
K8s 集群内TCP建连失败分析
一、背景
收到反馈部分请求在nodejs达到30多秒
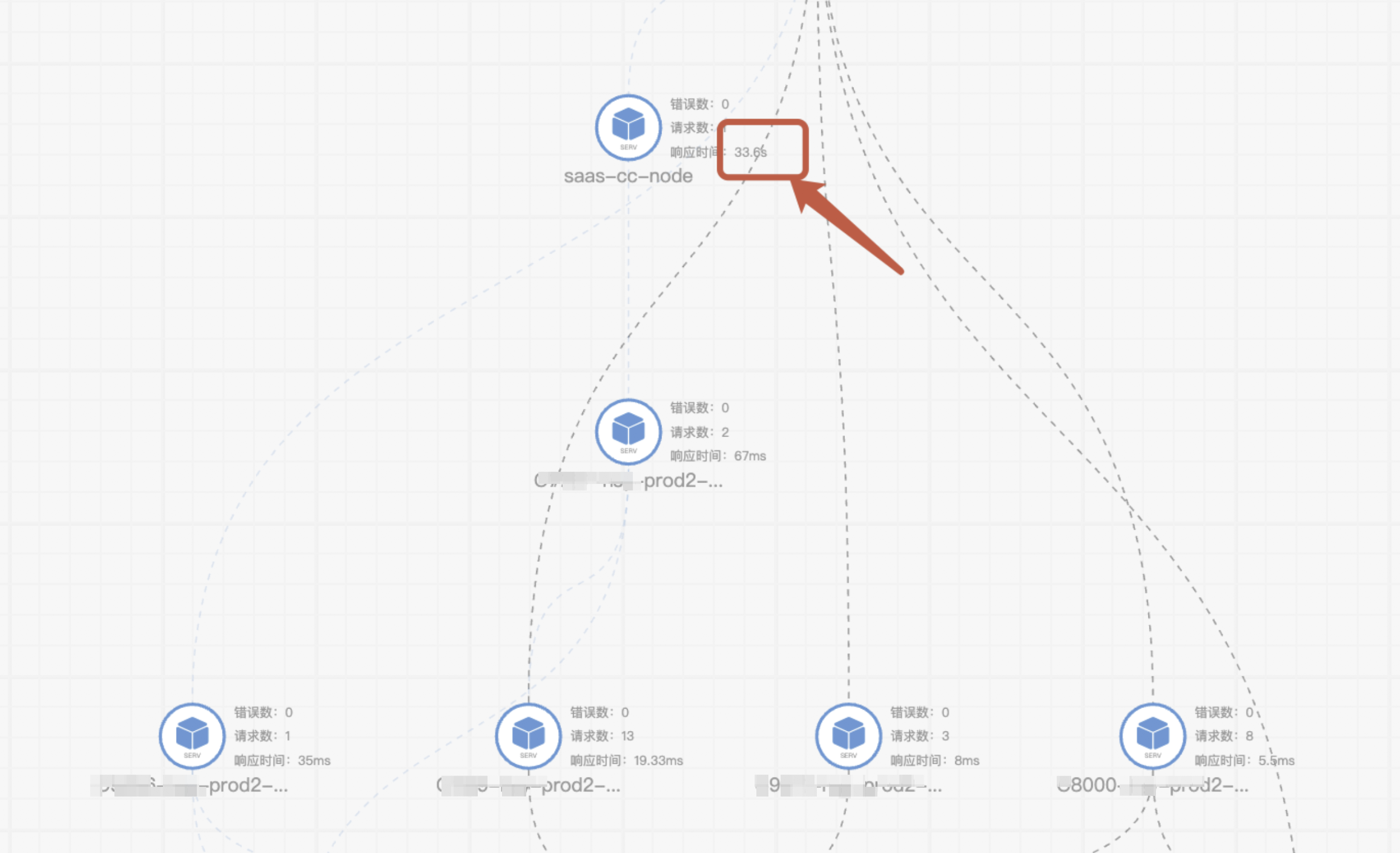
二、排查过程
请求链路如下:
slb--nginx--nodejs--slb--ingress–微服务
1、超时时间排查
从上方链路中发现,后端服务处理都很快,第一反应是哪里有超时了,超时时间配置的30s,于是开始在链路点上排查
slb超时时间320s
ingress超时时间300s
微服务tomcat超时时间20s
从以上超时时间发现slb和ingress都在300s以上,除了tomcat在20s,也不符合30s的超时时间
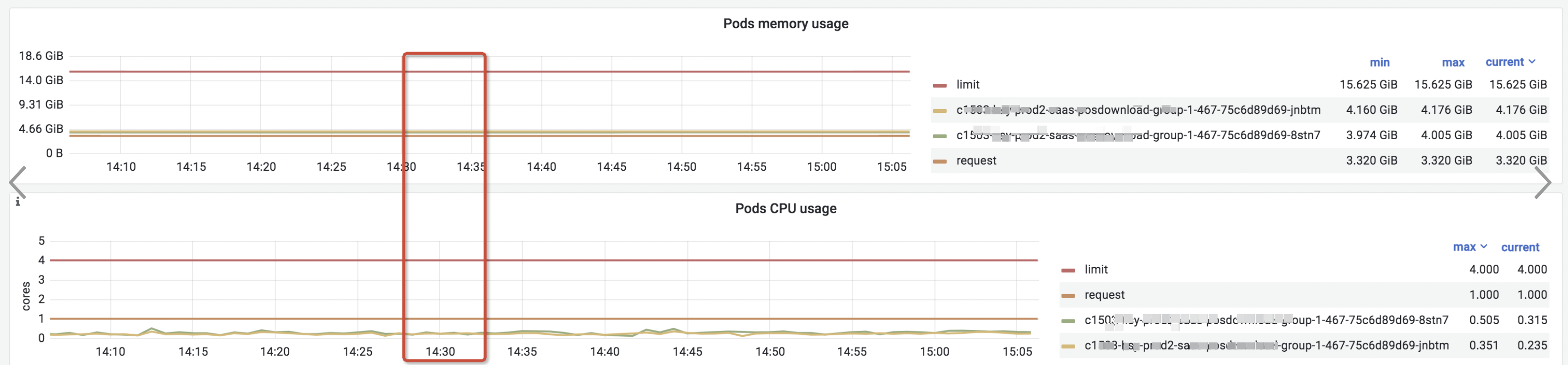
2、资源层面排查
1、微服务资源排查无异常
2、jvm无异常
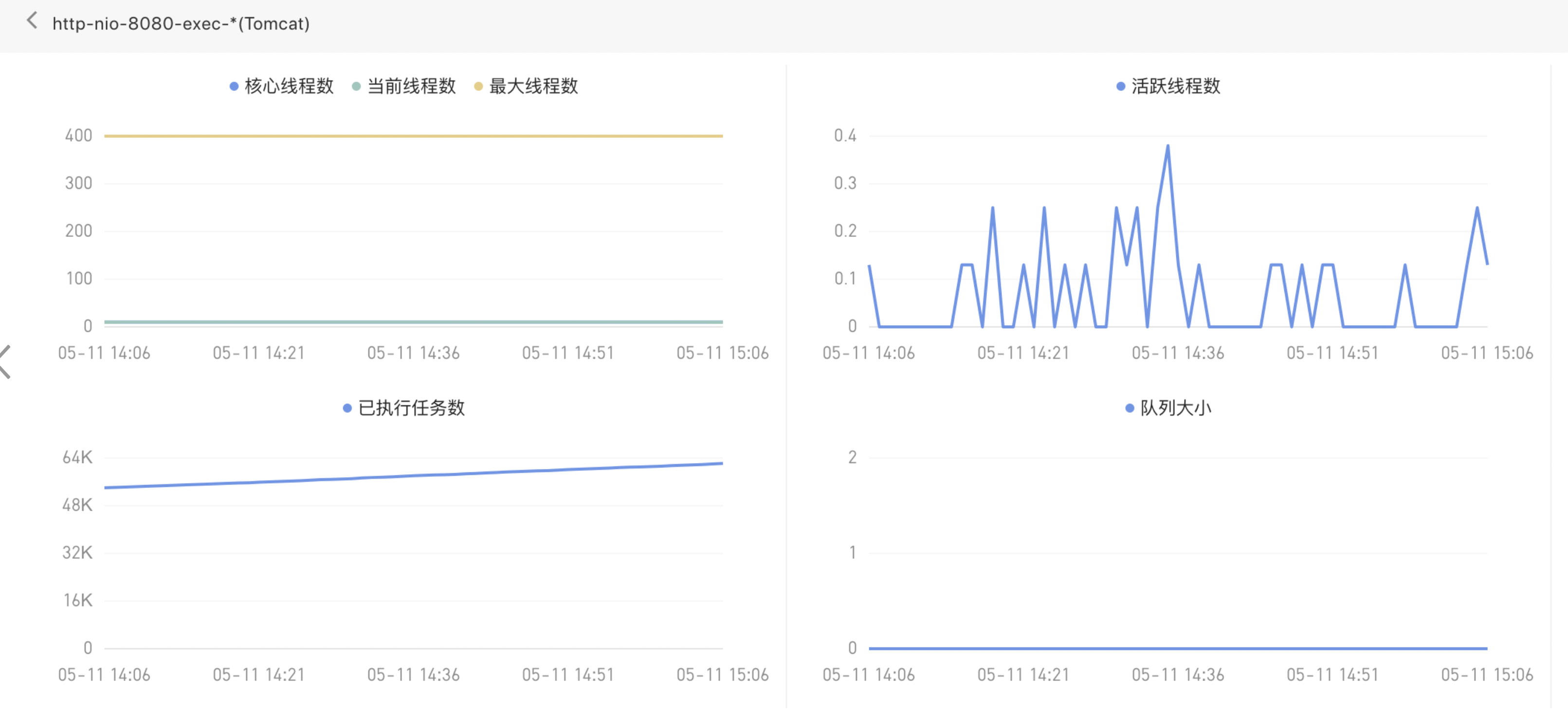
3、tomcat无异常---最大线程400
4、ingreess资源无异常
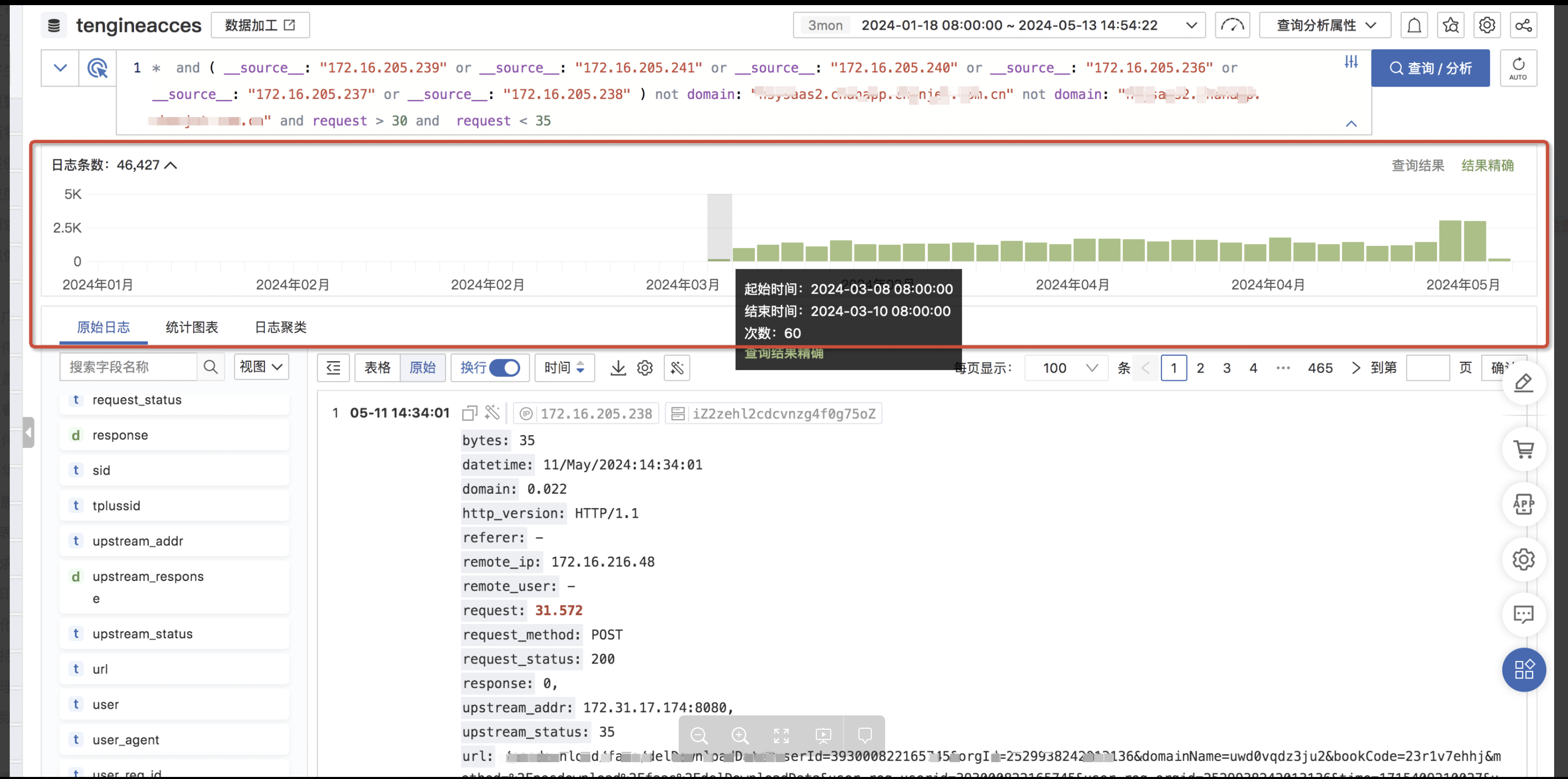
3、日志排查
查看ingress日志发现:
1、有请求时间30s的日志
2、日志收集格式错乱,无法正常按索引展示
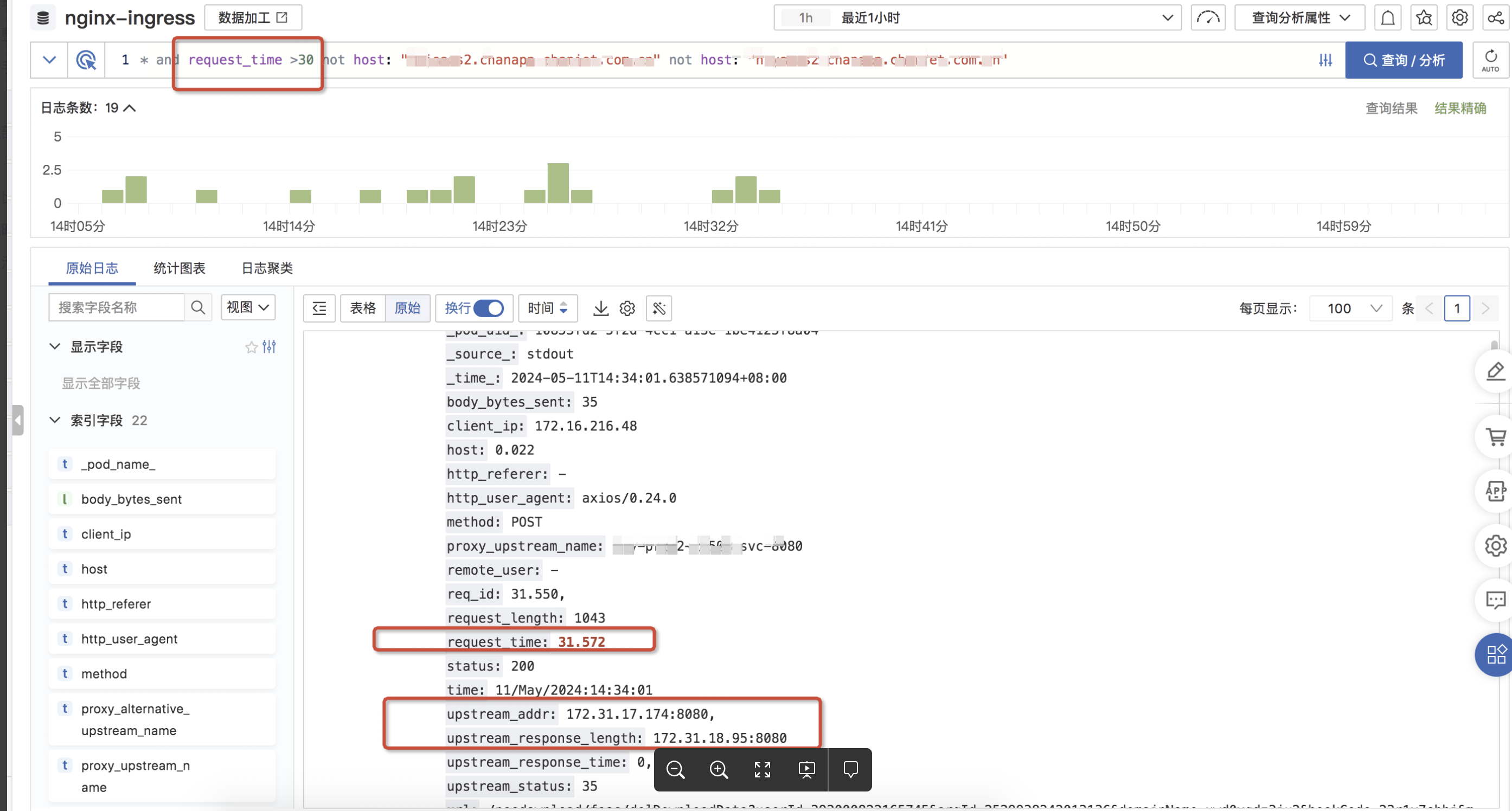
3、通过回溯ingress pod历史日志发现:
a. ingress连接后端upstream超时并且耗时31.7s后返回502
b. 第一次超时502后将请求转到下一个pod耗时0.0.1s成功返回200

可以看出原始ingress请求日志中将请求转发了两次,所以按之前的日志切割索引会错乱
但是出现两个新的问题
a、为什么会502
b、502为什么需要30s
4、深入排查
根据以上结论接着往下排查
a.后端排查
出现502肯定是后端出问题了无法响应了
排查后端日志发现ingress中的请求并没有打到后端服务上,链路追踪也查不到,业务日志也没有报错
30s的超时在链路点上都没有配置,而且也不可能出现后端服务 30s还没响应的情况
b.ingress排查
查看ingress所在宿主机系统日志,怀疑是不是系统存在瓶颈,可以看到系统内核有如下日志,经过排查这个日志和本次问题不匹配
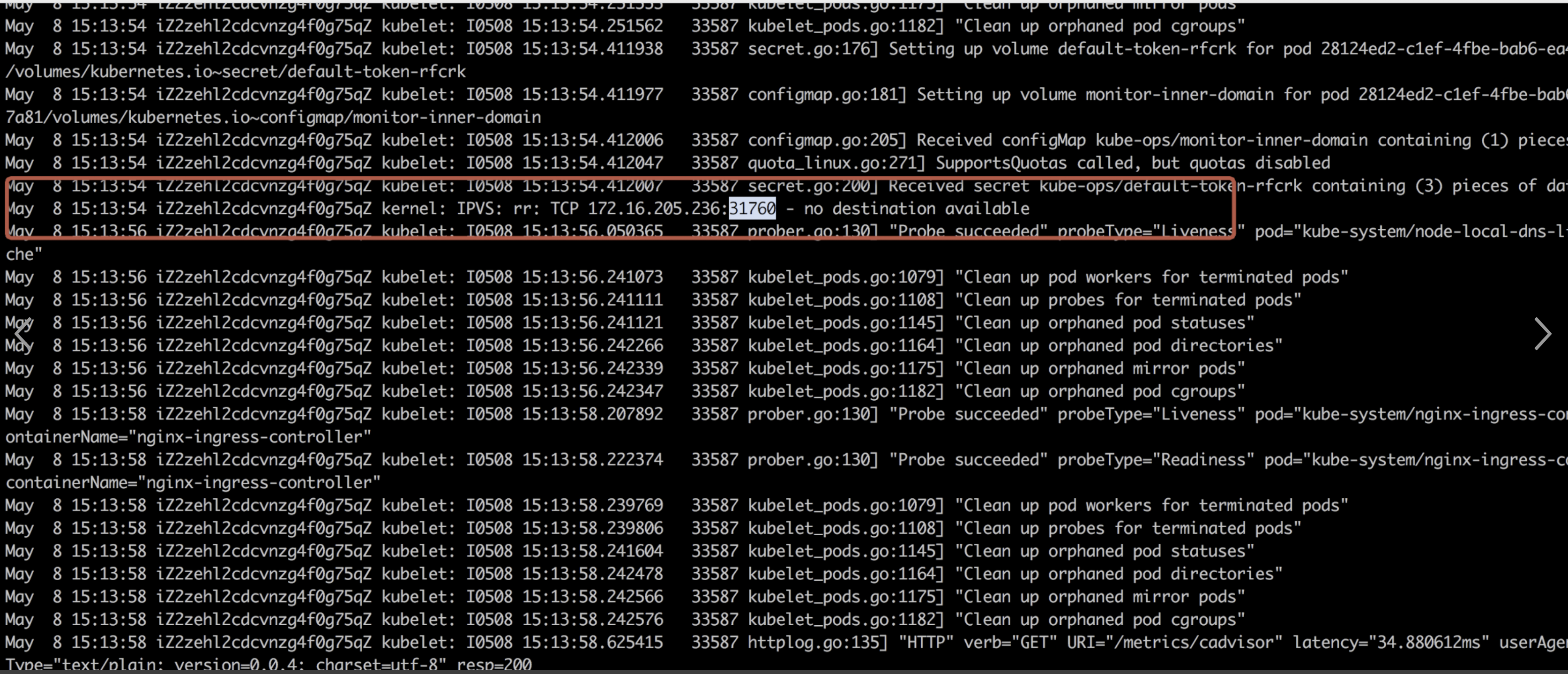
查看ingress资源也无异常
c. Tcp抓包分析
抓包本来想在线下环境抓包,但是压测发现,压测环境无法复现这个场景,别的集群也没有这种场景存在,那就只能在线上进行抓包分析了
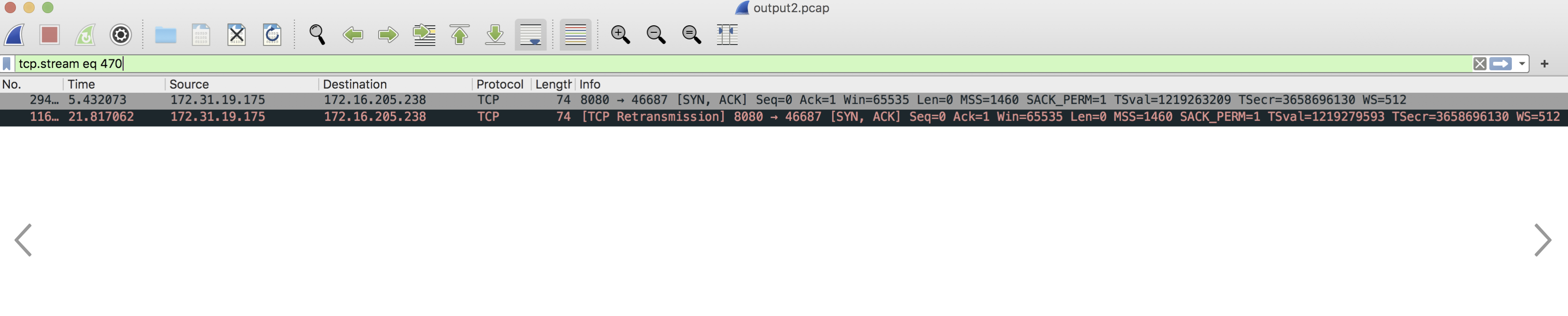
通过抓包分析可以看到,tcp三次握手过程中,在第二次握手中pod向ingress节点发送了SYN/ACK包后并未收到确认包,所以进行了tcp重传,重传的原因是第三次握手客户端(ingress)并没有向服务端(pod)发送ACK确认包,最终tcp建连未成功,通过抓包看两次重传间隔了16s。
通过以上分析可以判断是ingress的问题,ingress为什么没发送ACK包呢?
是不是和ingress流量大导致建连失败呢?查看了ingress节点的宿主机指标一切正常
接着往下分析发现全天任何时候都有这种情况 发生,凌晨是请求量特别低,那就和一切的并发类的没有关系了,那就只能是ingress 所在的节点在tcp建连或者网络存在丢包的情况
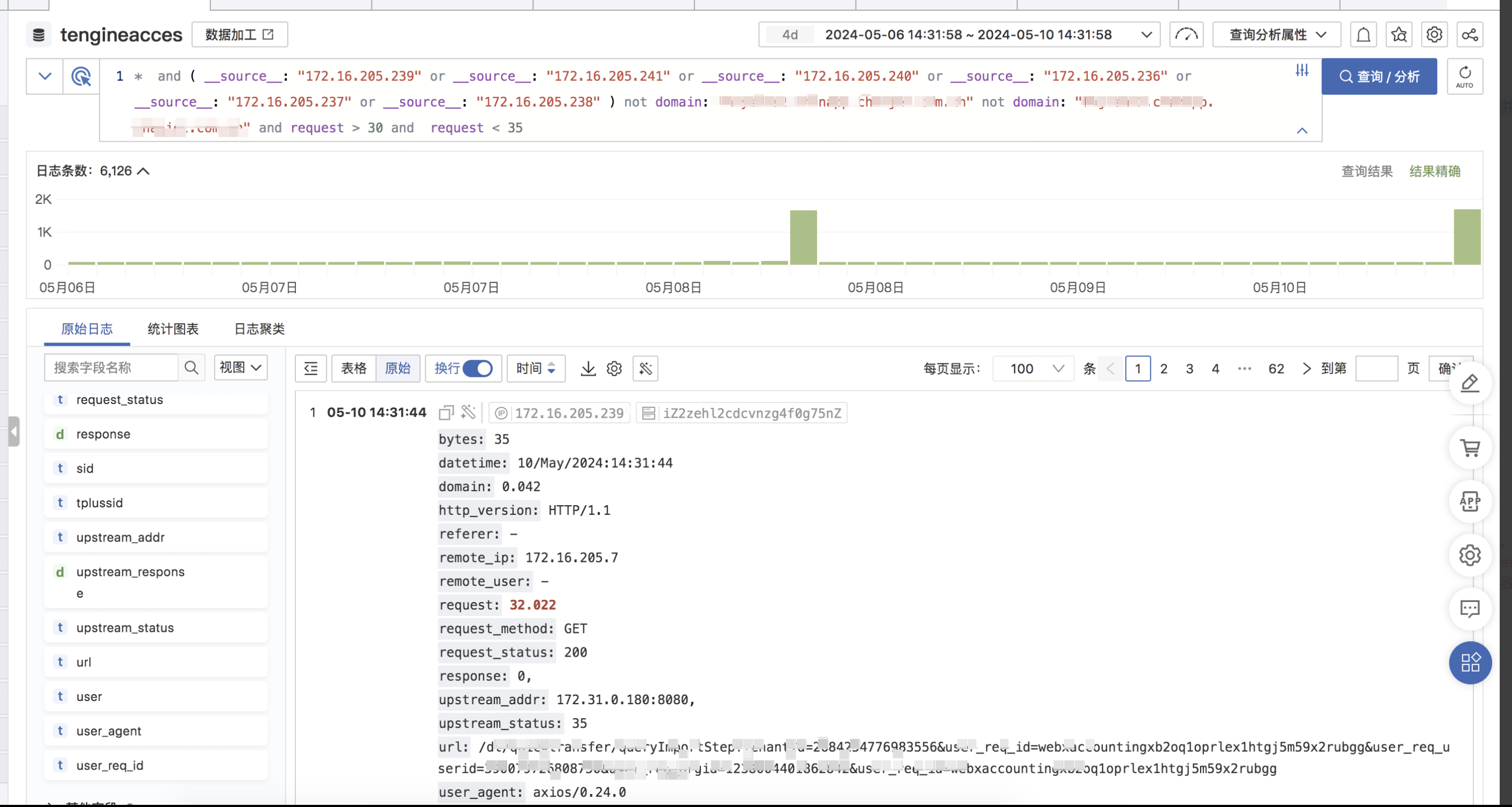
网络丢包: 查看ingress和业务在同一个可用区 ,那也和丢包没有关系了
那就只能是tcp socket建立的问题了,查看系统内核参数发现net.ipv4.ip_local_port_range配置为1024-65535 ,k8s中NodePort或LoadBalancer类型的Service在节点上所监听的NodePort端口范围,该参数默认值为30000~32767,系统所用的端口和k8s所用的端口存在冲突,在k8s官网可以看到: Kubernetes 1.24及以后的版本,去除了kube-proxy监听NodePort的逻辑,在NodePort与内核net.ipv4.ip_local_port_range范围有冲突的情况下,可能会导致偶发的TCP无法连接的情况,导致健康检查失败、业务异常等问题
恰好集群是从3月10号升级到1.24版本,拉取所有日志发现确实是从3月10号才开始有32s的超时,问题实锤
5、其余疑问
a.阿里云系统默认net.ipv4.ip_local_port_range = 32768 60999,为什么会被修改为1024-65535?下图是ingress yaml文件,可以看到在启动 的时候会将参数修改
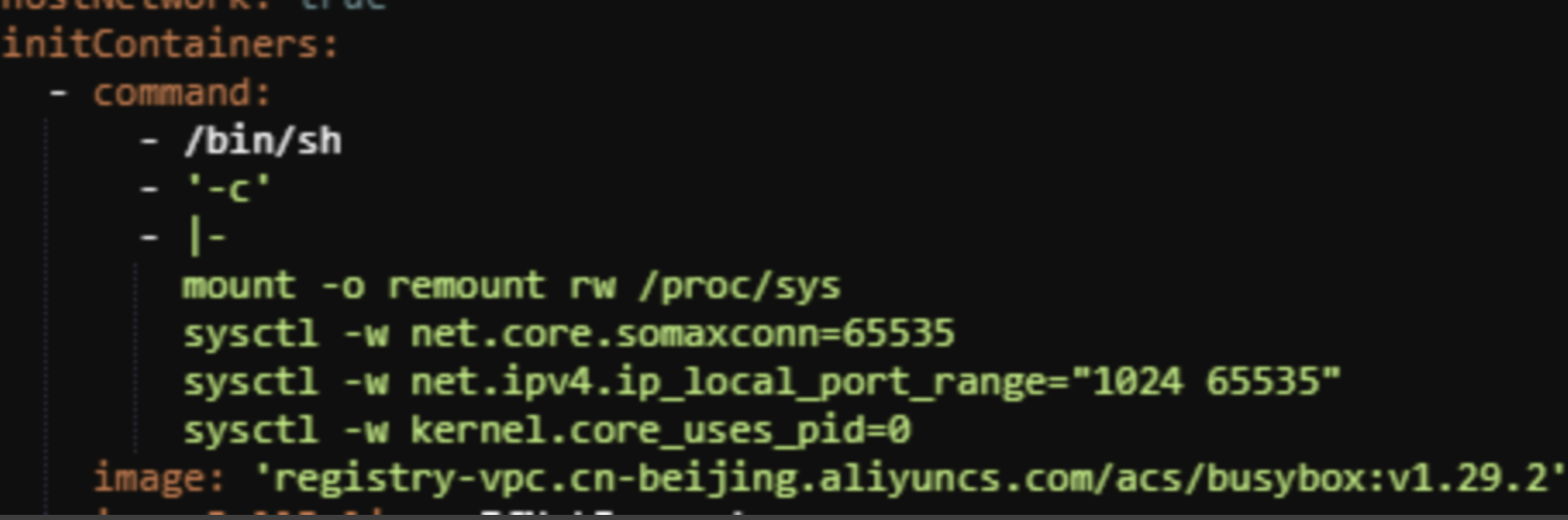
新版本的 ingress已经加上了判断条件,如果是hostnetwork网络的nginx -ingress则不会修改 local port参数,可能会有人有别的疑问:那非hostnetwork模式下,不是也会修改吗?在非hostnetwork模式下,该参数只会影响 nginx-ingress自己的网络命名空间,不会影响os的命名空间
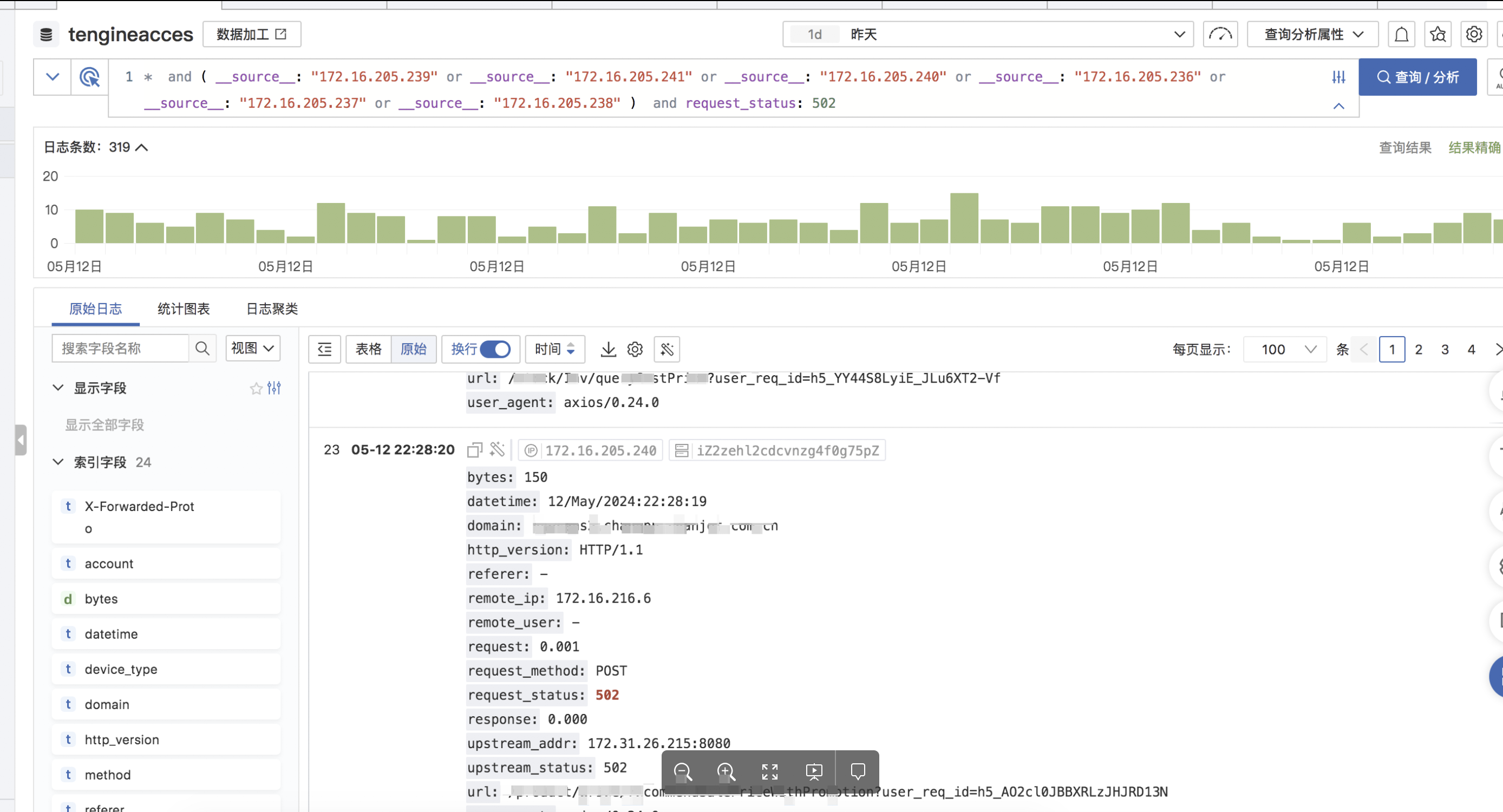
b. 抓取ingress原始日志还发现有502报错recv() failed (104: Connection reset by peer) while reading response header from upstream

对应 ingress 日志也可以看到每天有持续的502报错
可以在官方文档上看到:调整端口范围后,集群中可能存在部分NodePort或LoadBalancer类型的Service仍在使用ip_local_port_range参数端口范围内的端口作为NodePort。此时需要对这部分Service进行重新配置以避免冲突

这个需要将ingress版本升级到新版后在观察
6、后续
a. ingress日志收集问题-------错误日志收集和日志切割适配
b. 内核参数异常扫描,确保内核参数配置正确
c. Tomcat并发数是否达到限制,需要补全监控能力,目前配置为最大线程数400,队列大小100,超时时间20s
d. 内核参数tcp_tw_reuse 配置为2,2的含义如下,配置2可能会有多个进程共享TIME-WAIT套接字导致网络通信异常,如连接重置、数据包丢失等问题,影响通信质量,在多进程环境中,如果多个进程共享TIME-WAIT套接字,可能会导致连接混乱和不确定性,影响系统稳定性

e. 系统内核 Tcp 连接中半队列和全队列是否达到限制,需要监控
f.抓取ingress日志发现 项目集群 有如下报错 upstream prematurely closed connection while reading response header from upstream ,含义是读取来自上游服务器(如后端应用程序服务器)的响应标头时,发现连接被提前关闭。可能是ingress与pod间的连接为短链接。上游服务器处理完请求后会主动关闭连接,但因为ingress upstream设置了keepalive,nginx在收到reponse后仍然会尝试复用此连接,而此时连接已被上游服务器关闭,导致请求失败,需关闭keepalive,待验证
g. 部分后端错误日志中存在java.lang.NullPointerException: null 空指针的报错
h. ingress内默认GET请求 如果在当前upstream中请求失败会将请求转发到下一个节点,POST请求也存在转发的情况
i. 在tcp三次握手过程中 ,对握手失败的重传超时时间需要做限制,第二次握手中tcp_synack_retries配置为2,第一次握手tcp_syn_retries配置为6,如果网络存在问题,tcp建连重试6次,间隔时间为1/2/4/8/16/32 ,共需要127s,可以优化为2



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!