Nonebot2插件:不准涩涩...?就要
前言什么的懒得说了啦,能不能去看前面文章前言的帮我涨阅读量(X
建议觉得代码写的不对的直接骂死我
广告
快来之前视频教程里的群玩720053992,对于掌握了《提问的艺术》的人来说,群里的大佬会耐心解答你的问题的(404大佬和日向妈)(22/05/19 这几天确实好多和我一样的小白来问问题,提问的方式血压也高,但还是有大佬愿意解答,感谢)
这个插件只是用来蹭蹭时下热门流量XD,其实第一篇 里面有讲怎么简单实现
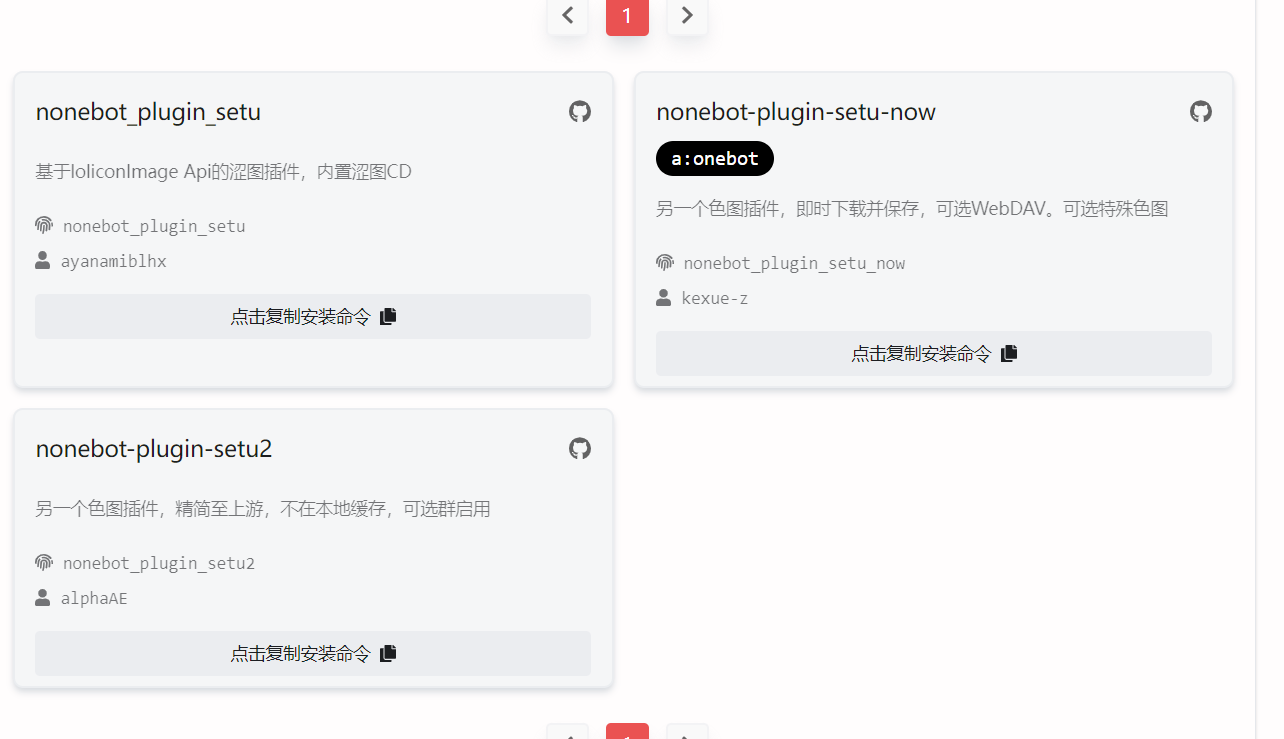
对于什么的都不会的小白来说,最简单的就是直接下载nb2商店里的三个se图插件以供使用
什么你下载了还不知道怎么用,那么请阅读好《提问的艺术》后快来加入广告里的404群提问吧
下面放下自己的实现
1.需要了解的
——知道基础的requests的语法(httpx我搞不懂诶嘿,但是比requests快很多,建议有能力的自己改成httpx)
——知道json类和转义方法
——确保已经阅读过了lolicon.app 的使用说明
2.开搓代码
首先定义一下参数
为了支持定向搜索tag,我们使用on_startwith()(响应以特定字符串开头的消息),这样后接需要搜索的tag和年龄限制也十分方便
点我看前面部分代码
import nonebot
import requests
from nonebot.rule import *
from nonebot import *
from nonebot.adapters.onebot.v11 import Bot, Event, GroupMessageEvent
from nonebot.adapters.onebot.v11.message import Message
import random
import re
import json
async def handle_rule(bot: Bot, event: Event) -> bool:
with open("你白名单txt存放地址", encoding='utf-8') as file: # 提取白名单群文件中的群号
white_block = []
for line in file:
line = line.strip()
line = re.split("[ |#]", line) # 可能会有'#'注释或者空格分割
white_block.append(line[0]) # 新建一个表给它扔进去
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
if group_id in white_block:
return True
else:
return False
setu = on_startswith('ldst', rule=handle_rule, priority=50)
@setu.handle()
async def setu_handle(bot: Bot, event: Event):
try:
whatever, group_id, user_id = event.get_session_id().split('_') # 获取当前群聊id,发起人id,返回的格式为group_groupid_userid
except: # 如果上面报错了,意味着发起的是私聊,返回格式为userid
group_id = None
user_id = event.get_session_id()
由于本人的偷懒,指令规定为"ldst"后接空格+tag的形式,当tag为"R18/r18/18"中的一个时,将图片设置为年龄限制模式
请确保已经阅读了lolicon.app 的请求部分使用说明!!
点我看碎片代码
reciece_message = str(event.get_message())
reciece_message = reciece_message.replace('ldst', '')
reciece_message = reciece_message.split(' ')
'''
将获取到的消息按空格分割开来
'''
url2 = "https://api.lolicon.app/setu/v2?"
for tag in reciece_message:
if tag !='':
if tag == 'R18' or tag == 'r18' or tag == '18': #如果接收到了年龄限制请求
url2 += "&r18=1"
'''
参考官网给的请求格式,开启年龄限制
这里可以在最外层加一个r18list用于控制允许开启r18的群聊,不然bot哪天被举报掉了都不知道
(呜呜你bot都没几个人用还担心这些干嘛)
'''
else:
url2 += "&tag=" + str(tag)
'''
同上,官网会自动模糊匹配部分关键词,需要注意的这个指令的编写并没有适配官网中提到的画师/作品id等其他功能,如有需要请自行增加并规范指令说明
如果想加这些功能也用&连接即可
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
'''
请求头好像不一定要加,但还是加上最好
'''
rresult = requests.get(url2,headers=headers)
rresult = rresult.text
rresult = json.loads(rresult)
'''
读取json类文件的操作,操作之后rresult变成了一个dict类,这样就可以调用了,返回的json如下
{"error":"",#是否报错,一般为空
"data":[{#返回按着指定的范围搜索到的图片,若没有结果即为空(需要注意这里是list套dict,如果请求了多张图片data里就是多张图片)
"pid":作品id,
"p":作品在对于id图片里的位置,
"uid":作者id,
"title":作品标题,
"author":作者名字,
"r18":是否为年龄限制图片,True和False,
"width":xxx,"height":xxx,#作品的宽高
"tags":[作品打的tag,挺多的,可能搜索到的tag只占图片一小部分],
"ext":作品格式(jpg/png....),
"uploadDate"作品上传时间戳,
"urls":{#作品镜像地址,等下需要用到的
"图片质量(大小),可以根据自己决定,默认为original":"https://i.pixiv.cat/img-original/img/2022/03/30/00/00/14/97268123_p0.jpg"#某个作品例子
}
}]
}
接下来就引用其中的需要的部分好了
需要注意的是引用时要replace('i.pixiv.cat','i.pixiv.re'),不然国内无法访问
'''
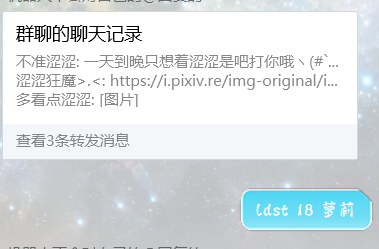
考虑一下可爱的群友,满怀希望的打下了ldst(或者是被迫在刷群聊的时候别人打下了ldst),紧接着跳出的图片让你可爱的群友当场社死!
为了避免这种情况的发生,请参考go-cqhttp合并转发消息 这样哪怕群友自己点进去然后社死也是自找的了(有区别吗....)
点我看最后一个part
虽然图片已经获取到本地且用消息类发送给了tx,但图片还是有审核不过的风险,这时候需要把可访问的网址单独提取出来给群友了(虽然qq还是不能直接跳转就是)if rresult['data'] == []:#如果指定的tag没有返回值
await setu.finish(Message("图库中似乎没有你想要的涩图呢...."))
try:
await bot.call_api('send_group_forward_msg', **{'group_id': int(group_id), 'messages': [
{
"type": "node",
"data": {
"name": "显示出来的用户id",
"uin": "随便指定一个QQ号,头像会变成那个人的头像",
"content": "这里内容随便你写"
}
},
{
"type": "node",
"data": {
"name": "涩涩狂魔>.<",
"uin": f"{user_id}",
"content": f"{rresult['data'][0]['urls']['original'].replace('i.pixiv.cat', 'i.pixiv.re')}"
}
},
{
"type": "node",
"data": {
"name": "多看点涩涩",
"uin": f"{user_id}",
"content": f"[CQ:image,file={rresult['data'][0]['urls']['original'].replace('i.pixiv.cat', 'i.pixiv.re')},id=40000]"
#总之上面是url引用格式,看不懂就直接复制吧
}
}
]})
'''
看到出来上面就是个json格式的message,所以你可以自己写个函数调用不至于每次用都写这么长
具体的格式要求和参数意义请参考官方文档
这玩意可玩性还挺高的,估计QQ聊天记录很多都可以这么伪造,不能教唆犯罪)
'''
except:#啊 如果走到了这一步说明图片被吞了,具体怎么返回自己写吧
await setu.finish(Message(
f"看到这条消息说明大概率被风控了,图片点我看{rresult['data'][0]['urls']['original'].replace('i.pixiv.cat', 'i.pixiv.re')}"))
偷偷放一下