
k8s监控终极解决方案(kube-prometheus安装及配置-包含定制化配置)
>>> 目录 <<<
一、概述
二、结构分析
三、Prometheus配置文件修改
四、添加外部监控
五、Scheduler和Controller配置
六、Alertmanager配置
七、监控数据持久化
八、Grafana仪表板配置
九、汇总
十、定制化配置
一、概述
首先Prometheus整体监控结构略微复杂,一个个部署并不简单。另外监控Kubernetes就需要访问内部数据,必定需要进行认证、鉴权、准入控制,
那么这一整套下来将变得难上加难,而且还需要花费一定的时间,如果你没有特别高的要求,还是建议选用开源比较好的一些方案。
在k8s初期使用Heapster+cAdvisor方式监控,这是Prometheus Operator出现之前的k8s监控方案。后来出现了Prometheus Operator,但是目前Prometheus Operator已经不包含完整功能,完整的解决方案已经变为kube-prometheus。项目地址为:https://github.com/coreos/kube-prometheus关于这个kube-prometheus目前应该是开源最好的方案了,该存储库收集Kubernetes清单,Grafana仪表板和Prometheus规则,以及文档和脚本,以使用Prometheus Operator 通过Prometheus提供易于操作的端到端Kubernetes集群监视。以容器的方式部署到k8s集群,而且还可以自定义配置,非常的方便。
![]()
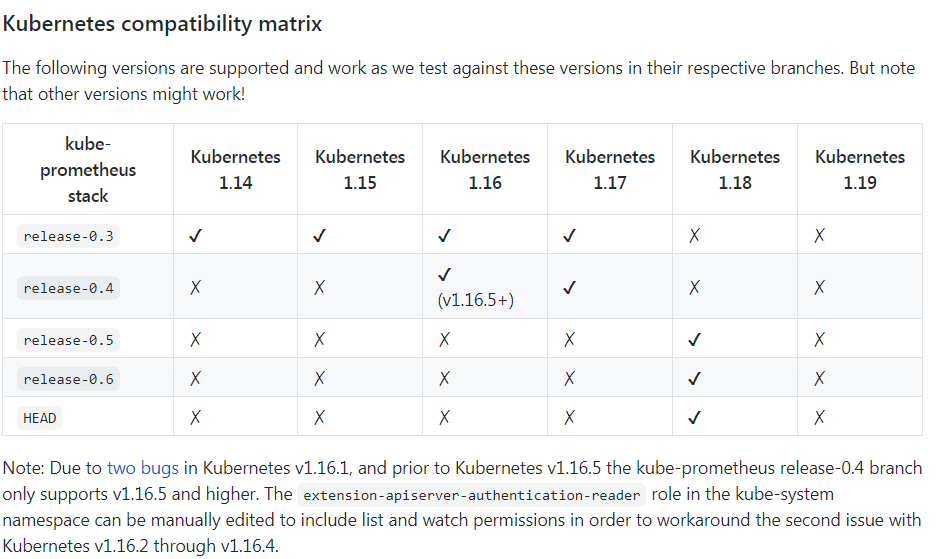
上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的prometheus这种资源对象就是作为Prometheus Server存在,而ServiceMonitor就是exporter的各种抽象,是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
下面是组件的具体介绍:
- Operator: Operator 资源会根据自定义资源(Custom Resource Definition / CRDs)来部署和管理 Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
- Prometheus: Prometheus 资源是声明性地描述 Prometheus 部署的期望状态。
- Prometheus Server: Operator 根据自定义资源 Prometheus 类型中定义的内容而部署的 Prometheus Server 集群,这些自定义资源可以看作是用来管理 Prometheus Server 集群的 StatefulSets 资源。
- ServiceMonitor: ServiceMonitor 也是一个自定义资源,它描述了一组被 Prometheus 监控的 targets 列表。该资源通过 Labels 来选取对应的 Service Endpoint,让 Prometheus Server 通过选取的 Service 来获取 Metrics 信息。
- Service: Service 资源主要用来对应 Kubernetes 集群中的 Metrics Server Pod,来提供给 ServiceMonitor 选取让 Prometheus Server 来获取信息。简单的说就是 Prometheus 监控的对象,例如 Node Exporter Service、Mysql Exporter Service 等等。
- Alertmanager: Alertmanager 也是一个自定义资源类型,由 Operator 根据资源描述内容来部署 Alertmanager 集群。
kube-prometheus包含的组件:
- Prometheus Operator
- 高可用的 Prometheus 默认会部署2个pod
- 高可用的 Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
二、结构分析
kube-prometheus相关部署文件在manifests目录中,共65个yaml,其中setup文件夹中包含所有自定义资源配置CustomResourceDefinition(一般不用修改,也不要轻易修改),所以部署时必须先执行这个文件夹。
其中包括告警(Alertmanager)、监控(Prometheus)、监控项(PrometheusRule)这三类资源定义,所以如果你想直接在k8s中修改对应控制器配置是没有用的(比如kubectl edit sts prometheus-k8s -n monitoring) 。
这里yaml文件看着很多,只要我们梳理一下就会很容易理解了,首先分为7个组件prometheus-operator、prometheus-adapter、prometheus、alertmanager、grafana、kube-state-metrics、node-exporter,
然后每个组件都会定义控制器、配置文件、集群权限、访问配置、监控配置, 但是我们一般只需要进行自定义告警配置和监控项,这样一筛选发现只需要修改几个文件即可。
[root@ymt108 manifests]# tree
.
├── alertmanager-alertmanager.yaml
├── alertmanager-secret.yaml # 告警配置
├── alertmanager-serviceAccount.yaml
├── alertmanager-serviceMonitor.yaml
├── alertmanager-service.yaml
├── grafana-dashboardDatasources.yaml
├── grafana-dashboardDefinitions.yaml
├── grafana-dashboardSources.yaml
├── grafana-deployment.yaml
├── grafana-serviceAccount.yaml
├── grafana-serviceMonitor.yaml
├── grafana-service.yaml
├── kube-state-metrics-clusterRoleBinding.yaml
├── kube-state-metrics-clusterRole.yaml
├── kube-state-metrics-deployment.yaml
├── kube-state-metrics-roleBinding.yaml
├── kube-state-metrics-role.yaml
├── kube-state-metrics-serviceAccount.yaml
├── kube-state-metrics-serviceMonitor.yaml
├── kube-state-metrics-service.yaml
├── node-exporter-clusterRoleBinding.yaml
├── node-exporter-clusterRole.yaml
├── node-exporter-daemonset.yaml
├── node-exporter-serviceAccount.yaml
├── node-exporter-serviceMonitor.yaml
├── node-exporter-service.yaml
├── prometheus-adapter-apiService.yaml
├── prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml
├── prometheus-adapter-clusterRoleBindingDelegator.yaml
├── prometheus-adapter-clusterRoleBinding.yaml
├── prometheus-adapter-clusterRoleServerResources.yaml
├── prometheus-adapter-clusterRole.yaml
├── prometheus-adapter-configMap.yaml
├── prometheus-adapter-deployment.yaml
├── prometheus-adapter-roleBindingAuthReader.yaml
├── prometheus-adapter-serviceAccount.yaml
├── prometheus-adapter-service.yaml
├── prometheus-clusterRoleBinding.yaml
├── prometheus-clusterRole.yaml
├── prometheus-operator-serviceMonitor.yaml
├── prometheus-prometheus.yaml # 监控配置
├── prometheus-roleBindingConfig.yaml
├── prometheus-roleBindingSpecificNamespaces.yaml
├── prometheus-roleConfig.yaml
├── prometheus-roleSpecificNamespaces.yaml
├── prometheus-rules.yaml # 默认监控项
├── prometheus-serviceAccount.yaml
├── prometheus-serviceMonitorApiserver.yaml
├── prometheus-serviceMonitorCoreDNS.yaml
├── prometheus-serviceMonitorKubeControllerManager.yaml
├── prometheus-serviceMonitorKubelet.yaml
├── prometheus-serviceMonitorKubeScheduler.yaml
├── prometheus-serviceMonitor.yaml
├── prometheus-service.yaml
└── setup
├── 0namespace-namespace.yaml
├── prometheus-operator-0alertmanagerCustomResourceDefinition.yaml
├── prometheus-operator-0podmonitorCustomResourceDefinition.yaml
├── prometheus-operator-0prometheusCustomResourceDefinition.yaml
├── prometheus-operator-0prometheusruleCustomResourceDefinition.yaml
├── prometheus-operator-0servicemonitorCustomResourceDefinition.yaml
├── prometheus-operator-clusterRoleBinding.yaml
├── prometheus-operator-clusterRole.yaml
├── prometheus-operator-deployment.yaml
├── prometheus-operator-serviceAccount.yaml
└── prometheus-operator-service.yaml
1 directories, 65 files
三、Prometheus配置文件修改
为了保留原始文件,建议先备份一份kube-prometheus原文件。
1、修改prometheus-prometheus.yaml,以下为修改后并经生产环境验证过后的配置文件,根据自己的k8s集群环境进行修改
1)replicas:根据项目情况调整副本数
2)retention:修改Prometheus数据保留期限,默认值为“24h”,并且必须与正则表达式“ [0-9] +(ms | s | m | h | d | w | y)”匹配。
3)additionalScrapeConfigs:增加额外监控项配置,具体配置查看第五部分“添加k8s外部监控”。
4)storage:volumeClaimTemplate: prometheus数据持久化配置,避免prometheus重启造成数据丢失,此处使用阿里云Nas创建的 StorageClass,创建StorageClass相关文章https://www.cnblogs.com/lidong94/p/14518362.html
5)nodeSelector && tolerations :节点选择器和污点,因为prometheus查询数据量大会导致k8s节点内存升高,如果所在节点上部署着线上服务会受到影响,故独立将prometheus放在特定的节点中(如果不需要可以删除)
apiVersion: monitoring.coreos.com/v1 kind: Prometheus metadata: labels: prometheus: k8s name: k8s namespace: monitoring spec: alerting: alertmanagers: - name: alertmanager-main namespace: monitoring port: web image: quay.io/prometheus/prometheus:v2.20.0 additionalScrapeConfigs: name: additional-scrape-configs key: prometheus-additional.yaml retention: 30d #修改Prometheus数据保留期限,默认值为24h,此处为保留30d, storage: volumeClaimTemplate: spec: storageClassName: alicloud-nas resources: requests: storage: 100Gi nodeSelector: zone: problem tolerations: - effect: NoSchedule key: forever operator: Equal value: problem podMonitorNamespaceSelector: {} podMonitorSelector: {} replicas: 1 #根据项目情况调整副本数,默认是2个 resources: requests: memory: 400Mi ruleSelector: matchLabels: prometheus: k8s role: alert-rules securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 serviceAccountName: prometheus-k8s serviceMonitorNamespaceSelector: {} serviceMonitorSelector: {} version: v2.20.0
2、PrometheusRule配置文件修改
首先查看默认监控项配置prometheus-rules.yaml,其中包括76个告警项,基本覆盖了k8s常用监控点。
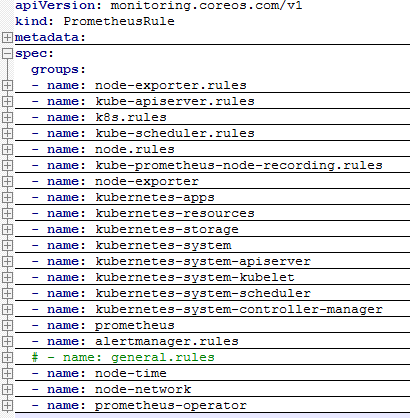


apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: prometheus: k8s role: alert-rules name: prometheus-k8s-rules namespace: monitoring spec: groups: - name: node-exporter.rules rules: - expr: | count without (cpu) ( count without (mode) ( node_cpu_seconds_total{job="node-exporter"} ) ) record: instance:node_num_cpu:sum - expr: | 1 - avg without (cpu, mode) ( rate(node_cpu_seconds_total{job="node-exporter", mode="idle"}[1m]) ) record: instance:node_cpu_utilisation:rate1m - expr: | ( node_load1{job="node-exporter"} / instance:node_num_cpu:sum{job="node-exporter"} ) record: instance:node_load1_per_cpu:ratio - expr: | 1 - ( node_memory_MemAvailable_bytes{job="node-exporter"} / node_memory_MemTotal_bytes{job="node-exporter"} ) record: instance:node_memory_utilisation:ratio - expr: | rate(node_vmstat_pgmajfault{job="node-exporter"}[1m]) record: instance:node_vmstat_pgmajfault:rate1m - expr: | rate(node_disk_io_time_seconds_total{job="node-exporter", device=~"mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|dasd.+"}[1m]) record: instance_device:node_disk_io_time_seconds:rate1m - expr: | rate(node_disk_io_time_weighted_seconds_total{job="node-exporter", device=~"mmcblk.p.+|nvme.+|rbd.+|sd.+|vd.+|xvd.+|dm-.+|dasd.+"}[1m]) record: instance_device:node_disk_io_time_weighted_seconds:rate1m - expr: | sum without (device) ( rate(node_network_receive_bytes_total{job="node-exporter", device!="lo"}[1m]) ) record: instance:node_network_receive_bytes_excluding_lo:rate1m - expr: | sum without (device) ( rate(node_network_transmit_bytes_total{job="node-exporter", device!="lo"}[1m]) ) record: instance:node_network_transmit_bytes_excluding_lo:rate1m - expr: | sum without (device) ( rate(node_network_receive_drop_total{job="node-exporter", device!="lo"}[1m]) ) record: instance:node_network_receive_drop_excluding_lo:rate1m - expr: | sum without (device) ( rate(node_network_transmit_drop_total{job="node-exporter", device!="lo"}[1m]) ) record: instance:node_network_transmit_drop_excluding_lo:rate1m - name: kube-apiserver.rules rules: - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[1d])) - ( ( sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[1d])) or vector(0) ) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[1d])) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[1d])) ) ) + # errors sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1d])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1d])) labels: verb: read record: apiserver_request:burnrate1d - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[1h])) - ( ( sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[1h])) or vector(0) ) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[1h])) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[1h])) ) ) + # errors sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[1h])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[1h])) labels: verb: read record: apiserver_request:burnrate1h - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[2h])) - ( ( sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[2h])) or vector(0) ) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[2h])) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[2h])) ) ) + # errors sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[2h])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[2h])) labels: verb: read record: apiserver_request:burnrate2h - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[30m])) - ( ( sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30m])) or vector(0) ) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[30m])) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[30m])) ) ) + # errors sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[30m])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[30m])) labels: verb: read record: apiserver_request:burnrate30m - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[3d])) - ( ( sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[3d])) or vector(0) ) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[3d])) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[3d])) ) ) + # errors sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[3d])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[3d])) labels: verb: read record: apiserver_request:burnrate3d - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[5m])) - ( ( sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[5m])) or vector(0) ) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[5m])) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[5m])) ) ) + # errors sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[5m])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m])) labels: verb: read record: apiserver_request:burnrate5m - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[6h])) - ( ( sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[6h])) or vector(0) ) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[6h])) + sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[6h])) ) ) + # errors sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET",code=~"5.."}[6h])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[6h])) labels: verb: read record: apiserver_request:burnrate6h - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1d])) - sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[1d])) ) + sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1d])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1d])) labels: verb: write record: apiserver_request:burnrate1d - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1h])) - sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[1h])) ) + sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[1h])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[1h])) labels: verb: write record: apiserver_request:burnrate1h - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[2h])) - sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[2h])) ) + sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[2h])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[2h])) labels: verb: write record: apiserver_request:burnrate2h - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[30m])) - sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[30m])) ) + sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[30m])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[30m])) labels: verb: write record: apiserver_request:burnrate30m - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[3d])) - sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[3d])) ) + sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[3d])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[3d])) labels: verb: write record: apiserver_request:burnrate3d - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m])) - sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[5m])) ) + sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[5m])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m])) labels: verb: write record: apiserver_request:burnrate5m - expr: | ( ( # too slow sum(rate(apiserver_request_duration_seconds_count{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[6h])) - sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",le="1"}[6h])) ) + sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE",code=~"5.."}[6h])) ) / sum(rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[6h])) labels: verb: write record: apiserver_request:burnrate6h - expr: | sum by (code,resource) (rate(apiserver_request_total{job="apiserver",verb=~"LIST|GET"}[5m])) labels: verb: read record: code_resource:apiserver_request_total:rate5m - expr: | sum by (code,resource) (rate(apiserver_request_total{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m])) labels: verb: write record: code_resource:apiserver_request_total:rate5m - expr: | histogram_quantile(0.99, sum by (le, resource) (rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET"}[5m]))) > 0 labels: quantile: "0.99" verb: read record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.99, sum by (le, resource) (rate(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"POST|PUT|PATCH|DELETE"}[5m]))) > 0 labels: quantile: "0.99" verb: write record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile - expr: | sum(rate(apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod) / sum(rate(apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod) record: cluster:apiserver_request_duration_seconds:mean5m - expr: | histogram_quantile(0.99, sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)) labels: quantile: "0.99" record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.9, sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)) labels: quantile: "0.9" record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.5, sum(rate(apiserver_request_duration_seconds_bucket{job="apiserver",subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)) labels: quantile: "0.5" record: cluster_quantile:apiserver_request_duration_seconds:histogram_quantile - interval: 3m name: kube-apiserver-availability.rules rules: - expr: | 1 - ( ( # write too slow sum(increase(apiserver_request_duration_seconds_count{verb=~"POST|PUT|PATCH|DELETE"}[30d])) - sum(increase(apiserver_request_duration_seconds_bucket{verb=~"POST|PUT|PATCH|DELETE",le="1"}[30d])) ) + ( # read too slow sum(increase(apiserver_request_duration_seconds_count{verb=~"LIST|GET"}[30d])) - ( ( sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30d])) or vector(0) ) + sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope="namespace",le="0.5"}[30d])) + sum(increase(apiserver_request_duration_seconds_bucket{verb=~"LIST|GET",scope="cluster",le="5"}[30d])) ) ) + # errors sum(code:apiserver_request_total:increase30d{code=~"5.."} or vector(0)) ) / sum(code:apiserver_request_total:increase30d) labels: verb: all record: apiserver_request:availability30d - expr: | 1 - ( sum(increase(apiserver_request_duration_seconds_count{job="apiserver",verb=~"LIST|GET"}[30d])) - ( # too slow ( sum(increase(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope=~"resource|",le="0.1"}[30d])) or vector(0) ) + sum(increase(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="namespace",le="0.5"}[30d])) + sum(increase(apiserver_request_duration_seconds_bucket{job="apiserver",verb=~"LIST|GET",scope="cluster",le="5"}[30d])) ) + # errors sum(code:apiserver_request_total:increase30d{verb="read",code=~"5.."} or vector(0)) ) / sum(code:apiserver_request_total:increase30d{verb="read"}) labels: verb: read record: apiserver_request:availability30d - expr: | 1 - ( ( # too slow sum(increase(apiserver_request_duration_seconds_count{verb=~"POST|PUT|PATCH|DELETE"}[30d])) - sum(increase(apiserver_request_duration_seconds_bucket{verb=~"POST|PUT|PATCH|DELETE",le="1"}[30d])) ) + # errors sum(code:apiserver_request_total:increase30d{verb="write",code=~"5.."} or vector(0)) ) / sum(code:apiserver_request_total:increase30d{verb="write"}) labels: verb: write record: apiserver_request:availability30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"2.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"2.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"2.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"2.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"2.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"2.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"3.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"3.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"3.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"3.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"3.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"3.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"4.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"4.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"4.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"4.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"4.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"4.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="LIST",code=~"5.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="GET",code=~"5.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="POST",code=~"5.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PUT",code=~"5.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="PATCH",code=~"5.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code, verb) (increase(apiserver_request_total{job="apiserver",verb="DELETE",code=~"5.."}[30d])) record: code_verb:apiserver_request_total:increase30d - expr: | sum by (code) (code_verb:apiserver_request_total:increase30d{verb=~"LIST|GET"}) labels: verb: read record: code:apiserver_request_total:increase30d - expr: | sum by (code) (code_verb:apiserver_request_total:increase30d{verb=~"POST|PUT|PATCH|DELETE"}) labels: verb: write record: code:apiserver_request_total:increase30d - name: k8s.rules rules: - expr: | sum(rate(container_cpu_usage_seconds_total{job="kubelet", metrics_path="/metrics/cadvisor", image!="", container!="POD"}[5m])) by (namespace) record: namespace:container_cpu_usage_seconds_total:sum_rate - expr: | sum by (cluster, namespace, pod, container) ( rate(container_cpu_usage_seconds_total{job="kubelet", metrics_path="/metrics/cadvisor", image!="", container!="POD"}[5m]) ) * on (cluster, namespace, pod) group_left(node) topk by (cluster, namespace, pod) ( 1, max by(cluster, namespace, pod, node) (kube_pod_info{node!=""}) ) record: node_namespace_pod_container:container_cpu_usage_seconds_total:sum_rate - expr: | container_memory_working_set_bytes{job="kubelet", metrics_path="/metrics/cadvisor", image!=""} * on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=""}) ) record: node_namespace_pod_container:container_memory_working_set_bytes - expr: | container_memory_rss{job="kubelet", metrics_path="/metrics/cadvisor", image!=""} * on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=""}) ) record: node_namespace_pod_container:container_memory_rss - expr: | container_memory_cache{job="kubelet", metrics_path="/metrics/cadvisor", image!=""} * on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=""}) ) record: node_namespace_pod_container:container_memory_cache - expr: | container_memory_swap{job="kubelet", metrics_path="/metrics/cadvisor", image!=""} * on (namespace, pod) group_left(node) topk by(namespace, pod) (1, max by(namespace, pod, node) (kube_pod_info{node!=""}) ) record: node_namespace_pod_container:container_memory_swap - expr: | sum(container_memory_usage_bytes{job="kubelet", metrics_path="/metrics/cadvisor", image!="", container!="POD"}) by (namespace) record: namespace:container_memory_usage_bytes:sum - expr: | sum by (namespace) ( sum by (namespace, pod) ( max by (namespace, pod, container) ( kube_pod_container_resource_requests_memory_bytes{job="kube-state-metrics"} ) * on(namespace, pod) group_left() max by (namespace, pod) ( kube_pod_status_phase{phase=~"Pending|Running"} == 1 ) ) ) record: namespace:kube_pod_container_resource_requests_memory_bytes:sum - expr: | sum by (namespace) ( sum by (namespace, pod) ( max by (namespace, pod, container) ( kube_pod_container_resource_requests_cpu_cores{job="kube-state-metrics"} ) * on(namespace, pod) group_left() max by (namespace, pod) ( kube_pod_status_phase{phase=~"Pending|Running"} == 1 ) ) ) record: namespace:kube_pod_container_resource_requests_cpu_cores:sum - expr: | max by (cluster, namespace, workload, pod) ( label_replace( label_replace( kube_pod_owner{job="kube-state-metrics", owner_kind="ReplicaSet"}, "replicaset", "$1", "owner_name", "(.*)" ) * on(replicaset, namespace) group_left(owner_name) topk by(replicaset, namespace) ( 1, max by (replicaset, namespace, owner_name) ( kube_replicaset_owner{job="kube-state-metrics"} ) ), "workload", "$1", "owner_name", "(.*)" ) ) labels: workload_type: deployment record: namespace_workload_pod:kube_pod_owner:relabel - expr: | max by (cluster, namespace, workload, pod) ( label_replace( kube_pod_owner{job="kube-state-metrics", owner_kind="DaemonSet"}, "workload", "$1", "owner_name", "(.*)" ) ) labels: workload_type: daemonset record: namespace_workload_pod:kube_pod_owner:relabel - expr: | max by (cluster, namespace, workload, pod) ( label_replace( kube_pod_owner{job="kube-state-metrics", owner_kind="StatefulSet"}, "workload", "$1", "owner_name", "(.*)" ) ) labels: workload_type: statefulset record: namespace_workload_pod:kube_pod_owner:relabel - name: kube-scheduler.rules rules: - expr: | histogram_quantile(0.99, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.99" record: cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.99, sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.99" record: cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.99, sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.99" record: cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.9, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.9" record: cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.9, sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.9" record: cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.9, sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.9" record: cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.5, sum(rate(scheduler_e2e_scheduling_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.5" record: cluster_quantile:scheduler_e2e_scheduling_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.5, sum(rate(scheduler_scheduling_algorithm_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.5" record: cluster_quantile:scheduler_scheduling_algorithm_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.5, sum(rate(scheduler_binding_duration_seconds_bucket{job="kube-scheduler"}[5m])) without(instance, pod)) labels: quantile: "0.5" record: cluster_quantile:scheduler_binding_duration_seconds:histogram_quantile - name: node.rules rules: - expr: | sum(min(kube_pod_info{node!=""}) by (cluster, node)) record: ':kube_pod_info_node_count:' - expr: | topk by(namespace, pod) (1, max by (node, namespace, pod) ( label_replace(kube_pod_info{job="kube-state-metrics",node!=""}, "pod", "$1", "pod", "(.*)") )) record: 'node_namespace_pod:kube_pod_info:' - expr: | count by (cluster, node) (sum by (node, cpu) ( node_cpu_seconds_total{job="node-exporter"} * on (namespace, pod) group_left(node) node_namespace_pod:kube_pod_info: )) record: node:node_num_cpu:sum - expr: | sum( node_memory_MemAvailable_bytes{job="node-exporter"} or ( node_memory_Buffers_bytes{job="node-exporter"} + node_memory_Cached_bytes{job="node-exporter"} + node_memory_MemFree_bytes{job="node-exporter"} + node_memory_Slab_bytes{job="node-exporter"} ) ) by (cluster) record: :node_memory_MemAvailable_bytes:sum - name: kubelet.rules rules: - expr: | histogram_quantile(0.99, sum(rate(kubelet_pleg_relist_duration_seconds_bucket[5m])) by (instance, le) * on(instance) group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"}) labels: quantile: "0.99" record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.9, sum(rate(kubelet_pleg_relist_duration_seconds_bucket[5m])) by (instance, le) * on(instance) group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"}) labels: quantile: "0.9" record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile - expr: | histogram_quantile(0.5, sum(rate(kubelet_pleg_relist_duration_seconds_bucket[5m])) by (instance, le) * on(instance) group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"}) labels: quantile: "0.5" record: node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile - name: kube-prometheus-node-recording.rules rules: - expr: sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[3m])) BY (instance) record: instance:node_cpu:rate:sum - expr: sum(rate(node_network_receive_bytes_total[3m])) BY (instance) record: instance:node_network_receive_bytes:rate:sum - expr: sum(rate(node_network_transmit_bytes_total[3m])) BY (instance) record: instance:node_network_transmit_bytes:rate:sum - expr: sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[5m])) WITHOUT (cpu, mode) / ON(instance) GROUP_LEFT() count(sum(node_cpu_seconds_total) BY (instance, cpu)) BY (instance) record: instance:node_cpu:ratio - expr: sum(rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal"}[5m])) record: cluster:node_cpu:sum_rate5m - expr: cluster:node_cpu_seconds_total:rate5m / count(sum(node_cpu_seconds_total) BY (instance, cpu)) record: cluster:node_cpu:ratio - name: kube-prometheus-general.rules rules: - expr: count without(instance, pod, node) (up == 1) record: count:up1 - expr: count without(instance, pod, node) (up == 0) record: count:up0 - name: kube-state-metrics rules: - alert: KubeStateMetricsListErrors annotations: description: kube-state-metrics is experiencing errors at an elevated rate in list operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubestatemetricslisterrors summary: kube-state-metrics is experiencing errors in list operations. expr: | (sum(rate(kube_state_metrics_list_total{job="kube-state-metrics",result="error"}[5m])) / sum(rate(kube_state_metrics_list_total{job="kube-state-metrics"}[5m]))) > 0.01 for: 15m labels: severity: critical - alert: KubeStateMetricsWatchErrors annotations: description: kube-state-metrics is experiencing errors at an elevated rate in watch operations. This is likely causing it to not be able to expose metrics about Kubernetes objects correctly or at all. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubestatemetricswatcherrors summary: kube-state-metrics is experiencing errors in watch operations. expr: | (sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics",result="error"}[5m])) / sum(rate(kube_state_metrics_watch_total{job="kube-state-metrics"}[5m]))) > 0.01 for: 15m labels: severity: critical - name: node-exporter rules: - alert: NodeFilesystemSpaceFillingUp annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left and is filling up. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemspacefillingup summary: Filesystem is predicted to run out of space within the next 24 hours. expr: | ( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 40 and predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!=""}[6h], 24*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: warning - alert: NodeFilesystemSpaceFillingUp annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left and is filling up fast. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemspacefillingup summary: Filesystem is predicted to run out of space within the next 4 hours. expr: | ( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 15 and predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!=""}[6h], 4*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: critical - alert: NodeFilesystemAlmostOutOfSpace annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemalmostoutofspace summary: Filesystem has less than 5% space left. expr: | ( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 5 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: warning - alert: NodeFilesystemAlmostOutOfSpace annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available space left. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemalmostoutofspace summary: Filesystem has less than 3% space left. expr: | ( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 3 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: critical - alert: NodeFilesystemFilesFillingUp annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left and is filling up. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemfilesfillingup summary: Filesystem is predicted to run out of inodes within the next 24 hours. expr: | ( node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 40 and predict_linear(node_filesystem_files_free{job="node-exporter",fstype!=""}[6h], 24*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: warning - alert: NodeFilesystemFilesFillingUp annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left and is filling up fast. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemfilesfillingup summary: Filesystem is predicted to run out of inodes within the next 4 hours. expr: | ( node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 20 and predict_linear(node_filesystem_files_free{job="node-exporter",fstype!=""}[6h], 4*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: critical - alert: NodeFilesystemAlmostOutOfFiles annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemalmostoutoffiles summary: Filesystem has less than 5% inodes left. expr: | ( node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 5 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: warning - alert: NodeFilesystemAlmostOutOfFiles annotations: description: Filesystem on {{ $labels.device }} at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available inodes left. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodefilesystemalmostoutoffiles summary: Filesystem has less than 3% inodes left. expr: | ( node_filesystem_files_free{job="node-exporter",fstype!=""} / node_filesystem_files{job="node-exporter",fstype!=""} * 100 < 3 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h labels: severity: critical - alert: NodeNetworkReceiveErrs annotations: description: '{{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf "%.0f" $value }} receive errors in the last two minutes.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodenetworkreceiveerrs summary: Network interface is reporting many receive errors. expr: | rate(node_network_receive_errs_total[2m]) / rate(node_network_receive_packets_total[2m]) > 0.01 for: 1h labels: severity: warning - alert: NodeNetworkTransmitErrs annotations: description: '{{ $labels.instance }} interface {{ $labels.device }} has encountered {{ printf "%.0f" $value }} transmit errors in the last two minutes.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodenetworktransmiterrs summary: Network interface is reporting many transmit errors. expr: | rate(node_network_transmit_errs_total[2m]) / rate(node_network_transmit_packets_total[2m]) > 0.01 for: 1h labels: severity: warning - alert: NodeHighNumberConntrackEntriesUsed annotations: description: '{{ $value | humanizePercentage }} of conntrack entries are used.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodehighnumberconntrackentriesused summary: Number of conntrack are getting close to the limit. expr: | (node_nf_conntrack_entries / node_nf_conntrack_entries_limit) > 0.75 labels: severity: warning - alert: NodeTextFileCollectorScrapeError annotations: description: Node Exporter text file collector failed to scrape. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodetextfilecollectorscrapeerror summary: Node Exporter text file collector failed to scrape. expr: | node_textfile_scrape_error{job="node-exporter"} == 1 labels: severity: warning - alert: NodeClockSkewDetected annotations: message: Clock on {{ $labels.instance }} is out of sync by more than 300s. Ensure NTP is configured correctly on this host. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodeclockskewdetected summary: Clock skew detected. expr: | ( node_timex_offset_seconds > 0.05 and deriv(node_timex_offset_seconds[5m]) >= 0 ) or ( node_timex_offset_seconds < -0.05 and deriv(node_timex_offset_seconds[5m]) <= 0 ) for: 10m labels: severity: warning - alert: NodeClockNotSynchronising annotations: message: Clock on {{ $labels.instance }} is not synchronising. Ensure NTP is configured on this host. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/nodeclocknotsynchronising summary: Clock not synchronising. expr: | min_over_time(node_timex_sync_status[5m]) == 0 and node_timex_maxerror_seconds >= 16 for: 10m labels: severity: warning - alert: NodeRAIDDegraded annotations: description: RAID array '{{ $labels.device }}' on {{ $labels.instance }} is in degraded state due to one or more disks failures. Number of spare drives is insufficient to fix issue automatically. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/noderaiddegraded summary: RAID Array is degraded expr: | node_md_disks_required - ignoring (state) (node_md_disks{state="active"}) > 0 for: 15m labels: severity: critical - alert: NodeRAIDDiskFailure annotations: description: At least one device in RAID array on {{ $labels.instance }} failed. Array '{{ $labels.device }}' needs attention and possibly a disk swap. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/noderaiddiskfailure summary: Failed device in RAID array expr: | node_md_disks{state="fail"} > 0 labels: severity: warning - name: prometheus-operator rules: - alert: PrometheusOperatorListErrors annotations: description: Errors while performing List operations in controller {{$labels.controller}} in {{$labels.namespace}} namespace. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusoperatorlisterrors summary: Errors while performing list operations in controller. expr: | (sum by (controller,namespace) (rate(prometheus_operator_list_operations_failed_total{job="prometheus-operator",namespace="monitoring"}[10m])) / sum by (controller,namespace) (rate(prometheus_operator_list_operations_total{job="prometheus-operator",namespace="monitoring"}[10m]))) > 0.4 for: 15m labels: severity: warning - alert: PrometheusOperatorWatchErrors annotations: description: Errors while performing watch operations in controller {{$labels.controller}} in {{$labels.namespace}} namespace. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusoperatorwatcherrors summary: Errors while performing watch operations in controller. expr: | (sum by (controller,namespace) (rate(prometheus_operator_watch_operations_failed_total{job="prometheus-operator",namespace="monitoring"}[10m])) / sum by (controller,namespace) (rate(prometheus_operator_watch_operations_total{job="prometheus-operator",namespace="monitoring"}[10m]))) > 0.4 for: 15m labels: severity: warning - alert: PrometheusOperatorSyncFailed annotations: description: Controller {{ $labels.controller }} in {{ $labels.namespace }} namespace fails to reconcile {{ $value }} objects. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusoperatorsyncfailed summary: Last controller reconciliation failed expr: | min_over_time(prometheus_operator_syncs{status="failed",job="prometheus-operator",namespace="monitoring"}[5m]) > 0 for: 10m labels: severity: warning - alert: PrometheusOperatorReconcileErrors annotations: description: '{{ $value | humanizePercentage }} of reconciling operations failed for {{ $labels.controller }} controller in {{ $labels.namespace }} namespace.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusoperatorreconcileerrors summary: Errors while reconciling controller. expr: | (sum by (controller,namespace) (rate(prometheus_operator_reconcile_errors_total{job="prometheus-operator",namespace="monitoring"}[5m]))) / (sum by (controller,namespace) (rate(prometheus_operator_reconcile_operations_total{job="prometheus-operator",namespace="monitoring"}[5m]))) > 0.1 for: 10m labels: severity: warning - alert: PrometheusOperatorNodeLookupErrors annotations: description: Errors while reconciling Prometheus in {{ $labels.namespace }} Namespace. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusoperatornodelookuperrors summary: Errors while reconciling Prometheus. expr: | rate(prometheus_operator_node_address_lookup_errors_total{job="prometheus-operator",namespace="monitoring"}[5m]) > 0.1 for: 10m labels: severity: warning - alert: PrometheusOperatorNotReady annotations: description: Prometheus operator in {{ $labels.namespace }} namespace isn't ready to reconcile {{ $labels.controller }} resources. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusoperatornotready summary: Prometheus operator not ready expr: | min by(namespace, controller) (max_over_time(prometheus_operator_ready{job="prometheus-operator",namespace="monitoring"}[5m]) == 0) for: 5m labels: severity: warning - alert: PrometheusOperatorRejectedResources annotations: description: Prometheus operator in {{ $labels.namespace }} namespace rejected {{ printf "%0.0f" $value }} {{ $labels.controller }}/{{ $labels.resource }} resources. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/prometheusoperatorrejectedresources summary: Resources rejected by Prometheus operator expr: | min_over_time(prometheus_operator_managed_resources{state="rejected",job="prometheus-operator",namespace="monitoring"}[5m]) > 0 for: 5m labels: severity: warning - name: kubernetes-apps rules: - alert: KubePodCrashLooping annotations: description: Pod {{ $labels.namespace }}/{{ $labels.pod }} ({{ $labels.container }}) is restarting {{ printf "%.2f" $value }} times / 5 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubepodcrashlooping summary: Pod is crash looping. expr: | rate(kube_pod_container_status_restarts_total{job="kube-state-metrics"}[5m]) * 60 * 5 > 0 for: 15m labels: severity: warning - alert: KubePodNotReady annotations: description: Pod {{ $labels.namespace }}/{{ $labels.pod }} has been in a non-ready state for longer than 15 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubepodnotready summary: Pod has been in a non-ready state for more than 15 minutes. expr: | sum by (namespace, pod) ( max by(namespace, pod) ( kube_pod_status_phase{job="kube-state-metrics", phase=~"Pending|Unknown"} ) * on(namespace, pod) group_left(owner_kind) topk by(namespace, pod) ( 1, max by(namespace, pod, owner_kind) (kube_pod_owner{owner_kind!="Job"}) ) ) > 0 for: 15m labels: severity: warning - alert: KubeDeploymentGenerationMismatch annotations: description: Deployment generation for {{ $labels.namespace }}/{{ $labels.deployment }} does not match, this indicates that the Deployment has failed but has not been rolled back. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubedeploymentgenerationmismatch summary: Deployment generation mismatch due to possible roll-back expr: | kube_deployment_status_observed_generation{job="kube-state-metrics"} != kube_deployment_metadata_generation{job="kube-state-metrics"} for: 15m labels: severity: warning - alert: KubeDeploymentReplicasMismatch annotations: description: Deployment {{ $labels.namespace }}/{{ $labels.deployment }} has not matched the expected number of replicas for longer than 15 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubedeploymentreplicasmismatch summary: Deployment has not matched the expected number of replicas. expr: | ( kube_deployment_spec_replicas{job="kube-state-metrics"} != kube_deployment_status_replicas_available{job="kube-state-metrics"} ) and ( changes(kube_deployment_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 ) for: 15m labels: severity: warning - alert: KubeStatefulSetReplicasMismatch annotations: description: StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} has not matched the expected number of replicas for longer than 15 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubestatefulsetreplicasmismatch summary: Deployment has not matched the expected number of replicas. expr: | ( kube_statefulset_status_replicas_ready{job="kube-state-metrics"} != kube_statefulset_status_replicas{job="kube-state-metrics"} ) and ( changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 ) for: 15m labels: severity: warning - alert: KubeStatefulSetGenerationMismatch annotations: description: StatefulSet generation for {{ $labels.namespace }}/{{ $labels.statefulset }} does not match, this indicates that the StatefulSet has failed but has not been rolled back. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubestatefulsetgenerationmismatch summary: StatefulSet generation mismatch due to possible roll-back expr: | kube_statefulset_status_observed_generation{job="kube-state-metrics"} != kube_statefulset_metadata_generation{job="kube-state-metrics"} for: 15m labels: severity: warning - alert: KubeStatefulSetUpdateNotRolledOut annotations: description: StatefulSet {{ $labels.namespace }}/{{ $labels.statefulset }} update has not been rolled out. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubestatefulsetupdatenotrolledout summary: StatefulSet update has not been rolled out. expr: | ( max without (revision) ( kube_statefulset_status_current_revision{job="kube-state-metrics"} unless kube_statefulset_status_update_revision{job="kube-state-metrics"} ) * ( kube_statefulset_replicas{job="kube-state-metrics"} != kube_statefulset_status_replicas_updated{job="kube-state-metrics"} ) ) and ( changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 ) for: 15m labels: severity: warning - alert: KubeDaemonSetRolloutStuck annotations: description: DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} has not finished or progressed for at least 15 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubedaemonsetrolloutstuck summary: DaemonSet rollout is stuck. expr: | ( ( kube_daemonset_status_current_number_scheduled{job="kube-state-metrics"} != kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} ) or ( kube_daemonset_status_number_misscheduled{job="kube-state-metrics"} != 0 ) or ( kube_daemonset_updated_number_scheduled{job="kube-state-metrics"} != kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} ) or ( kube_daemonset_status_number_available{job="kube-state-metrics"} != kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} ) ) and ( changes(kube_daemonset_updated_number_scheduled{job="kube-state-metrics"}[5m]) == 0 ) for: 15m labels: severity: warning - alert: KubeContainerWaiting annotations: description: Pod {{ $labels.namespace }}/{{ $labels.pod }} container {{ $labels.container}} has been in waiting state for longer than 1 hour. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubecontainerwaiting summary: Pod container waiting longer than 1 hour expr: | sum by (namespace, pod, container) (kube_pod_container_status_waiting_reason{job="kube-state-metrics"}) > 0 for: 1h labels: severity: warning - alert: KubeDaemonSetNotScheduled annotations: description: '{{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are not scheduled.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubedaemonsetnotscheduled summary: DaemonSet pods are not scheduled. expr: | kube_daemonset_status_desired_number_scheduled{job="kube-state-metrics"} - kube_daemonset_status_current_number_scheduled{job="kube-state-metrics"} > 0 for: 10m labels: severity: warning - alert: KubeDaemonSetMisScheduled annotations: description: '{{ $value }} Pods of DaemonSet {{ $labels.namespace }}/{{ $labels.daemonset }} are running where they are not supposed to run.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubedaemonsetmisscheduled summary: DaemonSet pods are misscheduled. expr: | kube_daemonset_status_number_misscheduled{job="kube-state-metrics"} > 0 for: 15m labels: severity: warning - alert: KubeJobCompletion annotations: description: Job {{ $labels.namespace }}/{{ $labels.job_name }} is taking more than 12 hours to complete. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubejobcompletion summary: Job did not complete in time expr: | kube_job_spec_completions{job="kube-state-metrics"} - kube_job_status_succeeded{job="kube-state-metrics"} > 0 for: 12h labels: severity: warning - alert: KubeJobFailed annotations: description: Job {{ $labels.namespace }}/{{ $labels.job_name }} failed to complete. Removing failed job after investigation should clear this alert. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubejobfailed summary: Job failed to complete. expr: | kube_job_failed{job="kube-state-metrics"} > 0 for: 15m labels: severity: warning - alert: KubeHpaReplicasMismatch annotations: description: HPA {{ $labels.namespace }}/{{ $labels.hpa }} has not matched the desired number of replicas for longer than 15 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubehpareplicasmismatch summary: HPA has not matched descired number of replicas. expr: | (kube_hpa_status_desired_replicas{job="kube-state-metrics"} != kube_hpa_status_current_replicas{job="kube-state-metrics"}) and changes(kube_hpa_status_current_replicas[15m]) == 0 for: 15m labels: severity: warning - alert: KubeHpaMaxedOut annotations: description: HPA {{ $labels.namespace }}/{{ $labels.hpa }} has been running at max replicas for longer than 15 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubehpamaxedout summary: HPA is running at max replicas expr: | kube_hpa_status_current_replicas{job="kube-state-metrics"} == kube_hpa_spec_max_replicas{job="kube-state-metrics"} for: 15m labels: severity: warning - name: kubernetes-resources rules: - alert: KubeCPUOvercommit annotations: description: Cluster has overcommitted CPU resource requests for Pods and cannot tolerate node failure. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubecpuovercommit summary: Cluster has overcommitted CPU resource requests. expr: | sum(namespace:kube_pod_container_resource_requests_cpu_cores:sum{}) / sum(kube_node_status_allocatable_cpu_cores) > (count(kube_node_status_allocatable_cpu_cores)-1) / count(kube_node_status_allocatable_cpu_cores) for: 5m labels: severity: warning - alert: KubeMemoryOvercommit annotations: description: Cluster has overcommitted memory resource requests for Pods and cannot tolerate node failure. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubememoryovercommit summary: Cluster has overcommitted memory resource requests. expr: | sum(namespace:kube_pod_container_resource_requests_memory_bytes:sum{}) / sum(kube_node_status_allocatable_memory_bytes) > (count(kube_node_status_allocatable_memory_bytes)-1) / count(kube_node_status_allocatable_memory_bytes) for: 5m labels: severity: warning - alert: KubeCPUQuotaOvercommit annotations: description: Cluster has overcommitted CPU resource requests for Namespaces. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubecpuquotaovercommit summary: Cluster has overcommitted CPU resource requests. expr: | sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="cpu"}) / sum(kube_node_status_allocatable_cpu_cores) > 1.5 for: 5m labels: severity: warning - alert: KubeMemoryQuotaOvercommit annotations: description: Cluster has overcommitted memory resource requests for Namespaces. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubememoryquotaovercommit summary: Cluster has overcommitted memory resource requests. expr: | sum(kube_resourcequota{job="kube-state-metrics", type="hard", resource="memory"}) / sum(kube_node_status_allocatable_memory_bytes{job="node-exporter"}) > 1.5 for: 5m labels: severity: warning - alert: KubeQuotaAlmostFull annotations: description: Namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage }} of its {{ $labels.resource }} quota. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubequotaalmostfull summary: Namespace quota is going to be full. expr: | kube_resourcequota{job="kube-state-metrics", type="used"} / ignoring(instance, job, type) (kube_resourcequota{job="kube-state-metrics", type="hard"} > 0) > 0.9 < 1 for: 15m labels: severity: info - alert: KubeQuotaFullyUsed annotations: description: Namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage }} of its {{ $labels.resource }} quota. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubequotafullyused summary: Namespace quota is fully used. expr: | kube_resourcequota{job="kube-state-metrics", type="used"} / ignoring(instance, job, type) (kube_resourcequota{job="kube-state-metrics", type="hard"} > 0) == 1 for: 15m labels: severity: info - alert: KubeQuotaExceeded annotations: description: Namespace {{ $labels.namespace }} is using {{ $value | humanizePercentage }} of its {{ $labels.resource }} quota. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubequotaexceeded summary: Namespace quota has exceeded the limits. expr: | kube_resourcequota{job="kube-state-metrics", type="used"} / ignoring(instance, job, type) (kube_resourcequota{job="kube-state-metrics", type="hard"} > 0) > 1 for: 15m labels: severity: warning - alert: CPUThrottlingHigh annotations: description: '{{ $value | humanizePercentage }} throttling of CPU in namespace {{ $labels.namespace }} for container {{ $labels.container }} in pod {{ $labels.pod }}.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/cputhrottlinghigh summary: Processes experience elevated CPU throttling. expr: | sum(increase(container_cpu_cfs_throttled_periods_total{container!="", }[5m])) by (container, pod, namespace) / sum(increase(container_cpu_cfs_periods_total{}[5m])) by (container, pod, namespace) > ( 25 / 100 ) for: 15m labels: severity: info - name: kubernetes-storage rules: - alert: KubePersistentVolumeFillingUp annotations: description: The PersistentVolume claimed by {{ $labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} is only {{ $value | humanizePercentage }} free. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubepersistentvolumefillingup summary: PersistentVolume is filling up. expr: | kubelet_volume_stats_available_bytes{job="kubelet", metrics_path="/metrics"} / kubelet_volume_stats_capacity_bytes{job="kubelet", metrics_path="/metrics"} < 0.03 for: 1m labels: severity: critical - alert: KubePersistentVolumeFillingUp annotations: description: Based on recent sampling, the PersistentVolume claimed by {{ $labels.persistentvolumeclaim }} in Namespace {{ $labels.namespace }} is expected to fill up within four days. Currently {{ $value | humanizePercentage }} is available. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubepersistentvolumefillingup summary: PersistentVolume is filling up. expr: | ( kubelet_volume_stats_available_bytes{job="kubelet", metrics_path="/metrics"} / kubelet_volume_stats_capacity_bytes{job="kubelet", metrics_path="/metrics"} ) < 0.15 and predict_linear(kubelet_volume_stats_available_bytes{job="kubelet", metrics_path="/metrics"}[6h], 4 * 24 * 3600) < 0 for: 1h labels: severity: warning - alert: KubePersistentVolumeErrors annotations: description: The persistent volume {{ $labels.persistentvolume }} has status {{ $labels.phase }}. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubepersistentvolumeerrors summary: PersistentVolume is having issues with provisioning. expr: | kube_persistentvolume_status_phase{phase=~"Failed|Pending",job="kube-state-metrics"} > 0 for: 5m labels: severity: critical - name: kubernetes-system rules: - alert: KubeVersionMismatch annotations: description: There are {{ $value }} different semantic versions of Kubernetes components running. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeversionmismatch summary: Different semantic versions of Kubernetes components running. expr: | count(count by (gitVersion) (label_replace(kubernetes_build_info{job!~"kube-dns|coredns"},"gitVersion","$1","gitVersion","(v[0-9]*.[0-9]*).*"))) > 1 for: 15m labels: severity: warning - alert: KubeClientErrors annotations: description: Kubernetes API server client '{{ $labels.job }}/{{ $labels.instance }}' is experiencing {{ $value | humanizePercentage }} errors.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeclienterrors summary: Kubernetes API server client is experiencing errors. expr: | (sum(rate(rest_client_requests_total{code=~"5.."}[5m])) by (instance, job) / sum(rate(rest_client_requests_total[5m])) by (instance, job)) > 0.01 for: 15m labels: severity: warning - name: kube-apiserver-slos rules: - alert: KubeAPIErrorBudgetBurn annotations: description: The API server is burning too much error budget. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeapierrorbudgetburn summary: The API server is burning too much error budget. expr: | sum(apiserver_request:burnrate1h) > (14.40 * 0.01000) and sum(apiserver_request:burnrate5m) > (14.40 * 0.01000) for: 2m labels: long: 1h severity: critical short: 5m - alert: KubeAPIErrorBudgetBurn annotations: description: The API server is burning too much error budget. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeapierrorbudgetburn summary: The API server is burning too much error budget. expr: | sum(apiserver_request:burnrate6h) > (6.00 * 0.01000) and sum(apiserver_request:burnrate30m) > (6.00 * 0.01000) for: 15m labels: long: 6h severity: critical short: 30m - alert: KubeAPIErrorBudgetBurn annotations: description: The API server is burning too much error budget. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeapierrorbudgetburn summary: The API server is burning too much error budget. expr: | sum(apiserver_request:burnrate1d) > (3.00 * 0.01000) and sum(apiserver_request:burnrate2h) > (3.00 * 0.01000) for: 1h labels: long: 1d severity: warning short: 2h - alert: KubeAPIErrorBudgetBurn annotations: description: The API server is burning too much error budget. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeapierrorbudgetburn summary: The API server is burning too much error budget. expr: | sum(apiserver_request:burnrate3d) > (1.00 * 0.01000) and sum(apiserver_request:burnrate6h) > (1.00 * 0.01000) for: 3h labels: long: 3d severity: warning short: 6h - name: kubernetes-system-apiserver rules: - alert: KubeClientCertificateExpiration annotations: description: A client certificate used to authenticate to the apiserver is expiring in less than 7.0 days. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeclientcertificateexpiration summary: Client certificate is about to expire. expr: | apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and on(job) histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 604800 labels: severity: warning - alert: KubeClientCertificateExpiration annotations: description: A client certificate used to authenticate to the apiserver is expiring in less than 24.0 hours. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeclientcertificateexpiration summary: Client certificate is about to expire. expr: | apiserver_client_certificate_expiration_seconds_count{job="apiserver"} > 0 and on(job) histogram_quantile(0.01, sum by (job, le) (rate(apiserver_client_certificate_expiration_seconds_bucket{job="apiserver"}[5m]))) < 86400 labels: severity: critical - alert: AggregatedAPIErrors annotations: description: An aggregated API {{ $labels.name }}/{{ $labels.namespace }} has reported errors. The number of errors have increased for it in the past five minutes. High values indicate that the availability of the service changes too often. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/aggregatedapierrors summary: An aggregated API has reported errors. expr: | sum by(name, namespace)(increase(aggregator_unavailable_apiservice_count[5m])) > 2 labels: severity: warning - alert: AggregatedAPIDown annotations: description: An aggregated API {{ $labels.name }}/{{ $labels.namespace }} has been only {{ $value | humanize }}% available over the last 10m. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/aggregatedapidown summary: An aggregated API is down. expr: | (1 - max by(name, namespace)(avg_over_time(aggregator_unavailable_apiservice[10m]))) * 100 < 85 for: 5m labels: severity: warning - alert: KubeAPIDown annotations: description: KubeAPI has disappeared from Prometheus target discovery. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeapidown summary: Target disappeared from Prometheus target discovery. expr: | absent(up{job="apiserver"} == 1) for: 15m labels: severity: critical - name: kubernetes-system-kubelet rules: - alert: KubeNodeNotReady annotations: description: '{{ $labels.node }} has been unready for more than 15 minutes.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubenodenotready summary: Node is not ready. expr: | kube_node_status_condition{job="kube-state-metrics",condition="Ready",status="true"} == 0 for: 15m labels: severity: warning - alert: KubeNodeUnreachable annotations: description: '{{ $labels.node }} is unreachable and some workloads may be rescheduled.' runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubenodeunreachable summary: Node is unreachable. expr: | (kube_node_spec_taint{job="kube-state-metrics",key="node.kubernetes.io/unreachable",effect="NoSchedule"} unless ignoring(key,value) kube_node_spec_taint{job="kube-state-metrics",key=~"ToBeDeletedByClusterAutoscaler|cloud.google.com/impending-node-termination|aws-node-termination-handler/spot-itn"}) == 1 for: 15m labels: severity: warning - alert: KubeletTooManyPods annotations: description: Kubelet '{{ $labels.node }}' is running at {{ $value | humanizePercentage }} of its Pod capacity. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubelettoomanypods summary: Kubelet is running at capacity. expr: | count by(node) ( (kube_pod_status_phase{job="kube-state-metrics",phase="Running"} == 1) * on(instance,pod,namespace,cluster) group_left(node) topk by(instance,pod,namespace,cluster) (1, kube_pod_info{job="kube-state-metrics"}) ) / max by(node) ( kube_node_status_capacity_pods{job="kube-state-metrics"} != 1 ) > 0.95 for: 15m labels: severity: warning - alert: KubeNodeReadinessFlapping annotations: description: The readiness status of node {{ $labels.node }} has changed {{ $value }} times in the last 15 minutes. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubenodereadinessflapping summary: Node readiness status is flapping. expr: | sum(changes(kube_node_status_condition{status="true",condition="Ready"}[15m])) by (node) > 2 for: 15m labels: severity: warning - alert: KubeletPlegDurationHigh annotations: description: The Kubelet Pod Lifecycle Event Generator has a 99th percentile duration of {{ $value }} seconds on node {{ $labels.node }}. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletplegdurationhigh summary: Kubelet Pod Lifecycle Event Generator is taking too long to relist. expr: | node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile{quantile="0.99"} >= 10 for: 5m labels: severity: warning - alert: KubeletPodStartUpLatencyHigh annotations: description: Kubelet Pod startup 99th percentile latency is {{ $value }} seconds on node {{ $labels.node }}. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletpodstartuplatencyhigh summary: Kubelet Pod startup latency is too high. expr: | histogram_quantile(0.99, sum(rate(kubelet_pod_worker_duration_seconds_bucket{job="kubelet", metrics_path="/metrics"}[5m])) by (instance, le)) * on(instance) group_left(node) kubelet_node_name{job="kubelet", metrics_path="/metrics"} > 60 for: 15m labels: severity: warning - alert: KubeletClientCertificateExpiration annotations: description: Client certificate for Kubelet on node {{ $labels.node }} expires in {{ $value | humanizeDuration }}. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletclientcertificateexpiration summary: Kubelet client certificate is about to expire. expr: | kubelet_certificate_manager_client_ttl_seconds < 604800 labels: severity: warning - alert: KubeletClientCertificateExpiration annotations: description: Client certificate for Kubelet on node {{ $labels.node }} expires in {{ $value | humanizeDuration }}. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletclientcertificateexpiration summary: Kubelet client certificate is about to expire. expr: | kubelet_certificate_manager_client_ttl_seconds < 86400 labels: severity: critical - alert: KubeletServerCertificateExpiration annotations: description: Server certificate for Kubelet on node {{ $labels.node }} expires in {{ $value | humanizeDuration }}. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletservercertificateexpiration summary: Kubelet server certificate is about to expire. expr: | kubelet_certificate_manager_server_ttl_seconds < 604800 labels: severity: warning - alert: KubeletServerCertificateExpiration annotations: description: Server certificate for Kubelet on node {{ $labels.node }} expires in {{ $value | humanizeDuration }}. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletservercertificateexpiration summary: Kubelet server certificate is about to expire. expr: | kubelet_certificate_manager_server_ttl_seconds < 86400 labels: severity: critical - alert: KubeletClientCertificateRenewalErrors annotations: description: Kubelet on node {{ $labels.node }} has failed to renew its client certificate ({{ $value | humanize }} errors in the last 5 minutes). runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletclientcertificaterenewalerrors summary: Kubelet has failed to renew its client certificate. expr: | increase(kubelet_certificate_manager_client_expiration_renew_errors[5m]) > 0 for: 15m labels: severity: warning - alert: KubeletServerCertificateRenewalErrors annotations: description: Kubelet on node {{ $labels.node }} has failed to renew its server certificate ({{ $value | humanize }} errors in the last 5 minutes). runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletservercertificaterenewalerrors summary: Kubelet has failed to renew its server certificate. expr: | increase(kubelet_server_expiration_renew_errors[5m]) > 0 for: 15m labels: severity: warning - alert: KubeletDown annotations: description: Kubelet has disappeared from Prometheus target discovery. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeletdown summary: Target disappeared from Prometheus target discovery. expr: | absent(up{job="kubelet", metrics_path="/metrics"} == 1) for: 15m labels: severity: critical - name: kubernetes-system-scheduler rules: - alert: KubeSchedulerDown annotations: description: KubeScheduler has disappeared from Prometheus target discovery. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubeschedulerdown summary: Target disappeared from Prometheus target discovery. expr: | absent(up{job="kube-scheduler"} == 1) for: 15m labels: severity: critical - name: kubernetes-system-controller-manager rules: - alert: KubeControllerManagerDown annotations: description: KubeControllerManager has disappeared from Prometheus target discovery. runbook_url: https://github.com/prometheus-operator/kube-prometheus/wiki/kubecontrollermanagerdown summary: Target disappeared from Prometheus target discovery. expr: | absent(up{job="kube-controller-manager"} == 1) for: 15m labels: severity: critical - name: prometheus rules: - alert: PrometheusBadConfig annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has failed to reload its configuration. summary: Failed Prometheus configuration reload. expr: | # Without max_over_time, failed scrapes could create false negatives, see # https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details. max_over_time(prometheus_config_last_reload_successful{job="prometheus-k8s",namespace="monitoring"}[5m]) == 0 for: 10m labels: severity: critical - alert: PrometheusNotificationQueueRunningFull annotations: description: Alert notification queue of Prometheus {{$labels.namespace}}/{{$labels.pod}} is running full. summary: Prometheus alert notification queue predicted to run full in less than 30m. expr: | # Without min_over_time, failed scrapes could create false negatives, see # https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details. ( predict_linear(prometheus_notifications_queue_length{job="prometheus-k8s",namespace="monitoring"}[5m], 60 * 30) > min_over_time(prometheus_notifications_queue_capacity{job="prometheus-k8s",namespace="monitoring"}[5m]) ) for: 15m labels: severity: warning - alert: PrometheusErrorSendingAlertsToSomeAlertmanagers annotations: description: '{{ printf "%.1f" $value }}% errors while sending alerts from Prometheus {{$labels.namespace}}/{{$labels.pod}} to Alertmanager {{$labels.alertmanager}}.' summary: Prometheus has encountered more than 1% errors sending alerts to a specific Alertmanager. expr: | ( rate(prometheus_notifications_errors_total{job="prometheus-k8s",namespace="monitoring"}[5m]) / rate(prometheus_notifications_sent_total{job="prometheus-k8s",namespace="monitoring"}[5m]) ) * 100 > 1 for: 15m labels: severity: warning - alert: PrometheusErrorSendingAlertsToAnyAlertmanager annotations: description: '{{ printf "%.1f" $value }}% minimum errors while sending alerts from Prometheus {{$labels.namespace}}/{{$labels.pod}} to any Alertmanager.' summary: Prometheus encounters more than 3% errors sending alerts to any Alertmanager. expr: | min without(alertmanager) ( rate(prometheus_notifications_errors_total{job="prometheus-k8s",namespace="monitoring"}[5m]) / rate(prometheus_notifications_sent_total{job="prometheus-k8s",namespace="monitoring"}[5m]) ) * 100 > 3 for: 15m labels: severity: critical - alert: PrometheusNotConnectedToAlertmanagers annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is not connected to any Alertmanagers. summary: Prometheus is not connected to any Alertmanagers. expr: | # Without max_over_time, failed scrapes could create false negatives, see # https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details. max_over_time(prometheus_notifications_alertmanagers_discovered{job="prometheus-k8s",namespace="monitoring"}[5m]) < 1 for: 10m labels: severity: warning - alert: PrometheusTSDBReloadsFailing annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has detected {{$value | humanize}} reload failures over the last 3h. summary: Prometheus has issues reloading blocks from disk. expr: | increase(prometheus_tsdb_reloads_failures_total{job="prometheus-k8s",namespace="monitoring"}[3h]) > 0 for: 4h labels: severity: warning - alert: PrometheusTSDBCompactionsFailing annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has detected {{$value | humanize}} compaction failures over the last 3h. summary: Prometheus has issues compacting blocks. expr: | increase(prometheus_tsdb_compactions_failed_total{job="prometheus-k8s",namespace="monitoring"}[3h]) > 0 for: 4h labels: severity: warning - alert: PrometheusNotIngestingSamples annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is not ingesting samples. summary: Prometheus is not ingesting samples. expr: | rate(prometheus_tsdb_head_samples_appended_total{job="prometheus-k8s",namespace="monitoring"}[5m]) <= 0 for: 10m labels: severity: warning - alert: PrometheusDuplicateTimestamps annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is dropping {{ printf "%.4g" $value }} samples/s with different values but duplicated timestamp. summary: Prometheus is dropping samples with duplicate timestamps. expr: | rate(prometheus_target_scrapes_sample_duplicate_timestamp_total{job="prometheus-k8s",namespace="monitoring"}[5m]) > 0 for: 10m labels: severity: warning - alert: PrometheusOutOfOrderTimestamps annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} is dropping {{ printf "%.4g" $value }} samples/s with timestamps arriving out of order. summary: Prometheus drops samples with out-of-order timestamps. expr: | rate(prometheus_target_scrapes_sample_out_of_order_total{job="prometheus-k8s",namespace="monitoring"}[5m]) > 0 for: 10m labels: severity: warning - alert: PrometheusRemoteStorageFailures annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} failed to send {{ printf "%.1f" $value }}% of the samples to {{ $labels.remote_name}}:{{ $labels.url }} summary: Prometheus fails to send samples to remote storage. expr: | ( rate(prometheus_remote_storage_failed_samples_total{job="prometheus-k8s",namespace="monitoring"}[5m]) / ( rate(prometheus_remote_storage_failed_samples_total{job="prometheus-k8s",namespace="monitoring"}[5m]) + rate(prometheus_remote_storage_succeeded_samples_total{job="prometheus-k8s",namespace="monitoring"}[5m]) ) ) * 100 > 1 for: 15m labels: severity: critical - alert: PrometheusRemoteWriteBehind annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} remote write is {{ printf "%.1f" $value }}s behind for {{ $labels.remote_name}}:{{ $labels.url }}. summary: Prometheus remote write is behind. expr: | # Without max_over_time, failed scrapes could create false negatives, see # https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details. ( max_over_time(prometheus_remote_storage_highest_timestamp_in_seconds{job="prometheus-k8s",namespace="monitoring"}[5m]) - on(job, instance) group_right max_over_time(prometheus_remote_storage_queue_highest_sent_timestamp_seconds{job="prometheus-k8s",namespace="monitoring"}[5m]) ) > 120 for: 15m labels: severity: critical - alert: PrometheusRemoteWriteDesiredShards annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} remote write desired shards calculation wants to run {{ $value }} shards for queue {{ $labels.remote_name}}:{{ $labels.url }}, which is more than the max of {{ printf `prometheus_remote_storage_shards_max{instance="%s",job="prometheus-k8s",namespace="monitoring"}` $labels.instance | query | first | value }}. summary: Prometheus remote write desired shards calculation wants to run more than configured max shards. expr: | # Without max_over_time, failed scrapes could create false negatives, see # https://www.robustperception.io/alerting-on-gauges-in-prometheus-2-0 for details. ( max_over_time(prometheus_remote_storage_shards_desired{job="prometheus-k8s",namespace="monitoring"}[5m]) > max_over_time(prometheus_remote_storage_shards_max{job="prometheus-k8s",namespace="monitoring"}[5m]) ) for: 15m labels: severity: warning - alert: PrometheusRuleFailures annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has failed to evaluate {{ printf "%.0f" $value }} rules in the last 5m. summary: Prometheus is failing rule evaluations. expr: | increase(prometheus_rule_evaluation_failures_total{job="prometheus-k8s",namespace="monitoring"}[5m]) > 0 for: 15m labels: severity: critical - alert: PrometheusMissingRuleEvaluations annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has missed {{ printf "%.0f" $value }} rule group evaluations in the last 5m. summary: Prometheus is missing rule evaluations due to slow rule group evaluation. expr: | increase(prometheus_rule_group_iterations_missed_total{job="prometheus-k8s",namespace="monitoring"}[5m]) > 0 for: 15m labels: severity: warning - alert: PrometheusTargetLimitHit annotations: description: Prometheus {{$labels.namespace}}/{{$labels.pod}} has dropped {{ printf "%.0f" $value }} targets because the number of targets exceeded the configured target_limit. summary: Prometheus has dropped targets because some scrape configs have exceeded the targets limit. expr: | increase(prometheus_target_scrape_pool_exceeded_target_limit_total{job="prometheus-k8s",namespace="monitoring"}[5m]) > 0 for: 15m labels: severity: warning - name: alertmanager.rules rules: - alert: AlertmanagerConfigInconsistent annotations: message: | The configuration of the instances of the Alertmanager cluster `{{ $labels.namespace }}/{{ $labels.service }}` are out of sync. {{ range printf "alertmanager_config_hash{namespace=\"%s\",service=\"%s\"}" $labels.namespace $labels.service | query }} Configuration hash for pod {{ .Labels.pod }} is "{{ printf "%.f" .Value }}" {{ end }} expr: | count by(namespace,service) (count_values by(namespace,service) ("config_hash", alertmanager_config_hash{job="alertmanager-main",namespace="monitoring"})) != 1 for: 5m labels: severity: critical - alert: AlertmanagerFailedReload annotations: message: Reloading Alertmanager's configuration has failed for {{ $labels.namespace }}/{{ $labels.pod}}. expr: | alertmanager_config_last_reload_successful{job="alertmanager-main",namespace="monitoring"} == 0 for: 10m labels: severity: warning - alert: AlertmanagerMembersInconsistent annotations: message: Alertmanager has not found all other members of the cluster. expr: | alertmanager_cluster_members{job="alertmanager-main",namespace="monitoring"} != on (service) GROUP_LEFT() count by (service) (alertmanager_cluster_members{job="alertmanager-main",namespace="monitoring"}) for: 5m labels: severity: critical - name: general.rules rules: - alert: TargetDown annotations: message: '{{ printf "%.4g" $value }}% of the {{ $labels.job }}/{{ $labels.service }} targets in {{ $labels.namespace }} namespace are down.' expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10 for: 10m labels: severity: warning - alert: Watchdog annotations: message: | This is an alert meant to ensure that the entire alerting pipeline is functional. This alert is always firing, therefore it should always be firing in Alertmanager and always fire against a receiver. There are integrations with various notification mechanisms that send a notification when this alert is not firing. For example the "DeadMansSnitch" integration in PagerDuty. expr: vector(1) labels: severity: none - name: node-network rules: - alert: NodeNetworkInterfaceFlapping annotations: message: Network interface "{{ $labels.device }}" changing it's up status often on node-exporter {{ $labels.namespace }}/{{ $labels.pod }}" expr: | changes(node_network_up{job="node-exporter",device!~"veth.+"}[2m]) > 2 for: 2m labels: severity: warning
kubectl apply -f manifests/setup
kubectl apply -f manifests/
四、添加外部监控
一个项目开始可能很难实现全部容器化,比如数据库、CDH集群。但是我们依然需要监控他们,如果分成两套prometheus不利于管理,所以我们统一添加这些监控到kube-prometheus中。
那么接下来我们新建prometheus-additional.yaml文件,添加额外监控组件配置scrape_configs。
- job_name: 'k8s_sercice_metrics' honor_labels: true kubernetes_sd_configs: - role: pod namespaces: names: [xxx-online, xxx-sandbox] ##如果你的服务部署在除kube-system、default、monitoring这三个namaspace之外,此处直接写是不生效的,具体修改请看下文第十步定制化配置 metrics_path: /swoole/stats relabel_configs: - action: keep source_labels: [__meta_kubernetes_pod_label_app, __meta_kubernetes_pod_container_name] regex: micro-service-article.*;micro-service-article.* - source_labels: - __meta_kubernetes_namespace target_label: namespace - job_name: 'ingress-nginx-endpoints' kubernetes_sd_configs: - role: pod namespaces: names: - kube-system relabel_configs: - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - source_labels: [__meta_kubernetes_service_name] regex: prometheus-server action: drop
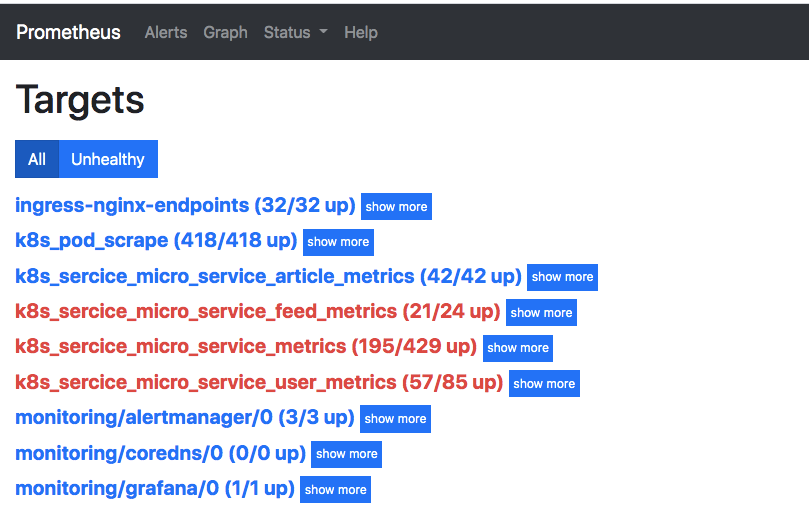
五、Scheduler和Controller配置
展开Status菜单,查看targets,可以看到只有图中两个监控任务没有对应的目标,这和serviceMonitor资源对象有关。
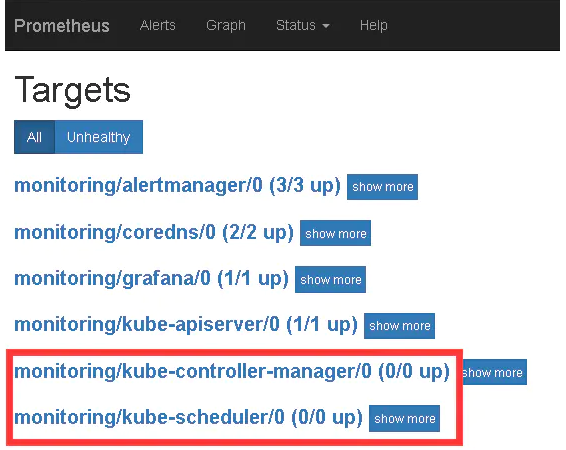
查看yaml文件prometheus-serviceMonitorKubeScheduler,selector匹配的是service的标签,但是kube-system namespace中并没有k8s-app=kube-scheduler的service
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- interval: 30s # 每30s获取一次信息
port: http-metrics # 对应service的端口名
jobLabel: k8s-app
namespaceSelector: # 表示去匹配某一命名空间中的service,如果想从所有的namespace中匹配用any: true
matchNames:
- kube-system
selector: # 匹配的 Service 的labels,如果使用mathLabels,则下面的所有标签都匹配时才会匹配该service,如果使用matchExpressions,则至少匹配一个标签的service都会被选择
matchLabels:
k8s-app: kube-scheduler
新建prometheus-kubeSchedulerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler #与servicemonitor中的selector匹配
spec:
selector:
component: kube-scheduler # 与scheduler的pod标签一直
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
同理新建prometheus-kubeControllerManagerService.yaml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
六、Alertmanager配置
监控和告警项已经配置好了,那么接下来我们将进行alertmanager告警配置了。
常用的接收方式就是邮件了,但这里我们将使用飞书和邮件进行接收,(飞书和企业微信道理相同),所以需要自行开发一个连接飞书的应用websocket,进行消息转发和处理。
当然,你也可以直接配置微信号和消息模板
global:
resolve_timeout: 5m #5m内没有收到告警标记为已恢复
smtp_smarthost: 'smtp.exmail.qq.com:465'
smtp_from: '发件箱名称'
smtp_auth_username: '发件箱名称'
smtp_auth_password: '发件箱密码'
smtp_require_tls: false
templates:
- '/usr/local/alertmanager/template/*.tmpl' 邮箱模板
route:
receiver: default
group_wait: 10s #如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送。
group_interval: 5m #用于定义相同的Gourp之间发送告警通知的时间间隔。
repeat_interval: 5m #如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
group_by: [alertname] #将多条告警合合并为一个通知,如果满足group_by中定义标签名称,那么这些告警将会合并为一个通知发送给接收器。
routes:
- receiver: webhook
group_wait: 10s
match:
status: warning
#配置接收器
receivers:
- name: webhook
webhook_configs:
- url: http://192.168.116.57:5004 #此处为自行开发的websocket地址,接收alertmanager告警并处理及发送到飞书或者企业微信
send_resolved: true
- name: default
email_configs:
- to: '收件箱名称'
send_resolved: true
html: '{{ template "emai.html" . }}' # 模板
headers: { Subject: "{{ .CommonAnnotations.summary }}" }
#抑制配置
#inhibit_rules:- source_match:
# status: 'critical'
#target_match:
# status: 'warning'
# Apply inhibition if the alertname is the same.
#equal: ['alertname' ]
然后我们需要将alertmanager配置以secret资源类型存储到k8s集群中。
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
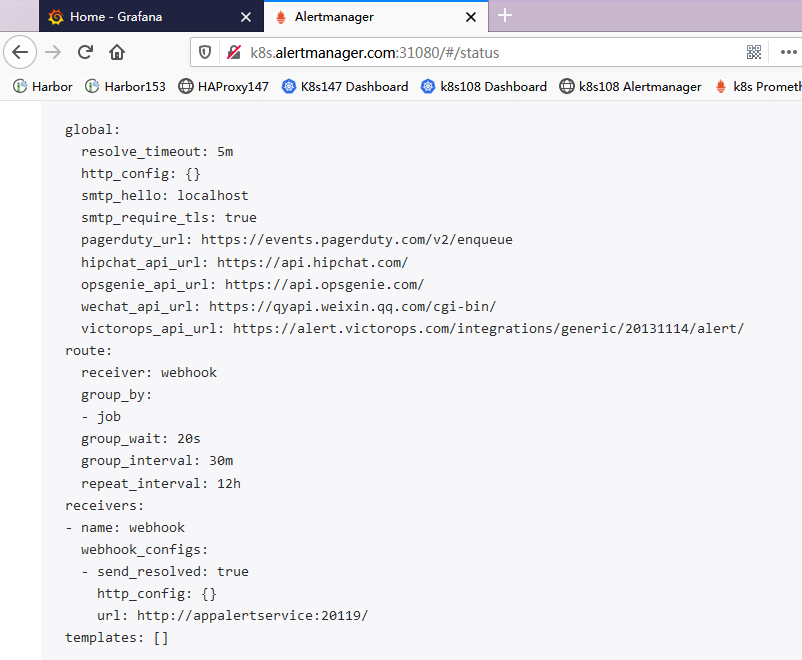
七、监控数据持久化
默认Prometheus和Grafana不做数据持久化,那么服务重启以后配置的Dashboard、账号密码、监控数据等信息将会丢失,所以做数据持久化也是很有必要的。
原始的数据是以 emptyDir 形式存放在pod里面,生命周期与pod相同,出现问题时,容器重启,监控相关的数据就全部消失了。
这里我们通过 storageclass 来做数据持久化,具体配置可以参考:Kubernetes实战总结 - 动态存储管理StorageClass
对于Grafana来说,我们需要在grafana-deployment.yaml中增加PVC配置,并且更改volumes.grafana-storage。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: monitoring
annotations:
volume.beta.kubernetes.io/storage-class: "managed-nfs-storage"
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: grafana
name: grafana
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
#- image: grafana/grafana:6.4.3
- image: registry.cn-shanghai.aliyuncs.com/leozhanggg/prometheus/grafana:6.4.3
name: grafana
ports:
- containerPort: 3000
name: http
readinessProbe:
httpGet:
path: /api/health
port: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
readOnly: false
...
volumes:
# - emptyDir: {}
# name: grafana-storage
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana
...
对于Prometheus来说,我们只需要在prometheus-prometheus.yaml中增加volumeClaimTemplate配置即可。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
#baseImage: quay.io/prometheus/prometheus
baseImage: registry.cn-shanghai.aliyuncs.com/leozhanggg/prometheus/prometheus
additionalScrapeConfigs:
name: additional-scrape-configs
key: prometheus-additional.yaml
retention: 15d
storage:
volumeClaimTemplate:
spec:
storageClassName: alicloud-nas
resources:
requests:
storage: 100Gi
...

九、Grafana仪表板配置
前面我们把监控和告警已经配置好了,那接下来就剩展示了。打开grafana -> 点击添加按钮 ->Import ->Upload .json file,导入监控仪表板。
{ "annotations": { "list": [ { "builtIn": 1, "datasource": "-- Grafana --", "enable": true, "hide": true, "iconColor": "rgba(0, 211, 255, 1)", "name": "Annotations & Alerts", "type": "dashboard" } ] }, "description": "This dashboard provides cluster admins with the ability to monitor nodes and identify workload bottlenecks. It can be deployed with PSPs enabled using the following helm chart - https://github.com/pivotal-cf/charts-grafana", "editable": true, "gnetId": 10000, "graphTooltip": 0, "id": 102, "iteration": 1597137794957, "links": [], "panels": [ { "collapsed": false, "datasource": null, "gridPos": { "h": 1, "w": 24, "x": 0, "y": 0 }, "id": 34, "panels": [], "repeat": null, "title": "Summary", "type": "row" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": true, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "editable": true, "error": false, "format": "percent", "gauge": { "maxValue": 100, "minValue": 0, "show": true, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 5, "w": 8, "x": 0, "y": 1 }, "height": "180px", "id": 4, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (container_memory_working_set_bytes{id=\"/\",kubernetes_io_hostname=~\"^$Node$\"}) / sum (machine_memory_bytes{kubernetes_io_hostname=~\"^$Node$\"}) * 100", "format": "time_series", "interval": "10s", "intervalFactor": 1, "refId": "A", "step": 10 } ], "thresholds": "65, 90", "title": "Cluster memory usage", "type": "singlestat", "valueFontSize": "80%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": true, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "percent", "gauge": { "maxValue": 100, "minValue": 0, "show": true, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 5, "w": 8, "x": 8, "y": 1 }, "height": "180px", "id": 6, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (rate (container_cpu_usage_seconds_total{id=\"/\",kubernetes_io_hostname=~\"^$Node$\"}[$interval])) / sum (machine_cpu_cores{kubernetes_io_hostname=~\"^$Node$\"}) * 100", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 10 } ], "thresholds": "65, 90", "title": "Cluster CPU usage", "type": "singlestat", "valueFontSize": "80%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": true, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "percent", "gauge": { "maxValue": 100, "minValue": 0, "show": true, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 5, "w": 8, "x": 16, "y": 1 }, "height": "180px", "id": 7, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (container_fs_usage_bytes{id=\"/\"}) / sum (container_fs_limit_bytes{id=\"/\"}) * 100", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "", "metric": "", "refId": "A", "step": 10 } ], "thresholds": "65, 90", "title": "Cluster filesystem usage", "type": "singlestat", "valueFontSize": "80%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": false, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "bytes", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 3, "w": 4, "x": 0, "y": 6 }, "height": "1px", "id": 9, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "20%", "prefix": "", "prefixFontSize": "20%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (container_memory_working_set_bytes{id=\"/\",kubernetes_io_hostname=~\"^$Node$\"})", "format": "time_series", "interval": "10s", "intervalFactor": 1, "refId": "A", "step": 10 } ], "thresholds": "", "title": "Used", "type": "singlestat", "valueFontSize": "50%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": false, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "bytes", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 3, "w": 4, "x": 4, "y": 6 }, "height": "1px", "id": 10, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (machine_memory_bytes{kubernetes_io_hostname=~\"^$Node$\"})", "format": "time_series", "interval": "10s", "intervalFactor": 1, "refId": "A", "step": 10 } ], "thresholds": "", "title": "Total", "type": "singlestat", "valueFontSize": "50%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": false, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "none", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 3, "w": 4, "x": 8, "y": 6 }, "height": "1px", "id": 11, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": " cores", "postfixFontSize": "30%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (rate (container_cpu_usage_seconds_total{id=\"/\",kubernetes_io_hostname=~\"^$Node$\"}[$interval]))", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 10 } ], "thresholds": "", "title": "Used", "type": "singlestat", "valueFontSize": "50%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": false, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "none", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 3, "w": 4, "x": 12, "y": 6 }, "height": "1px", "id": 12, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": " cores", "postfixFontSize": "30%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (machine_cpu_cores{kubernetes_io_hostname=~\"^$Node$\"})", "format": "time_series", "interval": "10s", "intervalFactor": 1, "refId": "A", "step": 10 } ], "thresholds": "", "title": "Total", "type": "singlestat", "valueFontSize": "50%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": false, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "bytes", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 3, "w": 4, "x": 16, "y": 6 }, "height": "1px", "id": 13, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (container_fs_usage_bytes{id=\"/\"})", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 10 } ], "thresholds": "", "title": "Used", "type": "singlestat", "valueFontSize": "50%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": false, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "format": "bytes", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 3, "w": 4, "x": 20, "y": 6 }, "height": "1px", "id": 14, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum (container_fs_limit_bytes{id=\"/\"})", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 10 } ], "thresholds": "", "title": "Total", "type": "singlestat", "valueFontSize": "50%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "collapsed": false, "datasource": null, "gridPos": { "h": 1, "w": 24, "x": 0, "y": 9 }, "id": 35, "panels": [], "repeat": null, "title": "Memory", "type": "row" }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "fill": 0, "fillGradient": 0, "grid": {}, "gridPos": { "h": 7, "w": 24, "x": 0, "y": 10 }, "id": 25, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": false, "max": false, "min": false, "rightSide": true, "show": true, "sideWidth": 200, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 1, "links": [], "nullPointMode": "connected", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": true, "steppedLine": false, "targets": [ { "expr": "sum (container_memory_working_set_bytes{image!=\"\",name=~\"^k8s_.*\",kubernetes_io_hostname=~\"^$Node$\"}) by (pod)", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "{{ pod }}", "metric": "container_memory_usage:sort_desc", "refId": "A", "step": 10 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Pods memory usage", "tooltip": { "msResolution": false, "shared": true, "sort": 2, "value_type": "cumulative" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "bytes", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "collapsed": false, "datasource": null, "gridPos": { "h": 1, "w": 24, "x": 0, "y": 17 }, "id": 37, "panels": [], "title": "CPU", "type": "row" }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 3, "editable": true, "error": false, "fill": 0, "fillGradient": 0, "grid": {}, "gridPos": { "h": 7, "w": 24, "x": 0, "y": 18 }, "height": "", "id": 17, "legend": { "alignAsTable": true, "avg": true, "current": true, "max": false, "min": false, "rightSide": true, "show": true, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 1, "links": [], "nullPointMode": "connected", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": true, "steppedLine": false, "targets": [ { "expr": "sum (rate (container_cpu_usage_seconds_total{image!=\"\",name=~\"^k8s_.*\",kubernetes_io_hostname=~\"^$Node$\"}[$interval])) by (pod)", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "{{ pod }}", "metric": "container_cpu", "refId": "A", "step": 10 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Pods CPU usage", "tooltip": { "msResolution": true, "shared": true, "sort": 2, "value_type": "cumulative" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "none", "label": "cores", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "collapsed": false, "datasource": null, "gridPos": { "h": 1, "w": 24, "x": 0, "y": 25 }, "id": 33, "panels": [], "repeat": null, "title": "Network I/O", "type": "row" }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "fill": 1, "fillGradient": 0, "grid": {}, "gridPos": { "h": 7, "w": 24, "x": 0, "y": 26 }, "id": 16, "legend": { "alignAsTable": true, "avg": true, "current": true, "max": false, "min": false, "rightSide": true, "show": true, "sideWidth": 200, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "connected", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "sum (rate (container_network_receive_bytes_total{image!=\"\",name=~\"^k8s_.*\",kubernetes_io_hostname=~\"^$Node$\"}[$interval])) by (pod)", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "-> {{ pod }}", "metric": "network", "refId": "A", "step": 10 }, { "expr": "- sum (rate (container_network_transmit_bytes_total{image!=\"\",name=~\"^k8s_.*\",kubernetes_io_hostname=~\"^$Node$\"}[$interval])) by (pod)", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "<- {{ pod }}", "metric": "network", "refId": "B", "step": 10 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Pods network I/O", "tooltip": { "msResolution": false, "shared": true, "sort": 2, "value_type": "cumulative" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "Bps", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "fill": 1, "fillGradient": 0, "grid": {}, "gridPos": { "h": 5, "w": 24, "x": 0, "y": 33 }, "height": "200px", "id": 32, "legend": { "alignAsTable": false, "avg": true, "current": true, "max": false, "min": false, "rightSide": false, "show": false, "sideWidth": 200, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "connected", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "sum (rate (container_network_receive_bytes_total{kubernetes_io_hostname=~\"^$Node$\"}[$interval]))", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "Received", "metric": "network", "refId": "A", "step": 10 }, { "expr": "- sum (rate (container_network_transmit_bytes_total{kubernetes_io_hostname=~\"^$Node$\"}[$interval]))", "format": "time_series", "interval": "10s", "intervalFactor": 1, "legendFormat": "Sent", "metric": "network", "refId": "B", "step": 10 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "Network I/O pressure", "tooltip": { "msResolution": false, "shared": true, "sort": 0, "value_type": "cumulative" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "Bps", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "Bps", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } } ], "refresh": "10s", "schemaVersion": 20, "style": "dark", "tags": [ "Prometheus", "Kubernetes" ], "templating": { "list": [ { "auto": true, "auto_count": 20, "auto_min": "2m", "current": { "text": "auto", "value": "$__auto_interval_interval" }, "hide": 2, "label": null, "name": "interval", "options": [ { "selected": true, "text": "auto", "value": "$__auto_interval_interval" }, { "selected": false, "text": "1m", "value": "1m" }, { "selected": false, "text": "10m", "value": "10m" }, { "selected": false, "text": "30m", "value": "30m" }, { "selected": false, "text": "1h", "value": "1h" }, { "selected": false, "text": "6h", "value": "6h" }, { "selected": false, "text": "12h", "value": "12h" }, { "selected": false, "text": "1d", "value": "1d" }, { "selected": false, "text": "7d", "value": "7d" }, { "selected": false, "text": "14d", "value": "14d" }, { "selected": false, "text": "30d", "value": "30d" } ], "query": "1m,10m,30m,1h,6h,12h,1d,7d,14d,30d", "refresh": 2, "skipUrlSync": false, "type": "interval" }, { "current": { "text": "prometheus", "value": "prometheus" }, "hide": 0, "includeAll": false, "label": null, "multi": false, "name": "datasource", "options": [], "query": "prometheus", "refresh": 1, "regex": "", "skipUrlSync": false, "type": "datasource" }, { "allValue": ".*", "current": { "text": "All", "value": "$__all" }, "datasource": "prometheus", "definition": "", "hide": 0, "includeAll": true, "label": null, "multi": false, "name": "Node", "options": [], "query": "label_values(kubernetes_io_hostname)", "refresh": 1, "regex": "", "skipUrlSync": false, "sort": 0, "tagValuesQuery": "", "tags": [], "tagsQuery": "", "type": "query", "useTags": false } ] }, "time": { "from": "now-5m", "to": "now" }, "timepicker": { "refresh_intervals": [ "5s", "10s", "30s", "1m", "5m", "15m", "30m", "1h", "2h", "1d" ], "time_options": [ "5m", "15m", "1h", "6h", "12h", "24h", "2d", "7d", "30d" ] }, "timezone": "browser", "title": "育苗通K8S集群监控", "uid": "6KoW2MIGk", "version": 15 }
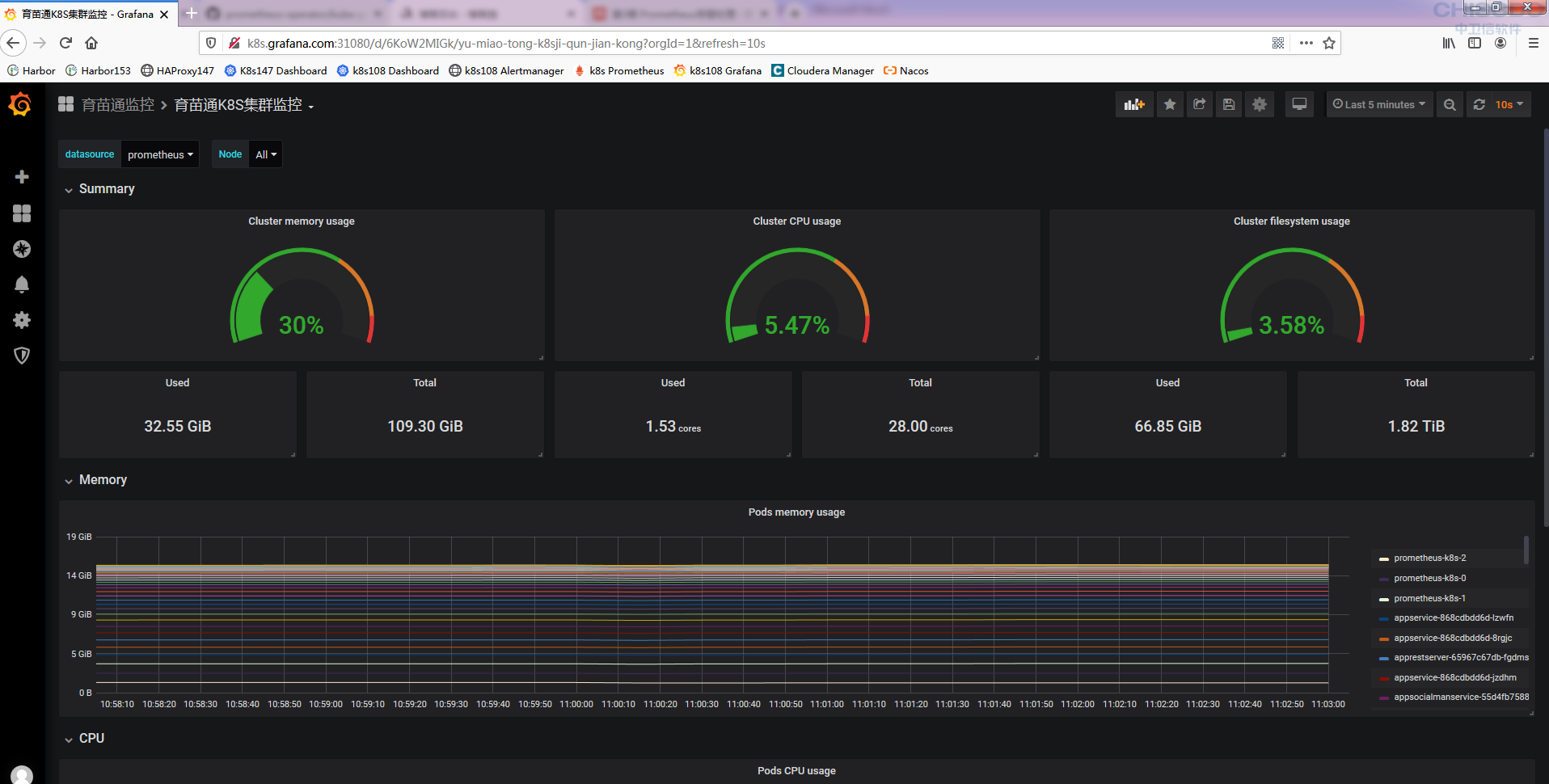
{ "annotations": { "list": [ { "builtIn": 1, "datasource": "-- Grafana --", "enable": true, "hide": true, "iconColor": "rgba(0, 211, 255, 1)", "name": "Annotations & Alerts", "type": "dashboard" } ] }, "description": "【中文版本】2020.06.28更新,增加整体资源展示!支持 Grafana6&7,Node Exporter v0.16及以上的版本,优化重要指标展示。包含整体资源展示与资源明细图表:CPU 内存 磁盘 IO 网络等监控指标。https://github.com/starsliao/Prometheus", "editable": true, "gnetId": 8919, "graphTooltip": 0, "id": 72, "iteration": 1597137684806, "links": [ { "icon": "external link", "tags": [], "targetBlank": true, "title": "更新node_exporter", "tooltip": "", "type": "link", "url": "https://github.com/prometheus/node_exporter/releases" }, { "icon": "external link", "tags": [], "targetBlank": true, "title": "更新当前仪表板", "tooltip": "", "type": "link", "url": "https://grafana.com/dashboards/8919" }, { "icon": "external link", "tags": [], "targetBlank": true, "title": "StarsL.cn", "tooltip": "", "type": "link", "url": "https://starsl.cn" }, { "asDropdown": true, "icon": "external link", "tags": [], "targetBlank": true, "title": "", "type": "dashboards" } ], "panels": [ { "collapsed": false, "datasource": "prometheus", "gridPos": { "h": 1, "w": 24, "x": 0, "y": 0 }, "id": 187, "panels": [], "title": "资源总览(关联JOB项)当前选中主机:【$show_hostname】实例:$node", "type": "row" }, { "columns": [], "datasource": "prometheus", "description": "分区使用率、磁盘读取、磁盘写入、下载带宽、上传带宽,如果有多个网卡或者多个分区,是采集的使用率最高的网卡或者分区的数值。", "fontSize": "100%", "gridPos": { "h": 12, "w": 24, "x": 0, "y": 1 }, "id": 185, "options": {}, "pageSize": 10, "showHeader": true, "sort": { "col": 5, "desc": false }, "styles": [ { "alias": "主机名", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 1, "link": false, "linkTooltip": "", "linkUrl": "", "mappingType": 1, "pattern": "nodename", "thresholds": [], "type": "string", "unit": "bytes" }, { "alias": "IP(链接到明细)", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "link": true, "linkTargetBlank": false, "linkTooltip": "浏览主机明细", "linkUrl": "/d/9CWBz0bik/node-exporter?orgId=1&var-job=${job}&var-hostname=All&var-node=${__cell}&var-device=All", "mappingType": 1, "pattern": "instance", "thresholds": [], "type": "number", "unit": "short" }, { "alias": "内存", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "link": false, "mappingType": 1, "pattern": "Value #B", "thresholds": [], "type": "number", "unit": "bytes" }, { "alias": "CPU核", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": null, "mappingType": 1, "pattern": "Value #C", "thresholds": [], "type": "number", "unit": "short" }, { "alias": " 运行时间", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #D", "thresholds": [], "type": "number", "unit": "s" }, { "alias": "分区使用率*", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #E", "thresholds": [ "70", "85" ], "type": "number", "unit": "percent" }, { "alias": "CPU使用率", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #F", "thresholds": [ "70", "85" ], "type": "number", "unit": "percent" }, { "alias": "内存使用率", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #G", "thresholds": [ "70", "85" ], "type": "number", "unit": "percent" }, { "alias": "磁盘读取*", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #H", "thresholds": [ "10485760", "20485760" ], "type": "number", "unit": "Bps" }, { "alias": "磁盘写入*", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #I", "thresholds": [ "10485760", "20485760" ], "type": "number", "unit": "Bps" }, { "alias": "下载带宽*", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #J", "thresholds": [ "30485760", "104857600" ], "type": "number", "unit": "bps" }, { "alias": "上传带宽*", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #K", "thresholds": [ "30485760", "104857600" ], "type": "number", "unit": "bps" }, { "alias": "5m负载", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "Value #L", "thresholds": [], "type": "number", "unit": "short" }, { "alias": "", "align": "right", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "decimals": 2, "pattern": "/.*/", "thresholds": [], "type": "hidden", "unit": "short" } ], "targets": [ { "expr": "node_uname_info{job=~\"$job\"} - 0", "format": "table", "instant": true, "interval": "", "legendFormat": "主机名", "refId": "A" }, { "expr": "sum(time() - node_boot_time_seconds{job=~\"$job\"})by(instance)", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "运行时间", "refId": "D" }, { "expr": "node_memory_MemTotal_bytes{job=~\"$job\"} - 0", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "总内存", "refId": "B" }, { "expr": "count(node_cpu_seconds_total{job=~\"$job\",mode='system'}) by (instance)", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "总核数", "refId": "C" }, { "expr": "node_load5{job=~\"$job\"}", "format": "table", "instant": true, "interval": "", "legendFormat": "5分钟负载", "refId": "L" }, { "expr": "(1 - avg(irate(node_cpu_seconds_total{job=~\"$job\",mode=\"idle\"}[5m])) by (instance)) * 100", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "CPU使用率", "refId": "F" }, { "expr": "(1 - (node_memory_MemAvailable_bytes{job=~\"$job\"} / (node_memory_MemTotal_bytes{job=~\"$job\"})))* 100", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "内存使用率", "refId": "G" }, { "expr": "max((node_filesystem_size_bytes{job=~\"$job\",fstype=~\"ext.?|xfs\"}-node_filesystem_free_bytes{job=~\"$job\",fstype=~\"ext.?|xfs\"}) *100/(node_filesystem_avail_bytes {job=~\"$job\",fstype=~\"ext.?|xfs\"}+(node_filesystem_size_bytes{job=~\"$job\",fstype=~\"ext.?|xfs\"}-node_filesystem_free_bytes{job=~\"$job\",fstype=~\"ext.?|xfs\"})))by(instance)", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "分区使用率", "refId": "E" }, { "expr": "max(irate(node_disk_read_bytes_total{job=~\"$job\"}[5m])) by (instance)", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "最大读取", "refId": "H" }, { "expr": "max(irate(node_disk_written_bytes_total{job=~\"$job\"}[5m])) by (instance)", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "最大写入", "refId": "I" }, { "expr": "max(irate(node_network_receive_bytes_total{job=~\"$job\"}[5m])*8) by (instance)", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "下载带宽", "refId": "J" }, { "expr": "max(irate(node_network_transmit_bytes_total{job=~\"$job\"}[5m])*8) by (instance)", "format": "table", "hide": false, "instant": true, "interval": "", "legendFormat": "上传带宽", "refId": "K" } ], "timeFrom": null, "timeShift": null, "title": "服务器资源总览表(每页10行)", "transform": "table", "type": "table" }, { "aliasColors": { "192.168.200.241:9100_Total": "dark-red", "Idle - Waiting for something to happen": "#052B51", "guest": "#9AC48A", "idle": "#052B51", "iowait": "#EAB839", "irq": "#BF1B00", "nice": "#C15C17", "sdb_每秒I/O操作%": "#d683ce", "softirq": "#E24D42", "steal": "#FCE2DE", "system": "#508642", "user": "#5195CE", "磁盘花费在I/O操作占比": "#ba43a9" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": null, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 8, "w": 8, "x": 0, "y": 13 }, "hiddenSeries": false, "id": 191, "legend": { "alignAsTable": false, "avg": false, "current": true, "hideEmpty": true, "hideZero": true, "max": false, "min": false, "rightSide": false, "show": true, "sideWidth": null, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "maxPerRow": 6, "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "repeat": null, "seriesOverrides": [ { "alias": "总平均使用率", "lines": false, "pointradius": 1, "points": true, "yaxis": 2 }, { "alias": "总核数", "color": "#C4162A" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "count(node_cpu_seconds_total{job=~\"$job\", mode='system'})", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "总核数", "refId": "B", "step": 240 }, { "expr": "sum(node_load5{job=~\"$job\"})", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "总5分钟负载", "refId": "A", "step": 240 }, { "expr": "avg(1 - avg(irate(node_cpu_seconds_total{job=~\"$job\",mode=\"idle\"}[5m])) by (instance)) * 100", "format": "time_series", "hide": false, "interval": "30m", "intervalFactor": 1, "legendFormat": "总平均使用率", "refId": "F", "step": 240 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "$job:整体总负载与整体平均CPU使用率", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": null, "format": "short", "label": "总负载", "logBase": 1, "max": null, "min": null, "show": true }, { "decimals": 0, "format": "percent", "label": "平均使用率", "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "192.168.200.241:9100_总内存": "dark-red", "内存_Avaliable": "#6ED0E0", "内存_Cached": "#EF843C", "内存_Free": "#629E51", "内存_Total": "#6d1f62", "内存_Used": "#eab839", "可用": "#9ac48a", "总内存": "#bf1b00" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 1, "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 8, "w": 8, "x": 8, "y": 13 }, "height": "300", "hiddenSeries": false, "id": 195, "legend": { "alignAsTable": false, "avg": false, "current": true, "max": false, "min": false, "rightSide": false, "show": true, "sort": "current", "sortDesc": false, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "总内存", "color": "#C4162A", "fill": 0 }, { "alias": "总平均使用率", "lines": false, "pointradius": 1, "points": true, "yaxis": 2 } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "sum(node_memory_MemTotal_bytes{job=~\"$job\"})", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "总内存", "refId": "A", "step": 4 }, { "expr": "sum(node_memory_MemTotal_bytes{job=~\"$job\"} - node_memory_MemAvailable_bytes{job=~\"$job\"})", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "总已用", "refId": "B", "step": 4 }, { "expr": "(sum(node_memory_MemTotal_bytes{job=~\"$job\"} - node_memory_MemAvailable_bytes{job=~\"$job\"}) / sum(node_memory_MemTotal_bytes{job=~\"$job\"}))*100", "format": "time_series", "hide": false, "interval": "30m", "intervalFactor": 1, "legendFormat": "总平均使用率", "refId": "H" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "$job:整体总内存与整体平均内存使用率", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": null, "format": "bytes", "label": "总内存量", "logBase": 1, "max": null, "min": "0", "show": true }, { "decimals": null, "format": "percent", "label": "平均使用率", "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 1, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 8, "w": 8, "x": 16, "y": 13 }, "hiddenSeries": false, "id": 197, "legend": { "alignAsTable": false, "avg": false, "current": true, "hideEmpty": false, "hideZero": false, "max": false, "min": false, "rightSide": false, "show": true, "sideWidth": null, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "总平均使用率", "lines": false, "pointradius": 1, "points": true, "yaxis": 2 }, { "alias": "总磁盘量", "color": "#C4162A" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "sum(avg(node_filesystem_size_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance))", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "总磁盘量", "refId": "E" }, { "expr": "sum(avg(node_filesystem_size_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance)) - sum(avg(node_filesystem_free_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance))", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "总使用量", "refId": "C" }, { "expr": "(sum(avg(node_filesystem_size_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance)) - sum(avg(node_filesystem_free_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance))) *100/(sum(avg(node_filesystem_avail_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance))+(sum(avg(node_filesystem_size_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance)) - sum(avg(node_filesystem_free_bytes{job=~\"$job\",fstype=~\"xfs|ext.*\"})by(device,instance))))", "format": "time_series", "instant": false, "interval": "30m", "intervalFactor": 1, "legendFormat": "总平均使用率", "refId": "A" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "$job:整体总磁盘与整体平均磁盘使用率", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": 1, "format": "bytes", "label": "总磁盘量", "logBase": 1, "max": null, "min": "0", "show": true }, { "decimals": null, "format": "percent", "label": "平均使用率", "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "collapsed": false, "datasource": "prometheus", "gridPos": { "h": 1, "w": 24, "x": 0, "y": 21 }, "id": 189, "panels": [], "title": "资源明细:【$show_hostname】", "type": "row" }, { "cacheTimeout": null, "colorBackground": false, "colorPostfix": false, "colorPrefix": false, "colorValue": true, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "datasource": "prometheus", "decimals": 0, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "format": "s", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "threshcisLabels": false, "threshcisMarkers": true }, "gridPos": { "h": 2, "w": 2, "x": 0, "y": 22 }, "hideTimeOverride": true, "id": 15, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "null", "nullText": null, "options": {}, "pluginVersion": "6.4.2", "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "avg(time() - node_boot_time_seconds{instance=~\"$node\"})", "format": "time_series", "hide": false, "instant": true, "interval": "", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 40 } ], "threshciss": "1,2", "thresholds": "1,3", "title": "运行时间", "type": "singlestat", "valueFontSize": "70%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "datasource": "prometheus", "fieldConfig": { "defaults": { "color": { "mode": "thresholds" }, "custom": {}, "decimals": 2, "displayName": "", "mappings": [ { "from": "", "id": 1, "operator": "", "text": "N/A", "to": "", "type": 1, "value": "0" } ], "max": 100, "min": 0, "thresholds": { "mode": "absolute", "steps": [ { "color": "green", "value": null }, { "color": "red", "value": 70 }, { "color": "#EAB839", "value": 90 } ] }, "unit": "percent" }, "overrides": [] }, "gridPos": { "h": 6, "w": 3, "x": 2, "y": 22 }, "id": 177, "options": { "displayMode": "lcd", "fieldOptions": { "calcs": [ "last" ], "defaults": { "decimals": 1, "mappings": [ { "from": "", "id": 1, "operator": "", "text": "N/A", "to": "", "type": 1, "value": "0" } ], "max": 100, "min": 0.1, "thresholds": { "0": { "color": "green", "value": null }, "1": { "color": "red", "value": 80 }, "mode": "absolute", "steps": [ { "color": "green", "value": null }, { "color": "#EAB839", "value": 70 }, { "color": "red", "value": 90 } ] }, "unit": "percent" }, "override": {}, "overrides": [], "values": false }, "orientation": "horizontal", "reduceOptions": { "calcs": [ "mean" ], "values": false }, "showUnfilled": true }, "pluginVersion": "6.4.3", "targets": [ { "expr": "100 - (avg(irate(node_cpu_seconds_total{instance=~\"$node\",mode=\"idle\"}[5m])) * 100)", "instant": true, "interval": "", "legendFormat": "总CPU使用率", "refId": "A" }, { "expr": "avg(irate(node_cpu_seconds_total{instance=~\"$node\",mode=\"iowait\"}[5m])) * 100", "hide": true, "instant": true, "interval": "", "legendFormat": "IOwait使用率", "refId": "C" }, { "expr": "(1 - (node_memory_MemAvailable_bytes{instance=~\"$node\"} / (node_memory_MemTotal_bytes{instance=~\"$node\"})))* 100", "instant": true, "interval": "", "legendFormat": "内存使用率", "refId": "B" }, { "expr": "(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint=\"$maxmount\"}-node_filesystem_free_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint=\"$maxmount\"})*100 /(node_filesystem_avail_bytes {instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint=\"$maxmount\"}+(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint=\"$maxmount\"}-node_filesystem_free_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint=\"$maxmount\"}))", "hide": false, "instant": true, "interval": "", "legendFormat": "最大分区({{mountpoint}})使用率", "refId": "D" }, { "expr": "(1 - ((node_memory_SwapFree_bytes{instance=~\"$node\"} + 1)/ (node_memory_SwapTotal_bytes{instance=~\"$node\"} + 1))) * 100", "instant": true, "legendFormat": "交换分区使用率", "refId": "F" } ], "timeFrom": null, "timeShift": null, "title": "", "type": "bargauge" }, { "columns": [], "datasource": "prometheus", "description": "本看板中的:磁盘总量、使用量、可用量、使用率保持和df命令的Size、Used、Avail、Use% 列的值一致,并且Use%的值会四舍五入保留一位小数,会更加准确。\n\n注:df中Use%算法为:(size - free) * 100 / (avail + (size - free)),结果是整除则为该值,非整除则为该值+1,结果的单位是%。\n参考df命令源码:", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fontSize": "100%", "gridPos": { "h": 6, "w": 10, "x": 5, "y": 22 }, "id": 181, "links": [ { "targetBlank": true, "title": "https://github.com/coreutils/coreutils/blob/master/src/df.c", "url": "https://github.com/coreutils/coreutils/blob/master/src/df.c" } ], "options": {}, "pageSize": null, "scroll": true, "showHeader": true, "sort": { "col": 6, "desc": false }, "styles": [ { "alias": "分区", "align": "auto", "colorMode": null, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "mappingType": 1, "pattern": "mountpoint", "thresholds": [ "" ], "type": "string", "unit": "bytes" }, { "alias": "可用空间", "align": "auto", "colorMode": "value", "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 1, "mappingType": 1, "pattern": "Value #A", "thresholds": [ "10000000000", "20000000000" ], "type": "number", "unit": "bytes" }, { "alias": "使用率", "align": "auto", "colorMode": "cell", "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "rgba(245, 54, 54, 0.9)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 1, "mappingType": 1, "pattern": "Value #B", "thresholds": [ "70", "85" ], "type": "number", "unit": "percent" }, { "alias": "总空间", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 0, "link": false, "mappingType": 1, "pattern": "Value #C", "thresholds": [], "type": "number", "unit": "bytes" }, { "alias": "文件系统", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "link": false, "mappingType": 1, "pattern": "fstype", "thresholds": [], "type": "string", "unit": "short" }, { "alias": "设备名", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "dateFormat": "YYYY-MM-DD HH:mm:ss", "decimals": 2, "link": false, "mappingType": 1, "pattern": "device", "preserveFormat": false, "sanitize": false, "thresholds": [], "type": "string", "unit": "short" }, { "alias": "", "align": "auto", "colorMode": null, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "decimals": 2, "pattern": "/.*/", "preserveFormat": true, "sanitize": false, "thresholds": [], "type": "hidden", "unit": "short" } ], "targets": [ { "expr": "node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}-0", "format": "table", "hide": false, "instant": true, "interval": "", "intervalFactor": 1, "legendFormat": "总量", "refId": "C" }, { "expr": "node_filesystem_avail_bytes {instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}-0", "format": "table", "hide": false, "instant": true, "interval": "10s", "intervalFactor": 1, "legendFormat": "", "refId": "A" }, { "expr": "(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}-node_filesystem_free_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}) *100/(node_filesystem_avail_bytes {instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}+(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}-node_filesystem_free_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}))", "format": "table", "hide": false, "instant": true, "interval": "", "intervalFactor": 1, "legendFormat": "", "refId": "B" } ], "title": "【$show_hostname】:各分区可用空间(EXT.*/XFS)", "transform": "table", "type": "table" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": true, "colors": [ "rgba(50, 172, 45, 0.97)", "rgba(237, 129, 40, 0.89)", "#d44a3a" ], "datasource": "prometheus", "decimals": 2, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "format": "percent", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 2, "w": 2, "x": 15, "y": 22 }, "id": 20, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "nullPointMode": "connected", "nullText": null, "options": {}, "pluginVersion": "6.4.2", "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": true, "lineColor": "#3274D9", "show": true, "ymax": null, "ymin": null }, "tableColumn": "", "targets": [ { "expr": "avg(irate(node_cpu_seconds_total{instance=~\"$node\",mode=\"iowait\"}[5m])) * 100", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 20 } ], "thresholds": "20,50", "timeFrom": null, "timeShift": null, "title": "CPU iowait", "type": "singlestat", "valueFontSize": "80%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "avg" }, { "aliasColors": { "cn-shenzhen.i-wz9cq1dcb6zwc39ehw59_cni0_in": "light-red", "cn-shenzhen.i-wz9cq1dcb6zwc39ehw59_cni0_in下载": "green", "cn-shenzhen.i-wz9cq1dcb6zwc39ehw59_cni0_out上传": "yellow", "cn-shenzhen.i-wz9cq1dcb6zwc39ehw59_eth0_in下载": "purple", "cn-shenzhen.i-wz9cq1dcb6zwc39ehw59_eth0_out": "purple", "cn-shenzhen.i-wz9cq1dcb6zwc39ehw59_eth0_out上传": "blue" }, "bars": true, "dashLength": 10, "dashes": false, "datasource": "prometheus", "editable": true, "error": false, "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 0, "grid": {}, "gridPos": { "h": 6, "w": 7, "x": 17, "y": 22 }, "hiddenSeries": false, "id": 183, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": false, "show": false, "sort": "current", "sortDesc": true, "total": true, "values": true }, "lines": false, "linewidth": 2, "links": [], "nullPointMode": "null as zero", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 1, "points": false, "renderer": "flot", "repeat": null, "seriesOverrides": [ { "alias": "/.*_out上传$/", "transform": "negative-Y" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "increase(node_network_receive_bytes_total{instance=~\"$node\",device=~\"$device\"}[60m])", "interval": "60m", "intervalFactor": 1, "legendFormat": "{{device}}_in下载", "metric": "", "refId": "A", "step": 600, "target": "" }, { "expr": "increase(node_network_transmit_bytes_total{instance=~\"$node\",device=~\"$device\"}[60m])", "hide": false, "interval": "60m", "intervalFactor": 1, "legendFormat": "{{device}}_out上传", "refId": "B", "step": 600 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "每小时流量$device", "tooltip": { "msResolution": false, "shared": true, "sort": 0, "value_type": "cumulative" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "bytes", "label": "上传(-)/下载(+)", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "cacheTimeout": null, "colorBackground": false, "colorPostfix": false, "colorValue": true, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "datasource": "prometheus", "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "format": "short", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 2, "w": 2, "x": 0, "y": 24 }, "id": 14, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "maxPerRow": 6, "nullPointMode": "null", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "count(node_cpu_seconds_total{instance=~\"$node\", mode='system'})", "format": "time_series", "instant": true, "interval": "", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 20 } ], "thresholds": "1,2", "title": "CPU 核数", "type": "singlestat", "valueFontSize": "80%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorPostfix": false, "colorValue": true, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "datasource": "prometheus", "decimals": null, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "format": "short", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 2, "w": 2, "x": 15, "y": 24 }, "id": 179, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "maxPerRow": 6, "nullPointMode": "null", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "avg(node_filesystem_files_free{instance=~\"$node\",mountpoint=\"$maxmount\",fstype=~\"ext.?|xfs\"})", "format": "time_series", "instant": true, "interval": "", "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 20 } ], "thresholds": "100000,1000000", "title": "剩余节点数:$maxmount ", "type": "singlestat", "valueFontSize": "70%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorValue": true, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "datasource": "prometheus", "decimals": 0, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "format": "bytes", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 2, "w": 2, "x": 0, "y": 26 }, "id": 75, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "maxPerRow": 6, "nullPointMode": "null", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "70%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "sum(node_memory_MemTotal_bytes{instance=~\"$node\"})", "format": "time_series", "instant": true, "interval": "", "intervalFactor": 1, "legendFormat": "{{instance}}", "refId": "A", "step": 20 } ], "thresholds": "2,3", "title": "总内存", "type": "singlestat", "valueFontSize": "80%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "cacheTimeout": null, "colorBackground": false, "colorPostfix": false, "colorValue": true, "colors": [ "rgba(245, 54, 54, 0.9)", "rgba(237, 129, 40, 0.89)", "rgba(50, 172, 45, 0.97)" ], "datasource": "prometheus", "decimals": null, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "format": "locale", "gauge": { "maxValue": 100, "minValue": 0, "show": false, "thresholdLabels": false, "thresholdMarkers": true }, "gridPos": { "h": 2, "w": 2, "x": 15, "y": 26 }, "id": 178, "interval": null, "links": [], "mappingType": 1, "mappingTypes": [ { "name": "value to text", "value": 1 }, { "name": "range to text", "value": 2 } ], "maxDataPoints": 100, "maxPerRow": 6, "nullPointMode": "null", "nullText": null, "options": {}, "postfix": "", "postfixFontSize": "50%", "prefix": "", "prefixFontSize": "50%", "rangeMaps": [ { "from": "null", "text": "N/A", "to": "null" } ], "sparkline": { "fillColor": "rgba(31, 118, 189, 0.18)", "full": false, "lineColor": "rgb(31, 120, 193)", "show": false }, "tableColumn": "", "targets": [ { "expr": "avg(node_filefd_maximum{instance=~\"$node\"})", "format": "time_series", "instant": true, "intervalFactor": 1, "legendFormat": "", "refId": "A", "step": 20 } ], "thresholds": "1024,10000", "title": "总文件描述符", "type": "singlestat", "valueFontSize": "70%", "valueMaps": [ { "op": "=", "text": "N/A", "value": "null" } ], "valueName": "current" }, { "aliasColors": { "192.168.200.241:9100_Total": "dark-red", "Idle - Waiting for something to happen": "#052B51", "guest": "#9AC48A", "idle": "#052B51", "iowait": "#EAB839", "irq": "#BF1B00", "nice": "#C15C17", "sdb_每秒I/O操作%": "#d683ce", "softirq": "#E24D42", "steal": "#FCE2DE", "system": "#508642", "user": "#5195CE", "磁盘花费在I/O操作占比": "#ba43a9" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 8, "w": 8, "x": 0, "y": 28 }, "hiddenSeries": false, "id": 7, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "rightSide": false, "show": true, "sideWidth": null, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "maxPerRow": 6, "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "repeat": null, "seriesOverrides": [ { "alias": "/.*总使用率/", "color": "#C4162A", "fill": 0 } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "avg(irate(node_cpu_seconds_total{instance=~\"$node\",mode=\"system\"}[5m])) by (instance) *100", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "系统使用率", "refId": "A", "step": 20 }, { "expr": "avg(irate(node_cpu_seconds_total{instance=~\"$node\",mode=\"user\"}[5m])) by (instance) *100", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "用户使用率", "refId": "B", "step": 240 }, { "expr": "avg(irate(node_cpu_seconds_total{instance=~\"$node\",mode=\"iowait\"}[5m])) by (instance) *100", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "磁盘IO使用率", "refId": "D", "step": 240 }, { "expr": "(1 - avg(irate(node_cpu_seconds_total{instance=~\"$node\",mode=\"idle\"}[5m])) by (instance))*100", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "总使用率", "refId": "F", "step": 240 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "CPU使用率", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": 0, "format": "percent", "label": "", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "192.168.200.241:9100_总内存": "dark-red", "使用率": "yellow", "内存_Avaliable": "#6ED0E0", "内存_Cached": "#EF843C", "内存_Free": "#629E51", "内存_Total": "#6d1f62", "内存_Used": "#eab839", "可用": "#9ac48a", "总内存": "#bf1b00" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 8, "w": 8, "x": 8, "y": 28 }, "height": "300", "hiddenSeries": false, "id": 156, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "rightSide": false, "show": true, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "总内存", "color": "#C4162A", "fill": 0 }, { "alias": "使用率", "color": "rgb(0, 209, 255)", "lines": false, "pointradius": 1, "points": true, "yaxis": 2 } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "node_memory_MemTotal_bytes{instance=~\"$node\"}", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "总内存", "refId": "A", "step": 4 }, { "expr": "node_memory_MemTotal_bytes{instance=~\"$node\"} - node_memory_MemAvailable_bytes{instance=~\"$node\"}", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "已用", "refId": "B", "step": 4 }, { "expr": "node_memory_MemAvailable_bytes{instance=~\"$node\"}", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "可用", "refId": "F", "step": 4 }, { "expr": "node_memory_Buffers_bytes{instance=~\"$node\"}", "format": "time_series", "hide": true, "intervalFactor": 1, "legendFormat": "内存_Buffers", "refId": "D", "step": 4 }, { "expr": "node_memory_MemFree_bytes{instance=~\"$node\"}", "format": "time_series", "hide": true, "intervalFactor": 1, "legendFormat": "内存_Free", "refId": "C", "step": 4 }, { "expr": "node_memory_Cached_bytes{instance=~\"$node\"}", "format": "time_series", "hide": true, "intervalFactor": 1, "legendFormat": "内存_Cached", "refId": "E", "step": 4 }, { "expr": "node_memory_MemTotal_bytes{instance=~\"$node\"} - (node_memory_Cached_bytes{instance=~\"$node\"} + node_memory_Buffers_bytes{instance=~\"$node\"} + node_memory_MemFree_bytes{instance=~\"$node\"})", "format": "time_series", "hide": true, "intervalFactor": 1, "refId": "G" }, { "expr": "(1 - (node_memory_MemAvailable_bytes{instance=~\"$node\"} / (node_memory_MemTotal_bytes{instance=~\"$node\"})))* 100", "format": "time_series", "hide": false, "interval": "30m", "intervalFactor": 10, "legendFormat": "使用率", "refId": "H" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "内存信息", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "bytes", "label": null, "logBase": 1, "max": null, "min": "0", "show": true }, { "format": "percent", "label": "内存使用率", "logBase": 1, "max": "100", "min": "0", "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "192.168.10.227:9100_em1_in下载": "super-light-green", "192.168.10.227:9100_em1_out上传": "dark-blue" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 8, "w": 8, "x": 16, "y": 28 }, "height": "300", "hiddenSeries": false, "id": 157, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "rightSide": false, "show": true, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 1, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 2, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "/.*_out上传$/", "transform": "negative-Y" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "irate(node_network_receive_bytes_total{instance=~'$node',device=~\"$device\"}[5m])*8", "format": "time_series", "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_in下载", "refId": "A", "step": 4 }, { "expr": "irate(node_network_transmit_bytes_total{instance=~'$node',device=~\"$device\"}[5m])*8", "format": "time_series", "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_out上传", "refId": "B", "step": 4 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "每秒网络带宽使用$device", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "bps", "label": "上传(-)/下载(+)", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "15分钟": "#6ED0E0", "1分钟": "#BF1B00", "5分钟": "#CCA300" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "editable": true, "error": false, "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 1, "grid": {}, "gridPos": { "h": 8, "w": 8, "x": 0, "y": 36 }, "height": "300", "hiddenSeries": false, "id": 13, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "rightSide": false, "show": true, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "maxPerRow": 6, "nullPointMode": "null as zero", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "repeat": null, "seriesOverrides": [ { "alias": "/.*总核数/", "color": "#C4162A" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "node_load1{instance=~\"$node\"}", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "1分钟负载", "metric": "", "refId": "A", "step": 20, "target": "" }, { "expr": "node_load5{instance=~\"$node\"}", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "5分钟负载", "refId": "B", "step": 20 }, { "expr": "node_load15{instance=~\"$node\"}", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "15分钟负载", "refId": "C", "step": 20 }, { "expr": " sum(count(node_cpu_seconds_total{instance=~\"$node\", mode='system'}) by (cpu,instance)) by(instance)", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "CPU总核数", "refId": "D", "step": 20 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "系统平均负载", "tooltip": { "msResolution": false, "shared": true, "sort": 2, "value_type": "cumulative" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "vda_write": "#6ED0E0" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "description": "Read bytes 每个磁盘分区每秒读取的比特数\nWritten bytes 每个磁盘分区每秒写入的比特数", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 1, "gridPos": { "h": 8, "w": 8, "x": 8, "y": 36 }, "height": "300", "hiddenSeries": false, "id": 168, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "show": true, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "/.*_读取$/", "transform": "negative-Y" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "irate(node_disk_read_bytes_total{instance=~\"$node\"}[5m])", "format": "time_series", "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_读取", "refId": "A", "step": 10 }, { "expr": "irate(node_disk_written_bytes_total{instance=~\"$node\"}[5m])", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_写入", "refId": "B", "step": 10 } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "每秒磁盘读写容量", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": null, "format": "Bps", "label": "读取(-)/写入(+)", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": {}, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 1, "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 8, "w": 8, "x": 16, "y": 36 }, "hiddenSeries": false, "id": 174, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "rightSide": false, "show": true, "sideWidth": null, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "/Inodes.*/", "yaxis": 2 } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}-node_filesystem_free_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}) *100/(node_filesystem_avail_bytes {instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}+(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}-node_filesystem_free_bytes{instance=~'$node',fstype=~\"ext.*|xfs\",mountpoint !~\".*pod.*\"}))", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "{{mountpoint}}", "refId": "A" }, { "expr": "node_filesystem_files_free{instance=~'$node',fstype=~\"ext.?|xfs\"} / node_filesystem_files{instance=~'$node',fstype=~\"ext.?|xfs\"}", "hide": true, "interval": "", "legendFormat": "Inodes:{{instance}}:{{mountpoint}}", "refId": "B" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "磁盘使用率", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": null, "format": "percent", "label": "", "logBase": 1, "max": "100", "min": "0", "show": true }, { "decimals": 2, "format": "percentunit", "label": null, "logBase": 1, "max": "1", "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "vda_write": "#6ED0E0" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "description": "Reads completed: 每个磁盘分区每秒读完成次数\n\nWrites completed: 每个磁盘分区每秒写完成次数\n\nIO now 每个磁盘分区每秒正在处理的输入/输出请求数", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 9, "w": 8, "x": 0, "y": 44 }, "height": "300", "hiddenSeries": false, "id": 161, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "show": true, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 1, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "/.*_读取$/", "transform": "negative-Y" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "irate(node_disk_reads_completed_total{instance=~\"$node\"}[5m])", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_读取", "refId": "A", "step": 10 }, { "expr": "irate(node_disk_writes_completed_total{instance=~\"$node\"}[5m])", "format": "time_series", "hide": false, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_写入", "refId": "B", "step": 10 }, { "expr": "node_disk_io_now{instance=~\"$node\"}", "format": "time_series", "hide": true, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}", "refId": "C" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "磁盘读写速率(IOPS)", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": null, "format": "iops", "label": "读取(-)/写入(+)I/O ops/sec", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "Idle - Waiting for something to happen": "#052B51", "guest": "#9AC48A", "idle": "#052B51", "iowait": "#EAB839", "irq": "#BF1B00", "nice": "#C15C17", "sdb_每秒I/O操作%": "#d683ce", "softirq": "#E24D42", "steal": "#FCE2DE", "system": "#508642", "user": "#5195CE", "磁盘花费在I/O操作占比": "#ba43a9" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": null, "description": "每一秒钟的自然时间内,花费在I/O上的耗时。(wall-clock time)\n\nnode_disk_io_time_seconds_total:\n磁盘花费在输入/输出操作上的秒数。该值为累加值。(Milliseconds Spent Doing I/Os)\n\nirate(node_disk_io_time_seconds_total[1m]):\n计算每秒的速率:(last值-last前一个值)/时间戳差值,即:1秒钟内磁盘花费在I/O操作的时间占比。", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 0, "gridPos": { "h": 9, "w": 8, "x": 8, "y": 44 }, "hiddenSeries": false, "id": 175, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": false, "rightSide": false, "show": true, "sideWidth": null, "sort": null, "sortDesc": null, "total": false, "values": true }, "lines": true, "linewidth": 1, "links": [], "maxPerRow": 6, "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "irate(node_disk_io_time_seconds_total{instance=~\"$node\"}[5m])", "format": "time_series", "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_每秒I/O操作%", "refId": "C" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "每1秒内I/O操作耗时占比", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "decimals": null, "format": "percentunit", "label": "", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "vda": "#6ED0E0" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "description": "Read time seconds 每个磁盘分区读操作花费的秒数\n\nWrite time seconds 每个磁盘分区写操作花费的秒数\n\nIO time seconds 每个磁盘分区输入/输出操作花费的秒数\n\nIO time weighted seconds每个磁盘分区输入/输出操作花费的加权秒数", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 1, "fillGradient": 1, "gridPos": { "h": 9, "w": 8, "x": 16, "y": 44 }, "height": "300", "hiddenSeries": false, "id": 160, "legend": { "alignAsTable": true, "avg": true, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": true, "show": true, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "null as zero", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "/,*_读取$/", "transform": "negative-Y" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "irate(node_disk_read_time_seconds_total{instance=~\"$node\"}[5m]) / irate(node_disk_reads_completed_total{instance=~\"$node\"}[5m])", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_读取", "refId": "B" }, { "expr": "irate(node_disk_write_time_seconds_total{instance=~\"$node\"}[5m]) / irate(node_disk_writes_completed_total{instance=~\"$node\"}[5m])", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_写入", "refId": "C" }, { "expr": "irate(node_disk_io_time_seconds_total{instance=~\"$node\"}[5m])", "format": "time_series", "hide": true, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}", "refId": "A", "step": 10 }, { "expr": "irate(node_disk_io_time_weighted_seconds_total{instance=~\"$node\"}[5m])", "format": "time_series", "hide": true, "interval": "", "intervalFactor": 1, "legendFormat": "{{device}}_加权", "refId": "D" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "每次IO读写的耗时(参考:小于100ms)(beta)", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "s", "label": "读取(-)/写入(+)", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": false } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "192.168.200.241:9100_TCP_alloc": "semi-dark-blue", "TCP": "#6ED0E0", "TCP_alloc": "blue" }, "bars": false, "dashLength": 10, "dashes": false, "datasource": "prometheus", "decimals": 2, "description": "Sockets_used - 已使用的所有协议套接字总量\n\nCurrEstab - 当前状态为 ESTABLISHED 或 CLOSE-WAIT 的 TCP 连接数\n\nTCP_alloc - 已分配(已建立、已申请到sk_buff)的TCP套接字数量\n\nTCP_tw - 等待关闭的TCP连接数\n\nUDP_inuse - 正在使用的 UDP 套接字数量\n\nRetransSegs - TCP 重传报文数\n\nOutSegs - TCP 发送的报文数\n\nInSegs - TCP 接收的报文数", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 0, "fillGradient": 0, "gridPos": { "h": 8, "w": 16, "x": 0, "y": 53 }, "height": "300", "hiddenSeries": false, "id": 158, "interval": "", "legend": { "alignAsTable": true, "avg": false, "current": true, "hideEmpty": true, "hideZero": true, "max": true, "min": false, "rightSide": true, "show": true, "sideWidth": null, "sort": "current", "sortDesc": true, "total": false, "values": true }, "lines": true, "linewidth": 1, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pointradius": 5, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "/.*Sockets_used/", "color": "#E02F44", "lines": false, "pointradius": 1, "points": true, "yaxis": 2 } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "node_netstat_Tcp_CurrEstab{instance=~'$node'}", "format": "time_series", "hide": false, "instant": false, "interval": "", "intervalFactor": 1, "legendFormat": "CurrEstab", "refId": "A", "step": 20 }, { "expr": "node_sockstat_TCP_tw{instance=~'$node'}", "format": "time_series", "interval": "", "intervalFactor": 1, "legendFormat": "TCP_tw", "refId": "D" }, { "expr": "node_sockstat_sockets_used{instance=~'$node'}", "hide": false, "interval": "30m", "intervalFactor": 1, "legendFormat": "Sockets_used", "refId": "B" }, { "expr": "node_sockstat_UDP_inuse{instance=~'$node'}", "interval": "", "legendFormat": "UDP_inuse", "refId": "C" }, { "expr": "node_sockstat_TCP_alloc{instance=~'$node'}", "interval": "", "legendFormat": "TCP_alloc", "refId": "E" }, { "expr": "irate(node_netstat_Tcp_PassiveOpens{instance=~'$node'}[5m])", "hide": true, "interval": "", "legendFormat": "{{instance}}_Tcp_PassiveOpens", "refId": "G" }, { "expr": "irate(node_netstat_Tcp_ActiveOpens{instance=~'$node'}[5m])", "hide": true, "interval": "", "legendFormat": "{{instance}}_Tcp_ActiveOpens", "refId": "F" }, { "expr": "irate(node_netstat_Tcp_InSegs{instance=~'$node'}[5m])", "interval": "", "legendFormat": "Tcp_InSegs", "refId": "H" }, { "expr": "irate(node_netstat_Tcp_OutSegs{instance=~'$node'}[5m])", "interval": "", "legendFormat": "Tcp_OutSegs", "refId": "I" }, { "expr": "irate(node_netstat_Tcp_RetransSegs{instance=~'$node'}[5m])", "hide": false, "interval": "", "legendFormat": "Tcp_RetransSegs", "refId": "J" }, { "expr": "irate(node_netstat_TcpExt_ListenDrops{instance=~'$node'}[5m])", "hide": true, "interval": "", "legendFormat": "", "refId": "K" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "网络Socket连接信息", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "transformations": [], "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": null, "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": "已使用的所有协议套接字总量", "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } }, { "aliasColors": { "filefd_192.168.200.241:9100": "super-light-green", "switches_192.168.200.241:9100": "semi-dark-red", "使用的文件描述符_10.118.72.128:9100": "red", "每秒上下文切换次数_10.118.71.245:9100": "yellow", "每秒上下文切换次数_10.118.72.128:9100": "yellow" }, "bars": false, "cacheTimeout": null, "dashLength": 10, "dashes": false, "datasource": "prometheus", "description": "", "fieldConfig": { "defaults": { "custom": {} }, "overrides": [] }, "fill": 0, "fillGradient": 1, "gridPos": { "h": 8, "w": 8, "x": 16, "y": 53 }, "hiddenSeries": false, "hideTimeOverride": false, "id": 16, "legend": { "alignAsTable": false, "avg": false, "current": true, "max": false, "min": false, "rightSide": false, "show": true, "total": false, "values": true }, "lines": true, "linewidth": 2, "links": [], "nullPointMode": "null", "options": { "dataLinks": [] }, "percentage": false, "pluginVersion": "6.4.2", "pointradius": 1, "points": false, "renderer": "flot", "seriesOverrides": [ { "alias": "/每秒上下文切换次数.*/", "color": "#FADE2A", "lines": false, "pointradius": 1, "points": true, "yaxis": 2 }, { "alias": "/使用的文件描述符.*/", "color": "#F2495C" } ], "spaceLength": 10, "stack": false, "steppedLine": false, "targets": [ { "expr": "node_filefd_allocated{instance=~\"$node\"}", "format": "time_series", "instant": false, "interval": "", "intervalFactor": 5, "legendFormat": "使用的文件描述符", "refId": "B" }, { "expr": "irate(node_context_switches_total{instance=~\"$node\"}[5m])", "interval": "", "intervalFactor": 5, "legendFormat": "每秒上下文切换次数", "refId": "A" }, { "expr": " (node_filefd_allocated{instance=~\"$node\"}/node_filefd_maximum{instance=~\"$node\"}) *100", "format": "time_series", "hide": true, "instant": false, "interval": "", "intervalFactor": 5, "legendFormat": "使用的文件描述符占比_{{instance}}", "refId": "C" } ], "thresholds": [], "timeFrom": null, "timeRegions": [], "timeShift": null, "title": "打开的文件描述符(左 )/每秒上下文切换次数(右)", "tooltip": { "shared": true, "sort": 2, "value_type": "individual" }, "type": "graph", "xaxis": { "buckets": null, "mode": "time", "name": null, "show": true, "values": [] }, "yaxes": [ { "format": "short", "label": "使用的文件描述符", "logBase": 1, "max": null, "min": null, "show": true }, { "format": "short", "label": "context_switches", "logBase": 1, "max": null, "min": null, "show": true } ], "yaxis": { "align": false, "alignLevel": null } } ], "refresh": "", "schemaVersion": 20, "style": "dark", "tags": [ "Prometheus", "node_exporter" ], "templating": { "list": [ { "allValue": null, "current": { "tags": [], "text": "node-exporter", "value": "node-exporter" }, "datasource": "prometheus", "definition": "label_values(node_uname_info, job)", "hide": 0, "includeAll": false, "index": -1, "label": "JOB", "multi": false, "name": "job", "options": [], "query": "label_values(node_uname_info, job)", "refresh": 1, "regex": "", "skipUrlSync": false, "sort": 5, "tagValuesQuery": "", "tags": [], "tagsQuery": "", "type": "query", "useTags": false }, { "allValue": null, "current": { "text": "All", "value": "$__all" }, "datasource": "prometheus", "definition": "label_values(node_uname_info{job=~\"$job\"}, nodename)", "hide": 0, "includeAll": true, "index": -1, "label": "主机名", "multi": false, "name": "hostname", "options": [], "query": "label_values(node_uname_info{job=~\"$job\"}, nodename)", "refresh": 1, "regex": "", "skipUrlSync": false, "sort": 5, "tagValuesQuery": "", "tags": [], "tagsQuery": "", "type": "query", "useTags": false }, { "allFormat": "glob", "allValue": null, "current": { "text": "ymt108", "value": "ymt108" }, "datasource": "prometheus", "definition": "label_values(node_uname_info{job=~\"$job\",nodename=~\"$hostname\"},instance)", "hide": 0, "includeAll": false, "index": -1, "label": "Instance", "multi": true, "multiFormat": "regex values", "name": "node", "options": [], "query": "label_values(node_uname_info{job=~\"$job\",nodename=~\"$hostname\"},instance)", "refresh": 1, "regex": "", "skipUrlSync": false, "sort": 5, "tagValuesQuery": "", "tags": [], "tagsQuery": "", "type": "query", "useTags": false }, { "allFormat": "glob", "allValue": null, "current": { "text": "All", "value": "$__all" }, "datasource": "prometheus", "definition": "label_values(node_network_info{device!~'tap.*|veth.*|br.*|docker.*|virbr.*|lo.*|cni.*'},device)", "hide": 0, "includeAll": true, "index": -1, "label": "网卡", "multi": true, "multiFormat": "regex values", "name": "device", "options": [], "query": "label_values(node_network_info{device!~'tap.*|veth.*|br.*|docker.*|virbr.*|lo.*|cni.*'},device)", "refresh": 1, "regex": "", "skipUrlSync": false, "sort": 1, "tagValuesQuery": "", "tags": [], "tagsQuery": "", "type": "query", "useTags": false }, { "allValue": null, "current": { "text": "/", "value": "/" }, "datasource": "prometheus", "definition": "query_result(topk(1,sort_desc (max(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.?|xfs\",mountpoint!~\".*pods.*\"}) by (mountpoint))))", "hide": 2, "includeAll": false, "index": -1, "label": "最大挂载目录", "multi": false, "name": "maxmount", "options": [], "query": "query_result(topk(1,sort_desc (max(node_filesystem_size_bytes{instance=~'$node',fstype=~\"ext.?|xfs\",mountpoint!~\".*pods.*\"}) by (mountpoint))))", "refresh": 2, "regex": "/.*\\\"(.*)\\\".*/", "skipUrlSync": false, "sort": 5, "tagValuesQuery": "", "tags": [], "tagsQuery": "", "type": "query", "useTags": false }, { "allValue": null, "current": { "text": "ymt108", "value": "ymt108" }, "datasource": "prometheus", "definition": "label_values(node_uname_info{job=~\"$job\",instance=~\"$node\"}, nodename)", "hide": 2, "includeAll": false, "index": -1, "label": "展示使用的主机名", "multi": false, "name": "show_hostname", "options": [], "query": "label_values(node_uname_info{job=~\"$job\",instance=~\"$node\"}, nodename)", "refresh": 1, "regex": "", "skipUrlSync": false, "sort": 5, "tagValuesQuery": "", "tags": [], "tagsQuery": "", "type": "query", "useTags": false } ] }, "time": { "from": "now-12h", "to": "now" }, "timepicker": { "hidden": false, "now": true, "refresh_intervals": [ "15s", "30s", "1m", "5m", "15m", "30m" ], "time_options": [ "5m", "15m", "1h", "6h", "12h", "24h", "2d", "7d", "30d" ] }, "timezone": "browser", "title": "育苗通Node资源监控", "uid": "hb7fSE0Zz", "version": 11 }
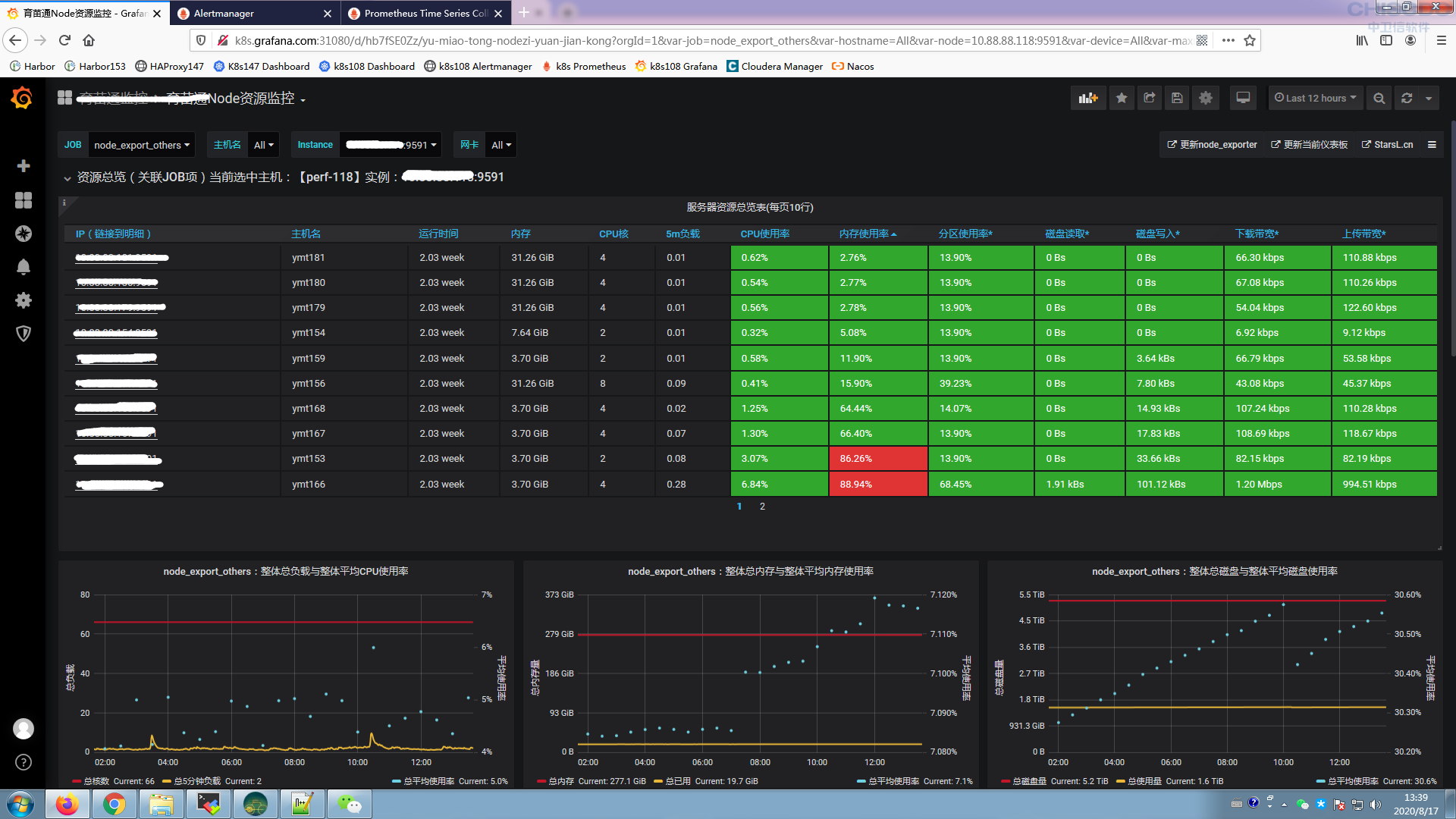
当然,默认还内置了很多k8s相关的资源监控模板。
更多监控模板:https://grafana.com/grafana/dashboards
九、汇总
特殊说明1:我们还可以自定义etcd监控,详情可参考:https://www.jianshu.com/p/2fbbe767870d
- 第一步:建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项;
- 第二步:为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象;
- 第三步:确保 Service 对象可以正确获取到 metrics 数据。
特殊说明2:部署kube-prometheus可能会出现无法连接apiserver问题,详情可参考:【解决】Error from server (ServiceUnavailable): the server is currently unable to handle the request
当我们完成了所有配置, 那接下来还需要整理一下,编写升级脚本upgrade.sh,方便之后部署,以及修改更新。
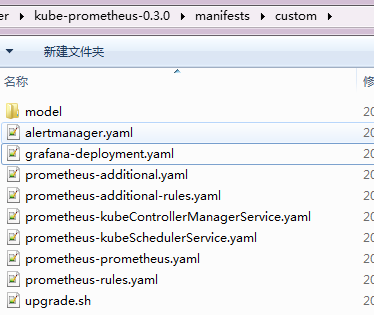
#!/bin/sh # deploy kubernetes service kubectl apply -f prometheus-kubeControllerManagerService.yaml kubectl apply -f prometheus-kubeSchedulerService.yaml # upgrade alertmanager configuration kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring --dry-run -oyaml > alertmanager-secret.yaml kubectl apply -f alertmanager-secret.yaml # upgrade scrape configs kubectl create secret generic additional-scrape-configs --from-file=prometheus-additional.yaml -n monitoring --dry-run -oyaml > additional-scrape-configs.yaml kubectl apply -f additional-scrape-configs.yaml # upgrade prometheus rules kubectl apply -f prometheus-additional-rules.yaml kubectl apply -f prometheus-rules.yaml # upgrade prometheus configuration kubectl apply -f prometheus-prometheus.yaml # upgrade grafana configuration kubectl apply -f grafana-deployment.yaml
十、定制化配置
1、namespace定制化
如果使用原生kube-prometheus 安装的 kube-prometheus 只会监控 default kube-system monitoring(kube-prometheus 自己创建的ns)三个命名空间,而如果想要添加其他的命名空间,就需要定制化kube-prometheus
定制步骤
自动化脚本如下
# 所有操作均使用root账户 #安装golang并设置环境变量 dnf install -y git curl -O https://dl.google.com/go/go1.15.2.linux-amd64.tar.gz tar -xf go1.15.2.linux-amd64.tar.gz mv go /usr/local echo >> "export PATH=$PATH:/usr/local/go/bin" ~/.bashrc echo >> "export PATH=$PATH:/root/go/bin" ~/.bashrc echo >> "export GOPATH=/root/go" ~/.bashrc echo >> "export GO111MODULE="on"" ~/.bashrc source ~/.bashrc # 安装jsonnet 和 jb 工具 定制化 kube-prometheus 需要用到 #安装json-bundle go get github.com/jsonnet-bundler/jsonnet-bundler/cmd/jb #安装jsonnet go get github.com/google/go-jsonnet/cmd/jsonnet #clone kube-prometheus git clone https://github.com/prometheus-operator/kube-prometheus.git mkdir my-kube-prometheus # 把clone下来的代码复制一遍,因为定制化代码,不会生成CRD,但是会把manifests下的文件都删掉 cp -r kube-prometheus/* my-kube-prometheus cd my-kube-prometheus # 安装必要的jsonnet依赖库 jb install github.com/prometheus-operator/kube-prometheus/jsonnet/kube-prometheus jb update cat add-namespace.yaml << EOF local kp = (import 'kube-prometheus/kube-prometheus.libsonnet') + { _config+:: { namespace: 'monitoring', prometheus+:: { namespaces+: ['default', 'kube-system','monitoring','rook-ceph'], }, }, }; { ['00namespace-' + name]: kp.kubePrometheus[name] for name in std.objectFields(kp.kubePrometheus) } + { ['0prometheus-operator-' + name]: kp.prometheusOperator[name] for name in std.objectFields(kp.prometheusOperator) } + { ['node-exporter-' + name]: kp.nodeExporter[name] for name in std.objectFields(kp.nodeExporter) } + { ['kube-state-metrics-' + name]: kp.kubeStateMetrics[name] for name in std.objectFields(kp.kubeStateMetrics) } + { ['alertmanager-' + name]: kp.alertmanager[name] for name in std.objectFields(kp.alertmanager) } + { ['prometheus-' + name]: kp.prometheus[name] for name in std.objectFields(kp.prometheus) } + { ['grafana-' + name]: kp.grafana[name] for name in std.objectFields(kp.grafana) } EOF
如果要除了添加对应的namespace 还要添加对应点 servicemonitor,参看这里
生成客户化的kube-prometheus
./build.sh add-namespace.yaml
然后就可以看到
[root@k8smaster my-kube-prometheus]# ./build.sh add-namespace.jsonnet + set -o pipefail ++ pwd + PATH=/root/my-kube-prometheus/tmp/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin:/usr/local/go/bin:/usr/local/go/bin:/usr/local/go/bin:/usr/local/go/bin:/root/go/bin + rm -rf manifests + mkdir -p manifests/setup + jsonnet -J vendor -m manifests add-namespace.jsonnet + xargs '-I{}' sh -c 'cat {} | gojsontoyaml > {}.yaml' -- '{}' + find manifests -type f '!' -name '*.yaml' -delete + rm -f kustomization
最后通过对比,发现生成出来的文件,只有
- prometheus-roleSpecificNamespaces.yaml
- prometheus-roleBindingSpecificNamespaces.yaml 发生了变化
变化内容如下
prometheus-roleBindingSpecificNamespaces.yaml
- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: prometheus-k8s namespace: default roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: prometheus-k8s subjects: - kind: ServiceAccount name: prometheus-k8s namespace: monitoring - apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: prometheus-k8s namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: prometheus-k8s subjects: - kind: ServiceAccount name: prometheus-k8s namespace: monitoring - apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: prometheus-k8s namespace: monitoring roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: prometheus-k8s subjects: - kind: ServiceAccount name: prometheus-k8s namespace: monitoring - apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: prometheus-k8s namespace: rook-ceph roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: prometheus-k8s subjects: - kind: ServiceAccount name: prometheus-k8s namespace: monitoring
prometheus-roleSpecificNamespaces.yaml
- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: prometheus-k8s namespace: default rules: - apiGroups: - "" resources: - services - endpoints - pods verbs: - get - list - watch - apiGroups: - extensions resources: - ingresses verbs: - get - list - watch - apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: prometheus-k8s namespace: kube-system rules: - apiGroups: - "" resources: - services - endpoints - pods verbs: - get - list - watch - apiGroups: - extensions resources: - ingresses verbs: - get - list - watch - apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: prometheus-k8s namespace: monitoring rules: - apiGroups: - "" resources: - services - endpoints - pods verbs: - get - list - watch - apiGroups: - extensions resources: - ingresses verbs: - get - list - watch - apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: prometheus-k8s namespace: rook-ceph rules: - apiGroups: - "" resources: - services - endpoints - pods verbs: - get - list - watch - apiGroups: - extensions resources: - ingresses verbs: - get - list - watch
ps:不执行脚本也可以直接修改这两个文件,修改完记得apply
2、修改Prometheus 配置项
在容器化编排工具 Kubernetes 集群中配置Prometheus 服务时,一般使用 kube-prometheus 这个项目进行部署。Kube-prometheus 的使用方式,在项目的说明文档中都有介绍,这里就不赘述了。
Kube-prometheus 项目中对其他资源对象的管理是通过 Prometheus-Operator 项目实例来实现的;所以在管理和更新 Prometheus 服务是需要通过 Operator 来实现。
我们在使用 Kube-prometheus 项目配置 Prometheus 监控后,难免会进行一些调整,增加一些自定义的配置,这时候我们就需要更深入了解 Kube-prometheus 项目是如何配置 Prometheus 服务,并给我们预设什么样的调整配置方式。
Prometheus 服务配置文件添加配置项
kube-prometheus 项目给我们提供了一份默认的 Prometheus 配置文件内容;在默认的环境中,这份默认配置已经很够用的了。
在项目维护过程中,我们难免会增加新的监控对象(Target);这是我们改如果修改 Prometheus 服务的配置文件,来实现目的呐?
1.1、修改Prometheus 服务配置文件对象(错误)
Prometheus 服务的配置文件由 prometheus-k8s 名称的 Secret 对象存储;一般情况下,只需要修改这个对象,既可以完成配置项修改的操作。但是这个对象无法修改,所以这个方式不可行。
1.2、修改Prometheus 服务的Statefulset 对象编辑文件(错误)
配置文件不能修改,那就新创建一个配置文件对象;让 Prometheus 服务引用新的配置文件对象;也可以实现更新配置信息的目的。
修改 prometheus-k8s 名称的 statefulset 对象,使其挂载的配置文件对象为新的配置文件。但是发现 statefulset 对象也是不能修改的;所以这个方式不可行。
1.3、官方提供的修改方式
Kube-prometheus 项目提供的修改 Prometheus 配置文件的方式是新编辑一个附加配置文件。
https://github.com/prometheus-operator/prometheus-operator/tree/master/example/additional-scrape-configs
具体实现查看第五步,其过程主要包括
- 编写一个附加配置文件(prometheus-additional.yaml),用于扩展 Prometheus 配置。
- 利用附加配置文件生产一个 Secret 配置对象(additional-scrape-configs.yaml)。
- 修改 Prometheus CRD 对象实例,添加附加配置项的配置信息(prometheus.yaml)。
- 其他关于角色、绑定和账号的配置一般可以忽略。



【更多】
参考:https://www.cnblogs.com/leozhanggg/p/13502983.html
参考:https://www.orchome.com/8193
Prometheus配置文件说明: https://www.cnblogs.com/rexcheny/p/10675891.html
Kube-prometheus详解:https://www.cnblogs.com/kevingrace/p/11151649.html