
看到一个非常好的介绍coredump的文章,做个记录,
参考链接:
https://blog.csdn.net/sunxiaopengsun/article/details/72974548
什么是coredump
Coredump叫做核心转储,它是进程运行时在突然崩溃的那一刻的一个内存快照。操作系统在程序发生异常而异常在进程内部又没有被捕获的情况下,会把进程此刻内存、寄存器状态、运行堆栈等信息转储保存在一个文件里。
该文件也是二进制文件,可以使用gdb、elfdump、objdump或者windows下的windebug、solaris下的mdb进行打开分析里面的具体内容。
注:core是在半导体作为内存材料前的线圈,当时用线圈当做内存材料,线圈叫做core。用线圈做的内存叫做core memory。
ulimit
虽然我们知道进程在coredump的时候会产生core文件,但是有时候却发现进程虽然core了,但是我们却找不到core文件。
在Linux和Solaris下是需要进行设置的。
ulimit -c 可以设置core文件的大小,如果这个值为0.则不会产生core文件,这个值太小,则core文件也不会产生,因为core文件一般都比较大。
使用ulimit -c unlimited来设置无限大,则任意情况下都会产生core文件。
可以通过修改/etc/profile文件:来永久设置文件大小和文件名和存储位,在文件末尾添加:
ulimit -c unlimited
echo /data/coredump/core.%e.%p> /proc/sys/kernel/core_pattern
同时我们也可以通过ulimit修改栈区的size大小.默认是8M,当程序比较大时,就容易出现段错误.可以将其设置为200M
也是在文件末尾添加:ulimit -s 204800 重启开发板即可.
在嵌入式开发板调试过程.
gdb ./ctest
进入gdb环境后,敲
core-file /data/coredump/core.ctest.6408
敲bt命令,这是gdb查看back trace的命令
gdb 调试coredump的简单示例
#include "stdio.h"
#include "stdlib.h"
void dumpCrash()
{
char *pStr = "test_content";
free(pStr);
}
int main()
{
dumpCrash();
return 0;
}
如上代码,pStr指针指向的是字符串常量,字符串常量是保存在常量区的,free释放常量区的内存肯定会导致coredump。
首先把上面的代码拷贝到linux机器上,保存为dumpTest.c文件,gcc编译

gcc -o dumpTestdumpTest.c
运行dumpTest产生core文件

生成core文件
如上,运行dumpTest的时候进程coredump了,但是没有产生core文件
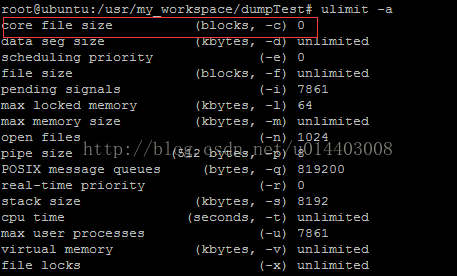
如截图所示,系统设置的core文件大小为0,此时即使产生了coredump,也不会产生core文件。
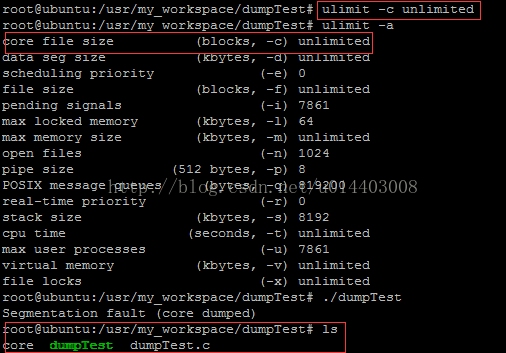
如截图所示,ulimit -c unlimited设置core文件大小后,产生了名字为core的core文件。
此时生成的core文件名称都是统一的”core”命名。
自定义core文件的文件名
上面的设置只是使能了core dump功能,缺省情况下,内核在coredump时所产生的core文件放在与该程序相同的目录中,并且文件名固定为core。很显然,如果有多个程序产生core文件,或者同一个程序多次崩溃,就会重复覆盖同一个core文件。
我们通过修改kernel的参数,可以指定内核所生成的coredump文件的文件名。例如,Easwy使用下面的命令使kernel生成名字为core_filename_time_pid格式的core dump文件:
echo /usr/core_log/core_%e_%t_%p > /proc/sys/kernel/core_pattern
echo后面内容最好不要带上引号,有的系统会把引号也带入,如下:

这样,系统是不识别该内容的,也就会导致程序coredump而不会生成core文件。

如上截图,通过设置core文件的名称以及路径,程序coredump的时候就会在指定路径按照指定的规则命名生成core文件。
可以在core_pattern模板中使用变量见下面的列表:
%%单个%字符
%p所dump进程的进程ID
%u所dump进程的实际用户ID
%g所dump进程的实际组ID
%s导致本次core dump的信号
%t core dump的时间 (由1970年1月1日计起的秒数)
%h主机名
%e程序文件名
设置永久保存
上面截图可以看到,我后面再次执行生成coredump文件的时候实际上又再次设置了ulimit-c unlimited的,因为中间机器重启了。上面的设置都只是临时的,重启之后就需要重新设置,如何设置永久生效呢?
打开/etc/security/limits.conf 文件,在该文件的最后加上两行
#下面是我的配置
@root soft core unlimited
@root hard core unlimited
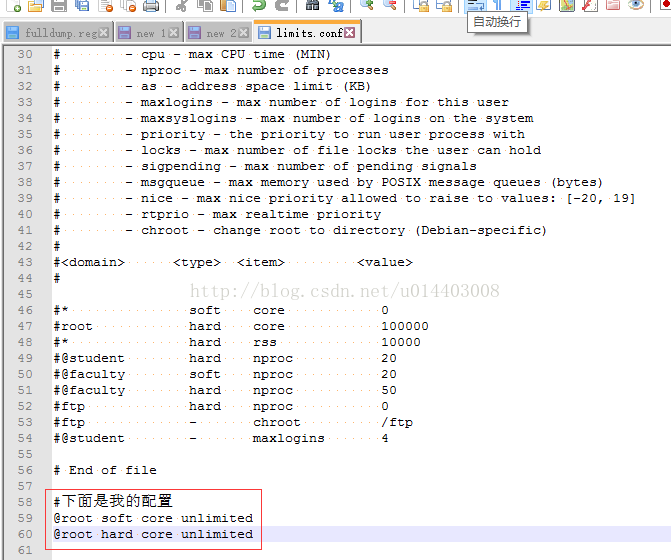
配置好后,放回原目录,重启reboot。
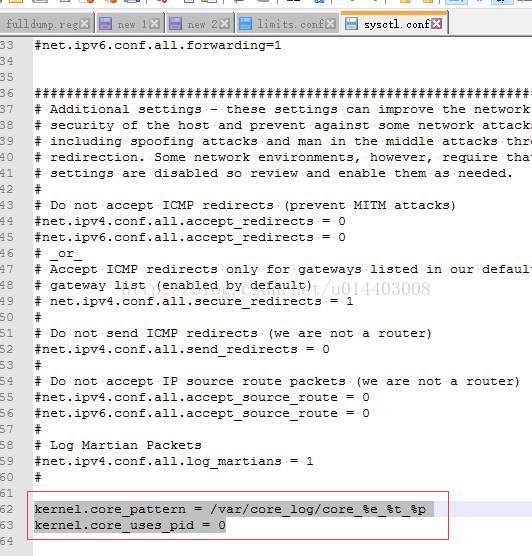
命名规则的修改在/proc/sys/kernel/core_pattern中也只是临时的,这个也是动态加载和生成的。永久修改在/etc/sysctl.conf文件中,在该文件的最后加上两行:
kernel.core_pattern = /var/core_log/core_%e_%t_%p
kernel.core_uses_pid = 0
可以使用以下命令,使修改结果马上生效。
#sysctl –p
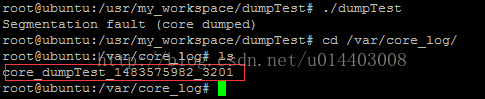
如上截图,当前生成的core文件命名按照上面定义的规则加上了程序名称、coredump时间,进程ID等信息,并放到了指定目录/var/core_log
gdb调试coredump初步尝试
gdb打开core文件的格式为
gdb程序名(包含路径) core*(core文件名和路径),如下截图
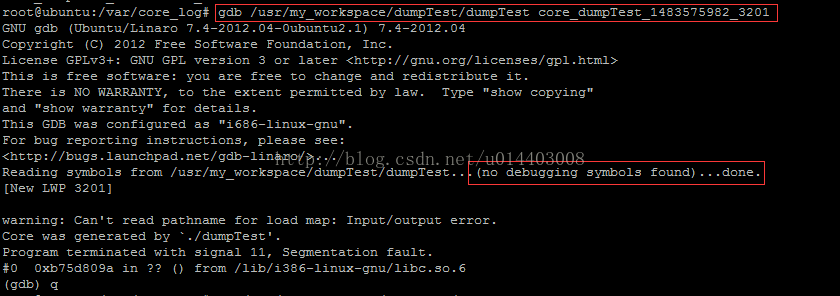
如上,gdb打开core文件时,有显示没有调试信息,因为之前编译的时候没有带上-g选项,没有调试信息是正常的,实际上它也不影响调试core文件。因为调试core文件时,符号信息都来自符号表,用不到调试信息。如下为加上调试信息的效果。
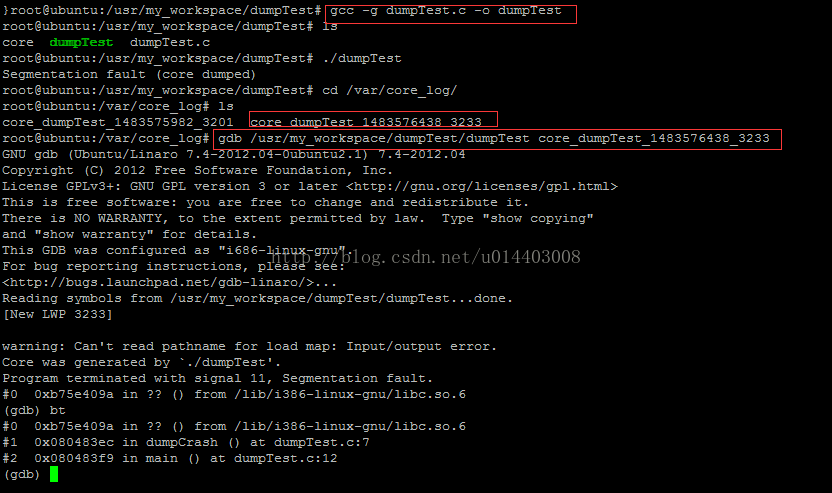
查看coredump时的堆栈
查看堆栈使用bt或者where命令
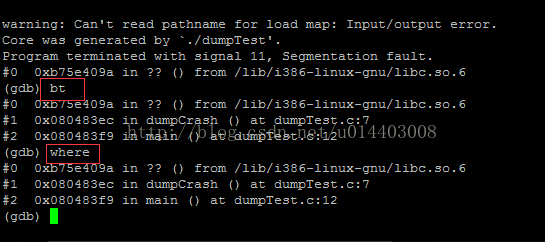
如上,在带上调试信息的情况下,我们实际上是可以看到core的地方和代码行的匹配位置。
但往往正常发布环境是不会带上调试信息的,因为调试信息通常会占用比较大的存储空间,一般都会在编译的时候把-g选项去掉。
没有调试信息的情况下找core的代码行
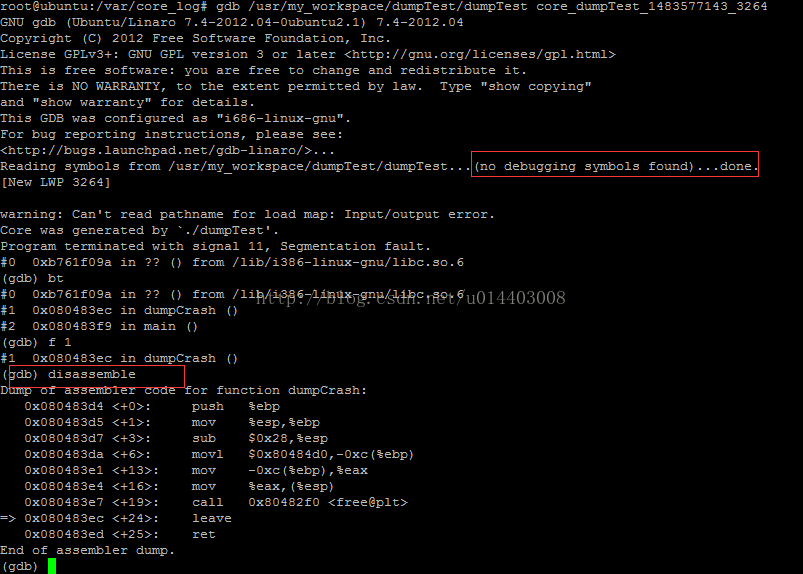
如上截图,没有调试信息的情况下,打开coredump堆栈,并不会直接显示core的代码行。
此时,frame addr(帧数)或者简写如上,f 1 跳转到core堆栈的第1帧。因为第0帧是libc的代码,已经不是我们自己代码了。
disassemble打开该帧函数的反汇编代码。
#1 0x080483ec in dumpCrash () (gdb) disassemble Dump of assembler code for function dumpCrash: 0x080483d4 <+0>: push %ebp 0x080483d5 <+1>: mov %esp,%ebp 0x080483d7 <+3>: sub $0x28,%esp 0x080483da <+6>: movl $0x80484d0,-0xc(%ebp) 0x080483e1 <+13>: mov -0xc(%ebp),%eax 0x080483e4 <+16>: mov %eax,(%esp) 0x080483e7 <+19>: call 0x80482f0 <free@plt> => 0x080483ec <+24>: leave 0x080483ed <+25>: ret End of assembler dump.
如上箭头位置表示coredump时该函数调用所在的位置

如上截图,shell echo free@plt |C++filt 去掉函数的名词修饰
不过上面的free使用去掉名词修饰效果和之前还是一样的。但是我们可以推测到这里是在调用free函数。
如此,我们就能知道我们coredump的位置,从而进一步能推断出coredump的原因。
当然,现实环境中,coredump的场景肯定远比这个复杂,都是逻辑都是一样的,我们需要先找到coredump的位置,再结合代码以及core文件推测coredump的原因。
寻找this指针和虚指针
#include "stdio.h"
#include <iostream>
#include "stdlib.h"
using namespace std;
class base
{
public:
base();
virtual void test();
private:
char *basePStr;
};
class dumpTest : public base
{
public:
void test();
private:
char *childPStr;
};
base::base()
{
basePStr = "test_info";
}
void base::test()
{
cout<<basePStr<<endl;
}
void dumpTest::test()
{
cout<<"dumpTest"<<endl;
delete childPStr;
}
void dumpCrash()
{
char *pStr = "test_content";
free(pStr);
}
int main()
{
dumpTest dump;
dump.test();
return 0;
}
如上代码,实现了一个简单的基类和一个子类。在main函数里定义一个子类的实例化对象,并调用它的虚函数方法test,test里由于直接delete没有初始化的指针childPStr,肯定会造成coredump。本次我们就希望通过dump文件,找到子类dumpTest的this指针和虚函数指针。
和gcc一样,使用g++ -o DumpCppTest dumpTest.cpp编译cpp文件生成可执行程序。
./DumpCppTest 执行该程序,程序因为直接delete未初始化的指针,肯定会coredump。生成core文件如下
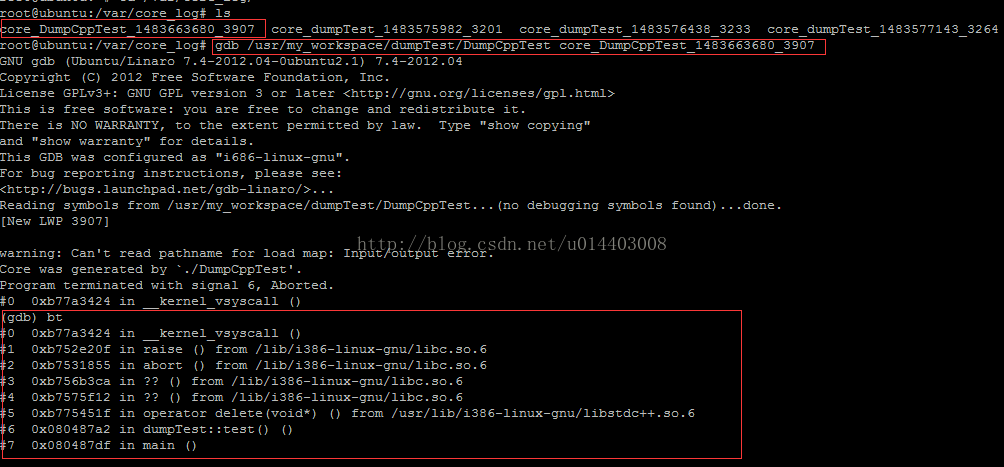
如上,使用gdb打开core文件,同时bt打开core的堆栈信息。
从堆栈可以看到,最后两帧为我们程序自己的函数,其他的都是libc的代码。
f 6 调到第6帧上,之后info frame查看堆栈寄存器信息。
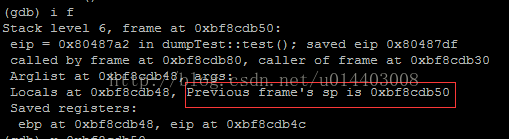
如上截图所示,前一帧的栈寄存器地址是0xbf8cdb50,它的前一帧也就是main函数的位置,main函数里调用dump.test()的位置,那我们在这个地址上应该可以找到dump的this指针和它的虚指针,以及虚指针指向的虚函数表
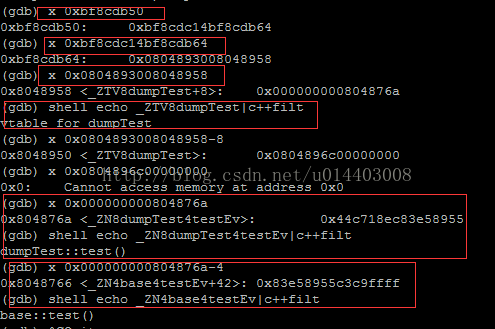
如图所示,0xbf8cdb50地址指向的是前一帧保存dump信息的位置,0xbf8cdc14bf8cdb64就表示dump的this指针,而this指针指向的第一个8字节0x0804893008048958就表示虚指针,如上,通过x 0x0804893008048958看到_ZTV8dumpTest+8的内容。
shell echo_ZTV8dumpTest|c++filt 可以看到“vtable for dumpTest”的内容。这个就表示dumpTest的虚函数表。
从上面也可以看到,这个地址指向的是虚函数表+8的偏移位置,而这个位置0x000000000804876a 通过x 0x000000000804876a 可以看到,存储的内容就是

dumpTest::test() 函数。
这里也印证了,在继承关系里,基类的虚函数是在子类虚函数的前面。

如上,x 0x000000000804876a-4 就可以看到dumpTest的基类base的虚函数test的位置。
如上,在实际问题中,C++程序的很多coredump问题都是和指针相关的,很多segmentfault都是由于指针被误删或者访问空指针、或者越界等造成的,而这些都一般意味着正在访问的对象的this指针可能已经被破坏了,此时,我们通过去寻找函数对应的对象的this指针、虚指针能验证我们的推测。之后再结合代码寻找问题所在。
gdb 查看core进程的所有线程堆栈
#include <iostream>
#include <pthread.h>
#include <unistd.h>
using namespace std;
#define NUM_THREADS 5 //线程数
int count = 0;
void* say_hello( void *args )
{
while(1)
{
sleep(1);
cout<<"hello..."<<endl;
if(NUM_THREADS == count)
{
char *pStr = "";
delete pStr;
}
}
} //函数返回的是函数指针,便于后面作为参数
int main()
{
pthread_t tids[NUM_THREADS]; //线程id
for( int i = 0; i < NUM_THREADS; ++i )
{
count = i+1;
int ret = pthread_create( &tids[i], NULL, say_hello,NULL); //参数:创建的线程id,线程参数,线程运行函数的起始地址,运行函数的参数
if( ret != 0 ) //创建线程成功返回0
{
cout << "pthread_create error:error_code=" << ret << endl;
}
}
pthread_exit( NULL ); //等待各个线程退出后,进程才结束,否则进程强制结束,线程处于未终止的状态
}
如上代码,简单示意C++多线程。
在linux下使用g++直接编译该cpp文件会报错,报错信息如下:

会报 undefined reference to `pthread_create' 的错误信息,解决办法如下:
使用 g++ -o MultiThreadDump MultiThread.cpp -lpthread 编译,编译参数上带上-lpthread即可。

运行./MultiThreadDump
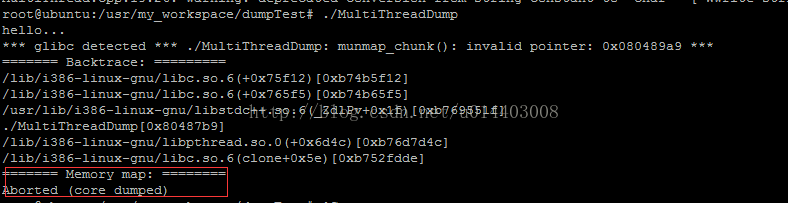
由于上面代码里在count等于5的时候,会delete一个未初始化的指针,肯定会coredump。
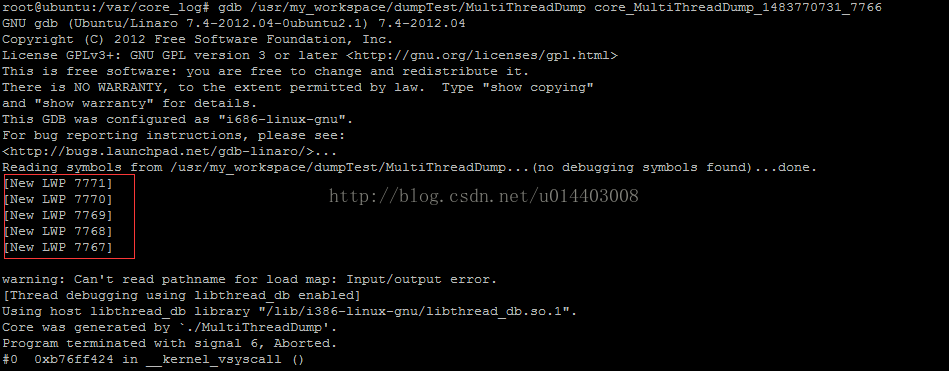
如上,gdb打开coredump文件,能看到5个线程LWP的信息。
如何,查看每个线程的堆栈信息呢?
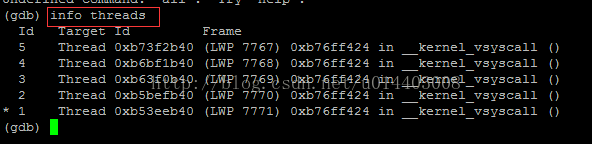
首先,info threads查看所有线程正在运行的指令信息
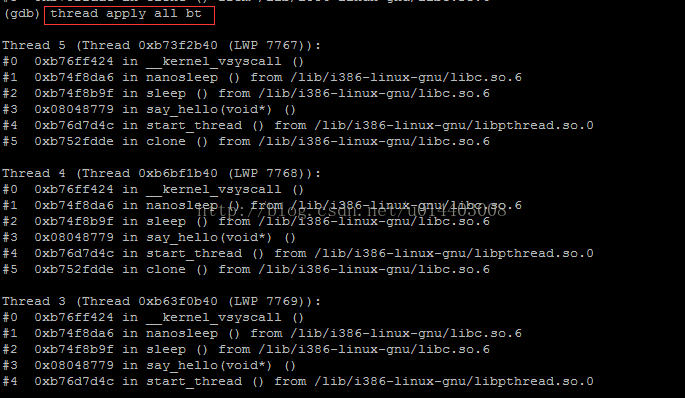
thread apply all bt打开所有线程的堆栈信息
查看指定线程堆栈信息:threadapply threadID bt,如:
thread apply 5 bt
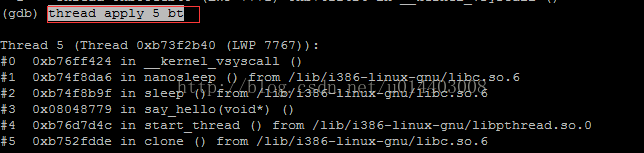
进入指定线程栈空间
thread threadID如下:
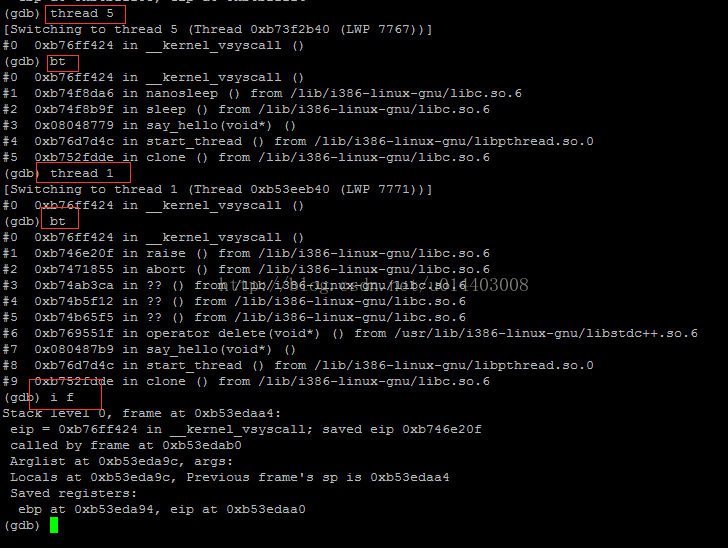
如上截图所示,可以跳转到指定的线程中,并查看所在线程的正在运行的堆栈信息和寄存器信息。
总结:
如上,简单介绍了3种不同情况下的gdb调试coredump文件的情况,基本涵盖了调试coredump问题时的大部分会用到的gdb命令。
gdb调试coredump,大部分时候还是只能从core文件找出core的直观原因,但是更根本的原因一般还是需要结合代码一起分析当时进程的运行上下文场景,才能推测出程序代码问题所在。
因此gdb调试coredump也是需要经验的积累,只有有一定的功底和对于基础知识的掌握才能在一堆二进制符号的core文件中找出问题的所在。
--------------------- 本文来自 sunxiaopengsun 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/sunxiaopengsun/article/details/72974548?utm_source=copy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号