
Python爬虫实践——爬取网站文章
初学Python,对爬虫也是一知半解,恰好有个实验需要一些数据,所以本次爬取的对象来自中国农业信息网中下属的一个科技板块种植技术的文章(http://www.agri.cn/kj/syjs/zzjs/)
首先,分析网站结构:各文章标题以列表的形式展示,点击标题获得则是文章的正文,如图所示:
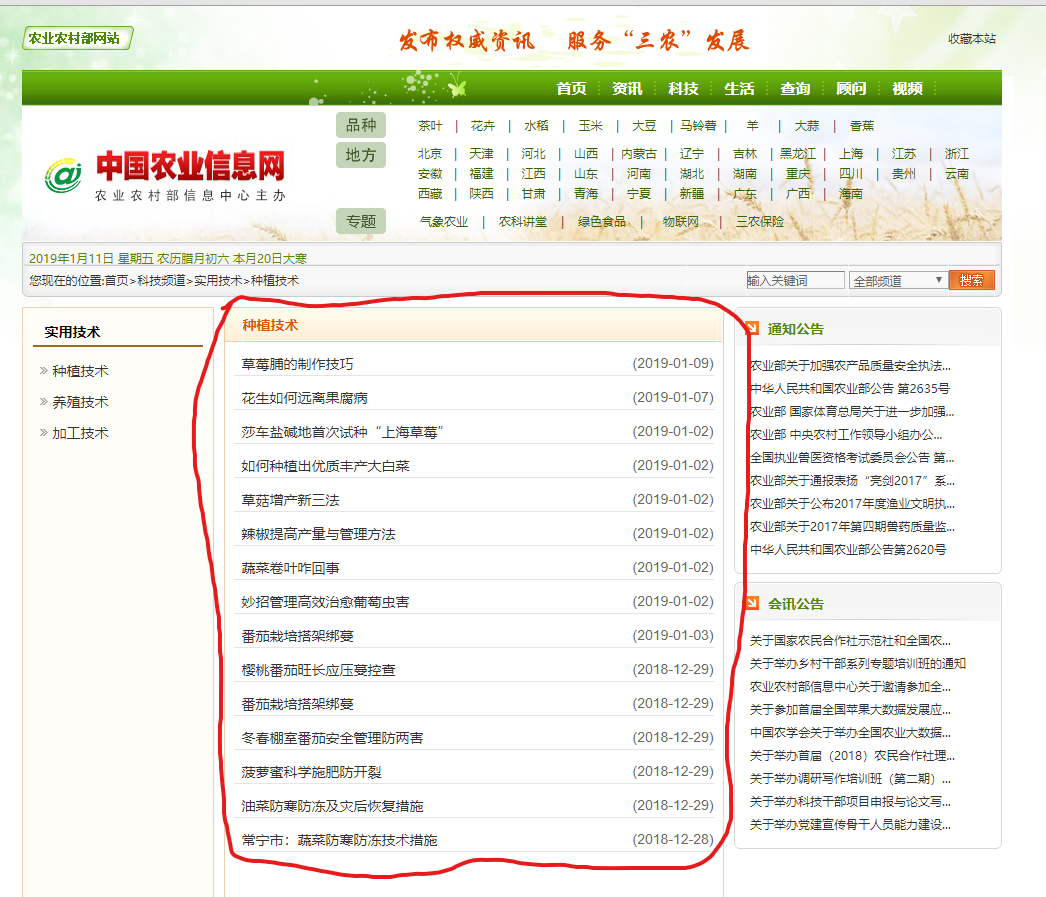

分析网页源码,不难看出图一所示的URL规律,其首页为 http://www.agri.cn/kj/syjs/zzjs/index.htm ,其后续页面分别为 http://www.agri.cn/kj/syjs/zzjs/index_1.htm 、http://www.agri.cn/kj/syjs/zzjs/index_2.htm …… 等等以此类推,因此可以使用循环对URL来赋值得到想要的页数。
下一步,获取新闻的标题和URL,通过解析网页源码,发现所有标题包含在如下结构中:

得到结构后,可以据此使用Beautifulsoup得到所需的a标签链接和标题,并将其存入dictionary中,使用key保存标题,而URL作为其value值
最后,将得到的dictionary遍历,取出每个链接并解析网页代码,得到需要的文章信息,最后一并存进数据库,代码如下:
# -*- coding: UTF-8 -*- from bs4 import BeautifulSoup import requests import sys import pymysql import re #--------set page amount---------- def set_download_urls(): downloadUrls = [] baseUrl = 'http://www.agri.cn/kj/syjs/zzjs/' downloadUrls.append('http://www.agri.cn/kj/syjs/zzjs/index.htm') for i in range(1,10): url = baseUrl + 'index_' + str(i) + '.htm' downloadUrls.append(url) return downloadUrls #--------get download page urls def get_download_tables(): downloadUrls = set_download_urls() tables = [] for url in downloadUrls: req = requests.get(url) req.encoding = 'utf-8' html = req.text table_bf = BeautifulSoup(html) tables.append(table_bf.find('table',width=500,align='center')) return tables #---------get article links------------ def get_download_url(): downloadTables = get_download_tables() articles = [] for each in downloadTables: articles.append(each.find_all('a',class_='link03')) return articles def read_article_info(): articles = get_download_url() baseUrl = 'http://www.agri.cn/kj/syjs/zzjs' dict = {} for each in articles: for item in each: dict[item.string] = baseUrl + item.get('href')[1:] return dict #---------method of save to MySQL----------- def save_mysql(title,date,source,content,tech_code,info_code): db = pymysql.connect('localhost','root','123456','persona') cursor = db.cursor() sql = 'INSERT INTO information_stock (title,date,source,content,tech_code,info_code) VALUES ("%s","%s","%s","%s",%s,%s)' % (title,date,source,content,tech_code,info_code) try: cursor.execute(sql) db.commit() print("write success") except Exception as e: db.rollback() print("write fail") print(e) db.close() #---------get content info and save --------------- def get_content(title,url): print(title + '---->' + url) req = requests.get(url) req.encoding = 'utf-8' html = req.text table_bf = BeautifulSoup(html) article = table_bf.find('table',width=640) #----article content----- #content = article.find(class_='TRS_Editor').get_text() #content = article.find('div',attrs={'id':re.compile("TRS_")}).select("p") content = article.select("p") info = article.find(class_='hui_12-12').get_text() date = info[3:19] source = info.split(":")[3] text = "" for item in content: text += item.get_text() text += "\n" #print(text) save_mysql(title,date,source,text,0,0) #--------save all article ----------- def save_data(): dict = read_article_info() for key,value in dict.items(): get_content(key,value) save_data()
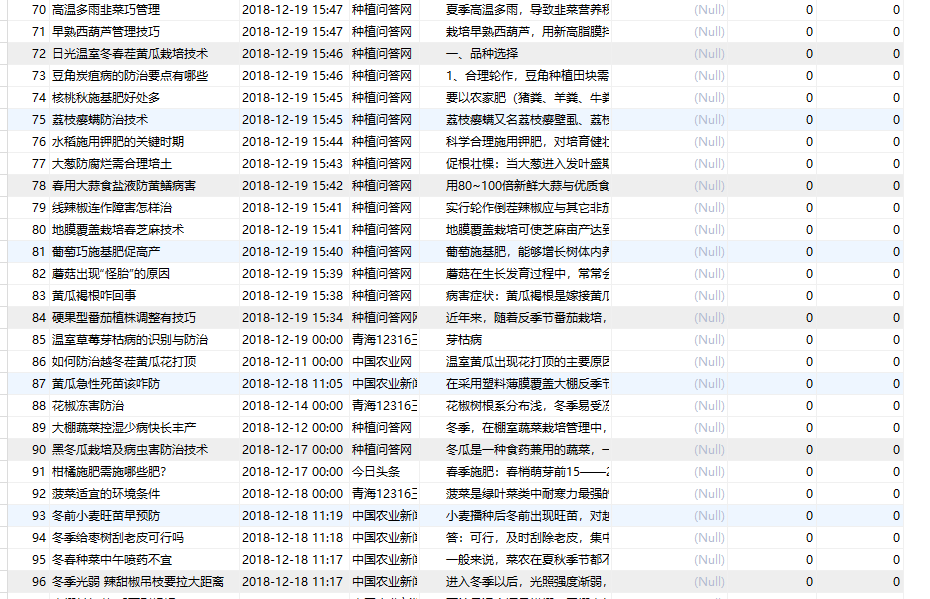
爬取结果入库:
请dalao不吝赐教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号