
Java八股文总结
- Q:Java好在哪里?
- 跨平台,垃圾回收机制,生态;Jvm可以将编译后的字节码解释成不同系统的机器码,进而达到跨平台的效果;
- Q:Java是按值传递还是按引用传递?
- 按值传递;对于基本数据类型,很好理解;对于引用类型,引用变量本身再栈中也只是持有堆中对象的地址,所有再传递时,也时将地址传递,本质也就是值传递;
- Q:Java为啥不支持多继承?
- 多继承会导致出现菱形继承问题;就比如B,C同时继承A;但是D又继承了B,C;这个时候如果D调用A的方法,B,C中会有不同的方法实现;这样就不确定到底是调用哪一个方法实现;
- Q:什么是不可变的类?
- 最常见的,就是String类;这个类被final修饰,不可以被继承,且属性私有不可变; 就比如这里 ,
String str="str1"; System.out.println(str); str="str2"; System.out.println(str);;"str1",会在字符常量池生成一个str1的对象引用(如果不存在相同常量值);当修改成"str2",也是和"str1"一样,寻找相同常量值的对象引用,并修改原对象的引用;并没有修改原对象的内容;所以本质还是不可变的; - 【误区】:final修饰只是标识这个变量或类(不能继承)不能修改,并不是说不能修改它的状态(属性);如果其属性非私用,也可以修改;而对于该类的方法修改,会返回一个新对象;String类的replace()就是返回一个新的String对象;
- 最常见的,就是String类;这个类被final修饰,不可以被继承,且属性私有不可变; 就比如这里 ,
- Q:Execption和Error的区别?
Execption是可以预料到的意外情况,应该被开发者捕获处理;Error是不可控的程序错误,通常程序已经不能正常运行,捕获也无济于事;
- Q: JDK8的新特性:引入了lambda表达式;新增stream流接口;修改了HashMap(链表转红黑树)以及CurrentHashMap(并发安全使用CAS+sync实现)的底层实现;用元空间替代了永久代;新增了日期类,接口的默认方法,静态方法;
- Q:
String,StringBuffer和StringBuilder啥区别?- String底层也是使用了final char[]进行存储字符,是不可变的;所以再修改时,避免不了的需要创建对象,造成不必要的资源消耗,而
StringBuffer使用了一个可变的char[]存储字符串,通过append拼接,添加到char[]中,同时使用sync来保证线程安全,所以会比较消耗资源,而StringBuilder与之类似,只是没有sync,性能会更好; - 总结:字符串较少或字符需要常量池化,使用
String;多线程字符串添加与修改使用StringBuffer,单线程使用StringBuilder;
- String底层也是使用了final char[]进行存储字符,是不可变的;所以再修改时,避免不了的需要创建对象,造成不必要的资源消耗,而
- Q: JVM和JRE的区别?
- JRE(Java Runtime Environment):Java运行环境;包含了
JVM(执行java字节码文件,提供java运行环境),核心类库(一些Java标准类库,如java.lang.,java.util.)以及支持Java程序运行的文件; - JDK(Java Development Kit): Java开发工具包;可以视为JRE的超集,包含了JRE的所有;包含了JVM,核心类库,以及一些java程序的开发工具(如编译器(
javac),调试器(jdb),打包工具(jar)); - 【总结】:JDK包含JRE,JRE包含JVM;
![]()
- JRE(Java Runtime Environment):Java运行环境;包含了
- Q: JDk动态代理,静态代理,CGLIB是啥?区别?
- 静态代理,是直接再硬编码代理了目标类,是编译时代理;动态代理,通过实现代理类的接口,通过反射调用代理对象,实现代理,他是再运行时实现代理,只支持接口实现; CGLIB是通过继承代理类实现代理,底层使用的是字节码拼接完成继承;它灵活性更高,可以代理任何类;
- Q: 注解的原理?
- 首先清楚,注解其实也就是给类,变量,方法等提供一些标识,一些额外信息的作用;我们可以获得对应的注解信息,做相应的处理;就比如,AOP切面增强时,可以获得方法注解信息,来判断是否需要对方法增强处理。
- 它有三个生命周期,
SOURCE(标识给编译器查看的,再编译之后会丢弃,就比如@Overrider,编译后的字节码文件是以及丢弃了),CLASS(标识给ClassLoader的,再类加载完成之后,就会丢弃),RUNTIME(这个是标识给JVM的,会永久保存在内存中);
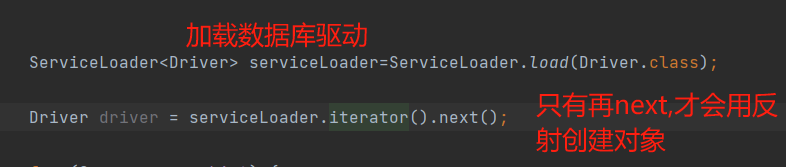
- Q: SPI了解吗?和API有啥区别?
- SPI(Service Provider Interface): 服务提供接口;也就是服务调用方提供的接口,给服务提供方的;API(Application Program Interface): 应用程序接口;也就是服务提供方暴露提供给服务调用方的;也就是对于由服务调用方暴露需要服务提供方实现的就是SPI(比如java.sql.Driver,spring的Cache模块),对于由服务提供方实现暴露服务调用方的就是API;
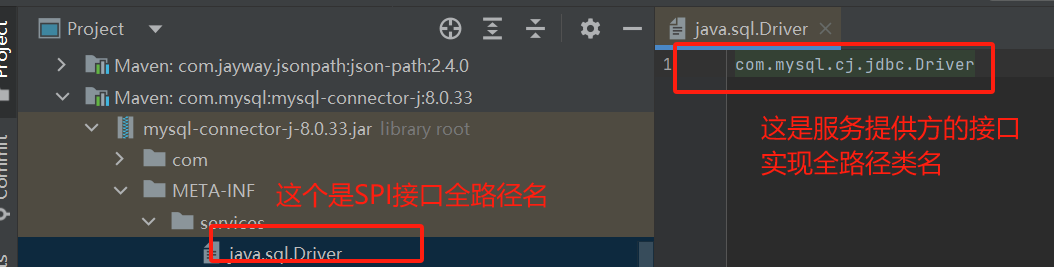
- Java里面有一个类加载器专门处理SPI接口的实现类,
ServiceLoader,会扫描META-INF/services包下的文件,文件名为SPI接口的全路径名,文件内容为该SPI实现类的全路径名;ServiceLoader会获得路径名并缓存,使用迭代器,再next()方法调用时,进行懒加载创建对应的对应实例对象; - 大致流程:
![]()
![]()
- Q:泛型有什么用?泛型擦除又是什么?
- 泛型是为了将类型参数化传递;解决类型的强制转换,提高代码可读性与复用性,减少类型错误的发生;对于泛型擦除,其实是为了向下兼容,jdk5之前并没有泛型概念;泛型擦除是指再编译期间,会擦除泛型的信息,统一变成
Object类型,再必要的时候,进行原类型强转;(直接硬编码的泛型,不会擦除;就比如这个List<String>和List<T>); - 泛型的上下界定符;
List<? extend A>:?只能是A或者A的子类,向上界定了?的类型;List<? super A>: ?只能是A或A的超类,其父类;
- 泛型是为了将类型参数化传递;解决类型的强制转换,提高代码可读性与复用性,减少类型错误的发生;对于泛型擦除,其实是为了向下兼容,jdk5之前并没有泛型概念;泛型擦除是指再编译期间,会擦除泛型的信息,统一变成
- Q:Integer和Long缓存池了解吗?
- 由于一般使用Integer数据都相对较小,就对Integer/Long提供了-128~127的缓存;在使用
valueOf进行包装时,会判断范围,返回对应的包装类;![]() 所以,再-128-127范围内的Integer对象,
所以,再-128-127范围内的Integer对象,equals是相等的,都是引用的同一个对象;不过,Float和Double并没有缓存,毕竟小数范围就很大了...
- 由于一般使用Integer数据都相对较小,就对Integer/Long提供了-128~127的缓存;在使用
- Q:说一下类的加载过程?
- 五个步骤:加载,检验,准备,解析,初始化;
- 加载:将字节码文件加载进入内存,并生成一个Class对象;检验:检验代码中是否存在权限错误问题,是否有危险代码;准备:为静态变量设置初始值,分配内存空间;解析:解析代码语义,并将引用变量替换为实际地址引用;初始化:执行静态代码块,完成静态变量初始化;准备阶段只是占坑;
- Q:双亲委派是什么?
- 双亲委派指的是Java的类加载过程中,会优先委派父加载器去加载,一层一层委派,直到顶层(
Bootstrap),如果父加载器加载失败,在委派子加载器加载;这里的父加载器不是那种继承关系,是逻辑上的父子关系;Java提供的加载器有三种类加载器,Bootstrap ClassLoader(用于加载java的核心类库),Extension ClassLoader(加载java的拓展类),Application ClassLoader(加载当前应用,也就是我们自己写的),最后自定义加载类(前提是存在);每个类加载器都有自己特地需要加载的文件; - 双亲委派是Java推荐的一种类加载方式,主要是为了保证一个类再方法区只存在一个Class实体,同时也是保证java的核心类库不会被恶意入侵;设想一下,如果不是双亲委派的方式,自定义了一个
java.lang.String类且有恶意代码,如果Application ClassLoader优先加载,那这样方法区是不是会存在两个String类
- 双亲委派指的是Java的类加载过程中,会优先委派父加载器去加载,一层一层委派,直到顶层(
- Q:
new String("str")一共创建了几个对象?- 一个或者两个对象;首先,如果字符常量池没有
str,会再常量池里创建一个;其次,new 一定会在堆内存创建一个String对象;
- 一个或者两个对象;首先,如果字符常量池没有
- Q: 再JDk9,将String的char[]改成了byte[],这是为啥?
- 节约内存;一个char是两个字节,设计之初其实是为了兼容UTF编码,有些字符需要两个字节表示;比如GBK汉字,就是两个字节;使用byte可以节省一半的内存;
- 线程的生命周期?
- 五个状态:NEW(新建态),RUNNABLE(运行态),BLOCKED(阻塞态),WAITING(等待),TIMED_WAITING(限时等待),TERMINATED(终结态);
NEW:new Thread()进入初始化;WAITING:start()线程就绪,获得资源进入等待;RUNNABLE: 获得cpu调度,进入运行态;BLOCKED: 执行线程阻塞的操作,线程进入阻塞态;TIMED_WATTING: 这个过程有可能是再等待CPU调度,也有可能是线程被挂起阻塞了;线程等待时间超时,线程唤醒进入等待(这里是等待cpu调度);TERMINATED: 线程执行完毕或者异常,线程终止;
- 五个状态:NEW(新建态),RUNNABLE(运行态),BLOCKED(阻塞态),WAITING(等待),TIMED_WAITING(限时等待),TERMINATED(终结态);
- Q: 运行时异常和编译时异常的区别?
- 编译时异常是指需要开发者手动catch或throw的异常,否则编译不通过;比如
IOExecption,ClassNotFoundExecption;这些需要显式的处理;运行时异常,集成自RuntimeExecption,可能再程序运行时发生,不要求显式处理;比如NullPointerException,ArithmeticException;
- 编译时异常是指需要开发者手动catch或throw的异常,否则编译不通过;比如

 所以,再-128-127范围内的Integer对象,
所以,再-128-127范围内的Integer对象,- Java集合
- Q: 介绍一下Java的集合?
- 首先,java集合有两个顶级接口类型,一个是
Collection和Map;前者是使用使用集合的方式存储对象;后者是使用k-v的形式存储对象; Collection:有三个子接口,Set,Queue和List;前者的特点是不重复,典型的有无序的HashSet以及有序的TreeSet;后者可重复,典型的是ArrayList和LinkedList;ArrayList是基于动态数组实现的,元素之间地址连续,所以的它的读取速度快,但是因为连续所以删除元素的时候,需要重新复制删除,效率较低;LinkedList是基于双向链表实现的,元素地址随机,读取需要遍历的方式,其次因为每一个Node都维护了上/下一个Node的地址和元素,所以内存开销很更大;但是因为对于删除操作,只需要修改指针指向就可以,效率很高;Map: 一个键值对形式保存元素;主要是HashMap;还有两个有序的LinkedHashMap(使用链表)和TreeMap(使用红黑树);
- 首先,java集合有两个顶级接口类型,一个是
- Q: 列表的实现有哪些?
- 两个常见的
ArrayList和LinkedList,他们都是线程不安全的;Vector,和ArrayList类似都是基于动态数组实现,不过他是线程安全的;还有一个CopyOnWriteArrayList,他也是基于动态数组实现,不过他是线程安全的,它的copy只会再write的时候执行;
- 两个常见的
- Q: HashSet和HashMap是什么关系?
- HashSet的底层数据结构是使用的HashMap实现的;用HashMap的key来存储元素;
- Q: 为啥HashMap的扩容后的大小必须是2的n次方?
- 主要是因为
(n-1)&hashcode,需要将元素均匀分配再存储桶中;这里再计算元素存储桶索引值,将元素均匀分配在储存桶里面;假设n=16,n-1=15,看下15的二进制01111,进行与运算,低位随机性还是很高的;如果是10000,与运算后,随机性底,哈希碰撞严重,元素没法均匀分配;
- 主要是因为
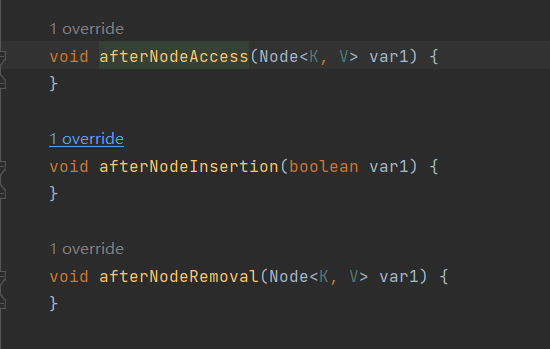
- Q: 什么是
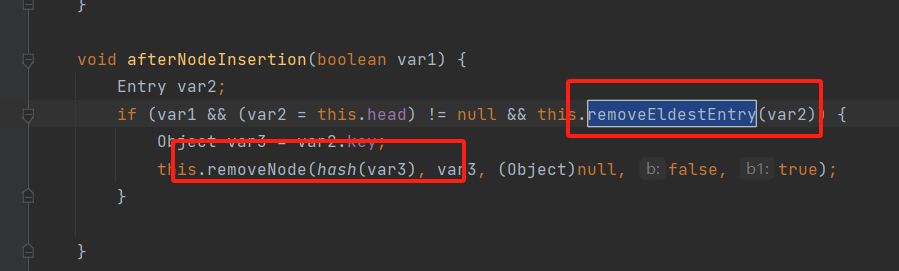
LinkedHashMap?- 也是基于HashMap实现的,只是它的Entry是基于node的双向链表的方式实现的;所以他是有序的;同是它是实现了HashMap提供的三个后置方法;
![]()
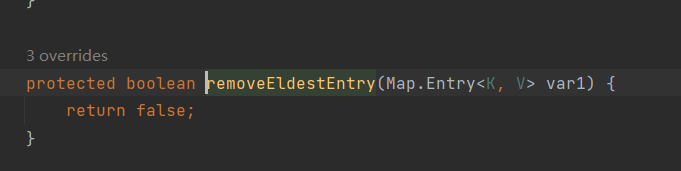
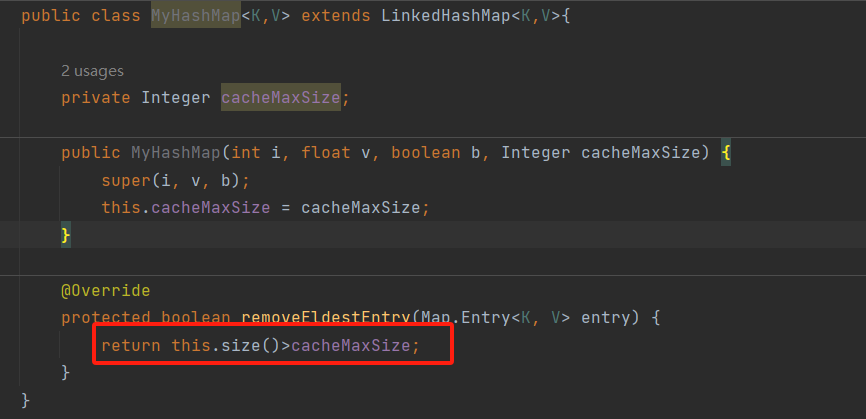
- 也就是LinkeHashMap是支持LRU算法的;LRU(Last Recently Used)算法,内存淘汰算法,最进访问的元素会被插入到末尾,认为最近访问的元素再次访问的可能性更大;LinkedHashMap有一个触发条件;
![]()
只有再返回true时会移除头节点;
![]()
一般可以这样,设置最大的缓存数;
![]()
- 也是基于HashMap实现的,只是它的Entry是基于node的双向链表的方式实现的;所以他是有序的;同是它是实现了HashMap提供的三个后置方法;
- Java的四种引用类型有哪些?
- 强引用,弱引用,软引用,虚引用;
- 强引用:这个是一般情况下会使用的;也就是使用Obj obj=new Obj()再堆内存创建引用,同时当前线程的栈内存中指向obj这个引用;强引用再GC时,如果对栈内存还有对obj的引用,则即使超出堆栈内存也不会被回收;
- 软引用:一般用于非常珍贵的高速缓存中,如果内存不足就会被回收;一般使用
SoftReference<Object> softReference = new SoftReference<>(new Object())创建; - 弱引用:只要发送gc就会被回收;
WeakReference<Object> weakReferenceO= new WeakReference<>(object); - 虚引用:虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。虚引用主要用来跟踪对象被垃圾回收器回收的活动。
- finally语句执行时机?
- finally语句需要try语句配合使用;这个代码块一般都是用来处理一些后续操作,比如关闭IO流,连接等等;无论是否出现异常都会执行;
- 一些特殊场合也会执行: 再try/catch语句中存在return语句;
- 不会执行的场景:调用 System.exit 函数,这个函数会立刻终止JVM的运行;当守护线程执行finally语句但是所有非守护线程都以及关闭时,会被JVM终止守护线程;
- 【注意】:如果其它语句块里面有return,finally语句的return会覆盖之前的return;
- Java并发编程
- Q:什么是多线程安全?
- 一段代码或一个对象,再应对多线程时,不会出现数据丢失,数据不一致等情况;就比如i++,到1000,如果使用多线程处理,很可能i到最后并不是1000;
- 相关措施:保证操作的原子性,要么不执行,要么全部执行完成;加入线程锁,保证只有一个线程访问资源;并发控制,使用条件变量,信号量,比如
CountDownLatch;
- Q: 线程和进程的区别?
- 进程是操作系统资源分配的基本单位;它包含程序代码,数据和资源;进程之间内存不共享,通信需要借助管道,消息队列;
- 线程是CPU的基本执行单位;同一个进程内的资源线程共享;一个进程可以包含多个线程;
- Q: Java的线程池执行原理?
- Java的线程池可以节约线程资源,统一管理线程的生命周期,控制并发数;它有几个核心参数,核心线程数,最大线程数,空闲时存活时间,阻塞任务队列,拒绝策略,(线程工厂);
- 执行原理:首先在创建线程池时,默认并不会创建线程; 当有任务时,开始优先创建核心线程处理 ;当前没有可用线程,且核心线程数达到最大时,会将任务阻塞在队列中; 当队列满了,就创建一个新线程处理;直到线程池线程总数 达到最大线程数时,且任务队列已满时,就会执行拒绝策略;当线程总数大于核心线程数时,会根据空闲时存活时间将线程销毁,直到只剩核心线程(设置
allowCoreThreadTimeOut可以回收核心线程);
Spring框架
- Q:Spring是怎么解决循环依赖的?
- spring采用三级缓存来解决(其实二级缓存就可以解决问题);一级缓存(singletonObjects),存储已经完成生命周期的bean;二级缓存(earlySingletonObjects),存储未完成生命周期的bean,三级缓存(singletonFactories),用来存储bean的对象工厂;
- 具体流程:1).假设A,B互相依赖;当spring创建A实例,同时也会创建A的对象工厂(它可以在必要时创建代理对象),进行依赖注入,发现依赖B;spring会将A的对象工厂存入三级缓存中;2).spring开始创建B实例,发现依赖于A,开始再一二三级缓存中找,再三级中找到A,同时将半成品A放入二级缓存,同时删除三级缓存中的A,最后完成B的实例化;3).并将B放入一级缓存中;spring继续完成A的实例化,再一二三级里查找B,在一级缓存中找到,最后完成A的实例化;同时删除二级缓存中的A;
- Q:Spring既然二级缓存可以解决循环依赖问题,为啥还要使用一个三级缓存呢?
- 三级缓存主要是解决Spring的AOP导致注入到bean中的属性对象与容器中的对象不一致问题;首先,spring的AOP代理是在Bean的后置处理进行的,也就是他会在依赖注入后面,按照流程,BeanA已经被添加到了二级缓存(或者已经注入的其他的Bean中);这样就会导致其他的Bean对象注入的是非代理对象;所以,需要想办法将BeanA的对象提前暴露,这样再注入的时候判断,并按需要对BeanA创建代理对象;然后再把这个代理对象放入二级缓存,这样就可以保证其他的Bean注入的是A的代理对象;
【spring这样做完全是基于Bean的生命周期考虑,如果提前暴露就会打破Bean的生命周期】;等A完成依赖注入后,就会为A创建一个代理对象,并且添加到一级缓存,删除二级缓存中的代理对象;【注意:对象工厂创建的代理对象实例和spring为A创建的代理对象实例必然不是同一个,但是他们的代理对象都是A,这个A是唯一的;也就是说,BeanB里面的代理对象有可能和IOC容器中的代理对象不是同一个,但是基于动态代理的原理,其本质还是对A进行调用处理】
- 三级缓存主要是解决Spring的AOP导致注入到bean中的属性对象与容器中的对象不一致问题;首先,spring的AOP代理是在Bean的后置处理进行的,也就是他会在依赖注入后面,按照流程,BeanA已经被添加到了二级缓存(或者已经注入的其他的Bean中);这样就会导致其他的Bean对象注入的是非代理对象;所以,需要想办法将BeanA的对象提前暴露,这样再注入的时候判断,并按需要对BeanA创建代理对象;然后再把这个代理对象放入二级缓存,这样就可以保证其他的Bean注入的是A的代理对象;
- Q: Spring中的ApplicationContext和BeanFactory有啥区别?
- 首先ApplicationContext是BeanFactory的子接口;BeanFactory是支持懒加载的;也就是说ApplicationContext具有BeanFactory所有的功能,比如创建bean,管理bean;但是ApplicationContext还实现了其它接口,比如EventPublisher,它可以发布事件;他也是实现了MessageResource接口,支持国际化;同时也继承了ResourceLoader,支持加载类路径下的项目资源;
- Q:SpringMVC的执行流程?
- 首先请求进入前端控制器(
dispatchServlet),前端控制器将请求委派给HandlerMapping(处理器映射器)处理,解析url信息,返回Handler调用执行链,前端控制器将执行线委派给HandlerAdpter处理,解析执行链,调用controller处理请求并返回ModelAndView,前端控制器将返回结果交给视图解析器(ViewReslover)解析返回View,前端控制器进行视图绚烂数据填充,最后返回给客户端;
- 首先请求进入前端控制器(
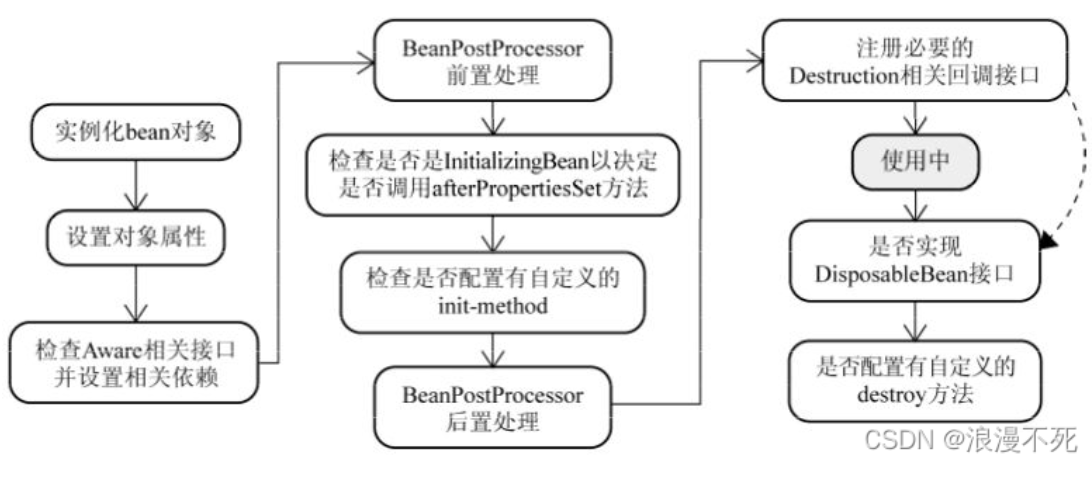
- Q:Spring中Bean的生命周期?
![]()
- 共8个步骤: 分为实例化;依赖注入;AWare接口回调(Aware接口回调主要是Bean用来获得自己再容器中的信息,常见的接口就比如
BeanNameAware接口);BeanPostProcessor的postProcessBeforeInitialization调用;初始化方法(Initialization接口,init-method)调用;BeanPostProcessor的postProcessAfterInitialization调用【Bean完成创建,可以使用了】;销毁(Disposeable接口,destory(),destroy-method);
- 共8个步骤: 分为实例化;依赖注入;AWare接口回调(Aware接口回调主要是Bean用来获得自己再容器中的信息,常见的接口就比如
- Q: SpringBoot中的Starter是啥?
- Starter是一个启动器,它将应用程序需要的依赖包打包到了一起,而不用需要额外导入,同时也省去了版本冲突问题;SpringBoot对Starter支持自动配置,可以将Starter中bean注入到容器中使用;就比如常见的
spring-boot-jdbc-starter,这个starter里面就集成了jdbc相关的依赖包;
- Starter是一个启动器,它将应用程序需要的依赖包打包到了一起,而不用需要额外导入,同时也省去了版本冲突问题;SpringBoot对Starter支持自动配置,可以将Starter中bean注入到容器中使用;就比如常见的
- Q: SpringBoot的自动配置是什么?
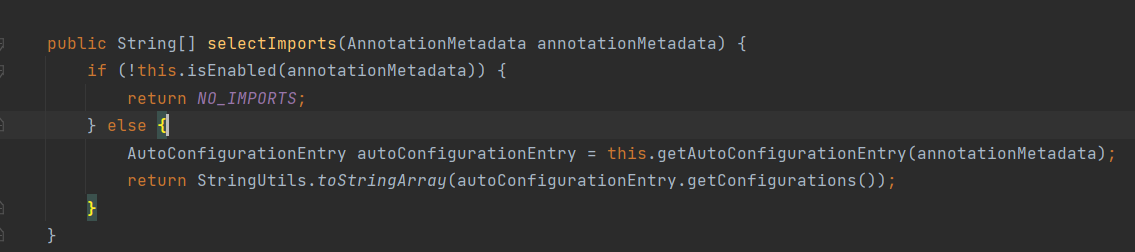
- 自动配置也就是说可以自动加载config类,将bean注入到容器中;注意区分自动装载(bean的初始化)和自动配置(config配置的bean注入容器);关键在
@SpringBootApplication->@EnableAutoConfiguration->@Import({AutoConfigurationImportSelector.class});@Import注解其实也就是将类注入到容器;AutoConfigurationImportSelector类中有一个方法selectImport
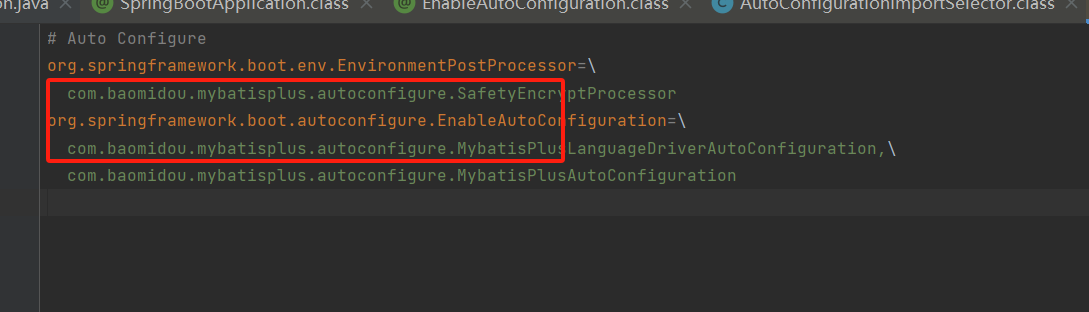
![]()
这个方法,会默认去扫描类路劲下的META-INF/spring.factories文件,里面是使用k-v的形式保存的类名,org.springframework.boot.autoconfigure.EnableAutoConfiguration的v值就是需要spring自动配置的类名;spring会依次读取,并缓存;后续依次反射创建对于实例;下面这个是Mybatis的文件;
![]()
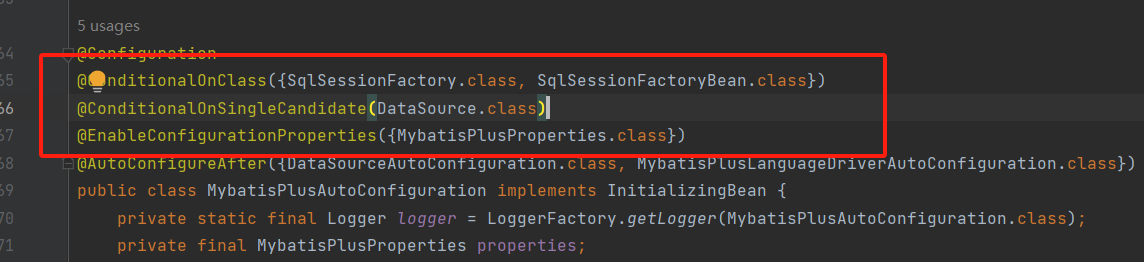
进入这个配置类,会发现他有很多的@Conditional注解,我们都知道这个注解可以用于条件判断,没错,直到当这个条件成立的时候,才会对config进行自动配置;下面是MyBatis自动配置类,可以发现,它要求必须存在数据源,同时还有Mybatis的属性配置类;
![]()
- 总结:Spring的自动配置其实是Spring再启动时,根据当前环境和条件,选择性的自动将一些配置类和Bean注入到容器中,简化开发的过程;其主要流程和关键在于这些注解:
@SpringBootApplication->@AutoConfiguration->@Import(AutoConfigurationImportSelector.class)->AutoConfigurationImportSelector.selectImport,这个selectImport方法会将扫描包下面的/META-INF/spring.fatories文件信息,来确实哪些类需要自动配置,那些类需要先做一些环境处理;之后spring再通过这些全类名通过反射创建对应的实际注入到容器中,完成自动配置;
- 自动配置也就是说可以自动加载config类,将bean注入到容器中;注意区分自动装载(bean的初始化)和自动配置(config配置的bean注入容器);关键在
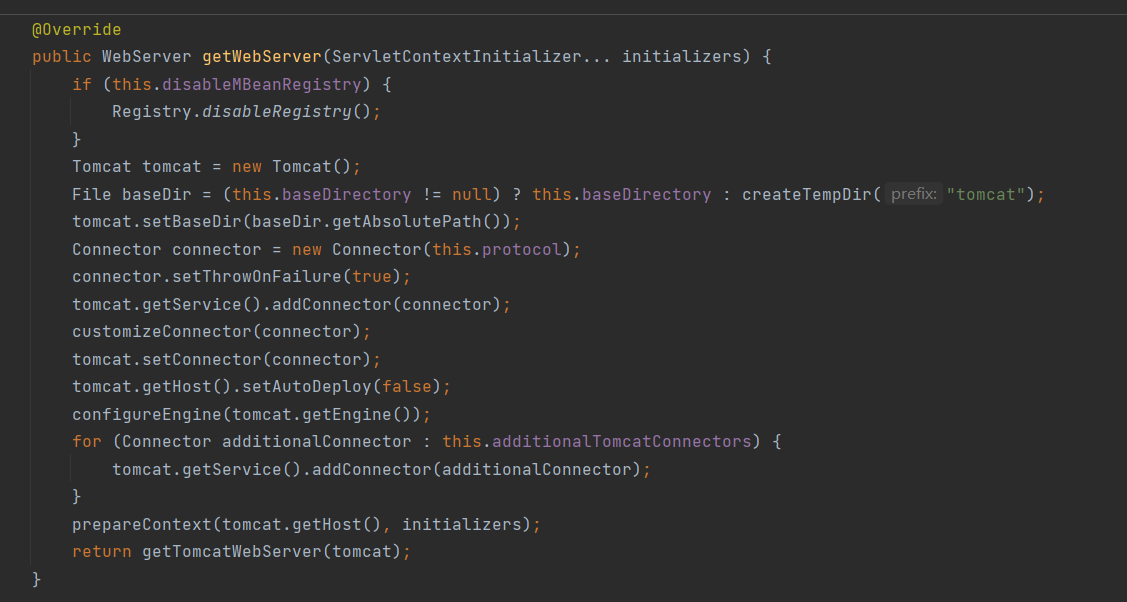
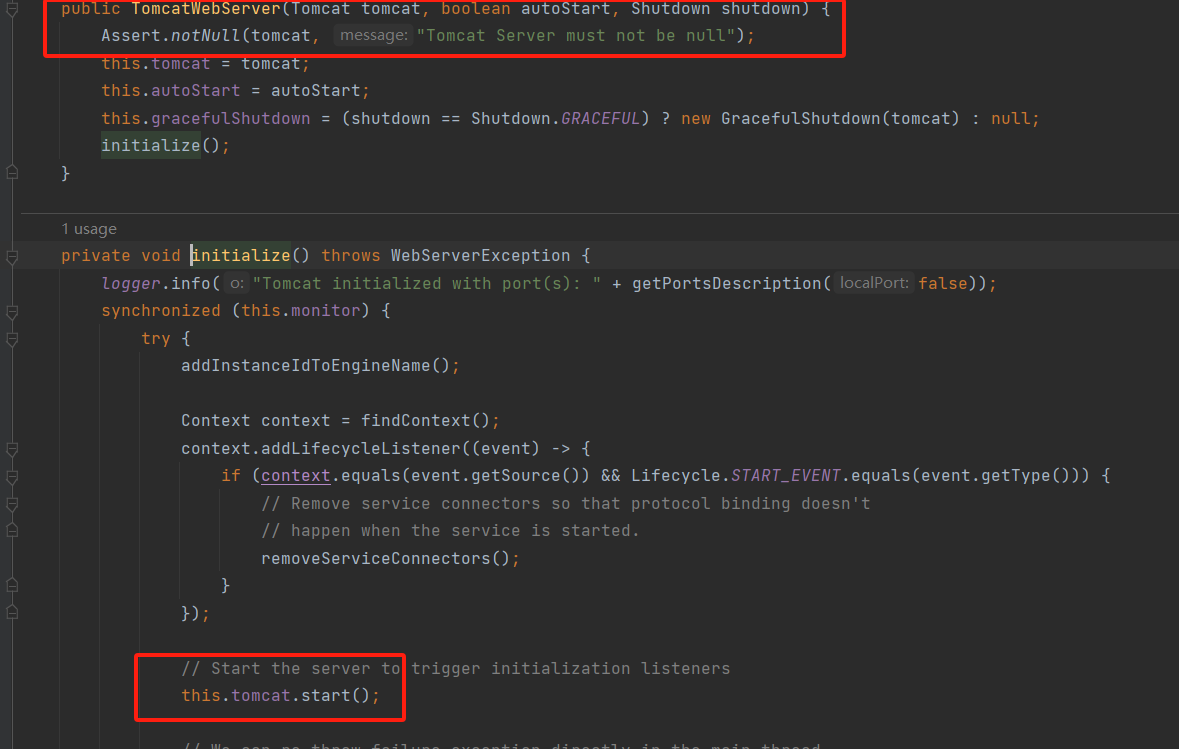
- Q:SpringBoot是怎样通过main方法启动web项目的?
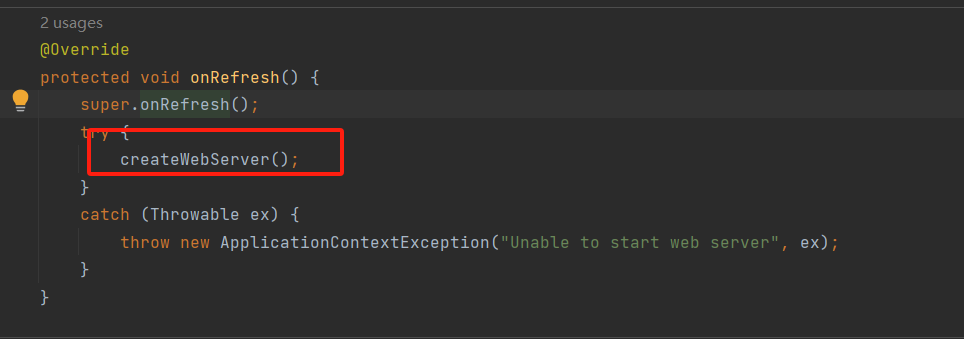
- 再run方法执行之后,spring会使用refreshContext刷新,这个过程会有一个onrefresh方法调用;大致为SpringBoot.run->refreshContext->refresh->onrefresh;这个期间关键会调用ServletWebServerApplicationContext.onrefresh
![]()
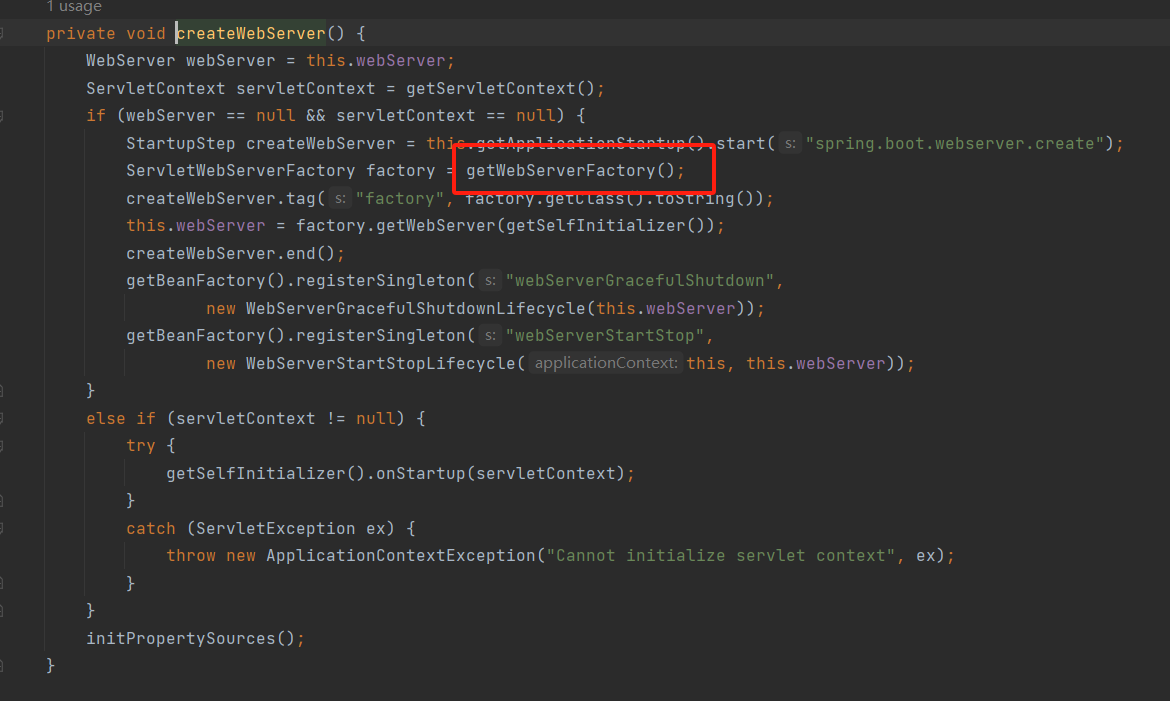
重点关注一下这个getWebServerFactory方法
![]()
这个方法返回接口由三个实现,分别对应三种不同的servlet容器(Tomcat,Jetty,Undertow),我们主要关注Tomcat的是是实现类
![]()
很明显,可以看到它创建Tomcat,并且getTomcatWebServer(tomcat);最后启动了Tomcat
![]()
至此,SpringBoot完成Web项目的启动;
- 再run方法执行之后,spring会使用refreshContext刷新,这个过程会有一个onrefresh方法调用;大致为SpringBoot.run->refreshContext->refresh->onrefresh;这个期间关键会调用ServletWebServerApplicationContext.onrefresh
- Q: SpringBoot是什么?
- SpringBoot是一个用来简化Spring应用开发的轻量级框架;基于约定大于配置的原则,SpringBoot将各种Spring的依赖包整合一起,进行统一管理,避免了多次引入Spring依赖以及繁杂的版本控制;
- Q: SpringBoot的核心特征是什么?
- 独立运行的Spring应用程序:SpringBoot内嵌Tomcat等Servlet容器,不需要外部容器运行;
- 自动配置:基于Conditional的自动配置,简化集成开发;
- 灵活的配置管理:可以通过application.yml对程序进行配置, 同时也支持使用环境变量或者命令行参数对变量配置
- 丰富的生产级功能:比如日志处理,运行监控,安全管理;
- 易于扩展:可以自定义starter,组装自己的依赖配置;集成了丰富的第三方框架,可以一键式引入部署开发;
- Q: 什么是Spring Initializer?
- 这个是Spring提供一个用于快捷创建Spring项目的插件,可以再IDE直接使用;
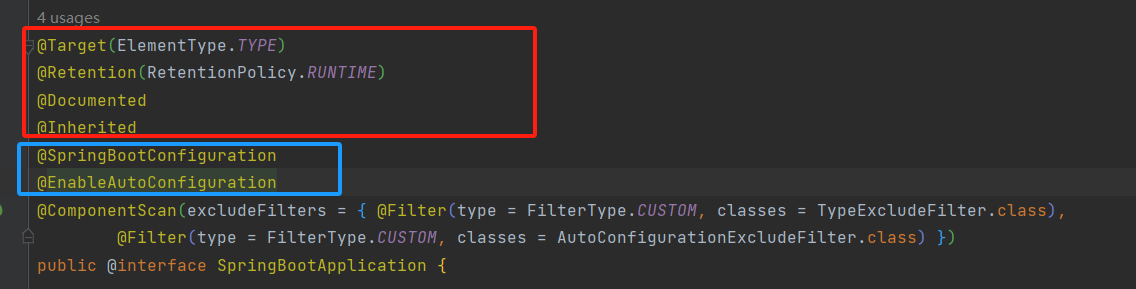
- Q:@SpringBootApplication注解的作用是啥?
-
这是一个组合注解,我们依次来看;首先是四个元注解,@Target,@Document,
@Inherited,@Retention;这个就不细说了;主要看后面几个: -
@SpringBootConfiguration:这个注解是SpringBoot中独有的注解,他其实是对@Configuration的封装;所以基本和@Configuration差别不大;这里只是用来标注一下启动类可以作为配置类,可以使用@Bean,@Import注解;
![]()
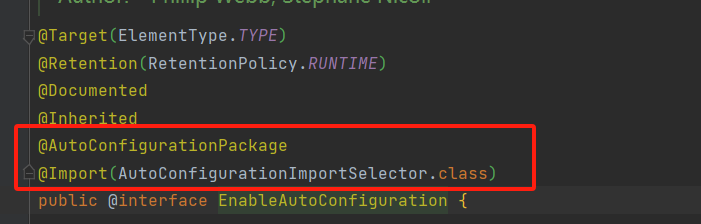
-
@EnableAutoConfiguration:这个注解内部还有一个注解,@AutoConfigurationPackage,这个注解引入了一个@Import(AutoConfigurationPackages.Registrar.class),这个类会扫描当前启动类包下的组件,配合ImportSelector实现类,完成对目标类的容器注入;还有一个比较重要的
@Import(AutoConfigurationImportSelector.class),这注解再之前已经详细介绍过了,它实现了ImportSelector接口,会扫描类路劲下的/MATE-INF/spring.factories,实现自动配置;
![]()
-
@ComponentScan:主要是用来扫描自己定义的组件,虽然前面的注解会自动扫描启动类同级包下面的类,这个注解就是进行拓展和完善的,注意和@AutoConfigurationPackage区分,AutoConfigurationPackage是自动配置中的一个部分,用来确定满足条件可自动装配的类,将这些类信息注入到容器,并不会主动去注入对象;
-
- Q:SpringBoot配置文件的加载顺序?
- SpringBoot官方提供的有三个配置文件,bootstrap.yml,application.properties,application.yaml;加载顺序从左至右;yaml文件格式通过缩进来体现层级关系,properties使用
.来体现层级关系;bootstrap.yml文件一般用在springcloud中,用来配置一些元数据信息,一般不会更改,比如配置中心的地址信息等等;通过spring.proflies.active也可以也可以设置当前开发环境,由此来加载对应的配置文件; - 总结:Java命令行参数>Jar外部配置文件>Jar内部配置文件>Java系统变量
- SpringBoot官方提供的有三个配置文件,bootstrap.yml,application.properties,application.yaml;加载顺序从左至右;yaml文件格式通过缩进来体现层级关系,properties使用
- Q:SpringBoot打包的jar和普通项目打包的jar有什么区别?
- Jar包是Java平台中一种用于打包多个文件的归档文件格式。主要包含.class类文件,资源文件(图片),元数据,清单文件等等...
- 项目依赖:SpringBoot项目是打包了应用需要的依赖;普通的Jar只包含应用的编译代码和资源文件,如果不把jar包放入到类路劲下的lib目录,是不会被打包进jar的;运行环境:SpringBoot内置了Servlet容器,可以直接部署;普通jar需要依赖于外部运行环境;文件结构:SpringBoot打包的jar会比普通的jar多一个BOOT-INF/classs目录,这里存放应用的.class文件;普通的jar通常只有 META-INF 目录和 classes 目录,类文件和资源文件直接位于这些目录下;启动方式:一般普通的jar会有一个程序入口,一般都是main,需要手动指定;Spring Boot 自动管理启动过程,包含了一个特定的 SpringApplication.run 方法,负责启动应用上下文和内嵌服务器。
- Q:如何在 Spring Boot 中定义和读取自定义配置?
- 定义:可以通过配置文件中定义;也可以通过命令行设置;
- 读取可以通过
@Value,@ConfigurationProperties,Environment,@PropertySource,原生方法;
Redis篇章
- Q:Redis的内存淘汰策略?
- 先说一下Redis的过期策略问题,这个是在正常情况下触发的清除策略;redis中对设置了过期时间的key放入同一个字典进行保存,当key的exprice到期,key就不可用了,再后续中删除策略处理;删除策略分两者,一个定期删除,还有一个是惰性删除;定期删除会每100ms随机再redis中选择20个key,对过期的key进行删除操作,同时会对过期比率判定,如果大于1/4会重复步骤;惰性删除是在获得key时,进行判断过期后删除;
- 对于内存淘汰策略,出现再redis内存超过最大设置内存时,触发;当然这个最大内存是可以进行命令设置的;主要有以下策略:
![]()
no-eviction是redis默认的淘汰策略;当内存不足时,对写操作拒绝服务;Redis的LRU策略和LinkedHashMap的不一样,Redis中,是将最近访问的放在队列头部;但是LRU算法有一个弊端,他只是记录,key最近有没有被访问,相对来说并不是非常准确,其次他每次修改队列结构,redis本省就是并发量大,自然而然就会造成消耗,所以redis使用了一个LFU策略,最近最少使用;它是主要记录key的使用次数;这样是保证了,对访问率底的key优先淘汰;
- Q:Redis的数据类型:string,hash,set,zset(有序的set),list,geo;【具体命令,可在redis-cli输入help命令查看】

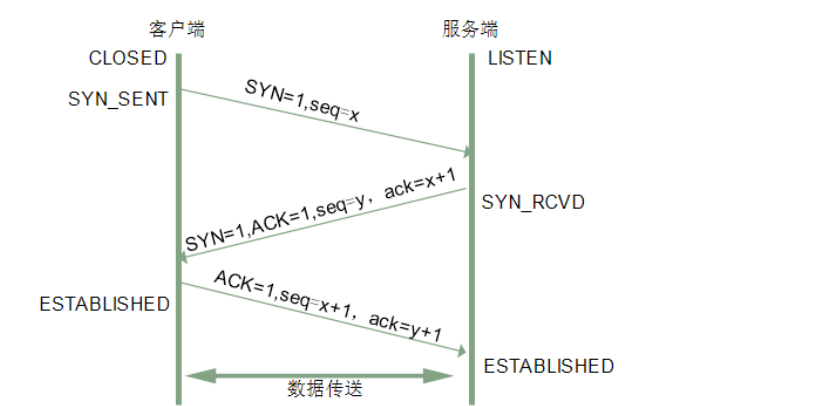
- Q:TCP的三次握手?【注意:tcp的三次连接本质也是数据包,这里的seq是标识包序号,实际以具体情况定;这里的ACK/SYN是报文头中的一个标志位,而ack=x+1是确认号,标识(x+1)-1之前数据包以及接受到了,ACK和ack确认号在TCP报文中存在与不同的位置】
- 第一次:客户端会将报文SYN标志位为1,标识这是一个SYN数据包;包序列号seq设置为x;客户端进入
SYN_SEND状态; - 第二次:服务端收客户端SYN包,检验是否可以建立连接;确认可以后,服务端将报文SYN以及ACK的标志位设置为1,ack确认号为x+1,包序列号设置为seq=y;服务端进入
SYN_RECED状态; - 第三次:客户端收到后,将报文ACK设置为1,同时设置确认号ack=y+1,设置报文序列seq=x+1,回复服务端;服务端在收到确认报文后,进入
established状态;
图解:![]()
- 第一次:客户端会将报文SYN标志位为1,标识这是一个SYN数据包;包序列号seq设置为x;客户端进入

 浙公网安备 33010602011771号
浙公网安备 33010602011771号