linux搭建Postgresql数据库
1.在操作系统中创建数据库用户:
groupadd postgres
useradd -g postgres -d /home/postgres postgres
设置密码
passwd postgres
2.授权
chown -R postgres:postgres postgres
3.下载依赖程序
PostgreSQL 下载地址:https://www.postgresql.org/ftp/source/v10.5/
下载postgresql-10.5.tar.gz,上传到服务器上 postgres 目录下,解压并编译,configure 后面参数根据实际情况添加,可参考 configure 帮助信息。
安装上传文件的命令:yum install lrzsz -y
解压:tar -zxvf postgresql-10.5.tar.gz
4.如果安装报错,就安装依赖包
yum install gcc -y
yum install readline -y
yum install readline-devel -y
yum install zlib-devel -y
yum install openssl-devel -y
yum install net-tools -y
5.进入到解压的路径执行编译
./configure --with-zlib --enable-nls --enable-integer-datetimes --with-openssl --enable-debug --enable-cassert --prefix=/home/postgres/app/pg105/
6.编译:
make world
7.安装:
make install-world
8.编译完成之后创建数据目录 pgdata
cd /home/postgres/
mkdir pgdata
chown 700 pgdata
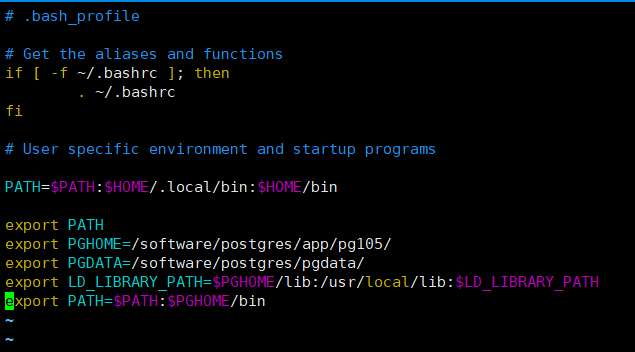
9.设置环境变量
vi ~/.bash_profile
export PGHOME=/home/postgres/app/pg105/
export PGDATA=/home/postgres/pgdata/
export LD_LIBRARY_PATH=$PGHOME/lib:/usr/local/lib:$LD_LIBRARY_PATH
export PATH=$PATH:$PGHOME/bin
让环境变量生效:source ~/.bash_profile
10.初始化数据库(pgdata目录根据实际情况修改)
/home/postgres/app/pg105/bin 到bin路径执行初始化命令
initdb -D /software/postgres/pgdata/ -E UTF-8 --locale=zh_CN.utf8
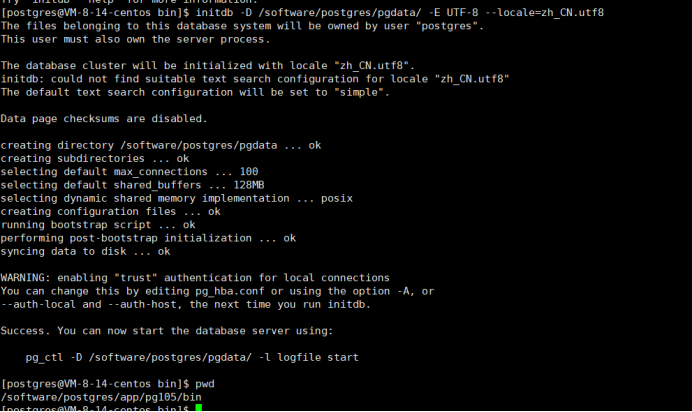
如果报错,记得再重新授权
chown -R postgres:postgres postgres
建议各个节点之间做 ssh 互信(root和postgres)和时间同步。在设置时区时请选择上海。
11.Postgresql 配置
postgresql.conf 配置文件说明如下,以下配置文件仅供参考,注意以下标红部分,实际配置可按找每台服务器硬件条件调整。
#----------------------------------------------------------------------
# CONNECTIONS AND AUTHENTICATION
#---------------------------------------------------------------------
# - Connection Settings –
listen_addresses = '0.0.0.0' # 连 接 数 据 库 配 置
port = 5432 #端口设置
max_connections = 1000 # 最 大 连 接 设 置
superuser_reserved_connections = 3 #决定为 PostgreSQL 超级用户连接而保留的连接“槽”数。
unix_socket_directories = '/tmp' #指定服务器用于监听来自客户端 应用的连接的 Unix 域套接字目录。
unix_socket_permissions = 0700 #设置 Unix 域套接字的访问权限。默认的权限是 0777,意思是任何人都可以连接,
#--------------------------------------------------------------------
# - TCP Keepalives –
#--------------------------------------------------------------------
tcp_keepalives_idle = 60 #指定不活动多少秒之后通过 TCP 向客户端发送一个 keepalive 消息。 0 值表示使用默认值。 在 Windows 上, 值若为 0,系统会将该参数设置为 2 小时,因为 Windows 不支持读取系统默认值。
tcp_keepalives_interval = 10 #指定在多少秒之后重发一个还没有被客户端告知已收到的 TCP keepalive 消息。0 值表示使用系统默认值。tcp_keepalives_count = 10 #指定与客户端的服务器连接被认为死掉之前允许丢失的 TCP keepalive 数量。0 值表示使用系统默认值。这个参数只有在支持 TCP_KEEPCNT 或等效套接字选项的系统上才可以使用。
#--------------------------------------------------------------------
# RESOURCE USAGE (except WAL)
#--------------------------------------------------------------------
# - Memory –
shared_buffers = 32GB #设置数据库服务器将使用的共享内存缓冲区量。默认通常是 128 兆字节(128MB),但是如果你的内核设置不支持(在initdb 时决定),那么可以会更少。这个设置必须至少为128 千字节(BLCKSZ 的非默认值将改变最小值)。shared_buffers 开始值是系统内存的 25%。
huge_pages = try #启 用 / 禁 用 巨 型 内 存 页 面 的 使 用 。可用的值是 try(默认)、on、 和 off。
temp_buffers = 8MB #设 置 每 个 数 据 库 会 话 使 用 的 临 时缓冲区的最大数目。
work_mem = 4MB #指定在写到临时磁盘文件之前被内部排序操作和哈希表使用的内存量。该值默认为四兆字节(4MB)。ORDER BY、DISTINCT 和归并连接都要用到排序操作。哈希连接、基于哈希的聚集以及基于哈希的IN 子查询处理中都要用到哈希表。 maintenance_work_mem = 2GB #指 定 在 维 护 性 操 作 ( 例 如VACUUM、CREATE INDEX 和 ALTER TABLE ADD FOREIGN KEY)中使用的 最大的内存量。其默认值是 64 兆字节(64MB)。
dynamic_shared_memory_type = posix #指定服务器应该使用的动态共享内存实现。
# - Cost-Based Vacuum Delay –
vacuum_cost_delay = 0 #进程超过代价限制后将休眠的时间长度,以毫秒计。其默认值为 0,这将禁用基于代价的清理延迟特性。
# - Background Writer –
bgwriter_delay = 10ms #指定后台写入器活动轮次之间的延迟。在每个轮次中,写入器都会为一定数量的脏缓冲区发出写操作(可以用下面的参数控制)。
bgwriter_lru_maxpages = 1000 #在每个轮次中,不超过这么多个缓冲区将被后台写入器写出。把这个参数设置为零可禁用后台写出(注意被一个独立、专用辅助进程管理的检查点不受影响)。默认值是 100 个缓冲区。
bgwriter_lru_multiplier = 10.0 #每一轮次要写的脏缓冲区的数目基于最近几个轮次中服务器进程需要的新缓冲区的数目。
bgwriter_flush_after = 256 #不管何时后端写入器写入了超过bgwriter_flush_after 字节,尝试强制 OS 把这些写发送到底层存储上。这样做将限制内核页缓存中脏数据的量,降低了在检查点末尾发出一个 fsync 时或者OS 在后台大批量写回数据时卡住的可能性。
# - Asynchronous Behavior –
max_worker_processes = 128 #设置系统能够支持的后台进程的最大数量。这个参数只能在服务器启动时设置,默认值为 8。
max_parallel_workers_per_gather = 0 #设置单个Gather 或 Gather Merge 节点能够开始的工作者的最大数量 。并行工作者会 从max_worker_processes 建立的进程池中取得, 受限于 max_parallel_workers。
old_snapshot_threshold = -1 #设置在使用快照时,一个快照可以被使用而没有发生 snapshot too old 错误风险的最小时间。这个参数只能在服务器启动时设置。
backend_flush_after = 0 # 只要一个后端写入了超过backend_flush_after 字节,就会尝试强制OS把这些写发送到底层存储。
#----------------------------------------------------------------------
# WRITE AHEAD LOG
#----------------------------------------------------------------------
# - Settings –
fsync = on # 如 果 打 开 这 个 参 数 ,PostgreSQL 服务器将尝试确保更新被物理地写入到磁盘,做法是发出 fsync()系统调用或者使用多种等价的方法(见 wal_sync_method)。这保证了数据库集簇在一次操作系统或者硬件崩溃后能恢复到一个一致的状态。建议打开。
synchronous_commit = on # 指定在命令返回 “success” 指 示给客户端之前,一个事务是否需要等待WAL记录被写入磁盘。合法的值是 on、remote_apply、remote_write、local和off。建议配置on
full_page_writes = on #当这个参数为打开时,PostgreSQL服务器在一个检查点之后的页面的第一次修改期间将每个页面的全部内容写到WAL中。
wal_level = logical # wal_level决定多少信息写入到WAL 中。默认值是replica, 它写入足够的数据以支持 WAL 归档和复制,包括在备用服务器上运行只读查询。 minimal 删除除了从崩溃或立即关闭中恢复所需 信息之外的所有日志记录。 最后,logical 会增加支持逻辑解码所需的信息。建议配置为logical
wal_writer_delay = 10ms # 指定WAL编写器刷新WAL的频率 。在刷新 WAL 之后, 它会睡眠 wal_writer_delay 毫秒,除非被异步提交的事务唤醒。
wal_writer_flush_after = 4MB # 指定WAL写入器刷写WAL的频繁程度。 如果上一次刷写发生在少于 wal_writer_delay 毫秒以前并且从上一次刷写发生以来产生了少于 wal_writer_flush_after 字节的 WAL,WAL 将只被写入到操作系统,而不刷新到磁盘。。如果 wal_writer_flush_after 被设置为 0,则WAL数据立即被刷新。默认是 1MB。
commit_delay = 0 #在一次WAL刷写被发起之前,commit_delay增加一个时间延迟,以微秒计。
wal_buffers = -1 # 用于还未写入磁盘的WAL数据的共享内存量。默认值 -1 选择等于 shared_buffers 的 1/32 的尺寸(大约 3%), 但是不小于 64kB 也不大于 WAL 段的尺寸(通常为 16MB)。
# - Checkpoints –
checkpoint_timeout = 10min # 自 动 WAL 检 查 点 之 间 的 最 长 时间,以秒计。 有效值在 30 秒和 1 天之间。 默认是 5 分钟(5min)。 增加这个参数的值会增加崩溃恢复所需的时间。
max_wal_size = 1GB # 在自动WAL检查点使得WAL增长到最大尺寸。这是软限制;特殊情况下 WAL 大小可以超过 max_wal_size,如重负载下,错误 archive_command,或者 较大 wal_keep_segments 的设置。缺省是 1GB。
checkpoint_completion_target = 0.1 #指定检查点完成的目标,作为检查点之间总时间的一部分。默认是 0.5。
checkpoint_flush_after = 1024kB #在执行检查点时,只要有checkpoint_flush_after 字节被写入, 就尝试强制 OS 把这些写发送到底层存储。
# - Archiving –
archive_mode = on # 当 启 用 archive_mode 时 , 可 以通过设置 archive_command 命令将完成的 WAL 段发送到归档存储。 除了 off,要禁用两种模式 on 和 always。
archive_command = 'cp %p /bak/pgarch/%f' #本地 shell 命令被执行来归档一个完成的 WAL 文件段。字符串中的任何%p 被替换成要被归档的文件的路径名, 而%f只被文件名替换, 注意需要提前建好归档路径 , 否则会报错 。
#---------------------------------------------------------------------
# REPLICATION
#--------------------------------------------------------------------
# - Sending Server(s) -
max_wal_senders = 5 # 指定来自后备服务器或流式基础备份客户端的并发连接的最大数量(即同时运行 WAL 发送进程 的最大数)。默认值是 10,0 值意味着禁用复制。
wal_keep_segments = 4 #指定在后备服务器需要为流复制获取日志段文件的情况下,pg_wal 目录下所能保留的过去日志文件段的最小数目。
wal_sender_timeout = 60s #中断那些停止活动超过指定毫秒数的复制连接。这对发送服务器检测一个后备机崩溃或网络中断有用。零值将禁用该超时机制。
max_replication_slots = 10 #指定服务器可以支持的复制槽最大数量。默认值为 10。要允许使用复制槽, wal_level 必须被设置为 archive 或 更高。把它的值设置为低于现有复制槽的数量会阻止服务器启动。
#--------------------------------------------------------------------
# - Master Server –
#---------------------------------------------------------------------
#synchronous_standby_names = 'xnode6,xnode7' #这个参数指定一个支持同步复制的后备服务器的列表。
#vacuum_defer_cleanup_age = 0 #指定 VACUUM 和 HOT 更新在清除死亡行版本之前,应该推迟多久(以事务数量计)。默认值是零个事务,表示死亡行版本将被尽可能快地清除,即当它们不再对任何打开的事务可见时尽快清除。
#---------------------------------------------------------------------
# - Standby Servers –
#---------------------------------------------------------------------
hot_standby = on # 指 定 在 恢 复 期 间 , 你是否能够连接并运行查询默认值是 on。这个参数只能在服务器启动时设置。它只在归档恢复期间或后备机模式下才有效。
max_standby_archive_delay = -1 #当热后备机处于活动状态时,这个参数决定取消那些与即将应用的 WAL 项冲突的后备机查询之前,后备服务器应该等待多久。当 WAL 数据被从 WAL 归档(并且因此不是当前的 WAL)时, max_standby_archive_delay 可以应用。
max_standby_streaming_delay = -1 #当热后备机处于活动状态时,这个参数决定取消那些与即将应用的 WAL 项冲突的后备机查询之前,后备服务器应该 等 待 多 久 当 WAL 数 据 正 在 通 过 流 复 制 被 接 收 时 , max_standby_streaming_delay 可以应用。默认值是 30 秒。wal_receiver_status_interval = 2s #指定在后备机上的 WAL 接收者进程向主服务器或上游后备机发送有关复制进度的信息的最小频度,它可以使用pg_stat_replication 视图看到。
hot_standby_feedback = on #指定一个热后备机是否将会向主服务器或上游后备机发送有关于后备机上当前正被执行的查询的反馈。
#wal_receiver_timeout = 60s #中止处于非活动状态超过指定毫秒数的复制链接。
#wal_retrieve_retry_interval = 5s #指定等待服务器应等待多长时间时, 当重试检索 WAL 数据之前来自任何源 (流复制,本地 pg_wal 或者 WAL 归档) 的 WAL 数据不可用。
#---------------------------------------------------------------------# QUERY TUNING
#--------------------------------------------------------------------random_page_cost = 4.0 # 设 置 规 划 器 对 一 次 非 顺 序 获 取磁盘页面的代价估计。默认值是 4.0。
effective_cache_size = 8192MB #设置规划器对一个单一查询可用的有效磁盘缓冲区尺寸的假设。这个参数会被考虑在使用一个索引的代价估计中, 更高的数值会使得索引扫描更可能被使用,更低的数值会使得顺序扫描更可能被使用。
constraint_exclusion = partition # constraint_exclusion 的 允 许 值是 on(对所有表检查约束)、off(从不检查约束)和 partition(只对继承的子表和 UNION ALL 子查询检查约束)。partition 是默认设置。它通常被用于继承和分区表来提高性能。
#-------------------------------------------------------------------
# ERROR REPORTING AND LOGGING
#-------------------------------------------------------------------
log_destination = 'stderr' #PostgreSQL 支 持 多 种 方 法 来 记录服务器消息,包括 stderr、csvlog 和 syslog。设置这个参数为一个由想要的日志目的地的列表,之间用逗号分隔。默认值是只记录到 stderr。
logging_collector = on #这个参数启用日志收集器,它是一个捕捉被发送到 stderr 的日志消息的后台进程,并且它会将这些消息重定向到日志文件中。
log_checkpoints = on #导致检查点和重启点被记录在服务器日志中。一些统计信息也被包括在日志消息中,包括写入缓冲区的数据和写它们所花的时间。
log_connections = on # 导致每一次尝试对服务器的连接被记录,客户端认证的成功完成也会被记录。 只有超级用户在会话开启时可以改变这个参数,并且在所有会话中不能改变。 缺省是 off。
log_disconnections = on #记录会话终止原因。日志输出提供信息类似于log_connections, 以及会话持续时间。只有超级用户在会话开启时可以改变这个参数, 并且在所有会话中不能改变。缺省是 off。 log_min_duration_statement = -1 #如果语句运行至少指定的毫秒数, 将导致记录每一个这种完成的语句的持续时间。将这个参数设置为零将打印所有语句的执行时间。设置为 -1 (默认值)将停止记录语句持续时间。
log_lock_waits = 1 #控制当一个会话为获得一个锁等到超过 deadlock_timeout时,是否要产生一个日志消息。
log_error_verbosity = verbose #控制为每一个被记录的消息要写入到服务器日志的细节量。有效值是 TERSE、DEFAULT 和 VERBOSE,每一个都为显示的消息增加更多域。
log_timezone = 'PRC' # 设置在服务器日志中写入的时间戳的时区。和TimeZone不同这个值是集簇范围的,因此所有会话将报告一致的时间戳。
log_line_prefix='%m' # 这是一个printf风格的字符串 ,它在每个日志行的开头输出。%字符开始“转义序列”,它将被按照下文描述的替换成状态信息。
log_rotation_age = 1d # 当logging_collector被启用时 ,这个参数决定一个个体日志文件的最长生命期。
autovacuum = on #控制服务器是否运行自动清理启动器后台进程。默认为开启,不过要自动清理正常工作还需要启用track_counts。
log_autovacuum_min_duration = 0 #如果自动清理运行至少该值所指定的毫秒数,被自动清理执行的每一个动作都会被日志记录。
autovacuum_max_workers = 8 #指定能同时运行的自动清理进程(除了自动清理启动器之外)的最大数量。默认值为 3。
autovacuum_naptime = 10s #指定自动清理在任意给定数据库上运行的最小延迟。在每一轮中后台进程检查数据库并根据需要为数据库中的表发出 VACUUM 和 ANALYZE 命令。
autovacuum_vacuum_cost_delay = 0 #指定用于自动 VACUUM 操作中的代价延迟值。如果指定-1(默认值),则使用 vacuum_cost_delay 值。默认值为 20毫秒。
datestyle = 'iso, ymd' #设置日期和时间值的显示格式, 以及解释有歧义的日期输入值的规则。
timezone = 'PRC' #设置用于显示和解释时间戳的时区。 lc_messages = 'zh_CN.utf8' #设置消息显示的语言。
lc_monetary = 'zh_CN.utf8' #设置用于格式化货币量的区域,例如用to_char函数族。
lc_numeric = 'zh_CN.utf8' #设置用于格式化数字的区域,例如用 to_char 函数族。可接受的值是系统相关的。
lc_time = 'zh_CN.utf8' #设置用于格式化日期和时间的区域,例如用to_char函数族。
default_text_search_config = 'pg_catalog.simple' #选择被那些没有显式参数指定配置的文本搜索函数变体使用的文本搜索配置。
deadlock_timeout = 1s #这是进行死锁检测之前在一个锁上等待的总时间(以毫秒计)。死锁检测相对昂贵,因此服务器不会在每次等待锁时都运行这个它。
#-------------------------------------------------------------------
# ERROR HANDLING
#-------------------------------------------------------------------
restart_after_crash = off #当被设置为真(默认值)时,PostgreSQL将在一次后端崩溃后自动重新初始化。
13.pg_hba.conf 配置
# TYPE DATABASE USER ADDRESS METHOD
host all all 10.10.56.17/32 md5
参数说明
host 参数表示安装PostgreSQL的主机
all 第一个all 表示该主机上的所有数据库实例
all 第二个all 表示所有用户
10.10.56.17/32 表示需要连接到主机的IP地址,32表示IPV4
md5 表示验证方式
即上述表示允许IP地址为10.10.56.17的所有用户可以通过MD5的密码验证方式连接主机上所有的数据库
也可以指定具体的数据库名称和用户
# TYPE DATABASE USER ADDRESS METHOD
host test pgtet 10.10.56.17/32 md5
即表示允许地址为10.10.56.17的用户pgtest通过MD5方式加密的密码方式连接主机上的test数据库。
也可以指定整个网段
# TYPE DATABASE USER ADDRESS METHOD
host test pgtet 0.0.0.0/0 md5
不进行密码验证
# TYPE DATABASE USER ADDRESS METHOD
host test pgtet 0.0.0.0/0 trust
修改配置文件,需要重启服务使之生效。还有更多配置方式,请参考官方文档。
任意一台机器连接(测试)
host all all 0.0.0.0/0 trust
14.启停服务
配置完成后,可进行服务的启停。
启动服务:pg_ctl start
停止服务:pg_ctl stop -m fast
重新加载配置文件:pg_ctl reload,需注意在postgresql.conf 配置文件中,有些参数需要重启数据库服务才可以生效。
对于配置服务器,太多时候我们在Linux中做的操作是,配置*.conf文件,然后重启服务。而很多服务都具有reload功能,而但是具体到某个配置,有时候直接说出需不需要重启服务而使得配置生效,这并不是一件容易的事情。但是,postgresql却讲这部分能用在数据表中显式的告诉了我们:
postgres# select name, context from pg_settings;
|
name |
context |
|
archive_command |
sihup |
|
archive_mode |
postmaster |
|
block_size |
internal |
|
log_connections |
backend |
|
log_min_duration_statement |
superuser |
|
search_patch |
user |
说明:
internal: 编译期间的设置,只有重新编译才能生效。
sighup: 只有服务重启才能生效。
postmaster: 给服务器发送HUP信号会是服务器重新加载postgresql.conf配置,可以立即生效。
backend: 与sighup类似,但是不影响正在运行的会话,只在新会话中生效
superuser: 使用superuser(如postgres)才能更改,不用重新加载所有配置即可生效。
user: 单个会话用户可以在任意时间做修改,只会影响该会话。
重新加载数据库配置的方法有三种:
(1)用超级用户运行
postgres=# SELECT pg_reload_conf();
(2)用UNIX的kill手动发起HUP信号
$kill -HUP PID
使用pg_ctl命令触发SIGHUP信号:$pg_ctl reload
15.启动 关闭
[postgres@localhost home]$ pg_ctl start
等待服务器进程启动 ....2022-04-29 11:12:56.803 CST [48490] 日志: listening on IPv4 address "0.0.0.0", port 5432
2022-04-29 11:12:56.804 CST [48490] 日志: listening on IPv6 address "::", port 5432
2022-04-29 11:12:56.807 CST [48490] 日志: listening on Unix socket "/tmp/.s.PGSQL.5432"
2022-04-29 11:12:57.040 CST [48491] 日志: 数据库上次关闭时间为 2022-04-29 11:12:48 CST
2022-04-29 11:12:57.049 CST [48490] 日志: 数据库系统准备接受连接
完成
服务器进程已经启动
[postgres@localhost home]$ pg_ctl stop -m fast
等待服务器进程关闭 ...2022-04-29 11:13:33.945 CST [48490] 日志: 接收到快速 (fast) 停止请求
.2022-04-29 11:13:33.950 CST [48490] 日志: 中断任何激活事务
2022-04-29 11:13:33.954 CST [48490] 日志: 工作进程: logical replication launcher (PID 48497) 已退出, 退出代码 1
2022-04-29 11:13:33.955 CST [48492] 日志: 正在关闭
2022-04-29 11:13:33.977 CST [48490] 日志: 数据库系统已关闭
完成
服务器进程已经关闭
[postgres@localhost home]$ pg_ctl reload
2022-04-29 11:14:15.250 CST [48501] 日志: 接收到 SIGHUP, 重载配置文件
服务器进程发出信号

 浙公网安备 33010602011771号
浙公网安备 33010602011771号