

09-分布式缓存
一、使用分布式缓存Redis
(一)分布式缓存和Redis
1、多级缓存
在一个简单的请求链路中,会经过Nginx、Redis、Tomcat、数据库,其中Nginx、Redis、Tomcat都有缓存存在,这也是常说的多级缓存。

2、缓存的作用与应用场景
使用缓存主要是为了煎炒访问时间和减少计算时间
缓存应用场景:
热点数据:这么比较好理解,对于热点数据的读取要尽量做到快
读写比高的数据:这个也比较好理解,对于读写比高的数据,也要使用缓存
共享数据:对于某些需要共享数据的场景来说,可以将数据放入分布式缓存中,从而达到共享数据的效果
数据最终一致性:对于某些场景来说,将数据放入分布式缓存,可以解决数据的最终一致性的问题,但是一般不会这么做。
3、缓存结构:
对于缓存来说,主要是用空间换时间,如下图所示,key为hello,value为world,使用Hash算法计算key对应的Hash值,最后决定其存储位置。实际上无论是EhCache、Guava、Caffeine、Redis、Hazelcast等缓存都是使用的这个思路,只是内存数据结构和时间复杂度的区别,所谓内存数据结构就是数据怎么存储,时间复杂度就是算法的好坏。

4、分布式环境和缓存
在分布式环境下,就要使用分布式缓存,常见的分布式缓存有Hazelcast、Memcache、Redis、etcd等。
其中Hazelcast和Memcache是比较早期的分布式缓存代表,其架构如下图所示,主要是有多台缓存服务器,但是所有的缓存服务器都要更新同步数据。
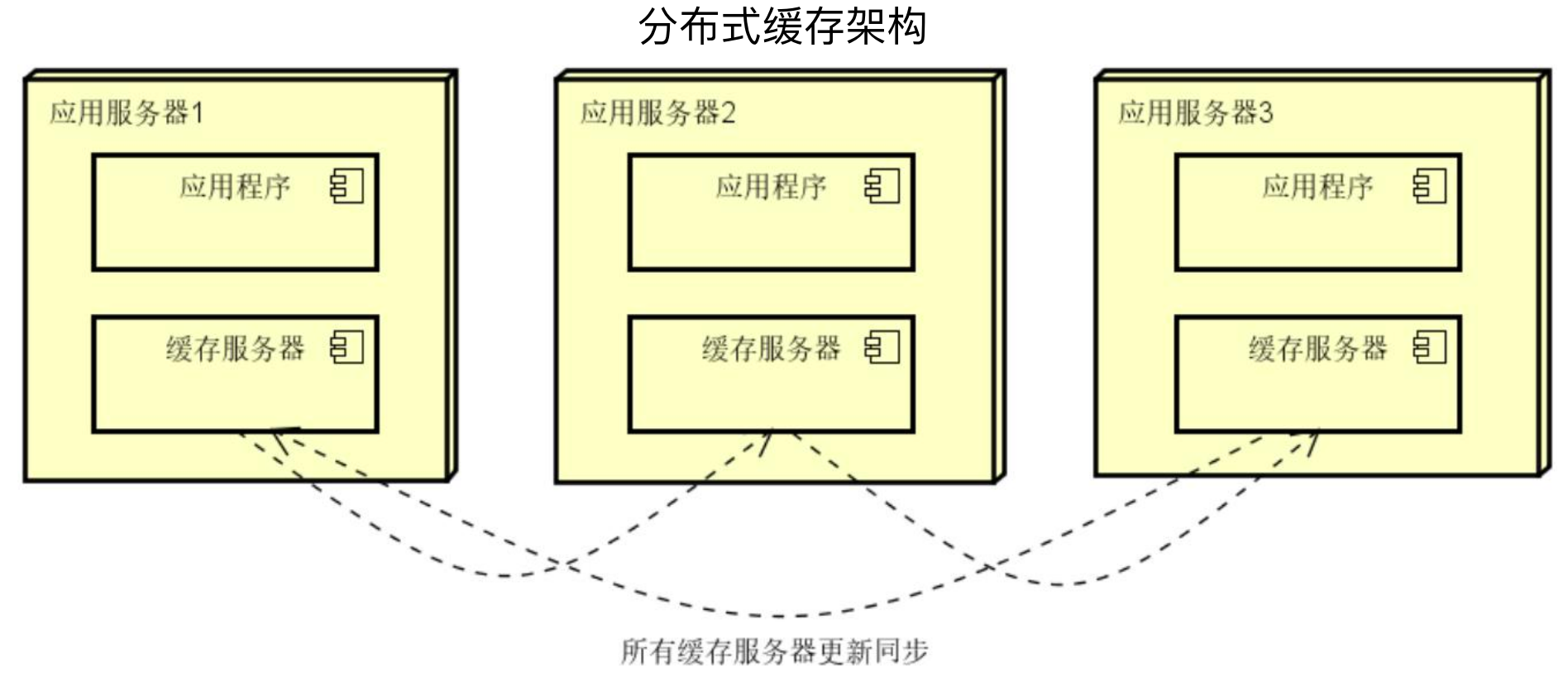
在互联网场景下,数据越来越多,服务期间同步数据的成本越来越高,像Hazelcast、Memcache这种需要所有服务器都同步数据的分布式缓存架构已经不能满足业务需要。
Redis的架构如下图所示,每台服务器上存储的数据都是独立的,客户端会计算缓存的存储地址并直接路由访问到对应的缓存服务器。

5、Redis特性
对于Redis来说,可以使用六个词简单概括,分别是:NoSQL、数据结构、高性能、持久化、高可用、单线程
NoSQL:Redis是一个NoSQL数据库
数据结构:Redis的数据结构非常丰富,包括基本的String、List、Set、Zset、Hash,高级的HyperLoglog等。
高性能:Redis使用了IO多路复用的事件驱动模式来实现Reactor架构
持久化:在之前的分布式缓存中间件中,例如Memcached,都是纯内存的缓存,但是Redis提供了RDB和AOF两种持久化方式
单线程:Redis使用了IO多路复用,同时使用单线程来避免多线程上线程切换带来的开销
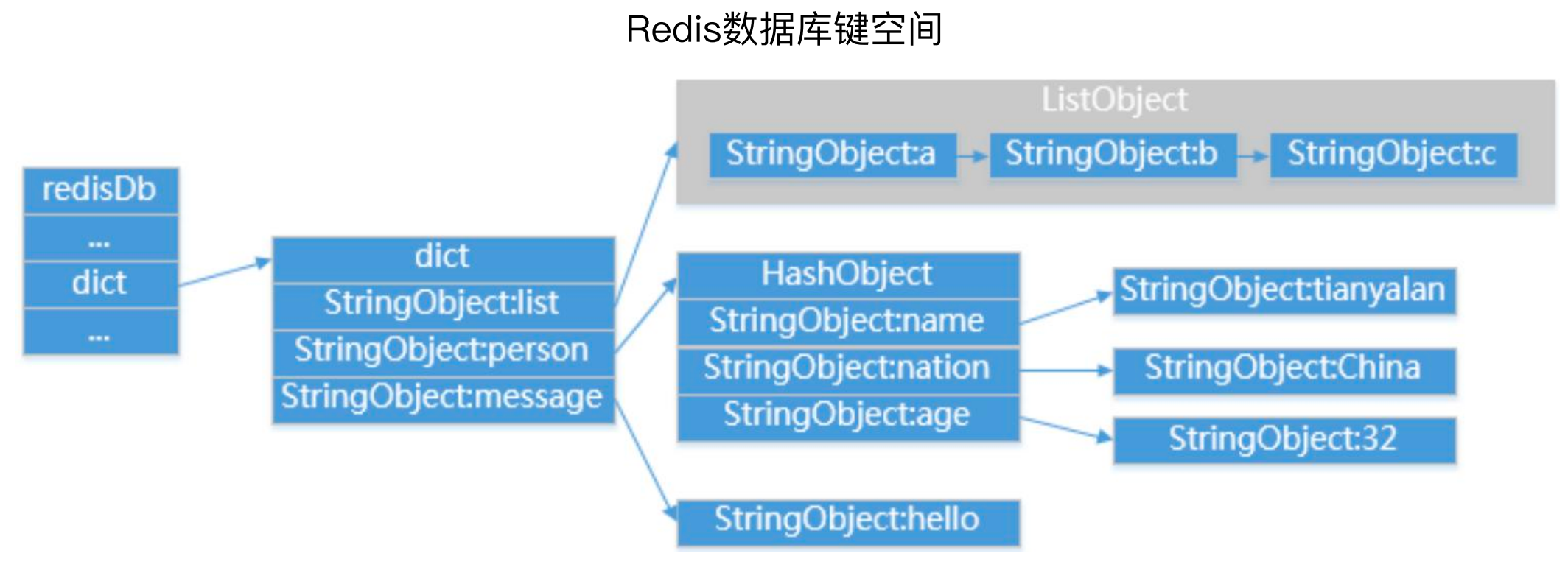
6、Redis 数据库
Redis的数据库键空间,其实就是一个数据字典,首先有数据库redisDb的概念,Redis默认有16个数据库,默认使用0号数据库,但是也可以进行设置。
如下图所示,字典dict中存储了三个键值对,分别是String-list、string-hash、string-string,在list中有多个String组成,在Hash中又有多个键值对。
7、Redis键生存时间
即缓存键过期处理策略,这里对应了一个经典的面试题,就是Reids key过期后的处理粗略是什么。
定时删除:针对键设置定时器,主动占用CPU时间,时效性最高,但是性能最差
惰性删除:获取键时判断是否过期,被动占用内存。时效性最低,但是性能最好
定期删除:隔一段时间扫描数据库,主动折中方案,是定时删除和惰性删除的折中
鉴于时效性和性能的平衡考虑,一般选用定期删除作为主要的处理手段,并使用定时删除或惰性删除来辅助。
8、Redis事件类型
这个也是一个经典的面试题,就是Redis为什么性能这么高,或者Redis为什么这么快。
Redis服务器是一个事件驱动程序,而且是一个事件驱动的单线程程序;在RocketMQ中,事件可以改变业务状态,在Redis中事件可以改变数据状态。
在Redis中有两种事件类型,分别为文件类型和时间类型,文件类型是套接字操作抽象,时间类型是定时操作抽象;这句话本身就挺抽象的,针对这两点,稍微做个介绍。但是总体来说,Redis的快一方面是因为其基于内存来处理的,另一方面就是因为其是基于事件驱动模型的。
(1)文件事件
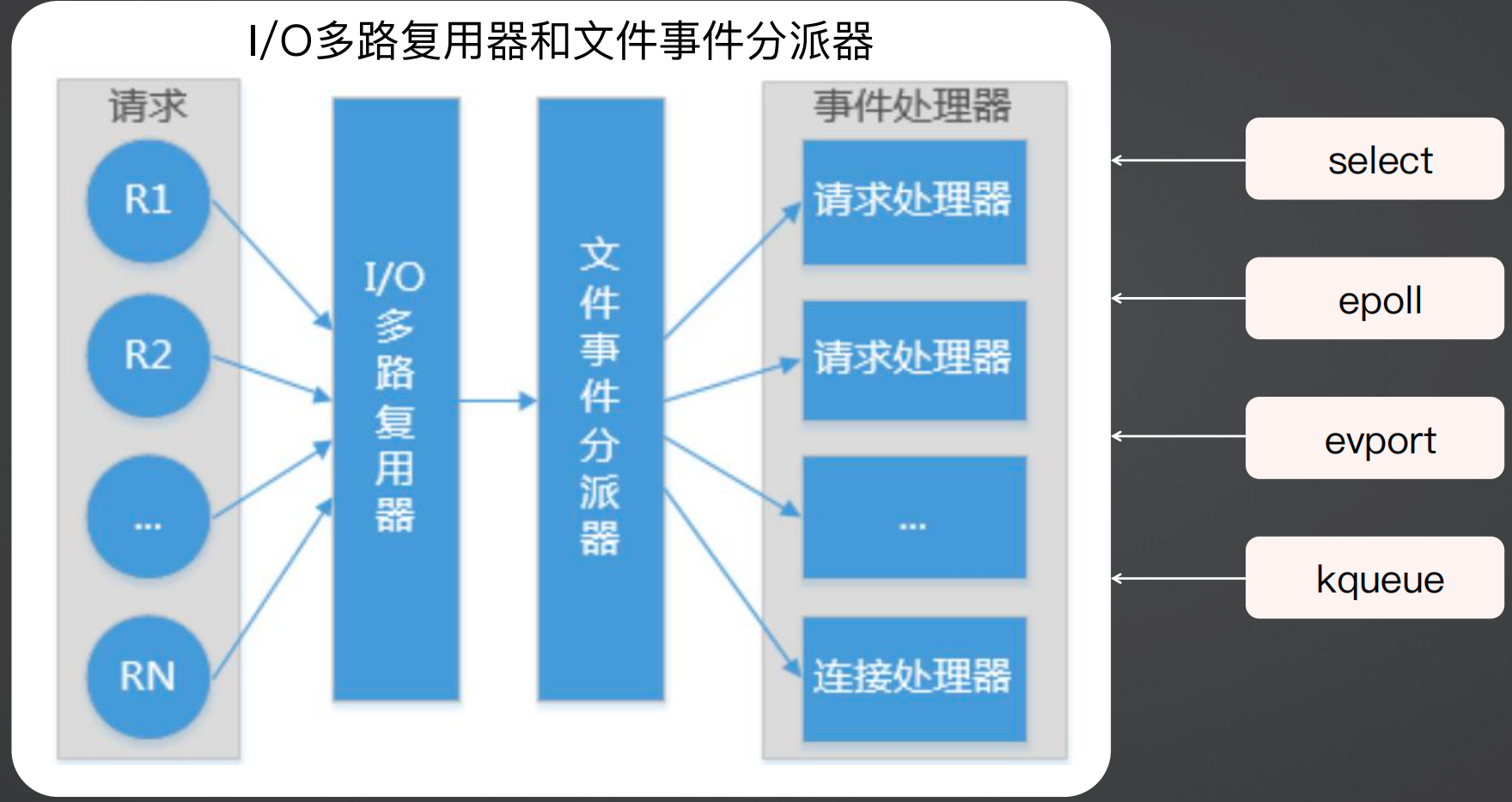
文件事件使用了Reactor架构,原理是定义事件循环,利用操作系统事件分离器(sumux_event)支持单线程在一系列事件源(event_loop)上同步等待事件,事件循环将事件逐个分发对应的事件处理程序(handle_event),后者对“它的”事件作出同步反应。这里说了两个”同步“,实际上就是在强调Reactor模型是同步非阻塞的模型,例如Netty中收发消息的handler仍然是同步处理的流程,因此不能在收发消息的handler中阻塞处理业务逻辑,例如操作数据库等操作,而应该使用异步或者线程池的方式。
Reactor模式是目前底层数据操作高性能的标准操作模式。

Redis也是这么做的,当请求过来后,使用Reactor模式的事件分离器dumux_event来做IO多路复用,将请求转发到文件事件进行分派器进行分派,分派到对应的请求处理器处理,这个请求处理器是Redis自带的类似于Netty中的Event Loop中的handler。
这是操作系统自带的模式,例如select、poll、epoll、evport、kqueue等,不同的操作系统支持的不一样,这也是为什么服务器要使用linux的原因,因为linux对于IO多路复用支持会更好一些,那么有的代码在windows上跑起来性能一般般,而在Linux上跑出来的性能就会很好。
(2)时间事件:
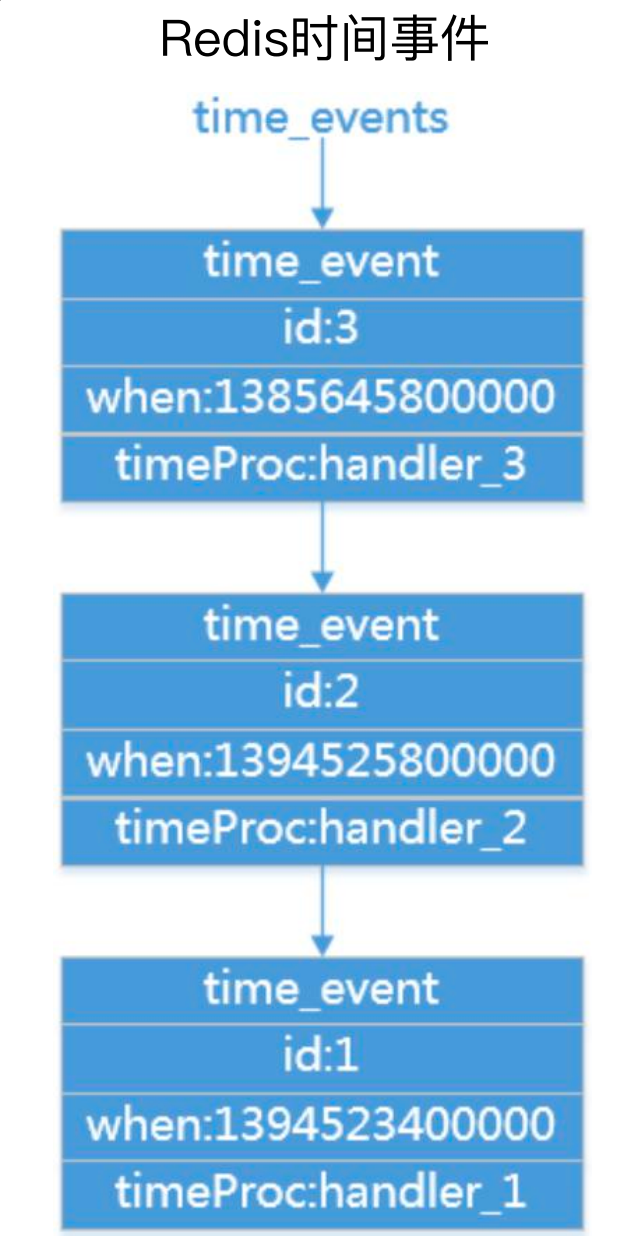
在Redis中内置了serverCron,每一秒执行一次,用于 更新服务器时间缓存、更新LRU时间、更新服务器每秒执行命令次数、管理客户端资源、管理数据库资源、检查持久化操作的运行状态等操作;相当于有一个不停的轮训机制,检查系统当中各种数据的状态,看有没有需要触发的,如果有就调用对应的处理器进行处理。
如下图所示,每一个时间都对应了一个事件,当轮询到时间一个时间后,就会获取对应的handler进行处理。
IO 触发的事件叫文件事件,系统内部轮询的事件叫时间事件,这两个事件模型共同组成了Redis的事件模型。
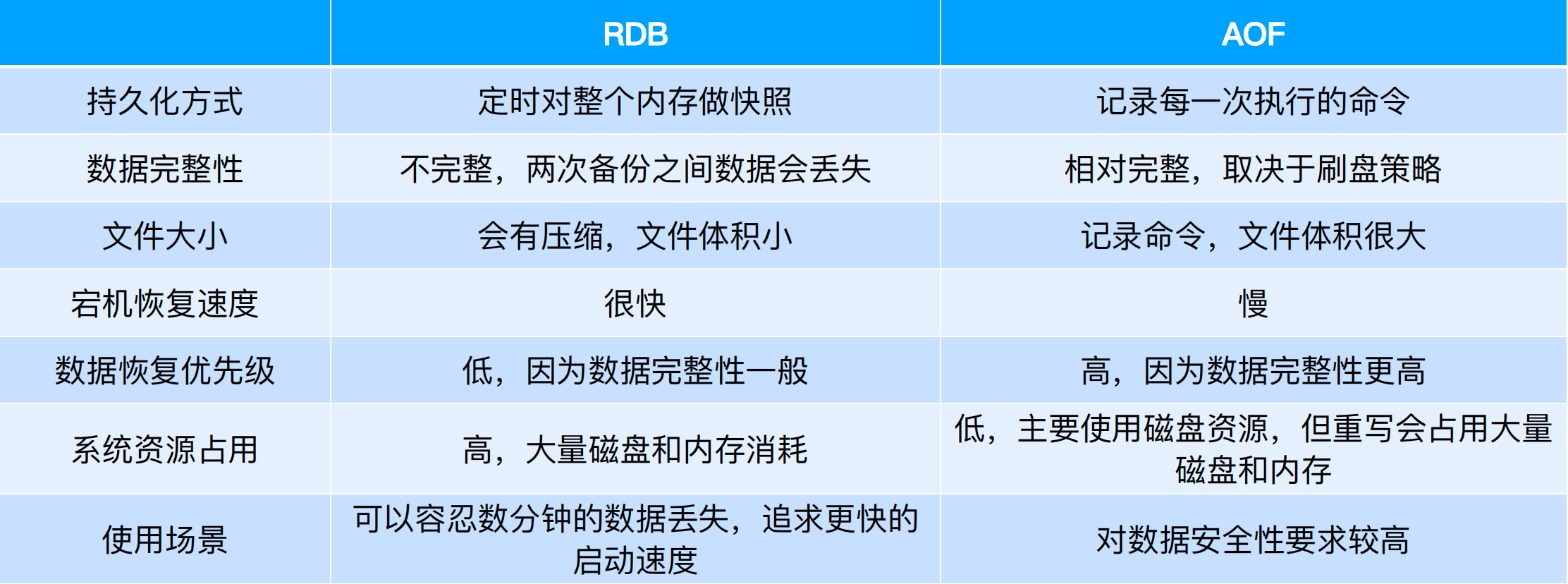
9、持久化
Redis提供了AOF和RDB两种持久化方式,具体的优缺点对比如下图所示。
10、集群:
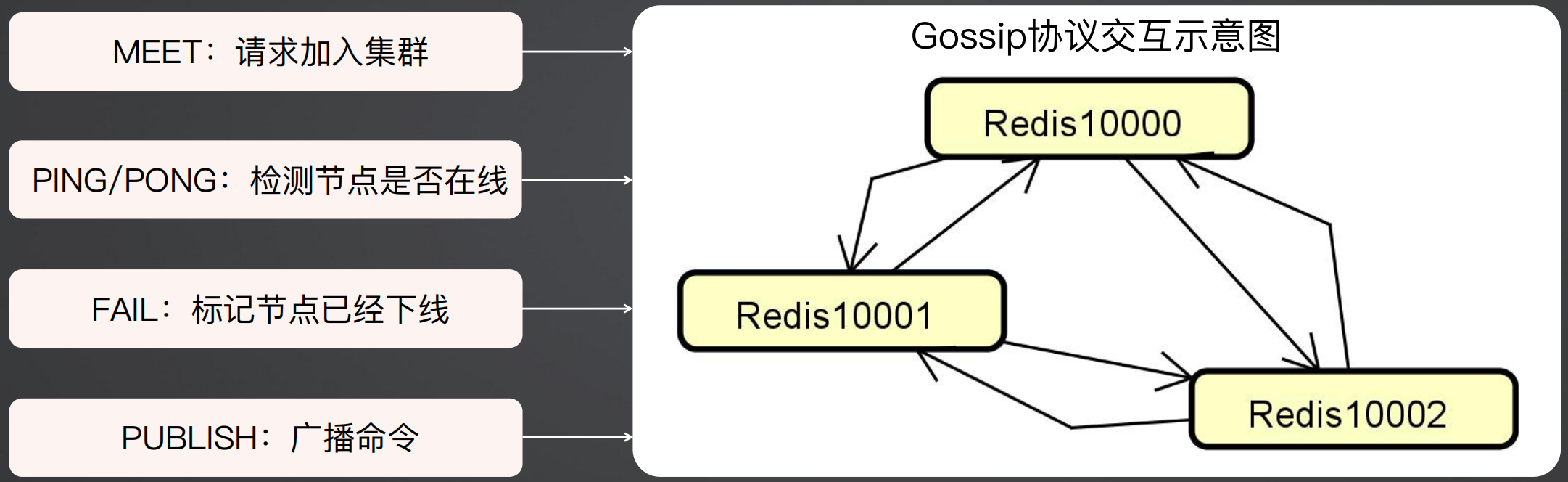
这个也有一个经典的面试题,就是Redis集群是用什么方式保证通信的。
在Redis集群中,使用的是Gossip协议进行通讯的,每个Redis节点每秒钟都会向其他的节点发送PING,然后被PING的节点会回一个PONG。
主要有MEET、PING/PONG、FAIL、PUBLISH四个命令组成了整个通信过程。
MEET:请求加入集群
PING/PONG:检测节点是否在线
FAIL:标记节点已经下线
PUBLISH:广播命令
(二)Redis数据结构
Redis提供了五大基础数据结构:Strings、Lists、Sets、Hashes、Sorted Sets
1、Lists
有序可重复的集合,根据插入顺序存储,实现简单Queue,提供了从两端Push和Pop操作

2、Sets
不能存储重复键、无序

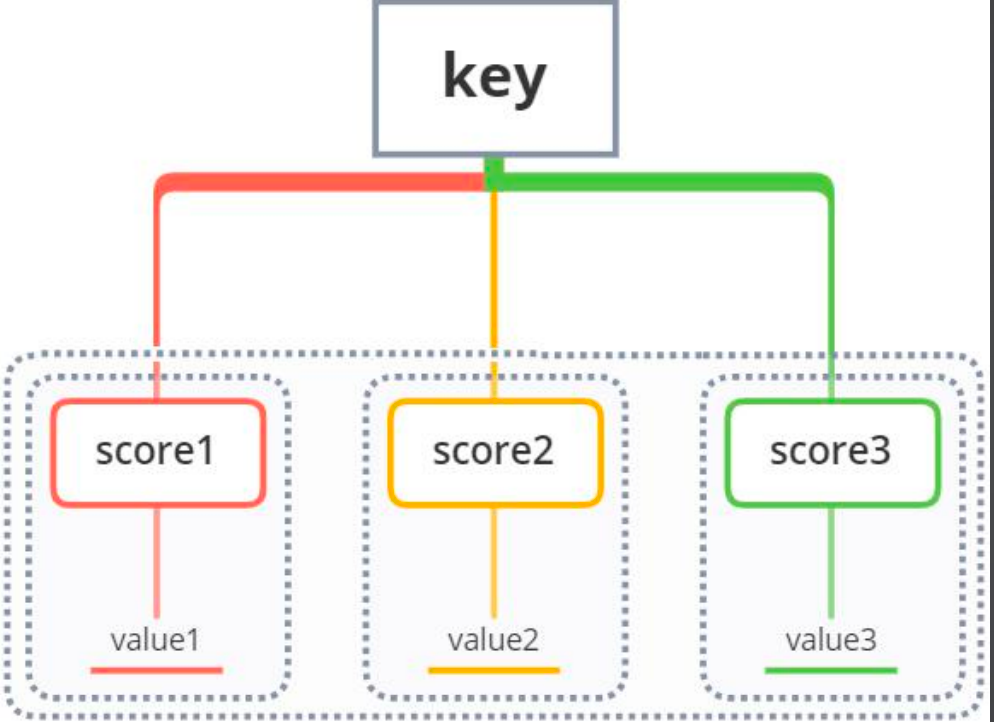
3、Sorted Sets(ZSET)
Value与一个Score关联,有序,高性能
ZADD:添加带有分值的成员到ZSET
ZRANGE:根据位置从ZSET中获取一定范围内的项
ZRANGEBYSCORE:根据分值从ZSET中获取一定范围内的项
ZREM:从ZSET中移除已存在的项
4、Hashes
映射String键和String值,适合表述业务对象
(三)Redis客户端集成
1、Redis客户端工具
Jedis:API比较全面;使用阻塞的I/O,方法调用都是同步的,不支持异步;客户端实例不是线程安全的,所以需要通过连接池来使用Jedis
lettuce:支持同步异步通信模式;API线程安全
Redisson:集成性框架,提供了很多开箱即用分布式相关操作服务,如分布式锁、分布式集合等
2、Spring Data Redis
Spring Data Redis 并不是客户端,只是对客户端做了集成,使用Spring Data Redis 主要需要设置连接工厂和序列化方式。
连接工厂是ConnectionFactory,对应的工厂类有 JedisConnectionFactory、LettuceConnectionFactory
序列化方式有JdkSerializationRedisSerializer(默认,最常用的序列化策略)、StringRedisSerializer(最轻量级和高效的策略)、 JacksonJsonRedisSerializer(封装使用较复杂)
3、RedisTemplate
使用 Spring Data Redis 需要通过配置来设置 RedisTemplate,配置内容主要就是连接工厂的序列化。
下面的示例是使用了具体的业务类LocalCustomerStaff进行配置,这样会造成多个业务场景要用缓存时需要创建多个配置类,如果是这种情况,可以将Value设置为String,在外部进行序列化和反序列化。
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, LocalCustomerStaff> redisTemplate(RedisConnectionFactory connectionFactory) {
// 创建RedisTemplate对象 R
edisTemplate<String, LocalCustomerStaff> redisTemplate = new RedisTemplate<>();
// 设置ConnectionFactory
redisTemplate.setConnectionFactory(connectionFactory);
// 设置Key的序列化 - String 序列化
RedisSerializer.string() =>StringRedisSerializer.UTF_8 redisTemplate.
setKeySerializer(RedisSerializer.string());
// 设置Value的序列化 - JSON 序列化
RedisSerializer.json() =>GenericJackson2JsonRedisSerializer redisTemplate.
setValueSerializer(RedisSerializer.json());
return redisTemplate;
}
}
4、RedisTemplate核心方法
RedisTemplate提供了是否存在key、删除key、过期时间等方法。
redisTemplate.hasKey(key); //判断是否有key所对应的值,有则返回true,没有则返回
redisTemplate.delete(key); //删除单个key值
redisTemplate.delete(keys); //删除一组key值
redisTemplate.expire(key,timeout,unit); //设置过期时间
redisTemplate.expireAt(key,date); //设置过期时间
redisTemplate.keys(pattern); //查找匹配的key值,返回一个Set集合类型
针对于String等类型,还提供了封装方法,具体如下所示。
opsForValue.get(key); //有则取出key值所对应的值
opsForValue.get(key,start,end); //返回key中字符串的子字符
opsForValue.setIfAbsent(key,value); //重新设置key对应的值,如果存在返回false,否则返回true
opsForValue.set(key,value); //设置当前的key以及value值
opsForValue.set(key,value,timeout,unit); //设置当前的key以及value值并且设置过期时间
opsForValue.multiGet(keys); //批量获取值
(四)客服系统案例演进
这里分析一下客服系统案例中可以应用缓存的场景。
1、IM登录信息存储
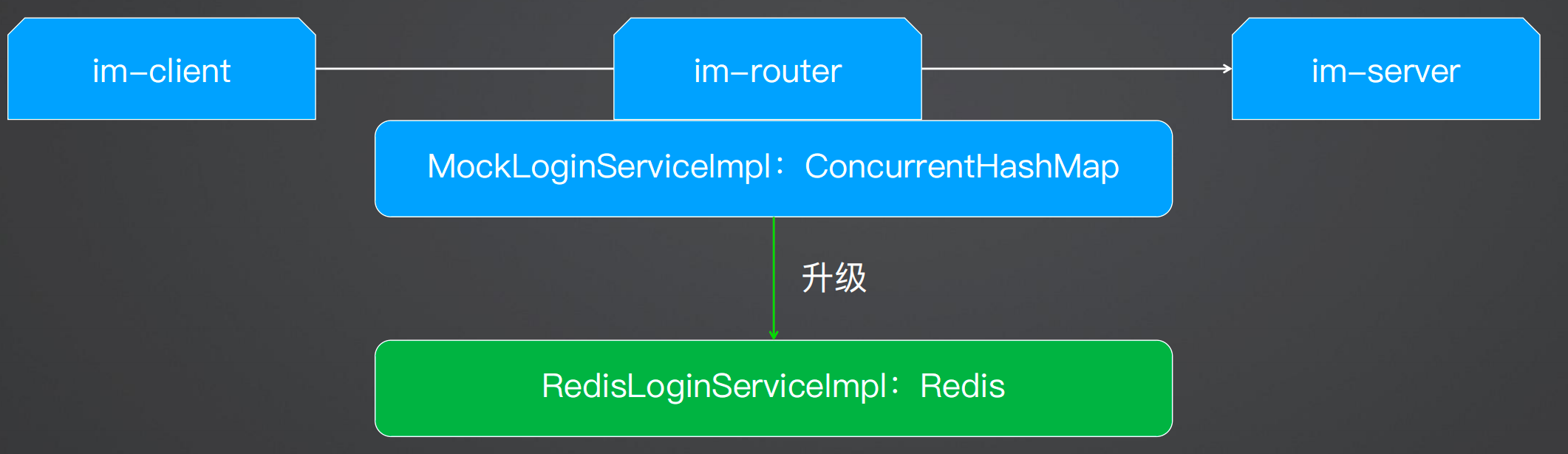
在之前提到 IM 高伸缩性架构时,需要存储登录状态,即客户端和服务端的关联关系,在之前的案例演示中将其存在了本地缓存(HashMap)中,但是一旦服务重启后登录信息就会丢失,因此这个就可以存储在分布式缓存中。
根据上述分析,最终的结果如下图所示,在无状态的路由层中将客户端的登录信息存储在分布式缓存中。当客户端发布消息时,需要查询分布式缓存用户是否登录。
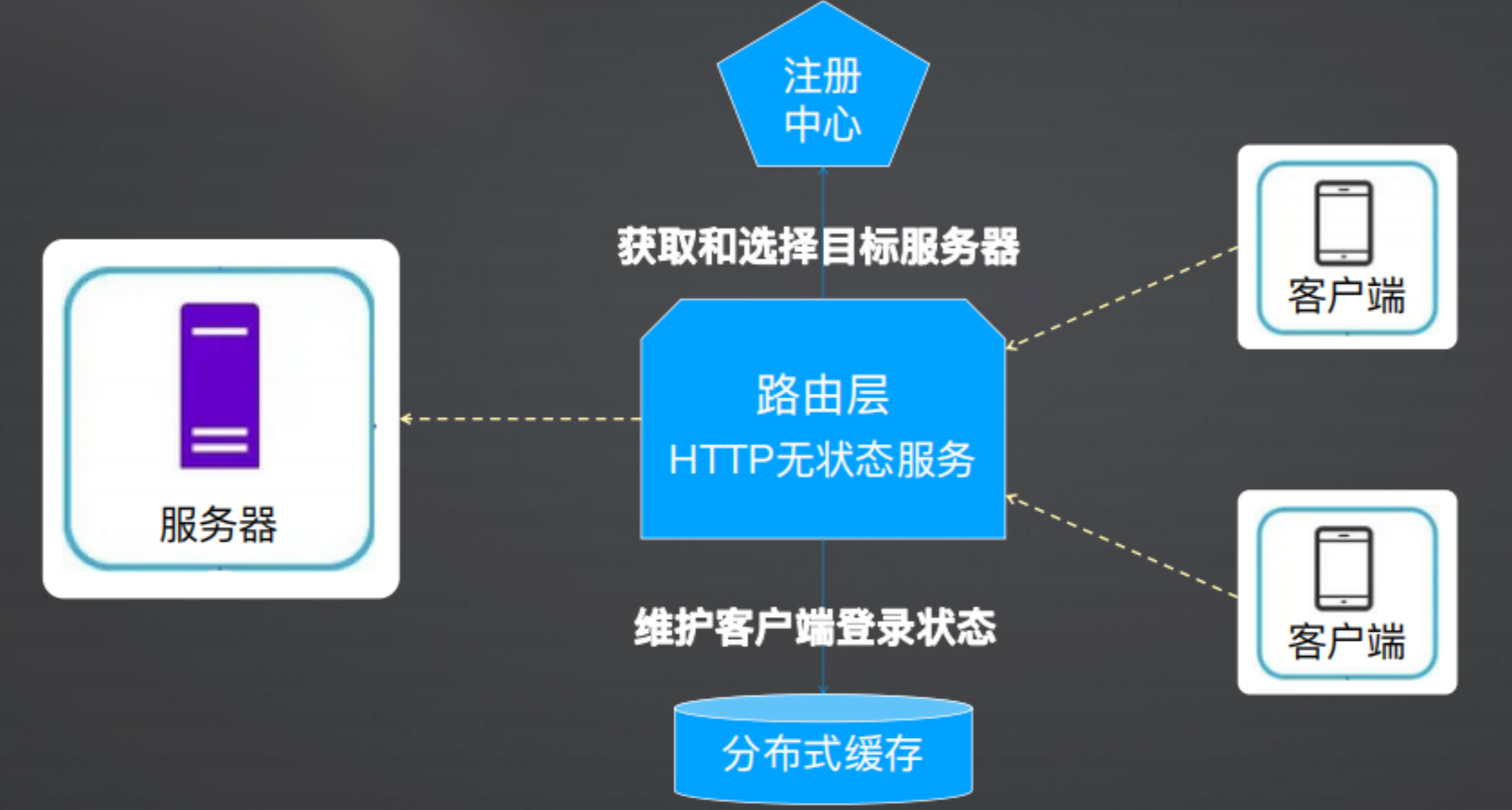
在之前做的时候,系统设计时,在客户端和服务端通信时,经过了路由层,在路由层的类MockLoginServiceImpl 中使用ConcurrentHashMap存储了 IM登录信息,这次演进架构本身并没有发生变化,主要是将内存存储改成Redis缓存:
(1)引入redis
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</dependency>
<!-- redis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>
(2)配置信息
spring:
redis:
host: 127.0.0.1
port: 6379
lettuce:
pool:
max-active: 8
max-wait: -1
max-idle: 8
min-idle: 0
connect-timeout: 10000
database: 0
(3)配置信息
配置RedisTemplate,由于该场景只针对于登录信息的存储,因此value直接使用了IMLoginRequest。
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, IMLoginRequest> redisTemplate(RedisConnectionFactory connectionFactory){
RedisTemplate<String, IMLoginRequest> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(connectionFactory);
// key 序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
// value 序列化
redisTemplate.setValueSerializer(RedisSerializer.json());
return redisTemplate;
}
}
(4)专门操作数据的接口与实现类
@Repository
public interface LoginRedisRepository {
void saveLogin(IMLoginRequest imLoginRequest);
void updateLogin(IMLoginRequest imLoginRequest);
void deleteLogin(String userId);
IMLoginRequest findLoginByUserId(String userId);
Boolean isLogin(String userId);
List<IMLoginRequest> getAllIMLoginRequest();
}
@Repository
public class LoginRedisRepositoryImpl implements LoginRedisRepository{
@Autowired
private RedisTemplate<String, IMLoginRequest> redisTemplate;
private static final String KEY_PREFIX = "ImLogin:";
@Override
public void saveLogin(IMLoginRequest imLoginRequest) {
redisTemplate.opsForValue().set(KEY_PREFIX + imLoginRequest.getUserid(), imLoginRequest);
}
@Override
public void updateLogin(IMLoginRequest imLoginRequest) {
redisTemplate.opsForValue().set(KEY_PREFIX + imLoginRequest.getUserid(), imLoginRequest);
}
@Override
public void deleteLogin(String userId) {
redisTemplate.delete(KEY_PREFIX + userId);
}
@Override
public IMLoginRequest findLoginByUserId(String userId) {
return redisTemplate.opsForValue().get(KEY_PREFIX + userId);
}
@Override
public Boolean isLogin(String userId) {
return redisTemplate.hasKey(KEY_PREFIX + userId);
}
@Override
public List<IMLoginRequest> getAllIMLoginRequest() {
Set<String> set = redisTemplate.keys(KEY_PREFIX + "*");
List<IMLoginRequest> imLoginRequests = redisTemplate.opsForValue().multiGet(set);
return imLoginRequests;
}
}
(5)业务逻辑
@Service("redis")
@Primary
public class RedisLoginServiceImpl implements LoginService {
@Autowired
private LoginRedisRepository loginRedisRepository;
@Override
public void login(IMLoginRequest request) {
loginRedisRepository.saveLogin(request);
}
@Override
public void logout(String userId) {
loginRedisRepository.deleteLogin(userId);
}
@Override
public boolean hasLogin(String userId) {
return loginRedisRepository.isLogin(userId);
}
@Override
public IMLoginRequest getLoginInfo(String userId) {
return loginRedisRepository.findLoginByUserId(userId);
}
@Override
public Map<String, IMLoginRequest> getAllIMLoginRequests() {
List<IMLoginRequest> allIMLoginRequests = loginRedisRepository.getAllIMLoginRequest();
Map<String, IMLoginRequest> loginRequestMap = new HashMap<>(allIMLoginRequests.size());
for(IMLoginRequest imLoginRequest: allIMLoginRequests){
loginRequestMap.put(imLoginRequest.getUserid(), imLoginRequest);
}
return loginRequestMap;
}
}
2、工单服务LocalCustomerStaff缓存处理
在之前的分析中,如果客服人员信息发生变更,则会发生一个消息,工单系统会在本地存储一份,之前存储的是mysql,会从mysql中获取数据,校验一些数据,由于客服人员信息的变更不频繁,但是频繁的查询数据库会造成性能的损耗,因此将其升级为从Redis查询。代码与上面类似,不再做展示。

二、Spring Cache缓存抽象和实现原理
(一)Spring缓存的抽象和使用过程
Spring缓存组件的核心优势在于设计并实现了一个抽象层,Spring提供了统一的缓存使用API,无论用户使用的是哪一个缓存组件,都可以使用同一的缓存API进行处理。
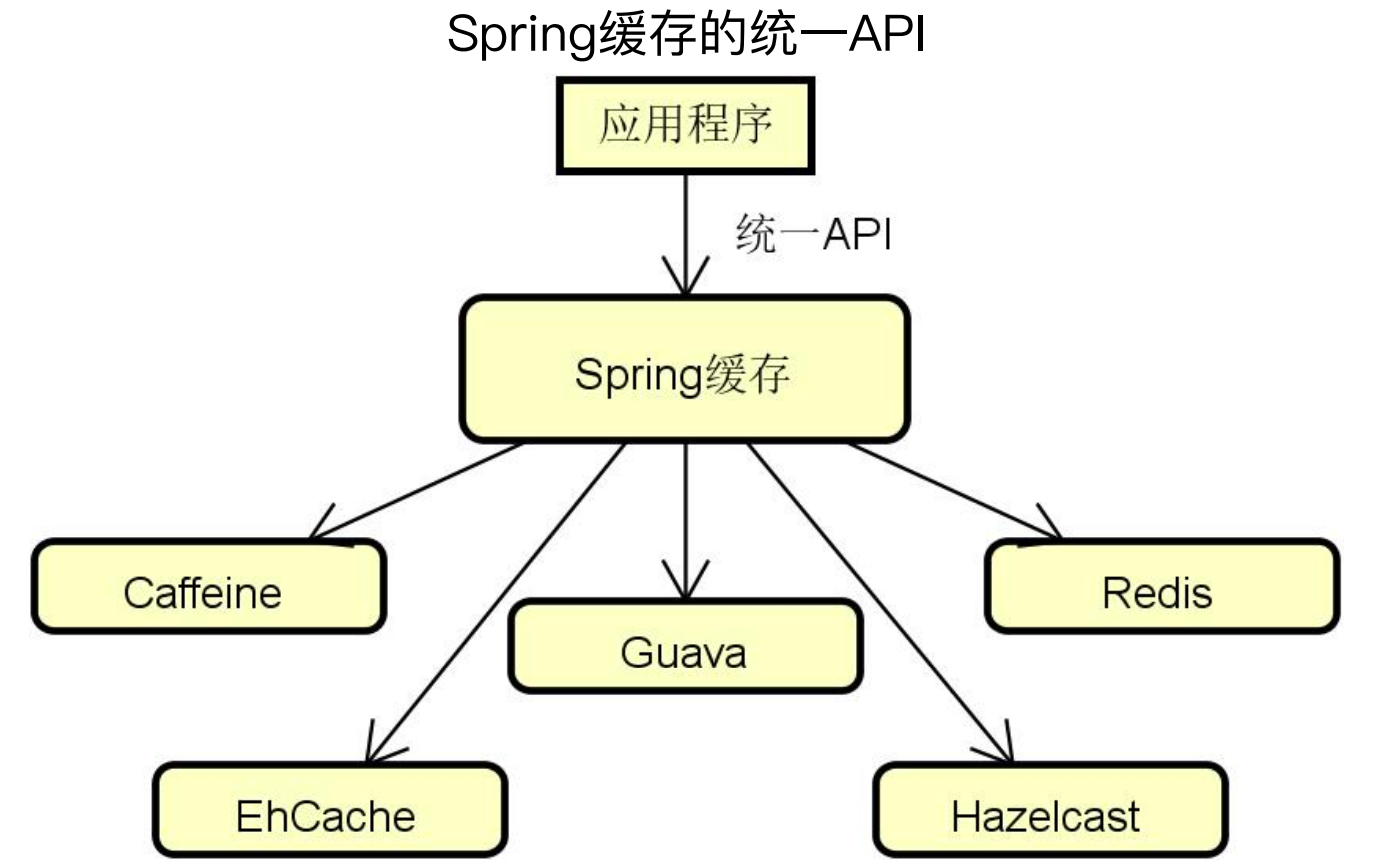
1、Spring缓存应用
使用Spring缓存进行开发主要是通过注解声明缓存并通过配置集成缓存。
首先是缓存注解:Spring提供了@Cacheable、@CachePut、@CacheEvict、@Caching等注解,同时也可以做自定义注解。
(1)@Cacheable注解
value:String[],要使用的缓存名称
key:String,基于SpEL表达式,用来计算自定义的缓存key,默认是方法的参数值
condition:String,基于SpEL表达式,如果得到的值是false则不会使用缓存,默认是true
// 缓存名字是user、key是user.123,其中123是入参id的值
@Cacheable(value = "user", key = "'user'.concat(#id.toString())")
public User findUserById(Long id) {
System.out.println("findUserById, id: " + id);
return userMappper.get(id);
}
// 主要是增加了condition属性,表示id是偶数才走缓存
@Cacheable(value = "user", key = "'user'.concat(#id.toString())", condition = "# id%2==0")
public User findUserById(Long id) {}
(2)@CachePut:更新缓存,每次使用新对象替换原有缓存中的老对象
@CachePut(value = "user", key = "'user'.concat(#user.id.toString())")
public User update(User user) {
System.out.println("update user: " + user.toString());
userMapper.put(user.getId(), user);
return user;
}
(3)@CacheEvict:删除缓存,移除缓存中的老对象
@CacheEvict(value = "user", key = "'user'.concat(#id.toString())")
public void remove(Long id) {
System.out.println("remove user id: " + id);
userMapper.remove(id);
}
(4)@Caching:复合注解,可以组合多个注解
// 查询使用cache1,删除用cache2和cache3
@Caching(cacheable = @Cacheable("cache1"), evict = {@CacheEvict("cache2"), @CacheEvict(value = "cache3", allEntries = true)})
(5)自定义缓存注解:
可以使用组合多个缓存使用,创建一个新的注解,在方法上使用新的注解即可。
@Caching(put = {@CachePut(value = "user", key = "#user.id"), @CachePut(value = "user", key = "#user.name")})
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
public @interface SpringUserCache {
}
@SpringUserCache
public User update(User user) {
}
2、Spring缓存键管理
Spring缓存键(key)可以使用自定义键也可以使用默认建。
(1)自定义键
可以使用SpEL表达式获取当前的方法名、方法、被调用对象、被调用对象Class、args等信息,根据这些信息可以组装我们自己想要的键值。
methodName:当前方法名,#root.methodName
method:当前方法,#root.method.name
target:当前被调用的对象,#root.target
targetClass:当前被调用的对象的class,#root.targetClass
args:当前方法参数组成的数组,#root.args[0]
// 使用参数名称设置键值
key = "'user'.concat(#id.toString())"
public User findUserById(Long id) {}
// 使用参数列表第一个设置键值
key ="'user'.concat(#args[0].toString())"
public User findUserById(Long id)
(2)默认键
如果我们不设置键值,就会使用Spring默认的键生成策略:如果方法没有参数,则使用0作为key;如果只有一个参数,则使用该参数作为key;如果参数多于一个的话则使用所有参数的hashCode作为key。
我们也可以自定义默认建生成策略,示例代码如下所示。
//自定义默认键生成策略
public interface KeyGenerator {
Object generate(Object target, Method method, Object... params);
}
public class SpringKeyGenerator implements KeyGenerator {
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder sb = new StringBuilder();
sb.append(target.getClass().getName());
sb.append(method.getName());
//把所有参数作为Key的一部分
for (Object obj : params) {
sb.append(obj.toString());
}
return sb.toString();
}
}
3、使用Spring缓存
(1)缓存配置:在配置类上添加@EnableCaching注解
@Configuration
@EnableCaching
public class SpringCacheConfig {
}
(2)配置缓存管理器CacheManager:如下代码所示,设置了SpringCache使用了ehcache,配置项为ehcache.xml
spring:
cache:
type: ehcache
ehcache:
config: classpath:ehcache.xml
(3)具体缓存组件配置:下面是ehcache的配置
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd" updateCheck="false">
<diskStore path="java.io.tmpdir"/>
<!-- 配置默认的缓存区 -->
<defaultCache.../>
<!-- 配置名为user的缓存区 -->
<cache name="user"
maxElementsInMemory="100"
eternal="false"
timeToIdleSeconds="900"
timeToLiveSeconds="900"
overflowToDisk="true"
maxElementsOnDisk="10000"
diskPersistent="true"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"/>
</ehcache>
4、Spring缓存在Spring家族中的应用
Spring缓存在Spring家族中也有对应的应用,例如安全组件Spring Security中,对于认证缓存,提供了UserCache接口。
public interface UserCache {
//从缓存获取用户信息
UserDetails getUserFromCache(String username);
//把用户信息放入缓存中
void putUserInCache(UserDetails user);
//从缓存中移除用户信息
void removeUserFromCache(String username);
}
配置Spring缓存的代码如下,主要是配置了缓存工厂、缓存管理器、以及通过缓存工厂获取UserCache示例。
@Configuration
@EnableCaching
public class SpringAuthCacheConfig {
@Bean
public EhCacheFactoryBean ehCacheFactoryBean() {
EhCacheFactoryBean ehCacheFactory = new EhCacheFactoryBean();
ehCacheFactory.setCacheManager(cacheManagerFactoryBean().getObject());
return ehCacheFactory;
}
@Bean
public CacheManager cacheManager() {
return new EhCacheCacheManager(cacheManagerFactoryBean().getObject());
}
@Bean
public UserCache userCache() {
EhCacheBasedUserCache userCache = new EhCacheBasedUserCache();
userCache.setCache(ehCacheFactoryBean().getObject());
return userCache;
}
}
(二)Spring缓存实现原理
1、Cache定义
Spring的顶层抽象是Cache接口,提供了对于缓存的操作方法,另外在该接口中还提供了缓存值的包装器接口ValueWrapper来获取真实的缓存值,这其实是一种职责分离的设计,在实际获取缓存值时,是使用包装器来获取的。
public interface Cache {
//定义缓存的名称
String getName();
//获取缓存的底层实现,例如EhCache等
Object getNativeCache();
//根据key得到一个ValueWrapper
ValueWrapper get(Object key);
//根据key和value的类型直接获取缓存值
<T> T get(Object key, Class<T> type);
//根据key获取缓存值,获取过程交给了一个回调函数
<T> T get(Object key, Callable<T> valueLoader);
//根据key往缓存放数据
void put(Object key, Object value);
//根据key往缓存放数据,在缓存值尚未就绪的情况下返回一个ValueWrapper
ValueWrapper putIfAbsent(Object key, Object value);
//从缓存中移除key对应的缓存
void evict(Object key);
//清空缓存
void clear();
//缓存值的包装器接口
interface ValueWrapper {
//获取真实的缓存值
Object get();
}
}
2、Cache实现
Cache接口有很多实现,例如CaffeineCache、ConcurrentMapCache、GuavaCache、JCacheCache、RedisCache等。
以 ConcurrentMapCache的get方法为例,其处理逻辑是先从缓存获取数据,如果有数据就返回,没有数据就加锁获取数据,判断缓存中是否存在,存在就返回,不存在就异步从数据库获取,获取到后将数据存入缓存并返回。示例代码如下所示:
@Override
public <T> T get(Object key, Callable<T> valueLoader) {
if (this.store.containsKey(key)) {
return (T) get(key).get();
} else {
// 加锁
synchronized (this.store) {
//如果缓存值存在则直接返回
if (this.store.containsKey(key)) {
return (T) get(key).get();
}
T value;
try {
//否则创建目标值
value = valueLoader.call(); // 异步回调
} catch (Throwable ex) {
throw new ValueRetrievalException(key, valueLoader, ex);
}
//把目标值缓存起来再返回
put(key, value);
return value;
}
}
}
3、CacheManager定义和实现
CacheManager定义了根据Cache名称获取Cache的getCache方法和获取所有Cache名称的方法getCacheNames,针对不同的实现就是创建不同的对象,实现该这两个方法。
public interface CacheManager {
//根据Cache名获取Cache
Cache getCache(String name);
//获取所有Cache的名称
Collection<String> getCacheNames();
}
//ConcurrentMapCacheManager
private final ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap<String, Cache>(16);
//CaffeineCacheManager
protected Cache createCaffeineCache(String name) {
return new CaffeineCache(name, createNativeCaffeineCache(name), isAllowNullValues());
}
4、@EnableCaching注解
@EnableCaching注解提供的方法从语义上来说和缓存没有什么关系,在Spring中,以Enable开头的注解基本上都提供了proxyTargetClass、mode、order这三个方法,分别表示动态代理实现方式、切面通知模式、BeanPostProcessor执行的顺序。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import(CachingConfigurationSelector.class)
public @interface EnableCaching {
//是否启用CGLIB代理,默认为false,即使用JDK代理
boolean proxyTargetClass() default false;
//切面通知模式,默认使用代理模式
AdviceMode mode() default AdviceMode.PROXY;
//BeanPostProcessor执行的顺序
int order() default Ordered.LOWEST_PRECEDENCE;
}
使用了@EnableCaching注解后,在Spring的AutoConfig中会有缓存拦截器CacheInterceptor,是一个AOP的实现,实现了MethodInterceptor接口并其重写了invoke方法,最后调用execute方法。
public class CacheInterceptor extends CacheAspectSupport implements MethodInterceptor, Serializable {
@Override
public Object invoke(final MethodInvocation invocation) throws Throwable {
Method method = invocation.getMethod()
CacheOperationInvoker aopAllianceInvoker = new CacheOperationInvoker() { …
};
try {
//执行拦截逻辑
return execute(aopAllianceInvoker, invocation.getThis(), method, invocation.getArguments());
}
......
}
}
在execute方法中,首先获取缓存键,然后获取Cache对象,调用Cache.get(key, Callable)方法获取缓存值;
//判断缓存条件
if (isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) {
//获取缓存键
Object key = generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT);
//获取Cache对象
Cache cache = context.getCaches().iterator().next();
try {
//调用Cache.get(key, Callable)方法获取缓存值
return wrapCacheValue(method, cache.get(key, new Callable<Object>() {
@Override
public Object call() throws Exception {
return unwrapReturnValue(invokeOperation(invoker));
}
}));
}
......
}
@EnableCaching注解总的来说就是通过拦截器组件CacheInterceptor,我们就把目标方法的执行过程和缓存机制整合在一起。
对于@EnableCaching分析总体来说不复杂,但是对于Spring中以Enable开头的注解基本上都是这个套路,使用拦截器组件进行拦截,然后在拦截器中执行对应的业务处理。
(三)客服系统案例演进
客服系统缓存应用场景:租户信息的增删改查添加缓存处理。
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置信息:这里除了redis配置外,还配置了spring.redis
spring:
cache:
type: redis
redis:
time-to-live: 20000 # 缓存超时时间 单位:ms
cache-null-values: false # 是否缓存空值
redis:
host: 127.0.0.1
port: 6379
lettuce:
pool:
max-active: 8
max-wait: -1
max-idle: 8
min-idle: 0
connect-timeout: 10000
database: 0
缓存配置:配置了缓存管理器和模板类,其中在缓存管理器中设置了默认的有效期,同时还对分页场景做了特殊的缓存时间设置;另外@EnableCaching注解可以放在任何地方,一般会放在配置类或者启动类上。
@Configuration
@EnableCaching
@AutoConfigureAfter(RedisAutoConfiguration.class)
public class RedisConfig extends CachingConfigurerSupport {
@Bean
CacheManager cacheManager(RedisConnectionFactory connectionFactory){
// 默认配置,默认超时时间为 30s
RedisCacheConfiguration defaultRedisConfig = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(30L)).disableCachingNullValues();
// 配置 pagedObject 分页数据超时时间为 120s
RedisCacheManager cacheManager = RedisCacheManager.builder(RedisCacheWriter.lockingRedisCacheWriter(connectionFactory))
.cacheDefaults(defaultRedisConfig)
.withInitialCacheConfigurations(
Collections.singletonMap("pageObject", RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(120L)).disableCachingNullValues())
).transactionAware().build();
return cacheManager;
}
@Bean
public RedisTemplate<String, Integer> redisTemplate(RedisConnectionFactory factory){
RedisTemplate<String, Integer> redisTemplate = new RedisTemplate<>();
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new JdkSerializationRedisSerializer());
redisTemplate.setExposeConnection(true);
redisTemplate.setConnectionFactory(factory);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
具体的业务场景
@Service
@CacheConfig(cacheNames = "outsourcing-system-object")
public class OutsourcingSystemServiceImpl extends ServiceImpl<OutsourcingSystemMapper, OutsourcingSystem> implements IOutsourcingSystemService {
@Override
public List<OutsourcingSystem> findAllOutsourcingSystems() {
LambdaQueryWrapper<OutsourcingSystem> queryWrapper = new LambdaQueryWrapper<>();
return baseMapper.selectList(queryWrapper);
}
@Override
@Cacheable(value = "pageObject", key = "#root.targetClass + '_' + #p0 + '_' + #p1")
public PageObject<OutsourcingSystem> findPagedOutsourcingSystems(Long pageSize, Long pageIndex) {
PageObject<OutsourcingSystem> pageObject = new PageObject<>();
IPage<OutsourcingSystem> pageResult = baseMapper.findPagedOutsourcingSystems(pageSize, pageIndex);
pageObject.buildPage(pageResult.getRecords(), pageResult.getTotal(), pageResult.getCurrent(), pageResult.getSize());
return pageObject;
}
@Override
@Cacheable(key = "#root.targetClass + '_' + #systemId")
public OutsourcingSystem findOutsourcingSystemById(Long systemId) {
return baseMapper.selectById(systemId);
}
@Override
@CachePut(key = "#root.targetClass + '_' + #outsourcingSystem.id")
public Boolean addOutsourcingSystem(OutsourcingSystem outsourcingSystem) {
return this.save(outsourcingSystem);
}
@Override
@CachePut(key = "#root.targetClass + '_' + #outsourcingSystem.id")
public Boolean updateOutsourcingSystem(OutsourcingSystem outsourcingSystem) {
return this.updateById(outsourcingSystem);
}
@Override
@CacheEvict(key = "#root.targetClass + '_' + #systemId")
public Boolean deleteOutsourcingSystemById(Long systemId) {
baseMapper.deleteById(systemId);
return true;
}
}
三、基于Redis实现分布式锁
(一)分布式锁概念和实现
1、分布式锁
分布式锁 (Distributed Lock) 是控制分布式系统或不同系统之间共同访问共享资源的一种锁实现,如果不同的系统或同一个系统的不同主机之间共享了某个资源时,往往需要互斥来防止彼此干扰来保证一致性。
分布式锁可以用于解决重复性处理和保证正确性处理的场景,重复性是指如果不使用分布式锁,会导致业务重复执行一些没有意义的工作;正确性是指使用分布式锁可以防止对数据的并发访问,避免数据不一致,数据损失等。
分布式锁的技术需求是互斥、防止死锁、性能和容错:
互斥:最基本要求:同一时刻只能有一个线程获得锁
防止死锁:合理设置锁的有效时间,避免无法执行释放锁的命令
性能:减少锁等待时间避免导致大量线程阻塞,锁的颗粒度和范围尽量小
容错:保证外部系统的正常运行,客户端加锁和解锁过程可控
Redis实现分布式锁的命令如下:
set key value[expiration EX seconds|PX milliseconds] [NX|XX]
EX:设置键的过期时间为second秒; PX:设置键的过期时间为millisecond 毫秒
NX:只在键不存在时,才对键进行设置操作。SET key value NX效果等同于 SETNX key value; XX:只在键已经存在时,才对键进行设置操作。
例:SET resource_name my_random_value NX PX 30000,即当resource_name这个key不存在时创建这样的key,设值为my_random_value,并设置过期时间30000毫秒。
Redis实现分布式锁的总体思路为:
指定一个key作为锁标记存入Redis中,指定一个唯一的标识作为value,这个value和业务强相关,例如线程id,请求唯一id等。
当key不存在时才能设置值,确保同一时间只有一个客户端获得锁,满足互斥性需求
设置一个过期时间,防止因系统异常导致没能删除这个key,满足防死锁需求
当处理完业务之后需要清除key来释放锁,清除key时需要校验value值
2、操作原子性和Lua脚本
在实现分布式锁时,必须保证操作步骤原子性,而Redis通过引入Lua脚本来实现这一目标。Redis中集成了Lua的编译和执行器,所以我们可以在Redis中定义Lua脚本去执行。同时,在Lua脚本中,可以直接调用Redis的命令,来操作Redis中的数据。使用Lua脚本可以减少网络开销并提高复用性。
Redis服务器会单线程原子性执行Lua脚本,保证Lua脚本在处理的过程中不会被任意其它请求打断。 例如下面的示例代码,就是用redis客户端的call方法执行lua脚本。
redis.call('set','hello','world')
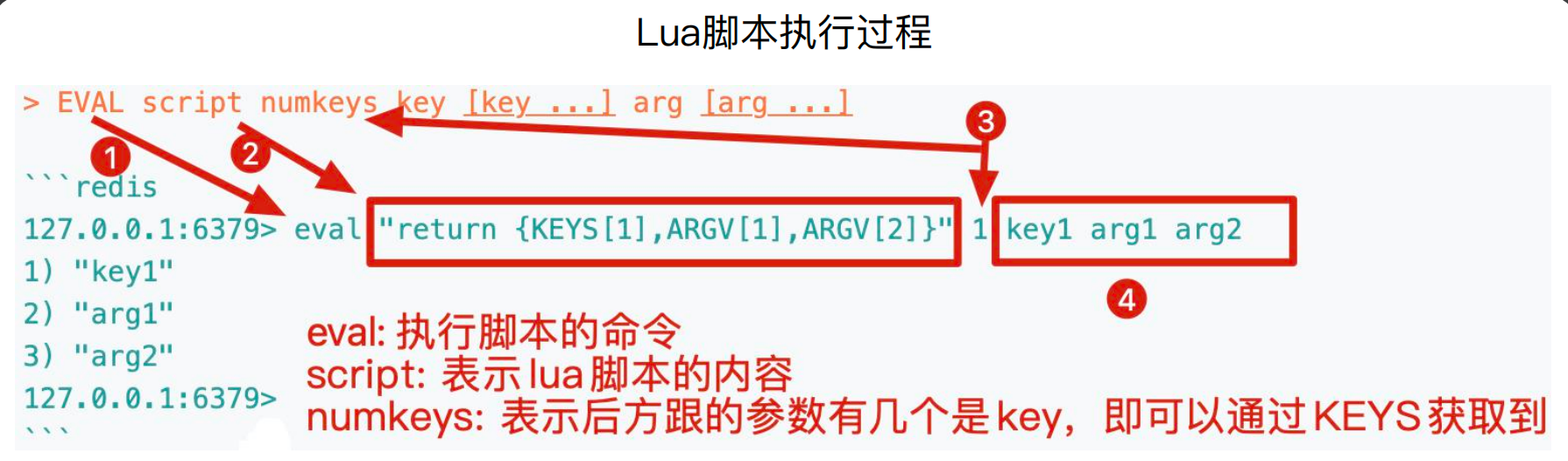
local value = redis.call('get',’hello’)
redis.call函数返回值就是Redis命令的执行结果,该函数会将Redis数据类型转化对应的Lua数据类型,如下图所示,eval是执行脚本的命令,script表示lua脚本的内容,numkeys表示后方跟的参数有几个key
下面是使用lua脚本来实现分布式锁删除key、实现一个访问频率限制功能
//分布式锁删除一个key
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
//实现一个访问频率限制功能
local times=redis.call('incr',KEYS[1])
-- 如果是第一次进来,设置一个过期时间
if times == 1 then
redis.call('expire',KEYS[1],ARGV[1])
end
-- 如果在指定时间内访问次数大于指定次数,则返回0,表示访问被限制
if times > tonumber(ARGV[2]) then
return 0
end
-- 返回1,允许被访问
return 1
3、Redisson:基于Redis实现分布式锁的主流框架
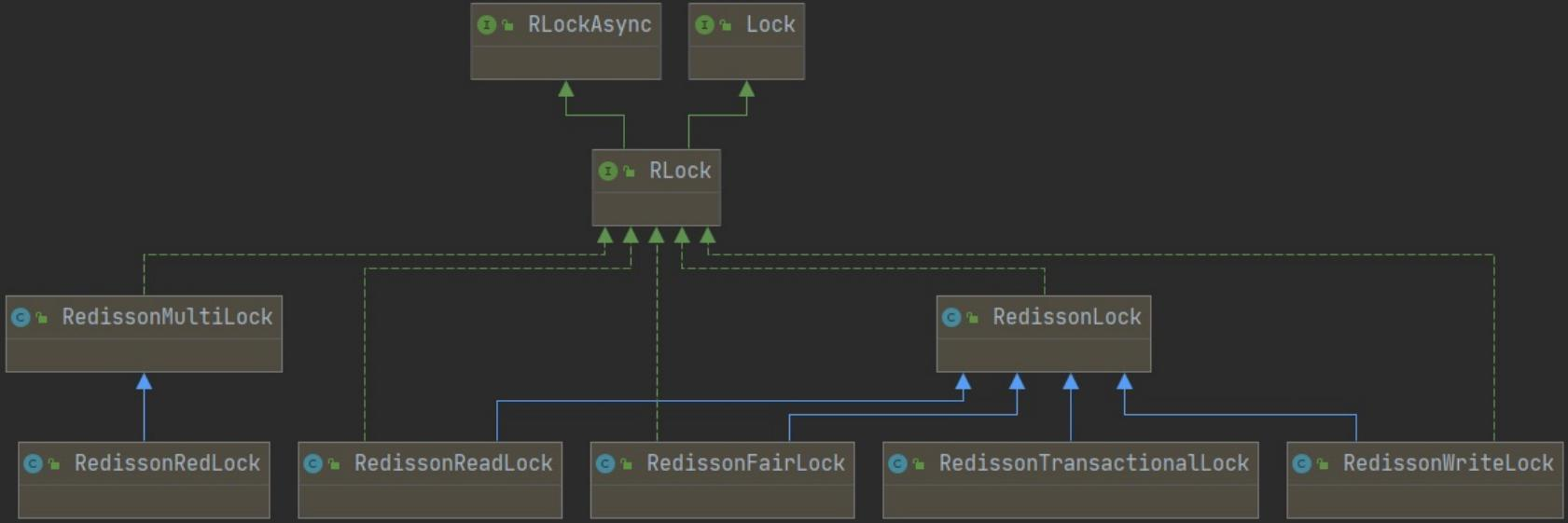
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory DataGrid)。它不仅提供了一系列的分布式的Java常用对象,实现了可重入锁(ReentrantLock)、公平锁(FairLock)、联锁(MultiLock)、 红锁(RedLock)、读写锁(ReadWriteLock)等,还提供了许多分布式服务。
Redisson提供了使用Redis的最简单和最便捷的方法,它的宗旨是促进使用者对Redis的关注分离 (Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
Redisson支持单点模式、主从模式、哨兵模式、集群模式,只是配置的不同。
Redisson分布式锁提供的方法如下所示:
public class RedissonLock {
private Redisson redisson;
// 加锁
public void lock(String lockName, long leaseTime) {
RLock rLock = redisson.getLock(lockName);
rLock.lock(leaseTime, TimeUnit.SECONDS);
}
// 释放锁
public void unlock(String lockName) {
redisson.getLock(lockName).unlock();
}
// 判断是否已加锁
public boolean isLock(String lockName) {
RLock rLock = redisson.getLock(lockName);
return rLock.isLocked();
}
// 获取锁
public boolean tryLock(String lockName, long leaseTime) {
RLock rLock = redisson.getLock(lockName);
boolean getLock = false;
try {
getLock = rLock.tryLock(leaseTime, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
return false;
}
return getLock;
}
}
如果不使用Redisson,也可以使用RedisTemplate来实现分布式锁,只不过需要自己写Lua脚本等实现,会比较麻烦。
使用RedisTemplate实现分布式锁在低版本和高版本的实现不同。
在低版本中,首先将 Lua 脚本封装成RedisScript脚本,然后调用redisTemplate的execute方法即可,如下代码所示,首先使用 setnx 命令加锁,如果嘉成成功则获取value值和当前的值是否相同,如果相同,再设置key的有效期。
//低版本RedisTemplate
public Boolean lock(String key, String value, int expireSeconds) {
key = getKey(key);
return redisTemplate.execute(LOCK_SCRIPT, Collections.singletonList(key), value, expireSeconds);
}
//lua脚本,用来设置分布式锁
private static final String LOCK_LUA_SCRIPT =
"if redis.call('setNx',KEYS[1],ARGV[1]) then\n" +
" if redis.call('get',KEYS[1])==ARGV[1] then\n" +
" return redis.call('expire',KEYS[1],ARGV[2])\n" +
" else\n" +
" return 0\n" +
" end\n" +
"end\n";
private static final RedisScript<Boolean> LOCK_SCRIPT = RedisScript.of(LOCK_LUA_SCRIPT, Boolean.class);
在高版本中,直接可以使用setIfAbsent方法来处理即可。
//高版本RedisTemplate
public boolean setIfNotExists(String key, String value, int seconds) {
key = getKey(key);
return redisTemplate.opsForValue().setIfAbsent(key, value, seconds, TimeUnit.SECONDS);
}
对于释放锁,也是将 Lua 脚本封装成RedisScript并调用redisTemplate的execute方法执行;如下代码所示,判断key对应的值是否与当前的值一致,如果一致,就删除 key。
public Boolean unlock(String key, String value) {
key = getKey(key);
return redisTemplate.execute(UNLOCK_SCRIPT, Collections.singletonList(key), value);
}
//lua脚本,用来释放分布式锁
private static final String UNLOCK_LUA_SCRIPT =
"if redis.call('get',KEYS[1]) == ARGV[1] then\n" +
" return redis.call('del',KEYS[1])\n" +
"else\n" +
" return 0\n" +
"end";
private static final RedisScript<Boolean> UNLOCK_SCRIPT = RedisScript.of(UNLOCK_LUA_SCRIPT, Boolean.class);
(二)Redisson分布式锁原理分析
1、加锁操作
Redisson分布式锁执行流程:线程获取锁,如果获取成功则启动WatchDog并执行Lua脚本。
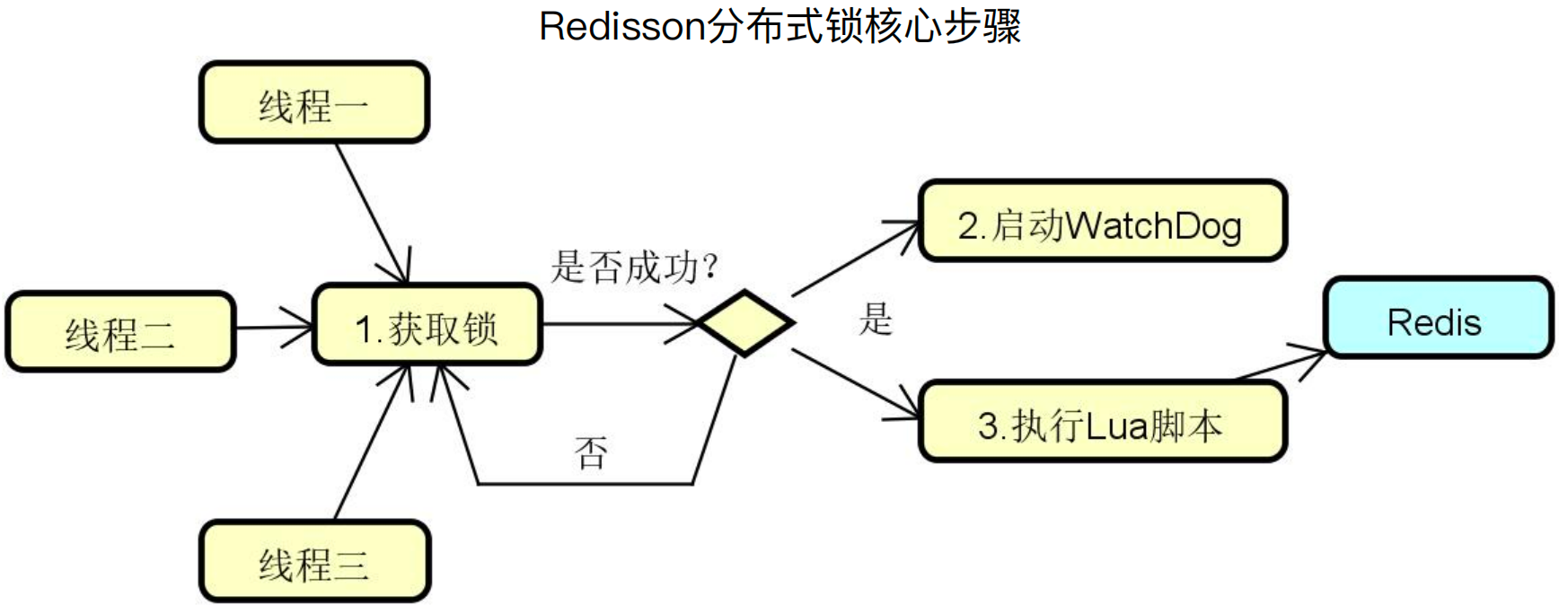
如果像上面RedisTemplate那样加锁,如果线程1获得锁后,它的业务逻辑需要执行2秒,这就会有个问题,在线程1执行1秒后,这个锁就自动过期了。 这个时候线程2进来了,就存在线程1和线程2同时在这段业务逻辑里执行代码,并且线程 1释放锁时,这个锁已经被线程2持有,这显然是不合理的。
Watch Dog的作用就是线程1 业务还没有执行完但锁就过期了,这时候线程1还想持有锁的话,就会启动一个Watch Dog后台线程,不断的延长该锁的生存时间。
Redisson提供了RLock接口,代码如下所示:
public interface RRLock {
//加锁,锁的有效期默认30秒
void lock();
//获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false
boolean tryLock();
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
//解锁
void unlock();
//中断锁,表示该锁可以被中断
void lockInterruptibly();
void lockInterruptibly(long leaseTime, TimeUnit unit);
//检验该锁是否被线程使用,如果被使用返回True
boolean isLocked();
}
以 tryLock 方法为例,主要是调用 tryAcquire 方法尝试获取锁,如果获取的 ttl 为空,则表示成功获取到锁,直接返回。
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
long time = unit.toMillis(waitTime);
long current = System.currentTimeMillis();
long threadId = Thread.currentThread().getId();
// 通过tryAcquire方法尝试获取锁
Long ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
//表示成功获取到锁,直接返回
if (ttl == null) {
return true;
}
//省略后半部分代码....
}
在 tryAcquire 方法中,调用 tryLockInnerAsync 方法获取锁(这里会区分是否设置了过期时间,如果没有设置就取系统配置或默认的过期时间),使用RFuture接收调用结果,如果调用成功,则会执行ttlRemainingFuture.onComplete回调。
在回调方法中,如果出现异常直接返回加锁失败;如果获取锁成功(ttlRemaining为null,表示目前没有被加锁或者锁已过期),如果显式的设置了过期时间,则设置过期时间,如果没有设置过期时间,则启动一个WatchDog(其实就是一个定时任务线程池)来做锁续约。
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
RFuture<Long> ttlRemainingFuture;
// leaseTime租约时间,即key的过期时间
if (leaseTime != -1) {
// 如果设置过期时间
// 通过tryLockInnerAsync方法获取锁
ttlRemainingFuture = tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
} else {//如果没设置了过期时间,则从配置中获取key超时时间,默认是30s过期
// 通过tryLockInnerAsync方法获取锁
ttlRemainingFuture = tryLockInnerAsync(waitTime, internalLockLeaseTime, TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
}
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) { //说明出现异常,直接返回
return;
}
//获取锁成功
if (ttlRemaining == null) { //表示第一次设置锁键
if (leaseTime != -1) { //表示设置过超时时间,更新internalLockLeaseTime,并返回
internalLockLeaseTime = unit.toMillis(leaseTime);
} else { //过期时间已失效
// 启动Watch Dog
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
tryLockInnerAsync:在该方法中也是使用了Lua脚本进行处理,主要分三种情况:
情况1:判断lock键是否存在,不存在直接调用hset存储当前线程信息并且设置过期时间,返回nil,告诉客户端直接获取到锁
情况2:判断lock键是否存在,存在则将重入次数加1,并重新设置过期时间,返回nil,告诉客户端直接获取到锁
情况3:被其它线程已经锁定,返回锁有效期的剩余时间,告诉客户端需要等待
//执行Lua脚本尝试获取锁
<T> RFuture<T> tryLockInnerAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
" return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getRawName()), unit.toMillis(leaseTime), getLockName(threadId));
}
renewExpirationAsync:如果当前获得锁的线程没有执行完,那么Watch Dog会自动给Redis中目标key延长超时时间默认情况下,Watch Dog的续期时间是30s,也可以通过修改Config.lockWatchdogTimeout来另行指定。
//执行Lua脚本,对指定的key进行续约
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;", Collections.singletonList(getRawName()), internalLockLeaseTime, getLockName(threadId));
}
2、解锁(unlock)
对于解锁操作,会调用 unlockInnerAsync方法,在该方法中,如果lock键不存在,通过publish指令发送一个消息表示锁已经可用;如果锁不是被当前线程锁定,则返回nil;由于支持可重入,在解锁时将重入次数需要减1,如果计算后的重入次数>0,则重新设置过期时间; 如果计算后的重入次数<=0,则发消息说锁已经可用。
//执行Lua脚本释放锁
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " + "redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;",
Arrays.asList(getRawName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
}
3、分布式锁的异常情况
但是对于Redis分布式锁来说,还存在着一些极端情况,例如:
客户端长时间内阻塞导致锁失效:网络问题或者GC等原因导致长时间阻塞,然后业务程序还没执行完锁就过期
Redis服务器时钟漂移:如果Redis服务器的机器时间发生了向前跳跃,就会导致这个key过早超时失效
单点实例安全问题:Redis主机在同步锁之前宕机,那么向其他及其申请锁就会再次得到这把锁
4、RedLock
RedLock 是一种用于解决 Redis 分布式锁在极端情况下的问题的算法和协议。
RedLock 的实现思路总结起来就是:原来都是向指定的一个redis服务器做操作(加锁、续期、解锁等),现在改为向所有redis节点做操作,只要超过半数操作成功,才认为本次操作成功。因此 RedLock 只适用于 Redis Cluster 集群,不适用于与单机和 Sentinel 集群。
(1)RedLock 可以解决以下问题:
分布式锁的可靠性:在分布式环境中,使用 Redis 实现分布式锁时,可能会遇到网络延迟、节点故障或竞争条件等问题。RedLock 通过在多个独立的 Redis 实例上获取锁,并使用大多数原则来判断锁的有效性,提供了更强大的分布式锁保证。它能够防止单个 Redis 节点故障或竞争条件导致的锁失效,提高分布式锁的可靠性。
锁的一致性:RedLock 通过判断大多数 Redis 实例上是否成功获取到锁,并且获取锁的客户端是同一个,来确定锁的有效性。这样可以确保在多个 Redis 实例之间,只有一个客户端能够持有锁,避免了多个客户端同时持有锁导致的并发问题,提供了锁的一致性。
高可用性:RedLock 使用多个独立的 Redis 实例来实现分布式锁,可以提供更高的可用性。即使部分 Redis 实例发生故障,只要大多数 Redis 实例正常运行,分布式锁仍然可用,不会因为单点故障而失效。
可靠的锁续约:RedLock 中的锁持有者需要定期续约锁的过期时间,以防止锁过期并被其他客户端获取。这样可以确保锁持有者在执行业务操作时,锁不会过期并被其他客户端抢占,提供了可靠的锁续约机制。
(2)具体实现逻辑如下:
获取锁:当客户端想要获取锁时,它会依次向多个独立的 Redis 实例发送获取锁的请求。每个请求都会使用相同的锁名称和唯一的标识符,确保锁的一致性和互斥性。
判断锁的有效性:在客户端成功获取锁后,它会检查多数 Redis 实例上是否成功获取到了锁(会检查多数 Redis 实例上锁的有效期(TTL,Time-To-Live)。如果发现多数实例上锁的有效期都较为接近,并且剩余时间不低于一个安全阈值(比如锁有效期的一半),那么认为锁是有效的),并且获取锁的客户端是同一个。这里的多数通常指的是大于一半的 Redis 实例。如果多数实例上成功获取到了锁,并且获取锁的客户端一致,那么认为锁是有效的。
续约锁:获取到锁的客户端会定期发送续约请求给所有 Redis 实例,以更新锁的过期时间。这样可以防止锁过期并被其他客户端获取,保持锁的持有状态。
释放锁:锁的持有者可以随时释放锁,将释放锁的请求发送给所有 Redis 实例。一旦锁被释放,其他客户端有机会获取到该锁。
下面代码是使用 Redisson 实现 Redlock 的代码样例。
//获取多个 RLock 对象
RLock lock1 = redissonClient1.getLock(lockKey);
RLock lock2 = redissonClient2.getLock(lockKey);
RLock lock3 = redissonClient3.getLock(lockKey);
//根据多个RLock对象构建RedissonRedLock
RedissonRedLock redLock = new RedissonRedLock(lock1, lock2, lock3);
try {
//尝试获取锁
boolean res = redLock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
//成功获得锁,在这里处理业务
}
} catch (
Exception e) {
throw new RuntimeException("aquire lock fail");
} finally {
//无论如何, 最后都要解锁
redLock.unlock();
}
RLock接口实现类:
(三)客服系统案例演进
对于各类信息的增删改都可以使用分布式锁,下面在更新客户信息场景使用分布式锁演示。
引入redis依赖
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</dependency>
<!-- redis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>
配置信息
spring:
redis:
port: 6379
host: localhost
业务场景使用分布式锁
@Autowired
private RedissonClient redissonClient;
@Override
public HangzhouCustomerStaff updateCustomerStaff(HangzhouCustomerStaff customerStaff) {
String lockKey = "HangzhouCustomerStaff" + customerStaff.getId();
// 获取 Lock 对象,并判断是否为空
RLock lock = redissonClient.getLock(lockKey);
if(Objects.isNull(lock)){
log.info("获取锁为空");
throw new BizException(MessageCode.SYSTEM_ERROR, "获取锁为空");
}
// 尝试加锁,如果加锁失败则抛出异常
boolean tryLock;
try{
tryLock = lock.tryLock(3, 60, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
log.info("获取锁异常");
throw new BizException(MessageCode.SYSTEM_ERROR, "获取锁异常");
}
// 没有获取到锁
if(!tryLock){
log.info("没有获取到锁");
throw new BizException(MessageCode.SYSTEM_ERROR, "没有获取到锁");
}
try {
log.info("业务执行成功");
return customerStaffRepository.save(customerStaff);
}catch (Exception e){
e.printStackTrace();
log.info("业务执行异常");
throw new BizException(MessageCode.SYSTEM_ERROR, "业务执行异常");
}finally {
// 判断要解锁的key是否已经被加锁,只有加锁成功的key才需要解锁
// 判断要解锁的key是否被当前线程持有,自己加的锁自己才能解
if(lock.isLocked() && lock.isHeldByCurrentThread()){
lock.unlock();
}
}
}
验证分布式锁
@Slf4j
@RestController
@RequestMapping("/customerStaffs/hangzhou/test")
public class HangzhouCustomerStaffTestController {
@Autowired
private HangzhouCustomerStaffService customerStaffService;
@PostMapping("/")
public void test() {
testCustomerStaffUpdate();
}
void testCustomerStaffUpdate(){
int corePoolSize = 16;
int maxPoolSize = 50;
long keepLivedTime = 2;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue queue = new LinkedBlockingQueue(1000);
ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, maxPoolSize, keepLivedTime, unit, queue);
for (int i=0; i<1000; i++) {
executor.execute(new UpdateCustomerStaffTask(buildCustomerStaff()));
}
}
class UpdateCustomerStaffTask extends Thread {
private HangzhouCustomerStaff hangzhouCustomerStaff;
public UpdateCustomerStaffTask(HangzhouCustomerStaff hangzhouCustomerStaff){
this.hangzhouCustomerStaff = hangzhouCustomerStaff;
}
@Override
public void run(){
customerStaffService.updateCustomerStaff(hangzhouCustomerStaff);
}
}
public HangzhouCustomerStaff buildCustomerStaff(){
HangzhouCustomerStaff hangzhouCustomerStaff = new HangzhouCustomerStaff();
hangzhouCustomerStaff.setId(1L);
hangzhouCustomerStaff.setAvatar("abc.jpg");
hangzhouCustomerStaff.setNickname("lcl");
hangzhouCustomerStaff.setGender("MALE");
hangzhouCustomerStaff.setGoodAt("擅长X");
hangzhouCustomerStaff.setRemark("remark");
hangzhouCustomerStaff.setCreatedAt(new Date());
hangzhouCustomerStaff.setUpdatedAt(new Date());
hangzhouCustomerStaff.setIsDeleted(false);
return hangzhouCustomerStaff;
}
}
四、Redis缓存应用高级主题
缓存架构如下所示,客户端写数据时要写入数据库,读取数据时,先从缓存获取,有数据就返回,没有数据就从数据库读取数据,如果数据库有数据,则将数据写入缓存并返回。
这样做可以减轻数据库的压力,同时提升响应效率和并发量。
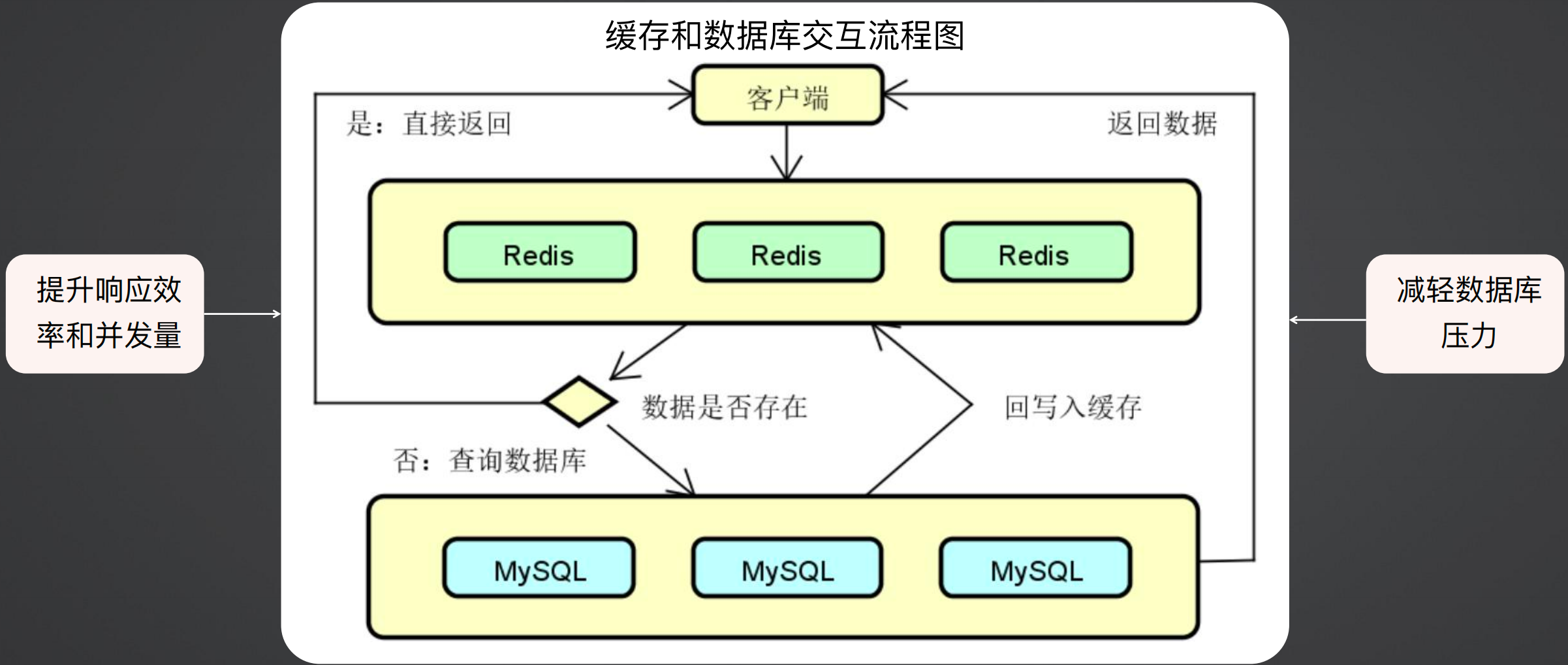
在处理缓存时,当缓存失效或没有抵挡住流量,流量直接涌入到数据库,在高并发的情况下,可能直接击垮数据库,导致整个系统崩溃;针对不同的场景可以分为缓存穿透、缓存击穿、缓存雪崩。
(一)缓存穿透
缓存穿透(Cache Penetration)是指查询一个缓存中和数据库中都不存在的数据,导致每次查询这条数据都会透过缓存,直接查数据库并最终返回空值。
当用户使用这条不存在的数据疯狂发起查询请求的时候,对数据库造成的压力就非常大,可能压垮数据库。
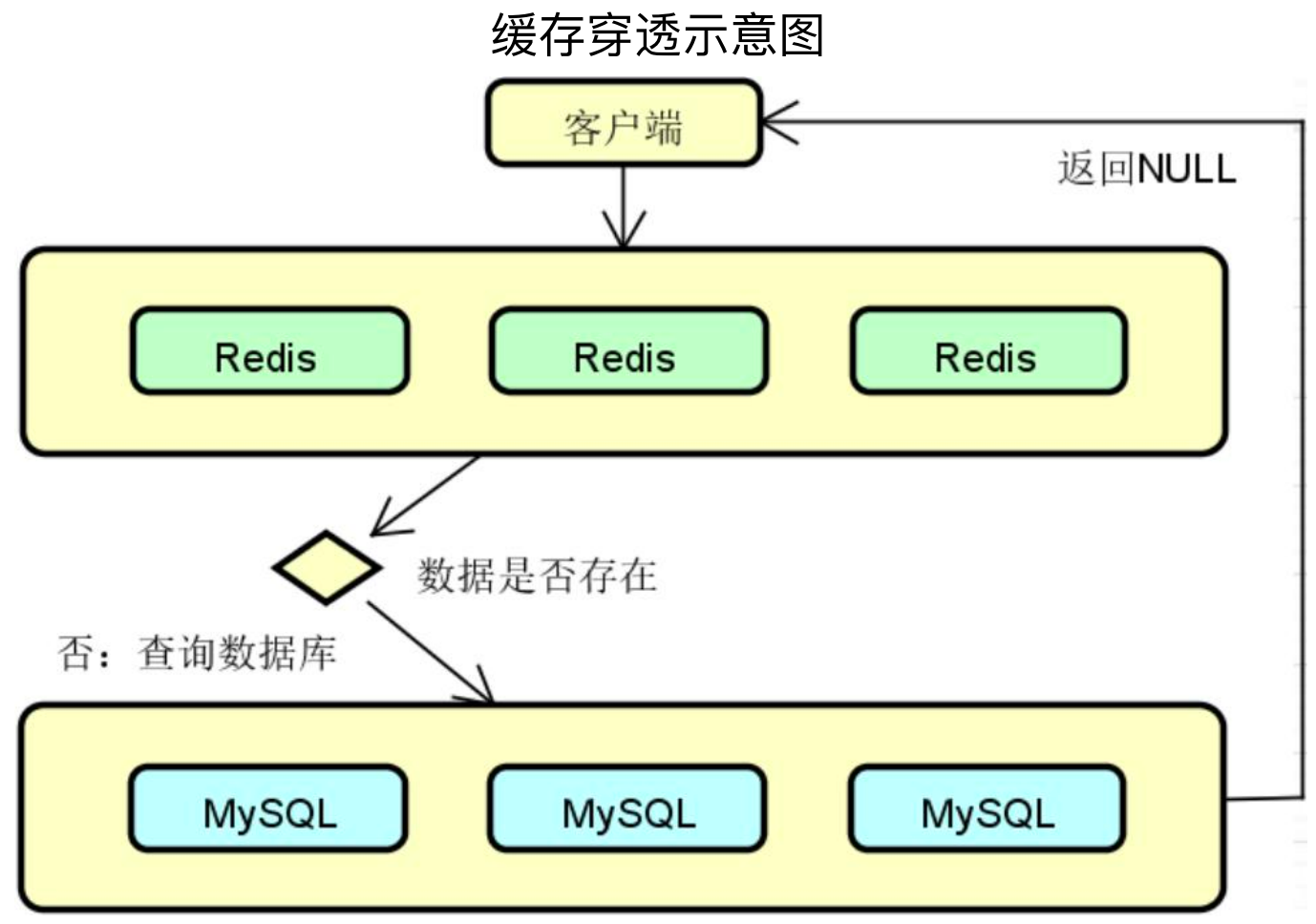
针对于缓存穿透,一般有缓存空对象、布隆过滤器、布谷鸟过滤器等解决方案。
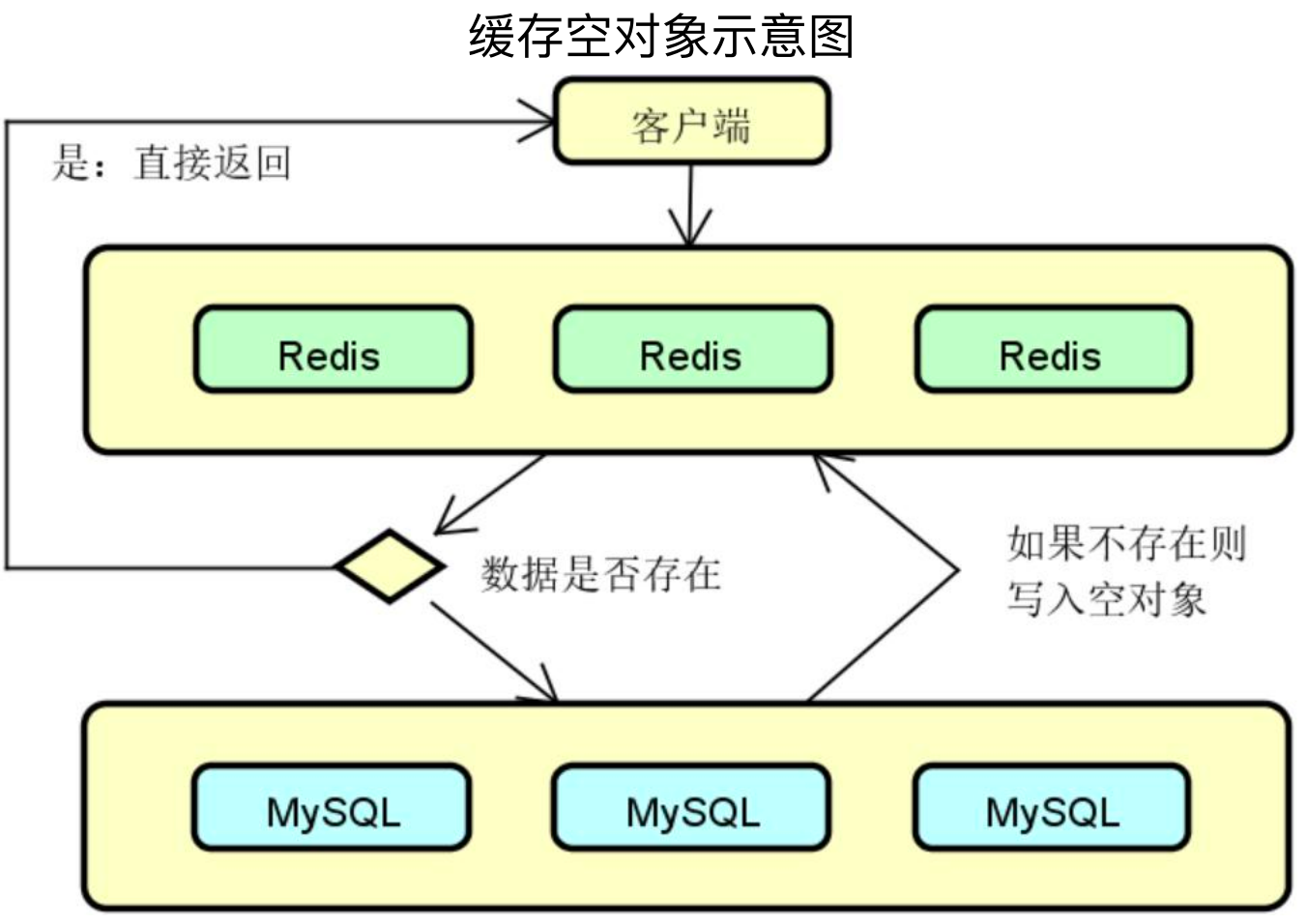
1、解决方案一:缓存空对象:
当数据库中查不到数据时缓存一个空对象,然后给这个空对象的缓存设置一个过期时间,这样下次再查询该数据的时候,就可以直接从缓存中拿到,从而达到了减小数据库压力的目的。
优势:实现简单,维护方便
劣势:额外的内存消耗;缓存层和存储层的短期数据不一致
代码实现示例:
String redisData = this.get(key);
//如果是人为设置的""则直接返回
if (JSON.toJSONString("").equals(redisData)) {
log.info("redis已缓存不存在的数据" + key);
return null;
}
//命中缓存并返回
T t = JSON.parseObject(redisData, T);
if (!ObjectUtils.isEmpty(t)) {
log.info("从redis中拿到" + key);
return t;
}
//没有命中缓存则查询数据库
T dbT = ...;
//数据库没有就设置key的值为""
if (ObjectUtils.isEmpty(dbT)) {
this.set(key, "", unExistTime, unExistTimeUnit);
log.error("数据库不存在, 已缓存不存在的key" + key);
return null;
}
2、解决方案二:布隆过滤器:
所谓布隆过滤器,就是一种数据结构,它是由一个长度为m bit的位数组与n个hash函数组成的数据结构,位数组中每个元素的初始值都是0。在初始化布隆过滤器时,会先将所有key进行n次hash运算,这样就可以得到n个位置,然后将这n个位置上的元素改为1。这样,就相当于把所有的key保存到了布隆过滤器中。
如下图所示,一共有3个key,对这3个key分别进行3次hash运算,key1经过三次hash运算后的结果分别为2/6/10,那么就把布隆过滤器中下标为2/6/10的元素值更新为1,然后再分别对key2和key3做同样操作,得到下图。

如果所有对应位置元素的值都为1,说明key在库中存在,则查库(指走原有逻辑,例如还是先查redis,如果存在则返回,不存在则需要查数据库);如果有任意一个位置的值不为1,说明key在库中不存在,则直接返回
优势:内存占用少
劣势:实现复杂,存在误判

具体代码可以使用Google Guava 中带的 BloomFilter:
引入 Guava
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</dependency>
编写布隆过滤器测试用例:在下面的测试用例中,具体逻辑:
首先创建了一个布隆过滤器,然后向其中初始化了 100w 数据
模拟一万次请求,其中有100次是真实存在的数据,其余数据为不存在的数据,并统计真实命中数据和误判数
计算打进后续流程中拦截率和错误数据率
@Slf4j
public class BloomFilterTest {
public static final Integer orderNums = 1000000;
@Test
public void bloom(){
// 创建一个布隆过滤器对象
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), BloomFilterTest.orderNums, 0.03D);
List<String> uuidQueryList = new ArrayList<>();
Set<String> uuidQuerySet = new HashSet<>();
long start = System.currentTimeMillis();
// 生成 100w 个uuid,分别放到三个容器中
for (int i=0; i<orderNums; i++) {
String uuid = UUID.randomUUID().toString();
bf.put(uuid);
uuidQueryList.add(uuid);
uuidQuerySet.add(uuid);
}
log.info("随机初始化100w个订单号耗时:{} ms", System.currentTimeMillis() - start);
// 布隆过滤器正确判断的订单号个数
int correct = 0;
// 布隆过滤器错误判断的订单号个数
int wrong = 0;
// 假设,测试的订单号数量为 1w 个
int testNum = 10000;
String uuidTest;
for (int i=0; i<testNum; i++) {
// 从已有的 100w 个订单中取出100个
uuidTest = i%100==0 ? uuidQueryList.get(i) : UUID.randomUUID().toString();
// 开始判断,布隆过滤器来一波
if(bf.mightContain(uuidTest)) {
// 如果集合中存在,说明真的存在
if(uuidQuerySet.contains(uuidTest)){
correct++;
}else {
wrong++;
}
}
}
log.info("==========================");
log.info("在已知已存在的100w个订单号中,从其中选100个已存在的订单号,其中布隆过滤器判断确实存在的数量有 {} 个", correct);
log.info("在已知已存在的100w个订单号中,外界随机生成9900个新订单号,其中布隆过滤器误判存在的数量有 {} 个,挡住的请求有 {} 个", wrong, testNum-wrong);
NumberFormat percent = NumberFormat.getPercentInstance();
// 保留两位小数
percent.setMaximumFractionDigits(2);
float wp = (float) wrong/(testNum-100);
float rp = (float) (testNum-100-wrong)/(testNum-100);
log.info("==========================");
log.info("布隆过滤器的正确率(抵挡住的):{}", percent.format(rp));
log.info("布隆过滤器的误报率(没有抵挡住的):{}", percent.format(wp));
}
}
输出结果:可以看到,真实的100个数据都走到了后续流程,但同时有279个非真实数据也进入了后续流程,对于整个进入后续业务流程来说,拦截率为97%,误判率为3%。
21:54:29.668 [main] INFO com.lcl.galaxy.distribution.im.server.BloomFilterTest - 随机初始化100w个订单号耗时:1649 ms
21:54:29.690 [main] INFO com.lcl.galaxy.distribution.im.server.BloomFilterTest - ==========================
21:54:29.690 [main] INFO com.lcl.galaxy.distribution.im.server.BloomFilterTest - 在已知已存在的100w个订单号中,从其中选100个已存在的订单号,其中布隆过滤器判断确实存在的数量有 100 个
21:54:29.690 [main] INFO com.lcl.galaxy.distribution.im.server.BloomFilterTest - 在已知已存在的100w个订单号中,外界随机生成9900个新订单号,其中布隆过滤器误判存在的数量有 279 个,挡住的请求有 9721 个
21:54:29.690 [main] INFO com.lcl.galaxy.distribution.im.server.BloomFilterTest - ==========================
21:54:29.690 [main] INFO com.lcl.galaxy.distribution.im.server.BloomFilterTest - 布隆过滤器的正确率(抵挡住的):97.18%
21:54:29.690 [main] INFO com.lcl.galaxy.distribution.im.server.BloomFilterTest - 布隆过滤器的误报率(没有抵挡住的):2.82%
整体来说,布隆过滤器拦截了大量的数据,虽然存在一定的误判,以上述案例为例,流量比真实数据要高三倍,但是相比于100倍的请求,已经降低了非常多,对于一般的应用场景来说,都可以接受。
3、解决方案三:布谷鸟过滤器
(1)布隆过滤器存在一些问题,例如:
查询性能弱:使用多个 hash 函数探测位图中多个不同的位点,这些位点在内存上跨度很大,会导致 CPU 缓存行命中率低
空间利用效率低:在相同的误判率下,布谷鸟过滤器的空间利用率要明显高于布隆,空间上大概能节省 40% 多
不支持反向操作(删除):这个问题是布隆过滤器的软肋。经过长时间的使用,可能经过了10亿的数据,但是现在有效的数据只有一千万,但是布隆过滤器不能删除数据,导致所有的数据都会留痕,随着时间推移,误判率就会越来越高。
不支持计数:其实就是想通过类似重入锁的计数方式解决不能删除数据的问题。
(2)布谷鸟过滤器考虑的点
最简单的布谷鸟哈希结构是一维数组结构,会有两个 hash 算法将新来的元素映射到数组的两个位置。如果两个位置中有一个位置为空,那么就可以将元素直接放进去,但是如果这两个位置都满了,随机踢走一个,然后自己霸占了这个位置。对于被踢走的元素,会重新找一个位置(因为每个数据都有两个位置)存放,但是可能存在一直被踢的情况(A踢走B,B踢走C,C踢走D等),布谷鸟算法针对这种情况设置了一个阈值,超过阈值则直接进行扩容(其实并不是)。
上面的布谷鸟哈希算法的平均空间利用率并不高,大概只有 50%。到了这个百分比,就会很快出现连续挤兑次数超出阈值。这样的哈希算法价值并不明显,所以需要对它进行改良。
一个是增加 hash 函数:大大降低碰撞的概率,将空间利用率提高到 95%左右)
另一个是在数组的每个位置上挂上多个座位:两个元素被 hash 在了同一个位置,也不必立即踢走,显著降低挤兑次数。这种方案的空间利用率只有 85%左右,但是查询效率会很高,同一个位置上的多个座位在内存空间上是连续的,可以有效利用 CPU 高速缓存。
更加高效的方案是将上面的两个改良方案融合起来,比如使用 4 个 hash 函数,每个位置上放 2 个座位。这样既可以得到时间效率,又可以得到空间效率。这样的组合甚至可以将空间利用率提到高 99%。
(3)布谷鸟过滤器原理
最终的布谷鸟过滤器的数据结构有桶和指纹的概念,桶(Bucket):布谷鸟过滤器将数据存储在一系列桶中,每个桶可以存储一个或多个元素的指纹(Fingerprint)。指纹(Fingerprint):指纹是通过哈希函数将元素映射为一个固定长度的二进制值,通常使用几个字节的数据来表示。
插入元素:
当要插入一个元素时,首先计算其指纹(Fingerprint)和哈希值。
然后选择一个桶(Bucket),将指纹插入到桶中的一个空闲位置。
如果选择的桶已满,可以通过以下步骤进行指纹的替换(Cuckoo Kick):
选择一个目标桶,将要插入的指纹替换到目标桶中。
检查目标桶中的指纹是否已满,如果已满,则将目标桶中的某个指纹替换到另一个桶中。
重复上述步骤,直到找到一个空闲位置或达到最大迭代次数为止。
如果插入操作成功,返回插入成功的标志;如果插入操作失败(无法找到空闲位置),则说明过滤器已满,无法插入新元素。
查找元素:
当要查询一个元素时,首先计算其指纹和哈希值。
根据哈希值找到对应的桶,并在桶中查找该指纹。
如果指纹在桶中存在,则判断元素可能存在于集合中;如果指纹在桶中不存在,则确定元素一定不存在于集合中。
删除元素:
布谷鸟过滤器支持删除操作,但是删除操作会引入一定的误判率。
删除操作将指纹从桶中清除,将对应的位置标记为“空闲”。
删除操作可能会导致桶内的指纹数量减少,为了避免桶内出现空洞,可能需要进行指纹的迁移操作。
(4)布谷鸟过滤器的优缺点
优点是支持删除操作、空间效率高,缺点是误判率略高、内存消耗较高。
除了上述优缺点,针对于布谷鸟过滤器声称的支持删除操作来说是很鸡肋的,因为无论是布隆过滤器还是布谷鸟过滤器都是采用了损失精度换空间的思想,在布谷鸟过滤器中,将元素压缩成指纹进行存储,那么肯定会有不同数据元素计算的指纹是相同的,然后删除存在误判。
如果真的发生误判,那么对于替换布隆过滤器的根本理由就站不住了,因为这两个过滤器的核心思想是不在过滤器中的数据一定不存在,如果误删,就打破了该基础。
针对于误删的情况,布谷鸟过滤器官方也承认这是有问题的,其给出的解决方案是对于同一个元素,插入次数不要超过 kb+1,k和b一个指hash函数数量,一个指桶的数量;官方描述如下图所示。

但是对于官方的解释还是持有疑问的,首先我们假设官方的描述没有问题,同一个元素插入次数不超过 kb+1 次就不会有问题,那么怎么保证不超过这个数据呢,我们是不是要维护一个计数器来记录每一个元素的插入次数,那么问题就来了,如果是小数据量,压根就不需要布隆过滤器或者布谷鸟过滤器,如果是上亿条数据,我还要花大量的空间维护插入次数,那这个过滤器又有什么意义呢。
(二)缓存击穿
缓存击穿(Cache Breakdown),是指当缓存中某个热点数据过期了,在该热点数据重新载入缓存之前,有大量的查询请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉。缓存击穿属于常见的“热点”问题。

对于缓存击穿的解决方案有很多,例如:
设置key永不过期
预先设置热门数据,提前存入缓存
实时监控热门数据,调整key过期时长:例如设置热点数据的过期时间是15分钟,后台启动定时任务每十分钟执行一次去更新热点数据
保证只有一个请求打到数据库:使用分布式锁保证同一时刻只能有一个查询请求重新加载热点数据到缓存中,其他线程只需等待该线程运行完毕即可重新从Redis中获取数据,不会查询数据库
使用分布式锁保证只有一个线程更新缓存代码实现:
//加分布式锁
private boolean tryLock(String key, Long lockTime, TimeUnit lockTimeUnit) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", lockTime, lockTimeUnit);
return BooleanUtil.isTrue(flag);
}
//释放分布式锁
private void unLock(String key) {
stringRedisTemplate.delete(key);
}
(三)缓存雪崩
缓存雪崩(Cache Avalanche)是指当缓存中有大量的key在同一时刻过期,或者Redis直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉。
击穿与雪崩的区别即在于击穿是对于特定的热点数据来说,而雪崩是全部数据。
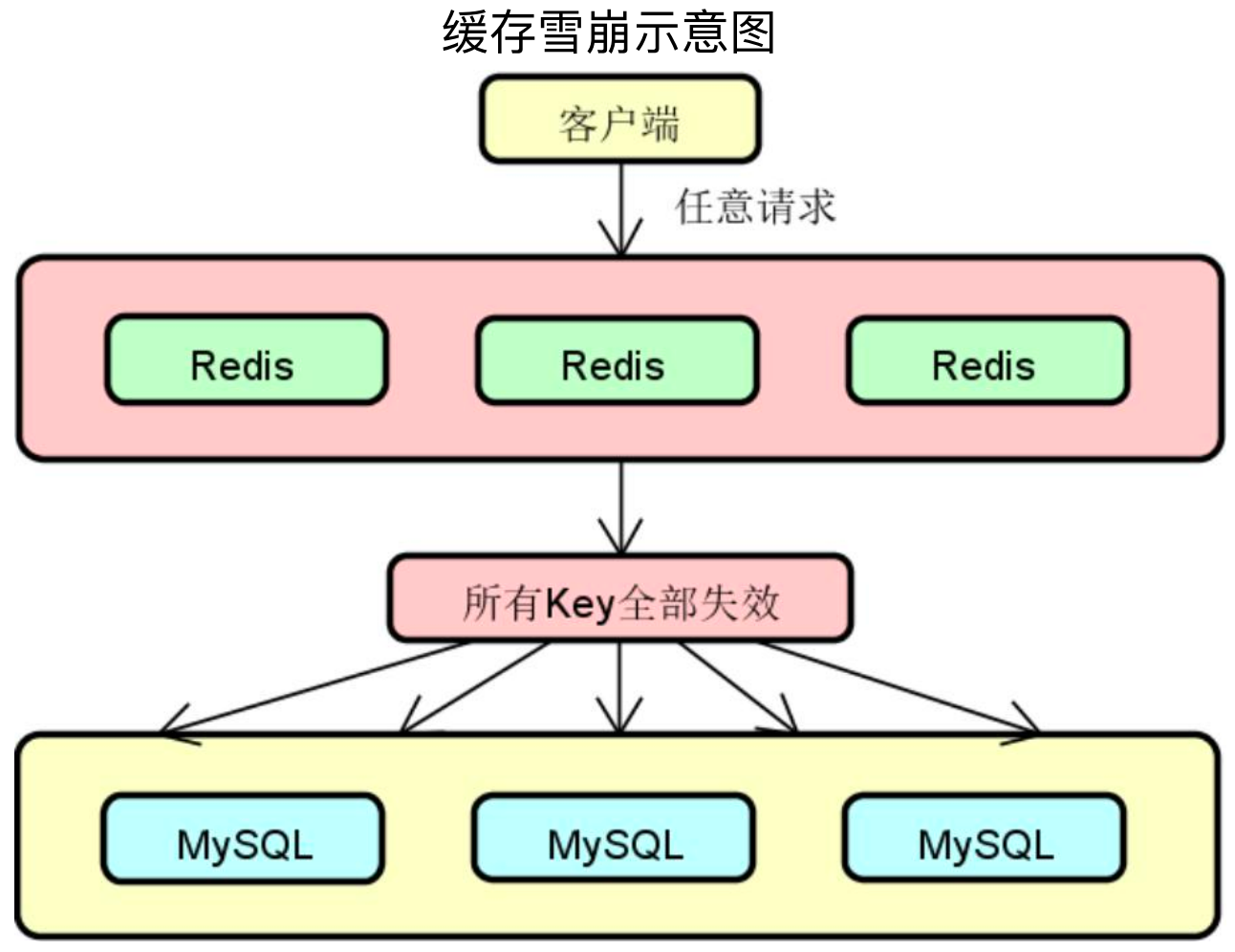
如上图所示,缓存雪崩表现为两种形式:缓存中有大量Key同时过期、Redis实例发生故障宕机。
表现形式一:缓存中有大量Key同时过期,导致大量请求无法得到处理,需要回源数据库。对应的解决方案有:
差异化设置过期时间:初始化过期时间增加一个较小的随机数
服务降级:允许核心业务访问数据库,非核心业务直接返回预定义的信息
过期时间更新:实时监控数据,调整key过期时长
表现形式二:Redis实例发生故障宕机,无法处理请求,就会导致大量请求积压到数据库层。对应的解决方案有:
Redis构建高可用集群:通过主从节点的方式构建Redis高可用集群,避免缓存实例宕机
请求限流:控制每秒进入应用程序的请求数,避免过多的请求访问到数据库
服务熔断:暂停业务应用对缓存服务的访问,从而降低对数据库的压力
差异化缓存过期时间实现:
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit timeUnit) {
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(timeUnit.toSeconds(time)));
stringRedisTemplate.opsForValue().set(key, JSON.toJSONString(redisData));
}
(四)客服系统案例演进
使用布隆过滤器做业务处理:
首先判断布隆过滤器中是否存在,如果不存在,认为是非法请求;
如果存在,则从缓存获取,缓存中如果有数据,则直接返回;
缓存中没有数据,则从数据库获取,数据库中有数据,将数据写入缓存并返回;
数据库中没有数据,向缓存中写入空数据并返回
除了业务逻辑外,使用了线程栅栏模拟高并发请求。
@Slf4j
public class BloomFilterThread implements Runnable{
private CyclicBarrier cyclicBarrier;
private BloomFilter<String> bloomFilter;
private LocalCustomerStaffMapper mapper;
private LocalCustomerStaffRedisRepository redisRepository;
public BloomFilterThread(CyclicBarrier cyclicBarrier, BloomFilter<String> bloomFilter,
LocalCustomerStaffMapper mapper, LocalCustomerStaffRedisRepository redisRepository) {
this.cyclicBarrier = cyclicBarrier;
this.bloomFilter = bloomFilter;
this.mapper = mapper;
this.redisRepository = redisRepository;
}
@Override
public void run() {
try {
// 等待所有线程准备就绪后一起执行
cyclicBarrier.await();
} catch (Exception e) {
e.printStackTrace();
}
String threadName = Thread.currentThread().getName();
// 初始化 1000 个 StaffId 进行攻击
Random random = new Random();
String staffId = String.valueOf(random.nextInt(1000));
// 先用布隆过滤器拦截
if(!bloomFilter.mightContain(staffId)){
log.info("{}:布隆过滤器中不存在该key,疑似非法请求!staffId为:{}", LocalDateTime.now(), staffId);
return;
}
// 如果布隆过滤器没有挡住,需要去redis中查询缓存数据
LocalCustomerStaff localCustomerStaff = redisRepository.findLocalCustomerStaffByStaffId(staffId);
if(localCustomerStaff != null){
log.info("{}:缓存在Redis中命中!staffId为:{}", LocalDateTime.now(), staffId);
return;
}
// 如果缓存中没有数据,需要查询数据库
localCustomerStaff = mapper.findLocalCustomerStaffByStaffId(Long.parseLong(staffId));
if(localCustomerStaff != null){
log.info("{}:数据在数据库中获取!staffId为:{}", LocalDateTime.now(), staffId);
redisRepository.saveLocalCustomerStaff(localCustomerStaff);
log.info("{}:缓存写入成功!staffId为:{}", LocalDateTime.now(), staffId);
return;
}
// 如果数据库中也没有,就往缓存中写入一个空对象
log.info("{}:数据在数据库中获取!staffId为:{}", LocalDateTime.now(), staffId);
redisRepository.saveEmptyCustomerStaff(staffId);
}
}
测试用例:主要就是使用@PostConstruct注解在执行测试用例前初始化了布隆过滤器
@ExtendWith(SpringExtension.class)
@SpringBootTest(classes = DistributionImTicketApplication.class)
@Slf4j
public class CustomerStaffBloomFilterTest {
@Autowired
private LocalCustomerStaffMapper mapper;
@Autowired
private LocalCustomerStaffRedisRepository redisRepository;
public static BloomFilter<String> bloomFilter;
@PostConstruct
public void init(){
long start = System.currentTimeMillis();
List<LocalCustomerStaff> staffs = mapper.selectList(null);
if(staffs != null && staffs.size() > 0){
bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), staffs.size());
staffs.forEach(staff -> {
bloomFilter.put(staff.getId().toString());
});
}
log.info("初始化全部客服数据到布隆过滤的时间为:{}", System.currentTimeMillis() - start);
}
@Test
public void customerStaffQueryTest() throws Exception {
int consurrent = 1000;
// 使用循环栅栏来实现1000个线程同时并发工作
CyclicBarrier cyclicBarrier = new CyclicBarrier(consurrent);
// 生成1000个固定线程的线程池
ExecutorService executorService = Executors.newFixedThreadPool(consurrent);
long start = System.currentTimeMillis();
for (int i=0; i<consurrent; i++) {
executorService.execute(new BloomFilterThread(cyclicBarrier, bloomFilter, mapper, redisRepository));
}
executorService.shutdown();
// 等待线程池中的任务全部执行完成
while (!executorService.isTerminated()){
}
log.info("1000个线程并发查询数据库,耗时:{}", System.currentTimeMillis() - start);
}
}
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号