
07-分布式搜索
一、使用Elastic Stack构建搜索能力
(一)搜索场景和解决方案
搜索是互联网系统的底层基础能力。
1、搜索引擎的基本特性和应用场景
搜索引擎的业务特征:以文本为中心,以读取为主操作,面向文档,灵活的、非结构化数据模式、内容关联性
搜索引擎的技术特征:海量文档数据、可扩展、容易部署、查询优化、结果按相关性排序
2、搜索引擎的两大应用场景
关键字搜索(多元化搜索条件数据过滤、转换和展示)
排名检索(置顶搜索、自定义排序规则)
3、搜索和数据库查询的区别
场景多元化:可以做关键字搜索和排名搜索
交互定制化:热门搜索、推荐搜索等等,可以做定制化
性能方面的高性能
4、什么是搜索
搜索是倒排索引 + 匹配评分
5、搜索引擎的执行流程:
添加:收集数据,维护索引围挡,构建索引
查询:搜索索引,找到索引,根据索引定位索引文档
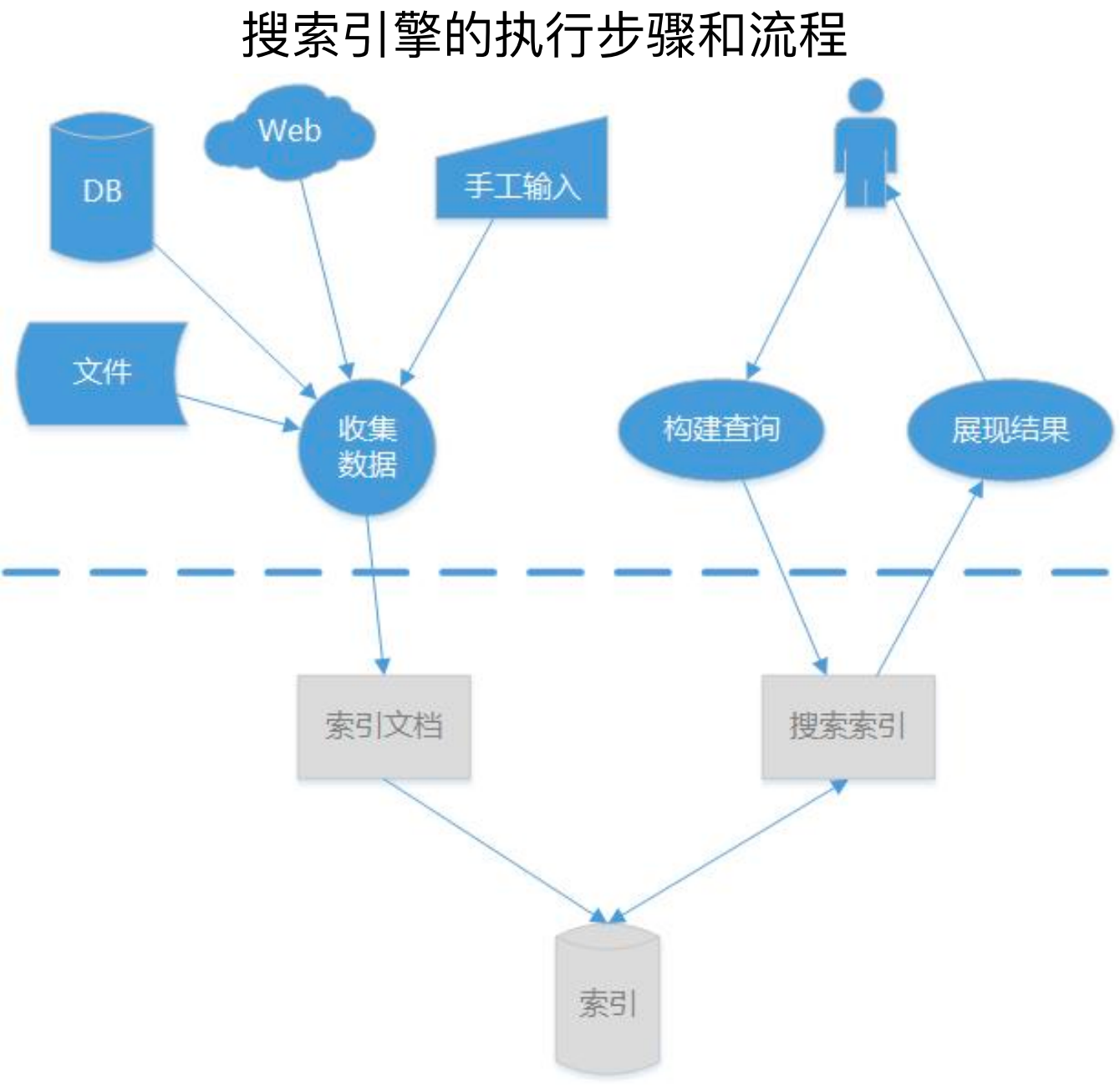
6、搜索引擎的实现
搜索引擎的实现可以分为底层索引和搜索能力,以及高层服务和体验能力,底层是使用Lucene实现的,高层是基于Elastic Search 或者 solr 来时实现的,Lucene是信息检索工具包,而 Elastic Search/Solr是企业级的搜索引擎系统。
(二)Elastic Stack
Lucene不是一个完整的搜索应用,只是维护倒排索引的工具。
Elastic Stack中有四个组件,分别是Elastic Search、Logstash、Kibana、Beats。
流程是:Beats(采集数据)→Logstash(ETL,加工和处理数据)→Elastic Search(存储与搜索)→Kibana(数据可视化)
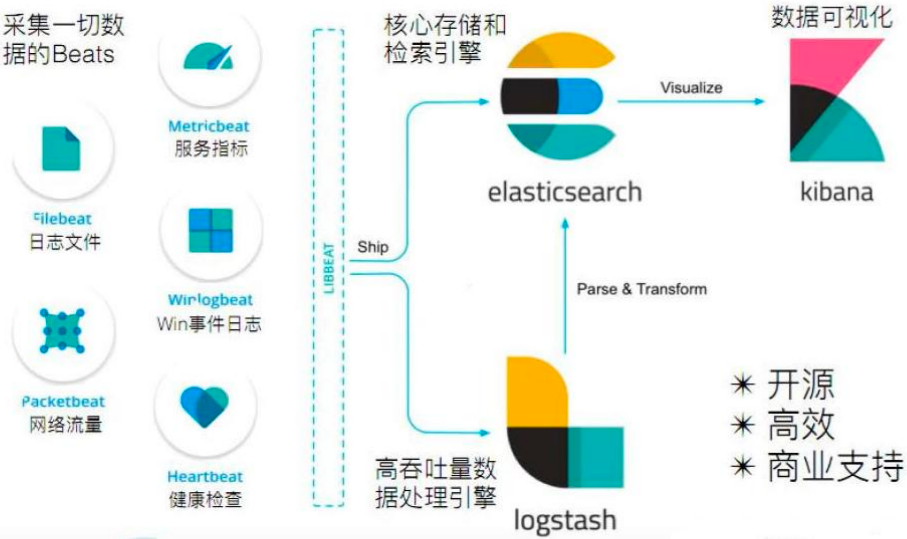
Elastic Search是企业级Web应用,支持功能扩展和分布式架构,提供了分页排序、自动补全、拼写纠错、展示高亮等系列功能。
ES 与 Solr 的对比:
ES内置分布式部署组件,开箱即用,Solr依赖外部组件,例如Zookeeper等,部署略显复杂;
ES是实时创建索引,Solr非实时,Solr会产生IO阻塞,查询性能较差,因此ES有明显优势;
数据量不大时Solr搜索有优势,但随着数据量增加ES无明显的性能损失,而Solr会明显变慢;总体来说Elastic Search的实时搜索性能优于Solr。
(三)搜索系统的开发过程
设计和开发搜索功能的步骤:
创建索引和文档
集成分词和词库
实现多元化搜索
打造搜索平台化
1、创建索引和文档
搜索引擎与关系型数据库对比:索引 --> 数据库、类型 --> 表、字段 --> 列数据、文档 --> 行数据
如下所示,properties设置了字段以及字段类型,然后通过create添加了一个文档(一行数据)
PUT /book_info
{
"mappings":{
"properties":{
"book_id":{
"type":"long"
},
"book_name":{
"type":"text"
},
"book_url":{
"type":"keyword"
},
"book_describe":{
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
{"create":{"_index":"book_info","_id":"1"}}
{
"book_id":1,
"blog_name":"Spring Boot进阶",
"book_url":"https://item.jd.com/13229441.html",
"book_describe":"Spring Boot框架的进阶书"
}
2、集成分词和词库:
分析器:
多语言分析器:Standard;
中文分析器:IK
词库:
语义相关:停用词、同义词、敏感词;
行为相关:热搜词(例如搜的越多,搜索结果越靠前)、相关搜索词(例如搜索春节,可以吧过年带出来)
如下所示,第一段是使用standard分词器对 "The quick brown fox" 进行分词,最终分成了多个分词,即 tokens,如下第二段代码。
POST _analyze
{
"analyzer": "standard",
"text": "The quick brown fox"
}
{
"tokens":[
{
"token":"the",
"start_offset":0,
"end_offset":3,
"type":"<ALPHANUM>",
"position":0
},
{
"token":"quick",
"start_offset":4,
"end_offset":9,
"type":"<ALPHANUM>",
"position":3
}
]
......
}
3、实现多元化搜索
整个搜索过程可以分为搜索输入、搜索执行、搜索输出,针对于每一个节点,都可以做一些定制化的处理。
例如在搜索输入阶段,可以做搜索词不全、搜索词纠错、搜索词推荐等
在搜索执行阶段,可以做单字段搜索、多字段搜索、聚合搜索等
在搜索输出阶段,可以做搜索高亮显示等
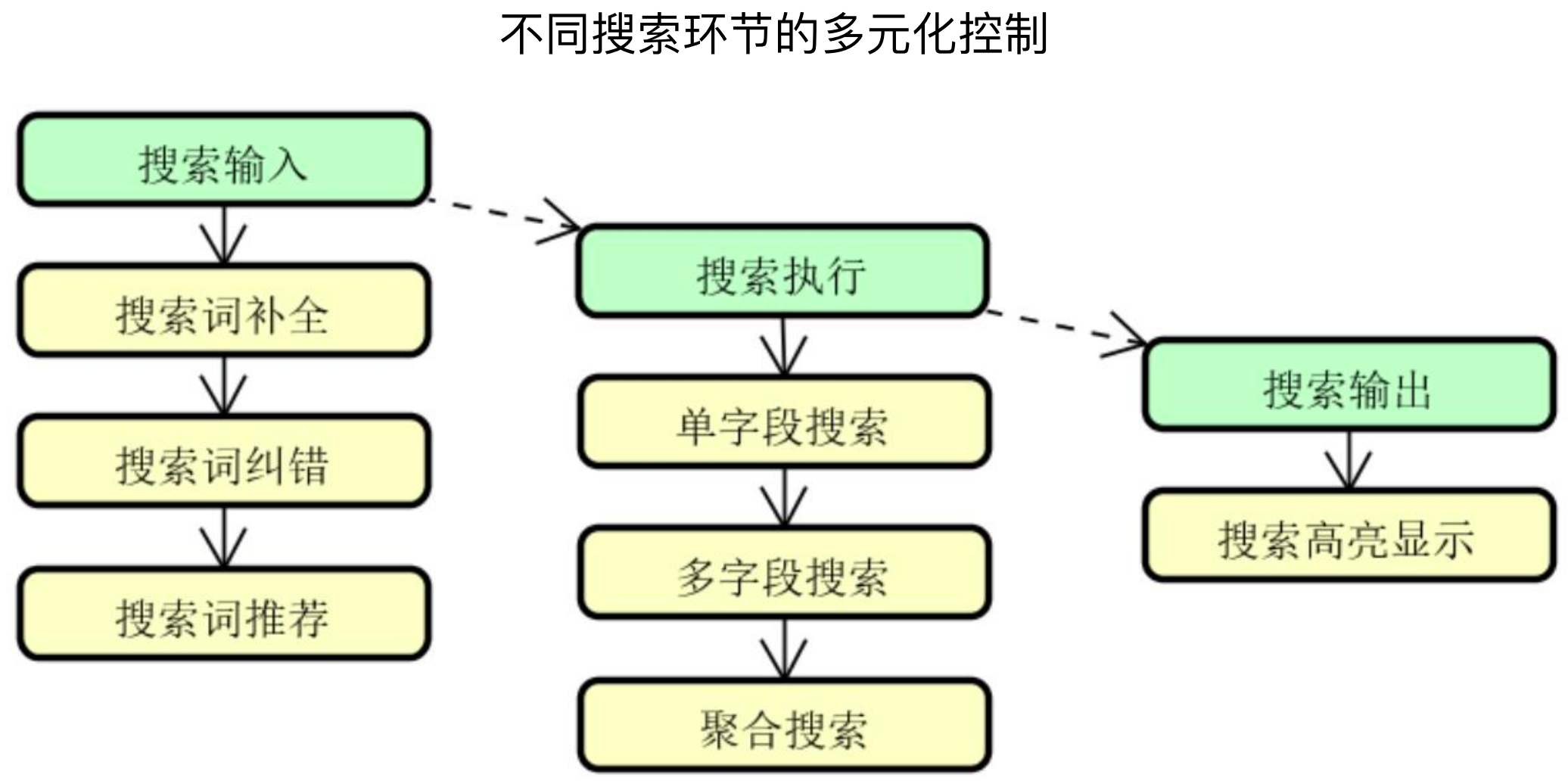
4、打造搜索平台化:
首先整个平台会对外提供一个通用服务接口,为各个客户端提供服务。这一块一般是 Java 团队来做,接口内的数据来自于数据平台、配置信息、基础搜索支持。
数据平台的信息主要来自原各个客户端的埋点数据,这一块主要由大数据团队负责
搜索配置信息一部分来自数仓的分析结果,例如根据买点信息更新热搜词和搜索相关词等,一部分来自运营配置平台,其中运营配置平台是一拨人负责
基础搜索支持主要是专门 ES 团队来负责,处理包括停用词、敏感词、专用词、同义词等内容。

二、构建底层索引和搜索机制
(一)Lucene构建索引
1、搜索引擎完整构成
搜索引擎的构成如下所示,最核心的是其中的黄色部分,算是搜索引擎的内核,然后在内核基础上,需要对用户提供一些操作接口,然后提供构建文档和原始文档的能力,同时还需要和外部系统进行交互,以及做一些辅助功能以提高用户体验。
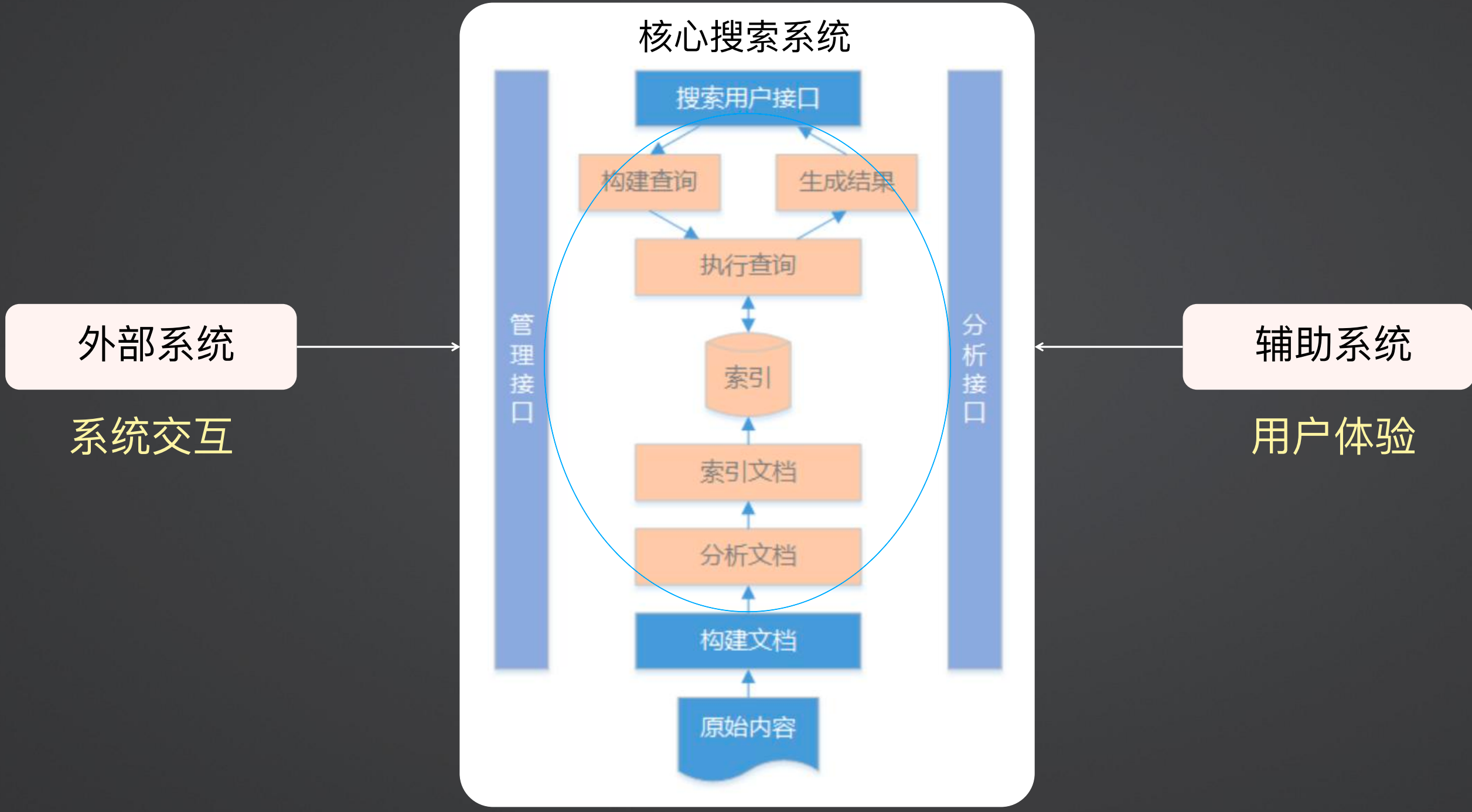
2、Lucene
上面黄色的搜索内核部分,就是使用Lucene,Lucene不是一个完整的搜索应用,其是一个基础的搜索引擎工具库。
Lucene最重要的两个功能是建立索引和执行搜索,建立索引的过程就是文档分析和文档建索引;搜索是建立搜索和执行搜索的过程。
建立搜索就是要确定是搜单个字还是多个字、模糊搜索还是精准匹配、项搜索还是多字段搜索、搜索完评分怎么打分等等。
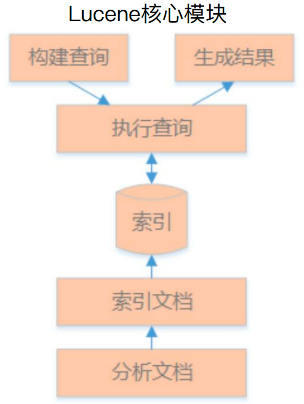
3、索引构建过程
倒排索引构建:给定一个文档,分析这个文档包含哪些单词,然后标记出哪些文档包含某个单词
索引、文档和域:文档(Document)是索引和搜索的原子单位,文档包含域(Field),而域包含被搜索内容,即索引。
4、索引组件:
首先一个Document中包含 Field的集合,一个Feild包含域名和域值,然后分析器按照一定的规范分析需要分析的Feild,分析出的结果通过IndexWriter写入索引库(文件目录)。
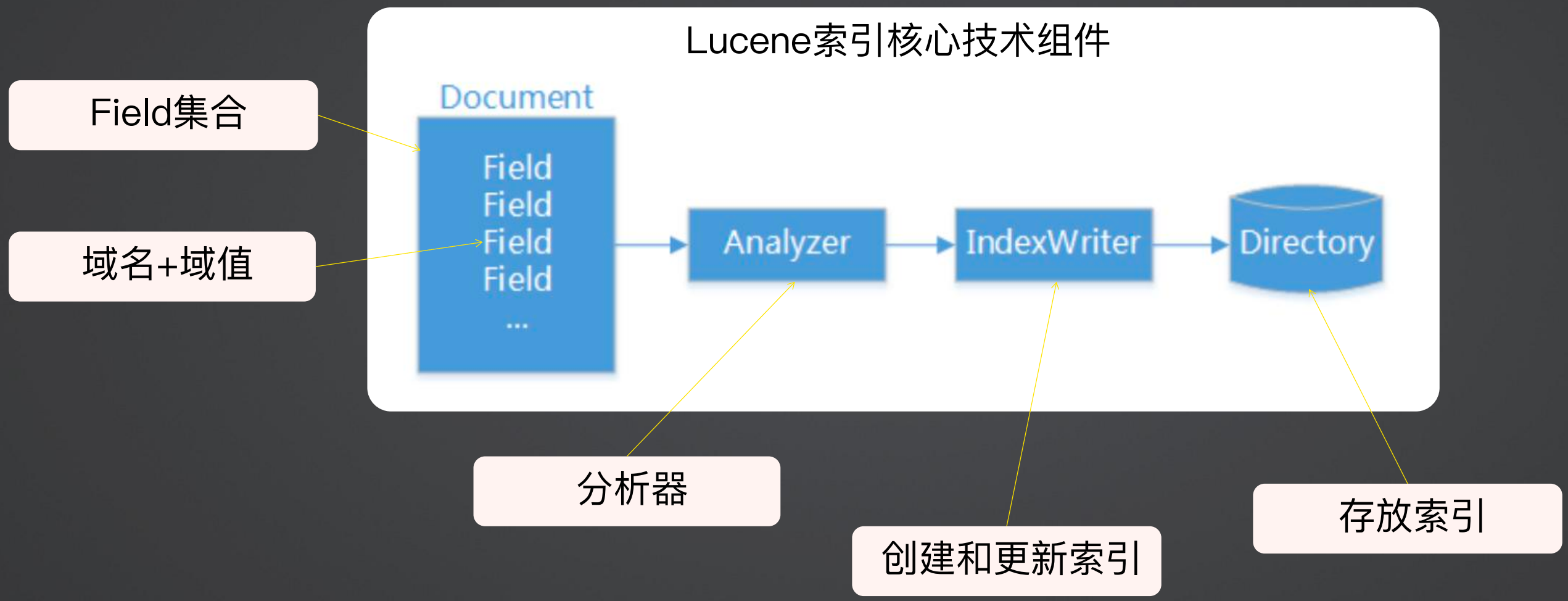
5、构建索引代码样例
(1)引入Lucene依赖
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>8.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-backward-codecs</artifactId>
<version>8.9.0</version>
</dependency>
(2)创建索引工具类
主要是封装Lucene底层的实现,并对上层操作屏蔽。
首先创建一个文件路径,并设置其分析器、合并索引配置、OpenMode等信息,并返回一个IndexWriter。
public class IndexUtil {
public static IndexWriter getIndexWriter(String indexPath, boolean create) throws IOException {
// 构建 FS 路径
Directory dir = FSDirectory.open(Paths.get(indexPath, new String[0]));
// 分析器,这里构建一个WhitespaceAnalyzer分析器,使用空格进行分析
Analyzer analyzer = new WhitespaceAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
// 合并:把不同的索引合并成一个索引
LogMergePolicy mergePolicy = new LogByteSizeMergePolicy();
//设置segment添加文档(Document)时的合并频率
// 值较小,建立索引的速度就较慢
// 值较大,建立索引的速度就较快,>10适合批量建立索引
mergePolicy.setMergeFactor(50);
//设置segment最大合并文档(Document)数
//值较小有利于追加索引的速度
//值较大,适合批量建立索引和更快的搜索
mergePolicy.setMaxMergeDocs(5000);
if (create) {
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
} else {
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
}
IndexWriter writer = new IndexWriter(dir, iwc);
return writer;
}
}
(3)写入索引
首先通过构造函数初始化IndexWriter,主要就是设置索引存储位置,如果位置不存在,则创建一个目录。
indexDoc方法负责生成索引,首先添加Field域,然后将域添加到Document文档中,如果是新增操作,则直接使用writer.addDocument,如果是更新操作,则调用writer.updateDocument方法,这里需要注意一点,新增方法的入参是document,更新方法的参数是term和document,term是项的概念,后面会解释。
最后需要提交和关闭IndexWriter,这样才能将索引写入文件。
public class BookIndex {
private String indexPath = "~/Documents/workspace/customer-system/customer-system-distribution/distribution-search-service/logs";
private IndexWriter writer;
public BookIndex() {
try {
File file = new File(indexPath);
if (!file.exists()) {
file.mkdir();
}
this.writer = IndexUtil.getIndexWriter(indexPath, true);
} catch (IOException e) {
e.printStackTrace();
}
}
public void indexDoc(List<Book> books) throws Exception {
for (Book book : books) {
Document document = new Document();
Field id = new Field("id", book.getId()+"", TextField.TYPE_STORED);
Field title = new Field("title", book.getTitle(), TextField.TYPE_STORED);
Field summary = new Field("summary", book.getSummary(), TextField.TYPE_STORED);
document.add(id);
document.add(title);
document.add(summary);
if(writer.getConfig().getOpenMode() == IndexWriterConfig.OpenMode.CREATE) {
writer.addDocument(document);
}else {
writer.updateDocument(new Term("id", book.getId()+""), document);
}
}
// 关闭索引
writer.commit();
writer.close();
}
}
(4)SearchService
@Service
public class SearchService {
private String indexPath = "~/Documents/workspace/customer-system/customer-system-distribution/distribution-search-service/logs";
@Autowired
private BookIndex bookIndex;
public void write(List<Book> books) throws Exception {
bookIndex.indexDoc(books);
}
//搜索
public List<Map> search(String value) throws Exception {
return null;
}
}
(5)Controller
@RestController
public class SearchController {
@Autowired
private SearchService searchService;
//创建索引
@GetMapping("/index")
public String createIndex() throws Exception {
// 拉取数据
List<Book> books = new ArrayList<>();
books.add(new Book(1, "hello", "this is hello book"));
books.add(new Book(1, "blue sky", "this is blue sky book"));
searchService.write(books);
return "创建索引成功";
}
//搜索
@GetMapping("search/{query}")
public List<Map> getSearchText(@PathVariable String query) throws Exception {
List<Map> mapList = searchService.search(query);
return mapList;
}
}
(6)结果
执行完创建索引后,可以看到索引目录有以下文件,其中write.lock是在未创建索引前就有的,主要是为了锁住目录。
write.lock的创建时机和代码的写法有关系,上面的代码样例使用了Spring的依赖注入,然后在构造函数中创建了IndexWriter,因此在项目启动时,就创建了索引文件的目录,并生成了write.lock文件。

(二)Lucene执行搜索
1、搜索组件:
IndexSearcher:搜索引擎的入口类,通过调用其各种search方法完成所有搜索操作
查询条件:
Query:封装某种查询类型的具体子类
QueryParser:将用户输入的查询表达式转换成具体的Query对象
查询结果:
TopDocs:保存search方法返回的具有较高评分的顶部文档(一组结果)
ScoreDoc:提供对TopDocs中每条搜索结果的访问接口(一组中的一个结果)
2、基本搜索:
在上面的更新代码中,提到了term的概念,基本搜索实际上就是项搜索,也可以叫特定项搜索,TermQuery
term = 文本内容 + 域名,即搜索内容+搜索域名,是面向搜索条件的描述
Field = 域名 + 域值,即域名和域对应的值,是面向搜索结果的描述
例如特定项搜索就是
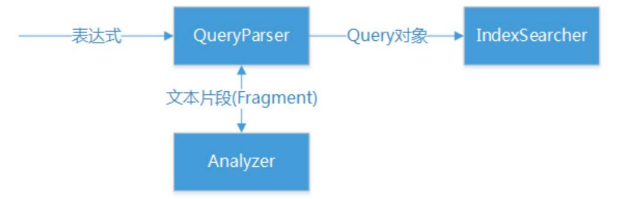
特定项搜索:TermQuery,参数化搜索:QueryParser
搜索流程如下图所示,首先根据表达式并通过QueryParse生成Query对象,这个过程需要使用分析器Analyzer进行解析;IndexSearcher使用Query对象进行查询
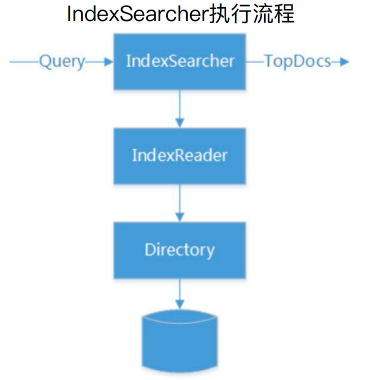
3、IndexSearcher
IndexSearcher也是一种封装,其底层通过IndexReader读取索引目录并读取数据。
IndexSearcher 提供的API
//直接搜索,返回评分最高的文档数量
TopDocs search(Query query,int n)
//搜索受文档子集约束、约束条件基于过滤策略
TopDocs search(Query query,Filter filter,int n)
//同上,结果排序通过自定义的Sort完成
TopFieldDocs search(Query query, Filter filter, int n,Sort sort)
//匹配搜索条件的文档数量
totalHits
//包含搜索结果的ScoreDoc对象数组
scoreDocs
//通过排序返回最大评分
getMaxScore
4、搜索代码样例
(1)构建IndexSearcher
如上分析所示,通过DirectoryReader打开FSDirectory文件,而FSDirectory通过传入的文件路径创建,最终创建一个IndexSearcher
public class SearchUtil {
public static IndexSearcher getIndexSearcher(String parentPath, ExecutorService service) throws IOException {
IndexReader reader = null;
try {
reader = DirectoryReader.open(FSDirectory.open(Paths.get(parentPath, new String[0])));
} catch (IOException e) {
e.printStackTrace();
}
return new IndexSearcher(reader, service);
}
}
(2)搜索
首先构建Query对象:通过解析器和搜索字段创建一个多字段解析器,根据传入的参数创建一个Query对象
通过第一步的IndexSearcher查询获取查询结果TopDocs,根据TopDocs获取ScoreDoc集合
循环ScoreDoc获取Document,解析Document并将其放入结果集中。
public List<Map> search(String value) throws Exception {
List<Map> list = new ArrayList<>();
Map map = null;
Analyzer analyzer = new WhitespaceAnalyzer();
ExecutorService executorService = null;
try{
executorService = Executors.newCachedThreadPool();
IndexSearcher searcher = SearchUtil.getIndexSearcher(indexPath, executorService);
// 构建 Query 对象
String[] fields = {"title", "summary"};
MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, analyzer);
Query query = parser.parse(value);
// 搜索并获取结果
TopDocs result = searcher.search(query, 1000);
ScoreDoc[] hits = result.scoreDocs;
for(int i=0; i< hits.length; i++){
Document hitDoc = searcher.doc(hits[i].doc);
map = new HashMap();
map.put("id", hitDoc.get("id"));
map.put("title", hitDoc.get("title"));
map.put("summary", hitDoc.get("summary"));
list.add(map);
}
return list;
}finally {
executorService.shutdown();
}
}
5、搜索类型
上面代码演示了多字段搜索,除了所字段搜索外,还有:
TermQuery(指定项搜索)
TermRangeQuery(项范围搜索)
NumericRangeQuery(数字范围搜索)
BooleanQuery(组合搜索)
PrefixQuery(字符串搜索)
PhraseQuery(短语搜索)
WildcardQuery(通配符搜索)
FuzzyQuery(模糊搜索)
(三)Lucene分析过程
1、分析过程:
分析器:所谓分析,是将Field(域)文本转换为Term(项)的过程,分析过程中所生成的基本单元为Token。
分析器(Analyzer)是搜索引擎的核心组件,与文本所属的语种和行业领域有直接关系。
在建立索引和执行搜索时,都需要使用分析器进行分析,具体代码样例如下代码所示:
//创建索引时执行分析
Analyzer analyzer = new StandardAnalyzer(...);
IndexWriter writer = new IndexWriter(..., analyzer, ...);
//搜索时执行分析
Analyzer analyzer = new StandardAnalyzer(...);
QueryParser parser = new QueryParser(..., analyzer);
Query query = parser.parse(expression);
不同的Feild可以使用不同的Analyze,Analyze分析的结果就是各个Token。
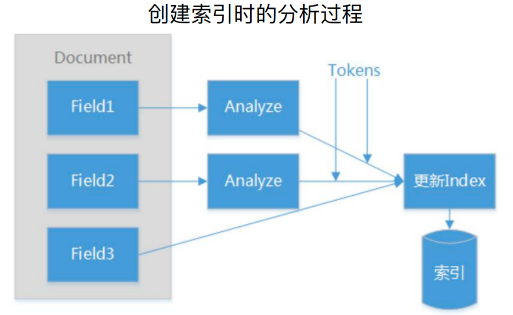
2、Token
在搜索引擎中,Token的基本结构实际上就是文本值+元数据,文本就是列举项中的一个内容,元数据指定了位置、偏移量。
如下图所示,文本是 “the quick brown fox”,分词后变为四个词,偏移量分别为0-3,4-9,10-15,16-19,这就是一个个Token,这些Token连在一起就像一个Token链。
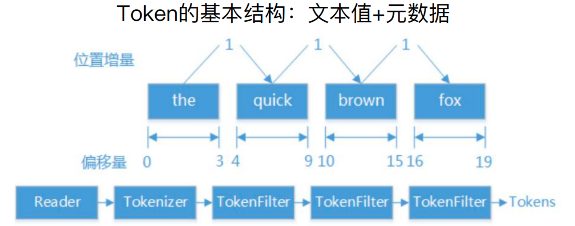
如果使用代码的方式来表示这些Token的话,其有一些Attribute(属性)来表示,样例如下:
TermAttribute:词汇单元对应的文本
PositionIncrementAttribute:位置增量
OffsetAttribute:起始字符和终止字符的偏移量
TypeAttribute:词汇单元类型
FlagsAttribute:自定义标志位
PayloadAttribute:词汇单元的有效负载
Tokenizer处理Token的方式实际上采用的是管道-过滤器模式。
3、内置分析器:分析器的执行效果与词库建设息息相关
前面代码代码用的分析器是WhitespaceAnalyzer(通过空格分隔文本),Lucene还内置了一些其他的分析器,例如:
WhitespaceAnalyzer:通过空格分隔文本
SimpleAnalyzer:非字母分隔文本
StopAnalyzer:去掉常用单词
StandardAnalyzer:最复杂的核心分析器
三、打造企业级搜索词库管理体系
(一)词库的构建策略
1、中文分词器
中文分词器有 IK Analyzer和 HanLP Analyzer两种。
IK Analyzer是提供ik_max_word和ik_smart两种分词策略;是最主要的中文分词器。
HanLP Analyzer是属于HanLP工具包,支持多种分词算法。
2、IK分析器
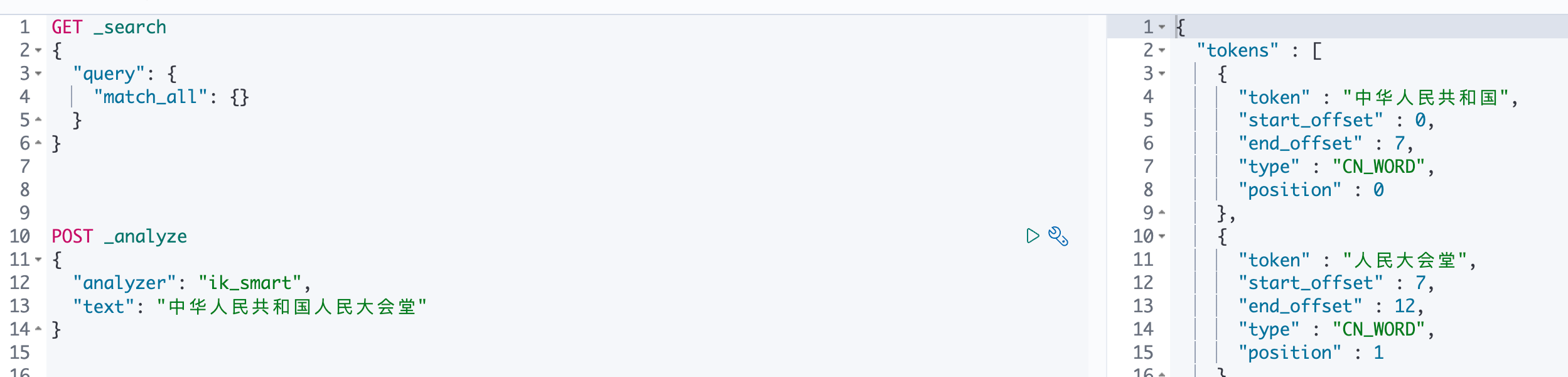
ik_smart 和 ik_max_word 两个分析器的主要区别在于切分词语的粒度上,ik_smart的切分粒度比较粗,而 ik_max_word将文本进行了最细粒度的拆分,甚至穷尽了各种可能的组合。
以中华人民共和国人民大会堂 为例,ik_smart 可以分为中华人民共和国、人民大会堂,ik_max_word可以分为中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂。
3、安装IK分析器:
(1)安装es
安装详见:ES--ELK搭建(ElasticSearch、Logstash、Kibana)
(2)安装 ik 分词器
在 github上下载与es对应版本的 ik 分词器(版本必须一致,否则会启动报错),下载地址:https://github.com/medcl/elasticsearch-analysis-ik/
然后在 es的 plugin目录下创建 ik目录(目录名称必须为 ik,否则会报错),然后将下载的 ik 分词器放到 ik 目录。
(3)引入Kibana
安装详见:ES--ELK搭建(ElasticSearch、Logstash、Kibana)
Kibana是为Elasticsearch设计的分析和可视化平台。
通过Kibana来搜索和查看存储在 Elasticsearch 索引中的数据并与之交互,可以很容易实现高级的数据分析和可视化,并以图表的形式展现出来。
4、专业词库
对于专业场景来说,有一些词是在这个领域内是一个词语,但是在通用领域就不是一个词语,在这样的场景下,就需要专业词库建设。
以医疗健康领域为例:就需要有医院词库(hospital.dic)、科室词库(department.dic)、药品词库(drug_info.dic)、健康词汇词库(health_word.dic)、症状词库 (symptom.dic)、疾病词库 (illness.dic)、补充停用词库(extra_stopword.dic)
以“新冠病毒”为例,如果在不做专业词库建设的情况下,分词结果是“新、冠、病毒”,而我们期望的是“新冠病毒”作为一个完成的词来呈现,那么就需要针对这个词做一些处理。
(1)新增词库
上面的操作中,在es的plugin目录中创建了一个ik目录,并复制了ik分词器的内容。
在 ik 分词器中,新建一个文件夹,在文件夹中创建一个以 .dic 结尾的文件,文件内写入我们要新增的词,我这里在创建了一个customer目录,并在目录中创建了一个customer.dic文件,在文件中配置了"新冠病毒"这个词。
(2)配置词库
修改 IK 分词器配置文件IKAnalyzer.cfg.xml,添加自己的扩展词
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">customer/customer.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
配置完成后,重启es,此时对于“新冠病毒”的分词结果就只有一个“新冠病毒”的结果。
(二)词库热更新机制
对于词库更新的场景,需要重启ES,这个体验非常不好,那么就引出了词库热更新的需求。
对于热更新,可以分为两种情况,一种是类似于敏感词表这种,不会变更,只会新增;另外一种是类似专业四表这种,会做新增、删除和更新操作。
同时对于热更新来说,期望是实时更新。
1、只新增:
(1)方案一
开放一个扩展词增量获取接口,根据IK分词器的规范设置HTTP请求头和响应信息通过IK的远程扩展词配置,实现分词器与远程扩展词接口之间的集成。
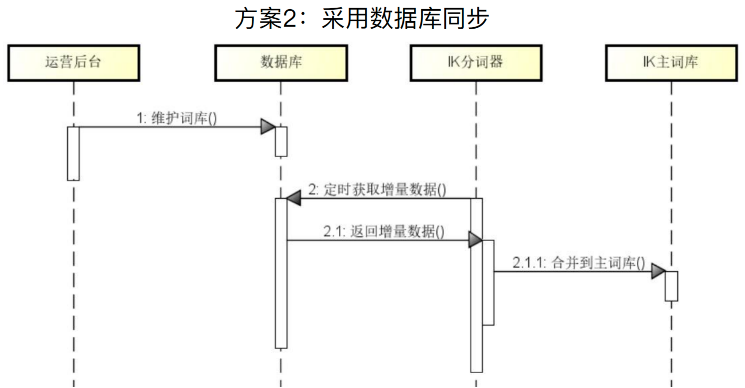
交互图如下所示,运营后台维护词库,然后IK分词器通过扩展词接口增量查询数据库的扩展词,并将其合并到主词库。
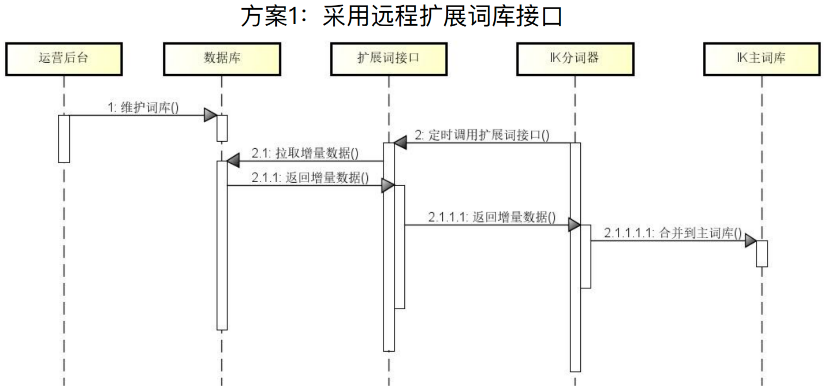
实现扩展词接口的框架如下所示,其提供了两个方法,方法地址一样,但是method不一样,一个是head一个是get,其逻辑是首先调用head接口,判断是否有需要变更的数据,如果存在要变更的数据,就调用get方法获取变更内容,最终更新到主词库。更新逻辑是IK分词器内置的实现。
@RestController
@RequestMapping(value = "ik")
public class DictionaryController {
//设置HTTP请求头
@RequestMapping(value = "/dict", method = RequestMethod.HEAD)
public void needUpdate(HttpServletRequest request, HttpServletResponse response) {
......
}
//设置HTTP响应信息
@RequestMapping(value = "/dict", method = RequestMethod.GET)
public void sendDict(HttpServletRequest request, HttpServletResponse response) {
......
}
}
代码样例:
首先在业务代码中编写上述内容,这里用到了HTTP协议的相关内容,当调用 HEAD 方法时,如果是首次加载或者有更新的数据,就将返回结果的header中的ETag设置为If-None-Match,同时设置Last-Modified为当前时间。
然后 IK 分词器就会判断,如果ETag为If-None-Match,就会调用get方法,获取数据。
@RestController
@RequestMapping(value = "ik")
public class DictionaryController {
private static Logger LOGGER = LoggerFactory.getLogger(DictionaryController.class);
// 最新更新间隔5分钟
private static final long MIN_UPDATE_INTERVAL = 300;
private static final String CHARSET = "UTF-8";
// 请求头
private static final String REQUEST_MODIFIED_KEY = "If-Modified-Since";
private static final String RESPONSE_MODIFIED_KEY = "Last-Modified";
// 响应头
private static final String REQUEST_ETAG_KEY = "If-None-Match";
private static final String RESPONSE_ETAG_KEY = "ETag";
@Autowired
DictionaryService dictionaryService;
private long globeLastModified;
@RequestMapping(value = "/dict", method = RequestMethod.HEAD)
public void needUpdate(HttpServletRequest request, HttpServletResponse response) throws IOException {
long current = System.currentTimeMillis() / 1000;
String lastModifiedStr = request.getHeader(REQUEST_MODIFIED_KEY);
String eTag = request.getHeader(REQUEST_ETAG_KEY);
if (StringUtils.isEmpty(lastModifiedStr)) {
// 首次加载
response.setStatus(HttpStatus.OK.value());
response.setHeader(RESPONSE_ETAG_KEY, eTag);
response.setHeader(RESPONSE_MODIFIED_KEY, String.valueOf(current));
return;
}
long lastModified;
try {
lastModified = Long.parseLong(lastModifiedStr);
globeLastModified = lastModified;
} catch (NumberFormatException e) {
LOGGER.error("invalid header info {}", lastModifiedStr, e);
response.sendError(HttpStatus.BAD_REQUEST.value(), "invalid header info");
return;
}
// 上次更新时间不会大于当前时间
if (lastModified >= current) {
LOGGER.error("illegal header info {}", lastModifiedStr);
response.sendError(HttpStatus.BAD_REQUEST.value(), "illegal header info");
return;
}
// 防止频繁更新
if (current <= lastModified + MIN_UPDATE_INTERVAL) {
response.setStatus(HttpStatus.NOT_MODIFIED.value());
return;
}
long lastDictionaryUpdateTime = dictionaryService.getLastUpdateTime() / 1000;
// 上次更新后如果数据库没有更新则不进行同步
if (lastModified >= lastDictionaryUpdateTime) {
response.setStatus(HttpStatus.NOT_MODIFIED.value());
} else {
response.setStatus(HttpStatus.OK.value());
response.setHeader(RESPONSE_ETAG_KEY, eTag);
response.setHeader(RESPONSE_MODIFIED_KEY, String.valueOf(current));
}
}
@RequestMapping(value = "/dict", method = RequestMethod.GET)
public void sendDict(HttpServletRequest request, HttpServletResponse response) {
response.setStatus(HttpStatus.OK.value());
response.setContentType("text/plain; charset=" + CHARSET);
List<String> words = dictionaryService.getWords(globeLastModified * 1000);
if (words != null) {
try (OutputStream out = response.getOutputStream()) {
for (String word : words) {
out.write((word + "\n").getBytes(CHARSET));
}
} catch (IOException e) {
LOGGER.error("dict update faild!", e);
}
}
}
}
然后在 IK 分词器中配置远程调用地址
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">customer/customer.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.249.1:11001/ik/dict</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
(2)方案二:
对于方案一来说,有时候有点弱,要是做一些扩展就不是很灵活,那么就可以使用第二种方案,修改 IK 分词器源码来做一些定制化。
主要流程是:首先调整 IK 分词器中词库加载代码。在代码中,从数据库中定时获取各个扩展词表中的数据,然后加载到IK分词器的主词库中。
但是这种方案不是很推荐,因为这种方式只适用于自己搭建ES服务,但是有很多时候我们使用的是云厂商的服务,那么这种方案就不能实现。
主要就是修改 IK 分词器源码中的代码。
//IK自带的字典管理类
public class Dictionary {
public static synchronized void initial(Configuration cfg) {
//通过定时任务获取数据库数据
DictLoader.getInstance().loadMysqlExtensionWords();
}
}
//自定义的数据库数据加载工具类
public class DictLoader {
public void loadMysqlExtensionWords() {
//首次加载全量的词
// 后面按照修改时间只加载增量的词
// 把从数据库加载的词放到字典里
Dictionary.getSingleton().addWords(extensionWords);
}
}
2、新增、更新和删除操作:
在IK的Dictionary类中,删除操作直接调用disableWords()方法,删除扩展词;修改操作先调用disableWords()方法删除扩展词,后调用addWords()方法添加扩展词。
最终将项目打包,替换原有的IK分词器内容,以及替换 jdbc 配置文件,添加数据库驱动包。
//自定义的数据库数据加载工具类
public class DictLoader {
public void loadMysqlExtensionWords() {
//对于删除的词库,直接执行disableWords操作
// 对于更新的词库,先执行删除操作
Dictionary.getSingleton().disableWords(deletedExtensionWords);
//对于更新和新增的词库,再执行新增操作
Dictionary.getSingleton().addWords(extensionWords);
}
}
四、使用Elastic Search构建搜索服务
(一)Elastic Search索引和文档操作方式
1、创建索引
比较建议通过kibana创建索引,使用kibana创建索引主要有两步:
(1)初始化settings
配置项,类似于初始化一个数据库时要配置编码格式,数据库名称等等。
如下代码表示设置了一个名为customer_auto_reply_index的索引,分词器使用的是ik_max_word
PUT /customer_auto_reply_index
{
"settings":{
"analysis":{
"analyzer":"ik_max_word"
}
}
}
(2)创建mappings
Document定义,类似于设置数据库的表结构。例如下面的代码表示,对于索引customer_auto_reply_index设置了三个Field,分别是id、word、content,对应的数据类型分别是long、text、text,其中word和content是需要分词和搜索的。
PUT /customer_auto_reply_index
{
"mappings":{
"properties":{
"id":{
"type":"long"
},
"word":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
}
},
"content":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
}
}
......
}
}
}
2、同步索引数据
添加数据有三种策略:
基于Kibana同步索引数据:开发调试使用
基于Logstash同步索引数据:一般场景同步,官方比较推荐,但是这种方案会有数据延迟。
基于客户端API同步索引数据:业务系统数据双写,可以解决数据延迟的问题。但是还是有点弱,现在有很多公司开始使用流的方式来写入数据,例如使用Flink。
(1) Kibana写入数据
下面的代码表示对索引customer_auto_reply_index写入了两条数据,然后查询该索引的全部数据。
这里需要提一点,访问路径中的 _doc 表示这是一个文档,_search 表示查询,在 ES 中,以下划线开头的都是其内置的语法,不能随意变动。
PUT /customer_auto_reply_index/_doc/1
{
"id":"1",
"word":"物流",
"content":"我们使用是用中通物流,当天下午15点之前下单当天发货,江浙沪预计1~2天到货,其 他省份预计3~4天到货",
"sort":"100"
}
PUT /customer_auto_reply_index/_doc/2
{
"id":"2",
"word":"发货地址",
"content":"我们的发货地址是杭州、上海两地多仓库发货",
"sort":"100"
}
get customer_auto_reply_index/_search
{
"query":{
"match_all":{
}
}
}
(2)Logstash写入数据
使用Logstash收集数据,例如从数据库中获取数据更新到ES中,那么就可以使用Logstash的logstash-input-jdbc插件。
在该插件中,有input输入和output输出两部分组成,输入就是数据从哪来,输出就是将数据写到ES的哪个索引。
控制输入:实际上就是配置了数据库的相关信息,以及获取数据的sql脚本,然后配置一个定时任务,其会定时执行数据库脚本获取数据。
input {
jdbc {
# 数据库
jdbc_connection_string => "jdbc:mysql://localhost:3306/customer_system"
# 用户名密码
jdbc_user => "root" jdbc_password => "root"
# jar包的位置
jdbc_driver_library => "./mysql-connector-java-8.0.28.jar"
# mysql的Driver
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 读取这个sql
statement_filepath => "/mysql2es.sql"
#每隔10分钟执行一次
schedule => "*/10 * * * *" ...
}
}
控制输出:将获取的数据写入es,下面的代码表示写入customer_auto_reply_index索引,然后文档id就是input中数据的id。同时将json数据输出到控制台。
output {
# index 索引名
index => customer_auto_reply_index
# 类似主键,es中id对应数据库的字段
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
这种方案在之前很流行,但是慢慢的被很多公司禁止使用,因为这种将业务逻辑放入脚本中执行,很难控制,业务边界也不清晰,优点类似于之前在Oracle中写各种执行计划。
(3)Elastic Search客户端更新数据
对于通过Elastic Search客户端更新数据,可以使用远程的ES客户端,也可以使用SpringData
原生Elastic Search客户端 :
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
Spring Data:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
配置信息:主要配置es的相关信息,以及索引信息
elasticsearch:
info:
username: elastic
password: 123456
hostname: localhost
port: 9200
scheme: http
index:
customerAutoReplyIndex: customer_auto_reply_index
配置类:用来获取配置文件值,比较推荐使用@ConfigurationProperties来获取
@RefreshScope
@ConfigurationProperties(prefix = "elasticsearch.info")
public class EsInfoConfig {
private String username;
private String password;
private String hostname;
private int port;
private String scheme;
}
客户端配置:如果使用的是原生的ES客户端,那么最终返回一个RestHighLevelClient,在需要使用的时候就可以注入该客户端进行操作。
public class EsClient {
private final EsInfoConfig esInfoConfig;
@Bean
public RestHighLevelClient restHighLevelClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost(esInfoConfig.getHostname(), esInfoConfig.getPort(), esInfoConfig.getScheme()));
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(esInfoConfig.getUsername(), esInfoConfig.getPassword()));
builder.setHttpClientConfigCallback(f -> f.setDefaultCredentialsProvider(credentialsProvider));
return new RestHighLevelClient(builder);
}
}
同步数据:RestHighLevelClient提供的API
//新增文档
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//批量新增文档
BulkResponse response = restHighLevelClient.bulk(request, RequestOptions.DEFAULT);
//更新文档
UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
//根据查询删除文档
restHighLevelClient.deleteByQuery(request, RequestOptions.DEFAULT);
3、初始化索引和数据
(1)创建索引
PUT /customer_auto_reply_index
{
"settings":{
"analysis":{
"analyzer":"ik_max_word"
}
},
"mappings":{
"properties":{
"id":{
"type":"long"
},
"word":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
}
},
"content":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword"
}
}
},
"sort":{
"type":"long"
},
"is_deleted":{
"type":"integer"
}
}
}
}
(2)添加索引
PUT /customer_auto_reply_index/_doc/1
{
"id":"1",
"word":"物流",
"content":"我们使用是用中通物流,当天下午15点之前下单当天发货,江浙沪预计1~2天到货,其他省份预计3~4天到货",
"sort":"100",
"is_deleted":"0"
}
PUT /customer_auto_reply_index/_doc/2
{
"id":"2",
"word":"发货地址",
"content":"我们的发货地址是杭州、上海两地多仓库发货",
"sort":"100",
"is_deleted":"0"
}
PUT /customer_auto_reply_index/_doc/3
{
"id":"3",
"word":"顺丰物流",
"content":"我们支持顺丰物流,但需要客户支付额外的物流费用",
"sort":"10",
"is_deleted":"0"
}
(3)查询索引
GET /customer_auto_reply_index/_search
(二)利用Elastic Search执行搜索
搜索执行流程:构建搜索对象、创建搜索条件、获取搜索结果,因为 ES 对于执行搜索封装的比较好,因此没有写在流程中。
1、构建搜索对象:
顶级搜索对象是SearchRequest,其包含搜索条件构建器SearchSourceBuilder,而SearchSourceBuilder又包含布尔查询构建器BoolQueryBuilder、高亮构建器HighlightBuilder、分页搜索支持from/size,其中BoolQueryBuilder又包含查询构建器列表QueryBuilders,QueryBuilders中包含具体构建器XXXBuilder。
Builder不止上面提到的这些,上面只是做一个样例。
SearchRequest:搜索对象
SearchSourceBuilder:搜索条件构建器
BoolQueryBuilder:布尔查询构建器,组合多个查询
QueryBuilders:查询构建器列表
XXXBuilder:具体构建器
HighlightBuilder:高亮构建器
from/size:分页搜索支持
2、创建搜索条件:
搜索条件在 ES 中有两大项,分别是项搜索和全文搜索。
项搜索:
项搜索叫做termQuery,项在上面Lucene中提到过,就是域名+搜索内容,项搜索不需要分析器,其不执行分析,搜索优点类似数据库,主要有wildcardQuery 通配符搜索,fuzzyQuery模糊搜索,prefixQuery字符串前缀搜索
全文搜索:
全文搜索会执行具体的分析操作,全文搜索有matchQuery单字段匹配搜索、multiMatchQuery多字段匹配搜索、matchPharseQuery词组匹配搜索。其中multiMatchQuery对字段进行分词处理,并依次匹配多个字段,可以在重点字段上设置权重(boost)。
3、获取搜索结果:
通过esClient.search发起搜素请求并获取结果SearchResponse,然后从SearchResponse获取匹配的数据,循环匹配数据就可以获取具体的数据,获取的数据和Lucene一样,也是一个Map结构。
//1. 发起搜素请求并获取结果
SearchResponse = esClient.search(searchRequest, EsConfig.COMMON_OPTIONS);
//2. 获取匹配的数据(SearchHits包含搜索命中结果集合)
SearchHits hits = response.getHits();
//3. 解析结果数据并包装成业务对象
for (SearchHit hit: hits) {
Map<String, Object> result = hit.getSourceAsMap();
......
}
4、搜索辅助功能:
除了上面提到的三大通用流程外,还可以设置项搜索、指定返回字段、结果计数、结果分页等
// 项搜索
SearchRequest searchRequest = ...
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(new TermQueryBuilder("city", "Hangzhou"));
// 指定返回的字段
searchSourceBuilder.fetchSource(new String[]{"title", "city"}, null);
searchRequest.source(searchSourceBuilder);
// 结果计数
CountRequest countRequest = new CountRequest("hotel");
countRequest.source(searchSourceBuilder);
CountResponse countResponse = client.count(countRequest, RequestOptions.DEFAULT);
// 结果分页
searchSourceBuilder.from(20);
searchSourceBuilder.size(10);
searchRequest.source(searchSourceBuilder);
在使用 ES 尤其是使用Kibana时,有一个重要的语言DSL(Domain Specific Language,领域特定语言)。
DSL 查询实际上就是一些辅助查询加上一些结果的展示,在 ES 中,DSL 基于JSON的搜索方式,在搜素时传入特定的JSON格式数据完成不同需求的搜索,通常可以和Kibana配合使用进行开发和调试。但是也可以不使用Kibana,使用脚本的方式上传DSL,ES 引擎也是认识的;也可以通过代码将查询条件拼装成 DSL,然后通过API调用也是可以的。
实际上我们通过API调用的方式,在ES中也会转换成DSL相同的数据结构并执行,因此在开发调试时使用DSL是一个很好的选择。
以下是DSL的样例:
//查询全部
{
"query":{
"match_all":{
}
}
}
//分页查询全部
{
"from":0,
"size":1,
"query":{
"match_all":{
}
}
}
//项查询
{
"query":{
"term":{
"title":"开发"
}
}
}
//全文多字段匹配查询
{
"query":{
"multi_match":{
"query":"Java",
"fields":[
"title",
"content"
],
"minimum_should_match":"50%"
}
}
}
5、搜索分析功能
在查询结果中,会有max_score和_score,当搜索结果出来后,谁排第一,那就是_score等于max_score的那条数据,具体某一项拍的名词,则是根据_score来排序。
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "customer_auto_reply_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : "1",
"word" : "物流",
"content" : "我们使用是用中通物流,当天下午15点之前下单当天发货,江浙沪预计1~2天到货,其他省份预计3~4天到货",
"sort" : "100",
"is_deleted" : "0"
}
(三)客服系统案例演进
1、客服系统搜索场景
对于客服系统来说,可以搜索用户信息、客服信息、也可以做客服的自动回复。
这里主要演示客服的自动回复功能,类似于淘宝中的客服自动回复。
2、引入依赖
这里要考虑版本问题,因为ES的版本管理还是有点复杂的,如果版本对应不上,就会导致项目起不来等各种各样的问题。
这里 lucene使用了8.9.0版本,ES使用了7.15.2版本。
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-backward-codecs</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</dependency>
3、配置文件
配置es的用户名、密码、地址、端口、协议,以及索引。
elasticsearch:
info:
username: elastic
password: changeme
hostname: 192.168.249.130
port: 9200
scheme: http
index:
customerAutoReplyIndex: customer_auto_reply_index
4、配置类
采用两个配置类,分别配置 ES 基础配置信息和索引信息
@Data
@Component
@ConfigurationProperties(prefix = "elasticsearch.index")
public class EsIndexProperties {
/**
* 客服自动回复索引
*/
private String customerAutoReplyIndex;
}
@Data
@Component
@ConfigurationProperties(prefix = "elasticsearch.info")
public class EsInfoConfig {
private String username;
private String password;
private String hostname;
private int port;
private String scheme;
}
5、客户端
初始化 ES 客户端,并注入 Spring 容器中。
@Configuration
@RequiredArgsConstructor
public class EsClient {
private final EsInfoConfig esInfoConfig;
@Bean
public RestHighLevelClient restHighLevelClient(){
RestClientBuilder builder = RestClient.builder(new HttpHost(esInfoConfig.getHostname(), esInfoConfig.getPort(), esInfoConfig.getScheme()));
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(esInfoConfig.getUsername(), esInfoConfig.getPassword()));
builder.setHttpClientConfigCallback(f -> f.setDefaultCredentialsProvider(credentialsProvider));
return new RestHighLevelClient(builder);
}
}
6、搜索实现
上面已经提到,对于查询来说,主要就是三步,分别是创建搜索对象、执行搜索、处理搜索结果,对于搜索执行来说,就是调用客户端的search方法,传入搜索对象就可以了,主要的流程在创建搜索对象和处理搜索结果。
(1)创建搜索对象
创建搜索对象主要分为三部分,项搜索、多字段搜索、分页。
对于项搜索,这里要查未被删除的数据;对于多字段搜索,设置哪些字段可以使用搜索词搜索;对于分页查询,要设置开始位置和每页数据量。
前面已经提到构建查询对象的层级结构,也就是如下的结构:
SearchRequest:搜索对象
SearchSourceBuilder:搜索条件构建器
BoolQueryBuilder:布尔查询构建器,组合多个查询
QueryBuilders:查询构建器列表
XXXBuilder:具体构建器
HighlightBuilder:高亮构建器
from/size:分页搜索支持
然后代码中也是按照这种结构构建,首先创建SearchSourceBuilder,然后在其中添加分页起始页、每页数据量、布尔查询构建器BoolQueryBuilder,然而BoolQueryBuilder是用来组合多种查询的,例如项搜索、所字段搜索等。其中对于多字段搜索可以设置哪些字段以及字段对应的权重。
(2)执行搜索
直接调用restHighLevelClient.search即可
(3)处理搜索结果
获取搜索结果,根据命中情况将Map转换为需要的对象即可。
全部代码如下所示:
@Service
@Slf4j
public class CustomerAutoReplySearchServiceImpl implements CustomerAutoReplySearchService {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Autowired
private EsIndexProperties esIndexProperties;
@Override
public Result<PageObject<CustomerAutoReply>> searchCustomerAutoReplies(SearchParamReq searchParamReq) throws IOException {
// 1、创建搜索对象
SearchRequest searchRequest = createSearchRequest(searchParamReq);
// 2、搜索执行
SearchResponse response;
try {
response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
log.info("搜索结果:{}", response.toString());
} catch (IOException e){
log.error("查询异常:{}", e.getMessage());
return Result.error("查询ES异常");
}
// 3、处理搜索结果
SearchHits searchHits = response.getHits();
List<CustomerAutoReply> customerAutoReplyList = new ArrayList<>();
for(SearchHit searchHit : searchHits){
Map<String, Object> result = searchHit.getSourceAsMap();
CustomerAutoReply customerAutoReply = convertCustomerAutoReply(result);
customerAutoReplyList.add(customerAutoReply);
}
PageObject<CustomerAutoReply> page = new PageObject<>();
page.buildPage(customerAutoReplyList, searchHits.getTotalHits().value, Long.valueOf(searchParamReq.getPageNum().toString()),Long.valueOf(searchParamReq.getPageSize().toString()));
return Result.success(page);
}
// 转换CustomerAutoReply对象
private CustomerAutoReply convertCustomerAutoReply(Map<String, Object> result) {
CustomerAutoReply customerAutoReply = new CustomerAutoReply();
customerAutoReply.setId(Long.parseLong(result.get("id").toString()));
customerAutoReply.setWord(result.get("word").toString());
customerAutoReply.setContent(result.get("content").toString());
customerAutoReply.setSort(Long.parseLong(result.get("sort").toString()));
customerAutoReply.setIsDeleted(Integer.parseInt(result.get("id").toString()));
return customerAutoReply;
}
// 创建搜索对象
private SearchRequest createSearchRequest(SearchParamReq searchParamReq) {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 创建搜索条件
// 1、构建项搜索,指定未被删除的数据
boolQueryBuilder.must(QueryBuilders.termQuery("is_deleted", searchParamReq.getIsDeleted()));
// 2、执行多字段搜索
String keyword = searchParamReq.getKeyWord();
if(StringUtils.hasText(keyword)) {
boolQueryBuilder.must(QueryBuilders.multiMatchQuery(keyword, "word", "content")
.field("word", 1f)
.field("content", 0.25f)
.type(MultiMatchQueryBuilder.Type.MOST_FIELDS)
.operator(Operator.AND));
}
sourceBuilder.query(boolQueryBuilder);
// 3、添加分页
sourceBuilder.from((searchParamReq.getPageNum()-1) * searchParamReq.getPageSize());
sourceBuilder.size(searchParamReq.getPageSize());
// 构建一级对象
SearchRequest searchRequest = new SearchRequest(new String[] {esIndexProperties.getCustomerAutoReplyIndex()}, sourceBuilder);
log.info("搜索条件searchRequest:{}", searchRequest.toString());
return searchRequest;
}
}
五、定制化搜索场景设计和实现
(一)Elastic Search评分机制
1、相关性原理简介
评分和排序都用到了相关性原理,所谓相关性原理是指文档与查询的匹配程度。
搜索本质是计算文档与查询的匹配程度,匹配的依据是评分,即实用评分函数,而评分的结果决定最终排序。
ES实用评分函数如下所示(是ES的实用评分函数,而不是通用的实用评分函数),其中比较重要的是 tf(词频)和 idf(逆向文档频率),其在自然语言处理中是非常重要的算法,用来计算文本之间的相似度。其原理是一个词在一个文档中出现的频率和所有文档包含这个词所出现的频率,然后两个文档的 tf 和 idf 比较就能体现出相关度。

2、TF-IDF:
TF指Term Frequence,代表分词频率,而IDF指Inverse Document Frequency,代表逆文档频率。
索引中一个分词出现的次数越多,代表越重要,ES使用TF进行统计。
另一方面,某个索引中包含某个分词的文档数量越少,这个分词越重要,通俗的讲,就是物以稀为贵,ES使用IDF进行统计。
一个词的词频(TF)与逆文档频率(IDF)的乘积越高,说明这个词与这些文档的关联度越高。
具体的计算公式:
TF-IDF = TF * IDF
TF = 某个分词在文章中出现的次数 / 此文档出现次数最多的词的出现次数
IDF= Log( 文档总数/(包含该词的文档数 + 1) )
示例:考虑一个包含100个单词的文档,其中“天”这个分词出现了10次,那么TF = (10 / 100) = 0.1,并且假设索引中有1000W份文档数量,其中有1000份文档中出现了“天”这个分词,此时逆文档频率(IDF)计算为 IDF = log(10,000,000 /1,000) = 4,最终,TD-IDF计算为 TF * IDF = 0.1 * 4 = 0.4
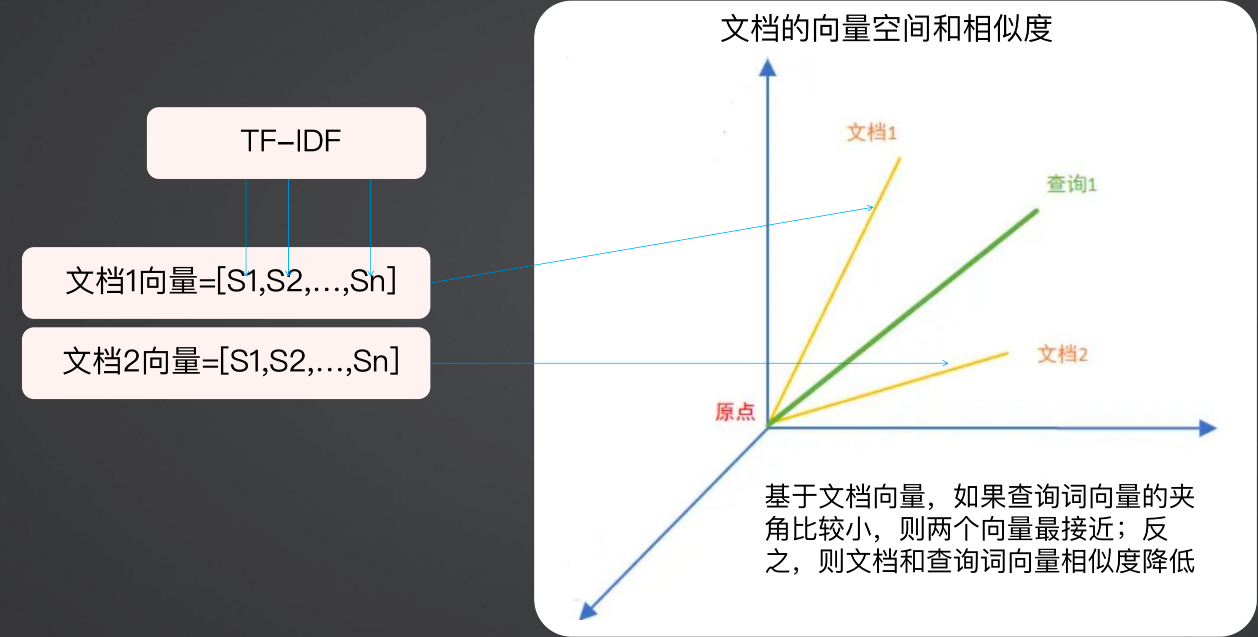
3、向量空间模型:
有了 TD-IDF 之后,就可以做很多事情,例如将每一个词都算一遍 TF-IDF,算出来之后是一个向量,这样每个文档都是一个向量,在对比两个文档相似度时,就可以使用向量空间来做计算。
基于文档向量,如果查询词向量的夹度(脚)比较小,则两个向量最接近,则返回该文档。
3、控制评分
对于做算法的人来说,对于向量空间模型肯定不陌生,但是对于做业务系统的人来说,可能没听过向量空间模型,ES充分考虑了这个问题,因此其提供了三大类评分控制方式:权重(boosting)、自定义评分(function_score)、查询后二次评(rescore_query)
(1)权重
Boost的含义,当boost > 1时,打分的相关度相对性提升,当0 < boost <1时,打分的权重相对性降低,当boost <0时,贡献负分。
在权重的配置中,可以通过设置positive来设置匹配结果,通过negative来降低文档的score,即如果匹配上positive并且也匹配上了 negative,那么降低这样的文档score,降低的方法是使用negative_boost控制降低score的系数。
{
"query":{
"boosting":{
## 匹配上positive的内容会放到结果集中
"positive":{
"term":{
"content":{
"value":"elasticsearch"
}
}
},
## 如果匹配上positive并且也匹配上了 negative,那么降低这样的文档score
"negative":{
"term":{
"content":{
"value":"solr"
}
}
},
## 控制降低score的系数
"negative_boost":0.2
}
}
}
(2)自定义评分
在ES中有多种自定义评分方式:
script_score:script脚本评分,灵活度最高
weight:字段权重评分
random_score:随机评分
field_value_factor:字段值因子评分
decay_functions:gauss/linear/exp等衰减函数
这里主要演示script_score(脚本评分),在脚本评分中,使用的Painless脚本。
Painless脚本的应用场景包括:字段再加工/统计输出、字段之间逻辑运算、定义特殊过滤条件、定义最终评分的计算公式、对字段个性化增删改操作
在使用Painless脚本时,首先要在kibana中构建一个Painless脚本,设置其语言、来源、参数等内容。
我们可以先使用这种方式进行验证,验证成功后再去写业务代码,而不是写完业务代码后去验证,错误了还要返工。
"script": {
"lang": "...",
"source" | "id": "...",
"params": { ... }
}
"script": {
"source": "ctx._source.price=params.price",
"params": {
"price": 334
}
}
"script": {
"source": "ctx._source.price=Math.pow(ctx._source.price, 2)"
}
Painless脚本的基本语法使用了ScriptSortBuilder,ScriptSortBuilder中内置了Script对象定义具体脚本、ScriptSortType枚举 STRING/NUMBER(排序的数据类型)、SortOrder枚举 ASC/DESC(升序或降序)。
下面是使用Painless脚本的代码样例:
// 最终评分
Script pinnedScript = new Script("'" + keyWord + "'==doc['name.keyword'].value ? 0:1")
ScriptSortBuilder pinnedSort = new ScriptSortBuilder(pinnedScript, ScriptSortBuilder.ScriptSortType.NUMBER).order(SortOrder.ASC);
(二)基于Elastic Search实现置顶搜索
1、置顶搜索需求
对于置顶搜索来说,常见的例如招聘网站中急招和直招的场景,电商中的广告,搜索引擎中的广告等等。
对于置顶搜的索场的业务场景来说,需要对对特定编号(如客服编号等)或特定标签(招聘网站中的直招、急招)的业务数据进行置顶。
除了置顶本身的诉求外,可能存在以下诉求点:
可配置:可以动态的修改置顶内容
可扩展:可以根据不同的业务需求来做置顶
可控制有效期:可以控制置顶的有效期
2、置顶搜索流程
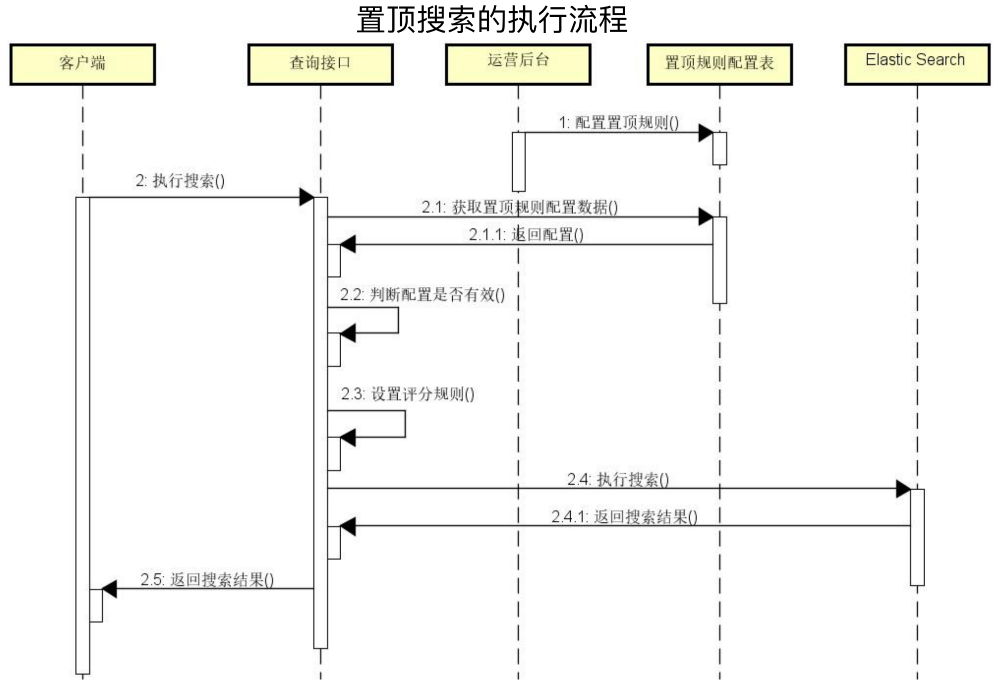
置顶搜索的时序图如下所示:
(1)运营后台配置置顶规则
(2)客户执行搜索,在搜索系统中,首先要查询置顶规则,然后判断是否有效,如果有效,设置置顶规则,最后查询ES并返回查询结果。
3、置顶搜索配置表
可配置:使用配置表,来解决可配置需求
可扩展:
在配置表中,使用platform、business_type来增加可扩展性,即针对不同的平台和不同的业务(可以是租户)来做不同的场景的置顶配置;
同时使用subject_word(主题词)来做匹配处理,例如搜索“蛋糕”,"蛋糕"这个词要在数据库中存在才能生效置顶,而不能搜索“蛋糕”置顶一个“物流“的结果,这显然是不合理的。
使用content_ids(内容ID)对内容进行抽象,例如客服编号,物流编号等,统称为内容 ID,其是一个数组,这样可以存储多个 id,因为在实际场景来说,可以置顶多个内容。
可控制有效期:指定该配置项的生效开始、结束时间、状态
CREATE TABLE `pinned_query_config` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`platform` VARCHAR ( 50 ) NOT NULL COMMENT '应用平台,1:APP 2:PC 3:小程序',
`business_type` TINYINT NOT NULL COMMENT '业务类型,1:客服管理 2:其他业务',
`subject_word` VARCHAR ( 100 ) NOT NULL COMMENT '主题词',
`start_time` datetime NOT NULL COMMENT '开始时间',
`end_time` datetime NOT NULL COMMENT '结束时间',
`content_ids` VARCHAR ( 100 ) NOT NULL COMMENT '内容ID',
`status` TINYINT NOT NULL DEFAULT '1' COMMENT '状态:1:待上线 2:使用中 3:已下线',
PRIMARY KEY ( `id` )
) ENGINE = INNODB COMMENT = '置顶搜索配置表'
4、开发置顶搜索评分脚本
如下代码表示根据客服人员编号进行动态匹配,逻辑是从配置表中先获取到需要置顶的内容id,这里是客服id,值为100,101,102,然后编写Painless脚本,脚本逻辑:从文档中获取staffId,如果staffId在staffList中存在,则返回0,不存在返回1,这个0和1直接影响了评分结果。
String staffString = "100,101,102";
Script staffPinnedScript = new Script(
"List staffList = " + staffString + ";"
+ "Long staffId = doc['staff_id'].value;"
+ "if(staffList.contains(staffId)) { return 0; }"
+ "else {return 1;}"
);
5、集成置顶搜索排序
//1. 从数据库中获取置顶搜索配置项
PinnedQueryConfig pinnedQueryConfig = ...;
//2. 根据配置项内容构建搜索脚本
Script staffPinnedScript = new Script(...);
//3. 创建ScriptSortBuilder
ScriptSortBuilder moviePinnedSort = new ScriptSortBuilder(staffPinnedScript, ScriptSortBuilder.ScriptSortType.NUMBER).order(SortOrder.ASC);
//4. 整合到SearchSourceBuilder(嵌入评分排序机制)
sourceBuilder.sort(staffPinnedSort);
(三)客服系统案例演进
客服系统置顶搜索场景:
用户输入关键词,如”物流” ,从数据库获取关键词对应的置顶自动回复Id配置,从 Elastic Search 获取数据,并根据配置信息定制化评分和排序,从而实现置顶目标自动回复内容。
1、填充置顶配置
在构建搜索对象前,先填充置顶配置,其实就是设置请求参数searchParamReq中的置顶搜索内容ids
// 从数据库获取置顶配置
PinnedQueryConfig pinnedQueryConfig = pinnedQueryConfigService.findActivePinnedQueryConfigBySubjectWord(searchParamReq.getKeyWord(), 1);
try {
if(pinnedQueryConfig != null){
searchParamReq.setPinnedContentIds(Arrays.asList(pinnedQueryConfig.getContentIds()));
}
} catch (Exception e){
searchParamReq.setPinnedContentIds(null);
}
2、添加置顶搜索支持
在创建搜索对象时,添加置顶搜索支持。
主要逻辑就是构建一个ScriptSortBuilder,然后在SearchSourceBuilder中使用ScriptSortBuilder排序,而构建ScriptSortBuilder对象就是前面提到的Painless脚本的处理逻辑。
private SearchRequest createSearchRequest(SearchParamReq searchParamReq) {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 创建搜索条件
// 1、构建项搜索,指定未被删除的数据
boolQueryBuilder.must(QueryBuilders.termQuery("is_deleted", searchParamReq.getIsDeleted()));
// 2、执行多字段搜索
String keyword = searchParamReq.getKeyWord();
if(StringUtils.hasText(keyword)) {
boolQueryBuilder.must(QueryBuilders.multiMatchQuery(keyword, "word", "content")
.field("word", 1f)
.field("content", 0.25f)
.type(MultiMatchQueryBuilder.Type.MOST_FIELDS)
.operator(Operator.AND));
}
sourceBuilder.query(boolQueryBuilder);
// 添加置顶搜索支持
createPinnedQuery(searchParamReq, sourceBuilder);
// 3、添加分页
sourceBuilder.from((searchParamReq.getPageNum()-1) * searchParamReq.getPageSize());
sourceBuilder.size(searchParamReq.getPageSize());
// 构建一级对象
SearchRequest searchRequest = new SearchRequest(new String[] {esIndexProperties.getCustomerAutoReplyIndex()}, sourceBuilder);
log.info("搜索条件sourceBuilder:{}", sourceBuilder.toString());
log.info("搜索条件searchRequest:{}", searchRequest.toString());
return searchRequest;
}
private void createPinnedQuery(SearchParamReq searchParamReq, SearchSourceBuilder sourceBuilder) {
List<String> customerAutoReplyIds = searchParamReq.getPinnedContentIds();
if(customerAutoReplyIds != null){
String customerAutoReplyString = buildQueryString(customerAutoReplyIds);
Script script = new Script(
"List customerAutoReplyList = " + customerAutoReplyString +";"
+ "Long customerAutoReplyId = doc['id'].value;"
+ "if(customerAutoReplyList.contains(customerAutoReplyId)) { return 0; }"
+ "else {return 1;}"
);
ScriptSortBuilder scriptSortBuilder = new ScriptSortBuilder(script, ScriptSortBuilder.ScriptSortType.NUMBER).order(SortOrder.ASC);
sourceBuilder.sort(scriptSortBuilder);
}
}
private String buildQueryString(List<String> customerAutoReplyIds) {
List<String> targetIds = new ArrayList<>();
for (String id : customerAutoReplyIds) {
String formatId = id + "L";//需要添加L后缀表明是Long类型
targetIds.add(formatId);
}
String[] customerAutoReplyList = targetIds.toArray(new String[0]);
return Arrays.toString(customerAutoReplyList);
}
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号