
MyCat入门
分布式系统
分布式系统是指其组件分布在网络上,组件之间通过传递消息进行通信和动作协调的系统。核心理 念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者大数据量的任 务。
分布式系统特点
透明性:分布式系统对于用户来说是透明的,一个分布式系统在用户面前的表现就像 一个传统的单处理机分时系统,可让用户不必了解其内部结构就能使用。
扩展性:分布式系统大的特点就是可扩展性,它能够根据需求的增加而扩展,可以 通过横向扩展使集群的整体性能得到线性提升,也可以通过纵向扩展单台服务器的性 能使服务器集群性能得到提升。
可靠性:分布式系统不允许单点失效的问题存在,它的基本思想是,如果一台机器坏 了,则其他的机器能够接替它进行工作,具有持续服务的特性。
高性能:采用服务器集群的方式能够保证系统的高性能。
分布式系统的缺点
在节点通信部分的开销大,线程安全问题也变得复杂,需要在保证数据完整性的同时 要兼顾性能。 过分依赖网络,网络信息的丢失或饱和将会抵消分布式系统的大部分优势。 有潜在的数据安全和网络安全等安全性问题。
CAP理论
CAP理论是指在分布式系统中不可能同时满足一致性 Consistency、可用性 Availability和分区容错 性 Partition Tolerance。
一致性(Consistency):系统在执行过某项操作后仍然处于一致的状态。在分布式 系统中,更新操作执行成功后所有的用户都应该读取到新的值。
可用性(Availability):每一个操作总是能够在一定的时间内返回结果。
分区容错性(Partition Tolerance):分区容错性是在网络故障、某些节点不能通信 的时候系统仍能继续工作。
数据一致性
强一致性:当更新操作完成之后,任何多个后续进程或者线程的访问都会返回新的 更新过的值。这种是对用户友好的,就是用户上一次写什么,下一次就保证能读到 什么。根据 CAP 理论,这种实现需要牺牲可用性。 弱一致性:系统并不保证后续进程或者线程的访问都会返回新的更新过的值。系统 在数据写入成功之后,不承诺立即可以读到新写入的值,也不会具体的承诺多久之 后可以读到。 最终一致性:弱一致性的特定形式。系统保证在没有后续更新的前提下,系统终返 回上一次更新操作的值。在没有故障发生的前提下,不一致窗口的时间主要受通信延 迟,系统负载和复制副本的个数影响。DNS 是一个典型的终一致性系统。
在绝大多数的场景,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证终一致 性。
分布式数据库
分布式数据库是指数据在物理上分布而在逻辑上集中管理的数据库系统。物理上分布式指分布式数 据库的数据分布在物理位置不同并由网络连接的节点或站点上;逻辑上集中是指各个数据库节点之 间在逻辑上是一个整体,并由统一的数据库管理系统管理。不同的节点分布可以跨不同的机房、城 市甚至国家。
数据分片
数据分片是指将数据全局的划分为相关的逻辑片段,有水平切分,垂直切分,混合切分三种类型。
水平切分:按照某个字段的某种规则将数据分散到多个节点库中,每个节点包含一部 分数据。可以将数据的水平切分简单的理解为按照数据进行切分,就是将表中的某些 数据分到一个节点,将另外的某些切分都另外的节点,从分布式的整体来看它们就是 一个整体的表。
垂直切分:垂直切分就是按照业务将表进行分类并分布到不同的节点上。
混合切分:水平切分与混合切分的结合。
分布式查询处理
分布式查询处理的任务就是把一个分布式数据库上的高层次的查询映射为在本地数据库上操作,将 要查询的数据定位到各个节点上,使得查询在各节点进行,后通过网络通信的操作汇聚查询结 果。
分布式事务
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的 分布式系统的不同节点之上。详细内容可参照分布式事务章节
Mycat数据库中间件
Mycat是一个开源的面向企业应用的开发的大数据库集群,支持事务,ACID,是可以替代Mysql的 加强版数据库。应用与Mycat以及Mysql关系图如下:
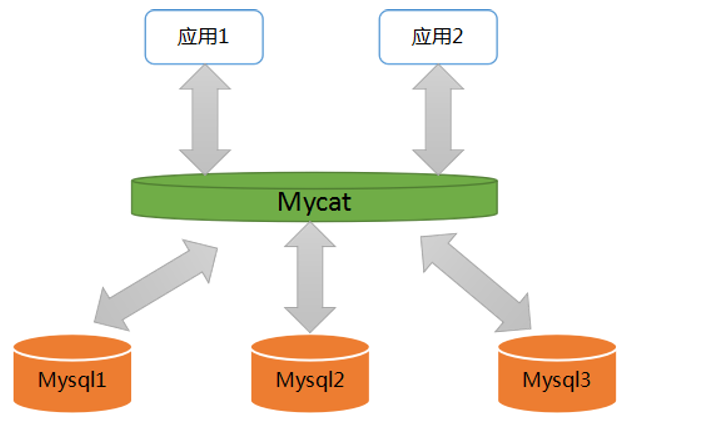
Mycat核心概念
逻辑库
开发人员通常在实际应用中并不需要知道中间件的存在,只需要关注数据库,所以数据库中间件可 以被当做一个或多个数据库集群构成的逻辑库。
逻辑表
在分布式数据库中,对于应用来说,读写数据的表就是逻辑表。逻辑表可以分部在一个或多个分片 节点上,也可以不分片。
分片表:分片表是将数据量很大的表切分到多个数据库实例中,所有分片组合起来构 成一张完成的表。例如我们的运单表。 非分片表:并非所有的表都需要进行分片,某些表可以不用分片。非分片表是相对于 分片表而言的不需要数据切分的表。 全局表:当业务表进行分片后,业务表与其他的基础表之间的关联查询就成了棘手的 问题,所以在Mycat中通过数据冗余来解决这类表的关联查询,即所有分片节点上都 复制了一份数据,这些冗余数据的表定义为全局表。例如我们的数据字典表,用户表 等。 ER表:ER表是基于E-R关系的数据分片策略,即子表的记录与其所关联的主表的记 录放在同一个数据分片上,即子表依赖于主表,通过表分组保证数据关联查询不会跨 库操作。例如我们的交接单表与交接单明细表。
分片节点
将数据切分后,一个大表被分到不同的分片数据库上,每个表分片所在的数据库就是分片节点。
节点主机
将数据切分后,每个分片节点不一定会独占一台机器,同一台机器上可以有多个分片数据库,这样 一个或者多个分片节点所在的机器就是节点主机。
Mycat原理
Mycat核心配置文件
Mycat三大核心配置文件:
server.xml:服务器参数调整和用户授权的配置文件。
schema.xml:逻辑库定义和表以及分片定义的配置文件。
rule.xml:是分片规则的配置文件。
Mycat分片规则
Mycat有多种分片规则,以下为部分常用分片规则:
取模分片:按照分片字段取模分片。
枚举分片:按照分片字段枚举值分布到不同的节点上。
范围分片:按照分片字段的范围进行分片。
一致性hash分片:按照分片字段做一致性hash分片。
分布式事务
随着并发量、数据量越来越大以及业务已经细化到不能再按照业务划分,我们不得不使用分布式数 据库提高系统的性能,在分布式系统中,各个节点在物理上都是相对独立的,每个节点上的数据操 作都可以满足ACID。但是,各个节点之间无法知道其他节点事务的执行情况,如果想让多台机器中 的数据保存一致,就必须保证所有的节点上的数据操作要么全部执行成功,要么全部不执行,比较 常规的解决方法就是引入“协调者”来统一调度所有节点的执行。
XA规范
X/Open组织(即现在的Open Group)定义了分布式事务处理模型。X/Open DTP模型包括应用程 序(AP)、事务管理器(TM)、资源管理器(RM)。通常把一个数据库内部的事务处理看做本地 事务,而分布式事务处理的对象是全局事务。全局事务是指在分布式事务处理环节中,多个数据库 可能需要共同完成一个工作,这个工作就是一个全局事务。在一个事务中可能更新几个不同的数据 库,此时一个数据库对自己内部所做的操作的提交不仅需要本身的操作成功,还需要全局事务相关 的其他数据库操作成功。如果任一数据库的任一操作失败,则参与此事务的所有数据库所做的所有 操作必须回滚。XA就是X/Open DTP定义的事务管理器与资源管理器之间的接口规范(即接口函 数),事务管理器用它来通知数据库事务的开始、结束、提交、回滚等。

二阶段提交
所谓的两个阶段是指准备阶段和提交阶段。
第一阶段:准备阶段
事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失 败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交,到达一种“万事 俱备,只欠东风”的状态。
可以进一步将准备阶段分为以下三个步骤:
1)协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响 应。
2)参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。(注意: 若成功这里其实每个参与者已经执行了事务操作)
3)各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返 回一个”同意”消息;如果参与者节点的事务操作实际执行失败,则它返回一个”中止”消息。
第二阶段:提交阶段
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否 则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理 过程中使用的锁资源。

