到需要的数据就好了
点我看限定卡池部分的代码
import requests
import re
import time
from loguru import logger
from lxml import etree
import json
url1 = "https://prts.wiki/w/%E5%8D%A1%E6%B1%A0%E4%B8%80%E8%A7%88/%E9%99%90%E6%97%B6%E5%AF%BB%E8%AE%BF"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66"
}
request = requests.get(url1, headers=headers).text
dom = etree.HTML(request, etree.HTMLParser())
data = dom.xpath("//div[@class='mw-parser-output']/table/tbody/tr")
limit_gacha_dict = {}
num = 0
for char in data:
try:
gacha_title = char.xpath("./td[1]/a[2]/text()")[0] # 获取获取卡池名字,用于切换卡池
if gacha_title == "联合行动":
gacha_title += str(num) if num else ''
num += 1
gacha_type = str(gacha_title).replace('【', '[').replace('】', ']') # 限定为啥是中文方框
# -> prts上爬干员上线时间一览非限定直接是池子名字了,但限定是[限定寻访]池子名字,还是不太好区分开来
if "跨年欢庆" in gacha_type:
# 这个东西prts上也要js点一下按钮,不想做了
# 反正是必new池,为了做出最好的符合卡池的效果要对每个人建立个数据库存储ta的干员仓库,暂时没这个想法(而且都会换池子了仓库有啥意义)
continue
if "限定寻访" in gacha_type:
limit_gacha_type = re.search("(?<=·)(.*?)(?=])", gacha_type).group() # 获取限定卡池隶属的类别,方便只出现对应会出现的干员
# 但还是没找到很好解决限定干员来历的方法
# 大概是针对限定干员,专门去爬一下ta的个人页面的上线卡池,并且把上线时间调到一年后(因为当期up不会被算在其他up里,所以直接按一年之后的算好了)
# 最后在获取基础信息那里搞了下
else:
limit_gacha_type = None # 不是限定这个参数就没啥必要
img_url = "https://prts.wiki" + str(char.xpath("./td[1]/a[1]/img/@data-srcset")).split()[-2]
start_time = str(char.xpath("./td[2]/text()")[0]).split(' ')[0] # 获取上线时间,只需要当天就行
up_six_operators = char.xpath("./td[3]/span/span/a/@title") # 获取up六星
try:
up_five_operators = char.xpath("./td[4]/span/span/a/@title") # 获取up五星(好像四星也被计入了emmm,懒得管了)
except:
up_five_operators = None # 新手卡池五星懒得做了,到时候读取到None就只读取开服的干员就好了
gacha_dict = {
"title": gacha_title, # 卡池名字
"img_url": img_url, # 卡池缩略图
"type": gacha_type, # 卡池类别,其实就是名字,只不过去掉了[标准寻访]
"limit_type": limit_gacha_type, # 限定卡池的类别,用于判断不同类别的限定干员是否会出现
"start_time": start_time, # 卡池开始时间,格式为xx-xx-xx(都是两位,不足补0,方便判断) ->主要是没有时间戳
"up_six_operators": up_six_operators, # up的六星
"up_five_operators": up_five_operators # up的五星和四星 ->其实没用到,未来用到了再说吧
}
limit_gacha_dict[gacha_dict['title']] = gacha_dict
# 寄,突然发现联合行动是一个名字 ->解决办法就用1234来按顺序吧
except Exception as e:
logger.debug(e)
with open('src/plugins/gacha/game_opreator_data/ark/限时卡池.txt', 'w', encoding='utf-8') as f: # 写在本地不用每次都爬
for j in limit_gacha_dict.values():
f.write(json.dumps(j, ensure_ascii=False))
f.write("\n")
目光转到常规卡池,啊很简单嘛,直接get一下
然后发现页面居然用了js加载按钮,那么简单的requests到这里不行了
小白的想法
我没找到对于这种很好的解决方法,一般对于模拟点击事件用requests库是通过抓包获取对应的url然后get,但很明显这里不适用有一个requests的升级库requests-html,可以支持JavaScript事件了
但有傻小白回去试了大半天一堆报错,还是爬回来写selenium了
update:破案了,上面那个小白往requests-html那个浏览器里扔了selenium用的chromedriver而不是应该用的Chromeium
但还是这个库还是只支持读取需要js加载完毕的,不支持模拟点击,所以对于这篇文档的实现还是用selenium吧
有需要的话可以参考下这篇文章关于render的说明
这时候就用到了selenium来模拟浏览器,进行点击操作了
不知道怎么配置的直接搜就好了,网上挺多
详细的部分代码里面说,一定掌握了xpath基础语法
from selenium import webdriver # 本次代码的核心
import logging
import time
from loguru import logger
from lxml import etree
import json
open_driver = webdriver.Chrome() # 有时间再换成无头浏览器吧
# open_driver = webdriver.Firefox()
# open_driver = webdriver.PhantomJS()
open_driver.get(
'https://prts.wiki/w/%E5%8D%A1%E6%B1%A0%E4%B8%80%E8%A7%88/%E5%B8%B8%E9%A9%BB%E6%A0%87%E5%87%86%E5%AF%BB%E8%AE%BF') # 打开prts常驻卡池一览
try:
data = open_driver.find_elements_by_xpath("//div[@class='collapsible-block-folded']/a")
# 获取所有展开按钮的位置,用xpath定位
# 一定要记得用elements! ->某个用element找不到问题的傻逼留
for i in data:
open_driver.execute_script("arguments[0].click();", i) # 用js的方式模拟点击
time.sleep(1) # 缓一下
except Exception as e:
logging.debug(e) # 报错了提示,不过应该不会,除非403或者400
time.sleep(5)
open_driver.close()
logger.info("开始爬取卡池数据") # 报一下情况
time.sleep(5) # 等待页面全部加载完全
try:
data = open_driver.page_source # 获取加载完毕后的当前指向网页源代码
dom = etree.HTML(data) # 转成xpath!beautifulsoup还不会
char_list2 = dom.xpath("//div[@class='mw-parser-output']/table/tbody/tr") # 这是所有卡池的位置
full_gacha_dict = {}
for i in char_list2:
try:
gacha_dict = {
'id': str(i.xpath("./td[1]/text()")[0]).split()[0], # 获取卡池序号用于切换卡池
'img_url': "https://prts.wiki" + str(i.xpath("./td[2]/a/img/@srcset")[0]).split()[-2], # 获取卡池图,懒得拼接了
'start_time': str(i.xpath("./td[3]/text()")[0]).split()[0], # 获取开始的时间戳,用于和干员上线时间进行比较从而确定卡池内干员
'up_six_operators': i.xpath("./td[4]/span/span/a/@title"), # 获取up的六星干员
'up_five_operators': i.xpath("./td[5]/span/span/a/@title") # 获取up的五星干员
}
"""
这里是写time的时候一个小记录
看prts加载的源代码看得到有用<br>分割
然而xpath读到<br>会自动断,从而text()不能获取全部 ->下面观察了下输出可以,但会分隔开来返回list了有点懒
这时候把text()换成descendant-or-self::text()就可以获取全部的文字了
但是会把换行符啥啥的都读进去,需要自己处理
然后发现比较的时候只需要记录池子开的时候就好了,所以没有用上面的方法(主要还是适配之前爬prts干员一览里的上线时间)
"""
full_gacha_dict[gacha_dict['id']] = gacha_dict # 放到dict里去
# logger.info(str(i.xpath("./td[3]/text()"))) # 测试用观察输出
except Exception as e:
# 由于每一个点击之后table第一行都会是具体信息,所以会报错啥的,不管继续就好了
logger.debug(e)
continue
with open('常驻卡池.txt', 'w', encoding='utf-8') as f: # 写在本地不用每次都爬
for j in full_gacha_dict.values():
f.write(json.dumps(j, ensure_ascii=False))
f.write("\n")
except Exception as e: # 出大问题,自己看报错
logger.debug(e)
open_driver.close() # 关闭浏览器
上面就是爬限时卡池了,然后是想办法解决限定干员的再次进池概率五倍提升和池子类别。 这部分整合到上一篇文章里提到的爬wiki里了,顺便把上面的两个也整到一起去了,放在文章最后面好了
2.换卡池
这部分就挺简单了,稍微用一个才知道的参数 CommandArg()
这个参数在 nonebot.params 里import,具体参考官方文档说明
参数得到的是message类的命令型消息命令后跟随的参数,会自动去除与指令中间的空格(不会影响参数里面的空格)
判断的时候转下str
才知道这个的用法,要考虑把前面的插件都重构一遍了
切换卡池部分,读取了的本地文件和以及跨文件调用函数,所以可能会有疑问
from nonebot import *
import json
import re
import math
import time
import json
from loguru import logger
from nonebot import *
from nonebot.adapters.onebot.v11 import Bot, Event, Message
from nonebot.params import CommandArg
async def handle_rule(bot: Bot, event: Event) -> bool:
with open("src/plugins/群名单.txt", encoding='utf-8') as file: # 提取白名单群文件中的群号
white_block = []
for line in file:
line = line.strip()
line = re.split("[ |#]", line) # 可能会有'#'注释或者空格分割
white_block.append(line[0]) # 新建一个表给它扔进去
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
if group_id in white_block or group_id == None:
return True
else:
return False
async def choose_gacha(name: str) -> dict: # 返回收到的卡池具体信息
normal_gacha = []
with open('src/plugins/gacha/game_opreator_data/ark/常驻卡池.txt', 'r',
encoding='utf-8') as r:
for lines in r.readlines():
js = json.loads(lines.strip())
normal_gacha.append(js)
limit_gacha = []
with open('src/plugins/gacha/game_opreator_data/ark/限时卡池.txt', 'r',
encoding='utf-8') as r:
for lines in r.readlines():
js = json.loads(lines.strip())
limit_gacha.append(js)
# 获取一下常驻(双up)卡池和限时(单up/限定/定向寻访)
if not name:
return normal_gacha[0] # 默认为最新卡池
if name.isdigit(): # 看看输入的是不是数字 ->常驻卡池id
if name > normal_gacha[0]['id']: # 大于最大的默认为最新卡池
name = normal_gacha[0]['id']
for x in normal_gacha:
if x['id'] == name:
return x # 不然就返回对于id的卡池
else:
for x in limit_gacha: # 如果不是数字,判断是不是某个限时卡池的名字(模糊匹配了)
if name in x['type']:
if ("复刻" in x['type'] or "返场" in x['type']) and ("返场" not in name and "复刻" not in name):
# 其实也就那么几个,判断下是不是单up复刻或者是两个返场,如果只是找第一次up就跳过复刻,唯一的问题是对复刻类的卡池输入要求要严格点
continue
else:
return x # 返回对于的up卡池信息
return normal_gacha[0] # 默认为最新卡池
change_gacha = on_command("切换方舟卡池", rule=handle_rule, priority=50)
now_gacha = on_command("方舟卡池", rule=handle_rule, priority=50)
@change_gacha.handle()
async def change_gacha_handle(message: Message = CommandArg()):
with open('src/plugins/gacha/game_opreator_data/ark/ark_gacha.txt', 'w', encoding='utf-8') as r:
r.write(str(message)) # 保存到本地,之前写的抽卡函数调用下上面写的获取卡池信息函数,以本地的卡池信息为准
await change_gacha.finish(Message("切换卡池成功"))
@now_gacha.handle()
async def now_gacha_handle():
now_gacha = ""
with open('src/plugins/gacha/game_opreator_data/ark/ark_gacha.txt', 'r', encoding='utf-8') as r:
for lines in r.readlines():
lines = lines.strip()
now_gacha = lines
n_gacha = await choose_gacha(now_gacha) # 获取一下卡池的缩略图
await change_gacha.finish(Message(f"当前卡池为[CQ:image,file={n_gacha['img_url']}]"))
3.实现效果
联合寻访(4捞4)
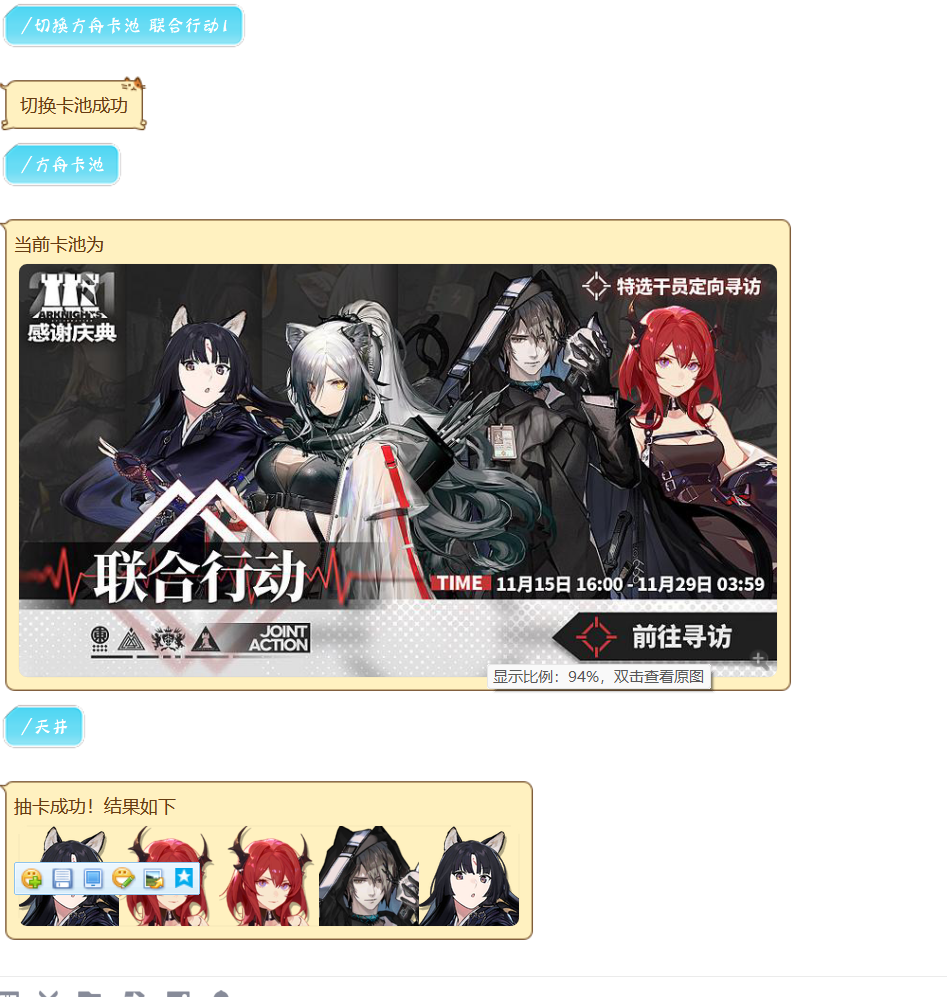
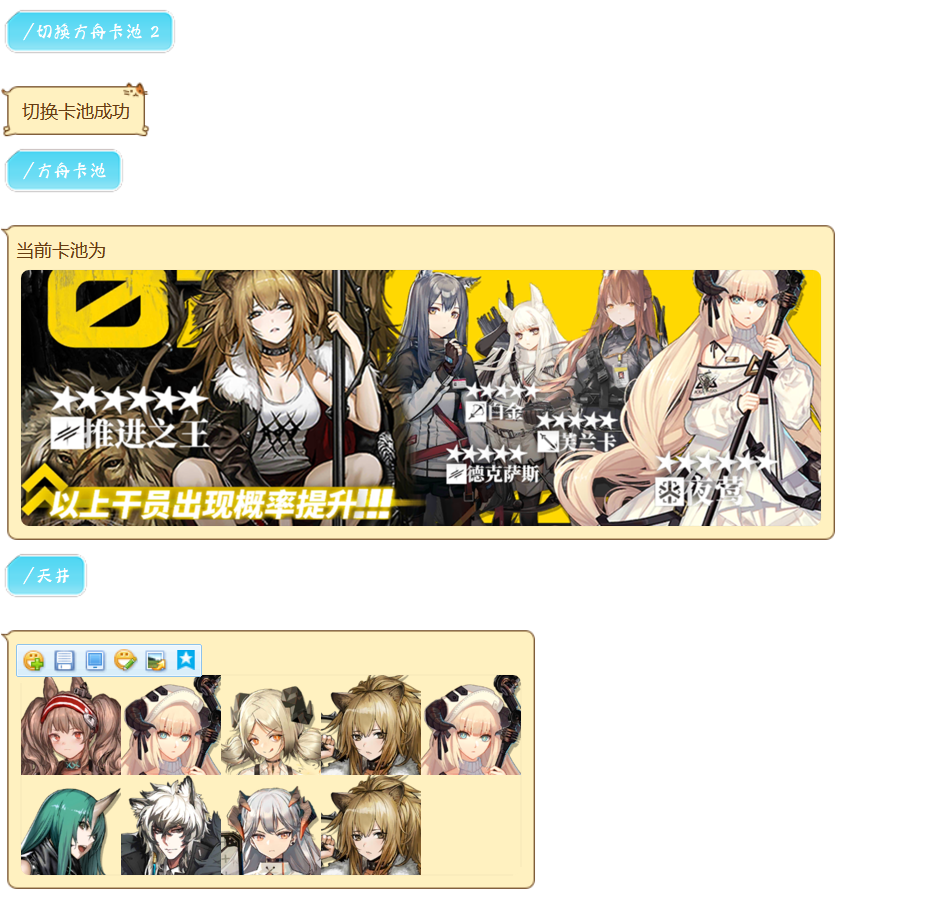
常驻卡池(普通双up)
限定卡池
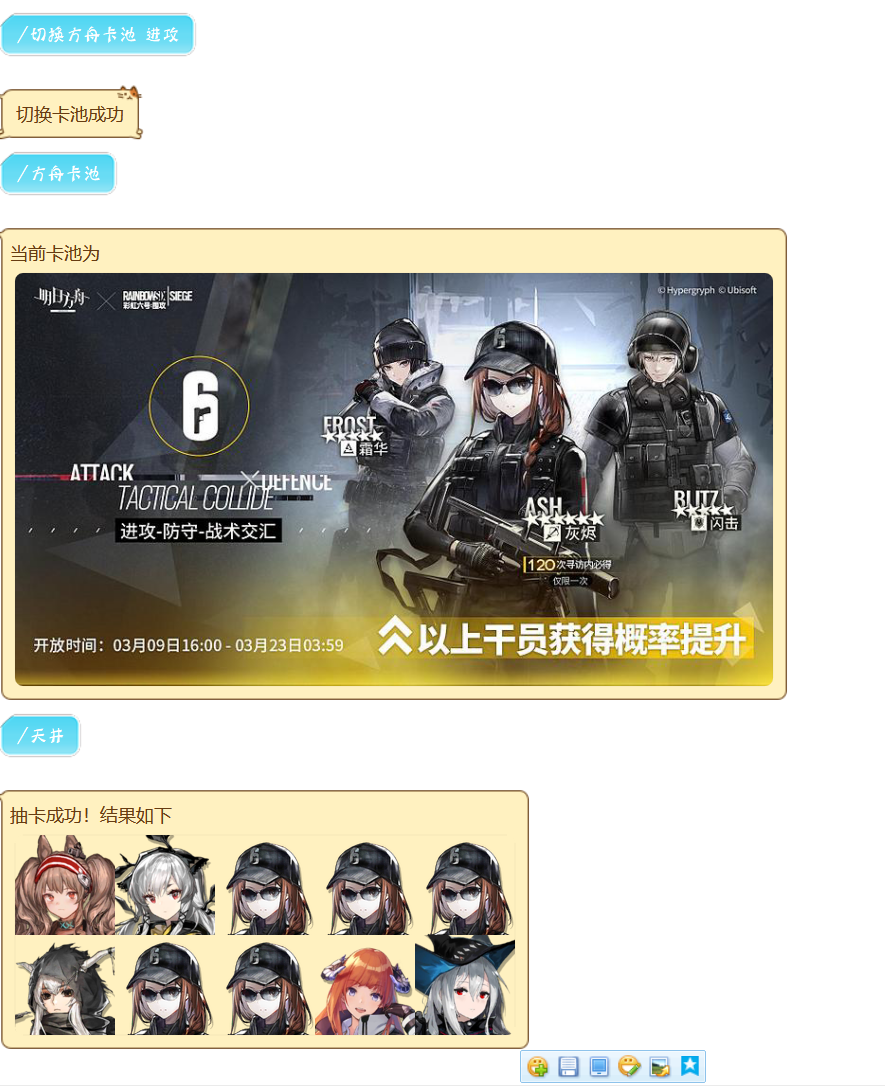
就是ash这个单独的联动池子没写120抽必得,懒了
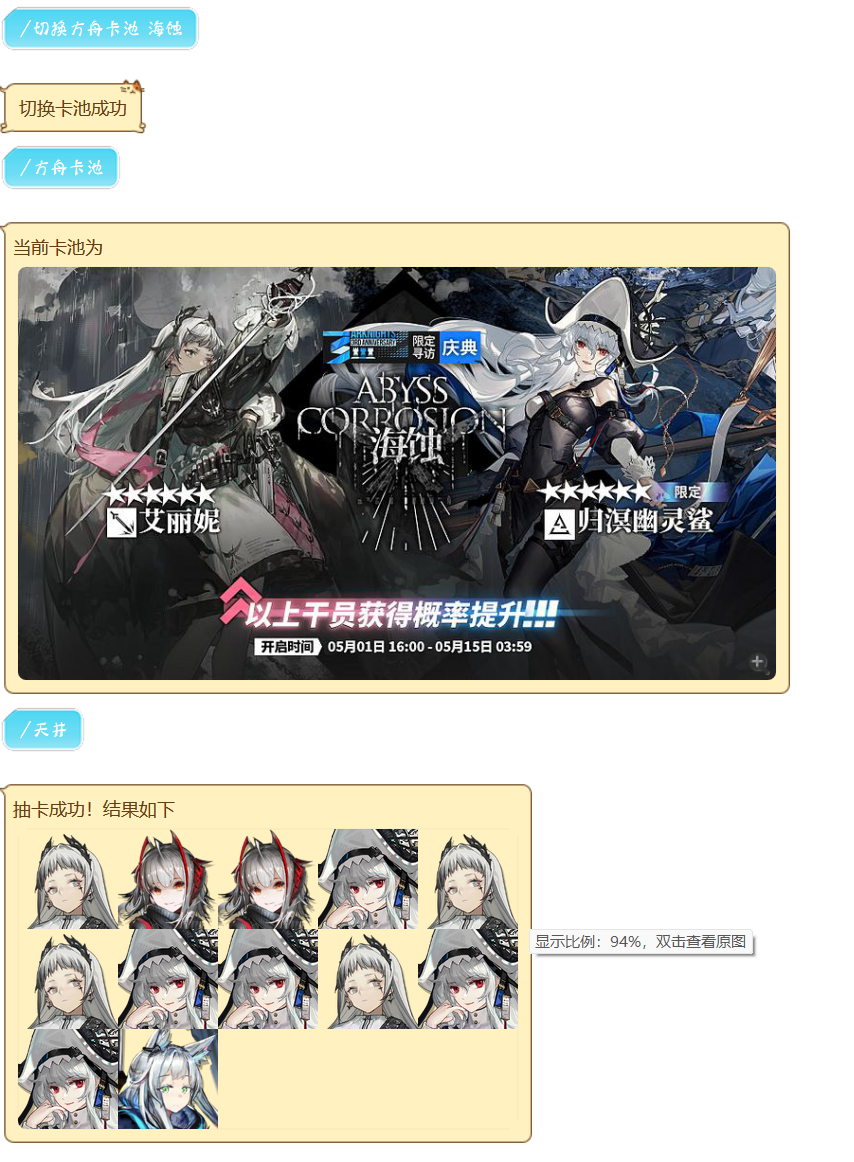
足以看出想在限定池里捞常驻和歪特定往期限定有多难了....也可能是我自己写的模拟不符合官方的
单up类
?我42呢
大概是没bug了
4.残留问题及其他
- prts的卡池一览并不是更新到最新的,更贴切的是留档,最新的(游戏中正up)卡池还是不能通过prts获取.可能某次限定模拟的时候需要自己写一下,或者从官网爬
- 没用无头浏览器,每次更新都是会弹出窗口,可以自己写个缩放函数.然后就是最好设成只响应超级用户,不然每次爬都会遍历一次本地文件(主要是保存图片这里),挺慢的影响其他的插件响应.
- 由于是基于prts爬取,所以要是prts的页面结构有变动就要大改.同时因为每次文件都是使用的覆写模式,万一产生了400类返回可能会导致本地的存储消失无法模拟抽卡,最好备个份
- 没考虑分群的情况,
虽然我的bot没啥人用如果出现了一个群切换另一个群也切换卡池,可能抽出来的会乱,可以考虑每个群拉个列表啥的.(如果每个群建了表其实可以考虑加每个人每天可以抽几次卡,防止刷屏;给每个人都建个六星仓库顺带记录下水位啥的) - 没了,但有种莫名的力量让我把5打出来
5.整体文件
水总字数用的,因为涉及到上一篇的地方都有小改,或许直接删了前一篇才是正确的?
文件目录如下
windows自带的tree好.....丑啊,还是换了npm下的工具包
|-gacha
|-icon
|-arknights
|-按照星级分别建立文件夹的干员头像
|-game_function
|-ark
|-arknights.py ->模拟抽卡
|-game_operator_data
|-ark
|-ark_gacha.txt ->保存的卡池信息
|-arknights.txt ->干员基础信息
|-常驻卡池.txt
|-限时卡池.txt
|-__init__.py
|-change_gacha.py
|-update_gacha.py
5.1 模拟抽卡
arknights.py
啥时候把这个点击按钮也改下
几乎是重写了一遍所以感觉前面那篇意义不是很大了....不规范命名方式警告!!!!
import math
import math
import random
import json
import requests
from PIL import Image
from lxml import etree
from loguru import logger
from src.plugins.gacha.change_gacha import choose_gacha # 调用另一个py文件里的函数,具体位置按你自己的来
async def ark_gacha(a: int) -> str: # 返回生成图片的地址(本地)
operators = []
with open('src/plugins/gacha/game_opreator_data/ark/arknights.txt', 'r', encoding='utf-8') as r:
for lines in r.readlines():
js = json.loads(lines.strip())
operators.append(js)
# 获取干员数据
original_P = [0.40, 0.50, 0.08, 0.02] # 所有卡池通用的3,4,5,6星的概率
up_other_P = [0.5, 0.5] # 所有非限定卡池(包括彩六联动那次)的当期up概率
star = [3, 4, 5, 6] # random.choices里用的数组
last_six = 0 # 水位
list_six = [] # 抽到的六星列表
with open('src/plugins/gacha/game_opreator_data/ark/ark_gacha.txt', 'r', encoding='utf-8') as r:
for lines in r.readlines():
lines = lines.strip()
receieve_gacha = lines
gacha_name = await choose_gacha(receieve_gacha) # 获取卡池信息
try:
up_operator = gacha_name['up_six_operators']
limit_operator = []
try:
gacha_type = gacha_name['id'] # 只是用于检验是不是常驻寻访,看要不要进except用的
gacha_type = "常驻"
full_operator = [x['name']
for x in operators
if x['star'] == 6 and x['name'] not in up_operator and "标准寻访" in x['from_where'] and x[
'join_time'] <= gacha_name['start_time']]
# 把所有不包括up的的非限定六都加进来,并且判断卡池时间和干员加入时间,如果加入时间更小那么说明卡池里有这个六星
except:
gacha_type = gacha_name['limit_type']
if "跨年欢庆" in gacha_name['type']:
return "wrong" # 这个没做,懒了
if "联合行动" in gacha_name['type']:
full_operator = [] # 联合行动不会有其他六星
gacha_type = "常驻"
elif gacha_type == None: # 标准的单up
gacha_type = "常驻"
full_operator = [x['name']
for x in operators
if
x['star'] == 6 and x['name'] not in up_operator and "标准寻访" in x['from_where'] and x[
'join_time'] <= gacha_name['start_time']]
# 同上面双up
else:
up_other_P = [0.3, 0.7] # 除了彩六其他的限定都是70%出率
gacha_type = gacha_name['limit_type']
full_operator = [x['name']
for x in operators
if
x['star'] == 6 and x['name'] not in up_operator and "标准寻访" in x['from_where'] and x[
'join_time'] <= gacha_name['start_time']]
# 加一下常驻干员,由于限定池子里的限定干员会以5倍权重提升出率,所以要分开处理
limit_operator = [x['name']
for x in operators
if
x['star'] == 6 and x['from_where'][-1] == gacha_type and x['join_time'] <=
gacha_name['start_time']]
# 判断是否为同一类的限定卡池,如果是那么就加入到这个池子里可以歪的限定干员
# from_where[-1]是为了防止报错
# 限定干员的加入时间设置为了解禁时间,方便计算
except Exception as e:
logger.exception("这tm是个啥错误\n", e)
return ''
# try: # 测试用的
# logger.info(gacha_name['title'])
# except:
# logger.info(gacha_name['id'])
try: # 计算限定里歪其他干员的时候常驻和限定的权重比率,emmm我也不知道是不是算对了
other_P = 1 / (len(full_operator) + 5 * len(limit_operator))
except: # 有一种可能是进了联合寻访,那么上面会是1/0报错,直接赋0
other_P = 0
for i in range(a): # 抽多少抽,虽然只做了300井的但实际上是可以自由设置多少抽的,毕竟是直接每次模拟
gt_star = random.choices(star, weights=original_P, k=1) # 判断一下这次抽的是不是6
for get_star in gt_star:
if get_star == 6:
last_six = 0 # 水位清零
six_operator = random.choices([0, 1], weights=up_other_P, k=1)[0] # 看是不是up
if (six_operator and up_operator) or (not full_operator): # 如果是up或者没有其他六星(指联合寻访) ->如果池子是新年必new的话也是走这里,懒得适配
list_six.append(random.choice(up_operator)) # 随机抽一个up6
else: # 歪了
if limit_operator: # 如果有限定干员
limit_or = \
random.choices([0, 1],
weights=[other_P * len(full_operator), 5 * other_P * len(limit_operator)])[0]
# 按照五倍权重的概率看抽到的是限定还是常驻
if limit_or:
list_six.append(random.choice(full_operator)) # 随机抽一个限定
else:
list_six.append(random.choice(limit_operator)) # 随机抽一个常驻
else: # 不是限定池子,从常驻里捞一个
list_six.append(random.choice(full_operator))
original_P = [0.40, 0.50, 0.08, 0.02] # 概率重置
else:
last_six += 1 # 水位加加
if last_six >= 50: # 水位已经到了阙值
original_P[3] += 0.02
# yj好像会让总概率接近2%,这个没想好怎么模拟(300的样本量直接模拟到2%的话不太好做出有非有偶的效果了)
gacha_img = Image.new(mode="RGBA", size=(100 * 5, (100) * math.ceil(len(list_six) / 5))) # 新建一块透明画布
high = 0 # 计算当前高度用
for j in range(len(list_six)):
character_img = Image.open(f"src/plugins/gacha/icon/arknights/6/{list_six[j]}.jpg") # 写绝对点
character_img = character_img.resize((100, 100)) # resize一下,其实prts的默认是100px不需要了 ->之前爬bwiki的遗留
if j and j % 5 == 0: # 5个一行
high += 100
gacha_img.paste(character_img, ((100 * (j % 5)), high)) # 粘上去
gacha_img.save(f"src/plugins/gacha/icon/arknights/gacha_result/gacha_result1.png")
img_url = "你的图片绝对地址"
return img_url # 传给主函数用于发送
5.2 更新卡池
update_gacha.py
下载需要的时间略久,所以不要在bot响应高峰期使用
import json
import re
import time
import urllib.parse
import requests
from dateutil.parser import parse
from lxml import etree
from nonebot.adapters.onebot.v11 import Bot, Event, GroupMessageEvent
from nonebot import on_command
from nonebot.adapters.onebot.v11.message import Message
from nonebot.params import CommandArg
from nonebot.permission import SUPERUSER
from loguru import logger
from selenium import webdriver
import os
async def handle_rule(bot: Bot, event: Event) -> bool:
with open("src/plugins/群名单.txt", encoding='utf-8') as file: # 提取白名单群文件中的群号
white_block = []
for line in file:
line = line.strip()
line = re.split("[ |#]", line) # 可能会有'#'注释或者空格分割
white_block.append(line[0]) # 新建一个表给它扔进去
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
if group_id in white_block or group_id == None:
return True
else:
return False
update_gacha = on_command('update', permission=SUPERUSER, rule=handle_rule, priority=50)
'''
本来是看的zhenxunbot的源码,后面改成直接爬prts了,一般箭头指的是一开始写的时候的思考
爬取Bwiki的方舟档案,获取干员头像及基本信息(稀有度/名字) -> 可以尝试下载prtswiki的头像类别,用selenium爬取干员信息 ->草prts有干员上线时间一览直接可以爬,bwiki紫菜吧!->又反转了,有人不会爬动态网页和js逆向,开摆!
不过BilibiWIki直接有卡池类别,不考虑更新不同步的情况下先爬Bwiki的具体信息然后下载prts的头像(prts的头像大小更加统一且默认无背景好看点)
同时爬取当前最新卡池,或模拟卡池(切换历史常驻卡池/定向寻访/单up卡池/限定卡池) -> 还没写
慢慢写了
面向cv编程!
'''
character_list = {}
@update_gacha.handle()
async def update_gacha_handle(bot: Bot, event: Event, message: Message = CommandArg()):
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
data = await bot.call_api('get_group_member_list', **{
'group_id': int(group_id)
})
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
if str(message) == "ark":
await update_operator()
await update_normal_gacha()
await update_limit_gacha()
await update_gacha.finish(Message(f"明日方舟相关信息已经更新!"))
else:
await update_gacha.send(message)
await update_gacha.finish()
async def update_operator(): # 爬干员基础信息(主要是获取头像)
url1 = "https://wiki.biligame.com/arknights/%E5%B9%B2%E5%91%98%E6%95%B0%E6%8D%AE%E8%A1%A8" # 获取干员基础信息——星极,获取途径,名字(zhenxunbot的部分) -> 现已作废
url2 = "https://prts.wiki/w/PRTS:%E6%96%87%E4%BB%B6%E4%B8%80%E8%A7%88/%E5%B9%B2%E5%91%98%E7%B2%BE%E8%8B%B10%E5%A4%B4%E5%83%8F" # 获取干员高清无背景统一头像
url3 = "https://prts.wiki/w/%E5%B9%B2%E5%91%98%E4%B8%8A%E7%BA%BF%E6%97%B6%E9%97%B4%E4%B8%80%E8%A7%88" # 获取干员上线时间,名字,获取途径 -> 主要是用于模拟抽卡和当期卡池没有对应六星
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66"
}
'''
用到的xpath基本小知识
"/"从根节点选取。
"//"从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
"@"选取属性。
下面面的意思就是匹配文档中div类,并且class为"mw-parser-output"的表,然后匹配其目录下的"/p/a"
'''
request = requests.get(url2, headers=headers).text
dom = etree.HTML(request, etree.HTMLParser()) # 构造一个DOM
char_list2 = dom.xpath("//div[@class='mw-parser-output']/p/a")
prts_dict = {} # 开一个用于最终输入的部分
for char in char_list2:
try:
img = char.xpath("./img/@data-srcset")[0] # 头像的url
name = char.xpath("./img/@alt")[0] # 对于的干员代号
img_url = "https://prts.wiki/" + urllib.parse.unquote(str(img).split(' ')[-2]) # 以网页的格式粘贴,好像不太需要
character_dict = {
'name': str(name).replace("头像 ", '').replace(".png", ''), # 名字格式,需要稍微改下
'img_url': img_url
}
prts_dict[character_dict['name']] = character_dict # 防止重复,以最后一个出现的覆盖
except:
continue
opreator_dict = {} # 同上
request = requests.get(url3, headers=headers).text
dom = etree.HTML(request, etree.HTMLParser())
char_list = dom.xpath(
"//table[@class='wikitable logo sortable filterable']/tbody/tr") # jquery-tablesorter原来是js插件......直接在客户端实现排序不用交请求给后端
for char in char_list:
try:
'''
xpath基础知识2
"."选取当前节点。
"td[1]"返回第x个类型
然后接着往下接着往下(格式自己参考网页)
"@srcset"获取图像高清的地址
"@src"获取的是适配后的地址
返回的是list所以[0]
仿照zhenxunbot的地方基本没了,感谢zhenxunbot
'''
name = char.xpath("./td[1]/a/text()")[0] # 名字
star = char.xpath("./td[2]/text()")[0] # 星级
join_time = char.xpath("./td[3]/text()")[0] # 上线时间,用于确保不同时间的卡池时确保不会出现超时空战士
# 这个格式是xxxx年x月x日 xx点xx分,和正常的时间格式字符串相比少了补位0,手动改下格式
j_time = re.findall(r"\d+", str(join_time))
correct_time = ""
for i in j_time:
if len(i) < 2:
correct_time += "0"
correct_time += i
# 最后补出来的格式就是像20200201的8位数字,可以直接用函数转换成2020-02-01,从而实现和卡池时间的比较
join_time = str(parse(correct_time)).split(' ')[0] # 这里用了个把数字字符串转成时间字符串的函数 parse,在开头有调用,具体参考官方文档
gacha_tpye = str(char.xpath("./td[4]/text()")[0]).replace("[标准寻访]", "") # 标准寻访前面有个[标准寻访],去掉一下(后面发现没有用到这个效果)
sources = str(char.xpath("./td[5]/text()")[0]).replace(' ','').split(',') # 可抽取到这个干员的卡池类别 ->就是是不是限定
if "限定寻访" in sources: # 如果是限定干员
url4 = "https://prts.wiki/w/"+str(name) # 爬一下
request4 = requests.get(url4).text
dom4 =etree.HTML(request4,etree.HTMLParser())
unlock_time = dom4.xpath("//div[@class='mw-parser-output']/table[1]/tbody/tr[3]/td/text()") # 限定干员解锁时间,记作ta的上线时间,因为第一次up会在up里不在歪到的干员里所以不用管
j_time = re.findall(r"\d+", str(unlock_time))
correct_time = ""
for i in j_time:
if len(i) < 2:
correct_time += "0"
correct_time += i
# 同上
join_time = str(parse(correct_time)).split(' ')[0] # 如果是限定的话进卡池时间就按解禁时间算,因为第一次必定在up里面
limit_type = dom4.xpath("//div[@class='mw-parser-output']/table[1]/tbody/tr[1]/td/text()")
limit_type = re.search("(?<=【).*?(?=】)",str(limit_type)).group() # 获取限定卡池类别
sources.append(limit_type) # 加到来源里去 ->也就是前面提到的[-1]的原因,因为联动的没有类别(不会歪出来)
character_dict = {
"prts_url": prts_dict[name]['img_url'], # 加进来了prst的头像,100px的,另一个格式是75px的
"name": name,
"star": int(star), # 这玩意前面带了个回车的,改成int了
"join_time": join_time,
"gacha_type": gacha_tpye,
"from_where": sources
}
opreator_dict[character_dict['name']] = character_dict
pic = requests.get(character_dict['prts_url'])
if os.path.exists(f"src/plugins/gacha/icon/arknights/{int(star)}/{name}.jpg"): # 写绝对路径
pass # 保存图片的时候优化一下....也不知道有没有用
else:
open(f"、src/plugins/gacha/icon/arknights/{int(star)}/{name}.jpg", "wb").write(pic.content) # 同上,写绝对路径
except Exception as e:
logger.debug(e) # 一般是读到了一些列表名不是干员名字,报个错意思下
continue
with open(r'src/plugins/gacha/game_opreator_data/ark/arknights.txt', 'w', encoding='utf-8') as f:
for j in opreator_dict.values():
f.write(json.dumps(j, ensure_ascii=False))
f.write("\n")
"""
其实应该是要输出成json的,但要改的地方太多懒得重构一遍了
with open(r'src/plugins/gacha/game_opreator_data/ark/arknights.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(opreator_dict.values, ensure_ascii=False,indent=4))
"""
async def update_limit_gacha(): # 获取限时卡池信息
url1 = "https://prts.wiki/w/%E5%8D%A1%E6%B1%A0%E4%B8%80%E8%A7%88/%E9%99%90%E6%97%B6%E5%AF%BB%E8%AE%BF"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.66"
}
request = requests.get(url1, headers=headers).text
dom = etree.HTML(request, etree.HTMLParser())
data = dom.xpath("//div[@class='mw-parser-output']/table/tbody/tr")
limit_gacha_dict = {}
num = 0
for char in data:
try:
gacha_title = char.xpath("./td[1]/a[2]/text()")[0] # 获取获取卡池名字,用于切换卡池
if gacha_title == "联合行动": # 因为保存的时候是唯一键,所以采用同一个名字的联合行动需要区分一下(但是prts是按最新时间排序的,所以可能倒序才是原本顺序)
gacha_title += str(num) if num else ''
num +=1
gacha_type = str(gacha_title).replace('【', '[').replace('】', ']') # 限定为啥是中文方框,改一下
# -> prts上爬干员上线时间一览非限定直接是池子名字了,但限定是[限定寻访]池子名字,还是不太好区分开来
if "跨年欢庆" in gacha_type:
continue # 新年必new池如果没存个人仓库的话不是很有实现的意义(懒+不会)
if "限定寻访" in gacha_type:
limit_gacha_type = re.search("(?<=·)(.*?)(?=])", gacha_type).group() # 获取限定卡池隶属的类别,方便只出现对应会出现的干员
# 但还是没找到很好解决限定干员来历的方法 ->用读取到限定干员时爬对于干员页面并且加到获取来源里去
# 大概是针对限定干员,专门去爬一下ta的个人页面的上线卡池,并且把上线时间调到一年后(因为当期up不会被算在其他up里,所以直接按一年之后的算好了) ->已经实现了
# 最后在获取基础信息那里搞了下
else:
limit_gacha_type = None # 不是限定这个参数就没啥必要
img_url = "https://prts.wiki" + str(char.xpath("./td[1]/a[1]/img/@data-srcset")).split()[-2]
start_time = str(char.xpath("./td[2]/text()")[0]).split(' ')[0] # 获取上线时间,只需要当天就行
up_six_operators = char.xpath("./td[3]/span/span/a/@title") # 获取up六星
try:
up_five_operators = char.xpath("./td[4]/span/span/a/@title") # 获取up五星(好像四星也被计入了emmm,懒得管了),因为没有做十连之类的显示3,4,5星的功能所以没有管
except:
up_five_operators = None # 新手卡池五星没有给具体值,懒得做了,到时候读取到None就只读取干员数据里开服的干员就好了
gacha_dict = {
"title": gacha_title,
"img_url": img_url,
"type": gacha_type,
"limit_type": limit_gacha_type,
"start_time": start_time,
"up_six_operators": up_six_operators,
"up_five_operators": up_five_operators
}
limit_gacha_dict[gacha_dict['title']] = gacha_dict
# 寄,突然发现联合行动是一个名字 ->解决办法就用1234来按顺序吧
except Exception as e:
# 和前一个函数里提到的一样,多半是读到了table名
logger.debug(e)
with open('src/plugins/gacha/game_opreator_data/ark/限时卡池.txt', 'w', encoding='utf-8') as f: # 写在本地不用每次都爬
for j in limit_gacha_dict.values():
f.write(json.dumps(j, ensure_ascii=False))
f.write("\n")
async def update_normal_gacha(): # 爬常驻类卡池,用了selenium
open_driver = webdriver.Chrome() # 有时间再换成无头浏览器吧
# open_driver = webdriver.Firefox()
# open_driver = webdriver.PhantomJS()
open_driver.get(
'https://prts.wiki/w/%E5%8D%A1%E6%B1%A0%E4%B8%80%E8%A7%88/%E5%B8%B8%E9%A9%BB%E6%A0%87%E5%87%86%E5%AF%BB%E8%AE%BF') # 打开prts常驻卡池一览
try:
data = open_driver.find_elements_by_xpath("//div[@class='collapsible-block-folded']/a")
# 获取所有展开按钮的位置,用xpath定位
# 一定要记得用elements! ->某个用element找不到问题的傻逼留
for i in data:
open_driver.execute_script("arguments[0].click();", i) # 用js的方式模拟点击
time.sleep(1) # 缓一下
except Exception as e:
logger.debug(e) # 报错了提示,不过应该不会,除非403或者400 ->后来的调试里出了一些奇怪的问题,也不知道是啥错误,暂且相信不会进这个报错吧
time.sleep(5)
# open_driver.close()
logger.info("开始爬取卡池数据") # 报一下情况
time.sleep(5) # 等待页面全部加载完全
try:
data = open_driver.page_source # 获取加载完毕后的当前指向网页的源代码
dom = etree.HTML(data) # 转成DOM并且使用xpath!beautifulsoup还不会
char_list2 = dom.xpath("//div[@class='mw-parser-output']/table/tbody/tr") # 这是所有卡池的位置
full_gacha_dict = {}
for i in char_list2:
try:
gacha_dict = {
'id': str(i.xpath("./td[1]/text()")[0]).split()[0], # 获取卡池序号用于切换卡池
'img_url': "https://prts.wiki" + str(i.xpath("./td[2]/a/img/@srcset")[0]).split()[-2],
'start_time': str(i.xpath("./td[3]/text()")[0]).split()[0], # 获取开始的时间戳,用于和干员上线时间进行比较从而确定卡池内干员
'up_six_operators': i.xpath("./td[4]/span/span/a/@title"), # 获取up的六星干员
'up_five_operators': i.xpath("./td[5]/span/span/a/@title") # 获取up的五星干员
}
"""
这里是写time的时候一个小记录
看prts加载的源代码看得到有用<br>分割
然而xpath读到<br>会自动断,从而text()不能获取全部 ->下面观察了下输出可以,但会分隔开来返回list了有点懒
这时候把text()换成descendant-or-self::text()就可以获取全部的文字了
但是会把换行符啥啥的都读进去,需要自己处理
然后发现比较的时候只需要记录池子开的时候就好了,所以没有用上面的方法(主要还是适配之前爬prts干员一览里的上线时间)
"""
full_gacha_dict[gacha_dict['id']] = gacha_dict # 放到dict里去
# logger.info(str(i.xpath("./td[3]/text()"))) # 测试用观察输出
logger.info(f"成功获取卡池{gacha_dict['id']}的信息")
except Exception as e:
# 由于每一个点击之后table第一行都会是具体信息,所以会报错啥的,不管继续就好了
logger.debug(e)
continue
with open('src/plugins/gacha/game_opreator_data/ark/常驻卡池.txt', 'w', encoding='utf-8') as f: # 写在本地不用每次都爬
for j in full_gacha_dict.values():
f.write(json.dumps(j, ensure_ascii=False))
f.write("\n")
except Exception as e: # 出大问题,自己看报错
logger.debug(e)
open_driver.close() # 关闭浏览器
5.3 切换卡池
change_gacha.py
同上,无更改
5.4 主函数
__init__.py
就是个简单的响应函数
from nonebot import *
from nonebot.rule import *
from nonebot.plugin import on_keyword
from nonebot.adapters.onebot.v11 import Bot, Event, GroupMessageEvent
from nonebot.adapters.onebot.v11.message import Message
from nonebot import on_keyword
from nonebot.params import CommandArg
from nonebot import on_command
import re
from src.plugins.gacha.game_function.ark.arknights import ark_gacha
async def handle_rule(bot: Bot, event: Event) -> bool:
with open("src/plugins/群名单.txt", encoding='utf-8') as file: # 提取白名单群文件中的群号
white_block = []
for line in file:
line = line.strip()
line = re.split("[ |#]", line) # 可能会有'#'注释或者空格分割
white_block.append(line[0]) # 新建一个表给它扔进去
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
if group_id in white_block or group_id == None:
return True
else:
return False
# gacha_ten = on_command("十连", rule=handle_rule, priority=40)
gacha_jing = on_command("天井", rule=handle_rule, priority=50)
@gacha_jing.handle()
async def gacha_jing_handle(bot: Bot, event: Event):
url1 = await ark_gacha(300) # 因为这里就是调用抽卡次数,所以要咋改抽几次都是可以自己设置的
await gacha_jing.finish(Message(f"抽卡成功!结果如下[CQ:image,file=file:///{url1},id=40000]"))
# 想做嘲讽啥的就基于抽到的六星个数写对于的输出语句就好
6. 感谢阅读到这里的
orz从小白开始写的好痛苦
细看挺多地方都有更加优秀的实现方式,但完全没学到还不是很先用
等有时间把我之前插件代码都重构一遍(X
好像每个插件都是需要放github上开源的?不知道了
不难看出想要模拟其他游戏的抽卡只需要爬一个头像和基础信息的网站,然后存一下对应的池子信息,差不多删删改改就好了
但是没玩啥其他游戏,就这样了!

