
06-分布式数据库
一、引入ShardingSphere
(一)分库分表理论和解决方案
1、对于 IM 聊天记录的存储的选型:
关系型数据库仍然是业务数据基石,因为关系型数据存有稳定性、可靠性和事务性的优势
但是如果用关系型数据库,就会存在单表容量问题:如MySQL单表千万级
为了解决单表瓶颈问题,就需要采用分库分表的方案来解决
2、分库分表首先是可以分为分库和分表,无论是分库还是分表,都可以分为垂直分库分表和水平分库分表:
垂直分库分表是根据业务拆分,垂直分库例如用户库、商品库、订单库,垂直分表例如用户信息表、用户头像表。
水平分库分表是根据业务主键进行分库分表,例如使用订单id将不同的订单拆分到不同的库表。
3、分库分表算法可分为:
取模算法:按照特定字段进行Hash求值和取模
范围限定算法:按年份、按时间等策略路由到目标数据库或表
预定义算法:直接路由到事先规划好的指定库或表中
4、分库分表与读写分离:
分库分表通常和读写分离配合实施,从数据库同步主数据库数据,然后读直接走从库,写走主库。
5、分库分表的挑战:
如何对多数据库进行高效治理
如何实现跨节点的分页和排序操作
如何生成全局唯一的主键
如何进行跨节点关联查询
如何确保事务一致性
6、分库分表解决方案:
分库分表背后的抽象概念就是分片(Sharding),即无论是分库还是分表,都是把数据划分成不同的数据片,并存储在不同的目标对象中,而具体的分片方式就涉及到实现分库分表的不同解决方案。解决方案可以是客户端分片,也可以是服务端分片。
客户端分片解决方案组成结构是应用程序写分片规则和分片逻辑,然后访问具体的数据库表,代表性框架:TDDL和ShardingSphere
服务器分片是使用代理服务器分片,客户端像访问数据库一样访问代理服务器,在代理服务器上配置分片规则和分片逻辑,代表性框架:Cobar、Mycat和ShardingSphere
(二)ShardingSphere简介
ShardingSphere设计理念不是颠覆,而是兼容,ShardingSphere包括ShardingSphere-JDBC和ShardingSphere-Proxy ,ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务,ShardingSphere-Proxy 定位为透明化的数据库代理,通过实现数据库二进制协议,对异构语言提供支持。
1、Sharding-JDBC
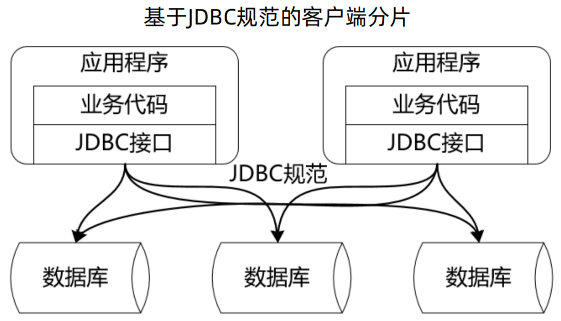
Sharding-JDBC 是基于JDBC规范的客户端分片,应用程序也是通过 JDBC 接口访问的数据库。
可以理解为所有的操作都是围绕 JDBC 规范来展开的,如下图所示,应用程序的业务代码都是通过 JDBC 接口访问的数据库,所以说Sharding-JDBC 是基于JDBC规范的客户端分片。
2、Sharding-JDBC - 兼容性支持:
兼容ORM框架:JPA、Hibernate、MyBatis等
兼容数据库连接池:DBCP、C3P0、BoneCP、Druid、HikariCP等
兼容数据库:MySQL、Oracle、SQLServer、PostgreSQL等
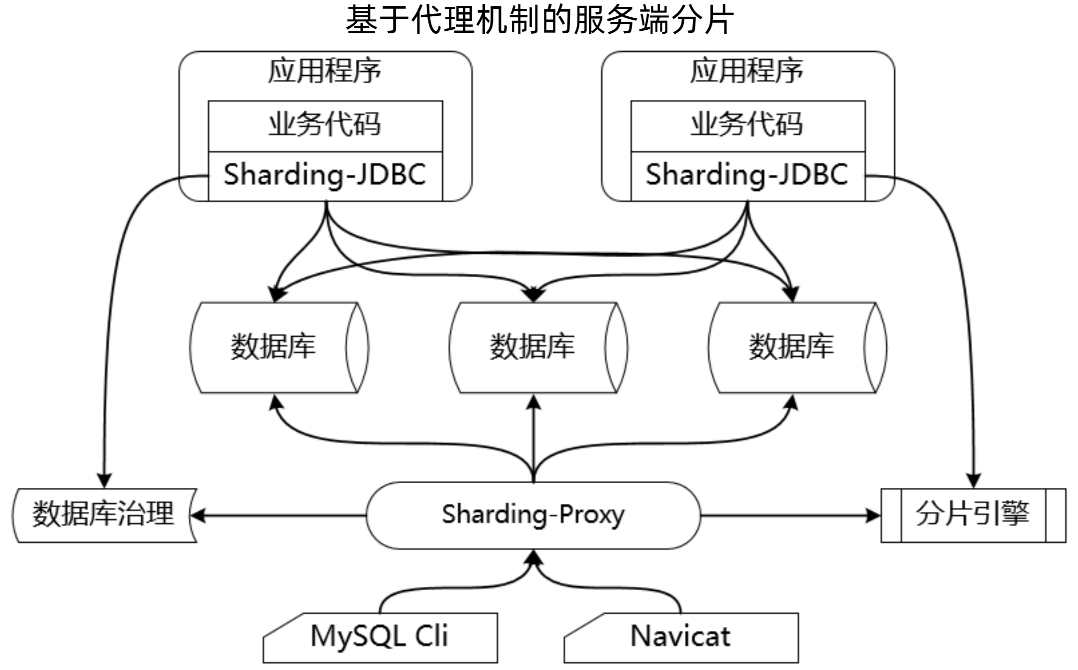
3、Sharding-Proxy:
Sharding-Proxy是一个独立部署的服务器,内部基于Sharding-JDBC 可以做数据库治理和分片引擎,外部客户端通过Sharding-Proxy服务器访问数据库。
4、Sharding-Proxy - 兼容性支:
兼容异构语言:封装了数据库二进制协议的服务端版本
兼容数据库:MySQL和PostgreSQL
兼容数据库客户端:MySQL命令行客户端、MySQL Workbench、Navicat等
5、ShardingSphere核心功能:
数据分片 :基于底层数据库提供分库分表解决方案,可以水平扩展计算和存储
分布式事务:基于 XA 和 BASE 的混合事务引擎,提供在独立数据库上的分布式事务功能,ShardingSphere背后也是Seata框架来做的分布式事务
读写分离:提供灵活的读写流量拆分和读流量负载均衡
数据迁移:提供跨数据源的数据迁移能力,并可支持重分片扩展
联邦查询:提供跨数据源的复杂查询分析能力,实现跨源的数据关联与聚合
数据加密:提供完整、透明、安全、低成本的数据加密解决方案
影子库:支持不同工作负载下的数据隔离,避免测试数据污染生产环境
(三)JDBC规范与ShardingSphere原理分析
1、JDBC API的执行流程
创建DataSource、获取Connection、创建Statement、执行SQL语句、处理ResultSet、关闭资源对象。
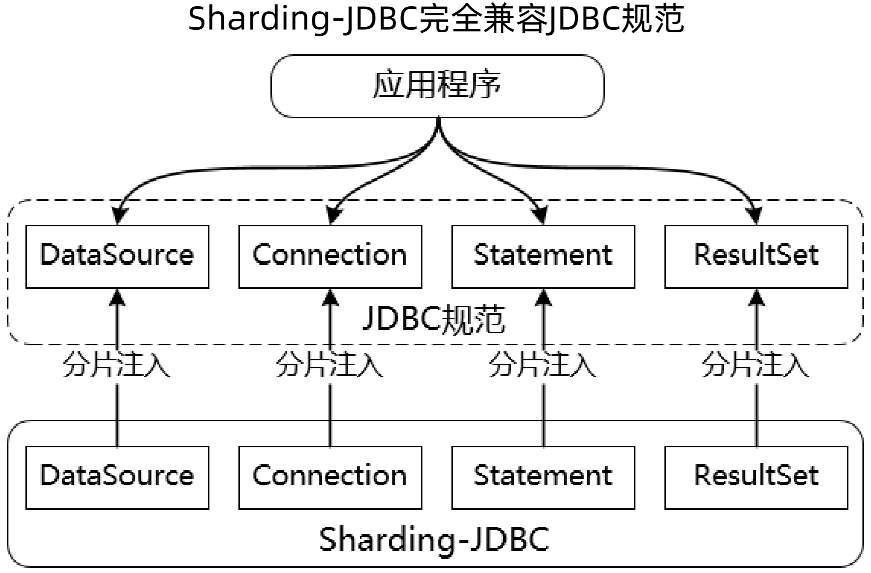
2、ShardingSphere兼容JDBC规范
应用程序访问的还是 JDBC 规范的接口,Sharding-JDBC 把这些对象都做了封装,在每个对象里都嵌入了分片引擎,那么最终访问的是Sharding-JDBC的API。
3、DataSource
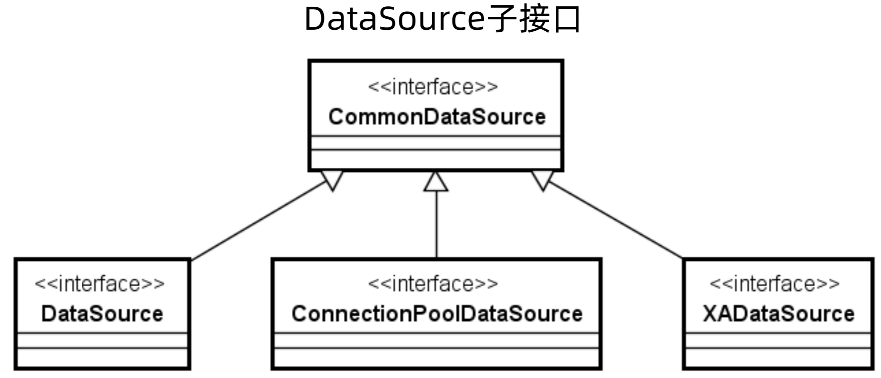
Sharding-JDBC 是如何做到能够兼容 JDBC 规范的,这就需要从 JDBC 的核心 API 进行切入,那么第一个核心对象就是 DataSource。
DataSource继承了 CommonDataSource 和 Wrapper 两个接口,其中 CommonDataSource 就是通用的DataSource,而 Wrapper 是包装器组件。
CommonDataSource有很多的子接口,例如DataSource,用来支持数据源,ConnectionPoolDataSource用来支持数据库连接池,XADataSource用来支持分布式事务。
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String username, String password) throws SQLException;
}
4、Wrapper接口:
Wrapper接口可以把一个由第三方供应商提供的、非JDBC标准的接口包装成标准接口。
以DataSource接口为例,如果想要实现自己的数据源MyDataSource,就可以提供一个实现了Wrapper接口的MyDataSourceWrapper类来完成包装和适配。
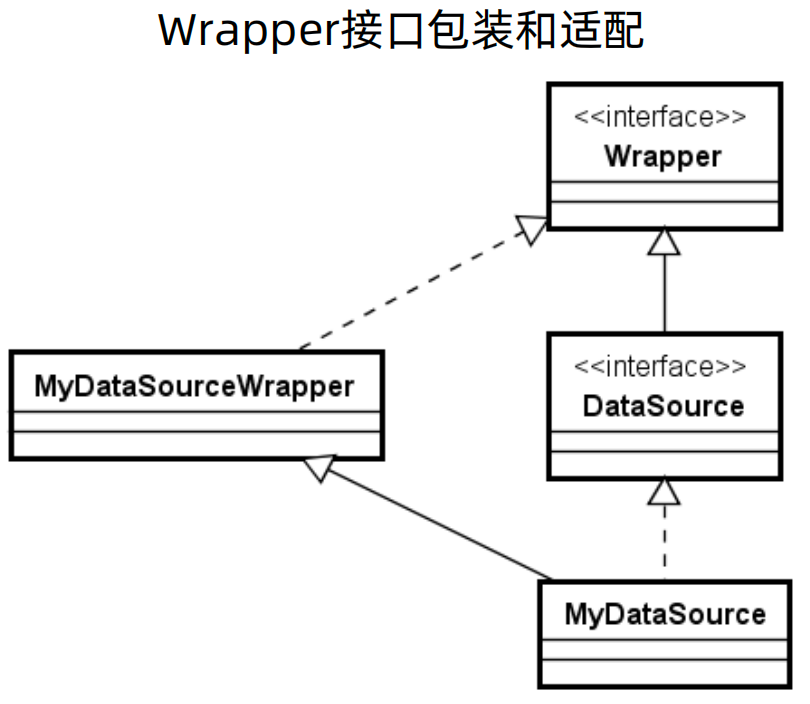
在JDBC规范中,除了DataSource之外,Connection、Statement、ResultSet等核心对象也都继承了这个接口。显然,ShardingSphere提供的就是非JDBC标准的接口,所以也应该会用到这个Wrapper接口,并提供了类似的实现方案。
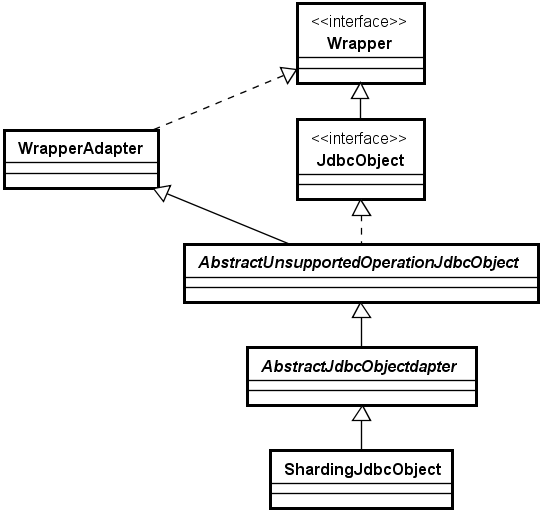
5、基于适配器模式的JDBC重写实现方案
适配器模式:适配器模式通常被用作是连接两个不兼容接口之间的桥梁,涉及到为某一个接口加入独立的或不兼容的功能。
如下图所示,就是基于适配器模式的JDBC重写实现方案
WrapperAdapter:首先定义一个包装器的适配类,实现Wrapper接口
JdbcObject:做了一层抽象,泛指JDBC API中DataSource等对象,如DataSource、Connection、Statement、ResultSet等,由于实现套路一样,因此下图做了一层抽象。
AbstractUnsupportOperationJdbcObject:然后通过 AbstractUnsupportOperationJdbcObject 继承 WrapperAdapter 并实现 JdbcObject 接口,在该抽象类中,不做扩展的直接处理,做扩展的提供抽象方法。
AbstractJdbcObjectAdapter:也是一层抽象,是针对DataSource、Connection、Statement、ResultSet等的具体抽象类
ShardingJdbcObject:泛指ShardingSphere中用于分片的ShardingDataSource等对象,在扩展方法中实现类分片相关的操作。
这个重写机制非常重要,在ShardingSphere中应用广泛
二、利用ShardingSphere实现分库分表
(一)ShardingSphere集成方式
1、抽象开源框架的应用方式
底层工具:拿到一个开原框架,第一要做就是确认框架的底层工具是什么,例如Dubbo,底层框架就是Netty,而ShardingSphere底层工具就是关系型数据库
基础规范:ShardingSphere的基础规范是 JDBC规范,对于Dubbo 而言,RPC架构是其基础规范
领域框架:像mabatis、Hebernate,JPA都是领域框架,而ShardingSphere则是对领域框架又做了一次封装,其定位不是领域框架,而是一种领域框架的集合,其依赖底层的 ORM 框架来完成处理。
开发框架:Spring家族框架,ShardingSphere集成了Spring。
2、数据库和JDBC集成
要配置数据库连接池和 JDBC 驱动,配置代码如下所示,这只是一个最简单的配置,使用 ShardingSphere 肯定有很多关于分库分表的配置,而这里主要先说明其与数据库和 JDBC 的集成。
## 数据库连接池
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
## JDBC驱动
spring.datasource.driverClassName = com.mysql.jdbc.Driver
spring.datasource.url = jdbc:mysql://127.0.0.1:3306/ds_traditional?
serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.datasource.username = root
spring.datasource.password = root
3、开发框架和领域框架集成:
可以使用 Java原生、Spring、Spring Boot、Spring Data JPA、MyBatis和MyBatis-Plus 等方式集成。
如下代码所示,和之前的代码没有任何区别。
@SpringBootApplication
@ComponentScan("org.geekbang.projects.c")
@MapperScan(basePackages = "org.geekbang.projects.c.mapper")
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
(二)ShardingSphere配置体系
1、行表达式
行表达式是ShardingSphere的一种配置语法支持,表现为${expression}或$->{expression}。
基于行表达式语法,${begin..end}表示的是一个从"begin"到"end"的范围区间,而多个${expression}之间可以用"."符号进行连接,代表多个表达式数值之间的一种笛卡尔积关系。行表达式也提供了${[enum1, enum1,…, enumx]}语法来表示枚举值。
例如现在有ds0和ds1两个数据库,每个数据库里面都有user1和user2两张表,那么配置的话,就需要有4中配置,而使用行行表达式就可以写成 ds${0..1}.user${0..1}
2、ShardingSphere核心配置
ShardingSphere的配置是一个树,有根节点,根节点下又有子节点
(1)配置根对象:ShardingRuleConfiguration(分片配置)
tables:分片规则配置集合,结构是Collection<ShardingTableRuleConfiguration>,即ShardingTableRuleConfiguration配置的集合
bindingTableGroups:绑定表配置,结构是Collection<String>,即String的集合
broadcastTables:广播表配置,结构是Collection<String>,即String的集合
defaultDatabaseShardingStrategy:默认分库策略,数据结构是 ShardingStrategyConfiguration
defaultTableShardingStrategy:默认分表策略,数据结构是 ShardingStrategyConfiguration
defaultKeyGenerateStrategy:默认键生成策略,数据结构是 KeyGenerateStrategyConfiguration
defaultShardingColumn:默认分片键列名,数据结构是 String
shardingAlgorithms:分片算法,数据结构是 Map<String, ShardingSphereAlgorithmConfiguration>
keyGenerators:键生成器,数据结构是 Map<String, KeyGenerateStrategyConfiguration>
(2)分片表规则:ShardingTableRuleConfiguration
actualDataNodes:物理库表接口,数据结构是 String
databaseShardingStrategy:分库策略,数据结构是 ShardingStrategyConfiguration,不设置就走默认,设置了就会把默认的覆盖掉
tableShardingStrategy:分表策略,数据结构是 ShardingStrategyConfiguration,不设置就走默认,设置了就会把默认的覆盖掉
keyGenerateStrategy:键生成策略,数据结构是 KeyGenerateStrategyConfiguration
(3)分库分表策略:ShardingStrategyConfiguration
NoneShardingStrategyConfiguration:不分片
HintShardingStrategyConfiguration:强制路由分片
ComplexShardingStrategyConfiguration:多分片键复杂分片
StandardShardingStrategyConfiguration:标准分片,包括shardingColumn和shardingAlgorithmName
shardingColumn:分片键列名,数据结构是 String
shardingAlgorithmName:分片算法名,数据结构是 String
(4)其他配置:
键生成策略:KeyGenerateStrategyConfiguration
column:主键列名,数据结构是 String
keyGeneratorName:键生成器名称,数据结构是 String
分片算法:ShardingSphereAlgorithmConfiguration
type:分片算法类型,如INLINE,数据结构是 String
props:分片算法属性,如算法表达式等,数据结构是 Properties
3、ShardingSphere配置方式
Java代码配置、Spring命名空间配置、Properties配置、Yaml配置。
基于ShardingSphere,开发人员实现数据分片的主要工作量来自配置而不是开发。
(三)ShardingSphere数据分片
1、数据分片开发步骤:
初始化数据源
设置分片策略
设置绑定表和广播表
设置分片规则
2、初始化数据源:
第一个配置的区别:配置不再是spring.dataSource,而是spring.shardingsphere.dataSources,即数据源不再是使用Spring自带的数据源,而是使用shardingsphere代理的数据源。shardingsphere在Spring的基础上对dataSources进行了拦截,完成了从普通原生的 JDBC 到 shardingsphere中shardingJdbc的转变。
第二个配置的区别:配置多个数据源
yaml:
spring:
shardingsphere:
dataSources:
dswrite: !!com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dswrite
username: root
password: root
dsread0: !!com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/dsread0
username: root
password: root
properties:
spring.shardingsphere.datasource.dswrite.url=jdbc:mysql://127.0.0.1:3306/dswrite
spring.shardingsphere.datasource.dswrite.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite.username=root
spring.shardingsphere.datasource.dswrite.password=root
spring.shardingsphere.datasource.dsread0.url=jdbc:mysql://127.0.0.1:3306/dsread0
spring.shardingsphere.datasource.dsread0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dsread0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dsread0.username=root
spring.shardingsphere.datasource.dsread0.password=root
3、设置分片策略
首先在spring.shardingsphere.rules.sharding.default-database-strategy配置项中配置默认分片策略
## 分片键,其中standard表示默认分片算法
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=user_id
## 设置分片算法,名称可以自定义,只要算法在算法库就可以
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline
## 设置分片算法,将分片算法放入算法库,此处database-inline将INLINE算法放入了算法库,上面的配置引用的就是该分片算法
## INLINE 是一种内联的算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE
## 分片算法表达式,使用props表示使用propertites设置表达式,这里的表达式要和前面的分片键保持一致
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds$->{user_id % 2}
4、设置绑定表和广播表
绑定表:所谓绑定表(BindingTable),是指分片规则一致的一组主表和子表。引入绑定表概念的根本原因在于,互为绑定表关系的多表关联查询不会出现笛卡尔积,因此关联查询效率将大大提升。请注意,如果想要达到这种效果,互为绑定表的各个表的分片键要完全相同。
广播表:广播表(BroadCastTable)是指所有的分片数据源中都存在的表,也就是这种表的结构和数据在每个数据库中都是完全一样的。广播表的适用场景比较明确,通常针对数据量不大且需要与海量数据表进行关联查询的应用场景,典型的例子就是每个分片数据库中都应该存在的字典表。
绑定表和广播表配置如下所示:
## 设置绑定表
spring.shardingsphere.rules.sharding.binding-tables[0]=health_record, health_task
## 设置广播表
spring.shardingsphere.rules.sharding.broadcast-tables=health_level
绑定表案例应用案例:
现在有health_record和health_task两张表,关联查询如下所示
SELECT record.remark_name FROM health_record record JOIN health_task task ON record.record_id=task.record_id WHERE record.record_id in (1, 2);
如果这两张表都分了两张表,那么在不设置绑定表的时候,关联查询如下所示,需要四次查询
SELECT record.remark_name FROM health_record0 record JOIN health_task0 task ON record.record_id=task.record_id WHERE record.record_id
in (1, 2);
SELECT record.remark_name FROM health_record0 record JOIN health_task1 task ON record.record_id=task.record_id WHERE record.record_id
in (1, 2);
SELECT record.remark_name FROM health_record1 record JOIN health_task0 task ON record.record_id=task.record_id WHERE record.record_id
in (1, 2);
SELECT record.remark_name FROM health_record1 record JOIN health_task1 task ON record.record_id=task.record_id WHERE record.record_id
in (1, 2);
如果设置了绑定表,就可以只做两次查询
SELECT record.remark_name FROM health_record0 record JOIN health_task0 task ON record.record_id=task.record_id WHERE record.record_id
in (1, 2);
SELECT record.remark_name FROM health_record1 record JOIN health_task1 task ON record.record_id=task.record_id WHERE record.record_id
in (1, 2);
5、设置分片规则
分库规则:database级别,使用 spring.shardingsphere.rules.sharding.default-database-strategy
## 设置分库分片键
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=patient_id
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE
## 设置分库分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds$->{patient_id % 2}
分表规则:表级别,使用 spring.shardingsphere.rules.sharding.tables,后面跟的就是具体的表,例如下面代码就是对 t_consultation 表进行分表
spring.shardingsphere.rules.sharding.tables.t_consultation.actual-data-nodes=ds.t_consultation$->{0..2}
## 设置分表分片键
spring.shardingsphere.rules.sharding.tables.t_consultation.table-strategy.standard.sharding-column=consultation_id
## 设置表名
spring.shardingsphere.rules.sharding.tables.t_consultation.table-strategy.standard.sharding-algorithm-name=t_consultation-inline
spring.shardingsphere.rules.sharding.sharding-algorithms.t_consultation-inline.type=INLINE
## 设置分表分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.t_consultation-inline.props.algorithm-expression=t_consultation$->{consultation_id % 3}
分库分表规则:
重点是actual-data-nodes,来设置库表的结合,例如下面actual-data-nodes配置的是ds$->{2..3}.t_consultation$->{0..2},即存在 ds2 和 ds3 两个数据库,每个数据库存在t_consultation0、t_consultation1、t_consultation2三张表。
## 设置分库分片键
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=patient_id
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline
## 设置分表表名和分片键
spring.shardingsphere.rules.sharding.tables.t_consultation.actual-data-nodes=ds$->{2..3}.t_consultation$->{0..2}
spring.shardingsphere.rules.sharding.tables.t_consultation.table-strategy.standard.sharding-column=consultation_id
spring.shardingsphere.rules.sharding.tables.t_consultation.table-strategy.standard.sharding-algorithm-name=t_consultation-inline
## 设置分库分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds$->{patient_id % 2}
## 设置分表分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.t_consultation-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.t_consultation-inline.props.algorithm-expression=t_consultation$->{consultation_id % 3}
(四)客服系统案例演进
1、建表IM消息存储机制回顾
CREATE TABLE `im_message` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`from_user_id` bigint(20) NOT NULL COMMENT '消息发送方用户Id',
`from_username` varchar(45) DEFAULT NULL COMMENT '消息发送方用户名',
`to_user_id` bigint(20) NOT NULL COMMENT '消息接收方用户Id',
`to_username` varchar(45) DEFAULT NULL COMMENT '消息接收方用户名',
`business_type_code` varchar(45) DEFAULT NULL COMMENT '业务类型编码',
`business_type_name` varchar(45) DEFAULT NULL COMMENT '业务类型名称',
`message` varchar(255) NOT NULL COMMENT '聊天消息',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='聊天记录表';
CREATE TABLE `im_business_type` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`business_type_code` varchar(45) DEFAULT NULL COMMENT '业务类型编码',
`business_type_name` varchar(45) DEFAULT NULL COMMENT '业务类型名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='业务类型表';
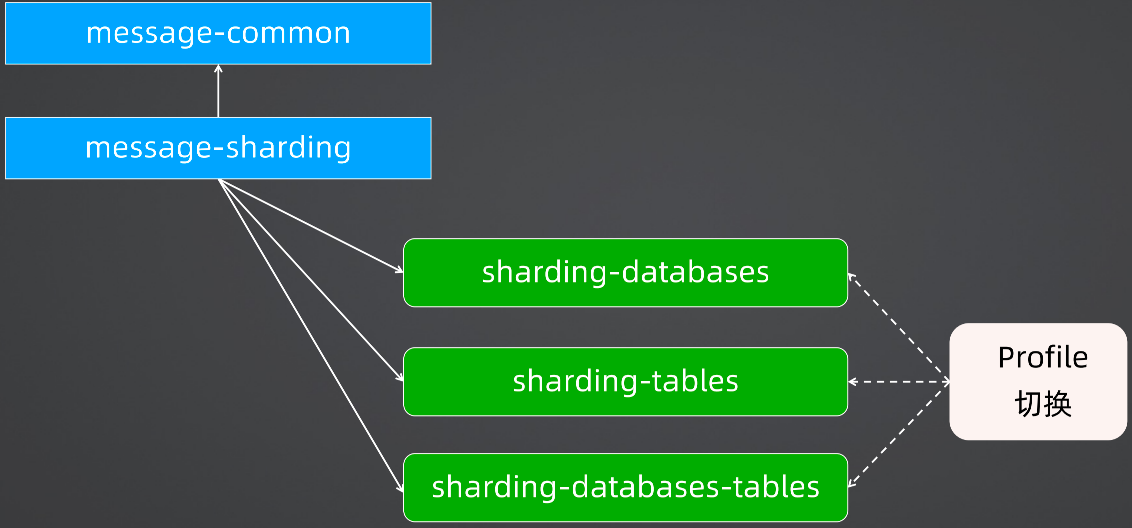
2、项目改造梳理
在分库分表的代码中,会创建一组工程。
首先是一个message-common工程,这个工程包含所有的MVC以及数据的增删改查操作。因为对于分库分表项目来说,都是对于配置项的改变,对于业务层和数据访问层的代码是没有任何侵入性的,那么对于业务代码都写在common项目中,其余想做的分片、路由等操作,都放在一个单独的项目中来做配置项的变更即可。
根据上述的拆分,那么就可以有一个sharding-databases配置来做分库,使用sharding-tables配置来做分表,使用sharding-databases-tables配置来做分库分表,然后基于Profile做到相互切换。
3、message-common
(1)实体对象
@ToString
@Data
public class ImBusinessType implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private String businessTypeCode;
private String businessTypeName;
}
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
public class ImMessage implements Serializable {
private static final long serialVersionUID = 1L;
private Long id;
private Long fromUserId;
private String fromUsername;
private Long toUserId;
private String toUsername;
private String businessTypeCode;
private String businessTypeName;
private String message;
private LocalDateTime createTime;
}
(2)Service
@Service
public class ImMessageServiceImpl implements ImMessageService {
@Autowired
private ImMessageMapper imMessageMapper;
@Autowired
private ImBusinessTypeMapper imBusinessTypeMapper;
@Override
public void saveImMessage(ImMessage imMessage) throws SQLException {
imMessageMapper.addImMessage(imMessage);
}
@Override
public List<ImMessage> findImMessages() throws SQLException {
List<ImMessage> messages = imMessageMapper.findImMessages();
return fillImMessagesWithBusinessType(messages);
}
@Override
public List<ImMessage> findImMessagesByUserId(Long toUserId) throws SQLException {
List<ImMessage> messages = imMessageMapper.findImMessagesByUser(toUserId);
return fillImMessagesWithBusinessType(messages);
}
private List<ImMessage> fillImMessagesWithBusinessType(List<ImMessage> messages) {
for (ImMessage message : messages) {
ImBusinessType businessType = imBusinessTypeMapper.findBusinessTypeByCode(message.getBusinessTypeCode());
message.setBusinessTypeName(businessType.getBusinessTypeName());
}
return messages;
}
}
(3)Controller
@RestController
@RequestMapping("/messages")
public class ImMessageController {
@Autowired
private ImMessageService imMessageService;
@PostMapping("/")
public Long saveImMessage(@RequestBody ImMessageDTO imMessageDTO) throws SQLException {
ImMessage imMessage = ImMessageConverter.INSTANCE.convert(imMessageDTO);
imMessageService.saveImMessage(imMessage);
return imMessage.getId();
}
@GetMapping()
public List<ImMessageDTO> findImMessages() throws SQLException {
List<ImMessage> imMessages = imMessageService.findImMessages();
return ImMessageConverter.INSTANCE.convertDTOs(imMessages);
}
@GetMapping("/{userId}")
public List<ImMessageDTO> findImMessagesByUserId(@PathVariable("userId") Long userId) throws SQLException {
List<ImMessage> imMessages = imMessageService.findImMessagesByUserId(userId);
return ImMessageConverter.INSTANCE.convertDTOs(imMessages);
}
}
(4)common项目的特殊设置
common项目没有主启动了,因为其不是一个项目,只是一个公共库。
4、message-traditional
该模块是一个传统意义上的项目实现,没有分库分表相关的操作,主要是为了演示使用项目集成 message-common 的可行性。
(1)主配置文件
mybatis.config-location=classpath:mybatis-config.xml
server.port=11001
spring.application.name=message-traditional-service
spring.profiles.active=traditional
(2)profile配置文件
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driverClassName = com.mysql.jdbc.Driver
spring.datasource.url = jdbc:mysql://192.168.249.130:3306/message?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.datasource.username = root
spring.datasource.password = root
(3)mybatis配置文件:
这里扫描的应该是 message-common 包中的文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<mappers>
<mapper resource="mappers/ImMessageMapper.xml"/>
<mapper resource="mappers/ImBusinessTypeMapper.xml"/>
</mappers>
</configuration>
(4)启动类
这里@MapperScan扫描的应该是 message-common 包中的文件,另外启动类扫描注解应该包含当前项目和 message-common 项目。
@SpringBootApplication(scanBasePackages = "com.lcl.galaxy.message.service")
@MapperScan(basePackages = "com.lcl.galaxy.message.service.common.mapper")
public class MessageTraditionalApplication {
public static void main(String[] args) {
SpringApplication.run(MessageTraditionalApplication.class, args);
}
}
(5)验证
访问controller,成功,此种引用方法可行。
5、分库
(1)搭建单独的分库分表案例模块message-sharding
内容和 message-traditional 基本上一致
(2)引入shardingsphere
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
</dependency>
(3)分库配置:application-sharding-databases.properties
这里要注意,如果单独分表,在algorithm-expression中就不需要配置库的信息
# 配置数据库名称
spring.shardingsphere.datasource.names=ds
# 数据库配置
spring.shardingsphere.datasource.ds.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds.url=jdbc:mysql://192.168.249.130:3306/ds?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds.username=root
spring.shardingsphere.datasource.ds.password=root
# 库表物理信息
# 逻辑表im_message表对应的物理库表地址
spring.shardingsphere.rules.sharding.tables.im_message.actual-data-nodes=ds.im_message_$->{0..2}
# 分片键
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-column=to_user_id
# 分片算法
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-algorithm-name=im_message-online
# 物理表主键id
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.column=id
# 物理表主键生成策略
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.key-generator-name=snowflake
# im_message-online 算法配置
# 类型配置
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.type=INLINE
# 算法的具体逻辑
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.props.algorithm-expression=im_message_$->{to_user_id % 3}
# snowflake策略配置,在shardingsphere中,小写表示是自定义的属性,大写是shardingsphere中自带的枚举类型
spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE
# 显示 sql
spring.shardingsphere.props.sql-show=true
(4)主配置文件引入profile配置文件
mybatis.config-location=classpath:mybatis-config.xml
server.port=11002
spring.application.name=message-sharding-service
spring.profiles.active=sharding-databases
6、分表
# 配置数据库名称
spring.shardingsphere.datasource.names=ds
# 数据库配置
spring.shardingsphere.datasource.ds.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds.url=jdbc:mysql://192.168.249.130:3306/ds?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds.username=root
spring.shardingsphere.datasource.ds.password=root
# 库表物理信息
# 逻辑表im_message表对应的物理库表地址
spring.shardingsphere.rules.sharding.tables.im_message.actual-data-nodes=ds.im_message_$->{0..2}
# 分片键
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-column=to_user_id
# 分片算法
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-algorithm-name=im_message-online
# 物理表主键id
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.column=id
# 物理表主键生成策略
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.key-generator-name=snowflake
# im_message-online 算法配置
# 类型配置
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.type=INLINE
# 算法的具体逻辑
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.props.algorithm-expression=im_message_$->{to_user_id % 3}
# snowflake策略配置,在shardingsphere中,小写表示是自定义的属性,大写是shardingsphere中自带的枚举类型
spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE
# 显示 sql
spring.shardingsphere.props.sql-show=true
7、分库分表
# 配置数据库名称
spring.shardingsphere.datasource.names=ds2,ds3
# 数据库配置
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://192.168.249.130:3306/ds2?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=root
spring.shardingsphere.datasource.ds3.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds3.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds3.url=jdbc:mysql://192.168.249.130:3306/ds3?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds3.username=root
spring.shardingsphere.datasource.ds3.password=root
# 库表物理信息
# 逻辑表im_message表对应的物理库表地址
spring.shardingsphere.rules.sharding.tables.im_message.actual-data-nodes=ds$->{2..3}.im_message_$->{0..2}
# 物理表主键id
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.column=id
# 物理表主键生成策略
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.key-generator-name=snowflake
# 广播表
spring.shardingsphere.rules.sharding.broadcast-tables=im_business_type
# 分库配置
# 分片键
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=from_user_id
# 分片算法
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline
# 分表配置
# 分片键
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-column=to_user_id
# 分片算法
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-algorithm-name=im_message-online
# database-inline 算法配置
# 分库逻辑
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds$->{from_user_id % 2 + 2}
# 分表逻辑
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.props.algorithm-expression=im_message_$->{to_user_id % 3}
# snowflake策略配置,在shardingsphere中,小写表示是自定义的属性,大写是shardingsphere中自带的枚举类型
spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE
# 显示 sql
spring.shardingsphere.props.sql-show=true
三、利用ShardingSphere实现强制路由和读写分离
(一)ShardingSphere和强制路由
1、强制路由
强制路由与一般的分库分表路由的不同之处在于,它并没有使用任何的分片键和分片策略。
通过解析SQL语句提取分片键并设置分片策略进行分片是ShardingSphere对重写JDBC规范的实现方式。但是如果我们没有分片键,是不是就只能进行访问所有的数据库和数据表进行全路由呢?显然,这种处理方式也不大合适。
这时候需要为SQL执行开一个“后门”,允许在没有分片键的情况下同样可以在外部设置目标数据库和表,这就是强制路由的设计理念。
2、数据库Hint机制
在关系型数据库中,Hint允许用户通过相关的语法影响SQL的执行方式,改变SQL的执行计划,从而实现对SQL进行特殊的优化。
很多数据库工具也提供了特殊的Hint语法。以MySQL为例,比较典型的Hint使用方式之一就是对索引的强制和忽略机制。
SELECT * FROM TABLE1 FORCE INDEX (FIELD1),强制使用FIELD1索引,即在创建表的时候没有索引,但是本次查询强制建立并使用索引
SELECT * FROM TABLE1 IGNORE INDEX (FIELD1, FIELD2),强制取消索引
对于分片字段非SQL决定、而由其他外置条件决定的场景,可使用SQL Hint灵活注入分片字段
3、HintManager
在ShardingSphere提供了HintManager工具类来做强制路由。
强制路由是线程不安全的,但是在HintManager中基于ThreadLocal存储HintManager实例,因此实现了线程安全。
HintManager 由于是线程安全的,因此使用完就需要释放资源,因此其实现了 AutoCloseable接口,该接口就是为了释放资源,在使用完毕后使用 try with resource 来释放资源。
其他的就是一些变量定义,例如数据库分片值、数据表分片值、是否只有数据库分片、是否只路由主库,那么在使用时,如果有数据库分片值,就使用数据库分片值;如果没有,就可以指定主库或从库来间接地完成路由。
这些是可以根据业务场景进行设置的,如果业务只访问主库,就把masterRouteOnly设置为true,业务场景需要对数据库分片,把数据库分片值扔到databaseShardingValues中即可,扔的过程就相当于人为的设置了分片键。
// 分片信息的作用范围就是当前线程
// try-with-resource机制
public final class HintManager implements AutoCloseable {
//基于ThreadLocal存储HintManager实例
private static final ThreadLocal<HintManager> HINT_MANAGER_HOLDER = new ThreadLocal<>();
// 根据业务场景进行分片键的设置
//数据库分片值
private final Multimap<String, Comparable<?>> databaseShardingValues = HashMultimap.create();
//数据表分片值
private final Multimap<String, Comparable<?>> tableShardingValues = HashMultimap.create();
//是否只有数据库分片
private boolean databaseShardingOnly;
//是否只路由主库
private boolean masterRouteOnly;
}
4、HintManager 使用方法:
设置强制路由分片信息:在使用HintManager时,不建议直接使用,可以定义一个HintManagerHelper,在该类中初始化hintManager,将hintManager的databaseShardingValues设置为1,即只使用第一个数据库实例。
public class HintManagerHelper {
static void initializeHintManagerForShardingDatabases(final HintManager hintManager) {
hintManager.setDatabaseShardingValue(1L);
}
}
推荐使用方法:上面提到可以使用 try with resource来关闭资源,因此推荐使用该方式。
try(HintManager hintManager=HintManager.getInstance();
Connection connection=dataSource.getConnection();
Statement statement=connection.createStatement()){
HintManagerHelper.initializeHintManagerForShardingDatabases(hintManager);
......
}
5、HintShardingAlgorithm
有时候没有那么简单就可以指定一个库或者表,那么就需要定制化的指定一个库表, 那么就会用到强制路由算法HintShardingAlgorithm。
HintShardingAlgorithm接口扩展了原有的分片接口ShardingAlgorithm,提供了Hint的操作,在Hint中什么都没做,只定义了一个doSharding方法,传入了两个参数,一个是所有可用的目标值,一个是强制路由信息,那么就可以根据传入的强制路由来对比和匹配可用目标值。
// 接口
public interface HintShardingAlgorithm<T extends Comparable<?>> extends ShardingAlgorithm {
Collection<String> doSharding(Collection<String> availableTargetNames,
HintShardingValue<Comparable<?>> shardingValue);
}
// 实现类
public final class HintInlineShardingAlgorithm implements HintShardingAlgorithm<Comparable<?>> {
public Collection<String> doSharding(Collection<String> availableTargetNames,
HintShardingValue<Comparable<?>> shardingValue) {
return shardingValue.getValues().isEmpty() ? availableTargetNames :
(Collection) shardingValue.getValues().stream()
.map(this::doSharding).collect(Collectors.toList());
}
}
(二)ShardingSphere和读写分离
1、读写分离与主从架构
一主多从架构场景下,写只会走主库,读一般都走从库,从库通过binlog同步主库数据,那么对于实时性要求很高的场景,就会因为数据同步导致数据不一致,那么在主库和从库不一致时,可以采用强制路由访问主库;另外对于多从来说,需要采用负载均衡机制来完成对目标从库的路由。
2、读写分离配置
ReadwriteSplittingRuleConfiguration:读写分离规则,5.0之后改的这个名字
dataSources:数据源,数据结构是 Collection<ReadwriteSplittingDataSourceRuleConfiguration>
loadBalancers:负载均衡器,数据结构是Map<String, ShardingSphereAlgorithmConfiguration>
ReadwriteSplittingDataSourceRuleConfiguration:读写分离数据源规则
name:读写分离数据源名称,数据结构是String
type:读写分离数据源类型,如Static,数据结构是Properties
props:数据源属性,如主数据源名等,数据结构是Properties
loadBalancerName:负载均衡算法名,数据结构是Properties
3、配置样例
## 读写分离类型
# 数据源名称定义为readwrite_ds(根据业务自定义)
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.type=Static
## 读写分离主从数据源
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.props.write-data-source-name=dswrite
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.props.read-data-source-names=dsread0,dsread1
## 从库负载均衡算法
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.load-balancer-name=round_robin
spring.shardingsphere.rules.readwrite-splitting.load-balancers.round_robin.type=ROUND_ROBIN
(三)客服系统案例演进
1、读写分离
# 配置数据库名称
spring.shardingsphere.datasource.names=dswrite,dsread0,dsread1
# 数据库配置
spring.shardingsphere.datasource.dswrite.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite.url=jdbc:mysql://192.168.249.130:3306/dswrite?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dswrite.username=root
spring.shardingsphere.datasource.dswrite.password=root
spring.shardingsphere.datasource.dsread0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dsread0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dsread0.url=jdbc:mysql://192.168.249.130:3306/dsread0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dsread0.username=root
spring.shardingsphere.datasource.dsread0.password=root
spring.shardingsphere.datasource.dsread1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dsread1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dsread1.url=jdbc:mysql://192.168.249.130:3306/dsread1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dsread1.username=root
spring.shardingsphere.datasource.dsread1.password=root
## 读写分离类型
# 数据源名称定义为readwrite_ds(根据业务自定义)
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.type=Static
## 读写分离主从数据源
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.props.write-data-source-name=dswrite
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.props.read-data-source-names=dsread0,dsread1
## 从库负载均衡算法
spring.shardingsphere.rules.readwrite-splitting.data-sources.readwrite_ds.load-balancer-name=round_robin
spring.shardingsphere.rules.readwrite-splitting.load-balancers.round_robin.type=ROUND_ROBIN
# 显示 sql
spring.shardingsphere.props.sql-show=true
2、读写分离 + 分库分表
# 配置数据库名称
spring.shardingsphere.datasource.names=dswrite0,dswrite1,dswrite0read0,dswrite0read1,dswrite1read0,dswrite1read1
# 数据库配置
spring.shardingsphere.datasource.dswrite0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite0.url=jdbc:mysql://192.168.249.130:3306/dswrite0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dswrite0.username=root
spring.shardingsphere.datasource.dswrite0.password=root
spring.shardingsphere.datasource.dswrite0read0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite0read0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite0read0.url=jdbc:mysql://192.168.249.130:3306/dswrite0read0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dswrite0read0.username=root
spring.shardingsphere.datasource.dswrite0read0.password=root
spring.shardingsphere.datasource.dswrite0read1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite0read1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite0read1.url=jdbc:mysql://192.168.249.130:3306/dswrite0read1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dswrite0read1.username=root
spring.shardingsphere.datasource.dswrite0read1.password=root
spring.shardingsphere.datasource.dswrite1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite1.url=jdbc:mysql://192.168.249.130:3306/dswrite1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dswrite1.username=root
spring.shardingsphere.datasource.dswrite1.password=root
spring.shardingsphere.datasource.dswrite1read0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite1read0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite1read0.url=jdbc:mysql://192.168.249.130:3306/dswrite1read0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dswrite1read0.username=root
spring.shardingsphere.datasource.dswrite1read0.password=root
spring.shardingsphere.datasource.dswrite1read1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.dswrite1read1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.dswrite1read1.url=jdbc:mysql://192.168.249.130:3306/dswrite1read1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.dswrite1read1.username=root
spring.shardingsphere.datasource.dswrite1read1.password=root
## 配置读写分离
# 配置 ds0 数据源
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds0.type=Static
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds0.props.write-data-source-name=dswrite0
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds0.props.read-data-source-names=dswrite0read0,dswrite0read1
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds0.load-balancer-name=round_robin
# 配置 ds1 数据源
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds1.type=Static
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds1.props.write-data-source-name=dswrite1
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds1.props.read-data-source-names=dswrite1read0,dswrite1read1
spring.shardingsphere.rules.readwrite-splitting.data-sources.ds1.load-balancer-name=round_robin
spring.shardingsphere.rules.readwrite-splitting.load-balancers.round_robin.type=ROUND_ROBIN
# 库表物理信息
# 逻辑表im_message表对应的物理库表地址
spring.shardingsphere.rules.sharding.tables.im_message.actual-data-nodes=ds$->{0..1}.im_message_$->{0..2}
# 物理表主键id
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.column=id
# 物理表主键生成策略
spring.shardingsphere.rules.sharding.tables.im_message.key-generate-strategy.key-generator-name=snowflake
# 广播表
spring.shardingsphere.rules.sharding.broadcast-tables=im_business_type
# 分库配置
# 分片键
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-column=from_user_id
# 分片算法
spring.shardingsphere.rules.sharding.default-database-strategy.standard.sharding-algorithm-name=database-inline
# 分表配置
# 分片键
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-column=to_user_id
# 分片算法
spring.shardingsphere.rules.sharding.tables.im_message.table-strategy.standard.sharding-algorithm-name=im_message-online
# database-inline 算法配置
# 分库逻辑
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds$->{from_user_id % 2}
# 分表逻辑
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.im_message-online.props.algorithm-expression=im_message_$->{to_user_id % 3}
# snowflake策略配置,在shardingsphere中,小写表示是自定义的属性,大写是shardingsphere中自带的枚举类型
spring.shardingsphere.rules.sharding.key-generators.snowflake.type=SNOWFLAKE
# 显示 sql
spring.shardingsphere.props.sql-show=true
四、利用ShardingSphere实现敏感数据的加解密
(一)数据脱敏的场景和应用
1、常见的敏感信息
身份证号、手机号、卡号、用户姓名、账号密码
2、抽象数据脱敏:数据脱敏的三个维度
敏感数据如何存储
敏感数据如何加解密
业务代码中如何嵌入数据脱敏
3、三个维度的抽象
(1)敏感数据如何存储
一种是敏感信息以密文的形式将加密之后的数据进行存储,好处是不存在任何一种途径能够从数据库中获取这些数据的明文
一种是基于统计分析需要,敏感信息同时保存明文和密文:将一个字段用两列来进行保存,一列保存明文,一列保存密文,但不确保明文和密文存储在同一个存储内。
(2)敏感数据如何加解密
对称加密:加密和解密使用同一秘钥加密和解密速度快,安全性较低,代表算法是DEA和AES
非对称加密:两个密钥,公钥加密,私钥解密加密和解密速度慢,安全性较高,代表算法是RSA和DSA
(3)业务代码中如何嵌入数据脱敏:
目标是尽量做到自动化和低侵入性,且应该对开发人员足够透明
自动化:自动将字段映射到明文列和密文类
配置化:灵活指定脱敏过程中所采用的各种加解密算法
(二)ShardingSphere加解密机制
1、敏感数据如何存储
在 ShardingSphere 中除了明文列(plainColumn)和密文列(cipherColumn)之外,还存在逻辑列(logicColumn)和查询列(assistedQueryColumn)。
逻辑列是用来设置分库分片键,一般不大用。
查询列用于查询操作。
2、敏感数据如何加解密
ShardingSphere 提供了EncryptAlgorithm接口,专门用来做加解密操作,其集成了ShardingSphereAlgorithm接口,该接口是ShardingSphere最底层的算法。
在EncryptAlgorithm中提供了加密和解密两个方法。
public interface EncryptAlgorithm<I, O> extends ShardingSphereAlgorithm {
//加密
O encrypt(I plainValue, EncryptContext encryptContext);
//解密
I decrypt(O cipherValue, EncryptContext encryptContext);
}
ShardingSphere提供了几种常见的加解密算法:SM3EncryptAlgorithm、SM4EncryptAlgorithm 、RC4EncryptAlgorithm、AESEncryptAlgorithm、MD5EncryptAlgorithm
3、 业务代码中如何嵌入数据脱敏
应用程序使用逻辑列操作数据库,而 ShardingSphere 会将逻辑列与明文列、密文列做绑定,实际上操作的是明文列和密文列。
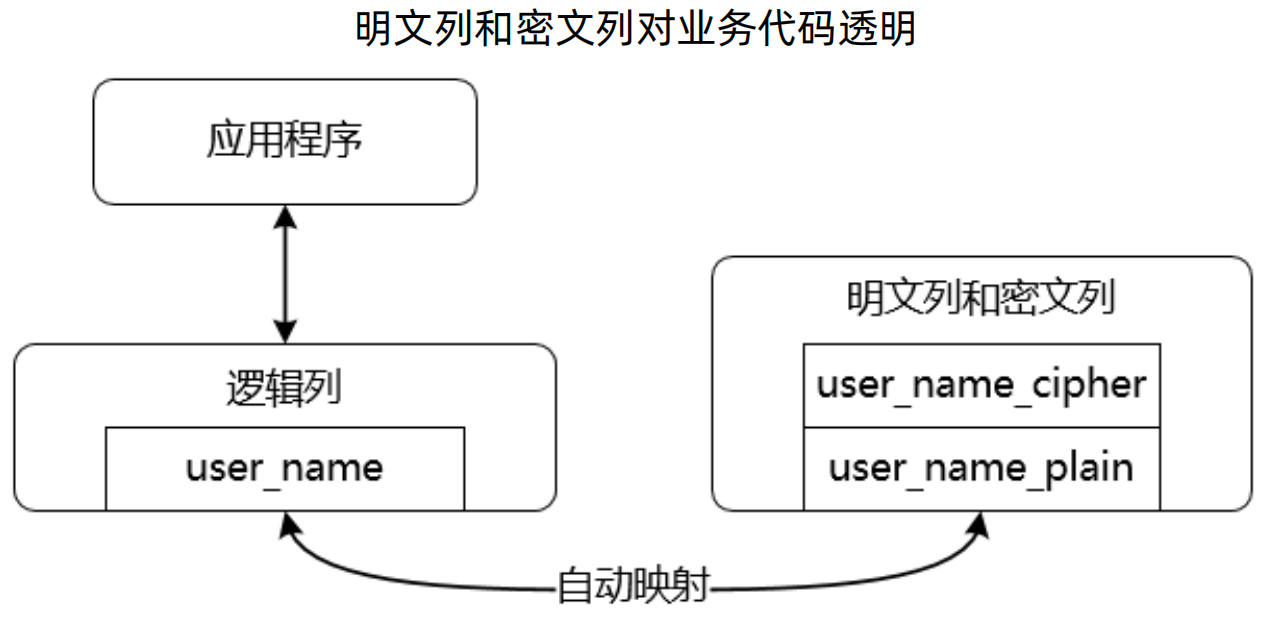
4、ShardingSphere加解密基本原理
ShardingSphere的原理就是对逻辑sql进行拦截与改写,而对于加解密场景,除了对于原始sql进行改写外,还根据脱敏配置进行处理。
如下图所示,原始sql是操作的用户名和密码列,用户名配置了同时又明文列和密文列,而密码配置了只有密文列,经过拦截改写后的sql如下图右半部分所示。
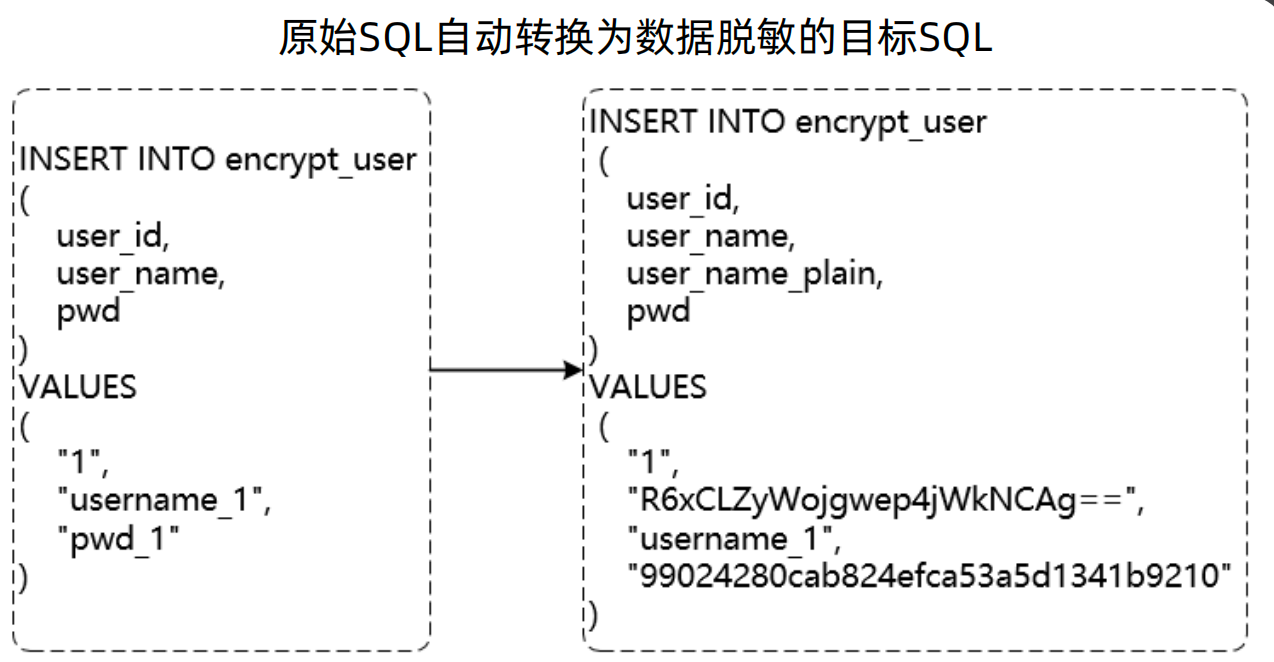
5、ShardingSphere加解密配置:
EncryptRuleConfiguration:加密规则
tables:加密表规则,数据结构是Collection<EncryptTableRuleConfiguration>
encryptors:解密器,数据结构是Map<String, ShardingSphereAlgorithmConfiguration>
EncryptTableRuleConfiguration:加密表规则
columns:解密列规则,数据结构是Collection<EncryptColumnRuleConfiguration>
EncryptColumnRuleConfiguration:加密列规则
logicColumn:逻辑列,数据结构是String
cipherColumn:密文列,数据结构是String
assistedQueryColumn:查询列,数据结构是String
plainColumn:明文列,数据结构是String
encryptorName:加密器名称,数据结构是String
queryWithCipherColumn:是否查询密文列,数据结构是Boolean
配置样例如下所示
spring.shardingsphere.rules.encrypt.encryptors.name-encryptor.type=AES
spring.shardingsphere.rules.encrypt.encryptors.name-encryptor.props.aes-key-value=123456abc
spring.shardingsphere.rules.encrypt.encryptors.password-encryptor.type=AES
# 加解密器配置
spring.shardingsphere.rules.encrypt.encryptors.password-encryptor.props.aes-key-value=123456abc
spring.shardingsphere.rules.encrypt.tables.t_user.columns.username.cipher-column=username
spring.shardingsphere.rules.encrypt.tables.t_user.columns.username.encryptor-name=name-encryptor
spring.shardingsphere.rules.encrypt.tables.t_user.columns.pwd.cipher-column=password
# 指定敏感数据列和加解密器映射关系
spring.shardingsphere.rules.encrypt.tables.t_user.columns.pwd.encryptor-name=password-encryptor
# 决定是直接返回明文列,还是查询密文列并进行解密再返回
spring.shardingsphere.props.query-with-cipher-column=true
(三)客服系统案例演进
客服系统IM消息加解密场景
CREATE TABLE `im_message` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`from_user_id` bigint(20) NOT NULL COMMENT '消息发送方用户Id',
`from_username` varchar(45) DEFAULT NULL COMMENT '消息发送方用户名',
`to_user_id` bigint(20) NOT NULL COMMENT '消息接收方用户Id',
`to_username` varchar(45) DEFAULT NULL COMMENT '消息接收方用户名',
`business_type_code` varchar(45) DEFAULT NULL COMMENT '业务类型编码',
`business_type_name` varchar(45) DEFAULT NULL COMMENT '业务类型名称',
`message` varchar(255) NOT NULL COMMENT '聊天消息',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='聊天记录表';
对于 from_username 和 to_username 做加密
# 配置数据库名称
spring.shardingsphere.datasource.names=ds4
# 数据库配置
spring.shardingsphere.datasource.ds4.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds4.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds4.url=jdbc:mysql://192.168.249.130:3306/ds4?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds4.username=root
spring.shardingsphere.datasource.ds4.password=root
# 加解密算法
spring.shardingsphere.rules.encrypt.encryptors.username-encryptor.type=AES
spring.shardingsphere.rules.encrypt.encryptors.username-encryptor.props.aes-key-value=123456abc
# 加解密器配置
# 设置 im_message 表的 from_user_name 字段对应的密文字段和使用的加密算法
spring.shardingsphere.rules.encrypt.tables.im_message.columns.from_username.cipher-column=from_username
spring.shardingsphere.rules.encrypt.tables.im_message.columns.from_username.encryptor-name=username-encryptor
# 设置 im_message 表的 to_user_name 字段对应的密文字段和使用的加密算法
spring.shardingsphere.rules.encrypt.tables.im_message.columns.to_username.cipher-column=to_username
spring.shardingsphere.rules.encrypt.tables.im_message.columns.to_username.encryptor-name=username-encryptor
# 使用密文查询
spring.shardingsphere.props.query-with-cipher-column=true
# 显示 sql
spring.shardingsphere.props.sql-show=true
五、ShardingSphere分片引擎执行流程解析
ShardingSphere分片引擎
ShardingSphere分片引擎由解析引擎、路有引擎、改写引擎、执行引擎、归并引擎组成。
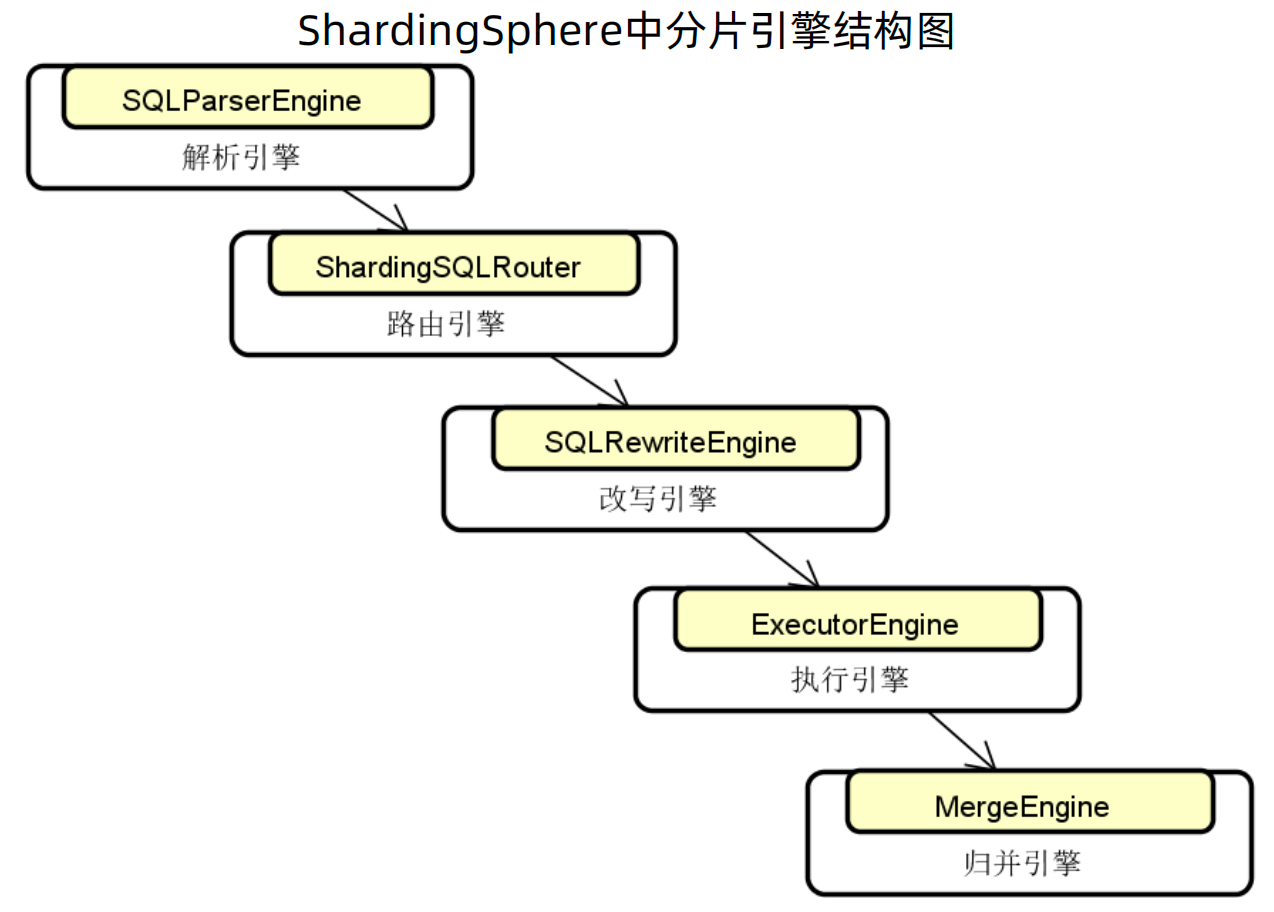
(一)SQL解析
1、解析引擎 - AST:
如 sql : SELECT task_id, task_name FROM health_task WHERE user_id = 'user1' AND record_id = 2,对应的语法树如下所示
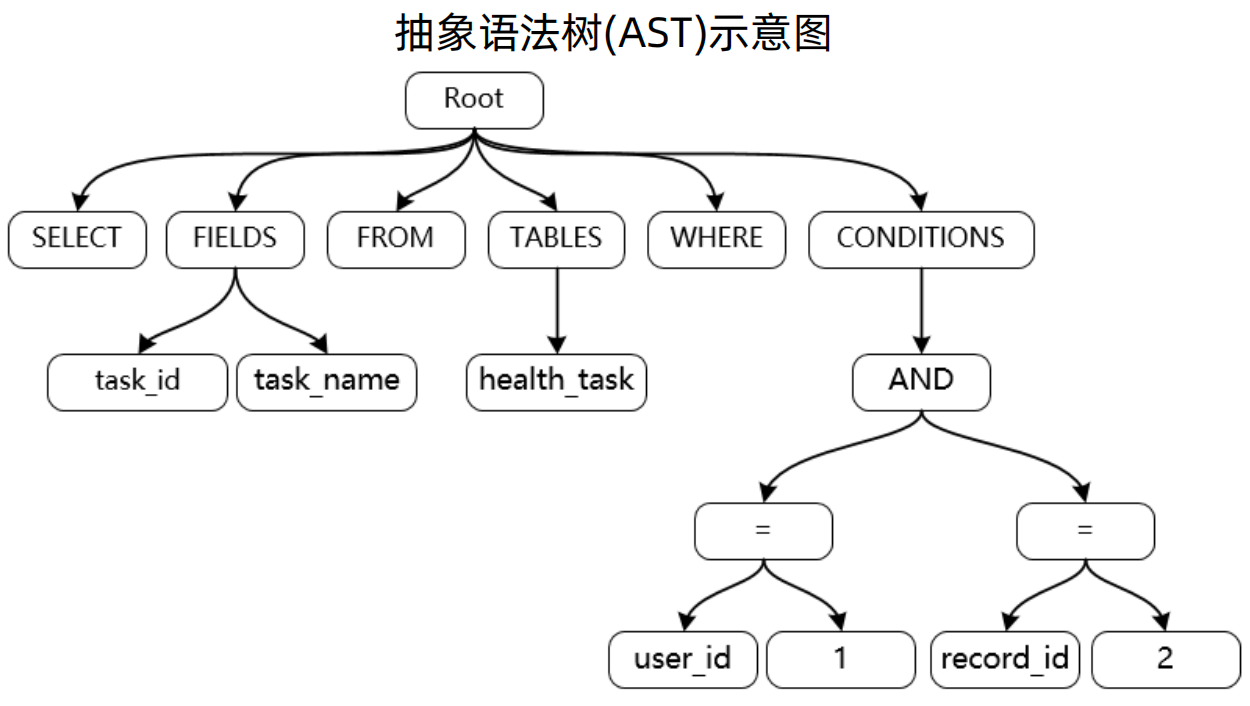
2、解析引擎的三大步骤:
生成SQL抽象语法树:输出AST
填充SQL语句:输出SQLSegment
提取SQL片段:输出SQLStatement
(二)SQL路由
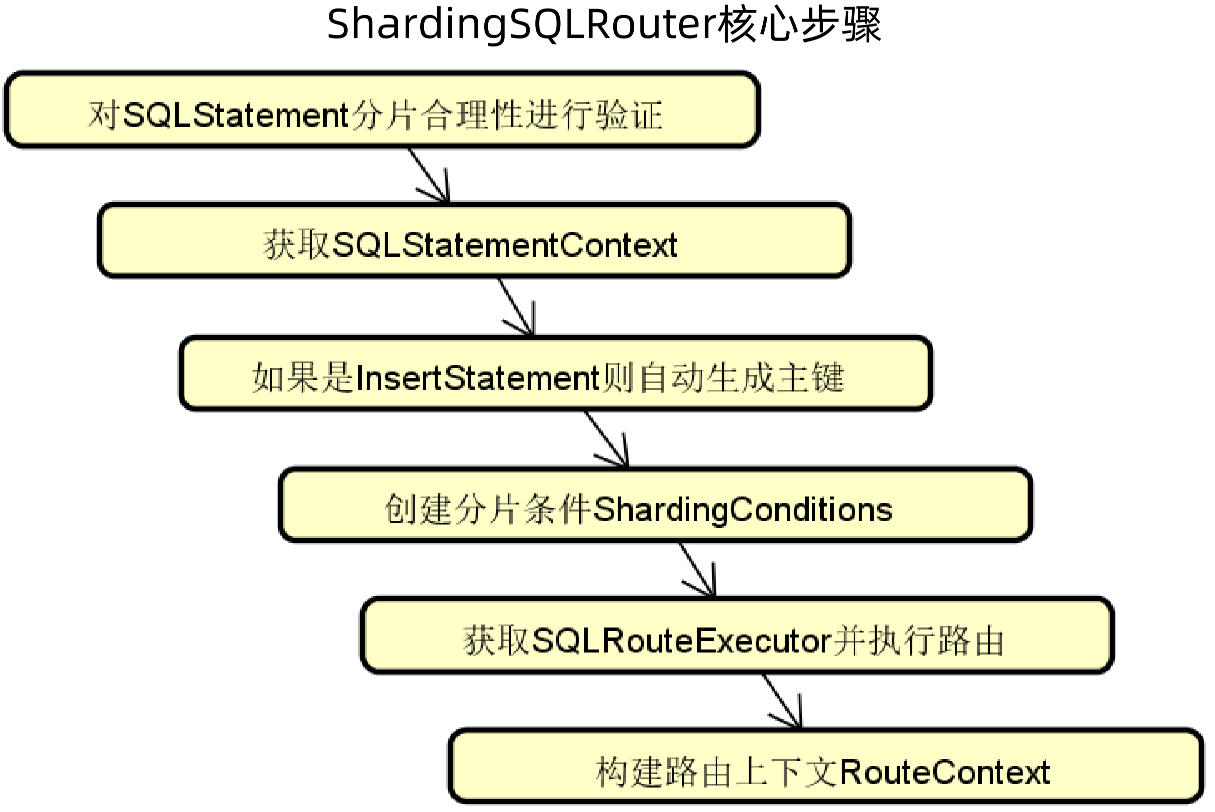
1、路由引擎 - 核心步骤:
(1)对SQLStatement分片合理性进行验证
(2)获取SQLStatementContext:SQLStatement上下文信息
(3)如果是InsertStatement则自动生成主键:使用指定的算法生成分布式主键
(4)创建分片条件ShardingConditions
(5)获取SQLRouteExecutor并执行路由
(6)构建路由上下文RouteContext
2、路由引擎核心组件交互
我们在设计源码时,经常会碰到一个问题:怎么把内存结构、分层结构设计的更合理。一般情况下都会设计两层组件:
一层叫做Infrastructure,也就是基础设施层,在ShardingSphere的路由层叫做ShardingSphere-infra-route,其提供的是基础能力,因此不直接面向业务。
一层在ShardingSphere-sharding-core,其是上层组件。
如下图所示,面向应用的是以Sharding开头的,面向分片的,是顶层的;面向底层是以SQL开头的,偏向底层。其中用虚线连接,表示这是两个不同包结构中的内容。

具体代码如下所示:
上层结构是ShardingRouteEngine,提供了执行路由返回路由上下文的方法route;
底层组件是SQLRouter,上层结构会依赖该接口来实现相关功能。
// 上层组件
public interface ShardingRouteEngine {
//执行路由,返回路由上下文
RouteContext route(ShardingRule shardingRule);
}
// 底层组件
public interface SQLRouter<T extends ShardingSphereRule> extends OrderedSPI<T> {
//创建路由上下文
RouteContext createRouteContext(LogicSQL logicSQL, ShardingSphereDatabase database, T rule, ConfigurationProperties props);
//装饰路由上下文
void decorateRouteContext(RouteContext routeContext, LogicSQL logicSQL, ShardingSphereDatabase database, T rule, ConfigurationProperties props);
}
3、SQLRouteEngine(入口) :
其通过SQLRouteExecutor具体执行路由,然后返回路由上下文。
在ShardingSphere中,有两个理由执行器,一个叫做AllSQLRouteExecutor,即全量路由,一个叫做PartialSQLRouteExector,即部分路由。
在部分路由中,需要传入路由规则ShardingSphereRule,根据规则进行路由。
public final class SQLRouteEngine {
private final Collection<ShardingSphereRule> rules;
private final ConfigurationProperties props;
public RouteContext route(final LogicSQL logicSQL, final ShardingSphereDatabase database) {
// 通过SQLRouteExecutor具体执行路由
SQLRouteExecutor executor =
isNeedAllSchemas(logicSQL.getSqlStatementContext().getSqlStatement())
? new AllSQLRouteExecutor()
: new PartialSQLRouteExecutor(rules, props);
return executor.route(logicSQL, database);
}
private boolean isNeedAllSchemas(final SQLStatement sqlStatement) {
return sqlStatement instanceof MySQLShowTablesStatement || sqlStatement instanceof
MySQLShowTableStatusStatement;
}
}
4、ShardingRule:
这里的配置项就是和上面案例中配置的一样了,例如分片算法、分片键算法、表规则列表等等。
//DataSource名称列表
private final Collection<String> dataSourceNames;
//分片算法
private final Map<String, ShardingAlgorithm> shardingAlgorithms = new LinkedHashMap<>();
//分片键算法
private final Map<String, KeyGenerateAlgorithm> keyGenerators = new LinkedHashMap<>();
//表规则列表
private final Map<String, TableRule> tableRules = new LinkedHashMap<>();
//绑定表规则列表
private final Map<String, BindingTableRule> bindingTableRules = new LinkedHashMap<>();
//广播表名称列表
private final Collection<String> broadcastTables;
//默认数据库分片策略
private final ShardingStrategyConfiguration defaultDatabaseShardingStrategyConfig;
//默认数据表分片策略
private final ShardingStrategyConfiguration defaultTableShardingStrategyConfig;
//默认分片键生成器
private final KeyGenerateAlgorithm defaultKeyGenerateAlgorithm;
//默认分片键
private final String defaultShardingColumn;
5、路由类型:
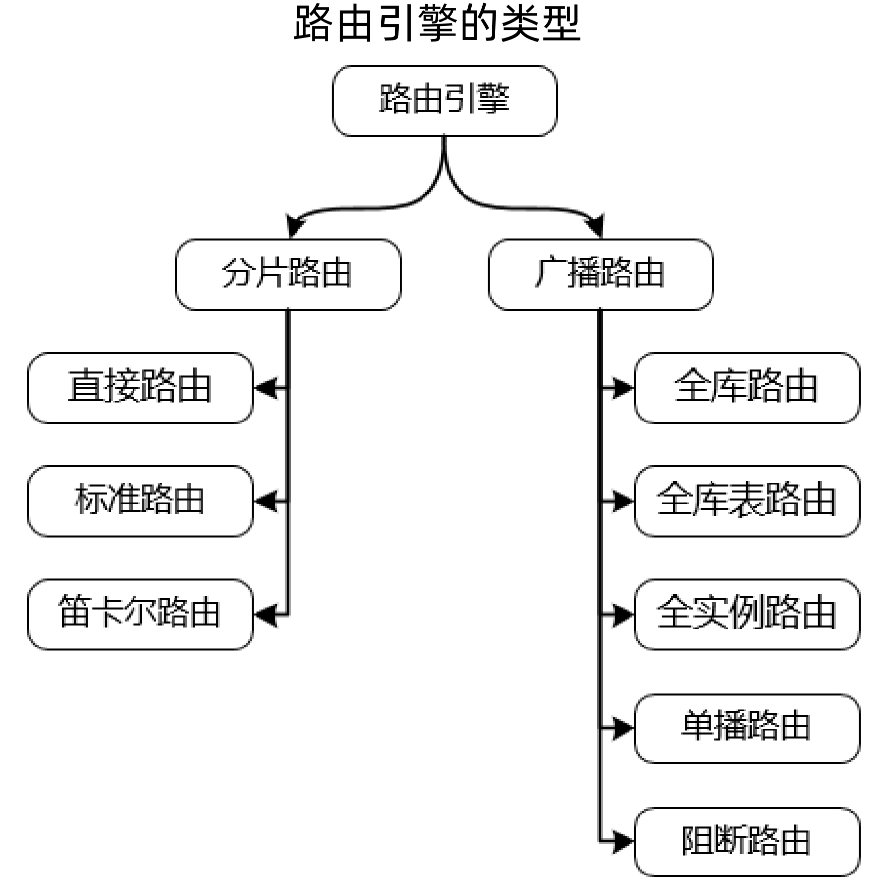
路由包括分片路由和广播路由两大类。
分片路由:
直接路由:直接找到某个点进行处理;
标准路由:像之前提到的广播表、绑定表这些,以及前面演示的,都是标准路由。
笛卡尔路由:相当于是全路由
广播路由:没有分片规则的路由,没有分片信息,只有路由规则
6、分片策略:
分片策略(SharingStrategy) = 分片算法(ShardingAlgorithm) + 分片键(column)
首先在TableRule中,定义了库级别的分片策略databaseSharingStrategy和表分片策略tableSharingStrategy,而在每一个策略中又有不同的分片算法
那么整体结构就是先有配置项,配置项中有分片策略,分片策略中有分片算法。
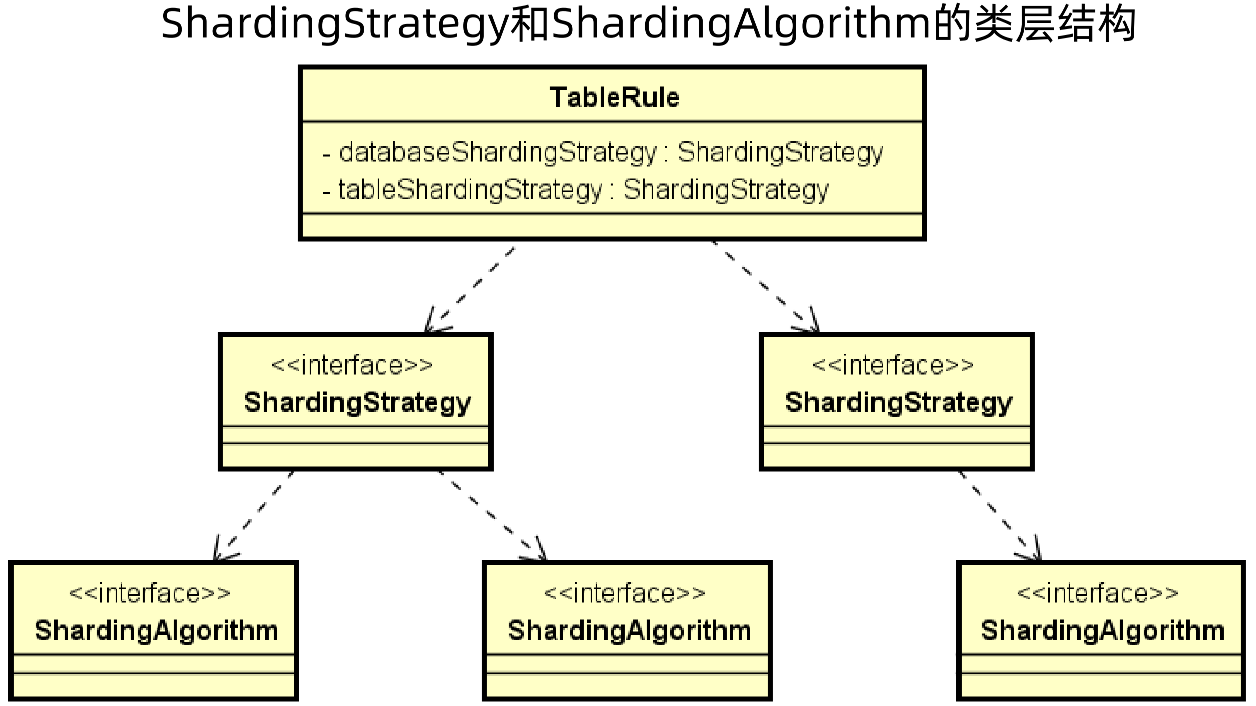
在 ShardingStrategy 中有三个方法:
获取分片列方法getShardingColumns:分片键是可以设置多个的
获取分片算法getShardingAlgorithm
执行分片doSharding:参数包括所有可用对象(库或者表)availableTargetNames,分片条件shardingConditionValues
在路由策略中会有路由算法,ShardingSphereAlgorithm是底层的算法,而ShardingAlgorithm继承自ShardingSphereAlgorithm,是专门做分片的算法,虽然在ShardingAlgorithm中什么都没做,这是ShardingSphere的命名规范,即以ShardingSphere开头的,都是底层的实现,而以Sharding开头的,都是面向应用层的实现。
public interface ShardingStrategy {
//获取分片列
Collection<String> getShardingColumns();
//获取分片算法
ShardingAlgorithm getShardingAlgorithm();
//执行分片
Collection<String> doSharding(Collection<String> availableTargetNames,
Collection<ShardingConditionValue> shardingConditionValues,
DataNodeInfo dataNodeInfo, ConfigurationProperties props);
}
public interface ShardingSphereAlgorithm extends TypedSPI, SPIPostProcessor {
Properties getProps();
}
public interface ShardingAlgorithm extends ShardingSphereAlgorithm {
}
挑一个具体的分片策略来进行说明:StandardShardingStrategy
StandardShardingStrategy是标准分片策略,提供对SQL语句中的(=, IN)和(>, <, >=, <=, BETWEEN, AND)等操作的分片支持,其提供了两种分片策略,一种是确定值分片PreciseSharding,用以处理(=, IN)操作的分片,一种是范围分片RangeSharding,用以处理(>, <, >=, <=, BETWEEN, AND)等操作的分片
public Collection<String> doSharding(final Collection<String> availableTargetNames, final Collection<ShardingConditionValue> shardingConditionValues, final DataNodeInfo dataNodeInfo, final ConfigurationProperties props) {
ShardingConditionValue shardingConditionValue = shardingConditionValues.iterator().next();
Collection<String> shardingResult = shardingConditionValue instanceof ListShardingConditionValue
// 如果分片值是一个列表,则执行PreciseSharding
? doSharding(availableTargetNames, (ListShardingConditionValue) shardingConditionValue, dataNodeInfo)
// 如果分片值是一个范围,则执行RangeSharding
: doSharding(availableTargetNames, (RangeShardingConditionValue) shardingConditionValue, dataNodeInfo);
Collection<String> result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
result.addAll(shardingResult);
return result;
}
(三)改写引擎
开发人员是面向逻辑库与逻辑表所书写的SQL,并不能够直接在真实的数据库中执行,SQL改写用于将逻辑SQL改写为在真实数据库中可以正确执行的SQL。
对于改写引擎而言,其核心还是一个Context,即SQLRewritecontext,其是通过SQLBuilder和SQLRewriteEngine来创建的。
在改写引擎中,SQLRewritecontext又通过装饰器模式封装了爱他SQLRewritecontext,装饰类主要有两个,一个是ShardingSQLRewriteContextDecorator,即用来做sql重新的的上下文,一个是EncryptSQLRewriteContextDecorator,即用来做加解密的上下文。
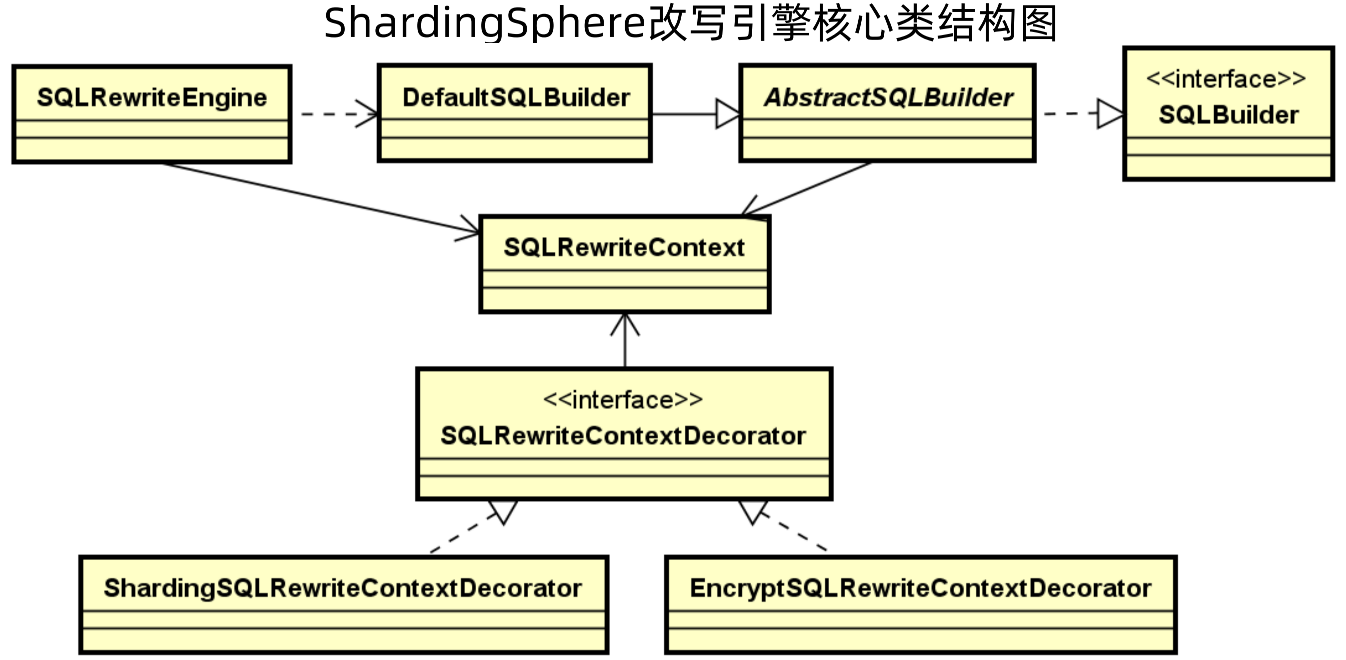
1、SQLRewriteContext
SQLRewriteContext源码如下所示,除了数据库名、原始sql等内容外,还有SQLToken生成器,其主要是来组装真实sql。
//数据库名
private final String databaseName;
//数据库Schema
private final Map<String, ShardingSphereSchema> schemas;
//SQLStatement上下文
private final SQLStatementContext<?> sqlStatementContext;
//原始SQL
private final String sql;
//参数列表
private final List<Object> parameters;
//SQLToken列表
private final List<SQLToken> sqlTokens = new LinkedList<>();
//参数构建器
private final ParameterBuilder parameterBuilder;
//SQLToken生成器
private final SQLTokenGenerators sqlTokenGenerators = new SQLTokenGenerators();
以分布式自增主键场景,原sql没有操作id主键,但是实际执行时,却根据配置的算法补充了分布式id,这实际上就是SQLToken来做的,这个场景下的SQLToken是GeneratedKeyInsertColumnToken。
INSERT INTO health_record (user_id, level_id, remark) values (1, 1, ”remark1”)
INSERT INTO health_record (record_id, user_id, level_id, remark) values (“471698773731577856”, 1, 1, ”Remark1”)
GeneratedKeyInsertColumnToken通过GeneratedKeyInsertColumnToken做了补列操作,然后通过toString方法生成对应的语句。
//补列操作
public final class GeneratedKeyInsertColumnToken extends SQLToken implements Attachable {
private final String column;
public GeneratedKeyInsertColumnToken(final int startIndex, final String column) {
super(startIndex);
this.column = column;
}
@Override
public String toString() {
return ", " + column;
}
}
2、装饰器模式:
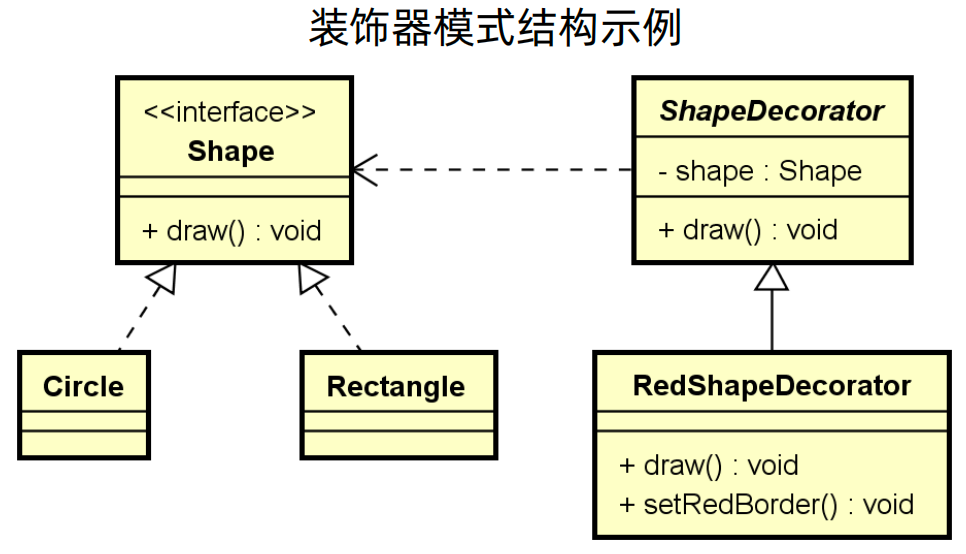
如下所示,有一个画画的接口Shape,实现类有画圆型和画方形,现在为了对画出来的形状添加边框,边框还有不同的颜色,那么就需要改变原来的类,要编程画红色边框圆形、画红色边框方形、画蓝色边框圆形、画蓝色边框方形等等,类的数量就是笛卡尔积,包装的越多,类就会越多,最后难以管理。
使用装饰器模式,设计一个画边框的类ShapDecorator,那么红色边框、蓝色边框只要继承ShapDecorator就可以了,这样我们只用装饰器模式,就可以解决类数量爆炸的问题,也可以做到很好的扩展。
装饰器模式有一个重要的点,就是装饰类要有原类的方法,例如下面的draw方法,不然整个调用流程就会出错。
装饰器模式一个典型的应用就是在Mybatis的缓存中,在Mybatis中存在缓存接口 Cache,针对与不同的场景有不同的实现,例如阻塞形式的缓存BlockingCache、先进先出的缓存FifoCache、有日志记录的缓存LoggingCache、采用Lru算法的 LruCache。
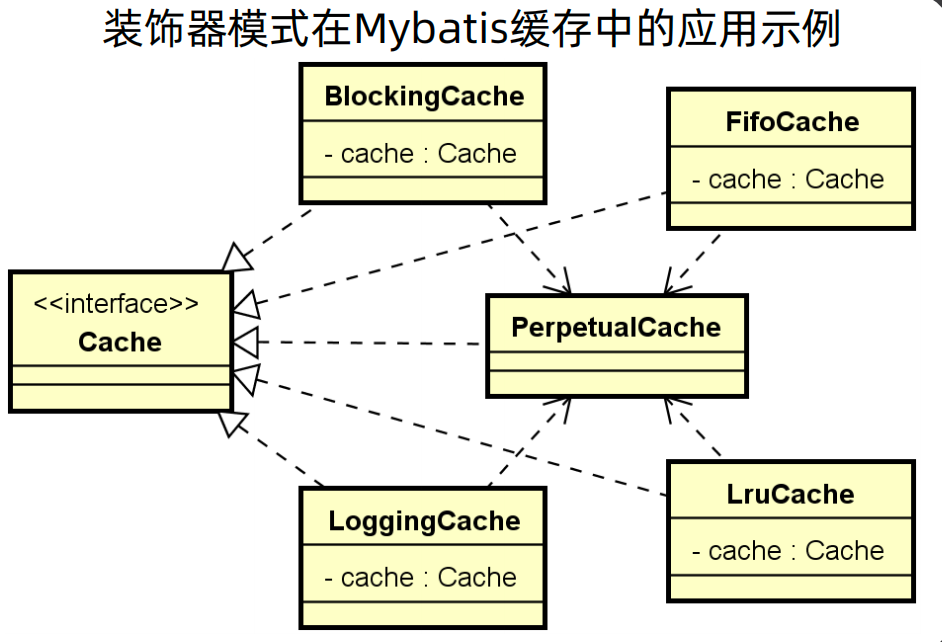
对于SQLRewriteContextDecorator而言,其提供了对SQLRewriteContext执行装饰的方法decorate,再具体的实现中,如ShardingSQLRewriteContextDecorator的decorate方法中,对参数进行了改写,并最终调用sqlRewriteContext.addSQLTokenGenerators生成SQLToken。
public interface SQLRewriteContextDecorator<T extends ShardingSphereRule> extends OrderedSPI<T> {
//对SQLRewriteContext执行装饰
void decorate(T rule, ConfigurationProperties props, SQLRewriteContext sqlRewriteContext, RouteContext routeContext);
}
public final class ShardingSQLRewriteContextDecorator implements SQLRewriteContextDecorator<ShardingRule> {
@Override
public void decorate(final ShardingRule shardingRule, final ConfigurationProperties props, final SQLRewriteContext sqlRewriteContext, final RouteContext routeContext) {
if (!sqlRewriteContext.getParameters().isEmpty()) {
......
// 参数改写
rewriteParameters(sqlRewriteContext, parameterRewriters);
}
// 生成SQLToken
sqlRewriteContext.addSQLTokenGenerators(new ShardingTokenGenerateBuilder(shardingRule, routeContext, sqlRewriteContext.getSqlStatementContext()).getSQLTokenGenerators());
}
private void rewriteParameters(final SQLRewriteContext sqlRewriteContext, final Collection<ParameterRewriter> parameterRewriters) {
for (ParameterRewriter each : parameterRewriters) {
each.rewrite(sqlRewriteContext.getParameterBuilder(), sqlRewriteContext.getSqlStatementContext(), sqlRewriteContext.getParameters());
}
}
}
3、SQLRewriteEntry(入口)
对于改写引擎来说,SQLRewriteEntry是其入口,外部访问改写引擎,就是通过SQLRewriteEntry的rewrite方法进行改写。
在rewrite方法中,首先创建改写上下文SQLRewriteContext,然后根据路由信息是否为空,选择走通用的改写实现类GenericSQLRewriteEngine的rewrite方法,还是路由改写引擎RouteSQLRewriteEngine的rewrite方法。
public final class SQLRewriteEntry {
private final Map<ShardingSphereRule, SQLRewriteContextDecorator> decorators;
public SQLRewriteEntry(final ShardingSphereDatabase database, final ConfigurationProperties props) {
decorators = SQLRewriteContextDecoratorFactory.getInstance(database.getRuleMetaData().getRules());
}
public SQLRewriteResult rewrite(final String sql, final List<Object> parameters, final SQLStatementContext<?> sqlStatementContext, final RouteContext routeContext) {
// 创建改写上下文
SQLRewriteContext sqlRewriteContext = createSQLRewriteContext(sql, parameters, sqlStatementContext, routeContext);
// 执行改写
return routeContext.getRouteUnits().isEmpty()
? new GenericSQLRewriteEngine(rule, protocolType, storageType).rewrite(sqlRewriteContext)
: new RouteSQLRewriteEngine(rule, protocolType, storageType).rewrite(sqlRewriteContext, routeContext);
}
......
}
(四)内核引擎KernelProcessor
ShardingSphere提供了内核处理器KernelProcessor,其认为SQL路由、SQL重写、SQL执行这三个执行引擎组成了一个完整的内核引擎,因此将这三个执行器组合在一起,形成一个KernelProcessor工具类。
如下代码所示,其是一个承上启下的类,执行了SQL路由和SQL重写后,就执行SQL执行。
public ExecutionContext generateExecutionContext(final LogicSQL logicSQL, final ShardingSphereDatabase database, final ConfigurationProperties props) {
//SQL路由
RouteContext routeContext = route(logicSQL, database, props);
//SQL重写
SQLRewriteResult rewriteResult = rewrite(logicSQL, database, props, routeContext);
//SQL执行
ExecutionContext result = createExecutionContext(logicSQL, database, routeContext, rewriteResult);
return result;
}
private RouteContext route(final LogicSQL logicSQL, final ShardingSphereDatabase database, final ConfigurationProperties props) {
return new SQLRouteEngine(database.getRuleMetaData().getRules(), props).route(logicSQL, database);
}
private SQLRewriteResult rewrite(final LogicSQL logicSQL, final ShardingSphereDatabase database, final ConfigurationProperties props, final
RouteContext routeContext) {
SQLRewriteEntry sqlRewriteEntry = new SQLRewriteEntry(database, props);
return sqlRewriteEntry.rewrite(logicSQL.getSql(), logicSQL.getParameters(), logicSQL.getSqlStatementContext(), routeContext);
}
private ExecutionContext createExecutionContext(final LogicSQL logicSQL, final ShardingSphereDatabase database, final RouteContext routeContext, final SQLRewriteResult rewriteResult) {
return new ExecutionContext(logicSQL, ExecutionContextBuilder.build(database, rewriteResult, logicSQL.getSqlStatementContext()), routeContext);
}
(五)SQL执行
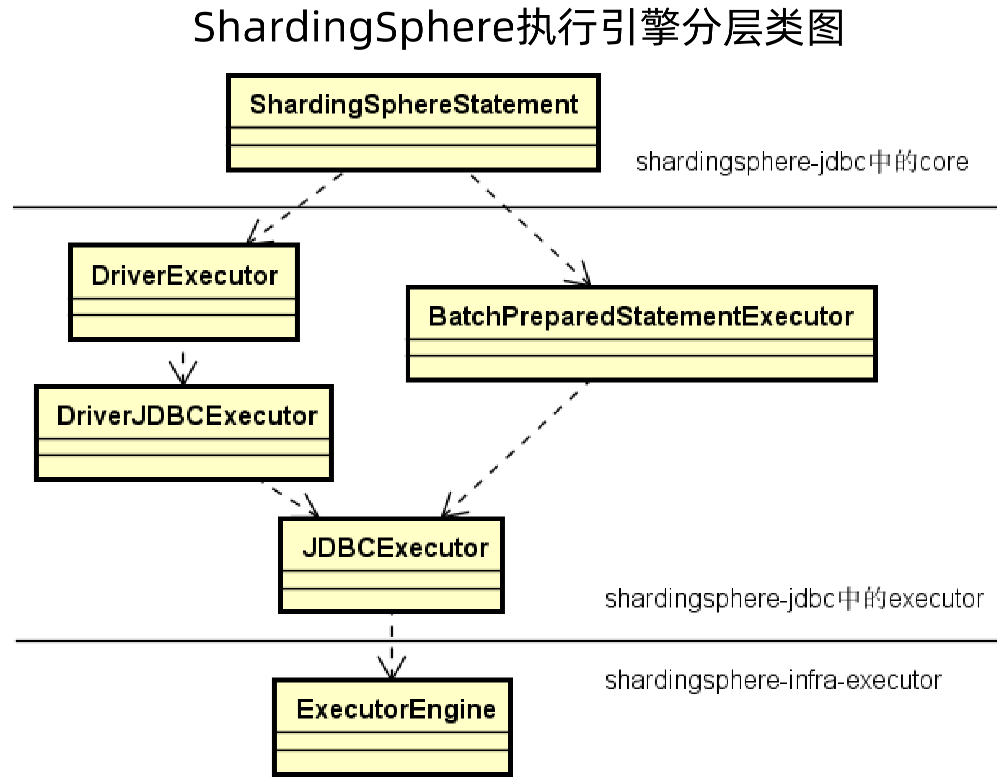
1、ShardingSphere执行引擎分层类图
ShardingSphere执行引擎分层类图如下所示,从物理上分为两部分:
一部分是sharding-infra-executor包,一看以sharding-infra开头,就知道是面向底层的;
一部分是sharding-jdbc包,其是面向应用程序的。
对于sharding-jdbc,又可以在逻辑上分为两层:
一层是sharding-jdbc中的core,其是真正面向应用程序,提供调用入口的类;
一层是sharding-jdbc中的executor,其是对sharding-infra-executor中ExecutorEngine的扩展,在这个里面,又分为批量执行的BatchPreparedStatementExecutor和基本的执行器DriverExecutor,这两个执行器最终都调用 JDBCExecutor来执行,而 JDBCExecutor又会调用sharding-infra-executor包的ExecutorEngine来执行。
2、ExecutorEngine
在 ExecutorEngine 的构造函数中,设置了ExecutorServiceManager。
ExecutorServiceManager 是用来管理ExecutorService的,其会根据传入的线程数量指定使用固定长度线程池或者缓存线程池。
public final class ExecutorEngine implements AutoCloseable {
private final ExecutorServiceManager executorServiceManager;
private ExecutorEngine(final int executorSize) {
executorServiceManager = new ExecutorServiceManager(executorSize);
}
}
public final class ExecutorServiceManager {
private final ExecutorService executorService;
public ExecutorServiceManager(final int executorSize, final String nameFormat) {
executorService = getExecutorService(executorSize, nameFormat);
}
private ExecutorService getExecutorService(final int executorSize, final String nameFormat) {
ThreadFactory threadFactory = ExecutorThreadFactoryBuilder.build(nameFormat);
// 使用JDK执行器服务
return 0 == executorSize ? Executors.newCachedThreadPool(threadFactory) : Executors.newFixedThreadPool(executorSize, threadFactory);
}
}
在 ExecutorEngine 的execute方法中,会根据传入的标识来决定走串行执行或者并行执行,实际上最终走的是syncExecute和asyncExecute,syncExecute是同步执行,即串行执行,而asyncExecute是异步执行,即并行执行。
这里使用了回调函数来处理,但是入参有firstCallback和callback,其实是为了第一个任务走当前线程,第二个及以后的任务走线程池。
public final class ExecutorEngine implements AutoCloseable {
public <I, O> List<O> execute(final ExecutionGroupContext<I> executionGroupContext, final ExecutorCallback<I, O> firstCallback,
final ExecutorCallback<I, O> callback, final boolean serial) throws SQLException {
return serial ?
serialExecute(executionGroupContext.getInputGroups().iterator(), firstCallback, callback) :
parallelExecute(executionGroupContext.getInputGroups().iterator(), firstCallback, callback);
}
private <I, O> Collection<O> syncExecute(final ExecutionGroup<I> executionGroup, final ExecutorCallback<I, O> callback) throws SQLException {
return callback.execute(executionGroup.getInputs(), true, ExecutorDataMap.getValue());
}
private <I, O> Future<Collection<O>> asyncExecute(final ExecutionGroup<I> executionGroup, final ExecutorCallback<I, O> callback) {
Map<String, Object> dataMap = ExecutorDataMap.getValue();
return executorServiceManager.getExecutorService().submit(() -> callback.execute(executionGroup.getInputs(), false, dataMap));
}
}
3、ConnectionMode:
在ShardingSphere中有两种连接模式,即MEMORY_STRICTLY和CONNECTION_STRICTLY,前者代表内存限制模式,后者则代表连接限制模式。
连接模式是ShardingSphere所提出的一个特有概念,背后体现的是一种设计上的平衡思想。
从数据库访问资源的角度来看,一方面需要对数据库连接资源的控制保护,避免数据库连接过多,一方面需要采用更优的归并模式达到对中间件内存资源的节省;如何处理好两者之间的关系,是ShardingSphere执行引擎需求解决的问题。为此,ShardingSphere提出了连接模式的概念。
举例来说,当采用内存限制模式时,对于同一数据源,如果有10张分表,那么执行时会获取10个连接并进行并行执行;而当采用连接限制模式时,执行过程中只会获取1个连接而进行串行执行,并在内存中进行后续处理。
具体采用哪种连接模式,是根据路由引擎所产生的的SqlUnits数来判断的,即按照每个数据库连接所需执行的SQL数来判断,如果每个数据库连接执行的SQL大于1,则使用内存模式,如果小于等于1,则使用限制模式。
public enum ConnectionMode {
MEMORY_STRICTLY, CONNECTION_STRICTLY
}
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;

4、QueryResult
执行结果是 JDBC 的 QueryResult,代码如下。
public interface QueryResult {
boolean next() throws SQLException;
Object getValue(int columnIndex, Class<?> type) throws SQLException;
......
}
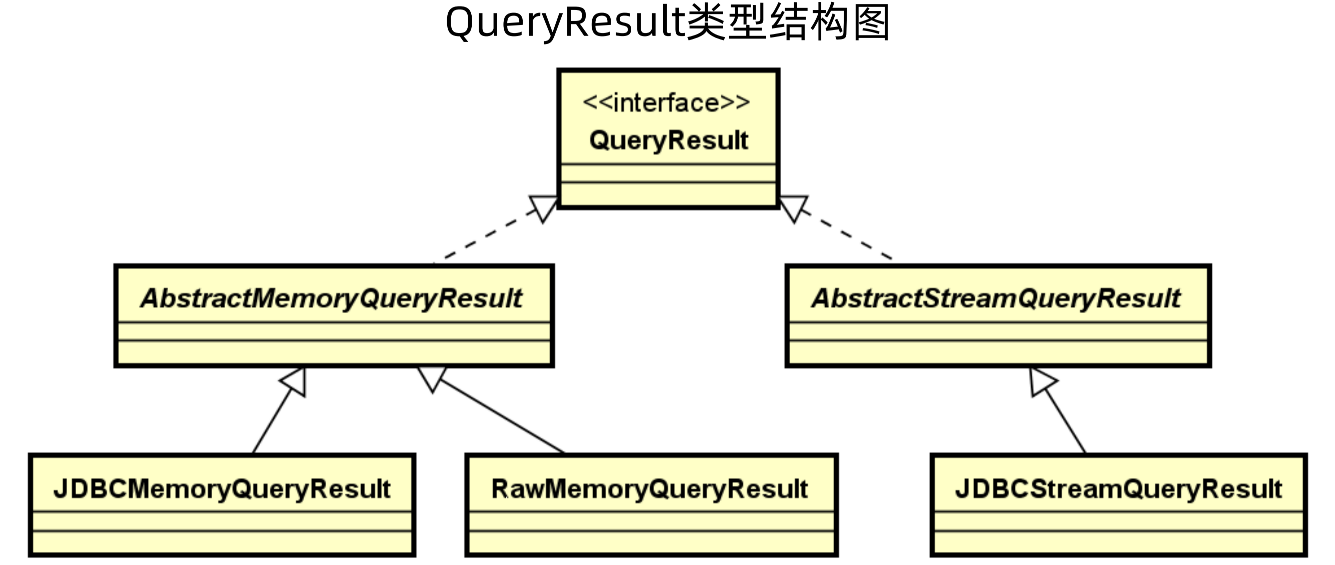
QueryResult 类型结构图如下所示,首先是QueryResult接口,然后有两个抽象类AbstractMemorYQueryResult和AbstractStreamQueryResult,其中AbstractMemorYQueryResult表示结果通过内存一次性处理完成,而AbstractStreamQueryResult表示通过流的方式一点点获取处理。
以 JDBCStreamQueryResult为例,其封装了 JDBC 原生的ResultSet,在 next 方法和 getValue 方法都是通过原生 ResultSet的API进行处理。
public final class JDBCStreamQueryResult extends AbstractStreamQueryResult {
@Getter
private final ResultSet resultSet; // 封装JDBC ResultSet
public JDBCStreamQueryResult(final ResultSet resultSet) throws SQLException {
super(new JDBCQueryResultMetaData(resultSet.getMetaData()));
this.resultSet = resultSet;
}
@Override
public boolean next() throws SQLException {
return resultSet.next();
}
@Override
public Object getValue(final int columnIndex, final Class<?> type) throws SQLException {
if (boolean.class == type) {
return resultSet.getBoolean(columnIndex);
} else if (byte.class == type) {
return resultSet.getByte(columnIndex);
}
......
}
}
5、ShardingSphereStatement
上面提到ShardingSphereStatement是执行引擎的入口,在其executeQuery方法中,流程如下:
创建sql:根据业务创建逻辑sql
创建执行器上下文:调用KernelProcessor根据逻辑sql获取ExecutionContext
执行sql并获取执行结果:通过DriverExecutor 执行查询
归并结果:使用归并引擎对结果进行归并
返回结果:返回使用ShardingSphereResultSet封装的结果
public class ShardingSphereStatement extends AbstractPreparedStatementAdapter {
private final DriverExecutor executor;
private final KernelProcessor kernelProcessor;
public ResultSet executeQuery(final String sql) throws SQLException {
ResultSet result;
try {
LogicSQL logicSQL = createLogicSQL(sql);
executionContext = createExecutionContext(logicSQL);
List<QueryResult> queryResults = executeQuery0();
MergedResult mergedResult = mergeQuery(queryResults);
result = new ShardingSphereResultSet(getShardingSphereResultSets(), mergedResult, this, executionContext);
}
......
return result;
}
private ExecutionContext createExecutionContext(final LogicSQL logicSQL) throws SQLException {
// 调用KernelProcessor获取ExecutionContext
return kernelProcessor.generateExecutionContext(logicSQL, metaDataContexts.getMetaData().getDatabases().get(connection.getDatabaseName()),
metaDataContexts.getMetaData().getProps());
}
private List<QueryResult> executeQuery0() throws SQLException {
StatementExecuteQueryCallback callback = new StatementExecuteQueryCallback()...
// 通过DriverExecutor 执行查询
return executor.getRegularExecutor().executeQuery(executionGroupContext, executionContext.getLogicSQL(), callback);
}
}
(六)归并引擎:
所谓归并,就是将从各个数据节点获取的多数据结果集,通过一定的策略组合成为一个结果集并正确的返回给请求客户端的过程。
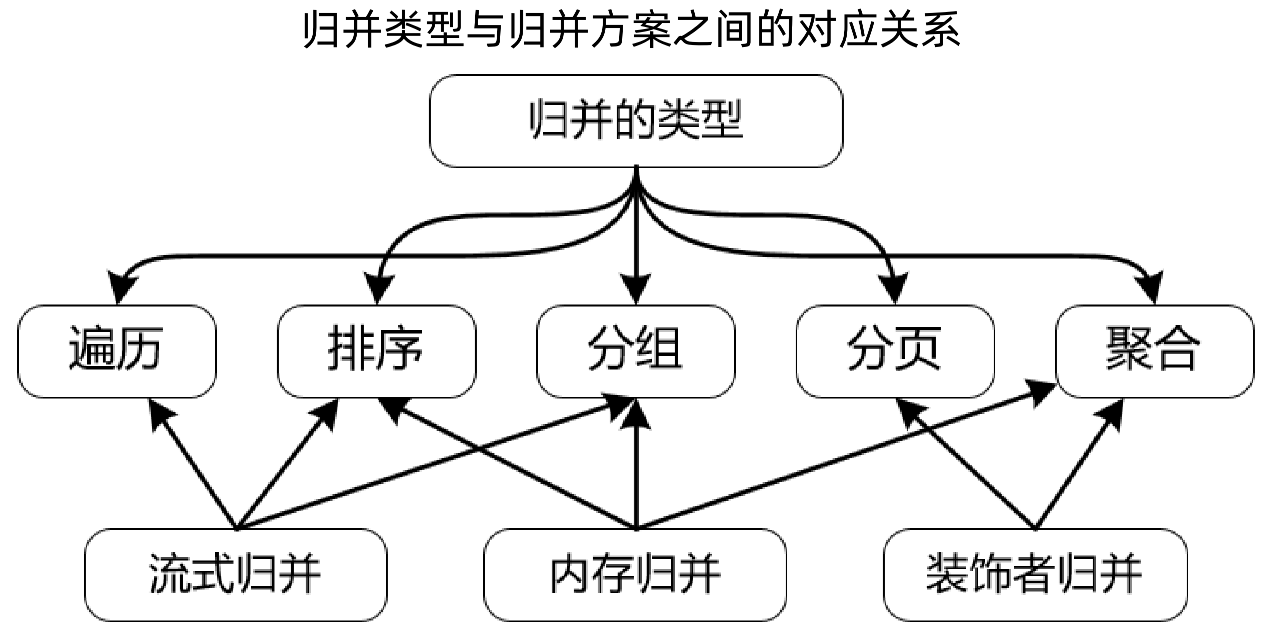
归并类型包括:遍历、排序、分组、分页、聚合
针对不同的归并类型,就需要采用不同的归并方案,理论如流式归并、内存归并、装饰着归并
上面提到在ShardingSphereStatement的executeQuery方法中,会调用mergeQuery方法做归并,其实mergeQuery方法就在ShardingSphereStatement中,如下源码所示,在mergeQuery方法中,新建了一个归并引擎MergeEngine,然后调用归并引擎的merge方法进行归并。
在MergeEngine类中,其调用了ResultMerger的merge方法进行归并。
ResultMerger是一个接口,具体的归并逻辑由不同的归并类型实现类来处理。
public class ShardingSphereStatement extends AbstractPreparedStatementAdapter {
private MergedResult mergeQuery(final List<QueryResult> queryResults) throws SQLException {
MergeEngine mergeEngine = new
MergeEngine(metaDataContexts.getMetaData().getDatabases().get(connection.getDatabaseName()),
metaDataContexts.getMetaData().getProps());
return mergeEngine.merge(queryResults, executionContext.getSqlStatementContext());
}
}
public final class MergeEngine {
private Optional<MergedResult> executeMerge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext) throws
SQLException {
for (Entry<ShardingSphereRule, ResultProcessEngine> entry : engines.entrySet()) {
if (entry.getValue() instanceof ResultMergerEngine) {
ResultMerger resultMerger = ...
return Optional.of(resultMerger.merge(queryResults, sqlStatementContext, database));
}
}
return Optional.empty();
}
}
// 通过ResultMerger执行归并
public interface ResultMerger {
MergedResult merge(List<QueryResult> queryResults, SQLStatementContext<?> sqlStatementContext, ShardingSphereDatabase
database) throws SQLException;
}
以排序归并为例,共查询三张表,归并过程如下所示:
排序归并示例步骤一:每一张表都有序

排序归并示例步骤二:队列指向值最大的表,并将三个结果按第一条数据从大到小做个指向
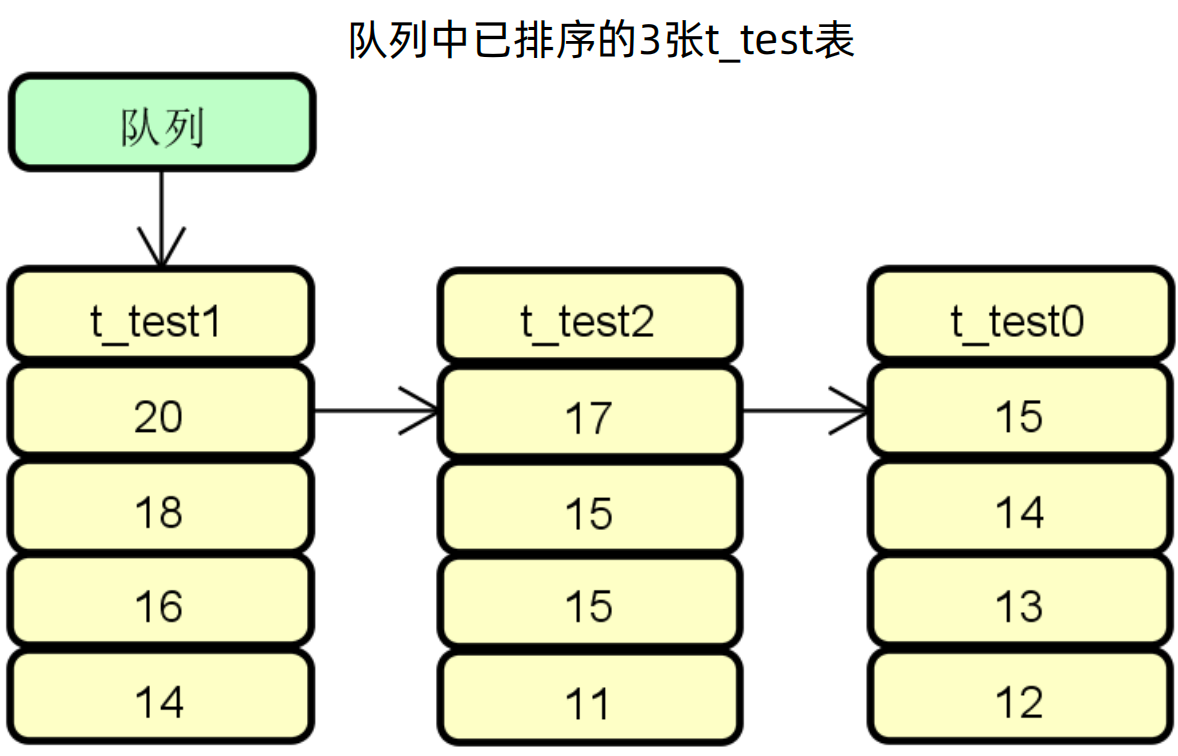
排序归并示例步骤三:将最大的数据放入队列,然后重新指向最大值的表,结果集之前的指向重新设置
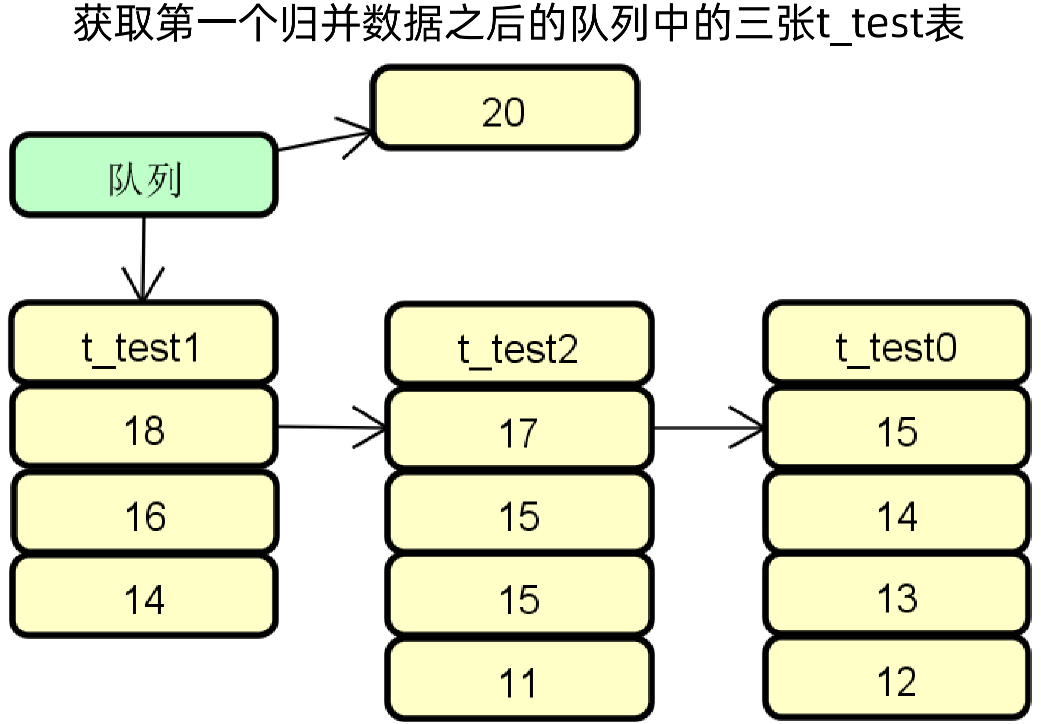
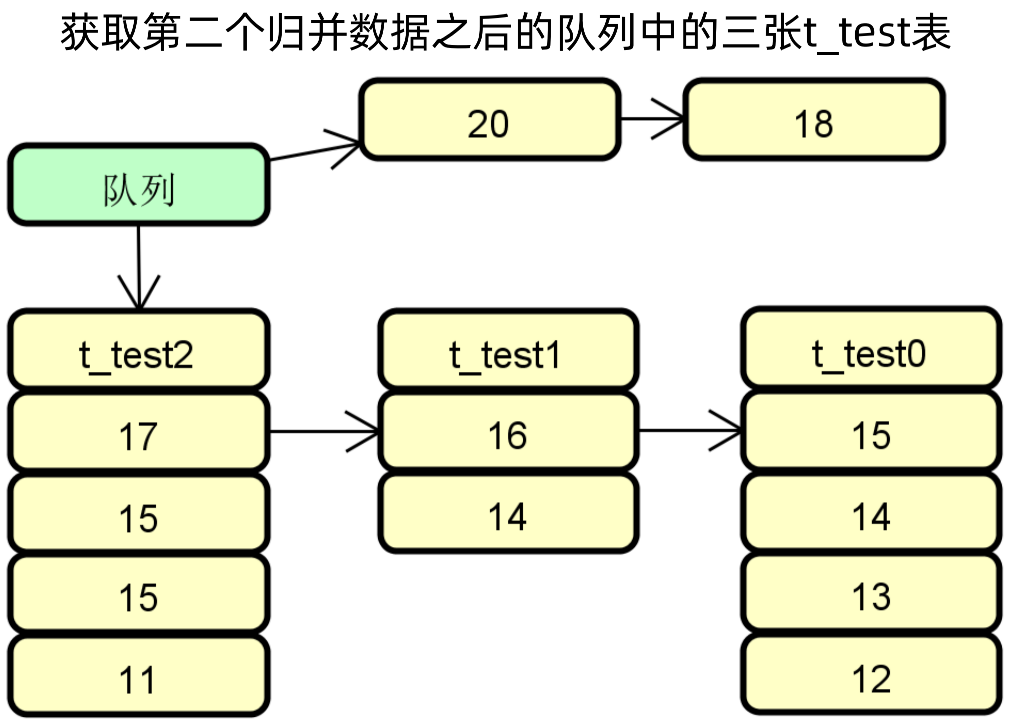
排序归并示例步骤四:将最大的数据放入队列,然后重新指向最大值的表,结果集之前的指向重新设置
排序归并代码示例:
首先构建一个优先级队列PriorityQueue,然后初始化该队列。
初始化时,循环所有的结果集,构建一个排序的结果集OrderByValue,通过offer方法放入优先级队列,最后通过peek方法从优先级队列中一个一个获取全部数据并封装到最终的结果集中。
而在next方法中,会获取PriorityQueue中的第一个元素,并弹出该元素;然后将游标指向firstOrderByValue的下一个元素,并重新插入到PriorityQueue中,这会促使PriorityQueue进行自动的重排序;最后将当前结果集指向PriorityQueue的第一个元素。
public class OrderByStreamMergedResult extends StreamMergedResult {
private final Queue<OrderByValue> orderByValuesQueue;
public OrderByStreamMergedResult(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext, final
ShardingSphereSchema schema) throws SQLException {
orderByItems = selectStatementContext.getOrderByContext().getItems();
//构建PriorityQueue
orderByValuesQueue = new PriorityQueue<>(queryResults.size());
//初始化PriorityQueue
orderResultSetsToQueue(queryResults, selectStatementContext, schema);
isFirstNext = true;
}
private void orderResultSetsToQueue(final List<QueryResult> queryResults) throws SQLException {
for (QueryResult each : queryResults) {
//构建OrderByValue
OrderByValue orderByValue = new OrderByValue(each, orderByItems);
if (orderByValue.next()) {
//添加OrderByValue到队列中
orderByValuesQueue.offer(orderByValue);
}
}
setCurrentQueryResult(orderByValuesQueue.isEmpty() ? queryResults.get(0) :
orderByValuesQueue.peek().getQueryResult());
}
@Override
public boolean next() throws SQLException {
if (orderByValuesQueue.isEmpty()) {
return false;
}
if (isFirstNext) {
isFirstNext = false;
return true;
}
//获取PriorityQueue中的第一个元素,并弹出该元素
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
//将游标指向firstOrderByValue的下一个元素,并重新插入到PriorityQueue中,这会促使PriorityQueue进行自动的重排序
if (firstOrderByValue.next()) {
orderByValuesQueue.offer(firstOrderByValue);
}
if (orderByValuesQueue.isEmpty()) {
return false;
}
//将当前结果集指向PriorityQueue的第一个元素
setCurrentQueryResult(orderByValuesQueue.peek().getQueryResult());
return true;
}
}
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号