

国密算法实现
国密算法实现
一、国产密码算法介绍
国产密码算法(国密算法)是指国家密码局认定的国产商用密码算法,在金融领域目前主要使用公开的SM2、SM3、SM4三类算法,分别是非对称算法、哈希算法和对称算法。
-
1.SM2算法:SM2椭圆曲线公钥密码算法是我国自主设计的公钥密码算法,包括SM2-1椭圆曲线数字签名算法,SM2-2椭圆曲线密钥交换协议,SM2-3椭圆曲线公钥加密算法,分别用于实现数字签名密钥协商和数据加密等功能。SM2算法与RSA算法不同的是,SM2算法是基于椭圆曲线上点群离散对数难题,相对于RSA算法,256位的SM2密码强度已经比2048位的RSA密码强度要高。
- 椭圆曲线参数并没有给出推荐的曲线,曲线参数的产生需要利用一定的算法产生。但在实际使用中,国密局推荐使用素数域256 位椭圆曲线,其曲线方程为y^2= x^3+ax+b(其中p是大于3的一个大素数,n是基点G的阶,Gx、Gy 分别是基点G的x与y值,a、b是随圆曲线方程y^2= x^3+ax+b的系数)。
-
2.SM3算法:SM3杂凑算法是我国自主设计的密码杂凑算法,适用于商用密码应用中的数字签名和验证消息认证码的生成与验证以及随机数的生成,可满足多种密码应用的安全需求。为了保证杂凑算法的安全性,其产生的杂凑值的长度不应太短,例如MD5输出128比特杂凑值,输出长度太短,影响其安全性SHA-1算法的输出长度为160比特,SM3算法的输出长度为256比特,因此SM3算法的安全性要高于MD5算法和SHA-1算法。
-
3.SM4算法:SM4分组密码算法是我国自主设计的分组对称密码算法,用于实现数据的加密/解密运算,以保证数据和信息的机密性。要保证一个对称密码算法的安全性的基本条件是其具备足够的密钥长度,SM4算法与AES算法具有相同的密钥长度分组长度128比特,因此在安全性上高于3DES算法。
具体参见国家密码局公布的细则
具体实现
安装了实验环境
-
python-3.6.5
工具
-
pycharm
SM2实现
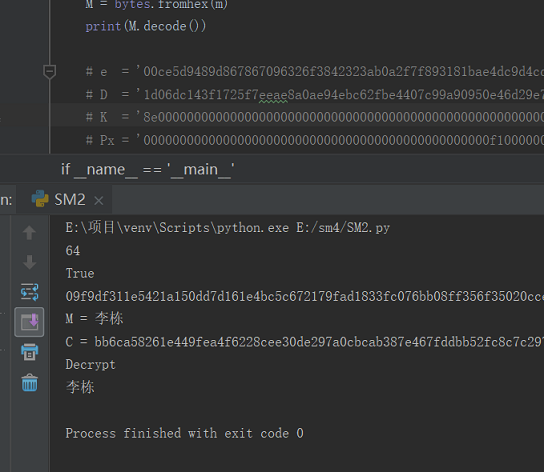
python3实现的国密SM2+SM3,SM3包括KDF功能,可配合SM2加解密(SM2调用了SM3模块)。SM2实现了各种素域下的签名、验签和加解密功能。
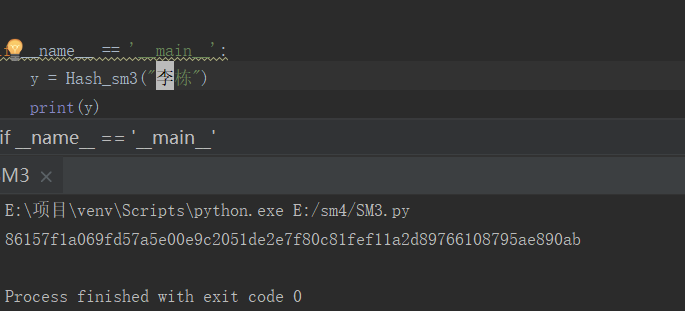
SM3实现
SM3密码杂凑算法的设计原理
SM3密码杂凑算法的设计主要遵循以下原则:
- 能够有效抵抗比特追踪法及其他分析方法;
- 在保障安全性的前提下,综合性能指标与SHA-256同等条件下相当.
(1)压缩函数的设计原则
压缩函数的设计具有结构清晰、雪崩效应强等特点,采用了以下设计技术:
- 消息双字介人。输人的双字消息由消息扩展算法产生的消息字中选出。为了使介入的消息尽快产生雪崩效应,采用了模2^23算术加运算和P置换等
- 每一步操作将上一步介入的消息比特非线性迅速扩散,每一消息比特快速地参与进一步的扩散和混乱
- 采用混合来自不同群运算,模2^23算术加运算、异或运算、3元布尔函数和P置换
- 在保证算法安全性的前提下,为兼顾算法的简介和软硬件及智能卡实现的有效性,非线性运算主要采用布尔运算和算术加运算
- 压缩函数参数的选取应使压缩函数满足扩散的完全性、雪崩速度快的特点
(2)消息扩展算法的设计
消息扩展算法将512b的消息分组扩展成2176b的消息分组。通过线性反馈移位寄存器来实现消息扩展,在较少的运算量下达到较好的扩展效果.消息扩展算法在SM3密码杂凑算法中作用主要是加强消息比特之间的相关性,减小通过消息扩展弱点对杂凑算法的攻击可能性。消息扩展算法有以下要求:
- 消息扩展算法满足保墒性
- 对消息进行线性扩展,使扩展后的消息之间具有良好的相关性
- 具有较快的雪崩效应
- 适合软硬件和智能卡实
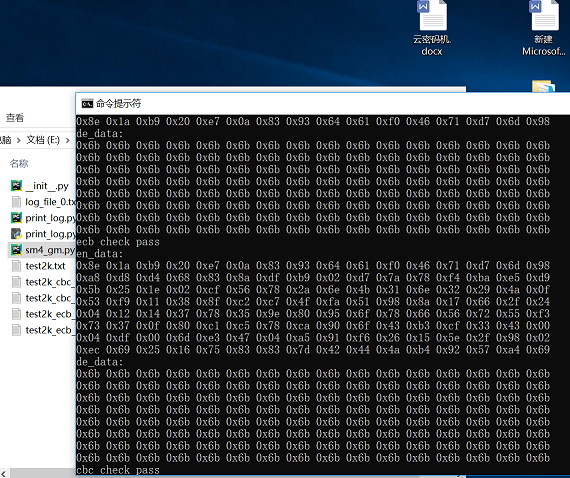
SM4实现
SMS4算法的加密过程
1.读入数据
2.计算轮密钥中间变量
3.计算轮密钥
4.SMS4算法第i+1轮加密
5.SMS4算法最终加密输出
SM4 无线局域网标准的分组数据算法。对称加密,密钥长度和分组长度均为128位。
SM4分组密码算法是我国自主设计的分组对称密码算法,用于实现数据的加密/解密运算,以保证数据和信息的机密性。要保证一个对称密码算法的安全性的基本条件是其具备足够的密钥长度,SM4算法与AES算法具有相同的密钥长度分组长度128比特,因此在安全性上高于3DES算法。SM4 密码算法基本运算有两部分:
- 1.模2加:⊕,32比特异或运算
- 2.循环移位: <<< i ,把32位字循环左移i位
SM4基本密码部件为
1非线性字节变换S盒(起混淆作用)
- S盒的置换规则:输入的高半字节为行号,低半字节为列号,行列交叉点处的数据即为输出。设输入为 “5F”,则行号为5,列号为F,于是S盒的输出值为表中第5行和第F列交叉点的值。
2 非线性字变换 τ:起混淆作用,具体为4个S盒并行置换,设输入字 A=(a0,a1,a2,a3),输出字B=(b0,b1,b2,b3),B = τ(A)=(S_box(a0), S_box(a1), S_box(a2), S_box(a3)
3 字线性部件 L变换: 起扩散作用
32位输入,32位输出。
设输入为 B,输出为C运算规则:
C=L(B)=B⊕(B<<<2)⊕((B<<<10)⊕(B<<<18) ⊕(B<<<24)
4 字合成变换 T:
由非线性变换 τ 和线性变换 L复合而成;
T(X) =L(τ(X))。(先S后L)
总结
此次实验是小组实验,对虽然在前期有了一定的python基础,但是要真正的编程去实现一个完整、复杂的算法还是感觉有点困难,所以我们的代码是在csdn中下载之后研究并做出一定修改。永健、孟亚和我每个人主要负责研究一个算法,之后在小组讨论,对算法做自己的汇报,是整个小组都懂得实现机制。我负责的是sm4的实现,这部分代码是由c语言转编译而来,这样的做法也开阔了自己的学习思路。

