18、异常(下)
上一节,我们讲解了如何合理的使用异常,其中提到,不合理的使用异常,比如异常太多,会导致程序变慢,那么,异常太多导致程序变慢的核心原因在哪里?
本节我们就深究到异常的底层实现原理来查找其原因
异常独特的运行机制:异常表、异常兜底、finally 内联
异常中最重要的三个成员变量:cause、detailMessage、stackTrace
- 异常的创建:当创建异常时函数调用栈中的所有函数的信息,遍历函数调用栈生成栈追踪信息
- 异常的抛出:当函数执行 throw 语句抛出异常时,JVM 底层会执行 "栈展开",依次将函数调用栈中的函数栈帧弹出,直到查找到哪个函数可以捕获这个异常为止
- 打印异常调用链:大部分情况下,我们都需要调用日志框架来打印异常调用链,把所有异常的栈追踪信息都打印出来,显然是比较耗时的
1、异常实现原理
1.1、示例 1
上一节,我们讲了异常的基本使用方法,本节,我们来看一个稍微复杂点的例子,代码如下所示,你觉得这段代码的运行结果是什么呢?
public class Demo { public static double div(int a, int b) { try { double res = a / b; System.out.println("in try block."); return res; } catch (ArithmeticException e) { System.out.println("in ATE catch block."); return -1.0; } finally { System.out.println("in finally block."); } } public static void main(String[] args) { double res = div(2, 1); System.out.println(res); res = div(2, 0); System.out.println(res); } }
上述代码的运行结果如下所示
// div(2, 1) in try block. in finally block. 2.0 // div(2, 0) in ATE catch block. in finally block. -1.0
1.2、解释
一般来讲,程序有 3 种执行结构:顺序、分支和循环,而异常的运行机制非常特别
不管 try 监听的代码块有没有异常抛出,finally 代码块总是被执行,并且,在 finally 代码执行完成之后,try 代码块和 catch 代码块中的 return 语句才会被执行
异常的这种特殊的运行机制,其底层是如何实现的呢?
实际上,我们只要看下上述代码对应的字节码,答案就一目了然了,上述代码中 div() 函数的字节码如下所示
字节码比较长,为了清晰的了解其结构,我对其做了一些标注

1.3、异常独特的运行机制
异常独特的运行机制主要包含以下 3 个部分内容
1.3.1、异常表
异常表对应上图字节码中最后一部分 Exception table
其中,from、to、target 都表示字节码的行号,当行号在 [from, to) 之间的代码抛出 type 类型的异常时,JVM 会跳转至 target 行字节码继续执行
- 如上图的 Exception Table,try 代码块的字节码对应的行号是 [0, 16),其抛出的 type 为 ArithmeticException 的异常,会匹配 Exception table 中的第一条规则
因此,JVM 跳转到 27 行字节码继续执行,对应的就是 catch 代码块 - 除了 ArithmeticException 之外,try 代码块抛出的其他异常,将会匹配 Exception table 中的第二条规则
因此,JVM 跳转到 50 行字节码继续执行,对应的就是异常兜底字节码
异常兜底字节码主要做的工作是执行 finally 代码块,然后再原封不动的将异常抛出 - catch 代码块的字节码对应的行号是 [27, 40),其在执行过程中,也有可能抛出异常
其抛出的异常,如果没有在 catch 代码块中捕获,根据 Exception table 中的第 3 条规则,JVM 会跳转到第 50 行字节码继续执行,也就是由异常兜底字节码来兜底
1.3.2、异常兜底
刚刚提到了异常兜底,实际上,这部分工作很简单
主要是捕获 try 代码块和 catch 代码块中未被捕获的异常,然后在执行完 finally 代码块之后,原封不动的将未被捕获的异常抛出
1.3.3、finally 内联
从上图中,我们可以发现,JVM 在生成字节码时,会将 finally 代码块内联(也就是插入)到 try 代码块和 catch 代码块中的 return 语句之前
这样就可以实现不管程序是否抛出异常,finally 代码块总是会被执行,并且在函数返回之间执行
1.3、示例 2
通过上述分析,我们对上面的示例代码稍加改造,在 finally 代码块中添加 return 语句,如下所示,现在,这段代码的运行结果是什么呢?
public class Demo { public static double div(int a, int b) { try { double res = a / b; System.out.println("in try block."); return res; } catch (ArithmeticException e) { System.out.println("in ATE catch block."); return -1.0; } finally { System.out.println("in finally block."); return -2.0; // 额外添加了这一行 } } public static void main(String[] args) { double res = div(2, 1); System.out.println(res); res = div(2, 0); System.out.println(res); } }
上述代码的运行结果如下所示
// div(2, 1) in try block. in finally block. -2.0 // div(2, 0) in ATE catch block. in finally block. -2.0
不管 try 代码块中的代码是正常运行还是抛出异常,div() 函数返回的值总是 -2.0
也就是说,执行完 finally 代码块中的 return 语句之后,函数就返回了,JVM 没有机会再执行 try 或 catch 代码块中的 return 语句了
实际上,如果我们把 finally 代码块中的 return 语句改为 throw 语句,效果也是一样的
所以,在开发中,我们切记不要在 finally 代码块中使用 return 语句和 throw 语句,否则,try 和 catch 代码块中的 return 和 throw 将不会被执行
2、异常性能分析
很多人都有这样的认识:异常会导致程序变慢,那么,为什么异常会导致程序变慢呢?慢在哪里呢?接下来,我们就来详细的分析一下
从上一小节示例代码的字节码中,我们可以发现
如果 try 代码块没有抛出异常,那么 JVM 就不会去搜索异常表,也不会执行 catch 代码块,程序正常执行结束,其运行轨迹跟没有 try-catch 语句包裹时的基本一样
除此之外,异常表、异常兜底字节码、finally 内联都是在编译时生成的,不会占用运行时间
因此,如果程序未抛出异常,那么程序的性能完全不会因为 try-catch 语句的引入而下降
实际上,异常导致程序变慢的情况,只发生在异常被抛出时
当一个异常被抛出时,程序中一般会额外增加这样三个操作:使用 new 创建异常、使用 throw 抛出异常、打印异常调用链
实际上,这三个操作都是比较耗时的,我们来依次分析一下
2.1、使用 new 创建异常
使用 new 创建异常的过程,主要包含两部分工作
- 第一部分是在堆上创建异常对象,初始化成员变量,这部分工作跟创建其他类型的对象没有区别
- 第二部分是调用异常父类 Throwable 中的 fillStackTrace() 函数生成栈追踪信息
栈追踪信息:当创建异常时函数调用栈中的所有函数的信息
栈追踪信息记录了:异常产生的整个函数调用链路,方便程序员定位此异常是如何产生的
示例 1
我们举个例子来解释一下,示例如下代码所示
public class Demo { public static void fa() { throw new RuntimeException("oops!"); // 抛出异常 } public static void fb() { fa(); } public static void fc() { fb(); } public static void fd() { fc(); } public static void fe() { fd(); } // main -> fe -> fd -> fc -> fb -> fa(抛出异常) public static void main(String[] args) { fe(); } }
图示 1
当 fa() 函数通过 new 创建 RuntimeException 异常时,根据专栏第 2 节内容的讲解,函数调用栈中将包含 fa()、fb()、fc()、fd()、fe()、main() 这 5 个函数的栈帧,如下图所示

解释 1
fillStackTrace() 函数所做的工作就是遍历函数调用栈,将每个函数的信息存入异常的 stackTrace 成员变量中,stackTrace 成员变量的定义如下所示
private StackTraceElement[] stackTrace; // 堆栈跟踪
stackTrace 为 StackTraceElement 类型的数组,StackTraceElement 类的定义如下所示
其成员变量有 4 个,分别是:函数所属类名、函数名、函数所属类文件名、异常抛出时此函数执行到了哪一行
public final class StackTraceElement { private String declaringClass; // 函数所属类名 private String methodName; // 函数名 private String fileName; // 函数所属类文件名 private int lineNumber; // 异常抛出时此函数执行到了哪一行 // ... 省略其他代码 ... }
示例 2
我们可以通过 getStackTrace() 函数,将异常的 stackTrace 栈追踪信息打印出来,如下代码所示
public class Demo { public static void fa() { RuntimeException e = new RuntimeException("oops!"); // 打印 strackTrace StackTraceElement[] stackTrace = e.getStackTrace(); for (StackTraceElement element : stackTrace) { System.out.println(element); } throw e; // 抛出异常 } public static void fb() { fa(); } public static void fc() { fb(); } public static void fd() { fc(); } public static void fe() { fd(); } // main -> fe -> fd -> fc -> fb -> fa(抛出异常) public static void main(String[] args) { fe(); } }
上述代码的打印结果如下所示
Demo.fa(Test.java:5) Demo.fb(Test.java:16) Demo.fc(Test.java:18) Demo.fd(Test.java:20) Demo.fe(Test.java:22) Demo.main(Test.java:26)
总结
如果函数调用栈的深度比较小,如上示例代码所示,只包含 5 个函数的栈帧,那么 fillStackTrace() 生成栈追踪信息的耗时也会比较少
但是,对于大部分项目来说,业务代码往往都是运行在容器(比如 Tomcat)、框架(比如 Dubbo、Spring)中
尽管业务代码的函数调用层次不会很深,但是累加上容器和框架中的函数调用,总的函数调用层次就有可能很深
这种情况下,fillStackTrace() 的耗时就相当可观了,这就是异常导致程序变慢的其中一个原因
特别是,如果在递归中抛出异常,函数调用栈非常深,有上千个函数栈帧,那么 fillStackTrace() 将会非常耗时,所以,在递归中不要轻易抛出异常
2.2、使用 throw 抛出异常
当创建完异常之后,我们一般会紧接着将其抛出,如下代码所示
public static void fa() { // ... throw new RuntimeException("oops!"); // 第 3 行代码 }
实际上,上述代码中的第 3 行代码包含两个操作:一个是创建异常、一个是抛出异常,等价于以下两行代码
其中,创建异常的性能我们已经分析过了,我们再来分析一下抛出异常的性能
RuntimeException e = new RuntimeException("oops!"); throw e;
当函数执行 throw 语句抛出异常时,JVM 底层会执行 "栈展开(stack unwinding)",依次将函数调用栈中的函数栈帧弹出,直到查找到哪个函数可以捕获这个异常为止
示例
我们举个例子解释一下,示例代码如下所示
public class Demo { public static void fa() { throw new RuntimeException("oops!"); // 抛出异常 } public static void fb() { fa(); } public static void fc() { fb(); } public static void fd() { try { fc(); } catch (Exception e) { System.out.println("I catch you!"); // 捕获处理 } } public static void fe() { fd(); } // main -> fe -> fd(捕获处理) -> fc -> fb -> fa(抛出异常) public static void main(String[] args) { fe(); } }
图示
当 fa() 函数执行 throw 语句抛出异常时,JVM 将执行栈展开,查找能够处理这个异常的函数
而 fa()、fb()、fc() 这三个函数内部均没有捕获此异常,所以,统统被弹出函数调用栈
直到遇到 fd() 函数,它捕获 中 fa() 函数抛出的异常,所以不会被弹出函数调用栈,JVM 从 fd() 函数继续再执行,上述栈展开过程如下图所示

解释
相对于普通的函数返回(调用 return 语句)导致的栈帧弹出
调用 throw 导致的栈展开除了包含栈帧弹出之外,还增加了一个过程,那就是在函数的异常表中查找是否有可匹配的处理规则
如果异常抛出之后,经过很多函数调用,最终才被捕获,那么查询这些函数的异常表的耗时就会比较多
这就是异常导致程序变慢的另一个原因,当然,相比于创建异常来说,栈展开的耗时要更小一些
因此,对于异常,我们应该遵守 "能捕获就尽量早捕获" 的开发原则
很多人喜欢使用 Spring AOP,在程序运行的很外层,捕获所有的异常,实际上这样的做法增加了栈展开的耗时
不过,权衡性能和开发的便利性,在没有大量异常抛出的情况下,这样做也是可行的
2.3、打印异常调用链
上一节我们讲到,当异常被捕获之后,一般有 3 种处理方式:记录日志、原封不动的抛出、封装成新的异常抛出
其中,"原封不动的抛出" 就相当于没有去捕获,我们重点分析 "记录日志" 和 "封装成新的异常抛出" 这两种处理方法
示例 1
上一节讲到,捕获到异常之后,如果封装成新的异常再抛出,我们一般会将捕获到的异常,通过 cause 参数,传递给新的异常,如下所示,这样异常调用链就不会断掉
try { // ... } catch (IOException e) { throw new RuntimeException("oops!", e); }
原理 1
上述代码中会调用如下构造函数,将对象 e 和字符串 "oops!" 分别传递给新的异常的 cause 成员变量和 detailMessage 成员变量
实际上,异常中最重要的三个成员变量就是 stackTrace、detailMessage 和 cause
public class Throwable { private StackTraceElement[] stackTrace; private String detailMessage; private Throwable cause; public Throwable(String message, Throwable cause) { fillInStackTrace(); // 生成 stackTrace this.detailMessage = message; this.cause = cause; } // ... 省略其他无关代码 ... }
记录日志
一般来说,在平时的开发中,我们使用日志框架来记录异常,如下所示,异常调用链信息会输出到日志文件中,方便程序员事后查看
我们一般不推荐使用 e.printStackTrace() 函数来打印异常日志
因为 printStackTrace() 函数会将异常调用链信息打印到标准出错输出(System.err)中(关于什么是标准出错输出,我们在下一节讲解 I / O 时会介绍)
简单理解就是打印到命令行,显然,这不方便保存以便反复查看
public static void test() { try { // ... } catch (IOException e) { log.error("....", e); // e.printStackTrace(); 不推荐此种方法 } }
实际上,log.error("...", e) 和 e.printStackTrace() 的主要区别在于:输出的目的地不同
其生成的异常调用链信息大差不差,都包含整个异常调用链上的异常之间的 caused by 关系,以及每个异常的栈追踪信息,我们拿 printStackTrace() 函数来举例分析
示例 2
我们通过一个例子来看下 printStackTrace() 函数是如何执行的,示例代码如下所示
public class Demo { // 低等级异常:编译时异常 public static class LowLevelException extends Exception { public LowLevelException() { super(); } public LowLevelException(String msg, Throwable cause) { super(msg, cause); } public LowLevelException(String msg) { super(msg); } public LowLevelException(Throwable cause) { super(cause); } } // 中等级异常:编译时异常 public static class MidLevelException extends Exception { // ... 与 LowLevelException 实现类似, 省略代码实现 ... } // 高等级异常:运行时异常 public static class HighLevelException extends RuntimeException { // ... 与 LowLevelException 实现类似, 省略代码实现 ... } public static void fa() throws LowLevelException { throw new LowLevelException("LowLevelException-msg"); // 低等级异常:编译时异常 } public static void fb() throws LowLevelException { fa(); // 低等级异常:编译时异常 } public static void fc() throws MidLevelException { try { fb(); } catch (LowLevelException e) { throw new MidLevelException("MidLevelException-msg", e); // 中等级异常:编译时异常 } } public static void fd() { try { fc(); } catch (MidLevelException e) { throw new HighLevelException("HighLevelException-msg", e); // 高等级异常:运行时异常 } } public static void fe() { fd(); } // main -> fe -> fd(高) -> fc(中) -> fb -> fa(低) public static void main(String[] args) { try { fe(); } catch (HighLevelException e) { e.printStackTrace(); } } }
图示 2
当 main() 函数调用 e.printStackTrace() 时,整个异常调用链如下图所示

解释 2
理论上,最终打印出来的异常调用链应该如下所示,每个异常的 stackTrace 栈追踪信息都打印出来了
demo.Demo$HighLevelException: HighLevelException-msg at demo.Demo.fd(Demo.java:45) at demo.Demo.fe(Demo.java:50) at demo.Demo.main(Demo.java:55) Caused by: demo.Demo$MidLevelException: MidLevelException-msg at demo.Demo.fc(Demo.java:37) at demo.Demo.fd(Demo.java:43) at demo.Demo.fe(Demo.java:50) at demo.Demo.main(Demo.java:55) Caused by: demo.Demo$LowLevelException: LowLevelException-msg at demo.Demo.fa(Demo.java:26) at demo.Demo.fb(Demo.java:30) at demo.Demo.fc(Demo.java:35) at demo.Demo.fd(Demo.java:43) at demo.Demo.fe(Demo.java:50) at demo.Demo.main(Demo.java:55)
但最终打印出来的异常调用链的真实情况却如下所示
每个异常只打印它生命周期(从创建到被捕获不再抛出)所经历的函数,这样打印出来的异常调用链信息的可读性更好
其中 "... 2 more" 和 "... 3 more" 记录的是 stackTrace 栈追踪信息中没有被打印出来的函数的个数
demo.Demo$HighLevelException: HighLevelException-msg at demo.Demo.fd(Demo.java:45) at demo.Demo.fe(Demo.java:50) at demo.Demo.main(Demo.java:55) Caused by: demo.Demo$MidLevelException: MidLevelException-msg at demo.Demo.fc(Demo.java:37) at demo.Demo.fd(Demo.java:43) ... 2 more Caused by: demo.Demo$LowLevelException: LowLevelException-msg at demo.Demo.fa(Demo.java:26) at demo.Demo.fb(Demo.java:30) at demo.Demo.fc(Demo.java:35) ... 3 more
因为 Throwable 类中暴露了足够的接口(比如 getStackTrace()、getCause())
所以我们也可以自己实现一个异常打印类,比如 ExceptionPrinter,按照自己想要的格式来输出异常调用,实际上,log.error("...", e) 就是这么干的
最后,我们再回到异常性能分析上,大部分情况下,我们都需要调用日志框架来打印异常调用链,把所有异常的栈追踪信息都打印出来,显然是比较耗时的
3、异常最佳实践
尽管异常会导致程序变慢,但毕竟异常并不常发生,所以,我们没必要为此担心
但是,据我了解,很多人会在程序中定义大量的业务异常,比如查询用户不存在时抛出 UserNotExistingException 异常
在高并发下,这类业务异常就有可能频繁发生,进而大量异常的创建、抛出、打印,就很有可能导致程序变得非常慢
我自己曾经开发过一个限流框架,应用到公司里的大部分业务系统,起到限流的作用
当促销活动导致业务系统流量暴增时,限流框架在生效的同时,也不幸导致了业务系统的宕机
最后追踪发现,这个问题就是由异常引起
在我们设计中,当访问被限流时,限流框架会抛出 OverloadException 异常
当大量访问被限流时,线程会大量创建、抛出、打印异常,而这些操作都是非常耗时的,因此,线程就无法响应其他正常请求了,进而导致整个系统响应变慢,甚至超时
3.1、原理
怎么来解决这个问题呢?
实际上,对于业务异常,我们没必要记录 stackTrace 栈追踪信息,只需要将一些有用的信息,记录在异常的 detailMessage 成员变量中即可
比如对于 UserNotExistingException 这个业务异常,我们只需要记录不存在的用户的 ID 即可
怎么才能创建不包含栈追踪信息的异常呢?
我们知道,stackTrace 栈追踪信息是在异常创建的同时调用 fillStackTrace() 函数生成的
Throwable 有一个特殊的构造函数,可以用来禁止在创建异常的同时调用 fillStackTrace() 函数,此构造函数如下所示
protected Throwable(String message, Throwable cause, boolean enableSuppression, boolean writableStackTrace) { if (writableStackTrace) { fillInStackTrace(); } else { stackTrace = null; } detailMessage = message; this.cause = cause; if (!enableSuppression) suppressedExceptions = null; }
3.2、示例
我们只需要在自定义异常时,调用父类 Throwable 的上述构造函数,将 writableStackTrace 赋值为 false 即可,示例代码如下所示
public class UserNotExistingException extends Throwable { public UserNotExistingException() { super(null, null, true, false); } public UserNotExistingException(String msg, Throwable cause) { super(msg, cause, true, false); } public UserNotExistingException(String msg) { super(msg, null, true, false); } public UserNotExistingException(Throwable cause) { super(null, cause, true, false); } }
这样没有了 "栈追踪信息 stackTrace","异常创建" 和 "打印异常调用链" 的耗时就微乎其微了
唯一耗时的部分就是抛出异常时触发的 "栈展开" 耗时,但相比异常创建和打印耗时,这部分耗时要小很多,所以也可以忽略
因此,使用这种方法可以解决在高并发下,程序中大量业务异常导致程序变慢的问题了
4、课后思考题
既然在打印异常调用链时,我们只需要打印每个异常的生命周期里所经历的函数,并不需要打印从 main() 函数到异常创建所经历的所有函数
那么,我们是不是可以在每个异常的 stackTrace 栈追踪信息中,只记录生命周期内所经历的函数呢?
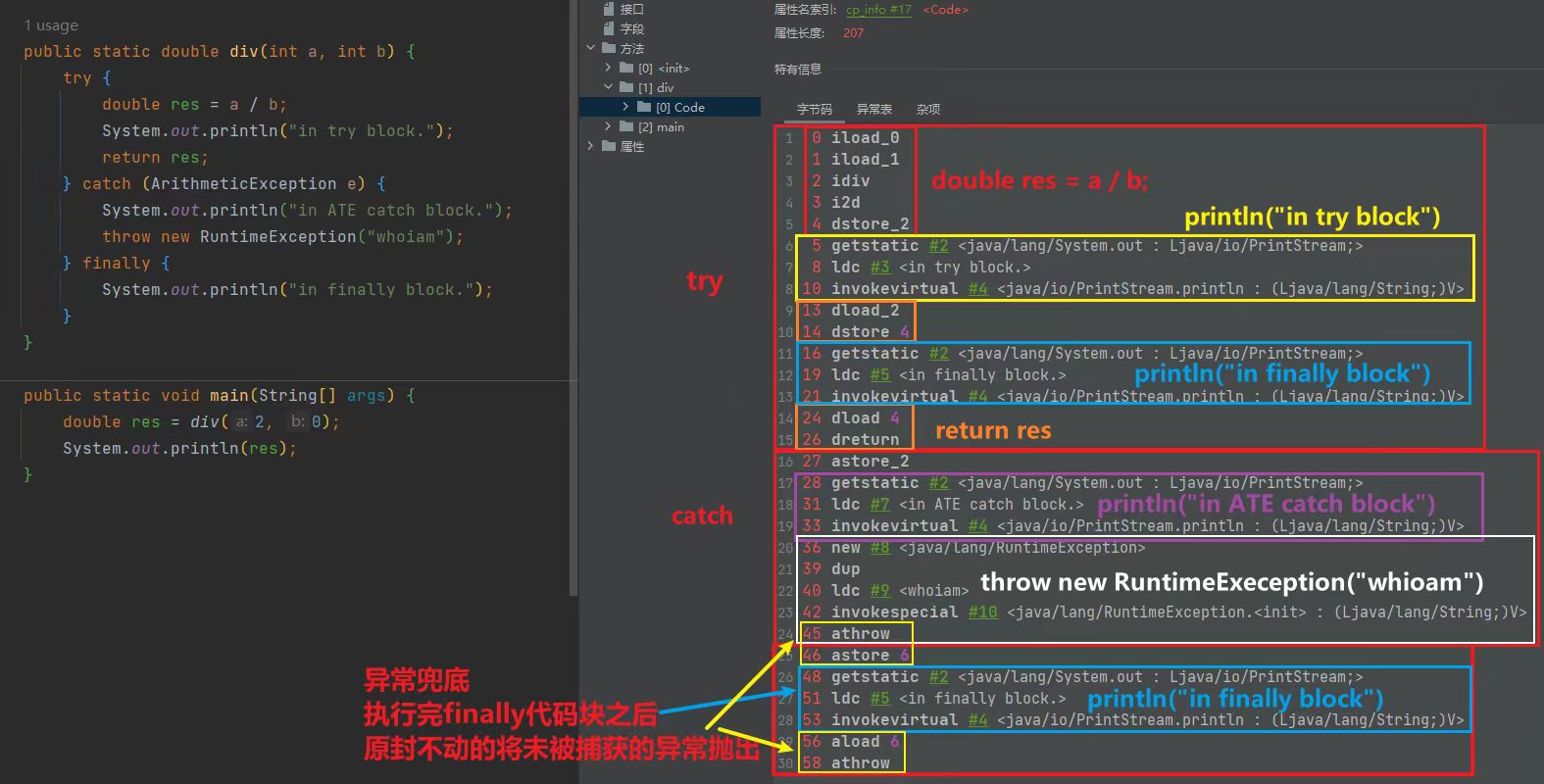
我们将下面的代码编译成字节码之后,finally 代码块会内联到 catch 代码块中的 throw 语句之前吗?为什么?
public static double div(int a, int b) { try { double res = a / b; System.out.println("in try block."); return res; } catch (ArithmeticException e) { System.out.println("in ATE catch block."); throw new RuntimeException("whoiam"); } finally { System.out.println("in finally block."); } }
不会 如果会的话,"in finally block." 就会输出 2 次 第一次:throw new RuntimeException("whoiam") 之前 第二次:throw new RuntimeException("whoiam") 之后,异常兜底的时候
本文来自博客园,作者:lidongdongdong~,转载请注明原文链接:https://www.cnblogs.com/lidong422339/p/17465543.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步