
04-分布式服务
一、分布式服务体系
(一)分布式系统概述
单体系统存在业务扩展性(任何业务的调整都需要发布整个系统)、性能扩展性(动态扩容对单体系统而言效率低下)、代码复杂度(修改一处代码容易引发连锁反应)的问题。
系统扩展性,指的是当系统的业务需求发生变化时,我们对现在系统改动程度的一种控制能力。改动程度越大,扩展性就越差。对于单体系统而言,任何改动都需要整个系统进行重新构建和发布,所以扩展性较低,本质原因是无法对代码进行物理上的拆分,所以代码组件之间的边界往往很难清晰划分。
伸缩性,指的是对系统性能的一种控制能力。如果通过简单扩容就能确保系统的性能得到等比例的提升,那么我们就认为该系统具备较好的伸缩性。对于单体系统而言,由于内存密集型和CPU密集型的代码都位于同一个服务器上,所以很难做到对资源的充分利用。
分布式系统区别于单体系统的是,会将整个系统拆分成多个能够独立运行的服务,这些服务在物理上是隔离的,相互之间基于网络进行通信和协调。
单体系统的拆分策略:
纵向拆分:基于不同的业务拆分,例如互联网医院系统,可以拆分为医生子系统、就诊子系统、患者子系统、处方服务
横向拆分:复用和组合业务能力,仍以互联网医院系统为例,拆分为医生子系统、就诊子系统、患者子系统、处方服务,前台使用分布式服务框架进行聚合。
分布式系统固有特性,也是分布式存在的问题:
网络传输的三态性:“成功”或“失败”、“超时”,区别与单体系统调用只有成功或失败,由于有了网络调用,因此存在超时的问题
请求的容错性:调用链路上的异常扩散,雪崩效应
系统的异构性:多种不同的技术体系
数据的一致性:传统的事务机制无法生效
(二)构建分布式服务体系
分布式系统核心技术点:
可用:降级和限流机制、集群和负载均衡等
性能:异步化、资源重用等
扩展:SPI机制、异步消息等
治理:服务注册和发现机制等
分布式服务体系的组成包括功能性组件和非功能性组件,功能性组件是指必须要有的,如果没有就不能正常运行,包括网络通信、序列化、传输协议、服务调用;非功能性组件包括服务治理、服务路由、服务容错、服务监控。
分布式服务框架有:Facebook Thrift、Twitter Finagle、Google gRPC、Alibaba Dubbo、Taobao HSF、Xinlang Motan
分布式服务拆封后一般有三种类型:
工具服务(Utility Service):应用程序与技术基础设施之间的交叉点;遵循独立开发和管理生命周期;也是可重用服务,区别业务模型 ,例如分布式ID服务、加密算法服务等等
实体服务(Entity Service):无关功能上下文 ,主例如订单服务,只处理订单的增删改查;建立一种一致的方法访问和处理业务数据;可重用,一般被更高级的任务服务使用。
任务服务(Task Service):非无关功能上下文,服务组合,例如下单服务,最终要调用订单、支付等服务;关注实现复杂业务流程,很大程度上由组合逻辑组成;通常需要维护状态,决定事务边界。
(三)客服系统案例演进
服务拆分策略 - 第一阶段:将项目拆分为客户服务、集成服务和其他模块,集成服务专门用来集成外包客服服务,最终的拆分结果为:
distribution-cs-dependency:仍然是一个用来做同一版本依赖管理的项目
distribution-customer-system:只保留定时任务和监控
distribution-cs-infrastructure-utility:同一工具服务
distribution-outsouring-system:外包客服系统
以上都是和单体系统一样的,下面几个事新拆出来的
distribution-customer-service:承载原distribution-customer-system项目中所有的MVC操作,通知调用distribution-intergation-service获取外部数据
distribution-intergation-service:承载原distribution-customer-system项目中bus操作,即服务集成的通用流程操作
二、RPC架构
(一)RPC架构基础结构和示例
RPC:Remote Process Call,远程过程调用,一切分布式系统的基础,包含分布式系统基本功能组件:网络通信、序列化/反序列化、传输协议和服务调用。
对于RPC来讲,主要就是通过一种协议做远程调用,下图展示的就是一个极简版的RPC,服务端使用RpcAcceptor接收服务调用,客户端使用RpcConnector做服务连接,然后客户端和服务端使用相同的协议(RpcProtocol)进行交互。
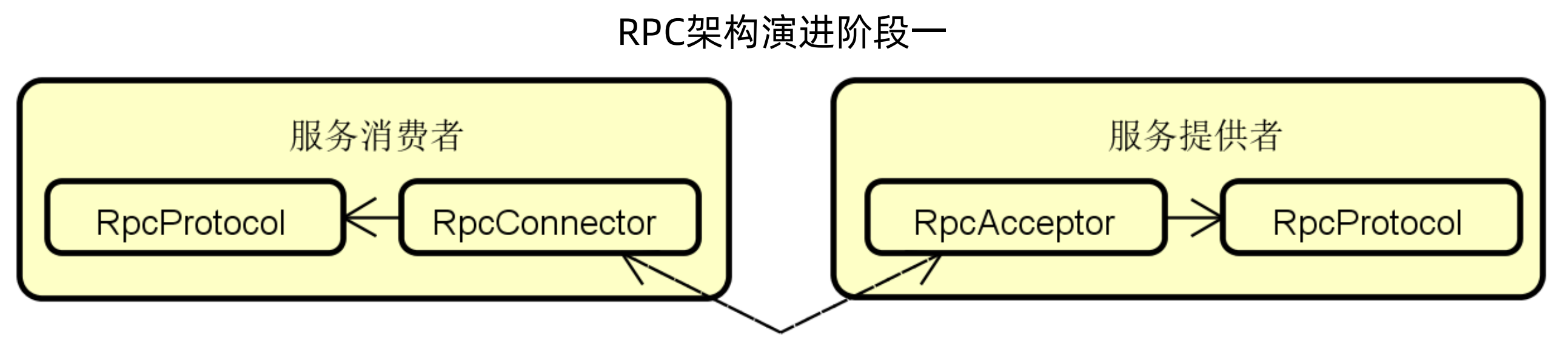
但是这样的结构还不够详细,具体RpcConnector和RpcAcceptor是怎么处理的,下图是一个演进的结果,首先在RPC框架的两端,都是通过API进行调用的,在客户端,使用RpcClient使用Caller调用API,然后API使用RpcCaller调用RpcConnector,在服务端,RpcAcceptor通过RpcInvoker调用API,然后API通过Callee调用RpcServer,即调用实现。同时客户端和服务端有一个相同的协议来保证通信。
对于API、Caller、Callee来说,是使用接口的方式抽离出去的,其他的则是在客户端或服务端需要实现的。
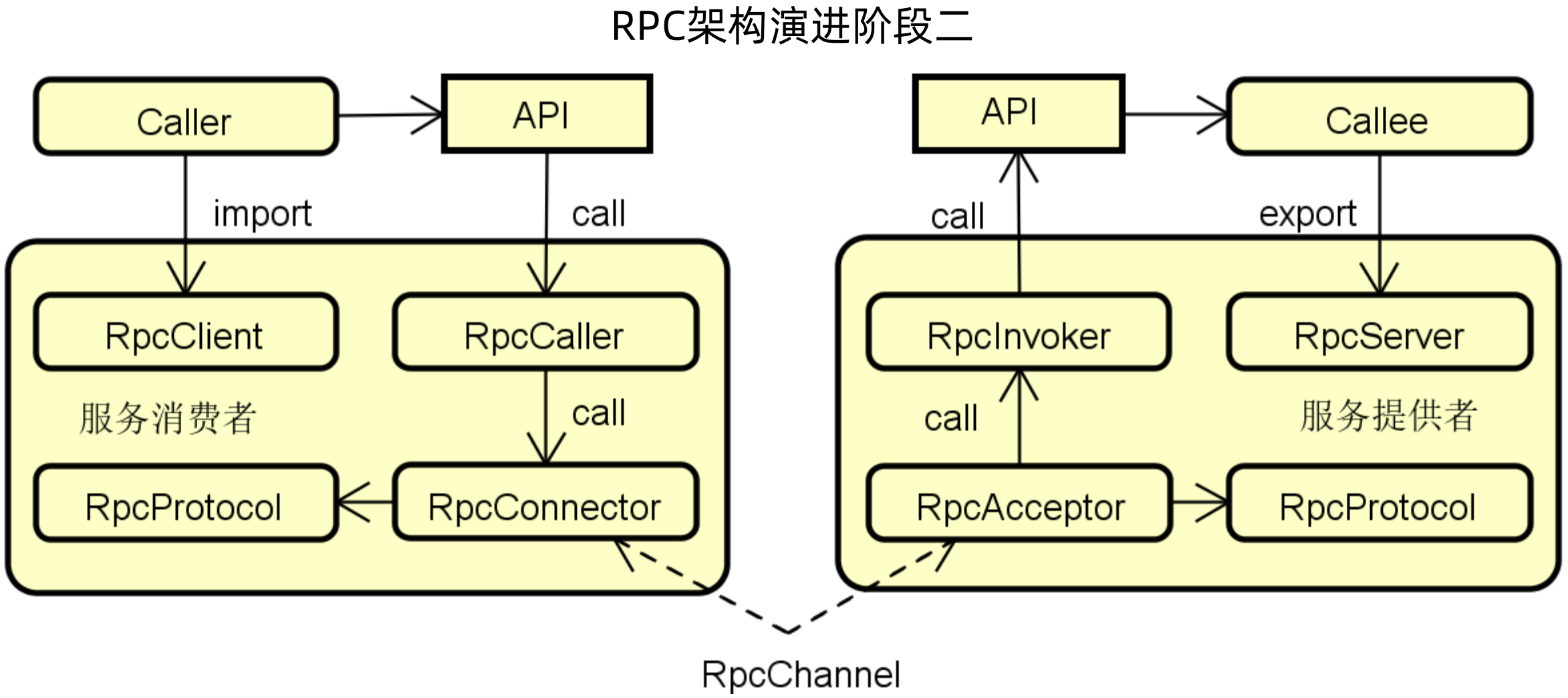
演进二虽然已经实现了RPC框架的基本功能,但是对于客户端来说,不想知道远程调用的IP等内容,那么可以加入RpcProxy来进行代理,并通过代理调用RpcCaller;服务端为了使用多线程等技术来提高性能,增加RpcProcessor,并用其调用RpcInvoker。
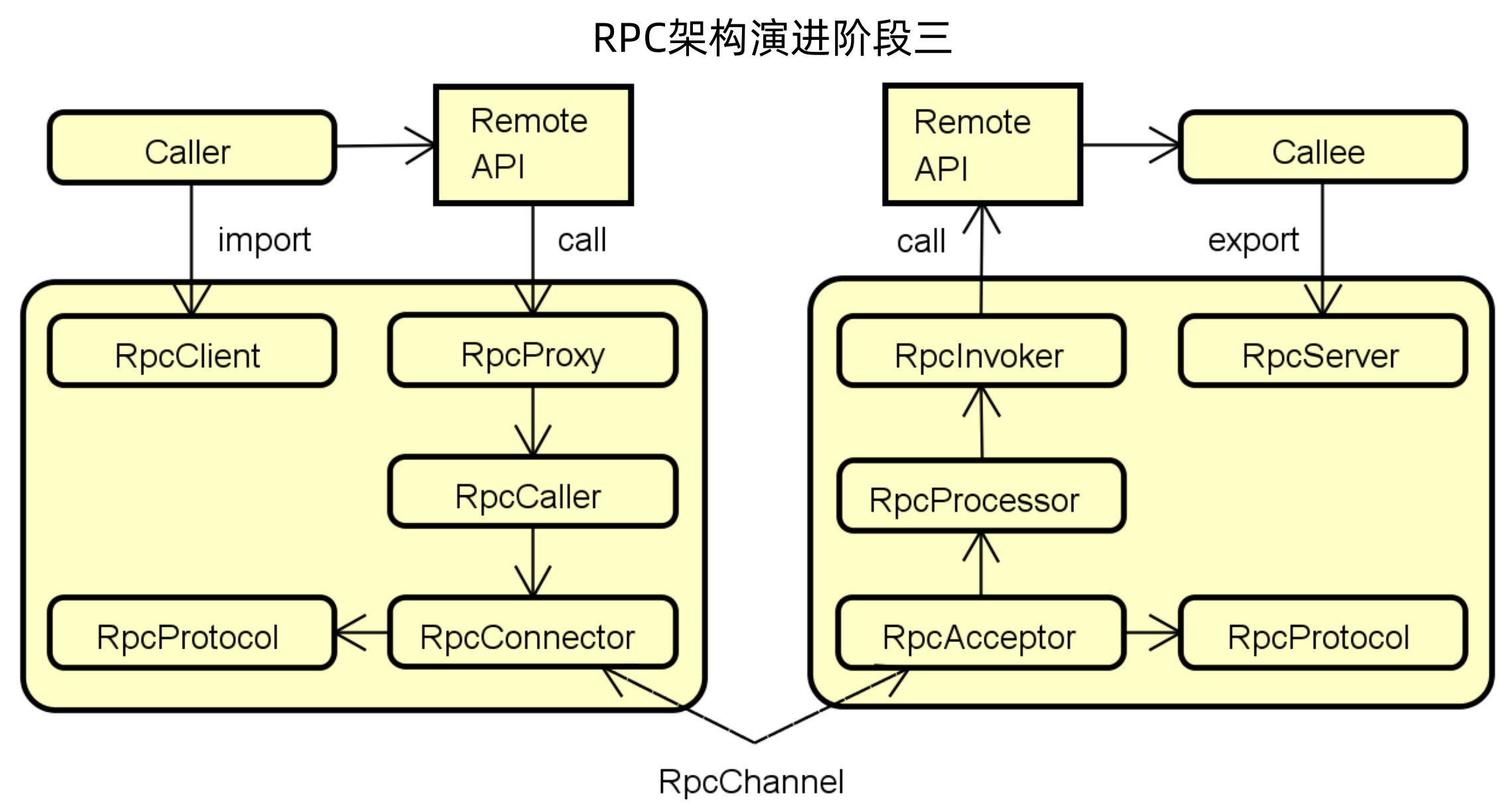
以上演进的最终结果就是RPC规范,目前所有的RPC框架都是基于以上规范做的实现和落地。那么RPC规范包含了10个组件,每个组件的作用稍微做个介绍。
RPC – 客户端组件与职责:
RpcClient:负责导入(import)远程接口的代理实现
RpcProxy:调用远程接口的代理实现
RpcCaller:负责编码和发送调用请求到服务端并等待结果
RpcConnector:负责维持连接通道和发送数据到服务端
RPC – 服务端组件与职责:
RpcServer:负责导出(export)远程接口
RpcInvoker:负责调用服务端接口的具体实现并返回结果
RpcAcceptor:负责接收客户端请求并返回请求结果
RpcProcessor:负责在服务端控制调用过程,包括管理调用线程池等
RPC – 通用组件与职责:
RpcProtocol:负责协议的编/解码
RpcChannel:充当数据传输的通道
针对上述组件,可以实现一个自定义的RPC架构:
Remote API:对于远程调用来说,使用UserService作为Remote API,提供一个简单的查询接口。
public interface UserService {
String getUserNameByCode(String code);
}
RpcProtocol:协议通俗的将就是通信双方约定好的规则,这里简单的定义了一个协议,传输时需要传递接口全限定名、方法名、参数类型和参数值
@Data
public class Protocol implements Serializable {
//接口名称(包括完整类路径)
private String interfaceName;
//调用方法名
private String methodName;
//参数类型按照接口参数顺序定义
private Class[] paramsTypes;
//参数的数据值
private Object[] parameters;
public Protocol() {
super();
}
public Protocol(String interfaceName, String methodName, Class[] paramsTypes, Object[] parameters) {
super();
this.interfaceName = interfaceName;
this.methodName = methodName;
this.paramsTypes = paramsTypes;
this.parameters = parameters;
}
}
RpcChannel:RpcChannel是Rpc通信的通道,这里使用 TCP Socket 来发送和接收信息。
服务端:
RpcAcceptor表示接收接受Socket请求,下面代码的service方法创建了一个ServerSocket,并使用其来接收请求,这里的ServerSocket就是上面的RpcChannel
RpcProcessor表示线程/服务池调度,在RpcAcceptor接收到请求后,其并不会自己处理请求,而是会将请求交由RpcProcessor来处理,RpcProcessor可以管理调用线程等,在下面案例中,其将请求放到线程池中进行处理
RpcInvoker表示反射响应请求,根据反射来获取具体实现,具体的实现在UserserviceImpl类中,其实现了Userservice接口。
@Data
public class RpcServer {
// 自定义线程池相关内容
private int threadSize = 10;
private ExecutorService threadPool;
//自定义缓存
private Map<String, Object> servicePool;
// 自定义端口
private int port = 9000;
public RpcServer(){
super();
synchronized (this){
threadPool = Executors.newFixedThreadPool(threadSize);
}
}
public RpcServer(Map<String, Object> servicePool, int threadSize, int port) {
super();
this.port = port;
this.servicePool = servicePool;
synchronized (this){
threadPool = Executors.newFixedThreadPool(threadSize);
}
}
public void service() throws IOException {
ServerSocket serverSocket = new ServerSocket(port);
// 执行请求
while (true){
Socket receiveSocket = serverSocket.accept();
final Socket socket = receiveSocket;
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
// 处理请求
process(socket);
socket.close();
} catch (IOException | ClassNotFoundException | InvocationTargetException | NoSuchMethodException | IllegalAccessException | InstantiationException e) {
e.printStackTrace();
}
}
});
}
}
// 处理请求
private void process(Socket socket) throws IOException, ClassNotFoundException, InvocationTargetException, NoSuchMethodException, IllegalAccessException, InstantiationException {
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
Protocol protocolMessage = (Protocol) objectInputStream.readObject();
Object result = call(protocolMessage);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
objectOutputStream.writeObject(result);
objectOutputStream.close();
}
//3.执行方法调用:RpcInvoker
private Object call(Protocol protocol) throws ClassNotFoundException, NoSuchMethodException,
IllegalAccessException, InstantiationException, InvocationTargetException {
if(servicePool == null) {
synchronized (this) {
servicePool = new HashMap<String, Object>();
}
}
//通过接口名称构建实现类
String interfaceName = protocol.getInterfaceName();
Class<?> serviceClass = Class.forName(interfaceName);
Object service = servicePool.get(interfaceName);
//判断servicePool对象是否存在,如果不存在,就创建新对象并放入池中
if(service == null) {
synchronized (this) {
service = serviceClass.newInstance();
servicePool.put(interfaceName, service);
}
}
//通过实现类来构建方法
Method method = serviceClass.getMethod(protocol.getMethodName(), protocol.getParamsTypes());
//通过反射来实现方法的执行
Object result = method.invoke(service, protocol.getParameters());
return result;
}
public class UserserviceImpl implements UserService {
private Map<String, String> userMap = new HashMap();
public UserserviceImpl(){
userMap.put("1", "lcl1");
userMap.put("2", "lcl2");
userMap.put("3", "lcl3");
userMap.put("4", "lcl4");
}
@Override
public String getUserNameByCode(String code) {
return userMap.get(code);
}
}
客户端:
RpcProxy表示代理,未实现
RpcCaller:组装请求并发送
RpcConnector:发送Socket请求
public class RpcClient {
private String serverAddress;
private int serverPort;
public RpcClient(String serverAddress, int serverPort) {
this.serverAddress = serverAddress;
this.serverPort = serverPort;
}
//RpcConnector + RpcInvoker
@SuppressWarnings("resource")
public Object sendAndReceive(Protocol protocol) {
Object result = null;
try {
Socket socket = new Socket(serverAddress, serverPort);
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
objectOutputStream.writeObject(protocol);
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
result = objectInputStream.readObject();
} catch (UnknownHostException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return result;
}
}
(二)RPC架构核心组件 - 网络通信
网络通信可以分为网络连接和IO模型。
网络连接分为长连接和短连接,长链接是TCP连接建立后,可以连续发送多个数据包,优点是节省资源/时延较小;短连接是TCP连接建立后,数据包传输完成即关闭连接,优点是结构简单。RPC框架为了追求性能,常用长连接进行通信
IO模型可以分为BIO、NIO、AIO,其中BIO是同步阻塞的IO模型,NIO是同步非阻塞的IO模型,NIO模型依赖与操作系统的I/O多路复用技术,如select、poll、epoll模型等,多路复用是使用reactor模式来实现的。AIO是异步非阻塞的IO模型。
(三)RPC架构核心组件 - 序列化
序列化概念和方式:
序列化:将对象转化为字节数组,用于网络传输、数据持久化或其他用途
反序列化:把从网络、磁盘等读取的字节数组还原成原始对象,以便后续业务逻辑操作
序列化和反序列化可以使用文本类序列化和二进制序列化两大类:
文本类是可读的,例如XML和 JSON
二进制类是不可读的,例如 Protocol Buffer 和 Thrift
序列化怎么选择:
(1) 跨语言支持:
异构系统就可能需要跨语言,常见的跨语言支持序列化工具:Hession、Protocol Buffer、Thrift、Avro
要做跨语言,就要牺牲某些语言的特性(其他语言没有的特性),例如是否支持泛型、是否支持Map/List等
另外就是接口开发友好性,例如是否需要中间语言,由于是跨语言,因此要先生成中间语言,然后再生成序列化文件,例如Protocol Buffer需要.proto文件、Thrift需要.thrift中间语言,这种是对开发不友好的。
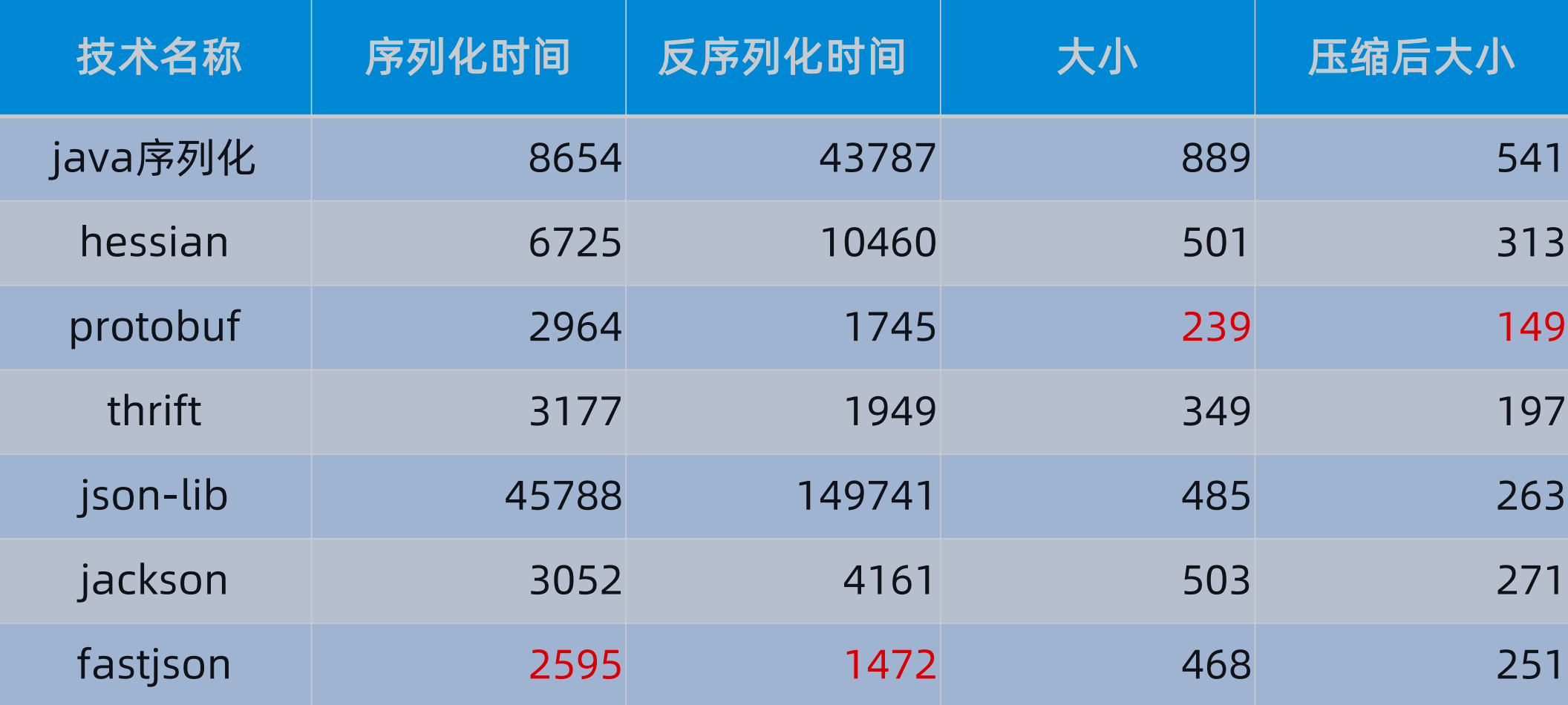
(2)性能:
性能主要从性能和空间两个维度来看,性能好就代表序列化和反序列化的时间,空间是指压缩的比例,压缩性能越好,压缩后占用的空间就越小,那么对于网络传输来说就更快。
Java领域序列化工具对比:https://github.com/eishay/jvm-serializers
(四)RPC架构核心组件 - 传输协议
通常在RPC框架中,为了性能和框架的扩展性,会自定义一些更合理的协议;主流的HTTP协议虽然很通用,通用的协议为了满足各个场景,会把各种东西都要兼容,复杂度就会很高,性能也不会很好,扩展性也不会很好。
自定义协议主要考虑的是性能和扩展性,切入点有以下几个:
1、自定义协议的通信模型和消息定义,也就是传输的消息本身是可以定制的
2、支持点对点长连接通信
3、使用NIO模型进行异步通信
4、提供可扩展的编解码框架,支持多种序列化方式,例如可以同时支持Json、Protocol Buffer等
自定义协议 - 协议消息定义:
协议消息的定义实际上就是传输的消息体的定义,一般都是在原有七层网络模型上通过Header+Body的方式来定义消息内容,可以在每一层上加上自定义的消息头,消息头可以表示是否异步、序列化方式等等内容。
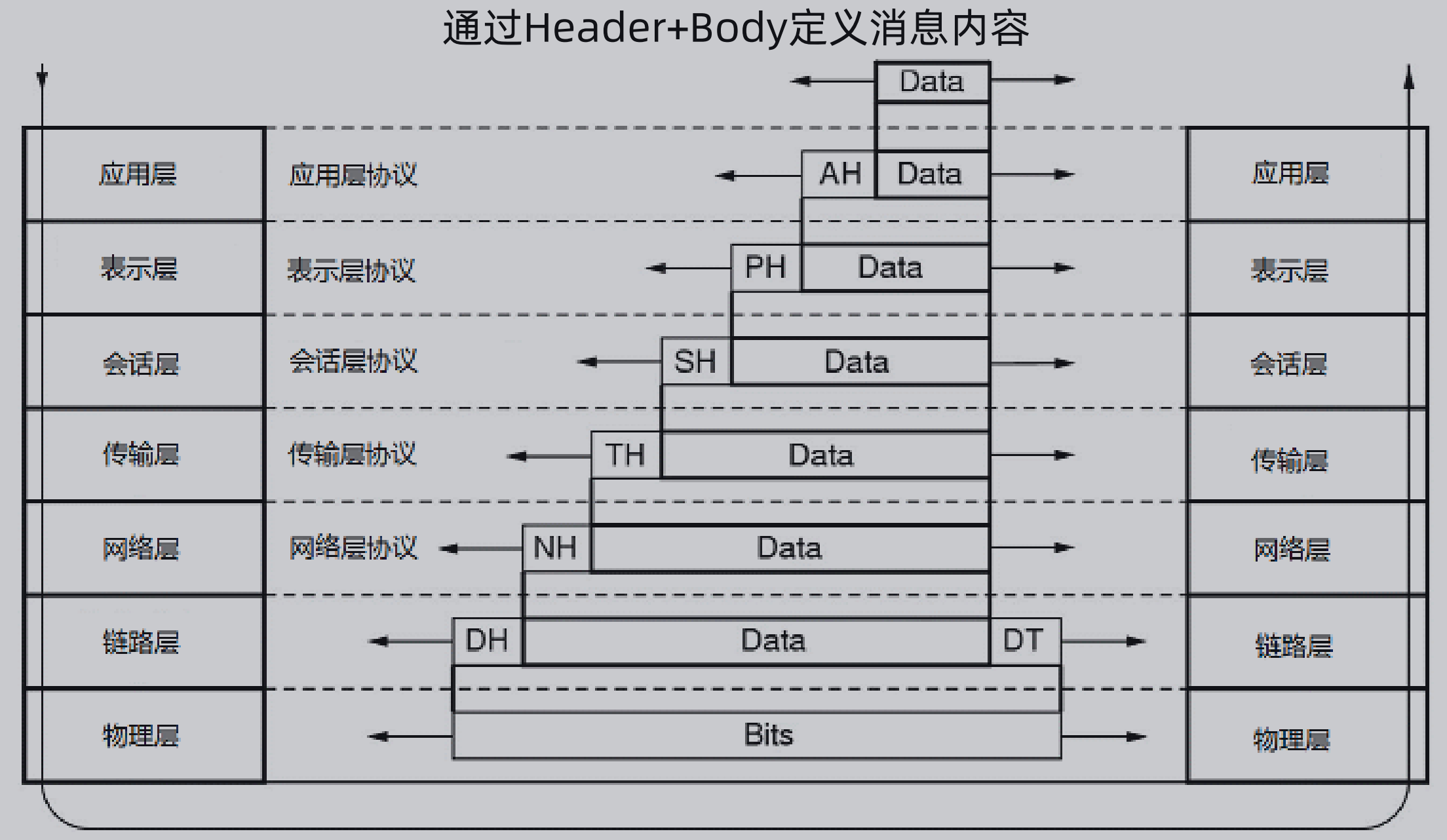
以Dubbo协议来说,网络层用的还是 IP,传输层用的还是 TCP,但是在会话层,使用了自定义的Dubbo协议,其定义了高位魔数、低位魔数、序列化id、同异步标志、状态、请求id、消息长度等。

RPC框架一般不会采用成熟的协议,因为要对性能和扩展上进行控制,同时也不会完全自己重写,因为重写的成本太高,一般会在原有的协议上进行修改。
(五)RPC架构核心组件 - 远程调用
服务调用基本方式可以分为同步调用和异步调用
服务调用扩展方式:
并行调用:多个任务不存在互相依赖管理,逻辑上可以并行执行。典型场景:工作流引擎。
泛化调用:提供泛化接口,对参数进行弱化,参数类型一般用Map,可以传输任何参数,不需要遵循 RPC 接口参数的定义,由于没有服务契约,所以要慎用。典型场景:测试集成。
三、使用Dubbo发布分布式服务
(一)引入Dubbo框架
Dubbo框架:高性能和透明化RPC实现方案,同时还是SOA服务治理方案
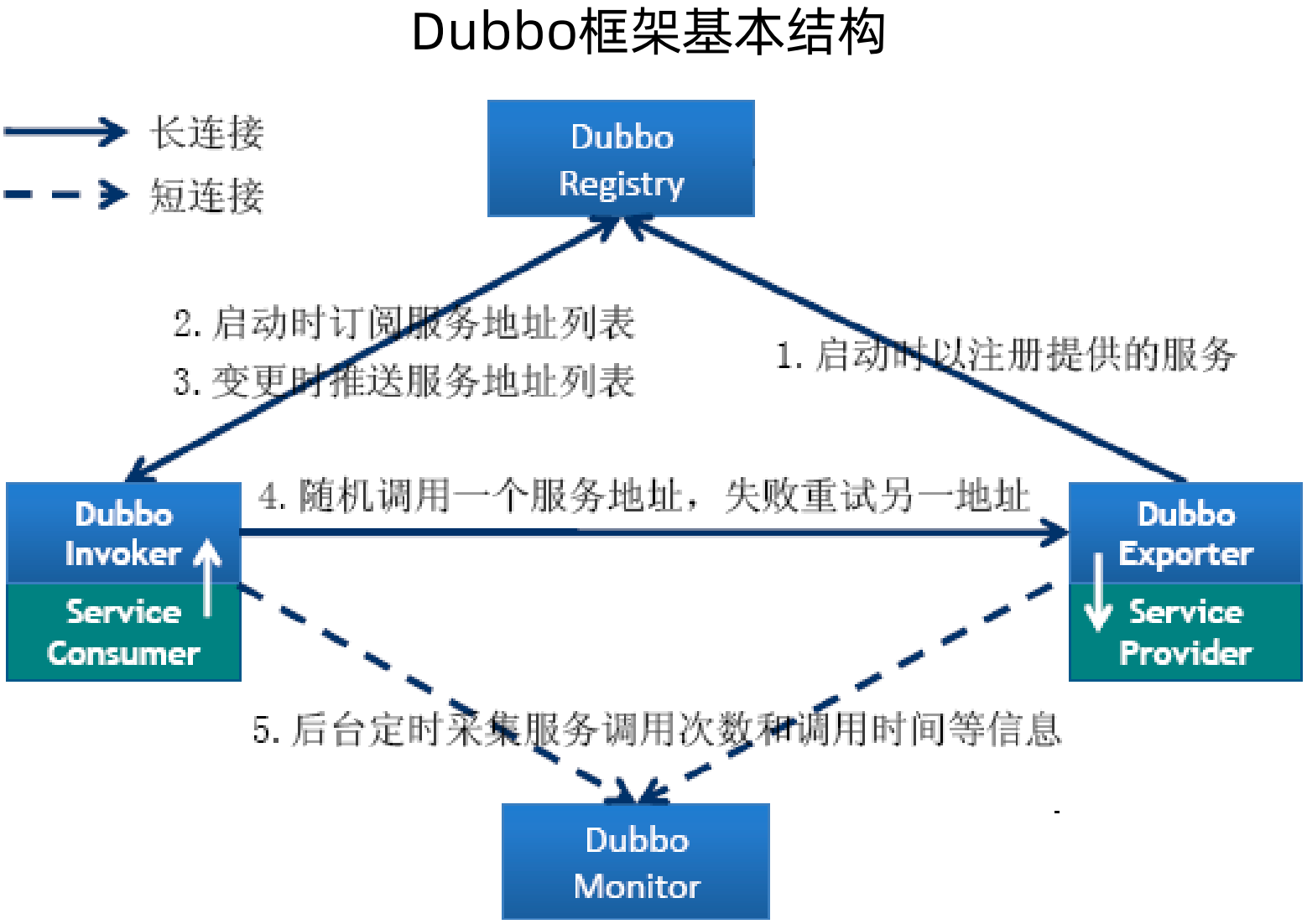
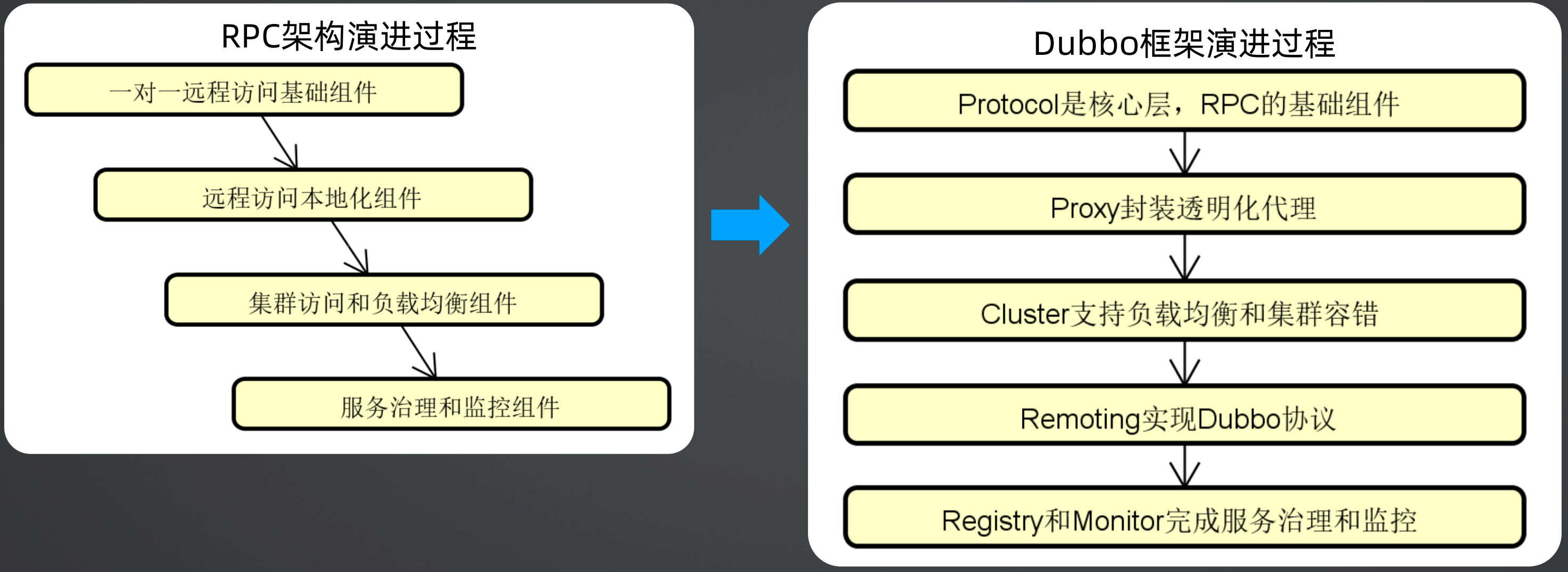
Dubbo框架RPC架构演进过程:
PRC 的基础就是一对一远程访问组件,在Dubbo中对应的是Protocol层,用来做远程调用
在客户端调用时像访问本地接口一样来访问远程接口,也就是远程访问本地化组件,在Dubbo中使用了Proxy做了代理封装
客户端要选择服务端的一个地址进行访问,也就是集群访问和负载均衡,Dubbo使用Cluster来支持负载均衡和集群容错
对于自定义协议,不是RPC所必须的,但是Dubbo基于性能和扩展的考虑,使用Remoting实现了Dubbo协议
对于服务治理和监控,Dubbo使用Registry和Monitor完成了服务治理和服务监控。
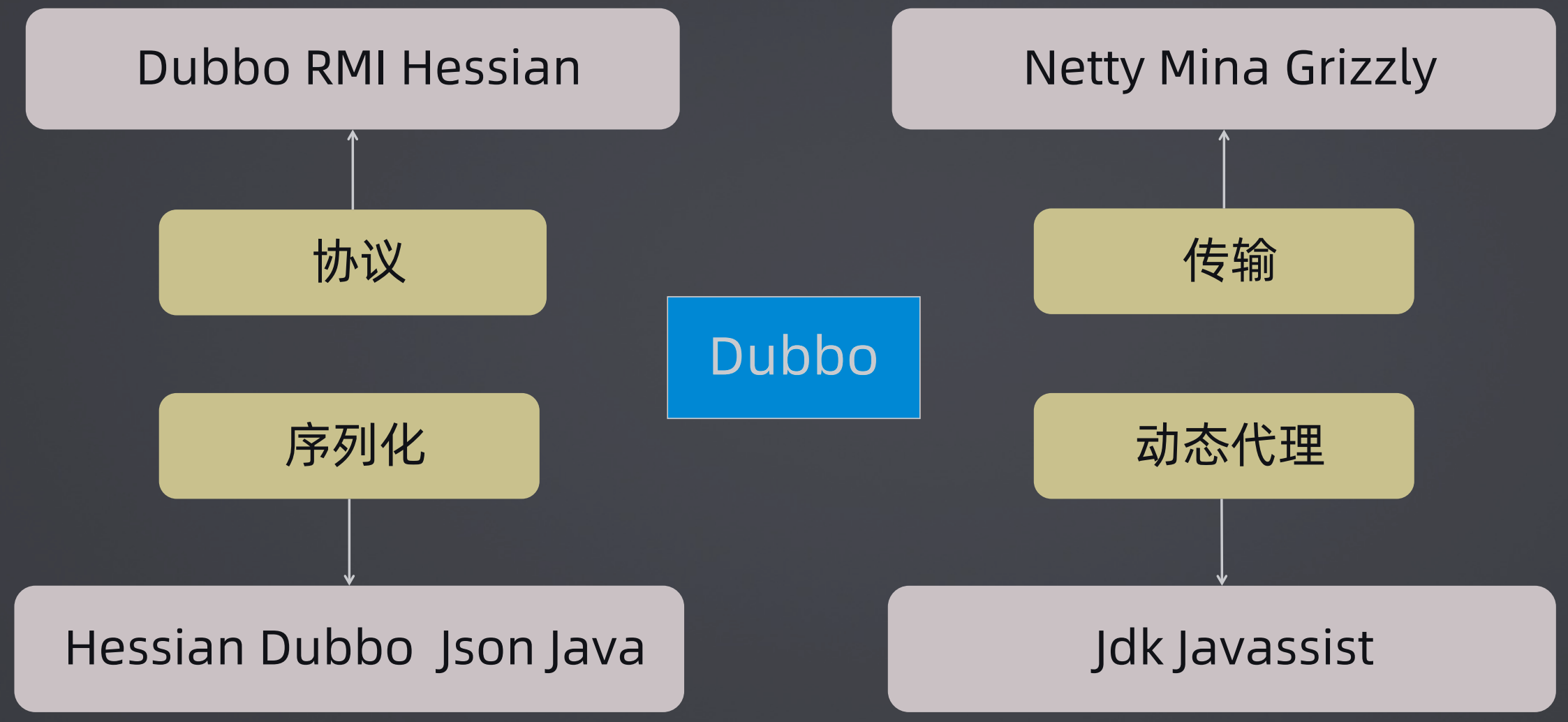
Dubbo中的RPC元素:
Dubbo没有限制只能使用某一种元素,都是可以替换的,例如协议可以使用Dubbo、RMI、Hessian等。
Dubbo开发方式:
XML配置方式:服务框架对业务代码零侵入,扩展和修改方便,配置信息修改实时生效
<dubbo:service/>:用于发布服务
<dubbo:reference/>:用于引用服务
<dubbo:protocol/> :用于指定传输协议
<dubbo:application/> :用于指定应用程序
<dubbo:registry/>:用于指定注册中心
注解方式:服务框架对业务代码零侵入,扩展和修改方便,修改配置需要重新编译代码
@EnableDubbo:启用Dubbo
@DubboService:服务发布
@DubboReference:服务引用
API方式:对业务代码侵入性强,容易与某种具体服务框架绑定,修改之后需要重新编译代码
DubboBootstrap:启动Dubbo
ServiceConfig:服务发布配置
ReferenceConfig:服务引用配置
(二)Dubbo框架服务发布机制
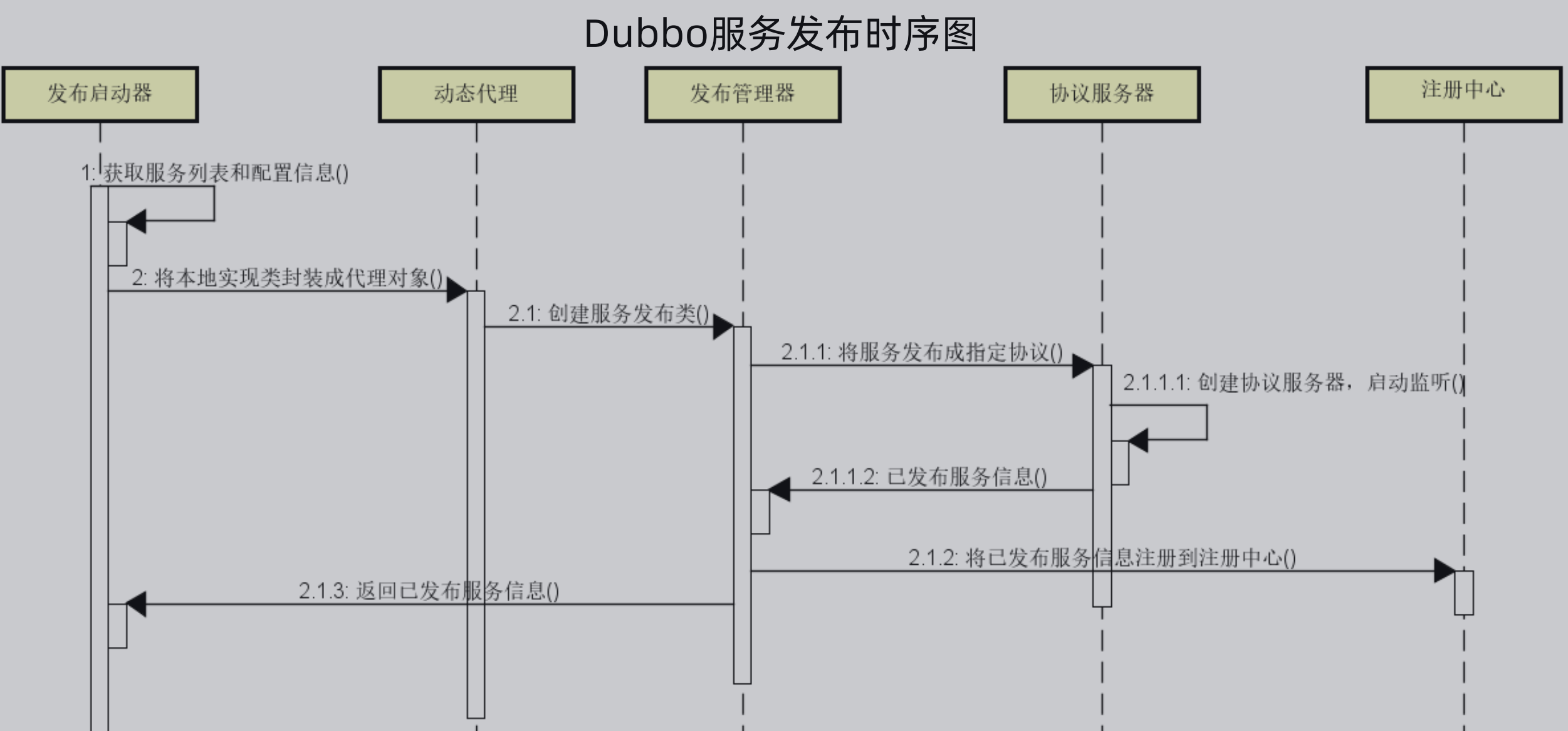
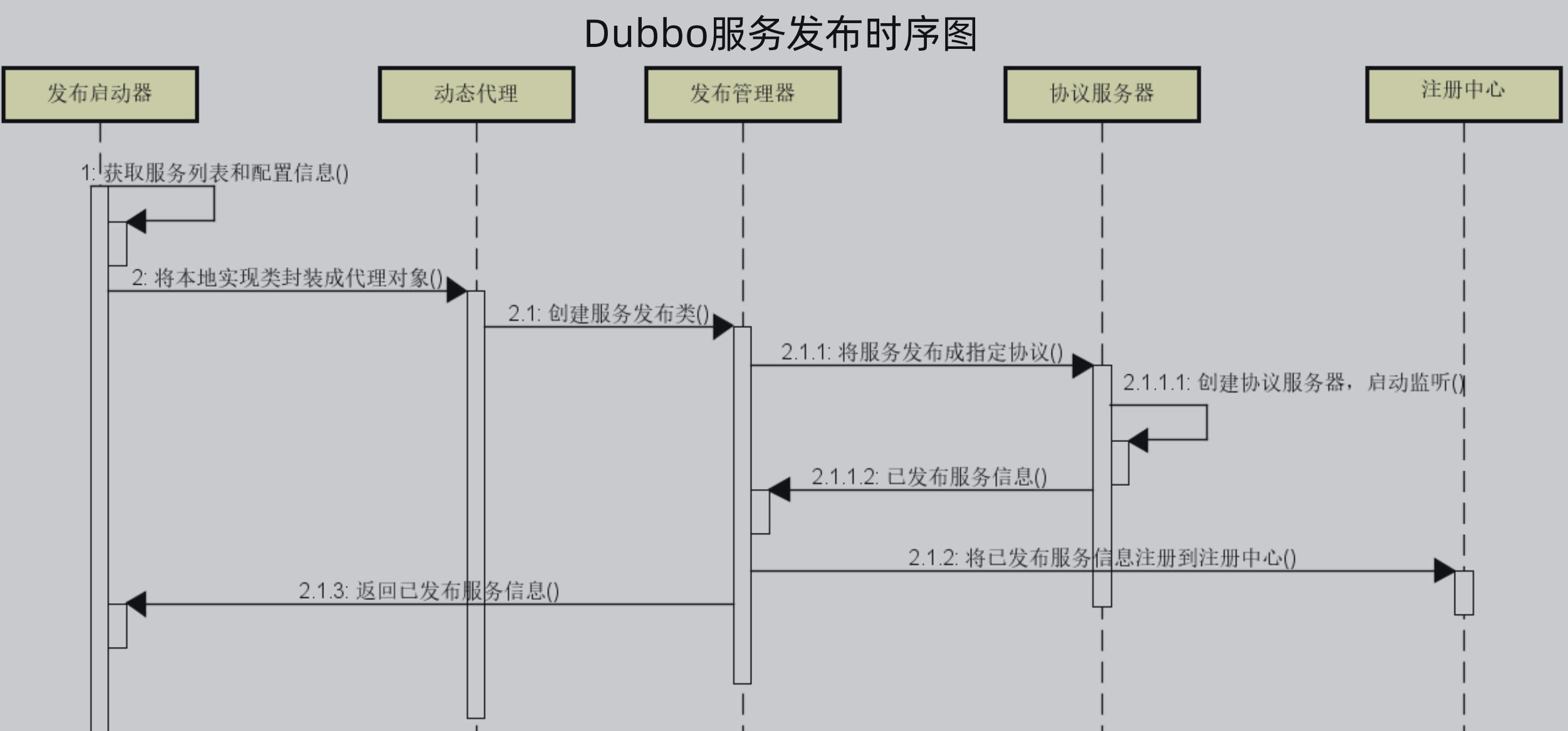
1、Dubbo服务发布流程:
在Dubbo的服务发布流程中,有五个对象,分别是发布启动器、动态代理、发布管理器、协议管理器、注册中心。
首先服务发布器根据服务信息和配置信息,低啊用动态代理将本地实现类封装成代理对象
动态代理调用发布管理器创建服务发布类
服务管理器调用协议服务器将服务发布成指定的协议,而协议服务器则创建指定的协议服务器,并启动监听
发布管理器获取到发布的服务后,将发布的服务注册到注册中心,然后整个流程结束。
2、Dubbo服务发布核心技术
(1)上下文信息:
请求地址、上下文、请求参数都存放当前调用过程中所需的环境信息,RpcContext的ThreadLocal 的临时状态记录器,根据请求控制状态变化
下面代码是Dubbo的源码中提取的相关的环境信息,包括请求URL、请求方法名、请求参数类型、请求参数值、本地地址、远程地址
private URL url; //请求URL
private String methodName; //请求方法名
private Class<?>[] parameterTypes; //请求参数类型
private Object[] arguments; //请求参数值
private InetSocketAddress localAddress; //本地地址
private InetSocketAddress remoteAddress; //远程地址
下面代码使用RpcContext.getContext()来获取相关的上下文信息并打印到日志。
public class UserServiceImpl implements UserService {
private static final Logger logger = LoggerFactory.getLogger(UserServiceImpl.class);
@Override
public User getUserByUserName(String userName) {
logger.info("getUserByUserName: " + userName + ", request from consumer: " +
RpcContext.getContext().getRemoteAddress());
return new User(...);
}
}
(2)多版本:
一个接口可以有多个版本的实现。
多版本可以作为服务接口多版本升级策略:当一个接口实现出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用,在低压力时间段,先升级一半提供为新版本,再将所有消费者升级为新版本,然后将剩下的一半提供者升级为新版本。
多版本代码实现:
public class UserServiceImpl1 implements UserService {
@Override
public User getUserByUserName(String userName) {
return new User(...);
}
}
public class UserServiceImpl2 implements UserService {
@Override
public User getUserByUserName(String userName) {
return new User(...);
}
}
多版本配置
<!--发布版本1.0.0服务-->
<bean id="userService" class="com.dubbo.demo.provider.UserServiceImpl1"/>
<dubbo:service interface="com.dubbo.demo.UserService" ref="userService" version="1.0.0"/>
<!--发布版本2.0.0服务-->
<bean id="userService" class="com.dubbo.demo.provider.UserServiceImpl2"/>
<dubbo:service interface="com.dubbo.demo.UserService" ref="userService" version="2.0.0"/>
<!--分别引用版本1.0.0和版本2.0.0服务-->
<dubbo:reference id="userService" interface="com.dubbo.demo.UserService" version="1.0.0"/>
<dubbo:reference id="userService"interface="com.dubbo.demo.UserService" version="2.0.0"/>
(3)隐式参数:
请求过程想要传递一些其他参数而又无法改变原有的方法定义,例如调用的是三方库,怎么办?
可以在服务消费方和提供方之间隐式传递参数,隐式参数(Implicit Parameter)。可以通过附件(Attachment)进行设置,对应RpcContext上的setAttachment 和getAttachment方法。
setAttachment 示例:
public static void main(String[] args) throws Exception {
ClassPathXmlApplicationContext context = new
ClassPathXmlApplicationContext("spring/dubbo-consumer.xml");
context.start();
UserService userService = context.getBean("userService", UserService.class);
RpcContext.getContext().setAttachment("parameter", "lcl");
System.out.println("result: " + userService.getUserByUserName("*").toString());
}
getAttachment 示例:
public class UserServiceImpl implements UserService {
@Override
public User getUserByUserName(String userName) {
String value = RpcContext.getContext().getAttachment("parameter");
return new User(...,value ,...);
}
}
(三)客服系统案例演进
Dubbo服务定义主要包括领域对象和服务定义两个部分。
领域对象是包括对现实中具体业务数据的抽象 ,而服务定义是包括针对领域对象所需要暴露的操作,那么上面提到的distribution-customer-service服务承载原distribution-customer-system项目中所有的MVC操作,同时需要有一个distribution-customer-service-definition服务来作为领域对象,对外提供服务,distribution-intergation-service同样如此。
这里演示distribution-intergation-service项目,主要用来做远程调用的整合,即之前的endpoint的处理。
1、领域对象:distribution-customer-service-definition
(1)首先定义实体
原有定义的入参是OutsourcingSystem,出参是CustomerStaff,是一个实体对象,而对于远程调用来说,定义一个统一的对象用于传输的非常必要的,因此这里使用OutsourcingSystemDTO代替原有的OutsourcingSystem,使用PlatformCustomerStaff代替原有的CustomerStaff。
对于远程传输的对象,必须实现序列化接口。
@Data
@EqualsAndHashCode(callSuper = false)
public class OutsourcingSystemDTO implements Serializable {
/**
* 系统名称
*/
private String systemName;
/**
* 系统编码
*/
private String systemCode;
/**
* 系统描述
*/
private String description;
/**
* 系统访问URL
*/
private String systemUrl;
}
(2)创建distribution-integration-service-definition项目,对外提供调用接口
public interface CustomerStaffIntegrationService {
List<PlatformCustomerStaff> fetchCustomerStaffs(OutsourcingSystemDTO outsourcingSystemDTO);
}
2、服务定义
创建distribution-intergation-service-provider项目,作为服务发布。
(1)引入 Dubbo 依赖
<!-- dubbo的自动配置类 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
</dependency>
<!-- dubbo对于zookeeper的集成 -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-dependencies-zookeeper</artifactId>
<type>pom</type>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--替换curator默认版本,确保和Zookeeper服务器兼容-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.2.0</version>
</dependency>
(2)Dubbo相关配置
dubbo:
protocol:
name: dubbo
port: -1
registry:
address: zookeeper://192.168.249.130:2181
file: /Users/aaa/Documents/workspace/customer-system/customer-system-distribution/dubbo-log
scan:
base-packages: org.geekbang.projects.cs
integration:
service:
version: 1.0.0
(3)编写接口实现类,同时使用 @DubboService 注解发布服务
@DubboService(version = "${integration.service.version}")
public class CustomerStaffIntegrationServiceImpl implements CustomerStaffIntegrationService {
@Autowired
private CustomerStaffEndpoint customerStaffEndpoint;
@Override
public List<PlatformCustomerStaff> fetchCustomerStaffs(OutsourcingSystemDTO outsourcingSystemDTO) {
return customerStaffEndpoint.fetchCustomerStaffs(outsourcingSystemDTO);
}
}
3、开启使用Dubbo
@SpringBootApplication
@EnableDubbo
public class IntegrationApplication {
4、distribution-customer-service 处理
distribution-customer-service服务承载原distribution-customer-system项目中所有的MVC操作。
同上面的distribution-intergation-service,分为distribution-customer-service-definition服务和distribution-customer-service-provider服务服务
(1)领域对象:distribution-customer-service-definition
public interface CustomerStaffSyncService {
void syncOutsourcingCustomerStaffsBySystemId(Long systemId);
}
(2)服务定义
创建distribution-customer-service-provider项目来实现上述接口,也是需要使用@DubboService来发布dubbo服务,pom文件和配置与上面一致,同时引入ICustomerStaffService调用系统集成服务。
@DubboService
public class CustomerStaffSyncServiceImpl implements CustomerStaffSyncService {
@Autowired
private ICustomerStaffService customerStaffService;
@Override
public void syncOutsourcingCustomerStaffsBySystemId(Long systemId) {
customerStaffService.syncGetOutsourcingCustomerStaffBySystemId(systemId);
}
}
四、Zookeeper服务发布和订阅机制解析
(一)Dubbo服务注册中心
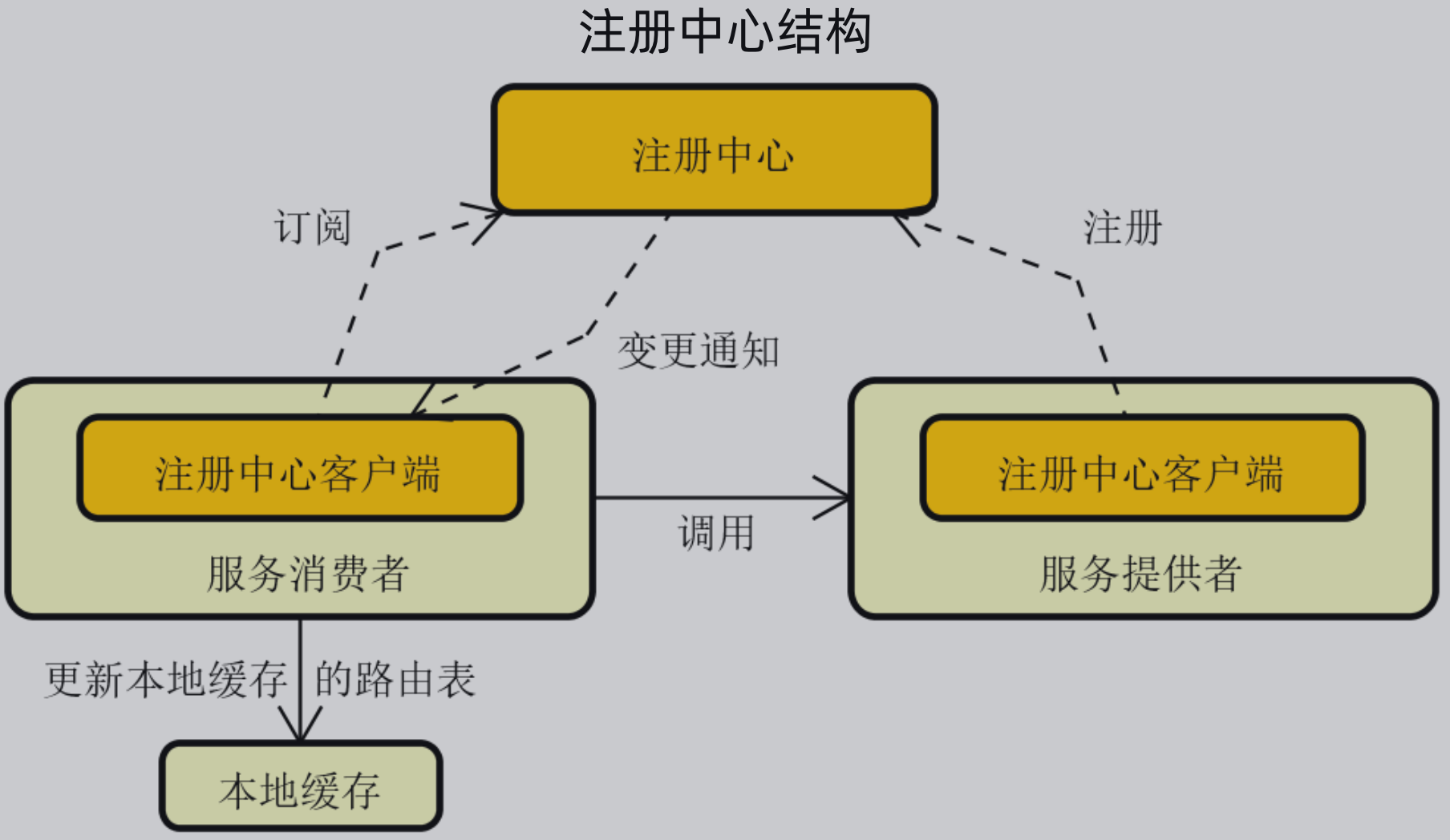
1、注册中心基本模型:
对于一个注册中心来说,要有一个 Server 进行独立部署;
服务提供者在服务启动后将其注册到注册中心;
而服务消费者通过订阅的方式来获取服务提供者的信息,同时如果服务提供者发生变更,注册中心也能及时的通知到服务消费者;
服务消费者内部需要有本地缓存,确保注册中心宕机后仍然可以做远程调用,但是还要确保本地缓存与注册中心的一致性;
2、注册中心能力包括:
支持对等集群:注册中心需要集群化部署
提供CRUD接口:可以增删改查服务
订阅发布机制:可以订阅服务
变更通知机制:服务变更后,订阅者需要能感知到
3、Dubbo中注册中心功能特性包括
Dubbo注册中心除了以上通用能力外,还提供了直连、只注册、只订阅、多注册中心等
直连:联调时会用,不想用注册中心
<dubbo:reference id="xxxService" interface="com.alibaba.xxx.XxxService" url="dubbo://localhost:20890"/>
只注册:
<dubbo:registry address="10.20.153.10:9090" register="false" />
只订阅:
<dubbo:registry address="10.20.141.150:9090" subscribe="false" />
多注册中心:同时调用两个不同注册中心中的服务,接口及版本号都一样,但连的数据库不一样
<!-- 多注册中心配置 -->
<dubbo:registry id="aRegistry" address="10.20.141.150:9090" />
<dubbo:registry id="bRegistry" address="10.20.154.177:9010" default="false" />
<!-- 引用中文站服务 -->
<dubbo:reference id="customerAService" interface="org.geekbang.projects.cs.CustomerService" version="1.0.0"
registry="aRegistry" />
<!-- 引用国际站服务 -->
<dubbo:reference id="customerBService" interface="org.geekbang.projects.cs.CustomerService" version="1.0.0"
registry="bRegistry" />
4、Dubbo注册中心
Dubbo注册中心支持Multicast 、Zookeeper、Redis、Consul、Nacos、Etcd3
Dubbo中的注册中心定义:
public interface RegistryService {
//注册
void register(URL url);
//取消注册
void unregister(URL url);
//订阅
void subscribe(URL url, NotifyListener listener);
//取消订阅
void unsubscribe(URL url, NotifyListener listener);
//根据URL查询对应的注册信息
List<URL> lookup(URL url);
}
public interface NotifyListener {
//针对不同URL执行注册中心变更通知
void notify(List<URL> urls);
}
Dubbo中的注册中心实现:
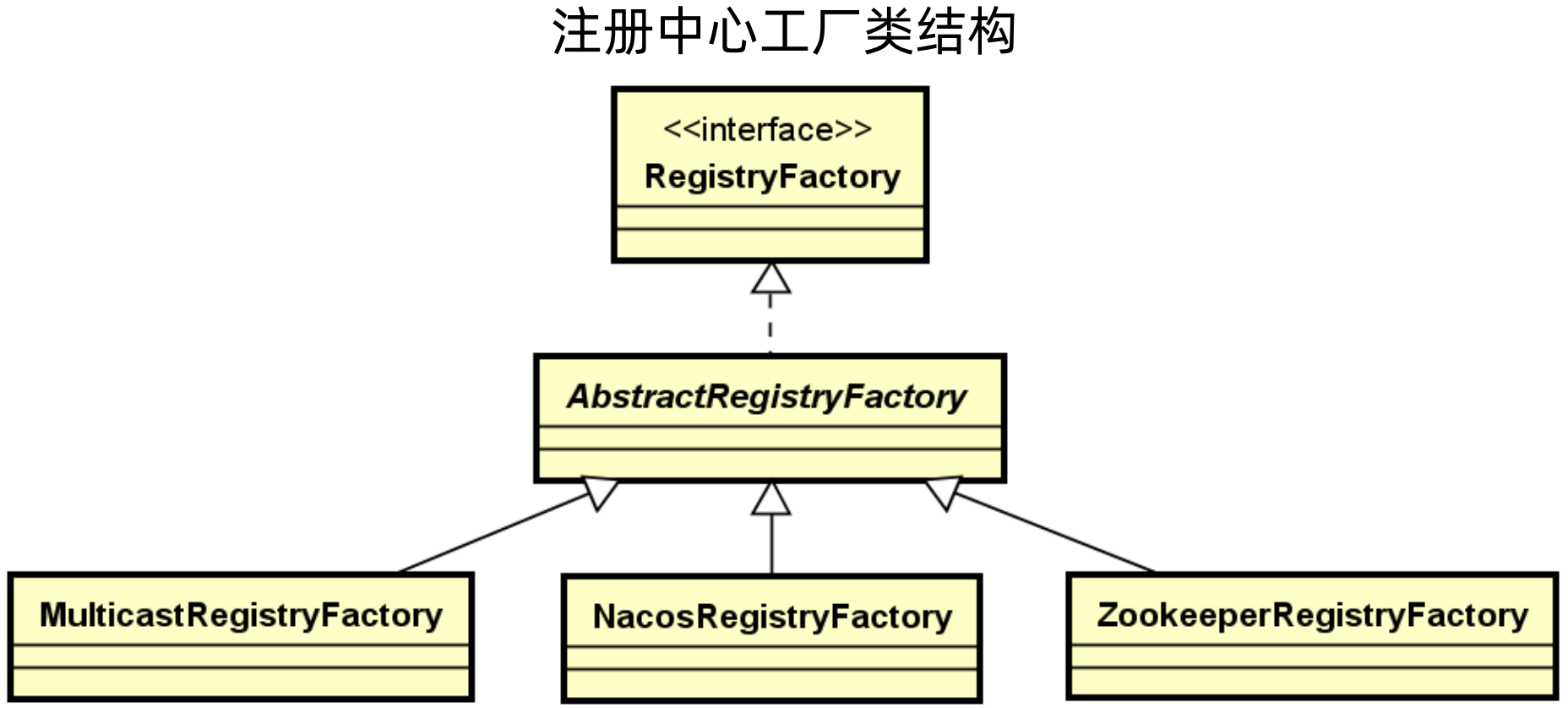
@SPI("dubbo")
public interface RegistryFactory {
Registry getRegistry(URL url);
}
public interface Registry extends Node, RegistryService {
}
注册中心工厂类结构:
Zookeeper注册中心接口:
(二)Zookeeper功能特性
1、Zookeeper框架
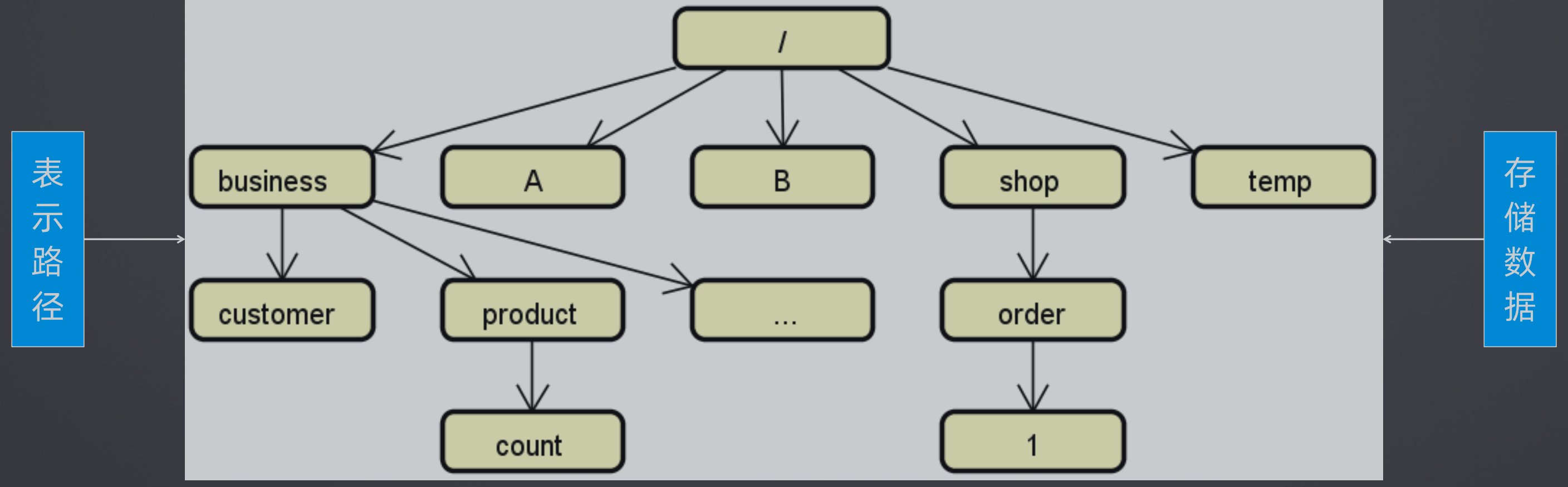
核心是一个精简的文件系统,提供基于目录节点(ZNode)树方式的数据存储,以及一些额外的抽象操作,如排序,通知和监控。本质上是一种分布式协调工具。
2、Zookeeper访问特性
Zookeeper访问是通过路径被引用,具有原子性和顺序访问的特点。
原子性访问:所有请求的处理结果在整个Zookeeper集群中所有机器是一致的
顺序访问:从同一客户端发起的事务请求,会按照其发起顺序严格应用到Zookeeper
3、Zookeeper操作模型
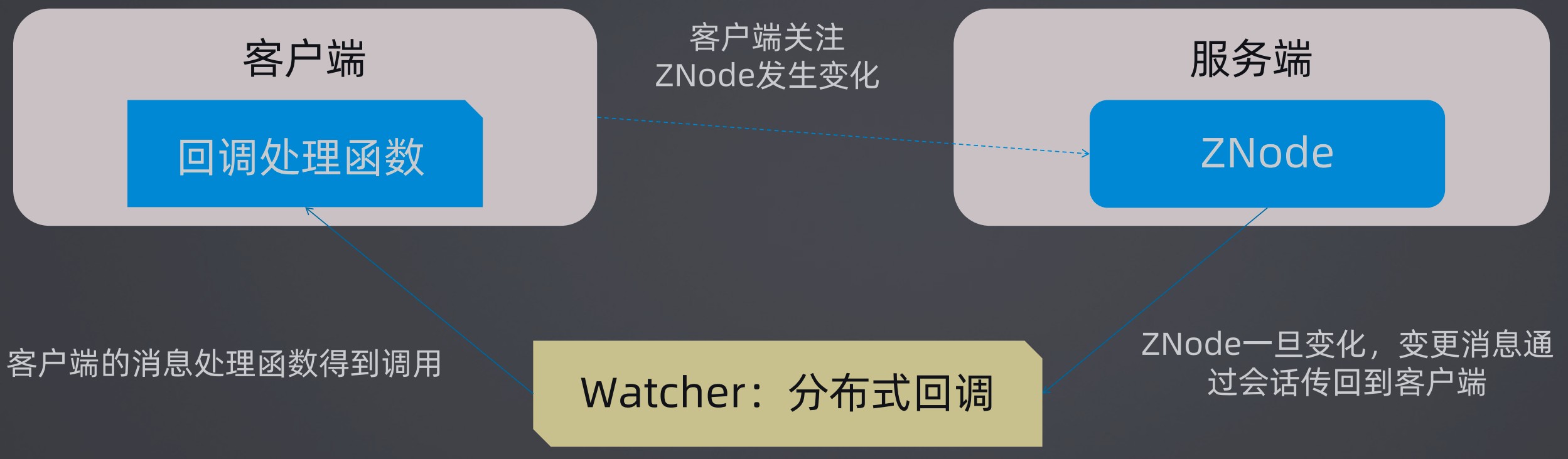
会话:Zookeeper的会话是使用TCP连接来发送请求,同时可以接收Watch事件,节点分为临时节点(Ephemeral)和持久节点(Persistent),主要区别是会话结束时节点是否自动删除。
Watcher:服务端有ZNode,客户端关注ZNode发生变化,ZNode一旦变化,变更消息通过会话(Watcher:分布式回调)传回到客户端,客户端的消息处理函数得到调用(客户端有回调处理函数)
4、Zookeeper核心API:
create:在ZooKeeper命名空间的指定路径中创建一个ZNode
delete:从ZooKeeper命名空间的指定路径中删除一个ZNode
exists:检查路径中是否存在ZNode
getChildren:获取ZNode的子节点列表
getData:获取与ZNode相关的数据
setData:将数据设置/写入ZNode的数据字段
getACL:获取ZNode的访问控制列表(ACL)策略
setACL:在ZNode中设置访问控制列表(ACL)策略
sync:将客户端的ZNode视图与ZooKeeper同步
(三)Dubbo中Zookeeper注册中心实现过程
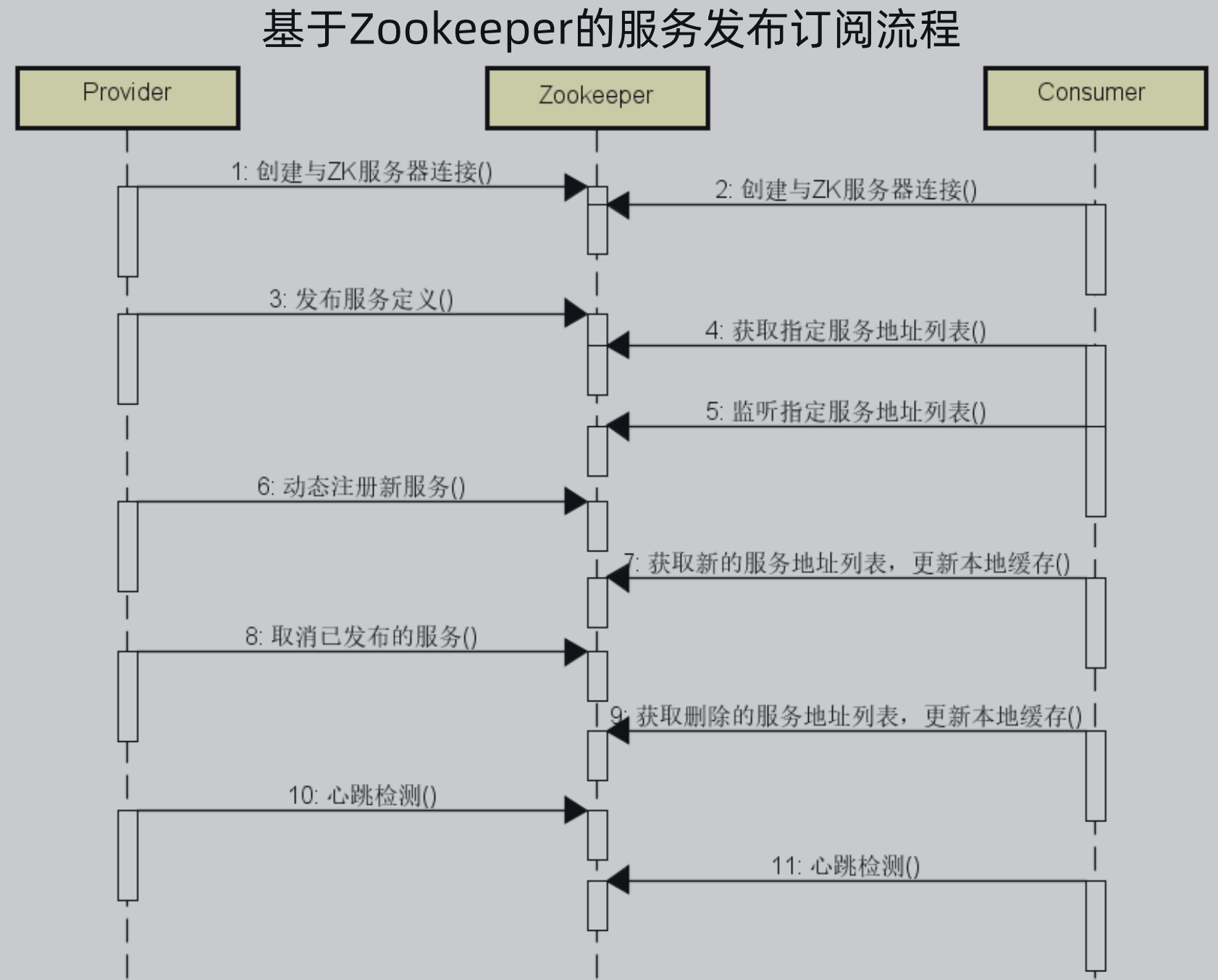
1、交互流程:
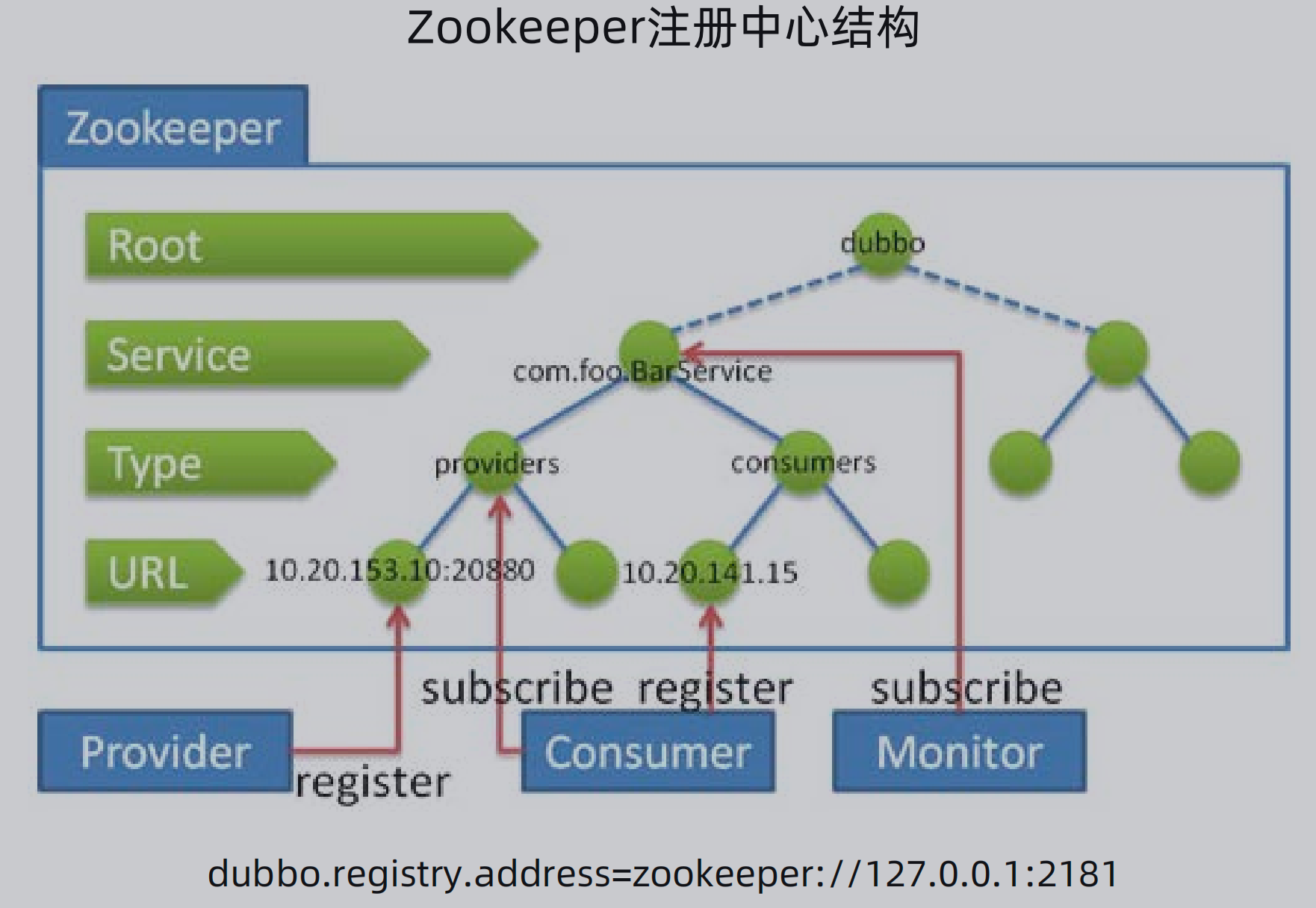
2、存储模型:
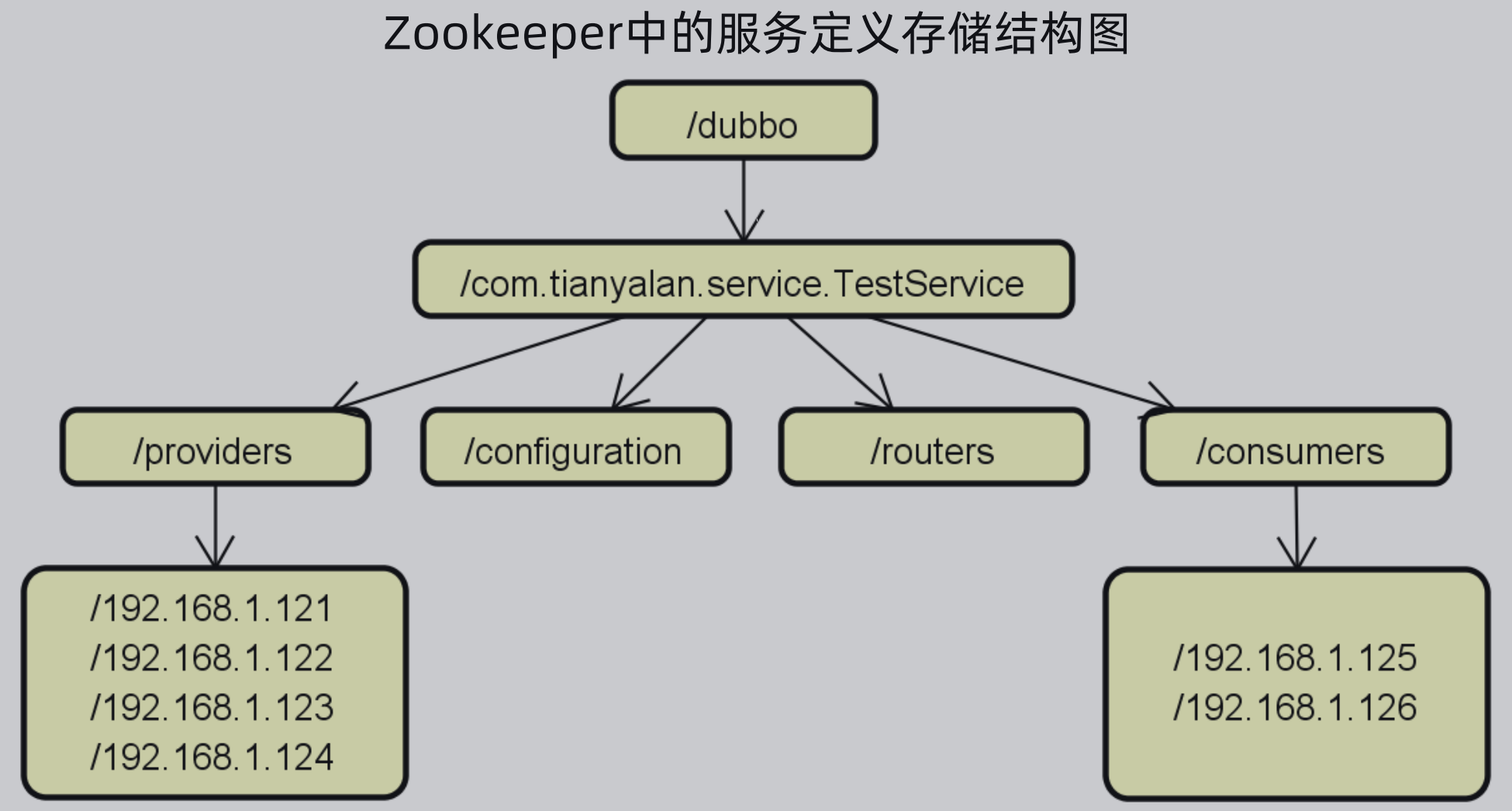
使用文件系统类似的树状结构进行存储,一级结构是 /dubbo,二级结构是指定的service,三级结构是配置、服务提供者、服务消费者、监控等等
3、Watcher:

4、Zookeeper注册中心核心类:
(1)ZookeeperRegistry:利用ZookeeperClient创建了对Zookeeper的连接,并且添加了自动回复连接的监听器
public ZookeeperRegistry(URL url, ZookeeperTransporter, zookeeperTransporter) {
super(url);
......
String group = url.getParameter(Constants.GROUP_KEY, DEFAULT_ROOT);
if (!group.startsWith(Constants.PATH_SEPARATOR)) {
group = Constants.PATH_SEPARATOR + group;
}
this.root = group;
// Transporter 是通信组件的封装
zkClient = zookeeperTransporter.connect(url);
// 利用ZookeeperClient创建了对Zookeeper的连接,并且添加了自动回复连接的监听器
zkClient.addStateListener(new StateListener() {
public void stateChanged(int state) {
// 如果是重连,则重新连接
if (state == RECONNECTED) {
try {
recover();
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}
});
}
(2)ZookeeperTransporter:定位上是一个底层通信组件,ZookeeperTransporter本身是一个接口,根据传入的URL通过创建与Zookeeper服务器的连接获取一个ZookeeperClient对象。
@SPI("zkclient")
public interface ZookeeperTransporter {
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
ZookeeperClient connect(URL url);
}
(3)ZookeeperClient:包含注册中心运行过程中的所有数据操作
public interface ZookeeperClient {
void create(String path, boolean ephemeral);
void delete(String path);
List<String> getChildren(String path);
List<String> addChildListener(String path, ChildListener listener);
void removeChildListener(String path, ChildListener listener);
void addStateListener(StateListener listener);
void removeStateListener(StateListener listener);
boolean isConnected();
void close();
URL getUrl();
}
(4)核心类类图:
对于Zookeeper不同的客户端,提供了不同的Transporter。
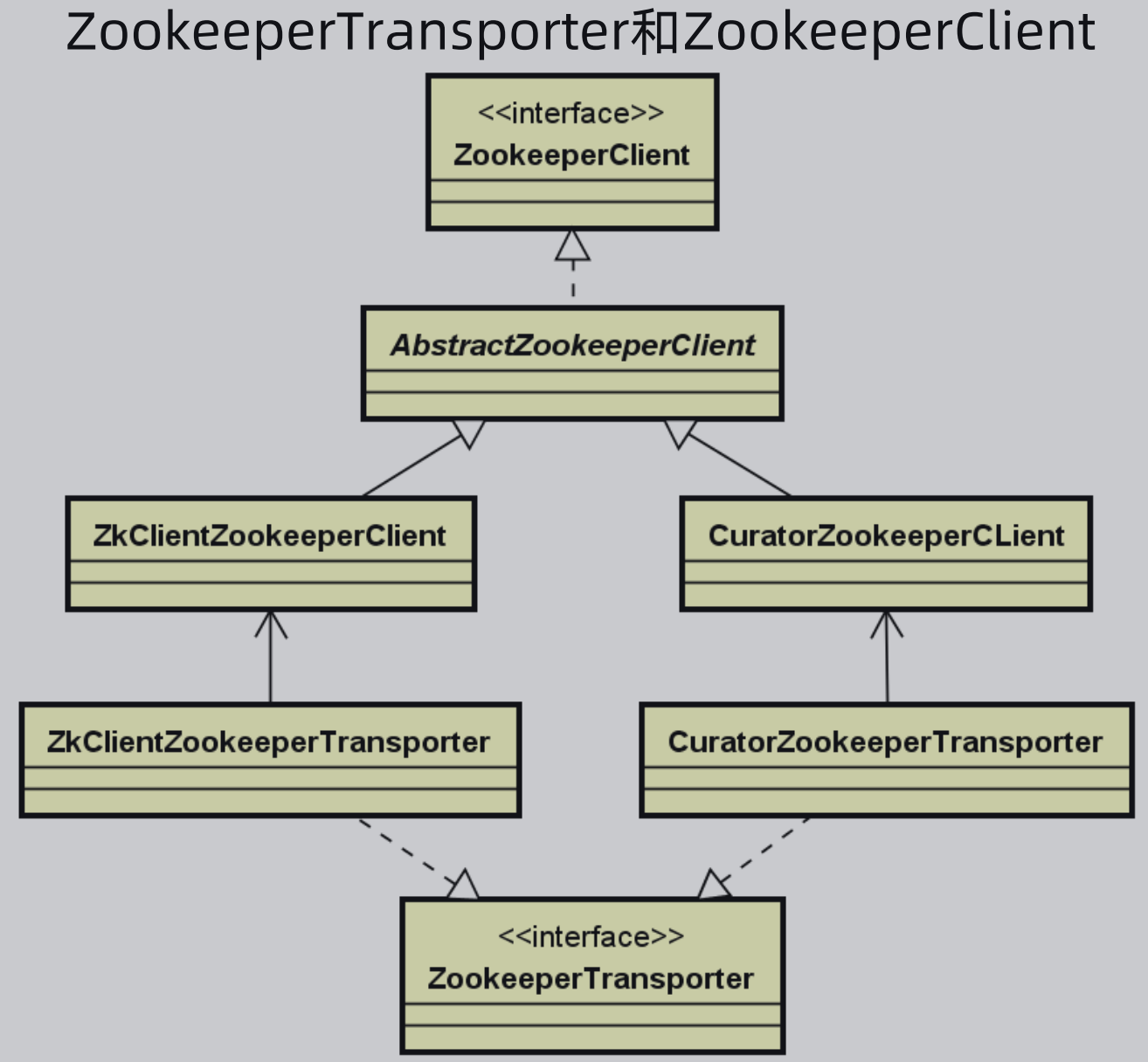
5、Zookeeper注册中心核心方法:
(1)注册:利用ZookeeperClient在服务器端创建一个URL的节点,该节点默认为临时节点,当客户端与服务端断开时会自动删除
//执行注册
protected void doRegister(URL url) {
try {
// 利用ZookeeperClient在服务器端创建一个URL的节点,该节点默认为临时节点,当客户端与服务端断开时会自动删除
zkClient.create(toUrlPath(url), url.getParameter(Constants.DYNAMIC_KEY, true));
} catch (Throwable e) {
...
}
}
(2)取消注册:取消注册的执行过程就是利用Zookeeper客户端删除URL节点
//取消注册
protected void doUnregister(URL url) {
try {
// 取消注册的执行过程就是利用Zookeeper客户端删除URL节点
zkClient.delete(toUrlPath(url));
} catch (Throwable e) {
...
}
}
(3)执行订阅:Dubbo会订阅父级目录, 而当有子节点发生变化时就会触发ChildListener中的回调函数,该回调函数会对该路径下的所有子节点执行subscribe操作
//执行订阅
ChildListener zkListener = listeners.get(listener);
if(zkListener==null){
listeners.putIfAbsent(listener,new ChildListener(){
public void childChanged(String parentPath,List<String> currentChilds){
for(String child:currentChilds){
child=URL.decode(child);
if(!anyServices.contains(child)){
anyServices.add(child);
// Dubbo会订阅父级目录, 而当有子节点发生变化时就会触发ChildListener中的回调函数,该回调函数会对该路径下的所有子节点执行subscribe操作
subscribe(url.setPath(child).addParameters(Constants.INTERFACE_KEY,child, Constants.CHECK_KEY,String.valueOf(false)),listener);
}
}
}
});
zkListener=listeners.get(listener);
}
(4)取消订阅:取消订阅URL的过程只是去掉URL上已经注册的监听器
//取消订阅
protected void doUnsubscribe(URL url, NotifyListener listener) {
ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.get(url);
if (listeners != null) {
ChildListener zkListener = listeners.get(listener);
if (zkListener != null) {
// 取消订阅URL的过程只是去掉URL上已经注册的监听器
zkClient.removeChildListener(toUrlPath(url), zkListener);
}
}
}
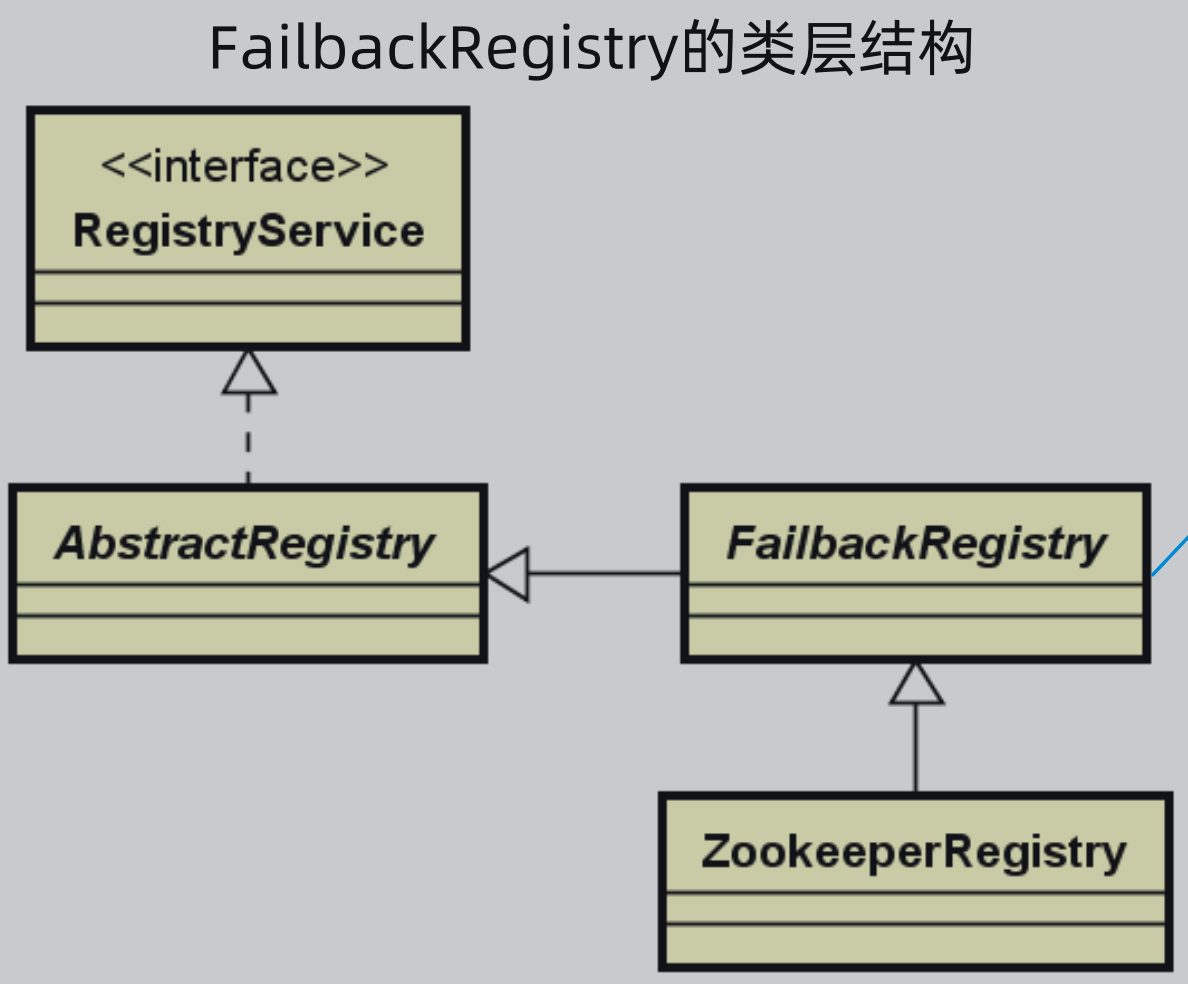
6、Zookeeper注册中心的容错性:
FailbackRegistry构造函数中会创建一个定时任务,每隔一段时间执行该retry方法。
从失败集合中获取URL,然后对每个URL执行doRegister操作从而实现重新注册。
五、使用Dubbo消费分布式服务
(一)Dubbo框架服务引用机制
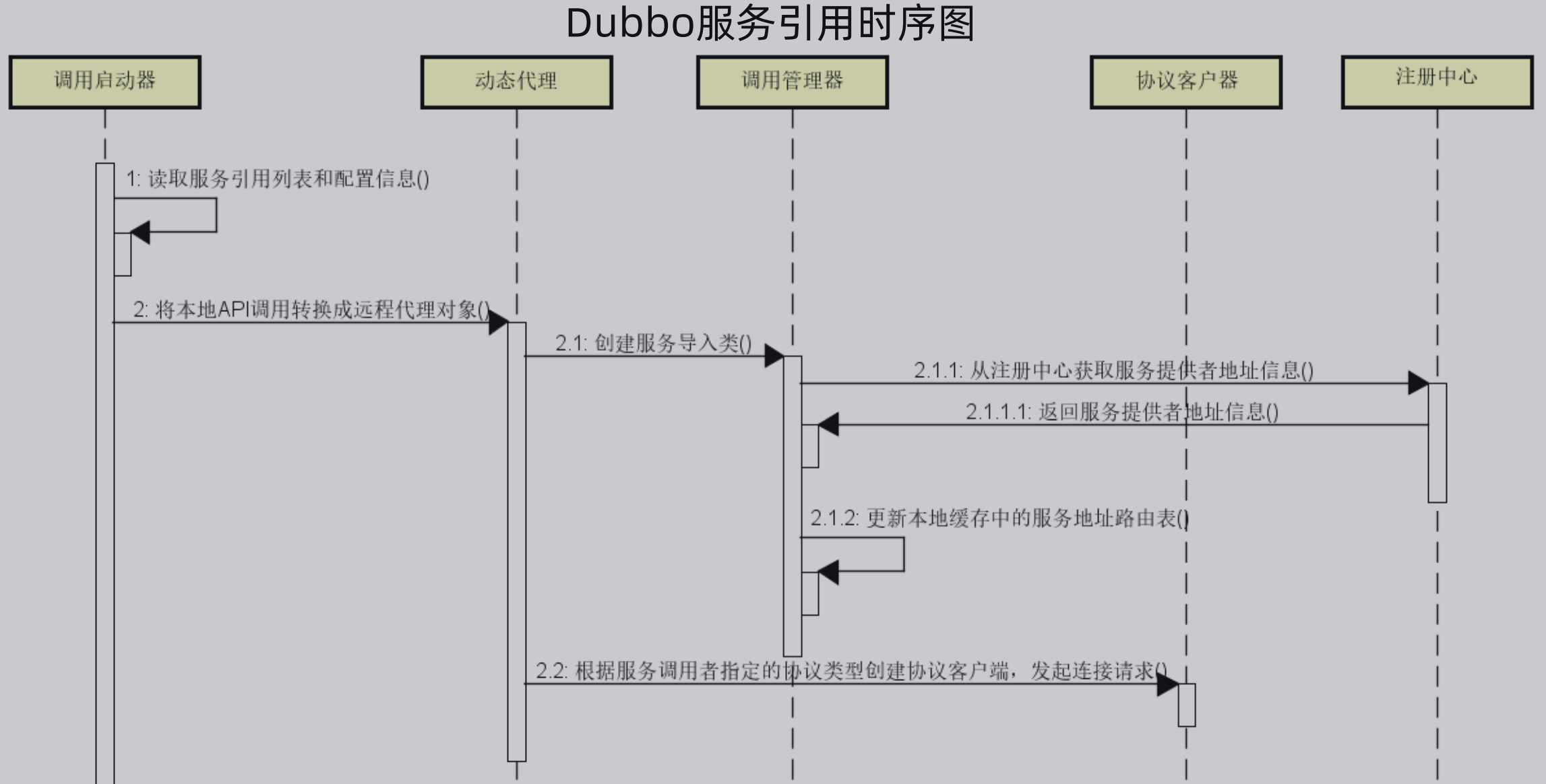
1、服务引用流程分析
上面提到了Dubbo的服务发布流程,如下所示:
而Dubbo服务的引用流程几乎与发布流程一一对应:
首先由调用启动器获取服务引用列表和配置信息,然后调用动态代理将本地API调用转换为远程代理对象
动态代理调用调用管理器创建服务导入类
调用管理器从注册中心获取服务提供者地址信息,并更新本地缓存中的服务地址路由表
然后动态代理根据服务调用者指定的协议类型创建协议客户端,发起连接请求
在上述流程中,比较关键的就是如何将远程调用转换为本地接口调用:
导入服务提供者接口API和服务信息
生成远程服务的本地动态代理对象
本地API调用转换成远程服务调用,返回调用结果
Dubbo远程调用全流程:
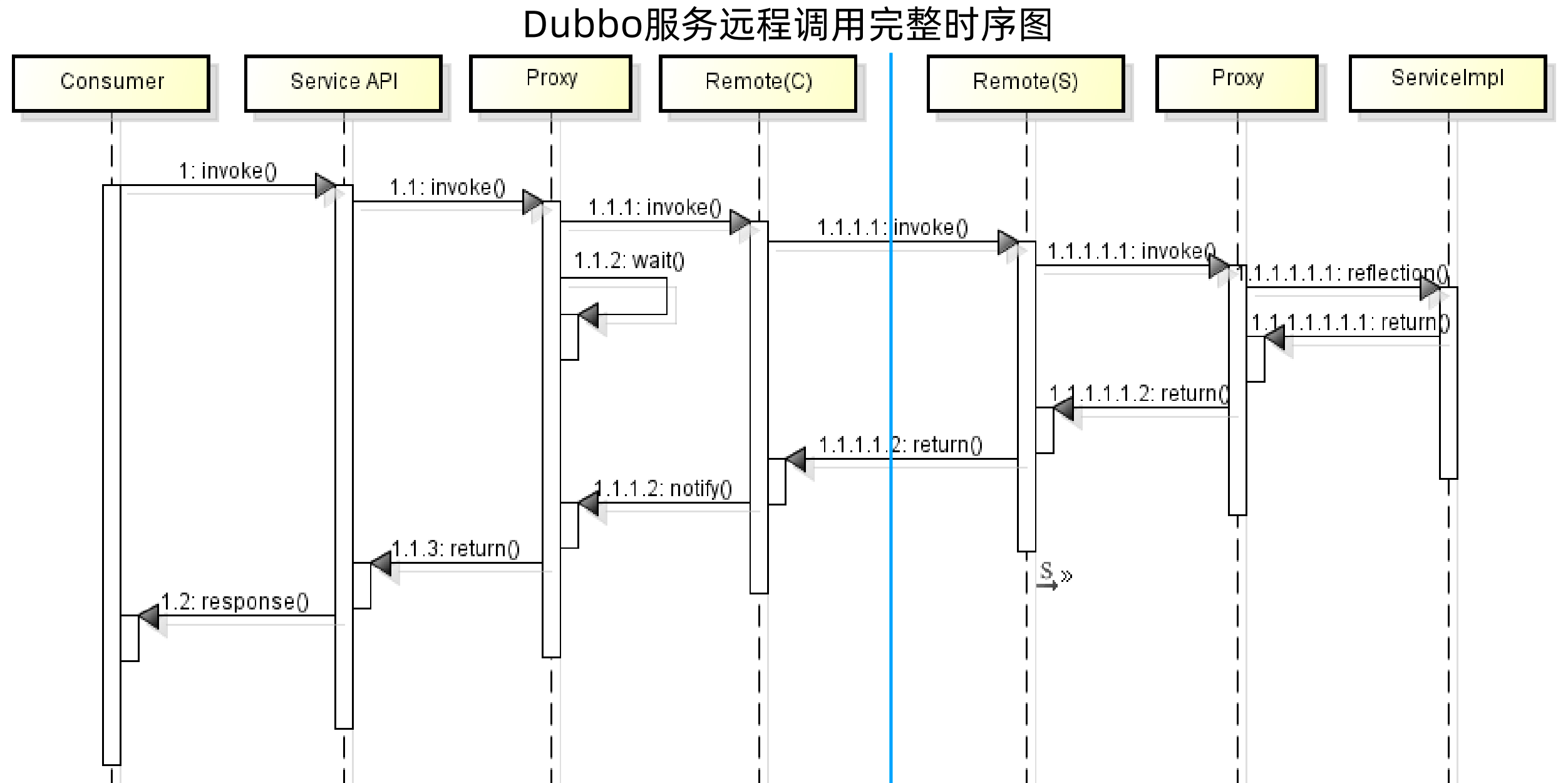
2、Dubbo服务调用核心技术:
(1)回声测试(EchoService)
回声测试是按照正常请求流程执行,能够测试整个调用是否通畅,可用于监控。
所有服务(无论是业务服务或者系统提供的服务)自动实现EchoService接口,只需将任意服务引用强制转型为EchoService即可使用。
首先就是回声测试接口(EchoService),内部提供了回声方法$echo,这种命名方式也是Dubbo的一种特点,框架内的接口都是以$开头。
public interface EchoService {
//定义回声方法
Object $echo(Object message);
}
在使用时,首先获取到业务接口,然后强转为EchoService,在调用其$echo方法获取状态,就可以判断接口是否正常。
public static void main(String[] args) throws Exception {
ClassPathXmlApplicationContext context = new
ClassPathXmlApplicationContext("spring/dubbo-consumer.xml");
context.start();
UserService userService = context.getBean("userService", UserService.class);
System.out.println("result: " + userService.getUserByUserName("*").toString());
//使用回声测试
EchoService echoService = (EchoService) userService;
String status = (String) echoService.$echo("OK");
System.out.println("status:" + status);
}
回声测试一般在自动化脚本中会使用。
(2)异步调用
基于NIO的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小所有异步编程接口开始以CompletableFuture为基础。
首先定义接口,返回值是CompletableFuture
//定义异步业务服务
public interface AsyncUserService {
CompletableFuture<User> getUserByUserNameAsync(String name);
}
然后是接口的实现
public class AsyncUserServiceImpl implements AsyncUserService {
@Override
public CompletableFuture<User> getUserByUserNameAsync(String name) {
CompletableFuture<User> future = CompletableFuture.supplyAsync(
() -> {
return new User(...);
}
);
return future;
}
}
接口调用
AsyncUserService asyncUserService = context.getBean("asyncUserService", AsyncUserService.class);
CompletableFuture<User> future = asyncUserService.getUserByUserNameAsync("*");
(3)泛化调用(GenericService)
实现一个通用的服务测试框架,能够调用所有服务。
实现泛化接口调用方式主要用于客户端没有API接口及模型类元的情况,参数及返回值中的所有POJO用Map表示。
泛化调用违反了接口契约,慎用。
与EchoService一样,所有的服务都实现了GenericService接口
泛化接口定义:
public interface GenericService {
Object $invoke(String method, String[] parameterTypes, Object[] args) throws GenericException;
default CompletableFuture<Object> $invokeAsync(String method, String[] parameterTypes, Object[] args) throws GenericException {
Object object = $invoke(method, parameterTypes, args);
if (object instanceof CompletableFuture) {
return (CompletableFuture<Object>) object;
}
return CompletableFuture.completedFuture(object);
}
}
泛化接口使用:与EchoService一样,强转为GenericService,然后调用其$invoke方法,入参是map,在map中可以输入任何参数。
GenericService userService = (GenericService) context.getBean("paramsUserService");
String[] parameterTypes = new String[]{"org.geekbang.projects.cs.UserParams"};
Map<String, Object> param = new HashMap<String, Object>();
param.put("class","org.geekbang.projects.cs.UserParams");
param.put("userName","testUserName");
System.out.println("result: "+userService.$invoke("getUserByParams",parameterTypes,new Object[]{param}));
(二)客服系统案例演进
客服系统服务消费链路分析:
customer-system 中有个定时任务,通过接口调用 customer-service获取数据,customer-service 调用对接系统intergation-service获取三方数据,intergation-service通过端点获取三方数据。
以 distribution-customer-service 为例,需要调用 distribution-intergation-service 提供的接口。
首先配置配置文件
dubbo:
protocol:
name: dubbo
port: -1
registry:
address: zookeeper://127.0.0.1:2181
file: D:/dubbo/customer-service/cache
scan:
base-packages: org.geekbang.projects.cs
customer:
service:
version: 1.0.0
#服务引用版本号
integration:
service:
version: 1.0.0
然后进行接口调用
@DubboService(version = "${customer.service.version}")
public class CustomerStaffSyncServiceImpl implements CustomerStaffSyncService {
@Autowired
private ICustomerStaffService customerStaffService;
@Override
public void syncOutsourcingCustomerStaffsBySystemId(Long systemId) {
customerStaffService.syncGetOutsourcingCustomerStaffBySystemId(systemId);
}
}
六、Dubbo服务端与客户端通信原理解析
(一)Dubbo网络通信组件整体架构
1、网络通信过程抽象:
使用分层架构进行抽象,可以分为业务逻辑层、调用层、和网络传输层,其中:
业务逻辑层是面向开发人员的
调用层在客户端是调用请求层,在服务端时调用响应层,对于网络通讯,一般会抽离一层网络传输层,这样调用层就会很薄,这样调用层只处理请求响应,同时可以处理一些请求时效,请求效果等等的处理
网络通讯层主要就是做网络通讯的,其实就是最底层的
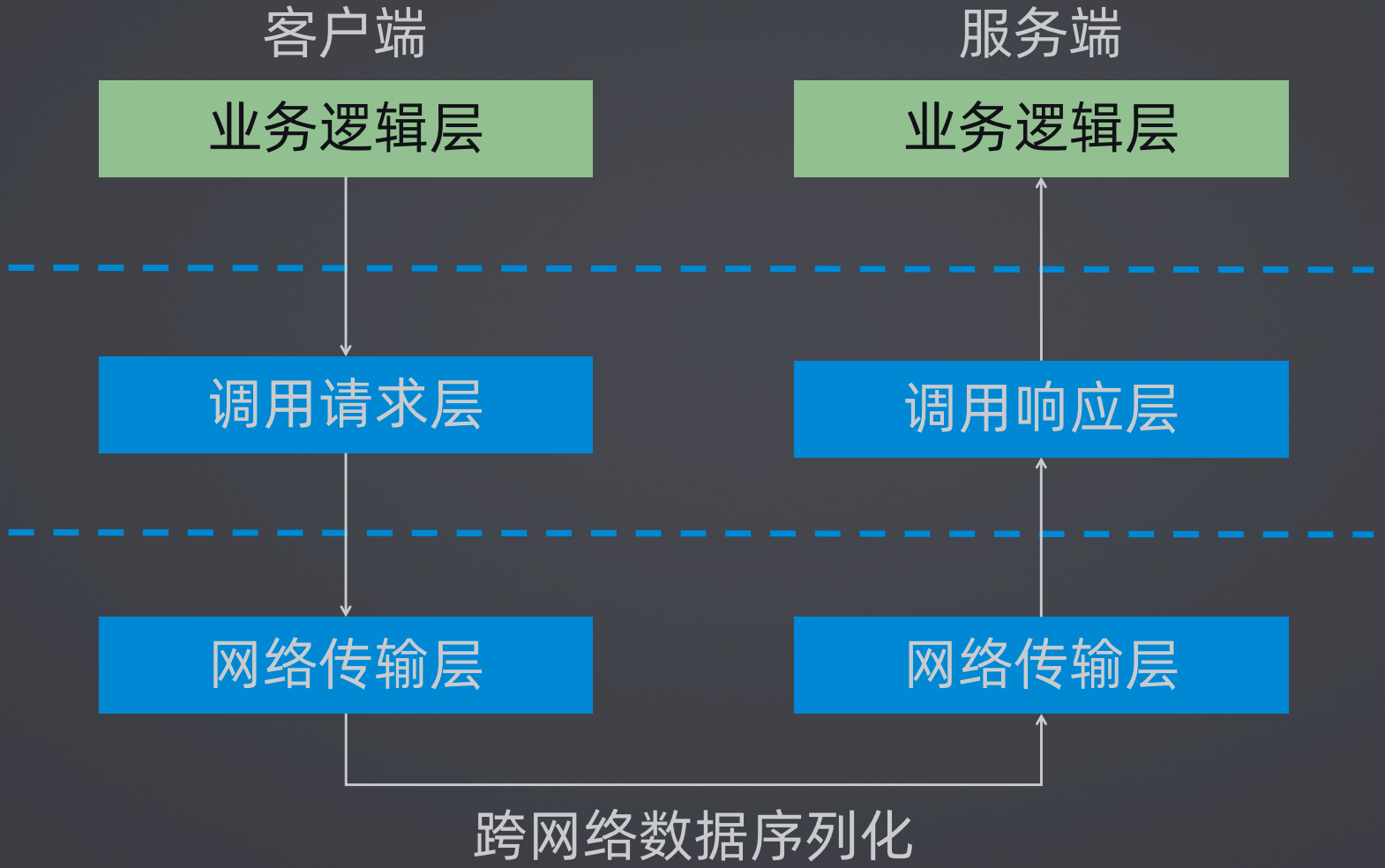
2、Dubbo中的网络通信组件(Remoting)
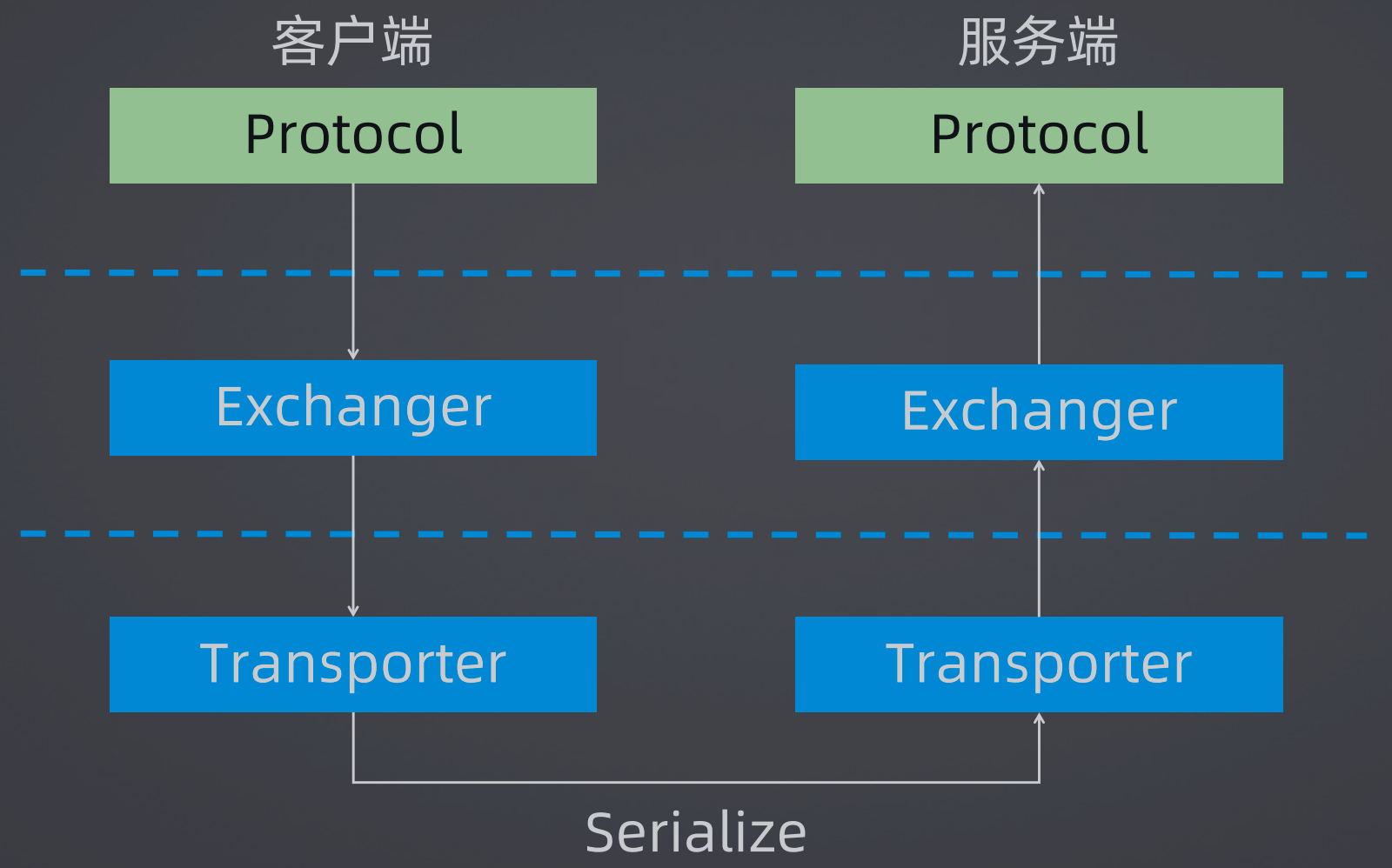
在Dubbo中单独抽象了一个网络通信组件 Remoting,其是在业务逻辑层下面专门用来做网络通信的,在Remoting中,又分为Exchange、Transport、Serialize三层。
Exchange层:信息交换层,用来封装请求-响应模式,对应上面的调用请求响应层。
Transport层:网络传输层,抽象Netty等框架作为统一的接口,对应上面的网络传输层。
Serialize层:序列化层,主要完成数据的序列化和反序列化过
3、Dubbo网络通信核心类:
在Dubbo代码中,业务逻辑层对应Protocol,即协议层,调用层对应Exchanger,网络传输层对应Transporter,网络传输需要Serialize序列化。
Protocol:
其提供了两个重要的方法:export 方法和 refer 方法,其中 export 方法对外暴露服务,refer方法对远程服务进行引用
基于以上两个方法的设计,那么Protocol就成了一切调用的入口,对于Protocol最常见的实现是DubboProtocol。
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
// 对外暴露服务
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
// 对远程服务进行引用
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
Exchanger:
exchanger封装了请求和响应的过程,其提供了bind和connect两个方法。
其中bind方法是面向服务器端的,返回的是服务端组件ExchangeServer;
connect方法是面向客户端的,返回值是客户端组件ExchangeClient
通过这两个方法,就形成了网络通信的闭环
@SPI(HeaderExchanger.NAME)
public interface Exchanger {
// 面向服务器端的bind方法
@Adaptive({Constants.EXCHANGER_KEY})
ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException;
// 面向客户端的connect方法
@Adaptive({Constants.EXCHANGER_KEY})
ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException;
}
Transporter:
Exchanger只是做网络通信,但是没有网络调用,而网络调用是通过Transporter来做的。
Transporter也是使用了bind和connect这两个方法来做网络调用,范式返回值却不一样,bind返回值是Server,connect返回值是Client,而Exchanger的返回值是ExchangeServer和ExchangeClient,可以看出一个偏底层,一个偏高级。
通知通过@SPI 注解,可以看到底层通信的框架使用的是Netty。
@SPI("netty")
public interface Transporter {
// 针对具体通信框架实现底层bind操作
@Adaptive({Constants.SERVER_KEY, Constants.TRANSPORTER_KEY})
Server bind(URL url, ChannelHandler handler) throws RemotingException;
// 针对具体通信框架实现底层connect操作
@Adaptive({Constants.CLIENT_KEY, Constants.TRANSPORTER_KEY})
Client connect(URL url, ChannelHandler handler) throws RemotingException;
}
(二)Dubbo服务器端通信机制解析
Dubbo中服务器端通信的目的就是集成并绑定Netty服务从而启动服务监听,典型的多层架构。
如下图所示,Exchanger绑定了一个ExchangerServer,Transporter绑定了Server,当通过URL调用时,调用的是Exchanger,实际上访问的是ExchangerServer,然后再调用Transpoter,即调用绑定的Server。
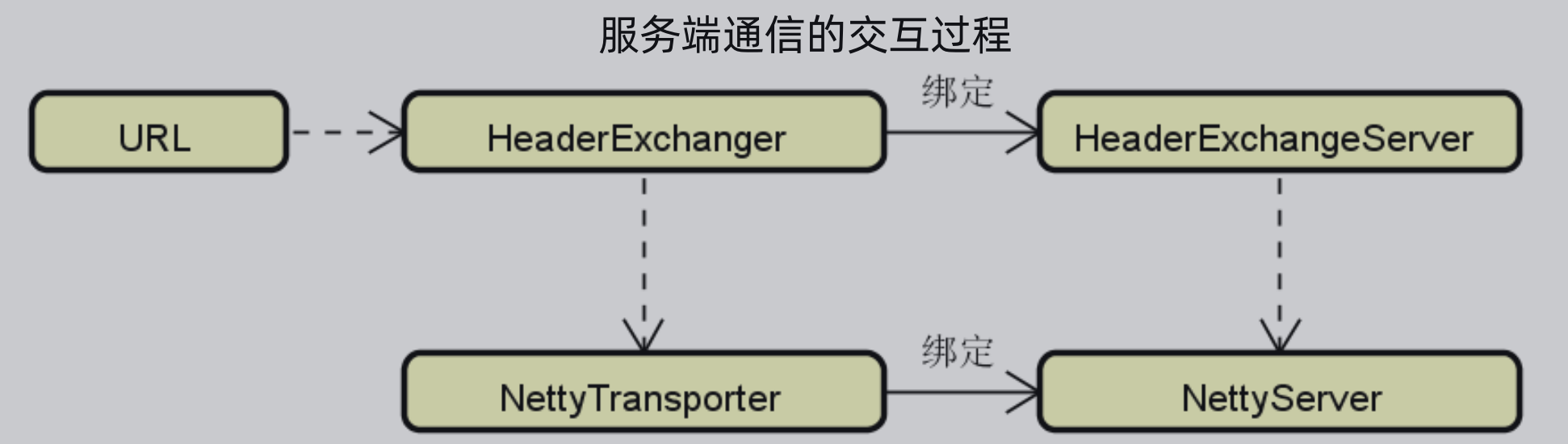
源码实现如下:
1、DubboProtocol创建ExchangeServer
在DubboProtocol中的openServer方法中,根据传入的服务请求URL来创建ExchangeServer,最终调用Exchangers.bind进行创建。
// 根据传入的服务请求URL来创建ExchangeServer
private void openServer(URL url) {
String key = url.getAddress();
boolean isServer = url.getParameter(Constants.IS_SERVER_KEY, true);
if (isServer) {
ExchangeServer server = serverMap.get(key);
if (server == null) {
serverMap.put(key, createServer(url));
} else {
server.reset(url);
}
}
}
// 通过Exchanger接口创建ExchangeServer
private ExchangeServer createServer(URL url) {
ExchangeServer server;
try {
// 通过Exchanger创建Server
server = Exchangers.bind(url, requestHandler);
}
return server;
}
2、HeaderExchanger
通过Transporter执行底层网络通信操作,在bind方法中,通过URL、ExchangeHandler来创建一个HeaderExchangeServer
public class HeaderExchanger implements Exchanger {
public static final String NAME = "header";
public ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeClient(Transporters.connect(url,
new DecodeHandler(new HeaderExchangeHandler(handler))), true);
}
public ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException {
return new HeaderExchangeServer(Transporters.bind(url,
new DecodeHandler(new HeaderExchangeHandler(handler))));
}
}
在HeaderExchanger中,会处理一些请求时效、请求效果等处理,例如下面的心跳检测,通过创建一个定时任务,来维护心跳。
//心跳检测功能
private void startHeatbeatTimer() {
stopHeartbeatTimer();
if (heartbeat > 0) {
heatbeatTimer = scheduled.scheduleWithFixedDelay(
// 定时心跳收发及心跳超时监测机制
new HeartBeatTask(new HeartBeatTask.ChannelProvider() {
public Collection<Channel> getChannels() {
return Collections.unmodifiableCollection(
HeaderExchangeServer.this.getChannels());
}
}, heartbeat, heartbeatTimeout),
heartbeat, heartbeat, TimeUnit.MILLISECONDS);
}
}
3、NettyTransporter
在Dubbo中Transporter有两个NettyTransporter、MinaTransporter、GrizzlyTransporter,默认使用Netty4对应的NettyTransporter,在该NettyTransporter种,提供了创建Netty服务端和客户端的方法。
public class NettyTransporter implements Transporter {
public static final String NAME = "netty4";
public Server bind(URL url, ChannelHandler listener) throws RemotingException {
return new NettyServer(url, listener);
}
public Client connect(URL url, ChannelHandler listener) throws RemotingException {
return new NettyClient(url, listener);
}
}
对对于创建Netty服务端的NettyServer方法来说,实际上就是通过Netty初始化服务器,并且通过Channel发送消息。
protected void doOpen() throws Throwable {
......
bootstrap = new ServerBootstrap(channelFactory);
final NettyHandler nettyHandler = new NettyHandler(getUrl(), this);
channels = nettyHandler.getChannels();
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() {
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(), NettyServer.this);
ChannelPipeline pipeline = Channels.pipeline();
pipeline.addLast("decoder", adapter.getDecoder());
pipeline.addLast("encoder", adapter.getEncoder());
pipeline.addLast("handler", nettyHandler);
return pipeline;
}
});
channel = bootstrap.bind(getBindAddress());
}
public void send(Object message, boolean sent) throws RemotingException {
Collection<Channel> channels = getChannels();
for (Channel channel : channels) {
if (channel.isConnected()) {
channel.send(message, sent);
}
}
}
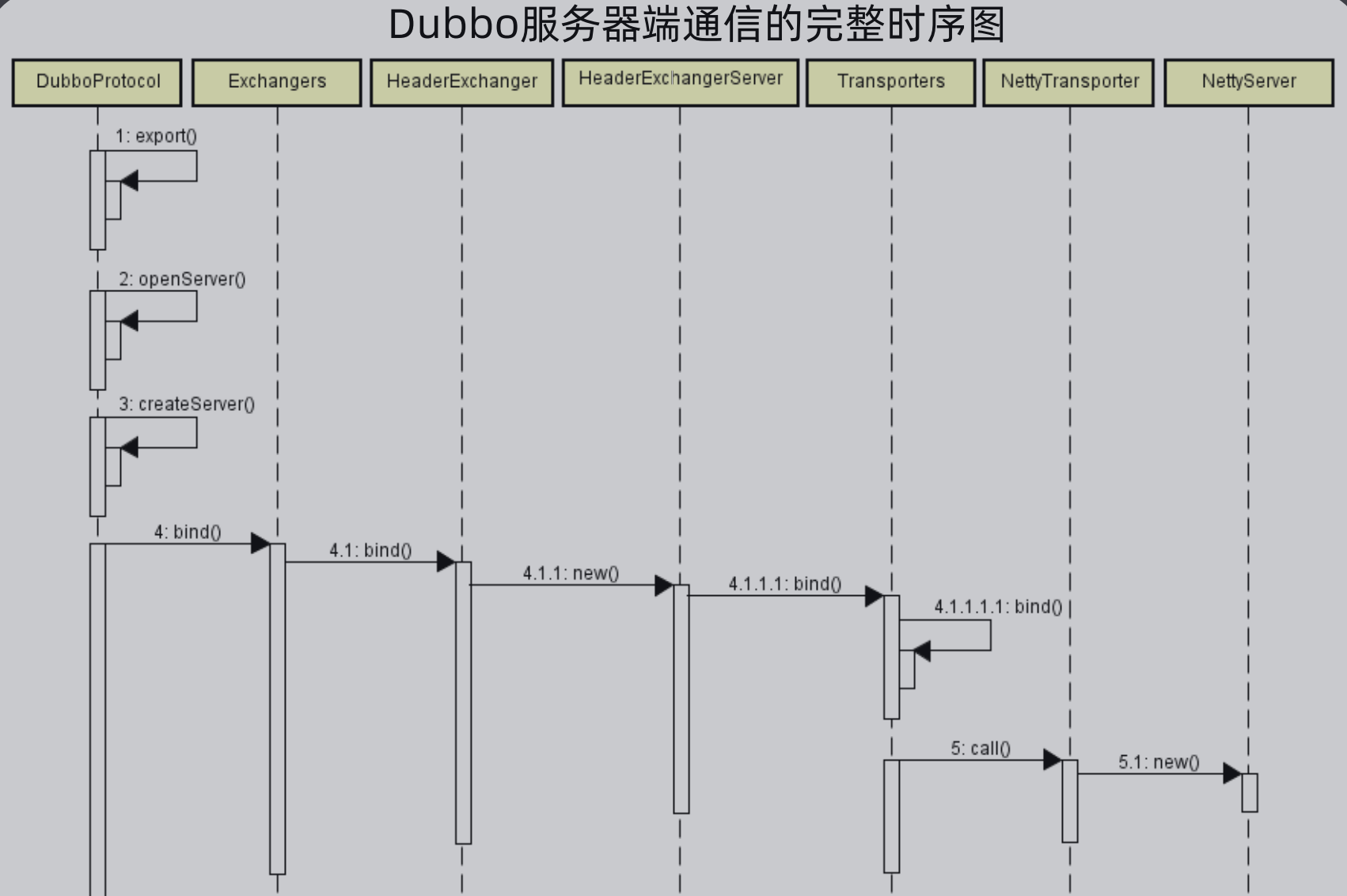
4、Dubbo服务器端网络通信全流程:
下面是使用时序图来表示整个Dubbo服务端通信的流程:
(1)首先通过DubboProtocol暴露一个服务,暴露服务时要打开一个服务
(2)然后会打开一个server,打开服务前要创建服务
(3)创建服务
(4)创建完毕后要绑定服务,使用Exchanger进行绑定
(5)实际底层使用的是Transporters进行绑定,而默认实现是Netty,最终创建的是NettyServer。
(三)Dubbo客户端通信机制解析
Dubbo客户端的结构与服务端一一对应,网络通信核心类:
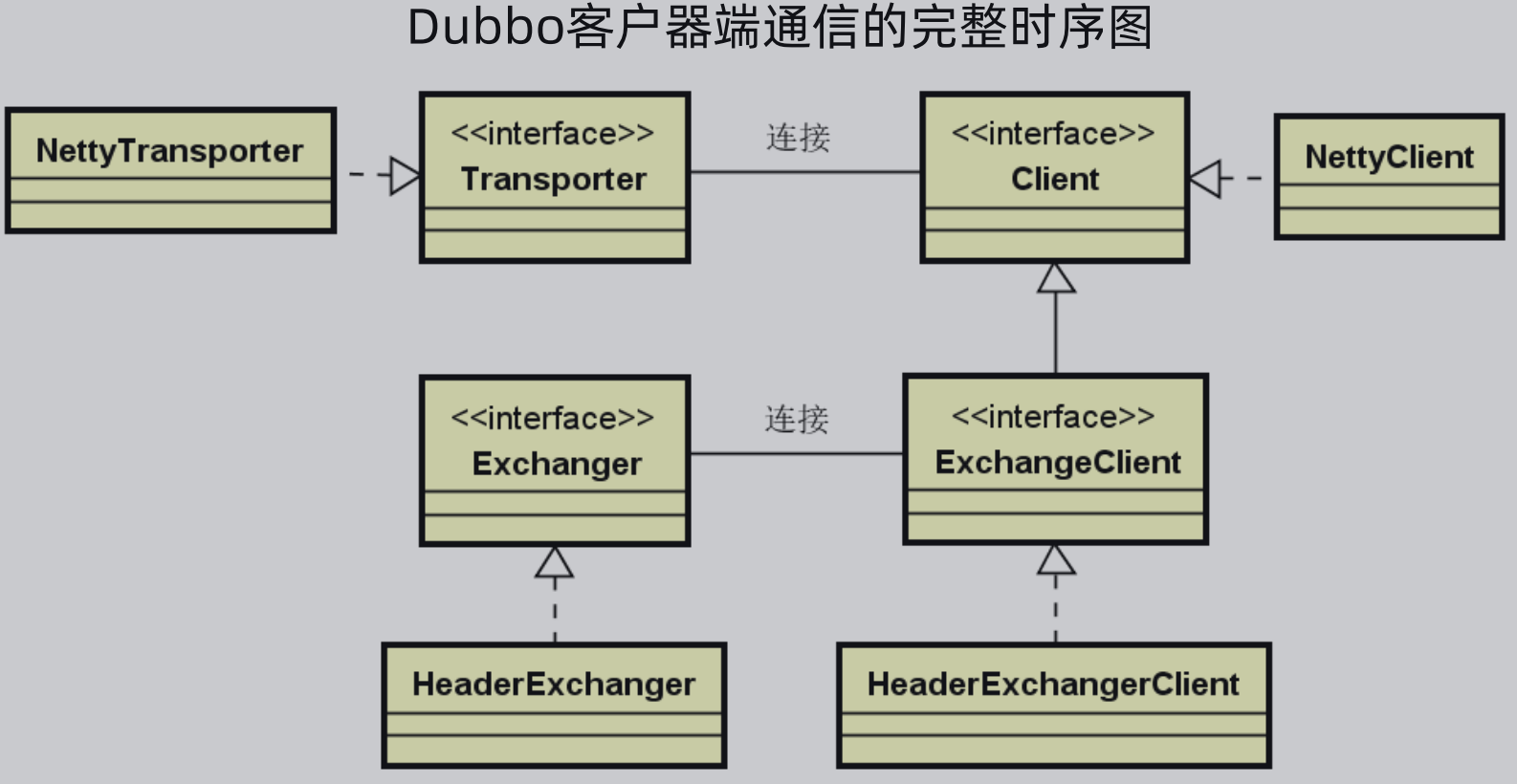
下面重点介绍两个类的方法:
1、NettyClient:通过Netty初始化客户端
@Override
protected void doOpen() throws Throwable {
......
bootstrap = new ClientBootstrap(channelFactory);
final NettyHandler nettyHandler = new NettyHandler(getUrl(), this);
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() {
NettyCodecAdapter adapter = new NettyCodecAdapter(getCodec(), getUrl(),
NettyClient.this);
ChannelPipeline pipeline = Channels.pipeline();
pipeline.addLast("decoder", adapter.getDecoder());
pipeline.addLast("encoder", adapter.getEncoder());
pipeline.addLast("handler", nettyHandler);
return pipeline;
}
});
}
2、DubboProtocol:获取ExchangeClient
private ExchangeClient initClient(URL url) {
ExchangeClient client;
try {
if (url.getParameter(Constants.LAZY_CONNECT_KEY, false)) {
client = new LazyConnectExchangeClient(url, requestHandler);
} else {
client = Exchangers.connect(url, requestHandler);
}
}
return client;
}
七、实现分布式服务容错
(一)服务容错的基本概念
服务访问失败的原因包括:大量请求导致的自身服务失败、依赖系统问题导致的失败等
在分布式服务中,由于有失败重试策略,那么一个服务异常,会导致依赖服务更大的重试流量,从而导致依赖服务也异常,最终导致系统雪崩。
服务失败的应对策略的基本思路包括超时和重试
超时:指如果服务未能在这个时间内响应,将回复一个失败消息;
重试:指为了降低网络瞬态异常所造成的的网络通信问题,可以使用重试机制,但是重试应该有次数限制,不能无限次重试。
Dubbo中的解决方案:容错思想包括集群容错和服务降级
集群容错:集群的建立已经满足冗余的条件,而围绕如何进行重试就产生了几种常见的集群容错略;
服务降级:对服务进行分级管理,必要时关闭对不重要服务的访问入口,节省资源用于处理重要服务的请求
(二)Dubbo集群容错
Dubbo负载均衡策略包括:Random(随机)、RoundRobin(轮询)、LeastActive(最少活跃调用数)、ConsistentHash(一致性 Hash)
Dubbo集群容错策略包括:Failover、Failfast、Failsafe、Failback、Forking、Broadcast,其中Failover是最常见的集群容错机制
Dubbo集群容错策略使用方法:
cluster配置项:代表集群容错机制,可任选一种
retries配置项:重试次数,当调用发生失败时重新发起请求的次数
代码样例如下:
<dubbo:reference id="userService" check="false" interface="....UserService" loadbalance="roundrobin" cluster="failover" retries="2"/>
(三)Dubbo服务降级
本地伪装 VS 本地存根:
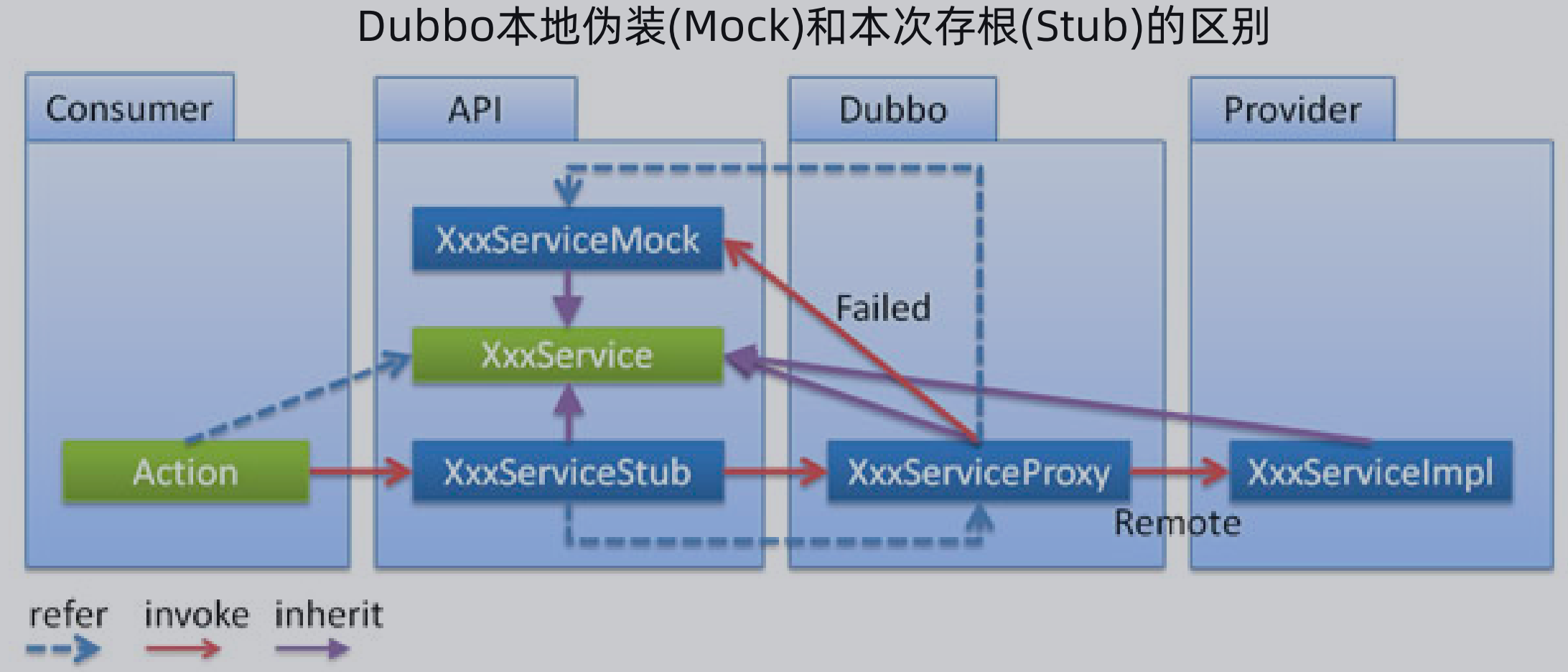
本地伪装是指当某服务提供者全部挂掉后,客户端不抛出异常,而是通过Mock数据返回失败,Mock类在服务消费者端配置
本地存根是指服务的提供方也有在本地执行部分逻辑的场景(例如原先校验参数),从而间接实现服务容错,Stub类在服务提供者端配置
实现本地伪装:
服务提供者模拟服务超时失败:
//服务提供者模拟服务超时失败
public class UserServiceImpl implements UserService {
@Override
public User getUserByUserName(String userName) {
try {
Thread.sleep(5000);//模拟服务端响应超时
} catch (InterruptedException e) {
e.printStackTrace();
}
return new User(...);
}
}
服务消费者实现和配置Mock类:
//服务消费者实现和配置Mock类
public class UserServiceMock implements UserService {
@Override
public User getUserByUserName(String userName) {
//降级实现
return new User(1L, "mock_username", "mock_password");
}
}
配置项:
<dubbo:reference id="userService" check="false" interface="...UserService" mock="....mock.UserServiceMock"/>
(四)客服系统案例演进
在distribution-customer-service调用distribution-intergation-service时使用降级策略。
首先在distribution-customer-service中编写降级类
@Component
public class CustomerStaffIntegrationServiceMock implements CustomerStaffIntegrationService {
@Override
public List<PlatformCustomerStaff> fetchCustomerStaffs(OutsourcingSystemDTO outsourcingSystemDTO) {
return null;
}
}
然后在distribution-customer-service的调用中,配置mock
@DubboReference(version = "${integration.service.version}", timeout = 5000, loadbalance = "roundrobin", retries = 2, mock = "com.lcl.galaxy.customer.service.provider.intergation.CustomerStaffIntegrationServiceMock")
private CustomerStaffIntegrationService customerStaffIntegrationService;
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号