



【外排序】只有 2G 内存, 如何排序 128G 数据?

在说明这个问题之前, 先来回顾一项计组基础知识: CPU最多可以访问到内存, 无法访问磁盘; 因此一般的排序算法(如快速/归并/堆/希尔)都只能对至少可存储在内存中的数据进行排序, 但现在需要面对的场景是数据量过大, 无法放入内存, 因此无法直接使用一般排序方法, 这时就需要使用外排序算法
外排序的初步思路
现在将问题缩小为, 假设有8G大小的数据(且假设这些数据都是整数)待排序, 而内存中只能放下2G数据, 那么最自然的思路当然是:
第一步, 每次读取2G大小的内容, 然后使用快排对这2G的内容进行排序, 再输出到临时文件中, 这样, 就拥有了4个有序的临时文件
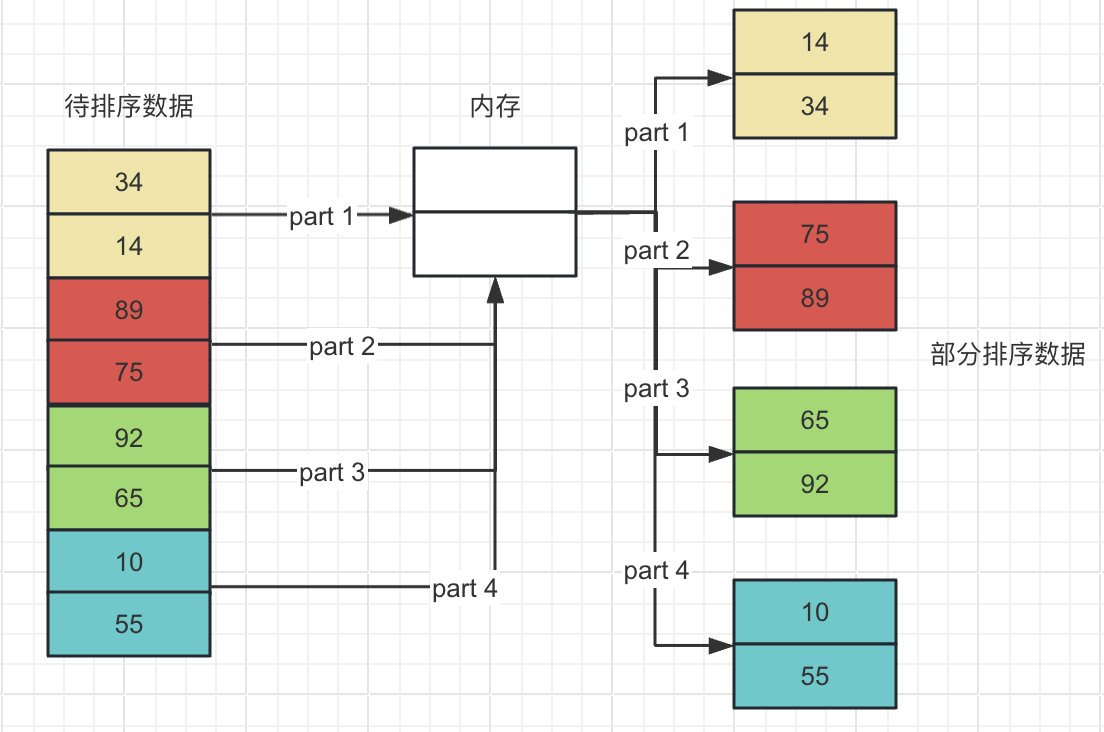
第二步, 查看指向这四个临时文件的文件指针, 假设第i个(1<=i<=4)指针指向的数据大小最小, 则将第i个指针指向的数据输出到结果中, 并位移第i个指针, 使其指向文件内的下一项数据
第三步, 如果4个文件指针都指向文件末尾, 则结束算法, 否则再次执行第二步
这种思路将整个外排序的过程分为了2个阶段:
预处理: 将大量无序内容分割成N个内部有序的小块
归并: 利用归并算法的思维, 对上一阶段产生的小块进行N路归并
缺陷
内存利用率不足: 快速排序的空间复杂度为$O(n)$, 这意味着如要排序2G大小的数据, 则要额外提供大约2G的内存空间, 实际存储数据的内存空间仅占全部空间的一半不到
CPU空置: 可以看到, 预处理过程中, 必须要首先读够2G大小的数据, 再进行排序, 但读取内容为io密集型任务, 而排序为CPU密集型任务, 两者应该并发进行, 才能最大化利用计算机资源
归并比较次数多: 假设每个临时文件的长度为m, 则归并算法的时间复杂度为$O(m*N)$, 耗时较多
改进
由于初步思路存在一定缺陷, 因此需要针对上述问题, 进行改进以提升效率:
对于预处理, 引入小根堆来对数据进行排序
对于归并过程, 引入竞赛树和最佳合并树来提升归并效率
预处理
小根堆
关于小根堆, 详细请学习"数据结构"课程
选择置换
假设内存空间最多可容纳s条数据, 获取待排序数据由另一线程RT执行, 则选择置换排序步骤如下:
与
RT通信, 获取s条数据, 利用这s条数据建立小根堆data创建与
data相关的新临时文件data file, 同时建立临时堆temp输出
data的堆顶数据x, 从RT获取一条待排序数据y; 如果$y<x$, 则y放入data, 否则, 将y放入temp如果
data为空(此时temp可能存储了s条数据), 则temp变为data, 跳转到第二步继续执行当不再能从
RT处获取任何数据时, 输出内存中剩余的数据并结束预处理流程
注意:
第三步中, 之所以要将y与刚输出到
data file的x进行比较, 是因为如果y在x之后输出到data file, 且y<x, 则data file内就会出现乱序的情况, 因此y必须要输出到其他临时文件中可以等到
temp内存储的数据数量达到$s/2$之后, 再对temp进行堆的初始化操作
有此可见, 外排序的预处理流程就是执行选择置换算法的流程
最佳合并树
假设, 经过预处理, 共生成三个临时文件A, B, C, 它们所包含的数据量如下, 现在要将它们进行2路归并, 且希望尽量减少从磁盘上读取的操作:
| 文件名 | 数据量 |
|---|---|
| A | 89 |
| B | 24 |
| C | 34 |
假设现在进行2路归并, 如果先将A和C归并为D(数据量为89+34=123), 则需要执行读写操作123次, 再将D与B归并为最终文件, 则需要执行读写操作123+24=147次, 因此, 一共需要执行读写操作123+147=270次
但是, 同样是2路归并, 如果先归并B和C为D, 则需执行读操作24+34=58次, 再归并A和D, 则需要执行读操作58+89=147次, 一共读写58+147=205次
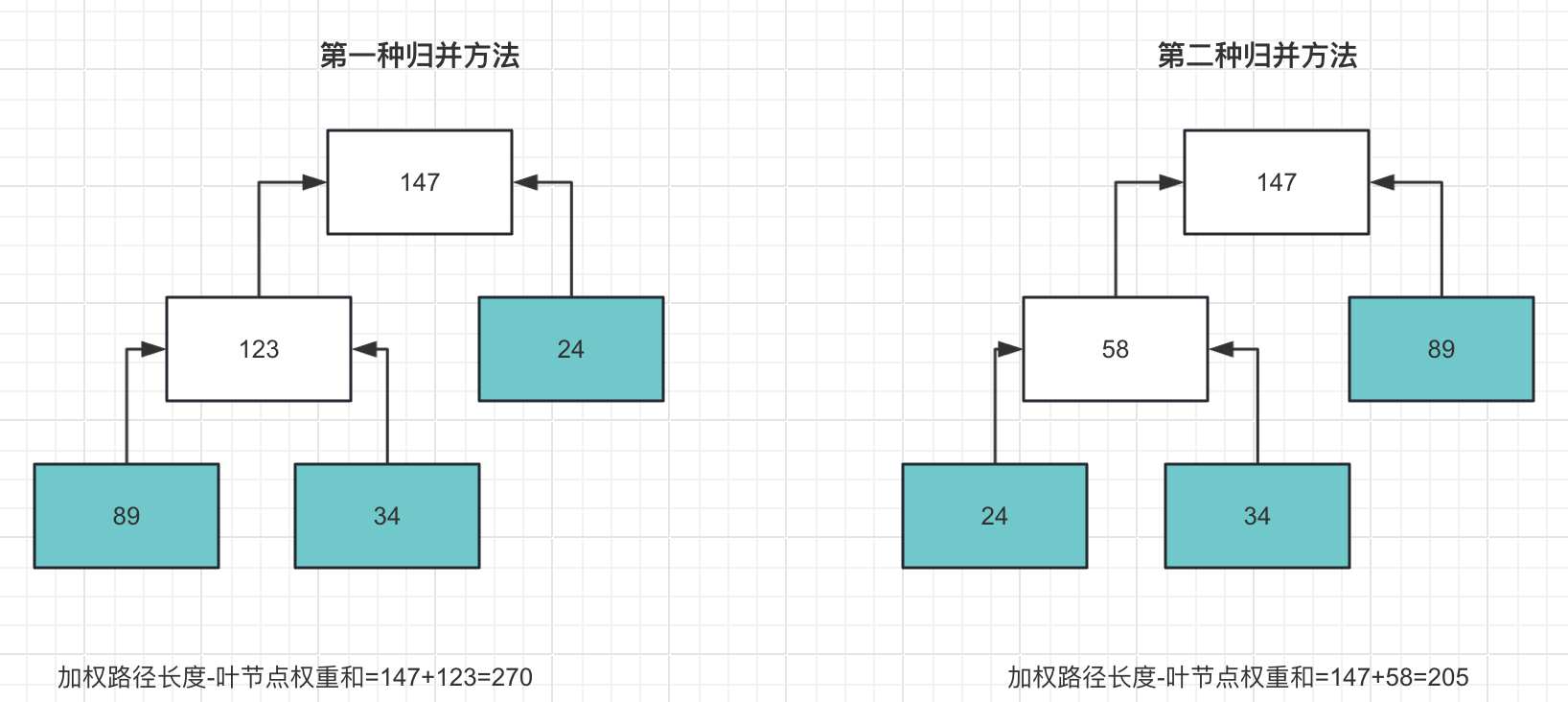
将两种归并方法用树的形式表示出来, 其中, 叶节点权重值为临时文件数据量, 可以发现, 读写次数完全取决于合并树的加权路径长度, 因此, 减少读写次数的目标就转化为求得加权路径最短的合并树
加权路径最短的合并树被称为最佳合并树
最佳合并树的构造方法与哈夫曼树类似, 区别仅在于最佳合并树为K叉树(K根据合并路数而变, 不一定为2)
归并
决定好合并次序后, 就可以开始执行归并操作
竞赛树
在这一步, 需要引入竞赛树, 竞赛树分为胜方树和败方树, 这里仅演示胜方树:
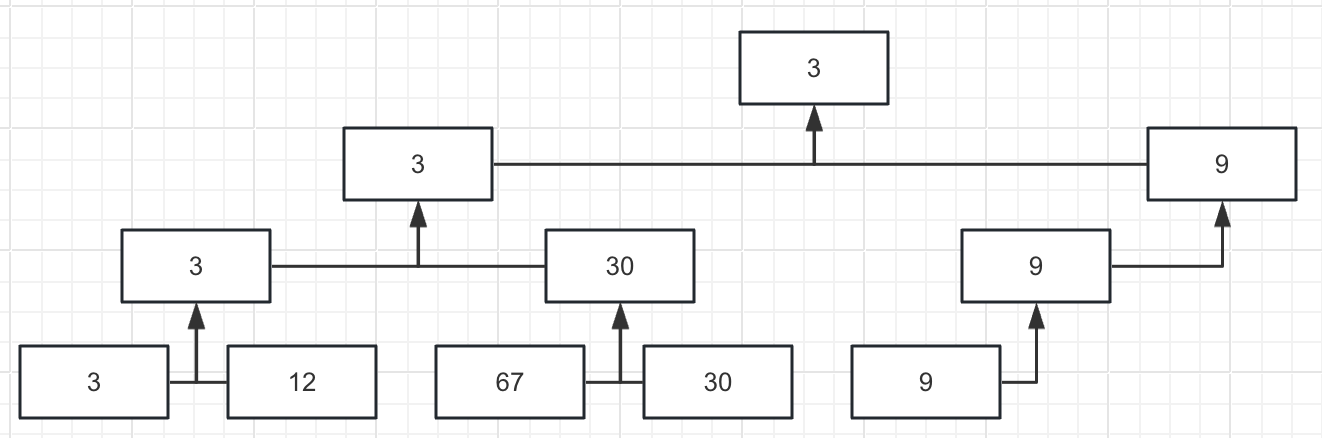
如图所示, 以5路归并为例, 从上一步选择出的临时文件中, 分别读取一条数据, 作为竞赛树的叶子节点, 使它们两两PK(比谁的值小), 胜方进入PK树的上一层, 循环执行此步骤, 直到选出值最小的数据
流程
归并操作的流程如下:
读取第一批K个数据, 利用它们构建竞赛树
从竞赛树中读取最终的胜者, 并确定它来自第i(1<=i<=K)份临时文件
将胜者输出, 并从第i份临时文件中读取下一条数据, 然后调整竞赛树
重复执行2, 3步, 直到所有数据均被输出
注意:
与预处理流程同理, 文件读取操作与比较操作可以并发进行
归并操作需要反复执行, 直到所有临时文件合成为最终文件

