
OpenResty:Nginx与lua基础
OpenResty 的两个基石:NGINX 和 LuaJIT。
NGINX基础
在 OpenResty 的开发中,我们需要注意下面几点:
- 要尽可能少地配置 nginx.conf;
- 避免使用if、set 、rewrite 等多个指令的配合;
- 能通过 Lua 代码解决的,就别用 NGINX 的配置、变量和模块来解决。
这样可以最大限度地提高可读性、可维护性和可扩展性。
下面这段 NGINX 配置,就是一个典型的反例,可以说是把配置项当成了代码来使用,在使用 OpenResty 进行开发时需要避免。
location ~ ^/mobile/(web/app.htm) {
set $type $1;
set $orig_args $args;
if ( $http_user_Agent ~ "(iPhone|iPad|Android)" ) {
rewrite ^/mobile/(.*) http://touch.foo.com/mobile/$1 last;
}
proxy_pass http://foo.com/$type?$orig_args;
}
NGINX 配置
NGINX 通过配置文件来控制自身行为,它的配置可以看作是一个简单 的 DSL。NGINX 在进程启动的时候读取配置,并加载到内存中。如果修改了配置文件,需要重启或者重载 NGINX,再次读取后才能生效。只有 NGINX 的商业版本,才会在运行时, 以 API 的形式提供部分动态的能力。
如下为一段简单的nginx配置文件:
worker_processes auto;
pid logs/nginx.pid;
error_log logs/error.log notice;
worker_rlimit_nofile 65535;
events {
worker_connections 16384;
}
http {
server {
listen 80;
listen 443 ssl;
location / {
proxy_pass https://foo.com;
}
}
}
stream {
server {
listen 53 udp;
}
基础概念:
1.每个指令都有自己适用的上下文(Context),也就是NGINX配置文件中指令的作用域。
最上层的是 main,里面是和具体业务无关的一些指令,比如上面出现的 worker_processes、pid 和 error_log,都属于 main 这个上下文。另外,上下文是有层级关系的,比如 location 的上下文是 server, server 的上下文是 http,http 的上下文是 main。
指令不能运行在错误的上下文中,NGINX 在启动时会检测 nginx.conf 是否合法。比如把 listen 80; 从 server 上下文换到 main 上下文,然后启动 NGINX 服务,会看到类似这样的报错:
"listen" directive is not allowed here ......
2.NGINX 不仅可以处理 HTTP 请求 和 HTTPS 流量,还可以处理 UDP 和 TCP 流量。
其中,七层的放在 HTTP 中,四层的放在 stream中。在 OpenResty 里面, lua-nginx-module 和 streamlua-nginx-module 分别和这俩对应。
NGINX 支持的功能,OpenResty 并不一定支持,需要看 OpenResty 的版本号。
OpenResty 的版本号是和 NGINX 保持一致的,所以很容易识别。比如 NGINX 在 2018 年 3 月份发布的 1.13.10 版本中,增加了对 gRPC 的支持,但 OpenResty 在 2019 年 4 月份时的最新版本是 1.13.6.2,由此 可以推断 OpenResty 还不支持 gRPC。
MASTER-WORKER 模式
NGINX 启动后,会有一个 Master 进程和多个 Worker 进程(也可以只有一个 Worker 进程)。
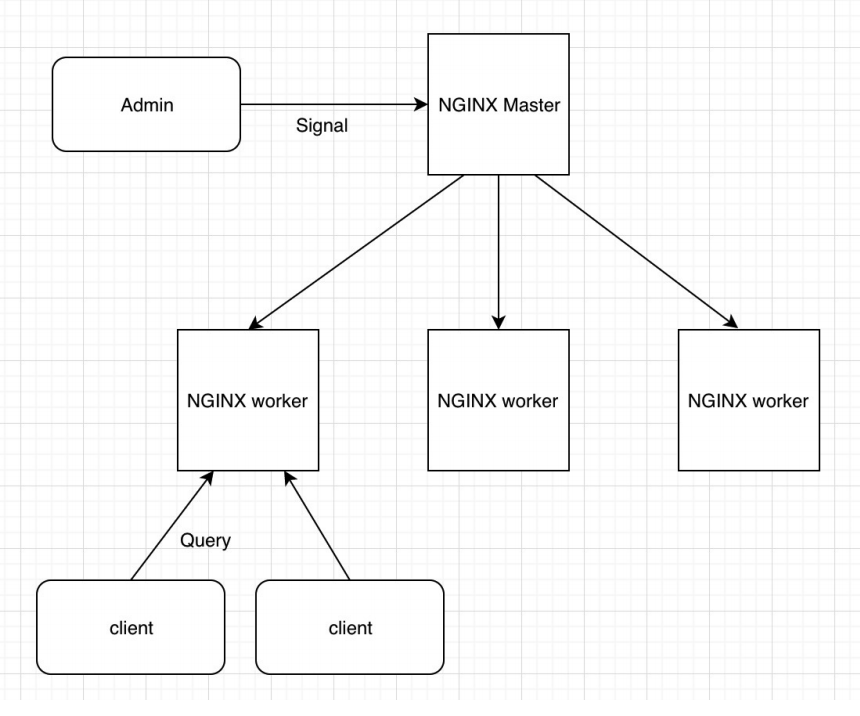
Master 进程,扮演“管理者”的角色,并不负责处理终端的请求,它是用来管理 Worker 进程的,包括接受管理员发送的信号量、监控 Worker 的运行状态。当 Worker 进程异常退出时, Master 进程会重新启动一个新的 Worker 进程。
Worker 进程则是“一线员工”,用来处理终端用户的请求。它是从 Master 进程 fork 出来的,彼此之间相互独立,互不影响。多进程的模式比 Apache多线程的模式要先进很多,没有线程间加锁,也方便调试。即使某个进程崩溃退出了,也不会影响其他 Worker 进程正常工作。
OpenResty 在 NGINX Master-Worker 模式的前提下,又增加了独有的特权进程(privileged agent)。 这个进程并不监听任何端口,和 NGINX 的 Master 进程拥有同样的权限,所以可以做一些需要高权限才能 完成的任务,比如对本地磁盘文件的一些写操作等。
如果特权进程与 NGINX 二进制热升级的机制互相配合,OpenResty 就可以实现自我二进制热升级的整个流程,而不依赖任何外部的程序。
减少对外部程序的依赖,尽量在 OpenResty 进程内解决问题,不仅方便部署、降低运维成本,也可以降低程序出错的概率。可以说,OpenResty 中的特权进程、ngx.pipe 等功能,都是出于这个目的。
执行阶段
执行阶段也是 NGINX 重要的特性,与 OpenResty 的具体实现密切相关。NGINX 有 11 个执行阶段,可以从 ngx_http_core_module.h 的源码中看到:
typedef enum {
NGX_HTTP_POST_READ_PHASE = 0,
NGX_HTTP_SERVER_REWRITE_PHASE,
NGX_HTTP_FIND_CONFIG_PHASE,
NGX_HTTP_REWRITE_PHASE,
NGX_HTTP_POST_REWRITE_PHASE,
NGX_HTTP_PREACCESS_PHASE,
NGX_HTTP_ACCESS_PHASE,
NGX_HTTP_POST_ACCESS_PHASE,
NGX_HTTP_PRECONTENT_PHASE,
NGX_HTTP_CONTENT_PHASE,
NGX_HTTP_LOG_PHASE
} ngx_http_phases;
OpenResty 也有 11 个 *_by_lua指令,它们和 NGINX 阶段的关系如下图所示(图片来 自 lua-nginx-module 文档):
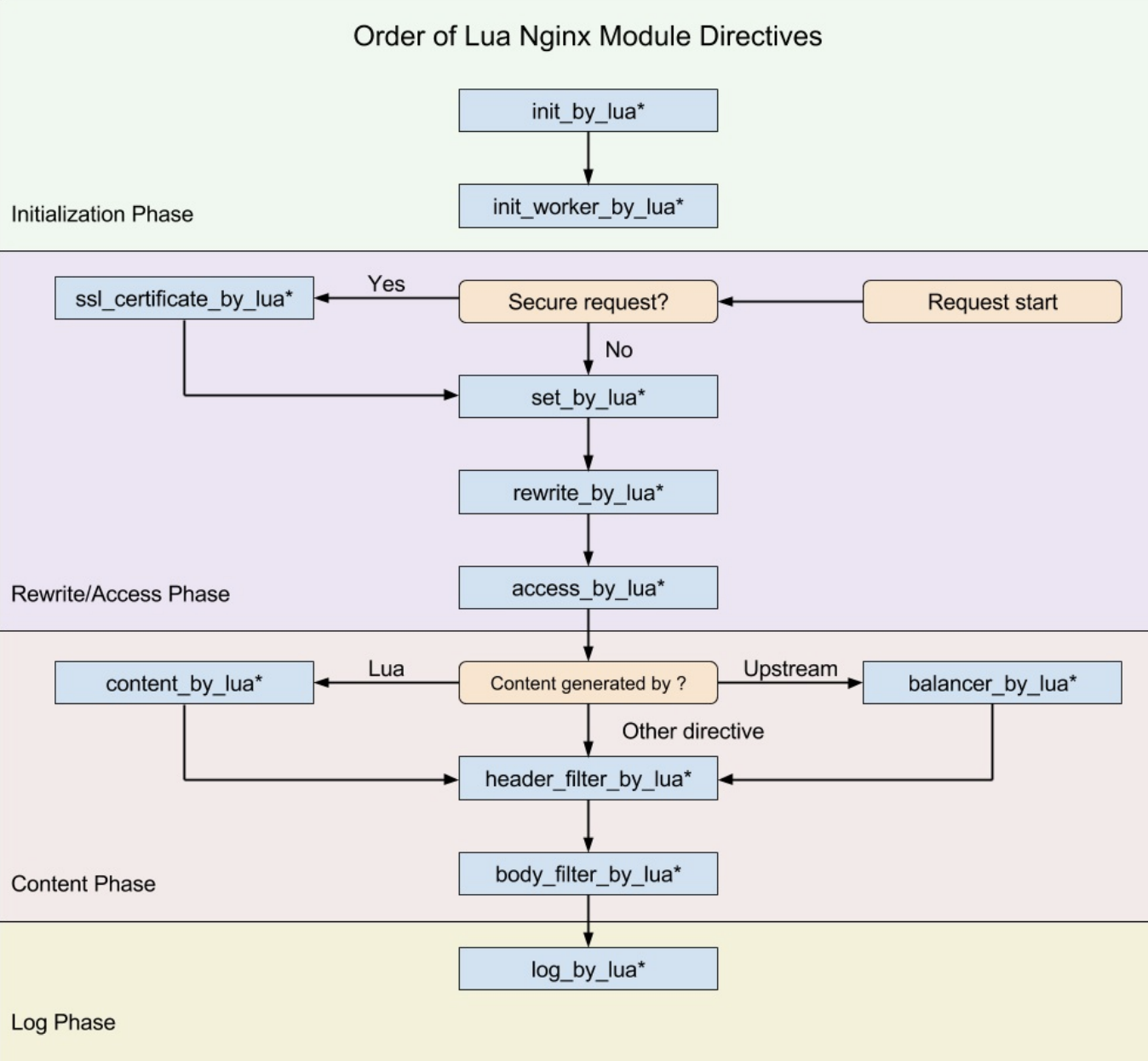
其中, init_by_lua 只会在 Master 进程被创建时执行,init_worker_by_lua 只会在每个 Worker 进程被创建时执行。其他的 *_by_lua 指令则是由终端请求触发,会被反复执行。
所以在 init_by_lua 阶段,我们可以预先加载 Lua 模块和公共的只读数据,这样可以利用操作系统的 COW(copy on write)特性,来节省一些内存。
对于业务代码来说,其实大部分的操作都可以在 content_by_lua 里面完成,但更推荐的做法,是根据不同的功能来进行拆分,比如下面这样:
set_by_lua:设置变量;
rewrite_by_lua:转发、重定向等;
access_by_lua:准入、权限等;
content_by_lua:生成返回内容;
header_filter_by_lua:应答头过滤处理;
body_filter_by_lua:应答体过滤处理;
log_by_lua:日志记录。
举一个例子来说明这样拆分的好处。假设对外提供了很多明文 API,现在需要增加自定义的加密 和解密逻辑。那么需要修改所有 API 的代码吗?
# 明⽂协议版本
location /mixed {
content_by_lua '...'; # 处理请求
}
当然不用。事实上,利用阶段的特性,我们只需要简单地在 access 阶段解密,在 body filter 阶段加密就可以了,原来 content 阶段的代码是不用做任何修改的:
# 加密协议版本
location /mixed {
access_by_lua '...'; # 请求体解密
content_by_lua '...'; # 处理请求,不需要关⼼通信协议
body_filter_by_lua '...'; # 应答体加密
}
二进制热升级
在修改完 NGINX 的配置文件后,还需要重启才能生效。但在 NGINX 升级自身版本的时候,却可以做到热升级。这看上去有点儿本末倒置,不过,考虑到 NGINX 是从传统静态的负载均衡、反向代理、文件缓存起家的,这倒也可以理解。
热升级通过向旧的 Master 进程发送 USR2 和 WINCH 信号量来完成。对于这两步,前者的作用,是启动新的 Master 进程;后者的作用,是逐步关闭Worker 进程。
执行完这两步后,新的 Master 和新的 Worker 就已经启动了。不过此时,旧的 Master 并没有退出。不退出的原因也很简单,如果你需要回退,依旧可以给旧的 Master 发送 HUP 信号量。当然,如果你已经确定不需要回退,就可以给旧 Master 发送 KILL 信号量来退出。
至此,二进制的热升级就完成了。
在 OpenResty 中用到的都是 Nginx 的基础知识,主要涉及到配置、主从进程、执行阶段等。而 其他能用 Lua 代码解决的,尽量用代码来解决,而非使用Nginx 的模块和配置,这是在学习 OpenResty 中的一个思路转变。
LUA基础
Lua是 OpenResty 中使用的脚本语言。Lua 在设计之初,就把自己定位为一个简单、轻量、可嵌入的胶水语言,没有走大而全的路线。虽然平常工作中可能没有直接编写 Lua 代码,但 Lua 的使用其实非常广泛。很多的网 游,比如魔兽世界,都会采用 Lua 来编写插件;而键值数据库 Redis 则是内置了 Lua 来控制逻辑。
另一方面,虽然 Lua 自身的库比较简单,但它可以方便地调用 C 库,大量成熟的 C 代码都可以为其所用。 比如在 OpenResty 中,很多时候都需要你调用 NGINX 和 OpenSSL 的 C 函数,而这都得益于 Lua 和 LuaJIT 这种方便调用 C 库的能力。
环境和 hello world
不用专门去安装标准 Lua 5.1 之类的环境,因为 OpenResty 已经不再支持标准 Lua,而只支持 LuaJIT。 这里介绍的 Lua 语法,也是和 LuaJIT 兼容的部分,而不是基于最新的 Lua 5.3。
在 OpenResty 的安装目录下,可以找到 LuaJIT 的目录和可执行文件。
$ which luajit /usr/local/Cellar/openresty/1.15.8.3_1/luajit/bin/luajit $ luajit -v LuaJIT 2.1.0-beta3 -- Copyright (C) 2005-2017 Mike Pall. http://luajit.org/
使用resty运行lua脚本,它最终也是用 LuaJIT 来执行的:
$ resty -e 'print("hello world")'
hello world
数据类型
Lua 中的数据类型不多,你可以通过 type 函数来返回一个值的类型,比如下面这样的操作:
$ resty -e 'print(type("hello world"))
> print(type(print))
> print(type(true))
> print(type(360.0))
> print(type({}))
> print(type(nil))
> '
string
function
boolean
number
table
nil
这几种就是 Lua 中的基本数据类型了。下面来简单介绍一下:
字符串
在 Lua 中,字符串是不可变的值,如果你要修改某个字符串,就等于创建了一个新的字符串。这种做法显然有利有弊:好处是即使同一个字符串出现很多次,在内存中也只有一份;但劣势也很明显,如果想修改、拼接字符串,会额外地创建很多不必要的字符串。
如下是把 1 到 10 这些数字当作字符串拼接起来。在 Lua 中,使用两个点号来表示字符串的相加:
$ resty -e ' > local s = "" > for i = 1,10 do > s = s..tostring(i) > end > print(s) > ' 12345678910
在 Lua 中,你有三种方式可以表达一个字符串:单引号、双引号,以及长括号(两对中括号)[[]]。长括号中的字符串不会做任何的转义处理。
$ resty -e 'print([[string has \n and \r]])' string has \n and \r
如果上面那段字符串中包括了长括号本身,在长括号中间增加一个或者多个 = 符号:
$ resty -e 'print([=[ string has a [[]]. ]=])' string has a [[]].
布尔值
true 和 false。但在 Lua 中,只有 nil 和 false 为假,其他都为真,包括 0 和空字符串也为真。
$ resty -e 'local a = 0
> if a then
> print("true")
> end
> a = ""
> if a then
> print("true")
> end'
true
true
这种判断方式和很多常见的开发语言并不一致,所以,为了避免在这种问题上出错,可以显式地写明比较 的对象,比如下面这样:
$ resty -e 'local a = 0
if a == false then
print("true")
end
'
数字
Lua 的 number 类型,是用双精度浮点数来实现的。LuaJIT 支持 dual-number(双数)模 式,也就是说, LuaJIT 会根据上下文来用整型来存储整数,而用双精度浮点数来存放浮点数。
LuaJIT 还支持⻓⻓整型的大整数,比如下面的例子:
$ resty -e 'print(9223372036854775807LL - 1)' 9223372036854775806LL
函数
函数在 Lua 中是一等公民,可以把函数存放在一个变量中,也可以当作另外一个函数的入参和出参。
下面两个函数的声明是完全等价的:
function foo() end foo = function () end
table
table 是 Lua 中唯一的数据结构
$ resty -e 'local color = {first = "red"}
> print(color["first"])'
red
空值
在 Lua 中,空值就是 nil。如果定义了一个变量,但没有赋值,它的默认值就是 nil:
$ resty -e 'local a > print(type(a))' nil
真正进入 OpenResty 体系中后,会发现很多种空值,比如 ngx.null 等等.
常用标准库
Lua 比较小巧,内置的标准库并不多。而且,在 OpenResty 的环境中,Lua 标准库的优先级是很低的。对 于同一个功能,更推荐优先使用 OpenResty 的 API 来解决,然后是 LuaJIT 的库函数,最后才是标准 Lua 的函数。
OpenResty的API > LuaJIT的库函数 > 标准Lua的函数,这个优先级会对性能产生非常大的影响。
几个比较常用的Lua标准库:
string 库
字符串操作是最常用到的,也是坑最多的地方。有一个简单的原则,那就是如果涉及到正则表达式的, 请一定要使用 OpenResty 提供的 ngx.re.* 来解决,不要用 Lua 的 string.* 处理。这是因为,Lua 的正 则独树一帜,不符合 PCRE 的规范。
其中 string.byte(s [, i [, j ]]),是比较常用到的一个 string 库函数,它返回字符 s[i]、s[i + 1]、 s[i + 2]、······、s[j] 所对应的 ASCII 码。i 的默认值为 1,即第一个字节,j 的默认值为 i。
$ resty -e 'print(string.byte("abc", 1, 3))
> print(string.byte("abc", 3)) -- 缺少第三个参数,第三个参数默认与第⼆个相同,此时为 3
> print(string.byte("abc")) -- 缺少第⼆个和第三个参数,此时这两个参数都默认为 1
> '
979899
99
97
table 库
在 OpenResty 的上下文中,对于Lua 自带的 table 库,除了 table.concat 、table.sort 等少数几个函 数,大部分都不推荐使用。
table.concat一般用在字符串拼接的场景下,可以避免生成很多无用的字符串。
$ resty -e 'local a = {"A","B","C"} print(table.concat(a))'
ABC
math 库
Lua math 库由一组标准的数学函数构成。数学库的引入,既丰富了 Lua 编程语言的功能,同时也方便了程序的编写。
在 OpenResty 的实际项目中,我们很少用 Lua 去做数学方面的运算,其中和随机数相关的 math.random() 和 math.randomseed() 两个函数比较常用,比如下面的这段代码可以在指 定的范围内,随机地生成两个数字。
$ resty -e 'math.randomseed (os.time()) > print(math.random()) > print(math.random(100))' 0.6389552204975 39
虚变量
设想这么一个场景,当一个函数返回多个值的时候,有些返回值我们并不需要,这时候,应该怎么接收这些值呢?
Lua 提供了一个虚变量(dummy variable)的概念, 按照惯例以一个下划线来命名,用来表示丢弃不需要的数值,仅仅起到占位的作用。
以 string.find 这个标准库函数为例,来看虚变量的用法。这个标准库函数会返回两个值,分别代表开始和结束的下标。
如果我们只需要获取开始的下标,只声明一个变量来接收 string.find 的返回值即可:
$ resty -e 'local s = string.find("hello","he") print(s)'
1
如果只想获取结束的下标,那就必须使用虚变量了:
$ resty -e 'local _, end_pos = string.find("hello", "he")
> print(end_pos)'
2
除了在返回值里使用,虚变量还经常用于循环中,
$ resty -e 'for _, v in ipairs({4,5,6}) do
> print(v)
> end'
4
5
6
而当有多个返回值需要忽略时,你可以重复使用同一个虚变量。
LuaJIT
LuaJIT是OpenResty 的另一块基石。在 OpenResty 中,写出正确的 LuaJIT 代码的门槛并不高,但要写出高效的 LuaJIT 代码绝非易事。
LuaJIT 在 OpenResty 整体架构中的位置:
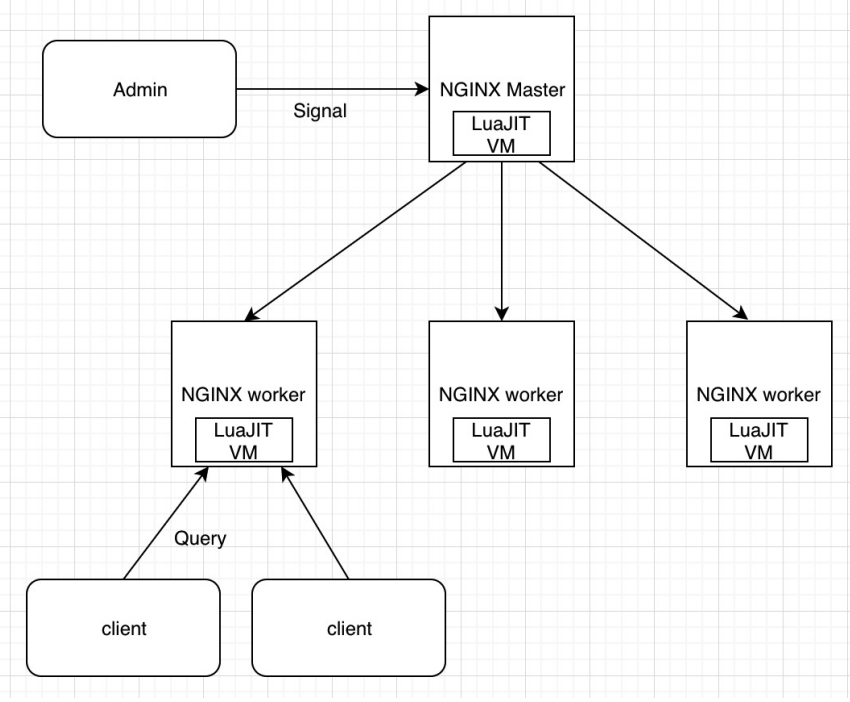
OpenResty 的 worker 进程都是 fork master 进程而得到的, 其实, master 进程中的 LuaJIT 虚拟机也会一起 fork 过来。在同一个 worker 内的所有协程,都会共享这个 LuaJIT 虚拟机,Lua 代 码的执行也是在这个虚拟机中完成的。这可以算是 OpenResty 的基本原理。
标准 Lua 和 LuaJIT 的关系
标准 Lua 和 LuaJIT 是两回事儿,LuaJIT 只是兼容了 Lua 5.1 的语法,并对 Lua 5.2 和 5.3 做了选择性支持。
在 OpenResty 几年前的老版本中, 编译的时候,可以选择使用标准 Lua VM ,或者 LuaJIT VM 来作为执行环境,不过,现在已经去掉了对标 准 Lua 的支持,只支持 LuaJIT。
OpenResty 并没有直接使用 LuaJIT 官方提供的 2.1.0-beta3 版本,而是在此基础上,扩展了 自己的 fork: [openresty-luajit2]
为什么选择 LuaJIT
不直接使用Lua,而是要用open resty维护的LuaJIT 最主要的原因,还是LuaJIT的性能优势。
其实标准 Lua 出于性能考虑,也内置了虚拟机,所以 Lua 代码并不是直接被解释执行的,而是先由 Lua 编 译器编译为字节码(Byte Code),然后再由 Lua 虚拟机执行。
而 LuaJIT 的运行时环境,除了一个汇编实现的 Lua 解释器外,还有一个可以直接生成机器代码的 JIT 编译 器。开始的时候,LuaJIT和标准 Lua 一样,Lua 代码被编译为字节码,字节码被 LuaJIT 的解释器解释执行。
但不同的是,LuaJIT的解释器会在执行字节码的同时,记录一些运行时的统计信息,比如每个 Lua 函数调用 入口的实际运行次数,还有每个 Lua 循环的实际执行次数。当这些次数超过某个随机的阈值时,便认为对 应的 Lua 函数入口或者对应的 Lua 循环足够热,这时便会触发 JIT 编译器开始工作。
JIT 编译器会从热函数的入口或者热循环的某个位置开始,尝试编译对应的 Lua 代码路径。编译的过程,是 把 LuaJIT 字节码先转换成LuaJIT 自己定义的中间码(IR),然后再生成针对目标体系结构的机器码。
所谓 LuaJIT 的性能优化,本质上就是让尽可能多的 Lua 代码可以被 JIT 编译器生成机器码,而不是回 退到 Lua 解释器的解释执行模式。
Lua 特别之处
Lua 的下标从 1 开始
$ resty -e 'local t={100};ngx.say(t[1])'
100
使用 .. 来拼接字符串
$ resty -e "ngx.say('hello' .. ', world')"
hello, world
只有 table 这一种数据结构
不同于 Python 这种内置数据结构丰富的语言,Lua 中只有一种数据结构,那就是 table,它里面可以包括数组和哈希表:
$ resty -e '
> local color = {first = "red", "blue", third = "green", "yellow"}
> print(color["first"])
> print(color[1])
> print(color["third"])
> print(color[2])
> print(color[3])
> '
red
blue
green
yellow
如果不显式地用_键值对_的方式赋值,table 就会默认用数字作为下标,从 1 开始。所以 color[1] 就是 blue。
另外,想在 table 中获取到正确长度,也是一件不容易的事情,我们来看下面这些例子:
$ resty -e 'local t1 = {1,2,3};print("t1 length:" .. table.getn(t1))'
t1 length:3
$ resty -e 'local t2 = { 1, a = 2, 3 };print("t2 length: " .. table.getn(t2))'
t2 length: 2
$ resty -e 'local t3 = { 1, nil };print("t3 length: " .. table.getn(t3))'
t3 length: 1
$ resty -e 'local t4 = { 1, nil, 2 };print("t4 length: " .. table.getn(t4))'
t4 length: 1
想 要在Lua 中获取 table 长度,必须注意到,只有在 table 是 序列 的时候,才能返回正确的值。
先序列是数组(array)的子集,也就是说,table 中的元素都可以用正整数下标访问到,不存在键值对的情况。对应到上面的代码中,除了 t2 外,其他的 table 都是 array。
序列中不包含空洞(hole),即 nil。综合这两点来看,上面的 table 中, t1 是一个序列,而 t3 和 t4 是 array,却不是序列(sequence)。
t4 的长度是 1 是因为,在遇到 nil 时,获取长度的逻辑就不继续往下运行,而是直接返回了。
默认是全局变量
除非相当确定,否则在 Lua 中声明变量时,前面都要加上 local,是因为在 Lua 中,变量默认是全局的,会被放到名为 _G 的 table 中。不加 local 的变量会在全局表中查 找,这是昂贵的操作。如果再加上一些变量名的拼写错误,就会造成难以定位的 bug。
所以,在 OpenResty 编程中,应该总是使用 local 来声明变量,即使在 require module 的时候也是一样:
-- Recommended
local xxx = require('xxx')
-- Avoid
require('xxx')
LuaJIT
除了兼容 Lua 5.1 的语法并支持 JIT 外,LuaJIT 还紧密结 合了 FFI(Foreign Function Interface),可以直接在 Lua 代码中调用外部的 C 函数和使用 C 的数据结构。
$ resty -e '
local ffi = require("ffi");
ffi.cdef[[
int printf(const char *fmt, ...);
]];
ffi.C.printf("Hello %s! \n", "world");
'
Hello world!
这几行代码,就可以直接在 Lua 中调用 C 的 printf 函数,打印出 Hello world!。
类似的,我们可以用 FFI 来调用 NGINX、OpenSSL 的 C 函数,来完成更多的功能。实际上,FFI 方式比传 统的 Lua/C API 方式的性能更优,这也是 lua-resty-core 项目存在的意义。
出于性能方面的考虑,LuaJIT 还扩展了 table 的相关函数:table.new 和 table.clear。这是两 个在性能优化方面非常重要的函数。
为什么lua-resty-core性能更高一些
在 Lua 中,可以用 Lua C API 来调用 C 函数,而在 LuaJIT 中还可以使用 FFI。对 OpenResty 而言:
- 在核心的 lua-nginx-module 中,调用 C 函数的 API,都是使用 Lua C API 来完成的;
- 而在 lua-resty-core 中,则是把 lua-nginx-module 已有的部分 API,使用 FFI 的模式重新实现了一遍。
以 ngx.base64_decode 这个很简单的 API 为例,看下 Lua C API 和 FFI 的实现有何不同 之处。
Lua CFunction
先来看下, lua-nginx-module 中用 Lua C API 是如何实现的。在项目的代码中搜索 decode_base64,可以找到它的代码实现在 ngx_http_lua_string.c 中
lua_pushcfunction(L, ngx_http_lua_ngx_decode_base64); lua_setfield(L, -2, "decode_base64");
这里注册了一个 CFunction:ngx_http_lua_ngx_decode_base64, 而它与 ngx.base64_decode 这个对外暴露的 API 是对应关系。
在这个 C 文件中搜索 ngx_http_lua_ngx_decode_base64,它定义在文件的开始位置:
static int ngx_http_lua_ngx_decode_base64(lua_State *L)
对于那些能够被 Lua 调用的 C 函数来说,它的接口必须遵循 Lua 要求的形式,也就是 typedef int (*lua_CFunction)(lua_State* L)。它包含的参数是 lua_State 类型的指针 L ;它的返回值类型是 一个整型,表示返回值的数量,而非返回值自身。
它的实现如下:
static int
ngx_http_lua_ngx_decode_base64(lua_State *L)
{
ngx_str_t p, src;
src.data = (u_char *) luaL_checklstring(L, 1, &src.len);
p.len = ngx_base64_decoded_length(src.len);
p.data = lua_newuserdata(L, p.len);
if (ngx_decode_base64(&p, &src) == NGX_OK) {
lua_pushlstring(L, (char *) p.data, p.len);
} else {
lua_pushnil(L);
}
return 1;
}
这段代码中,最主要的是 ngx_base64_decoded_length 和 ngx_decode_base64, 它们都是 NGINX 自身提供的 C 函数。
用 C 编写的函数,无法把返回值传给 Lua 代码,而是需要通过栈,来传递 Lua 和 C 之间的调用 参数和返回值。同时,这些代码也不能被 JIT 跟踪到, 所以对于 LuaJIT 而言,这些操作是处于黑盒中的,没法进行优化。
LuaJIT FFI
而 FFI 则不同。FFI 的交互部分是用 Lua 实现的,这部分代码可以被 JIT 跟踪到,并进行优化;当然,代码 也会更加简洁易懂。
还是以 base64_decode为例,它的 FFI 实现分散在两个仓库中: lua-resty-core 和 lua-nginx-module。
先来看下前者里面实现的代码:
ngx.decode_base64 = function (s)
local slen = #s
local dlen = base64_decoded_length(slen)
local dst = get_string_buf(dlen)
local pdlen = get_size_ptr()
local ok = C.ngx_http_lua_ffi_decode_base64(s, slen, dst, pdlen)
if ok == 0 then
return nil
end
return ffi_string(dst, pdlen[0])
end
OpenResty 中的函数都是有命名规范的:
- ngx_http_lua_ffi_ ,是用 FFI 来处理 NGINX http 请求的 Lua 函数;
- ngx_http_lua_ngx_ ,是用 Cfunction 来处理 NGINX http 请求的 Lua 函数;
- 其他 ngx_ 和 lua_ 开头的函数,则分别属于 NGINX 和 Lua 的内置函数。
LuaJIT FFI GC
在 FFI 中申请的内存,到底由谁来管理呢?是应该我们在 C 里面手动释 放,还是 LuaJIT 自动回收呢?
这里有个简单的原则:LuaJIT 只负责由自己分配的资源;而 ffi.C 是 C 库的命名空间,所以,使用 ffi.C 分配的空间不由 LuaJIT 负责,需要你自己手动释放。
举个例子,比如你使用 ffi.C.malloc 申请了一块内存,那你就需要用配对的 ffi.C.free 来释放。 LuaJIT 的官方文档中有一个对应的示例:
local p = ffi.gc(ffi.C.malloc(n), ffi.C.free) ... p = nil -- Last reference to p is gone. -- GC will eventually run finalizer: ffi.C.free(p)
这段代码中,ffi.C.malloc(n) 申请了一段内存,同时 ffi.gc 就给它注册了一个析构的回调函数 ffi.C.free。这样一来,p 这个 cdata 在被 LuaJIT GC 的时候,就会自动调用 ffi.C.free,来释放 C 级别的内存。而 cdata 是由 LuaJIT 负责 GC的 ,所以上述代码中的 p 会被 LuaJIT 自动释放。 这里要注意,如果你要在 OpenResty 中申请大块的内存,更推荐用 ffi.C.malloc 而不是 ffi.new。原因也很明显:
- ffi.new 返回的是一个 cdata,这部分内存由 LuaJIT 管理;
- LuaJIT GC 的管理内存是有上限的,OpenResty 中的 LuaJIT 并未开启 GC64 选项,所以单个 worker 内存 的上限只有2G。一旦超过 LuaJIT 的内存管理上限,就会导致报错。
在使用 FFI 的时候,我们还需要特别注意内存泄漏的问题。
lua-resty-core
FFI 的方式不仅代码更简洁,而且可以被 LuaJIT 优化,显然是更优的选 择。其实现实也是如此,实际上,CFunction 的实现方式已经被 OpenResty 废弃,相关的实现也从代码库中移除了。现在新的 API,都通过 FFI 的方式,在 lua-resty-core 仓库中实现。
在 OpenResty 2019 年 5 月份发布的 1.15.8.1 版本前,lua-resty-core 默认是不开启的,而这不仅会带来性能损失,更严重的是会造成潜在的 bug。所以,还在使用历史版本的用户,都手动开启 lua-resty-core。需要在 init_by_lua 阶段,增加一行代码就可以了
require "resty.core"
1.15.8.1 版本中,已经增加了 lua_load_resty_core 指令,默认开启了 luaresty-core。
lua-resty-core 中不仅重新实现了部分 lua-nginx-module 项目中的 API,比如 ngx.re.match、ngx.md5 等,还实现了不少新的 API,比如 ngx.ssl、ngx.base64、ngx.errlog、 ngx.process、ngx.re.split、ngx.resp.add_header、ngx.balancer、ngx.semaphore 等等。
FFI 虽然好,却也并不是性能银弹。它之所以高效,主要原因就是可以被 JIT 追踪并优化。如果你写的 Lua 代码不能被 JIT,而是需要在解释模式下执行,那么 FFI 的效率反而会更低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号