
MongoDB事务开发:读操作事务(未完成)
在读取数据的过程中我们需要关注以下两个问题:
从哪里读,关注数据节点位置;
什么样的数据可以读(数据是否提交),关注数据的隔离性。
第一个问题由readPreference来解决
第二个问题由readConcern来解决
什么是readPreference
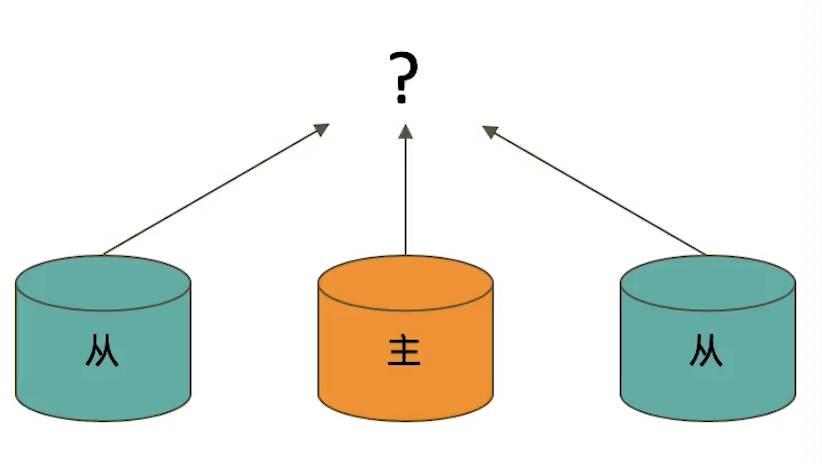
readPreference决定使用哪一个节点来满足正在发起的读请求。可选值包括:
- primary:只选择主节点(默认值);
- primaryPreferred:优先选择主节点,如果不可用则选择从节点;
- secondary:只选择从节点;
- secondaryPreferred:优先选择从节点,如果从节点不可用则选择主节点;
- nearest:选择最近的节点(使用ping time,针对多数据中心部署的情况)。
readPreference场景举例

readPreference与Tag
readPreference只能控制使用一类节点(按照节点的角色,不是固定的节点)。Tag则可以将节点选择控制到一个或几个节点。考虑以下场景:
一个5个节点的复制集;
3个节点硬件较好,专用于服务线上客户;
2个节点硬件较差,专用于生成报表
可以使用Tag来达到这样的控制目的:
为3个较好的节点打上{purpose:"online"};
为2个较差的节点打上{purpose:"analyse"}
在线应用读取时指定online,报表读取时指定reporting
readPreference配置
通过MongoDB的连接串参数:
mongodb://host1:27107,host2:27107,host3:27017/?replicaSet=rs&readPreference=secondary
通过MongoDB驱动程序API:
MongoCollection.withReadPreference(ReadPreferene readPref)
Mongo Shell
db.collection.find({}).readPref("secondary")
readPreference实验:从节点读

注意事项
- 指定readPreference时也应该注意高可用问题。例如将readPreference指定primary,则发生故障转移不存在primary期间将没有节点可读。如果业务允许,则应该选择primaryPreferred;
- 使用Tag时也会遇到同样的问题,如果只有一个节点拥有一个特定Tag,则在这个节点失效时将无节点可读。这在有时候是期望的结果,有时候不是。例如:
- 如果报表使用的节点失效,即使不生成报表,通常也不希望将报表负载转移到其它节点上,此时只有一个节点有报表Tag是合理的选择。
- 如果线上节点失效,通常希望有替代节点,所以应该保持多个节点有同样的Tag
- Tag有时需要与优先级 选举权综合考虑。例如做报表的节点通常不会希望它成为主节点,则优先级应该为0
什么是readConcern
在readPreference选择了指定的节点后,readConcern决定这个节点上的数据哪些是可读的,类似于关系数据库的隔离级别(脏读,提交读)。可选值包括:
available:读取所有可用的数据;
local:读取所有可用且属于当前分片的数据
majority:读取在大多数节点上提交完成的数据
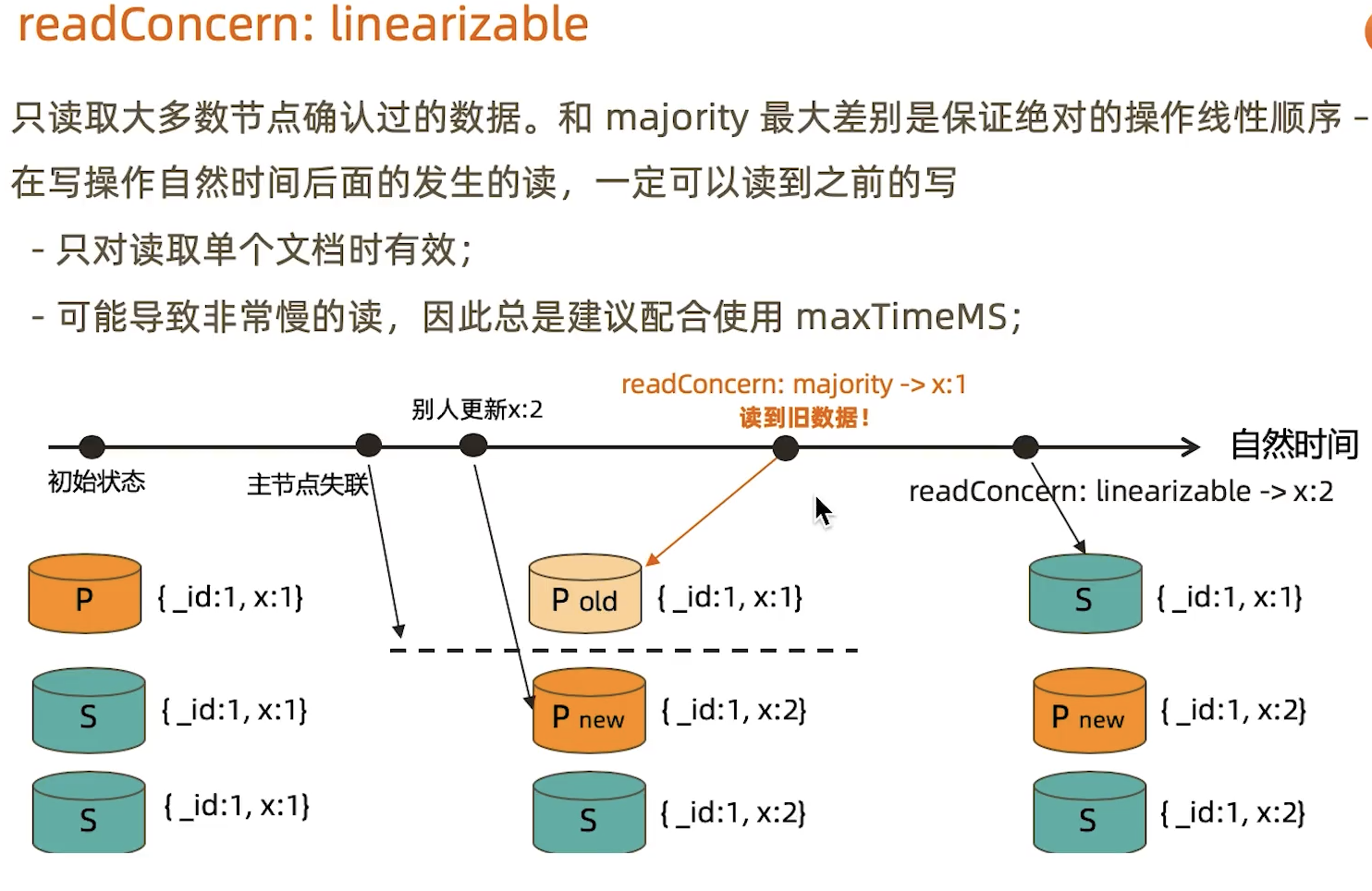
linearizable:可线性化读取文档(读保证可以读到之前的写)
snapshot:读取最近快照中的数据(等同于关系型的Serializable)
readConcern:local和available
在复制集中local和available是没有区别的。两者的区别主要体现在分片集上。
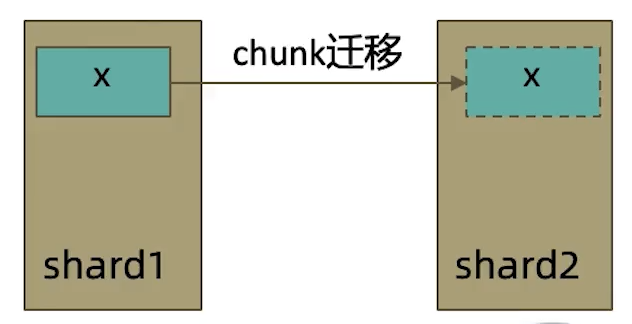
一个chunk x正在从shard1向shard2迁移;
整个迁移过程中chunk x中的部分数据会在shard1和shard2中同时存在,但源分片shard1仍然是chunk x的负责方
所有对chunk x的读写操作仍然进入shard1;
config中记录的信息chunk x仍然属于shard1
此时如果读shard2,则会体现出local和available的区别:
local:只取应该由shard2负责的数据(不包括x)
available:shard2上有什么就读什么(包括x)
注意事项:
- 虽然看上去总是应该选择local,但毕竟对结果集进行过滤会造成额外消耗,在一些无关紧要的场景(例如统计)下,也可以考虑available;
- mongodb<=3.6不支持对从节点使用{readConcern:"local"};
- 从节点读取数据时默认readConcern是local,从从节点读取数据时默认readConcern是available(向前兼容原因)
readConcern:majority
只读取大多数据节点上都提交了的数据。考虑如下场景:
集合中原有文档{x:0}
将x值更新为1
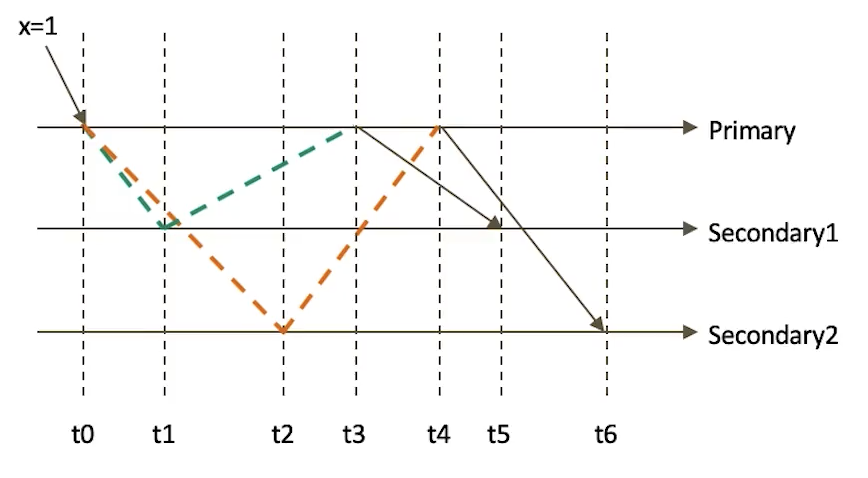
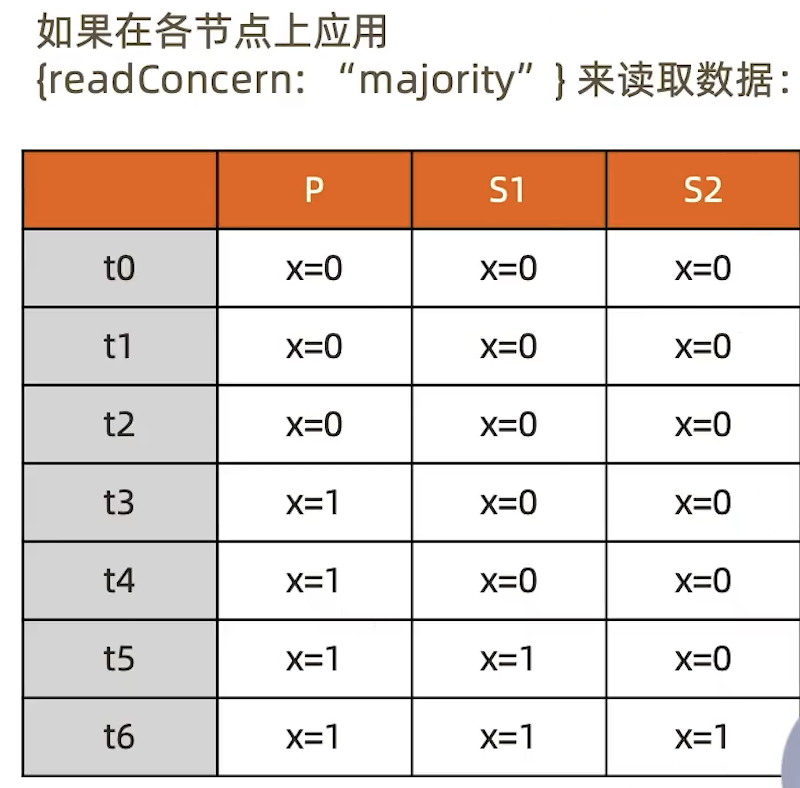
如果在各节点上应用{readConcern:"majority"}来读取数据
readConcern:majority的实现方式
考虑t3时刻的 Secondary1,此时:
对于要求majority的读操作,它将返回x=0
对于不要求majority的读操作,它将返回x=1
如何实现?
节点上维护多个x版本,mvcc机制
mongodb通过维护多个快照来链接不同的版本:
每个被大多数节点确认过的版本都将是一个快照;
快照持续到没有人使用为止才被删除
实验:readConcern:"majority" vs "local"
安装3节点复制集
设置配置文件内server参数enableMajorityReadConcern为true

将复制集中的两个从节点使用db.fsyncLock()锁住写入(模拟同步延迟)

readConcern:majority与脏读
MongoDB中的回滚:
写操作到达大多数节点之前都是不安全的,一旦主节点崩溃,而从节点还没有复制到该次操作,刚才的写操作就丢失了;
把一次写操作视为一个事务,从事务的角度,可以认为事务被回滚了。
所以从分布式系统的角度来看,事物的提交被提升到了分布式集群的多个节点级别的“提交”,而不再是单个节点上的“提交”。
在可能发生回滚的前提下考虑脏读的问题:
如果在一次写操作到达大多数节点前读取了这个写操作,然后因为系统故障该操作回滚了,则发生了脏读问题;
使用{readConcern:"majority"}可以有效避免脏读。
readConcern:如何实现安全的读写分离


readConcern:snapshot


 浙公网安备 33010602011771号
浙公网安备 33010602011771号