- 封装: 将数据与操作这个数据的方法包装起来,对数据实现只能通过自定义接口实现。
- 多态: 不同类型的子对象,可以对同一个消息做出不同的响应。
- 重载:同一个类同一方法名,不同参数返回值;
- 浅拷贝以及深拷贝:前者是指只拷贝对象的基本数据类型,以及引用地址,而不拷贝其引用指向的对象(就比如对象赋值操作,新/源变量都是指向同一个引用地址),后者即会拷贝基本数据类型,也会拷贝其引用指向的对象,也就是是一个完全独立的新对象。
- 对于sleep()和wait()方法,sleep会释放CPU但不会释放锁,wait会释放锁以及CPU,所以wait方法必须是
synchronized修饰的对象;
==和equals,前者:对于基本数据类型,比较的是变量值【equals是Object.class的方法,基本数据类型没有】,对于引用类型,比较其地址;后者:如果没有重写,是比较对象地址(默认使用的是==),重写后,按重写逻辑对比;
- 【注意】:如果重写了equals,那么hashCode方法也要求重写,并且保证如果equals和hashCode同时成立;否则再HashMap处理数据时,会导致相同对象却无法存储在同一个哈希桶里面;
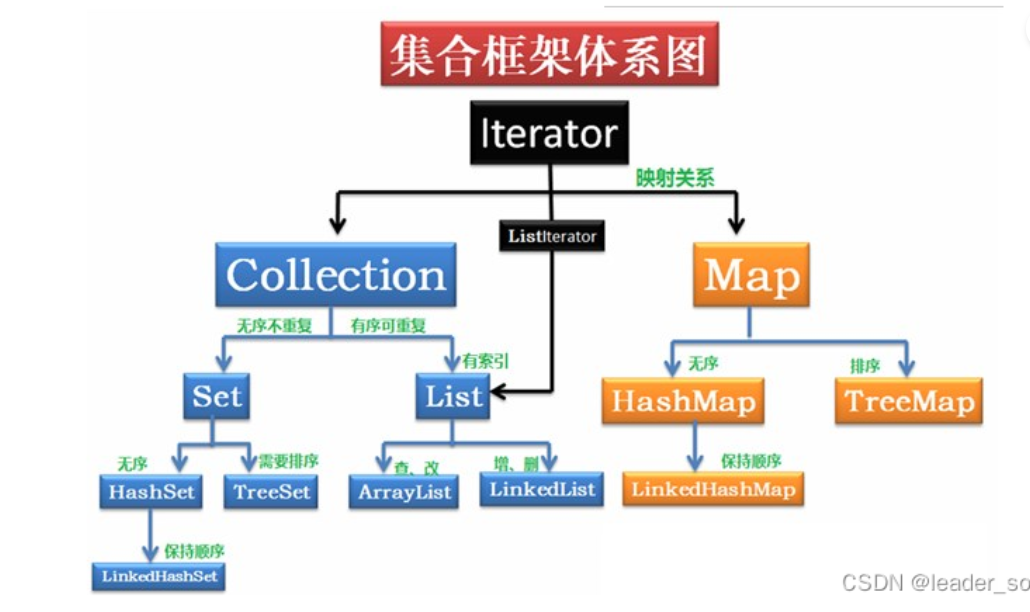
native关键子修饰的方法标识调用底层操作系统的方法;不能重写;StringBuffer和StringBuilder,StringBuffer线程安全(sync),效率更低;StringBuilder线程不安全,效率高;finalize()方法,Object类中的一个在被垃圾收集器处理之前做的一些清理工作,方法由垃圾收集器调用;可重写;- 集合体系
![]()
- ArraryList基于动态数组,适用于频繁的数据读取;LinkedList基于链表实现,适用于频繁的插入与删除;
- 如果未添加权限修饰,表示该方法当前包下可用;
HashMap是基于数组,链表,红黑树数据结构实现的;数组长度(默认为16)可在构造函数指定,数组(bucket)保存着一个链表(Node<K,V>),node持有下一个node的引用,形成链表,当链表数超过8时,会转成红黑树(平衡二叉树),提高效率;
put():当put时,会根据key计算hash值,再通过hash%array_len计算出数组的索引,获得该元素下的链表,遍历该元素的链表,同时比较hash(这里其实是比较是否存在相同的key),如果相同hash值相同(产生hash碰撞),在比较equals(),如果相同,则直接替换,如果没有,再创建添加到当前链表中;- 优化思路:每次的hash计算值都决定了新插入值的所在的数组位置,如果可以优化索引的算法,让链表尽量均匀分布在每个数组元素上,这样就可以减少每次遍历链表的次数,不过这个Java已经优化过了;
HashTable是线程安全的,它不允许key为null,同时存在contains()方法,实现原理与之类似;ConcurrentHashMap: 基于sync和CAS实现线程安全,底层数据结构和HashTable一致;对于HashTable,它的效率会更好,HashTable的所有方法几乎都是sync修饰,每次执行都需要判断锁;而ConcurrentHashMap只对数据行锁定,进一步减少了并发下锁冲突概率,同时使用CAS进一步保证了原子性;这也就是性能由于HashTable的原因;
- 线程的五种状态,新建,就绪,运行,阻塞,死亡;阻塞只能先转就绪态,再转运行态;
- 阻塞的常见情况:I/O操作;
sleep()或者wait() synchronized ;
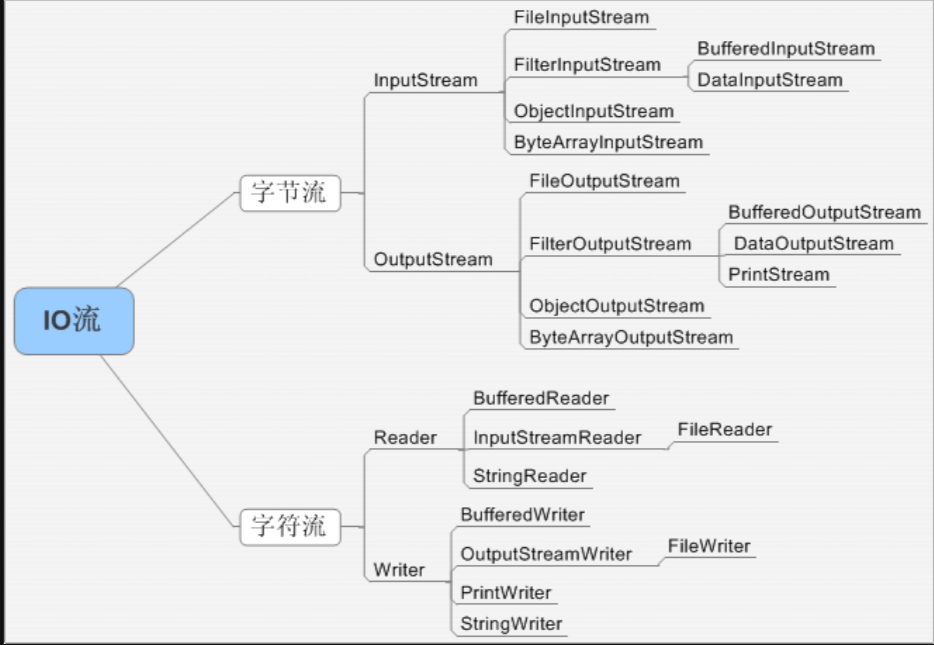
- 流类型
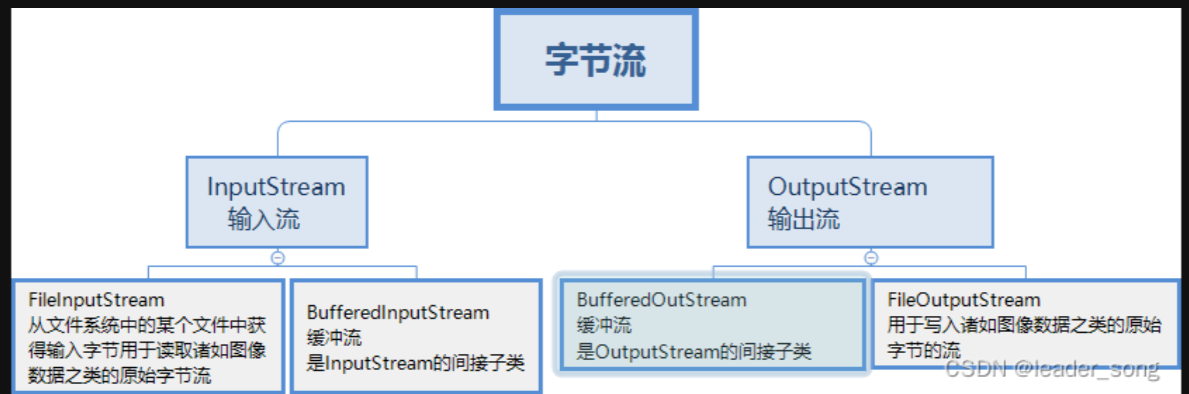
- 字节流
![]()
- 字符流
![]()
- 汇总
![]()
- 区别:字节流可以处理所有文件类型以及二进制数据(音频,图像...),字符流用于处理文本数据;
- 两个特殊类:
InputStreamReader,将字节输入流转字符输入流; OutputStreamWriter,将字节输出流转字符输出流;类似的还有两个WriterOutputStream和ReaderInputStream;这个两个类不是java.io包下的;
- Java反射
- 设计目的:提高程序灵活性,应对复杂的大框架,比如动态代理就是依赖于反射,Spring框架的AOP也是依赖于反射实现;
- 实现原理:再JVM的ClassLoader加载字节码文件的时候,会将类的信息保存再堆内存的
Class对象中,包括类的参数,方法,接口,父类;Class.forName()以及getClass()时,会在堆内存获取Class对象,如果没有则会重新使用ClassLoader进行加载;
- Java序列化:序列化,是指将对象转为可存储或者可传输的数据格式的过程;其实就是将Java对象转为对象流的形式,可以将对象流保存在文件中(二进制数据)或者进行网络传输;再通过
ObjectInputStream转换回来;
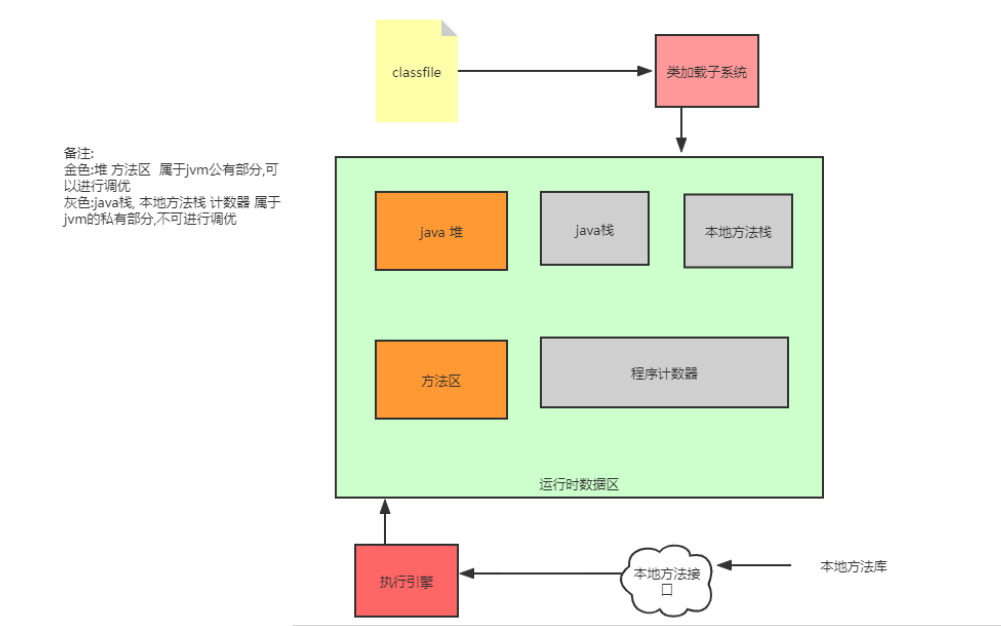
Cookie和Session:首先Cookie是保存再客户端,而session是保存在服务端;Cookie是服务端发送给客户端的一个小数据段,里面通常会有一些鉴权或用户状态信息,比如sessionId;而session是存储再服务端的用户信息或会话,一般有一个唯一Id,通常会使用Cookie来发送到客户端;我理解的是Cookie是客户端与服务端信息交换的一个特定请求头,Session是这个交换信息中存在一部分,比如也可以将一些其他的鉴权信息添加到Cookie中,浏览记录,购物车信息等等...;- Java的内存分区:
![]()
- 类加载系统:JVM会使用双亲委派的方式,进行加载字节码文件到内存中;首先BootStrap ClassLoader(根类加载器)尝试加载,Ext ClassLoader(拓展类加载器),Application ClassLoader(应用类加载器),最后自定义ClassLoader,如果都没有加载成功会抛出ClassNotFound异常;一般用户写的代码都是由应用类加载加载的。【双亲委派:再类加载的过程中,会优先委派父加载器加载,如果加载失败,再交由子加载器加载;】
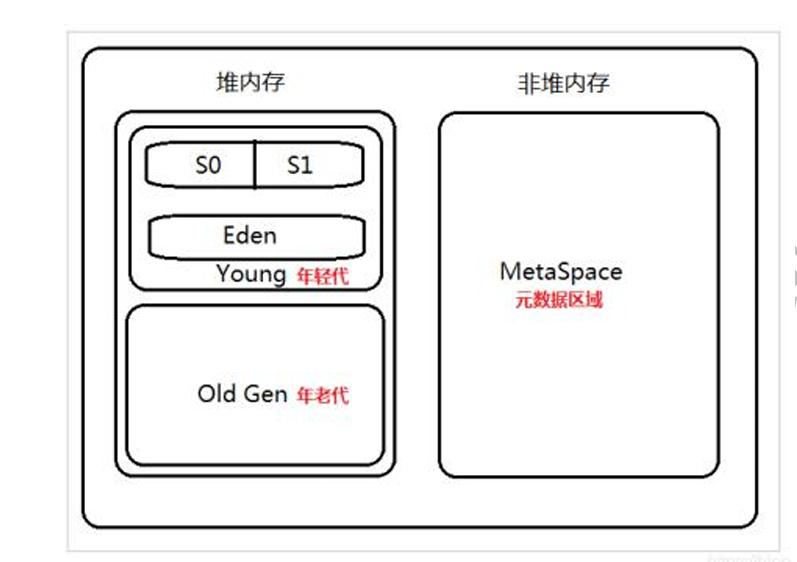
- Java堆内存(存放对象实例,这里的元空间再JDK1.8之后就不属于java的堆内存,使用的本地系统内存;这里画在一起只是表面JVM会对这个区域内容进行管理):
![]()
- 新生代区:当对象初次new创建时,会放在这个区域;老年区:当新生代区的对象经过多次GC任然存活,就会被放入这个区域,这个区域的GC频率会更小,GC的速度也会更慢;元空间区(Jdk1.7叫永久代):主要用于存储类的元数据信息(类名,接口,方法,变量...);
- 新生代还有三个区,一个叫伊甸区,生存区s0,生存区s1; 新创建的对象放在伊甸区,当经过第一轮的CG后,放入生存区s0,再次GC后,放入s1;
- 方法区(非堆):再JDK8之后,也被称为元空间,方法区是一个抽象概念,而JDK1.7的永久代以及之后版本的元空间都是它的具体实现;这里的数据线程共享,保存类的元数据信息,常量以及静态变量等数据;他里面还有一个常量池;常量池里的方法常量池保存了类的方法信息;【(JDK8)这里强调非堆内存,是因为这个部分内存属于本地内存,是操作系统管理;也就是它是不会被GC回收的;】
- Java栈内存:这里的数据线程私有,主要用来保存方法信息,包括参数,内部变量等;这里的GC执行频率较少;【这里的方法信息来自方法区的方法常量池,再线程执行调用方法时,会进行方法压栈】
- 虚拟机栈内存:这里的数据线程私有,基本和Java栈内存很类似,这里一般都是虚拟机内部的方法信息,也就是
native修饰的方法;
- 程序计数器:这个内存占用小,用来记录字节码指令执行的序号信息;程序的分支,跳转,循环,异常处理都是依赖它;每个线程都会维护一个计数器;
- 关于垃圾回收机制
- 垃圾回收机制主要针对方法区和JVM堆内存;因为相对于其他的比如java的栈内存,程序计数器,本地方法栈他们都是线程私有,随线程生命周期创建与销毁;一般来说,方法区里的数据一般不会回收,一般都是类加载而很少出现类卸载的情况;
- 回收的主要对象是没有被引用的对象,通常会有特定的算法来判断对象引用; 有二种判断方式:
- 引用计数:也就是统计当前对象的引用数,如果对象引用为0,则说明对象可回收;但是如果出现循环引用,就类似于死锁一样,无法回收;
- 可达性分析:也就是以对象属性为起点,进行遍历,判断是否可达,(比如 a.b.c=null,就说明b.c不可以,c就是可以被回收了,或者说a.b=null,b就可以被回收了)
- 当判断垃圾之后,就会采用特定的回收算法,主要用三种回收算法
- 标记清除算法(老年代): 就是对垃圾对象进行垃圾标记,直接清除;不过这种很容易出现内存碎片;就会导致内存一大片内存区域使用率很低;申请连续内存区域时失败;(这个适合回收内存较少的情况,整体的内存区域也比较少)
- 复制算法(新生代):其实也就是重新开辟一个与当前内存区域一样的内存区域,将旧区域的对象复制到新区域中,最后统一释放旧区域;这个可以解决内存碎片问题,不过会占用大量内存;
- 标记整理算法(老年代):也就是对内存进行重排序,使对象内存变成连续内存;但是这个搬运内存开销很大;
- 基于上述考虑,JVM采用的是分代回收,对不同的内存代采用不同的回收机制;
![]()
- 垃圾回收器(总共七个):
- Serial收集器:
- 优点:简单而高效(单线程),没有线程交互开销,在Client模式下的虚拟机中表现良好。
- 缺点:进行垃圾收集时,必须暂停其他所有的工作线程(Stop The World)。
- Serial Old收集器:
- 优点:Serial收集器的老年代版本,单线程,使用标记-整理算法,适合Client模式下的虚拟机。
- 缺点:和Serial收集器一样存在Stop The World问题。
- ParNew收集器:
- 优点:Serial收集器的多线程版本,在多CPU环境下表现更优。
- 缺点:同样存在Stop The World问题,但由于是并行工作,通常比Serial收集器有更快的垃圾收集速度。
- Parallel Scavenge收集器:
- 优点:关注吞吐量(CPU用于运行用户代码的时间与总时间的比值),可通过参数调节停顿时间或最大吞吐量。
- 缺点:同样存在Stop The World问题,但优化目标是提高吞吐量而非减少停顿时间。
- Parallel Old收集器:
- 优点:Parallel Scavenge收集器的老年代版本,多线程,使用标记-整理算法,适合Server模式下的虚拟机。
- 缺点:虽然是并行工作,但老年代的垃圾收集通常较为繁重,停顿时间可能较长。
- CMS(Concurrent Mark Sweep)收集器:
- 优点:以最短回收停顿时间为目标,适合对响应时间有较高要求的应用。
- 缺点:对CPU资源敏感,产生大量内存碎片,无法处理浮动垃圾,可能出现Concurrent Mode Failure。
- G1(Garbage-First)收集器:
- 优点:并行与并发,分代收集,空间整合,可预测的停顿时间,适合大堆内存和多处理器机器。
- 缺点:相对于其他收集器,G1有更复杂的资源管理开销。
- ZGC收集器:
- 优点:低延迟,高吞吐量,支持大内存,暂停时间不依赖于堆的大小。
- 缺点:相对于其他收集器,可能会牺牲一些吞吐量。
- 线程池:节省线程资源,提高利用率;控制并发数;线程池内部会有一个核心线程,当
keepLiveTime过后,allowCoreThreadTimeOut属性决定是否回收,默认不回收(false)。它有4个核心参数:最大线程数,最小线程数,阻塞队列,空闲线程最大存活时间;
- Atomic类:使用原子的方式操作数据,保证高并发下的数据安全;如
AtomicInteger,AtomicIntegerList;其底层实现使用CAS方式,这个是依赖于Native方法的方式;
- CAS(Compare And Set): 再设置值之前会判断是否为期望值,如果不是,说明有其他线程再操作,会重新获得,直到期望值达到,才会更新并设置;整个过程都是Native方法实现的;
Synchronized原理(同步锁):对于方法的同步锁,再JVM加载字节码文件时,会再将方法信息添加的方法常量池时,设置ACC_SYNCHRONIZED标志,当指令调用时,会检查是否是同步方法,如果是,执行线程将获得优先获得mointor(其实也就是类似于锁),当方法执行完毕释放;对于代码块,会使用两个指令标识(monitorenter,monitorexit),分别再代码块的开始与结束位置,同时会有一个计数器,当有执行线程获得锁时,计数器+1,当到结束位置时,计数器-1;当有其他线程尝试获得锁时,会判断计数器是否为0,非0标识有线程正在执行,其它线程就会处于阻塞状态,直到锁释放;Synchronized和Lock的区别:Lock是基于CAS方式实现,Sync是纯基于JVM实现;Lock提供了更加便捷的api(比如tryLock())同时也添加超时锁以及可中断(unlock())来灵活处理线程锁的获取,避免线程因等待锁释放而阻塞;ReentrantLock: 也是JUC包下的一个可重入锁;可打断,可设置超时时间;可设置条件变量;- 死锁:当两个或两个以上的线程持有对方需要的资源,且双方均未释放锁时,就会造成线程之间互相等待锁释放,导致死锁现象;
volatile关键字:Java中一个轻量级的同步关键字,保证变量的可见性,但不能保证原子性,即被修改所有线程可见;只可以修饰变量,但不会造成线程阻塞;- 悲观锁与乐观锁:乐观锁就是觉得不会出现并发安全问题,认为资源就只有它自己使用,只会在对资源修改时会判断是否是自己需要更改的值;典型的就是
CAS和版本号控制方式;悲观锁则认为,一个会发生并发安全问题,在拿到共享资源之后,就会上锁,阻塞其它线程获取;synch和ReentrantLock就是典型的悲观锁;
- 类的加载过程(延迟加载):分五个步骤,加载->验证->准备->解析->初始化;
- 加载:
ClassLoader通过类全限定名加载类的字节码文件,将字节码中的类信息封装成Class对象,并存入方法区中;
- 验证:
ClassLoader检验类命名,文件格式,变量引用是否有权限,是否有危险代码;
- 准备:为类的静态变量分配内存,并赋初值;
- 解析:解析类语义,并将引用类型变量替换为实际引用(比如内存地址);
- 初始化:执行静态代码块;这里是才是真正执行用户写的代码;除了自定义类加载器的情况下,上面的过程都是由JVM自动实现的;
- 类的加载时机(类的加载是延迟加载):首先类加载的目的是获得类的类信息,方法,变量,父类,以及接口信息到内存中,所以
- new创建(子)类实例时;
- 使用(子)类的静态方法,静态变量时;
- 反射(子)类时;
- cron表达式:一个时间表达式,再定时任务中使用较多;
- 有[秒] [分] [时] [日] [月] [周] [年] ,6位;就比如
* 1 0 * * * * ,表示每天的00:01执行任务;有几个比较常用的特殊字符;
* :表示匹配该域的任意值,可解读为 “每”。例如在[分]域使用*, 即表示每分钟都会触发定时任务。? :表示不指定值,只能用在[日]和[周]两个域。在不需要关心当前域时使用。例如要在每月 8 号触发任务,但不关心是周几,我们可以这么设置 0 0 0 8 * ?。- :表示该域的连续范围。例如在[分]域使用5-20则表示从5分到20分钟每分钟触发一次 。/ :该符号将所在域中的表达式分为两个部分,第一部分表示起始时间,第一部分表示间隔时间。例如在[分]域使用5/20则意味着从第5秒开始,每20分钟触发一次。在 [秒]域上定义 5/10 表示从第5秒开始每1 秒执行一次。
- final关键字:
- 修饰类: 这个类不能被继承;
- 修饰方法:这个方法不能被重写;对于final修饰的类,其方法也被隐式添加了final修饰;
- 修饰基本数据类型变量:这个变量的常量值不可以被修改;
- 修饰引用类型变量:这个变量的引用地址不可以修改;
- 【误区】:final修饰只是标识这个变量或类不能修改,并不是说不能修改它的状态(属性);
- Java的网络编程:
- 其实也就是使用java.net包下的相关类,建立socket连接,实现进程之间的数据通信;对于Socket连接,不依赖于任何协议,使用
Socket,InetSocketAddress与目标服务器建立连接;目标服务器使用ServerSocket监听端口,接收InputStream数据;对于Http请求(本质还是socket连接,只是添加了一个TCP/IP通信协议),使用URL根据统一资源定位符(URL)建立连接,获得输入流数据,实现数据通信;
- 关于
NIO(同步非阻塞IO)和BIO(同步阻塞IO)
- NIO: 在IO操作时的读入写出,线程可以做其他的事情,不会阻塞当前线程;BIO: 在IO操作时的读入写出时,线程会被阻塞,等待操作的完成;
- 首先说一下同步和异步【根本区别是调用者是否需要等待被调用者的执行结果】: 同步是说,当发起一个方法调用时,调用者必须等被调用者返回结果,才能继续执行;而异步是说,当发起一个方法调用时,被调用者立刻返回接收调用请求,调用者继续执行;而调用结果会通过事件等回调机制返回结果;
- 阻塞和非阻塞:阻塞是说,当发起一个请求时,在没有返回结果之前,当前线程会被挂起阻塞,等待资源获取,不能处理其他事情;非阻塞式说,当发起请求时,线程不会等待请求结果返回,再次期间它可以继续执行其他逻辑;
- NIO的实现原理:在这个IO模式中,会单独开启一个线程
selector来监听多个Channel读写操作,当有数据读入/写出时,会使用Buffer写入缓存区;调用方通过缓存区读取数据;
posted @
2024-06-24 23:26
乐可乐
阅读(
60)
评论()
收藏
举报



 浙公网安备 33010602011771号
浙公网安备 33010602011771号