- 事务:一个不可拆分的操作,要么全部执行完,要么全都不执行;
- 隔离级别:总共有四个,分别是
Read Uncommitted(读取未提交内容),Read Committed(读取提交内容),Repeatable Read(可重读),Serializable(可串行化);
- Read Uncommitted(读取未提交内容):一个事务可以读取另一个事务未提交的数据;如果另一个事务回滚,就很容易导致脏读;
- Read Committed(读取提交内容):这个是大部分的数据库系统默认的隔离级别;也就是事物之间对于未提交的事务,无法读取;就比如事务A有一个insert操作,这个时候有一个事务B,一个select操作,查询不到相关事务A的insert,A还没提交事务;
- Repeatable Read(可重读):Mysql数据库默认就是使用的这个隔离级别,一个事务内的多个实例可重复读,数据不变;就比如事务A有一个select userA ,有一个update userA,后面又有一个select userA;这两个select的查询结果是一样的,也就是可重复读;
- Serializable(可串行化):就是强制让事务进行串行处理,一个一个处理;这种情况下,很容易导致大量的数据库请求阻塞;
- 脏读:读取到事务回滚数据;不可重复读:同一事务下前后读取内容不一致;幻读:正对于数据表总体数据,同一事务的前后相同语句查询结果前后不一致;
- 关于Mysql的索引问题:
- 索引是用来加快数据查找效率,可以与数据行建立k-v关系;其底层是使用B+树实现的;
- 常见的有组合索引,单列索引,主键索引,唯一索引(列值必须唯一);
- 索引失效问题:索引失效是指MYSQL,原本可以使用索引但是由于条件问题,导致MYSQL不能使用索引查找,进行全盘扫描;
- 使用
Like模糊查找时值以 %或_开头;这个很容易想到,毕竟mysql的二叉树是基于列值创建的,如果值前缀不确定,二叉树也就失效了;(就比如假设有一个 lidachui-13,这个的意思是值lidachui对应的是数据行13,但是如果是%lidachui,就无法确定是不是这个节点数据了,就需要扫描全部索引和表,这样索引就失效了)
- 使用了函数或其它运算符操作查询结果:就比如
where age*10 <=200;都已经改变了原来列数据值,自然而然就没法使用索引提高查找效率了;
- 使用
or或and查找时,存在一方非索引列;如果一方不是索引列,那也还是需要查询库;另一个索引自然而然的效率提升也就失效了;
- 索引字段的数据类型进行了隐式转换;就比如
age='21';本来是一个int,变成了字符串,索引自然也就失效了;
- 关于SQL语句调优:
- 关于MVCC(多版本并发控制)
- 当前读:读取最新数据,会对读取数据行加锁;快照读:读取某个版本的数据,不会锁行,可以用于并发;
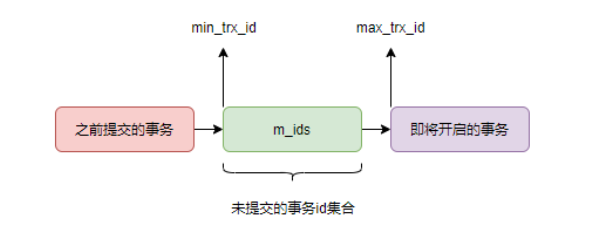
- ReadView:一致性视图,记录了当前活跃事务id,未提交事务id集,以及即将创建事务id;RR模式下,同一事物下只有第一次的快照读会生成,之后的读取都是沿用;(因为可重读是要保证读取数据前后一致,自然也就不需要更新ReadView);而在RC模式下,每一次的读取都会生成一个ReadView;(因为读已提交是要最新的数据,需要实时更新);
- ReadView里的几个字段:m_trx_id(未提交活跃事务id),min_trx_id(未提交活跃事务id集),max_trx_id(将要执行的事务id);
![]()
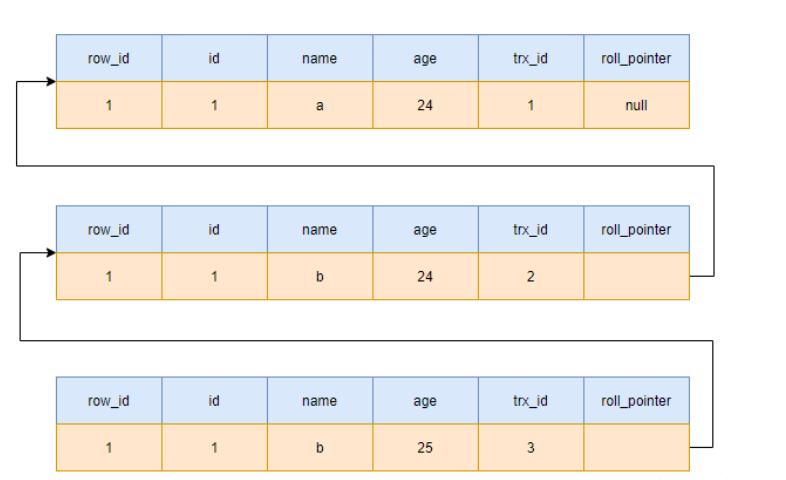
- mysql数据行不单纯只保留数据,还会有一个一个row_id(如果未设置主键,就会以这个作为唯一id),trx_id(操作数据行的事务id),roll_id(指向undo log日志中某条数据行id);
- 具体流程分析:假设RC模式下,事务1已经提交数据;事务2查找得到结果集,生成ReadView,根据查询的数据行trx_id,对比ReadView判断数据行对自己是否可见;如果有trx_id<min_trx_id;说明事务2之前有已经提交的事务1,数据行对事务2可见;
- 关于数据库中的redo log和undo log
- redo log:重做日志;这个日志是用来保证mysql实现事务持久化的;这个日志是针对于insert update语句,再事务提交之后,会将数据写入到mysql的redo log buffer缓冲区中,并通过后台线程写入到redo log日志文件以及数据库磁盘中;undo log:逻辑日志,用来保证mysql事务的回滚和一致性,这里记录了update insert 操作之前的数据结果;就比如,一条delete操作,undo log日志里面就会记录一条insert记录,记录的刚好是刚刚delete操作的数据行信息;当事务回滚时,就可以依赖于undo log 来执行相反的数据操作;
- undo log大致的数据结构:每一行的roll_pointer都会指向上一次提交的数据信息
![]()
- 总结:redo log用来保证mysql事务的持久化;undo log用来保证mysql事务的回滚;
- 关于Mysql的排序实现原理(ORDER BY)
- 介绍两个概念,一个sort buffer(排序内存) ,一个是rowid(临时排序内存);再执行sql时,mysql会创建一个sort buffer,用来处理排序,再内存里面实现排序;如果超出这个内存,就会创建一个临时文件,不过这个会影响sql执行效率;
posted @
2024-07-30 14:53
乐可乐
阅读(
59)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号