高峰应对记录
一、背景
最近这个点9月中旬了,快到双十一了,公司开始对一些较为重要的系统开始进行压测。在这个过程中,需要保证系统的稳定性,以及高吞吐量。所以记录这次的压测过程,自己遇到的各种问题以及自己的思考。
二、 过程记录
2.1 工作流程梳理
在确定系统被确定为高峰系统后,就需要对系统有一个完整的梳理,并对接下来的工作有一个梳理规划。其中主要有几个方面。如下:
- 系统功能的完整梳理
- 系统调用链路,以及上下游系统调用链路
- 系统现有监控梳理。如:业务监控、请求调用、重要接口日志监控等
- 系统应急预案。如:系统层面的容灾、高峰扩容等,接口层面的降级熔断等
- 系统压力测试
- 等……
梳理完项目,确立的工作流程主要是
- 对突如其来的问题有一个提前预案。如:当A系统对B系统有强依赖关系时,就需要考虑解除强依赖关系,或者说A系统通知到B系统,对具体的依赖做压力测试,保证接口最大程度可用。或者在自己监控缺少时,可是通过别人来查漏补缺。这些都是及其有必要的,因为三人行,必有吾师焉。
- 发生问题时可以快速解决。做了预案,那对于的解决策略在这个时候也要思考,并且记录下来,当高峰发生问题时,可以快速启动解决方案来解决线上问题。
在梳理完流程、监控后,接下来就是自己对系统一些功能模块访问量进行评估。这个评估一般是通过数据埋点,或历史数据来确定系统的接口调用量高峰期,通过对以往高峰期的流量查看,预估出这次高峰需要应对的测试压力。按照现有压测规则,基本都是对现有高峰流量*3。
这个压力测试无需太大,因为对一个成熟的系统来说,提高QPS的主要途径还是通过增加机器来应对,测试过大,增加机器过多,并部分或公司来说,也是一项额外的成本。可以通过监控系统监控,当高峰期压力实在顶不住时,在增加也无妨。并且额外的压力测试,也会耗费各位在做的优秀工程师的脑力,去优化系统的边边角角,实在是有一点得不偿失(这个得不偿失有待商榷,毕竟我们自己还是要有追求)。
2.2 压测记录
2.2.1 压测工具
公司采用的压测工具是从一家公司的买的压测工具,可以在网页操作并提供可视化界面。仔细观察了一下,其本质还是还是对JMeter的封装,其中主要的的指标有:RT、TPS、请求数、压测时间、请求成功率等。还可以选择请求节点数等(不太重要)。压测工具有蛮多中,大家可以根据自己的喜好选择。
在有了自己的压测工具后就可以自己开始动手测试啦。当然,我这边是测试同学弄好的测试脚本,我直接动动小手,点击一下启动,就可以对某些关键的接口开始测试了。
2.2.2 问题分享
开始压测问题后,就开始发现问题啦,这其中有自己技术架构设计时,对架构设计的过渡设计,也有开发过程中对代码开发的偷懒行为,都能通过自己压测发现出来。为什么强调自己压测呢?因为自己压测可以更好的发现问题,自己也可以有设计、开发有更深的理解,这样岂不是一举多得?
2.2.2.1 问题一:流量均衡
我们在进行压测过程中,最重要的当然是系统CPU、内存、网络等一些数据指标的观测了。在我最初的测试中,是有两个测试节点(不是常规的单节点测试,然后增加机器,看是否线性增长)。流量并不大,但是发现CPU和内存在两个节点上的分配并不均匀。我认为这就是一个较为严重的问题,因为流量不均衡会带来节点资源浪费的情况,也会导致增加机器并不能完全解决高峰流量请求的问题。
在发现这个问题后,第一时间查看了ng的配置,发现是通过ServiceIP进行流量转发,K8S容器会将流量转发给ServiceIP绑定的容器节点。分析一番后,在确定配置的NG没问题后,只好查找其他原因,最后发现是K8S service的问题。然后通过其他方式(公司云其他配置)解决了流量不均衡问题。
2.2.2.2 问题二:hystrix核心线程限制并发
先画一下系统简易调用关系图。如下:
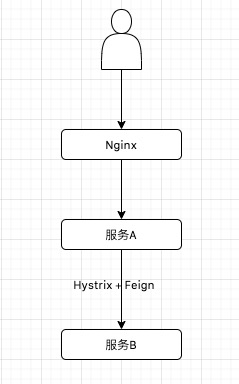
调用关系比较简单,用户通过域名访问,解析后,会转发到后端的Nginx来,Nginx反向代理到服务A上,这个时候,服务A在调用服务B。服务A在调用服务B的时候,通过Feign+Hystrix调用的。使用hystrix主要是用来控制进入把服务的流量,进行熔断,降级。但是也带来问题,让我娓娓道来。
Hystrix在服务调用的时候,有两种调用方式,分别是信号量和线程池。我采用的是默认配置,即使用线程池。在使用线程池的时候,会为每个Service创建一个调用线程池,调用线程池有一个默认值=10。核心线程池也就控制着最大并发量,虽然可以修改线程池的大小,但我是全service统一配置的,没有为某单独服务设置线程池,随意改动,则会影响全局配置,造成线程增加太多,这就可能带来上下文切换或其他方面的影响。
在发现这个问题后,的确不太好解决,但是由于架构目前来说不太复杂,也就带来了理想解决方案,修改完后关系图如下:
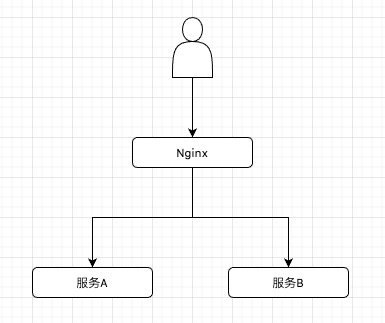
我主要的想法蛮简单,通过Nginx,直接把流量转到服务B来,就是通过切断调用关系。解决的方式有很多,说一说我这样的想法。
- 就目前来说,调用关系不复杂,改动的变化能接受。
- 目前调用关系不利用后面接入网关,现在就压测机会进行提前改造,减少以后改动范围。
- 改动的收益>风险
基于以上几点,所以进行了如此的改造。如果其它同学的关系架构、调用关系复杂,不建议这样修改。
2.2.2.3 代码耗时
在流量进入代码后,就需要考虑代码内部调用耗时了,还是说说这个问题的由来。
在进行内部流量测试的时候(去掉其它调用关系,如HTTP,RPC),发现压测的RT耗时不太满意,对于从用户到服务这段时间,目前来说无法优化,所以暂时不考虑,所以就从内部代码考虑。
如何进行代码时间监控呢?加日志是不可能去加日志的了。发现了一个好用的工具,给大家安利一下,那就是阿里开源的arthas,通过增强代码功能(字节码织入),来进行监测,简直不要太好用。具体使用我就不讲啦,大家可以自行百度一下(IDEA有插件,可以直接复制命令,实在不行,看文档,文档也齐全)。通过arthas,可以直接查询方法执行过程中,哪一个步骤耗时较多。通过查询,竟然发现Redis的get操作最耗时(这里我偷了个懒。这里跟踪了一下,可能是存储大大对象的问题,List对象我直接序列号成字符串存起来的,由于改动起来太大,并且以后可能会切换Redis客户端,收益和付出不成正比,所以最后放弃修改。大家如果Redis耗时这方面问题,可以从这慢查询,大对象优化方面入手。
2.2.2.4 容器线程池调优
容器线程池调优是一个麻烦的过程,容器线程池线程在这里是用了一种大概的调优方式,通过采集不同的并发量,确定大概的线程数量。如:10、20、...100、150。在线程数100到150时,线程的QPS,RT并没有增加,反而有下降的趋势。通过分析,将并发数均分,在对应到容器,算出大概最优线程数。在算出大概最优数后,在重新测试,看看测试结果。
2.2.2.5 容器切换
在测试过程中,还尝试切换了容器。现在web容器是用的jetty,采用的默认参数(线程数最大200)。因为代码中,多数是IO操作,所以就尝试了一下据说在IO方面表现更优秀的undertow。在这里就不具体介绍undertow了,可以在Spring中直接查看源代码。在测试完后,发现两者测试差距不大(测试次数较少,大家可以不做参考),最后又换回了jetty。
三、思考
这次压测等一切手段是在高峰时期准备的,我们是不是可以把这些手段或者优化都用在平常的开发中。如果用在平常的开发中,就可以应对突发流量,或其它突发请求,提升用户体验,也减少了在高峰时期的特殊调整。当然,在平时这么严格的执行策略,可能会增加测试、开发同学的一些工作量,但换来的价值我觉得是可行的。
四、总结
高峰应对还是非常重要的,主要是保证在系统高峰的时候保证系统的可用性,以及在应对突发问题时,采用的修复策略。这次的总结还是挺总要的,为以后再次应对高峰打下基础。
以上是这次总结,如有问题,欢迎大家讨论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号