可解释机器学习(李宏毅)学习笔记
本文为李宏毅老师机器学习课程中的可解释章节学习总结。
可解释的需求
- 理解模型内部的决策逻辑。 如果我们不去分析模型的决策逻辑,那么我们无法理解模型学到了什么。甚至部分情况下模型并没有学到我们想要的决策逻辑。此处课程举出了一个有趣的例子。 一匹在人群中会用马蹄敲击回应算数的马。 并非马学会了算数,而是因为它通过判断人群反应(正确答案会有欢呼)来终止马蹄敲击,以此获取奖励,如果将此马放到无人处,马就会不停敲击马蹄而不知道何时停止。这与人们的判断不同,这匹马并未学会算数。可以类比马就是一个黑箱模型,如果无法解释马算数的决策逻辑,那么无法判断这匹马是否真的学会算数。

- 高风险场景 :法庭,医药,自动驾驶。这类应用涉及伦理,公平,安全等对人们具有重要影响的领域。
- 基于模型解释,改进模型性能。 通过解释性技术,分析影响模型性能的因素来针对性的提高模型性能。
可解释的挑战
可解释与性能相矛盾。简单的机器学习模型具备较好的可解释性,例如线性模型,人们可以依据每个特征的权重大小,判断模型决策时依赖那些特征。而复杂的深度学习模型虽然具有极高的性能,但是却因缺乏可解释性而常常被人诟病。所以,如何保证高性能,同时具备较好的可解释性是目前面临的主要挑战。
可解释的目标
目前,这个可解释性的目标还存在一些争论。部分学者认为可解释的目标是完全理解模型的内部结构,决策逻辑。在这里,李老师提出了另一个观点,即我们不需要完全理解模型,但是我们需要模型为它的决策结果给出一个人们信服的理由。正如我们无法理解人脑的决策逻辑,但是只要另一个人给出足够充分的理由,我们依旧可以去相信一个人。
可解释的分类
这里的分类是基于可解释所针对的范围,针对单个实例的解释称为 Local Explanation,针对整个模型的解释称为 Global Explanation。我们可以通过下面一个简单例子来区分两者。
- Local Explanation 为什么判断这张图片是一只猫。
- Global Explanation 模型认为猫具有哪些特征。
局部可解释性
特征重要性分析
通过依次移除每个特征,依据模型决策变化程度,来判断出最有效的特征。
Reference: Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014 (pp. 818-833)
Saliency Map
对特征施加扰动\(\Delta x\),损失函数会产生一定变化\(\Delta e\),然后使用损失函数的变化和特征扰动的比值\(\frac{\Delta e}{\Delta x}\)来判断该特征的重要性。比值越大,说明该特征越重要。
saliency map: Karen Simonyan, Andrea Vedaldi, Andrew Zisserman, “Deep Inside Convolutional
Networks: Visualising Image Classification Models and Saliency Maps”, ICLR, 2014
该方法存在两个问题。
第一个问题是,生成的saliency map,具有较大的噪音,如Typical所示,所以为了使得saliency map具有更小的噪音。学者们提出了saliency map 方法来获得噪音更小的图片。

解决办法:通过对输入图片随机施加噪音,然后每张生成的图片生成的 saliency map 取平均。
smooth grad: Smilkov, D., Thorat, N., Kim, B., Viégas, F. and Wattenberg, M., 2017. Smoothgrad: removing noise by adding noise. arXiv preprint arXiv:1706.03825.
SmoothGrad 不见得更能反应模型决策的逻辑,但是他给出的结果却更加符合人的直觉。
第二问题,梯度并不总能有效反应特征的重要性。下图举出了一个例子,即动物鼻子的长度在判断是否为大象时,在不同长度范围对判断结果具有不同程度的影响。在大象鼻子较短时,增加鼻子长度对判断结果具有较为重要的影响,但是大象鼻子较长时,增加鼻子长度并不能对判断结果有较大的影响。
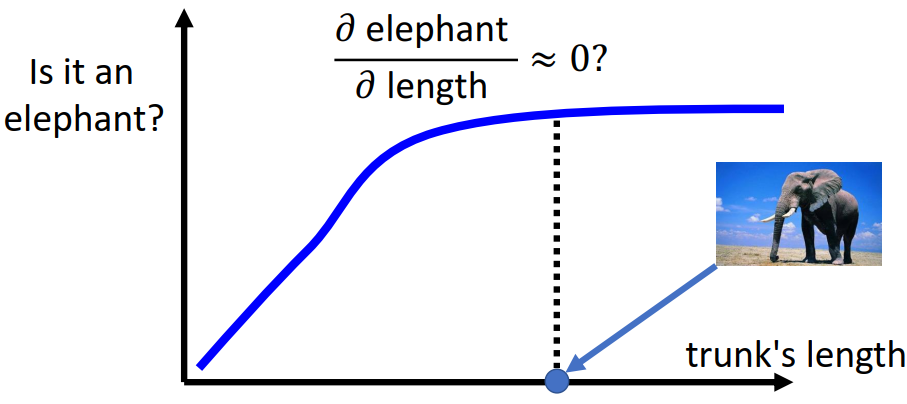
为了解决该问题,学者们提出了IG方法。
Sundararajan, M., Taly, A. and Yan, Q., 2016. Gradients of counterfactuals. arXiv preprint arXiv:1611.02639.
网络工作流程分析
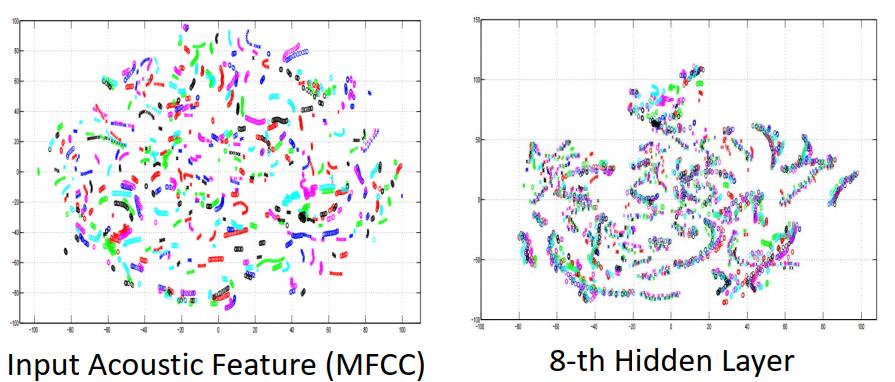
visualization 可视化方法
对网络的某一层输出结果降维,聚类等操作,进而可视化输出结果,来判断网络层作用。可以看出input的可视化结果(左图)和网络的第8层结果(右图)的区别。
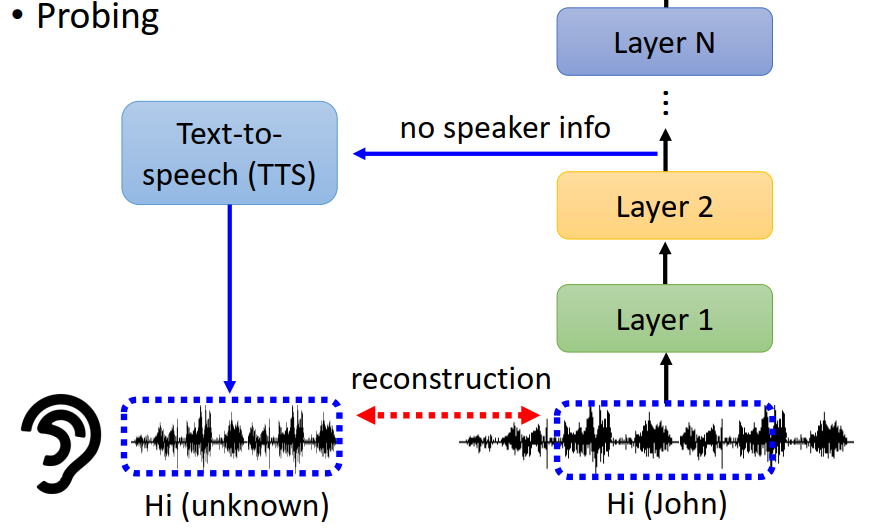
Probing(探针)
通过利用网络中间层进行下游任务,判断网络性能。
- 将bert的中间层用于词性分类(POS Classifier),如果词性分类任务性能较好,那么证明中间层学到了比较多的有关词性的特征。另外,分类任务性能不仅和中间层特征有关,而且还和词性分类模型有关(例如,无法正确分类也有可能是分类模型没有得到很好的训练)。在分析结果时,需要避免分类模型对分类结果的影响。
- 将语音辨识模型的中间层重构出语音,重构结果不包含讲者的信息,那么可以判断语音识别模型中间层能够去除模型的讲者信息。
全局可解释性
构造输入法
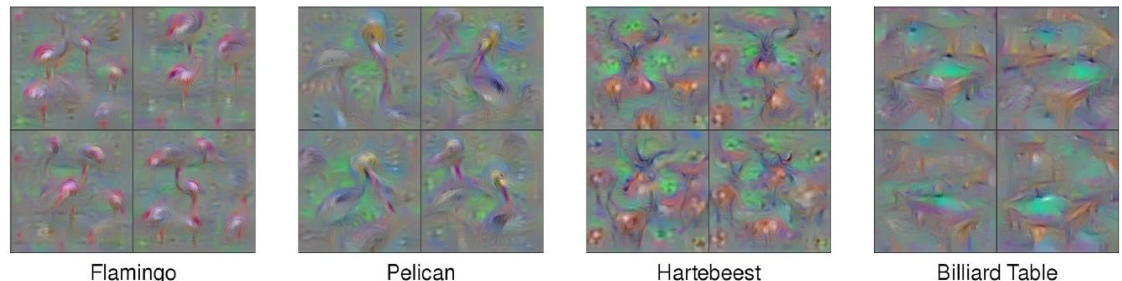
在图像领域,通过构造一个输入,该输入能够将模型的某些filter最大化,进而判断该filter的主要识别的特征。输入构造的方法常见方法为gradient ascent。
\(
X^* = \argmax_{X}\sum_{i}\sum_{j}a_{ij}
\)
其中\(a_{ij}\)为filter在图片位置i,j的输出。
多数情况,该方法想得到理想效果需要大量调参数。部分论文中通过大量调参得到的结果如下。
引入生成器
基本思想与上面一致,但是主要通过引入生成器来达到较好的效果。原始的优化目标为\(X^* = \argmax_{X}y_{i}\), 引入图片生成器后,优化目标变为\(z^* = \argmax_{z}y_{i}\)。
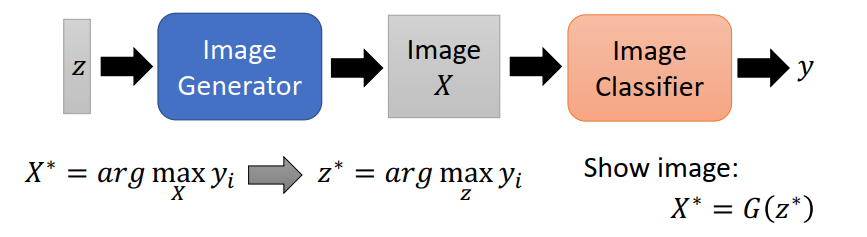
Nguyen, A., Clune, J., Bengio, Y., Dosovitskiy, A. and Yosinski, J., 2017. Plug & play generative networks: Conditional iterative generation of images in latent space. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4467-4477).
LIME
LIME的思想是使用简单模型在局部模仿全局模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号