
03-租户机制与服务集成
一、构建多租户机制
(一)多租户机制的设计方法
多租户是实现如何在多用户环境下共用相同的系统或程序组件,并且可确保各用户间数据的隔离性,多租户技术在共用的数据中心以单一系统架构与服务提供多数用户相同甚至可定制化的服务。场景可以分为业务集成(医院HIS系统/电商供应商对接)、开放平台(天气/地图/导航服务接入)、云平台(阿里云/腾讯云接入)等。
传统的模式是使用独立部署,一个租户对应一个应用,一个应用对应独立的数据库;而多租户模式是所有租户使用同一个应用,数据库可以是使用同一个,也可以分离。
多租户系统的核心功能包括:租户管理、权限管理、应用管理、运营管理四大块,其他三个比较好理解,这里单独说一下应用管理,应用管理指不是以人来接入的,而是以应用的方式接入(例如服务供应商提供一个多租户系统,例如地图、语音转写这些服务提供商,如果别的系统要集成这些服务,就需要开通账号进行接入),多租户系统开放一个端口给要接入的系统,让其可以访问即可。
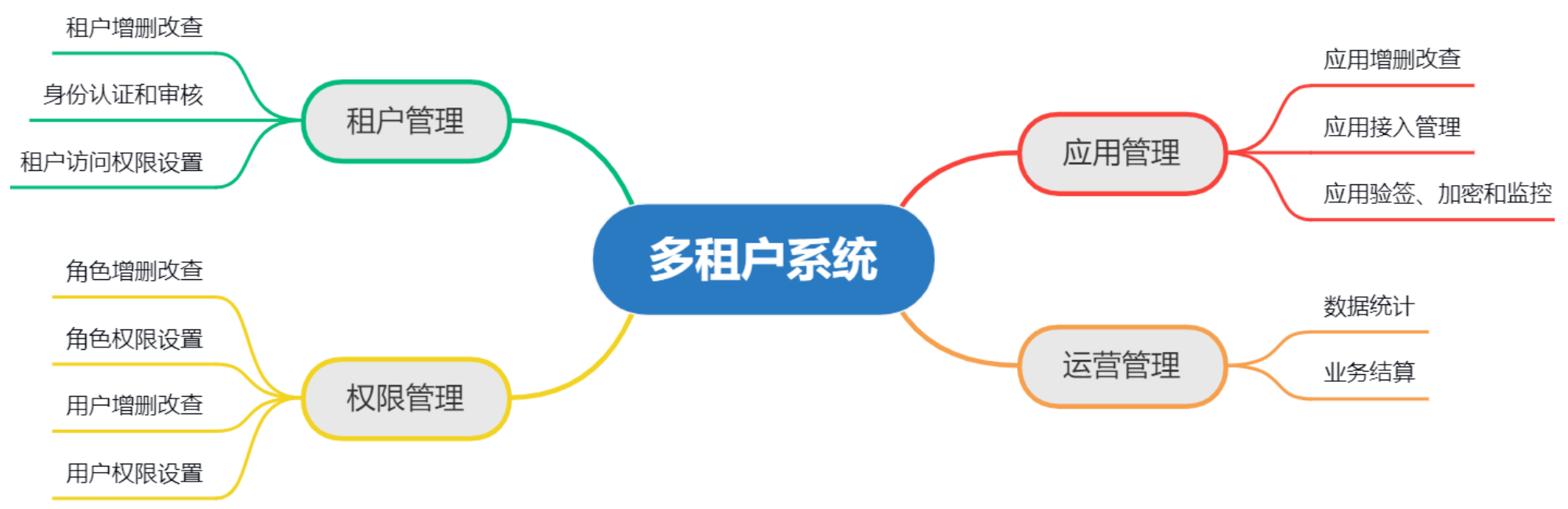
多租户的核心是数据隔离,隔离策略有独立数据库、共享数据库但隔离数据表空间、共享数据库且共享数据表空间三种。
独立数据库:
一个租户一个数据库,这种方案的代码在客户端之间共享,而用户数据物理上隔离
优势:有助于对数据模型进行扩展,满足不同租户的定制化需求;如果出现故障,恢复数据比较简单,数据安全性也高
劣势:增多了数据库的安装和维护数量,随之带来硬件的购置成本以及运维人员的增加
适用场景:适合安全性要求高且愿意付款的客户,典型的如银行、医院等,特别是医院,国家本身规定数据是用户隐私,不能随便拿出去。
共享数据库,隔离数据表空间:
所有租户共享同一个数据库,但是每个租户一个Schema,来自不同客户端的信息存储在不同的表中
优势:为安全性要求较高的租户提供了一定程度的逻辑数据隔离;针对不同Schema可以控制访问权限;每个数据库可支持更多的租户数量
劣势:不同租户的数据存储在一起,如果出现故障,数据恢复比较困难,因为恢复数据库将牵涉到其他租户的数据
适用场景:适合物理上不隔离的共享环境中的平衡方案
共享数据库,共享数据表空间:
所有租户共享同一个数据库、同一个Schema,但在表中增加类似TenantId等多租户数据字段
优势:维护和购置成本最低,允许每个数据库支持的租户数量最多;所有信息存储在一组表中时,更易于开发和维护
劣势:缺少扩展性,所有客户端都使用同一组表和列;数据备份和恢复最困难,需要逐表逐条备份和还原
适用场景:适合成本控制要求很高,且都数据安全性要求不高的场景
针对于上面三种数据隔离模式,怎么选择是个问题,主要从以下四点去考虑:
成本控制:成本和数据隔离成正比,隔离性越好则成本越高
安全要求:安全性要求越高,越倾向于隔离
租户数量:预期的租户越多,越倾向于共享
技术储备:共享性越高,对技术的要求越高
(二)客服系统案例演进
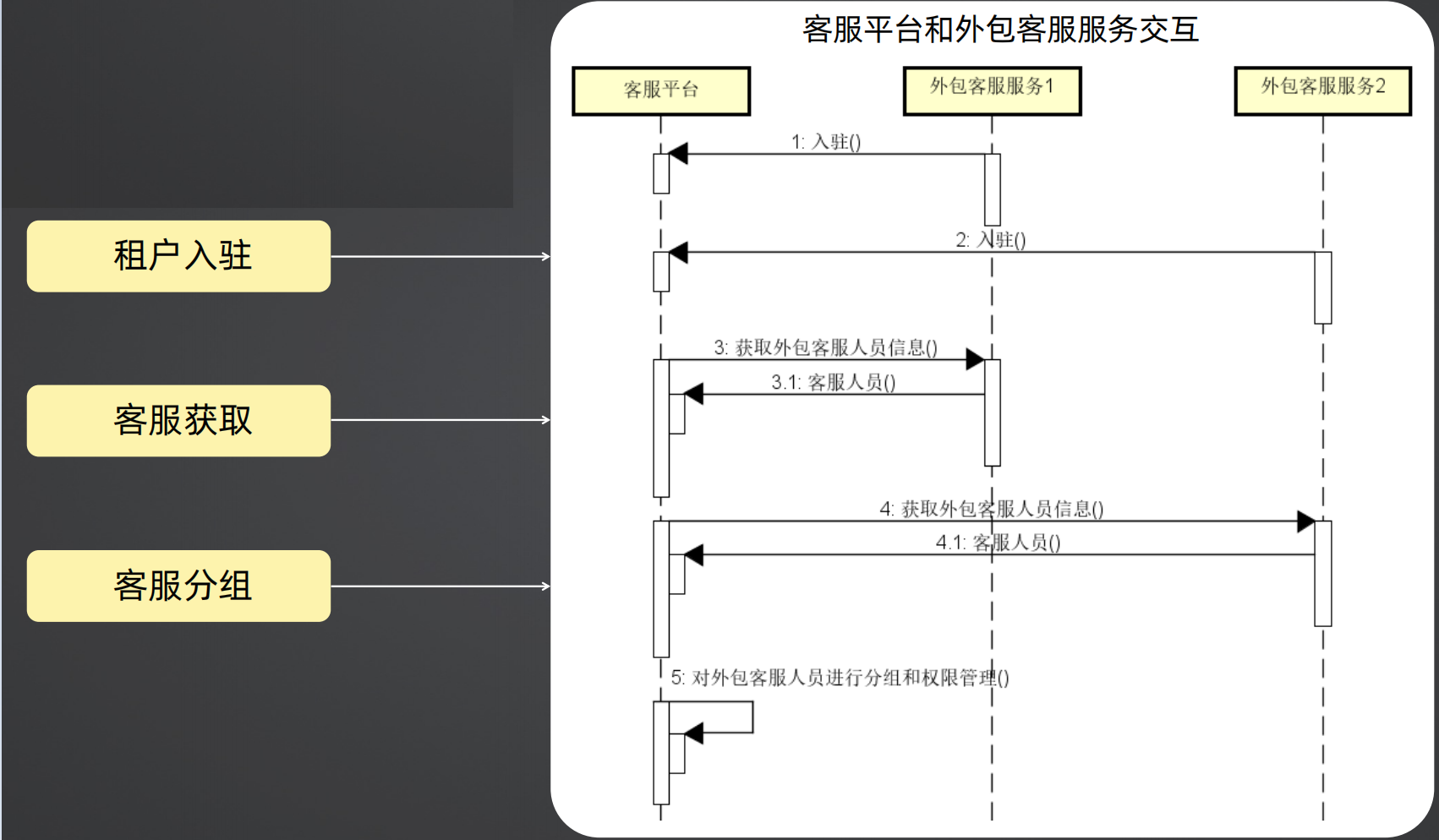
外包客服服务就是租户,作用是提供客服人员接入服务用户并获取运营收入,例如客服系统包含用户模块、客服模块、聊天模块、集成模块、管理模块以及其他模块,那么外包客服服务就是租户并进行入驻。
租户入驻和交互时序图:主要是外包客服服务入驻客服平台、客服平台从外包客服服务获取客服人员数据、客服平台对外包客服人员进行分组和权限管理,后续的流程就是客服平台自己的业务流程了。
关于客服平台如何从外包客服系统获取数据的问题,可以采用外部客服系统推送客服人员数据到客服平台,也可以采用客服平台从外部客服系统拉取客服人员数据。
由于存在两种数据同步情况,因此在设计租户表时,要兼顾这两种方式,如下表所示,使用系统访问URL字段来解决拉的场景,使用公钥私钥解决推的场景,具体的表设计如下:
CREATE TABLE `outsourcing_system` (
`id` BIGINT ( 20 ) NOT NULL AUTO_INCREMENT,
`system_name` VARCHAR ( 45 ) NOT NULL COMMENT '系统名称',
`description` VARCHAR ( 255 ) DEFAULT NULL COMMENT '系统描述',
`system_url` VARCHAR ( 45 ) NOT NULL COMMENT '系统访问URL',
`app_id` VARCHAR ( 45 ) NOT NULL COMMENT '系统Id',
`app_key` VARCHAR ( 255 ) NOT NULL COMMENT '数据公钥',
`app_secret` VARCHAR ( 255 ) NOT NULL COMMENT '数据私钥',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '客服外部系统'
业务表调整:采用第三种数据隔离方案,即共享数据库与表空间
CREATE TABLE `customer_staff` (
`id` BIGINT ( 20 ) NOT NULL AUTO_INCREMENT COMMENT '主键',
`group_id` BIGINT ( 20 ) DEFAULT NULL COMMENT '分组Id',
`staff_name` VARCHAR ( 45 ) NOT NULL COMMENT '客服姓名',
...
`system_id` BIGINT ( 20 ) DEFAULT NULL COMMENT '外部系统Id,非空标识该客服人员数据来自外部系统',
...
PRIMARY KEY ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '客服人员表'
设计好表之后同步新增实体类、Controller、Service、Mapper
二、实现跨服务HTTP请求和响应
(一)RestTemplate使用方式
一次HTTP请求过程包括构建请求对象(远程连接、网络请求等)、 执行远程调用(异常处理、状态码控制等)、数据结构转换(处理响应结果)
RestTemplate的优势:相较传统Apache中的HttpClient客户端工具类,RestTemplate对于编码的简便性以及异常的处理等方面都做了很多改进。
使用RestTemplate时,可以通过构造函数创建RestTemplate对象,如果不做多余的处理,直接使用无参构造即可,如果需要做一些特殊的设置,则使用有参构造。
// 无参构造创建RestTemplate
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
// 有参构造创建RestTemplate
@Bean
public RestTemplate customRestTemplate(){
HttpComponentsClientHttpRequestFactory httpRequestFactory = new
HttpComponentsClientHttpRequestFactory();
httpRequestFactory.setConnectionRequestTimeout(3000);
httpRequestFactory.setConnectTimeout(3000);
httpRequestFactory.setReadTimeout(3000);
return new RestTemplate(httpRequestFactory);
}
RestTemplate提供了很多方法,按照类别区分,有GET、POST、PUT、DELETE、Header、通用方法六类,其中GET包含getForObject和getForEntity,POST包含postForLocation、postForObject、postForEntity,PUT主要是put方法,DELETE是delete方法,Header是headForHeaders方法,这几种都是已经确定了访问类型后的具体操作,如果不确定,也可以使用通用方法,包括exchange和execute
指定URL和传递参数:
// URL中携带参数的Web请求,可以使用 PathVariable 的方式,也可以用 Parameter 的方式
("http://localhost:8082/account/{id}", 1)
("http://localhost:8082/account/{pageSize}/{pageIndex}", 20, 2)
("http://localhost:8082/account?pageSize=20&pageIndex=2")
// 通过Map对路径变量进行赋值
Map<String, Object> uriVariables = new HashMap<>();
uriVariables.put("pageSize", 20);
uriVariables.put("pageIndex", 2);
webClient.getForObject("http://localhost:8082/account/{pageSize}/{pageIndex}", Account.class, uriVariables);
// 直接通过对象对输入变量进行赋值
Order order = new Order();
order.setOrderNumber("Order0001");
order.setDeliveryAddress("DemoAddress");
restTemplate.postForEntity("http://localhost:8082/orders", order, Order.class);
get方法组:
getForEntity 方法的返回值是一个ResponseEntity对象,在这个对象中还包含了HTTP消息头等信息,而getForObject方法返回的则只是业务对象本身,这是两个方法组的主要区别。
public <T> T getForObject(URI url, Class<T> responseType)
public <T> T getForObject(String url, Class<T> responseType, Object... uriVariables){}
public <T> T getForObject(String url, Class<T> responseType, Map<String, ?> uriVariables)
Account result = restTemplate
.getForObject("http://localhost:8082/accounts/{accountId}", Account.class, accountId);
ResponseEntity<Account> result = restTemplate
.getForEntity("http://localhost:8082/accounts/{accountId}", Account.class, accountId);
Account account = result.getBody();
post方法组:
// 服务提供者
@RestController
@RequestMapping(value="orders")
public class OrderController {
@PostMapping(value = "")
public Order addOrder(@RequestBody Order order) {
Order result = orderService.addOrder(order);
return result;
}
}
// 通用实体对象
Order order = new Order();
// 服务访问
ResponseEntity<Order> responseEntity = restTemplate.postForEntity("http://localhost:8082/orders", order, Order.class);
return responseEntity.getBody();
exchange方法组:
一个通用且统一的方法,它既能发送GET和POST请求,也能用于其它各种类型的请求。
public <T> ResponseEntity<T> exchange(String url, HttpMethod method, @Nullable HttpEntity<?> requestEntity,
Class<T> responseType, Object... uriVariables) throws RestClientException
//普通用法
ResponseEntity<User> result = restTemplate.exchange("http://localhost:8080/users/{id}", HttpMethod.GET, null, User.class, 100);
//复杂用法
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON_UTF8); // 设置header
HashMap<String, Object> params = new HashMap<>();
params.put("orderNumber", orderNumber); // 设置对象属性
HttpEntity entity = new HttpEntity<>(params, headers); // 组装请求对象
ResponseEntity<Order> result = restTemplate.exchange(url, HttpMethod.GET, entity, Order.class); // 业务访问
实战技巧:
(1)指定消息转换器:用于在获取返回结果时的数据转换
RestTemplate 默认使用jackson进行数据的格式化,如果想要自己设置格式化,可以根据需要实现自定义的HttpMessageConverter并完成对RestTemplate的初始化,但是一般情况下RestTemplate默认的设置已经够使用了。
// RestTemplate 专门设置消息转换器的构造函数
public RestTemplate(List<HttpMessageConverter<?>> messageConverters) {
Assert.notEmpty(messageConverters, "At least one HttpMessageConverter required");
this.messageConverters.addAll(messageConverters);
}
// 使用 GsonHttpMessageConverter 做消息转换
@Bean
public RestTemplate restTemplate() {
List<HttpMessageConverter<?>> messageConverters = new ArrayList<HttpMessageConverter<?>>();
messageConverters.add(new GsonHttpMessageConverter());//添加一个GsonHttpMessageConverter
RestTemplate restTemplate = new RestTemplate(messageConverters);
return restTemplate;
}
(2)设置拦截器
通过实现ClientHttpRequestInterceptor接口,并调用setInterceptors方法可以将任何自定义的拦截器注入到RestTemplate的拦截器列表中。
下面这段代码来自Spring Cloud的LoadBalanceAutoConfiguration,为什么使用 Spring Cloud 的 @LoadBalanced注解,就可以做大服务调用的负载均衡,其就是对RestTemplate添加了拦截器,在拦截器中做了负载均衡处理。
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(
final LoadBalancerInterceptor loadBalancerInterceptor) {
return restTemplate -> {
List<ClientHttpRequestInterceptor> list = new ArrayList<>(
restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
restTemplate.setInterceptors(list);
};
}
(3)处理异常
在RestTemplate中,默认情况下当请求状态码不是返回200时就会抛出异常并中断接下来的操作,但是这种业务含义不强,同时一些网关的设置会将这些状态信息过滤掉后再返回,因为,有时我们会创建自己的一套状态码信息,那么就要通过覆盖来排除默认的 ResponseErrorHandler。
ResponseErrorHandler responseErrorHandler = new ResponseErrorHandler() {
@Override
public boolean hasError(ClientHttpResponse clientHttpResponse) throws IOException {
return true;
}
@Override
public void handleError(ClientHttpResponse clientHttpResponse) throws IOException {
//添加定制化的异常处理代码
}
};
RestTemplate restTemplate = new RestTemplate();
restTemplate.setErrorHandler(responseErrorHandler);
(二)WebClient使用方式
WebClilent是新一代的远程调用工具类,专门用于实现响应式编程下的远程调用。
创建WebClient:
可以使用工厂来无参方法或者有参方法创建,也可以使用构造器进行创建,在使用构造器创建时,可以设置相关的配置项。
这里和RestTemplate有一点点区别,RestTemplate主要关注的是请求的内容,而WebClient还会关注请求头相关的内容,可以进行设置。
//直接使用create()工厂方法来创建WebClient的实例
WebClient webClient = WebClient.create();
//使用baseUrl来初始化WebClient
WebClient webClient = WebClient.create("https://localhost:8081/accounts");
//使用构造器类Builder
WebClient webClient = WebClient.builder().build();
// 配置请求头
WebClient webClient = WebClient.builder()
.baseUrl("https://localhost:8081/accounts")
.defaultHeader(HttpHeaders.CONTENT_TYPE, "application/json")
.defaultHeader(HttpHeaders.USER_AGENT, "Reactive WebClient")
.build();
设置URL和参数:
可以通过uri方法中添加路径变量和参数值的方式进行设置,也可以通过Map对象传递路径变量和参数值的方式设置,也可以通过URIBuilder来获取对请求信息的完全控制
// 通过uri方法中添加路径变量和参数值
webClient.get().uri("http://localhost:8081/accounts/{id}", 100);
// 通过Map对象传递路径变量和参数值
Map<String, Object> uriVariables = new HashMap<>();
uriVariables.put("param1", "value1");
uriVariables.put("param2", "value2");
webClient.get().uri("http://localhost:8081/accounts/{param1}/{param2}", variables);
// 通过URIBuilder来获取对请求信息的完全控制
webClient.get().uri(uriBuilder -> uriBuilder.path("/accounts").build())
.header("Authorization", "Basic " + Base64Utils.encodeToString(token.getBytes(UTF_8)));
使用WebClient访问服务:
服务访问有retrieve 和 exchange两个方法:retrieve方法是获取响应主体并对其进行解码的最简单方法,而exchange与RestTemplate类似,可以使用对整个响应结果进行完整控制,该响应结果是一个ClientResponse对象,包含了响应的状态码、Cookie等信息
WebClient webClient = WebClient.create("http://localhost:8081");
Mono<Account> result = webClient.get().uri("/accounts/{id}", id)
.accept(MediaType.APPLICATION_JSON)
.retrieve()
.bodyToMono(Account.class);
Mono<Account> result = webClient.get().uri("/accounts/{id}", id)
.accept(MediaType.APPLICATION_JSON)
.exchange()
.flatMap(response -> response.bodyToMono(Account.class));
使用RequestBody:
RequestBody可以使用Mono封装的对象,也可以使用原始对象,如果请求体是Mono或者Flux类型的,需要使用body方法赋值,如果请求体是普通的对象,则需要使用syncBody方法赋值。
//请求体是Mono或Flux类型
Mono<Account> accountMono = ... ;
Mono<Void> result = webClient.post().uri("/accounts")
.contentType(MediaType.APPLICATION_JSON)
.body(accountMono, Account.class)
.retrieve()
.bodyToMono(Void.class);
//请求体是普通POJO类型
Account account = ... ;
Mono<Void> result = webClient.post().uri("/accounts")
.contentType(MediaType.APPLICATION_JSON)
.syncBody(account)
.retrieve()
.bodyToMono(Void.class);
WebClient实战技巧:
(1)请求拦截
逻辑就是在构建WebClient时,传入一个实现了ExchangeFilterFunction接口的过滤器,那么所有的请求访问时,都会先走过滤器。
过滤器的实现中,用到了类似管道过滤器模式,先将请求信息打印,然后调用next.exchange方法放行。
WebClient webClient = WebClient.builder().filter(logFilter()).build();
private ExchangeFilterFunction logFilter() {
return (clientRequest, next) -> {
logger.info("Request: {} {}", clientRequest.method(), clientRequest.url());
clientRequest.headers()
.forEach((name, values) -> values.forEach(value -> logger.info("{}={}", name, value)));
return next.exchange(clientRequest);
};
}
(2)异常处理
可以针对指定返回状态进行设置,在onStatus方法中,设置HttpStatus的状态是指定的状态是,向clientResponse中放入WebClientResponseException异常,同时该异常信息支持定制化。
public Flux<Account> listAccounts() {
return webClient.get().uri("/accounts)
.retrieve()
.onStatus(HttpStatus::is4xxClientError, clientResponse ->
Mono.error(new MyCustomClientException())
)
.onStatus(HttpStatus::is5xxServerError, clientResponse ->
Mono.error(new MyCustomServerException())
)
.bodyToFlux(Account.class);
(三)系统案例演进
首先创建一个RestTemplate,可以放到启动类里面设置
public class CustomerSystemApplication {
public static void main(String[] args) {
SpringApplication.run(CustomerSystemApplication.class, args);
}
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
然后就可以在系统中使用了
@Autowired
private RestTemplate restTemplate;
ResponseEntity<Order> responseEntity = restTemplate.postForEntity("http://localhost:8082/orders", order, Order.class);
三、RestTemplate实现原理剖析
(一)RestTemplate设计思想
RestTemplate实现了RestOperations接口,同时继承了interceptingHttpAccessor抽象类。
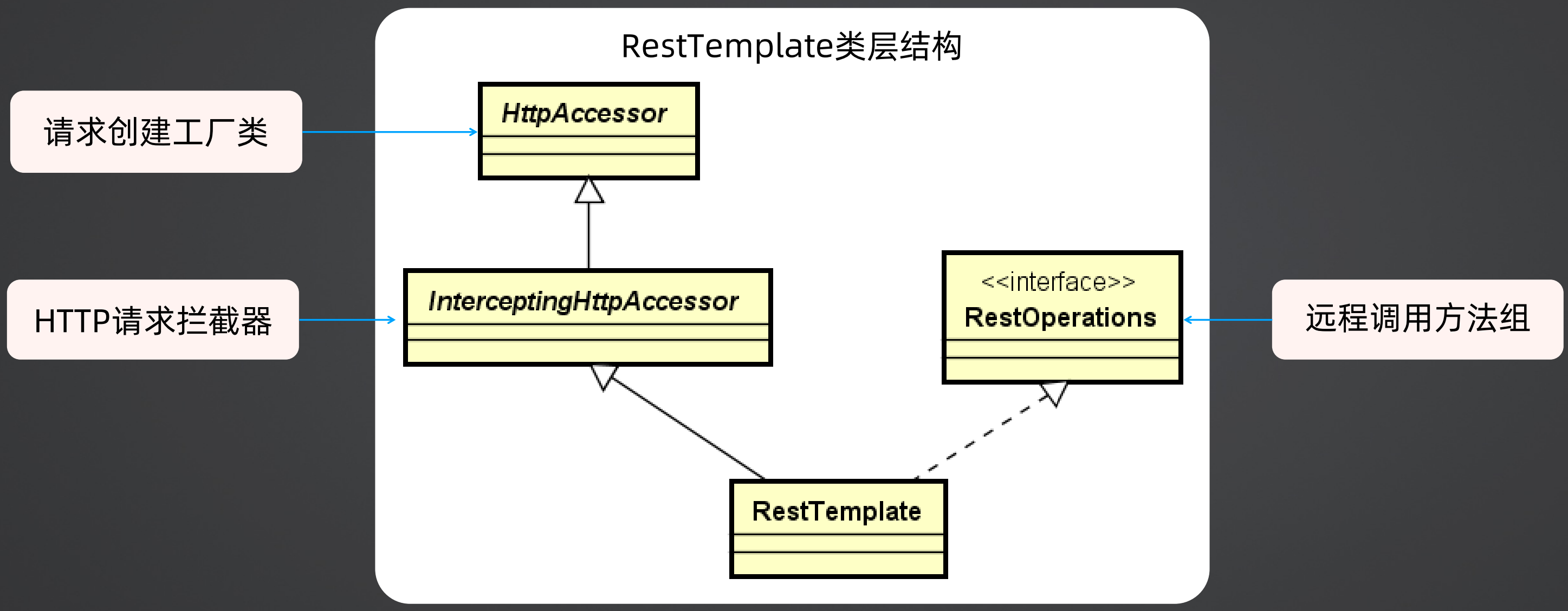
RestOperations接口中定义了所有get/post/put/delete/exchange等远程调用方法组,而这些方法都是遵循RESTful架构风格而设计的
public interface RestOperations {
<T> T getForObject(String url, Class<T> responseType, Object... uriVariables);
<T> ResponseEntity<T> getForEntity(String url, Class<T> responseType, Object... uriVariables);
<T> T postForObject(String url, @Nullable Object request, Class<T> responseType,Object... uriVariables);
void put(String url, @Nullable Object request, Object... uriVariables);
void delete(String url, Object... uriVariables);
<T> ResponseEntity<T> exchange(String url, HttpMethod method, @Nullable HttpEntity<?> requestEntity, Class<T> responseType, Object... uriVariables);
......
}
InterceptingHttpAccessor抽象类主要分为ClientHttpRequestInterceptor和ClientHttpRequestFactory两部分,ClientHttpRequestInterceptor主要是设置和管理请求拦截器,ClientHttpRequestFactory负责获取用于创建客户端HTTP请求的工厂类。
public abstract class InterceptingHttpAccessor extends HttpAccessor {
private final List<ClientHttpRequestInterceptor> interceptors = new ArrayList<>();
private volatile ClientHttpRequestFactory interceptingRequestFactory;
......
}
InterceptingHttpAccessor抽象类继承了HttpAccessor抽象类,HttpAccessor抽象类是真正完成ClientHttpRequestFactory的创建以及通过ClientHttpRequestFactory获取代表客户端请求的ClientHttpRequest对象
public abstract class HttpAccessor {
private ClientHttpRequestFactory requestFactory = new SimpleClientHttpRequestFactory();
......
}
RestTemplate设计思想总结:根据上面类的继承关系,RestTemplate主要用到了接口隔离原则,即用接口和抽象类分别提供了与HTTP请求相关的实现机制和基于RESTful风格的操作入口。
(二)RestTemplate远程调用执行流程
HTTP请求的标准处理主要分为三步,分别是构建请求对象(远程连接、网络请求等)、执行远程调用(异常处理、状态码控制等)、处理响应结果(数据结构转换)
远程调用入口exchange方法:对于RestTemplate,通用的远程调用方法是exchange方法,核心流程包括构建请求回调、构建响应体提取器、执行远程调用
@Override
public <T> ResponseEntity<T> exchange(String url, HttpMethod method, @Nullable HttpEntity<?> requestEntity, Class<T> responseType,
Object... uriVariables) throws RestClientException {
//构建请求回调
RequestCallback requestCallback = httpEntityCallback(requestEntity, responseType);
//构建响应体提取器
ResponseExtractor<ResponseEntity<T>> responseExtractor = responseEntityExtractor(responseType);
//执行远程调用
return nonNull(execute(url, method, requestCallback, responseExtractor, uriVariables));
}
远程调用的实际触发点doExecute方法:关于远程调用,就是上面说的三个步骤,创建请求对象、获取调用结果(远程调用)、处理调用结果,其中在创建请求对象后,有一个回调操作,这个就是上面构建的请求回调,这一步就会进行回调。
protected <T> T doExecute(URI url, @Nullable HttpMethod method, @Nullable RequestCallback requestCallback, @Nullable
ResponseExtractor<T> responseExtractor) throws RestClientException {
ClientHttpResponse response = null;
try {
//1.创建请求对象
ClientHttpRequest request = createRequest(url, method);
if (requestCallback != null) {
//执行对请求对象的回调
requestCallback.doWithRequest(request);
}
//2.获取调用结果
response = request.execute();
//3.处理调用结果,并使用结果提取从结果中提取数据
handleResponse(url, method, response);
return (responseExtractor != null ? responseExtractor.extractData(response) : null);
}
......
}
(1)创建请求对象
创建请求对象createRequest方法:在创建请求对象这一步,主要使用了JDK中的HttpURLConnection客户端,同时再设置超时时间、请求方法等常见属性,然后根据请求的设置,返回一个批处理的请求对象或者返回一个单一的请求对象。
public interface ClientHttpRequestFactory {
//创建客户端请求对象
ClientHttpRequest createRequest(URI uri, HttpMethod httpMethod) throws IOException;
}
public SimpleClientHttpRequestFactory implements ClientHttpRequestFactory {
......
@Override
public ClientHttpRequest createRequest(URI uri, HttpMethod httpMethod) throws IOException {
// 使用JDK中的HttpURLConnection客户端
HttpURLConnection connection = openConnection(uri.toURL(), this.proxy);
// 超时时间、请求方法等常见属性的设置
prepareConnection(connection, httpMethod.name());
if (this.bufferRequestBody) {
// 执行批处理或流处理
return new SimpleBufferingClientHttpRequest(connection, this.outputStreaming);
}
else {
return new SimpleStreamingClientHttpRequest(connection, this.chunkSize, this.outputStreaming);
}
}
}
回调样例:上面提到,对于执行请求回调的逻辑,是回调请求中设置的回调方法,例如下面的代码,在通过RestTemplate调用时,添加了一个回调方法,该方法使用map设置参数,然后使用消息转换器FormHttpMessageConverter将map放入request请求对象中。
那么在执行远程调用的doExecute方法中,创建完请求对象后,就会调用该回调方法,将参数设置到request请求对象上。
public interface RequestCallback {
//对请求对象执行回调
void doWithRequest(ClientHttpRequest request);
}
//示例:通过请求回调添加请求参数
new RestTemplate().execute(url,HttpMethod.POST, new RequestCallback(){
@Override
public void doWithRequest(ClientHttpRequest request) throws IOException{
MultiValueMap<String, String> map=new LinkedMultiValueMap<>();
map.add("username",user);
map.add("password",password);
new FormHttpMessageConverter().write(map,MediaType.APPLICATION_FORM_URLENCODED,request);
}
},...);
(2)执行远程调用:
远程调用执行的是request.execute()方法,这个request是ClientHttpRequest接口,实际上一般用的是SimpleBufferingClientHttpRequest类,该类的继承关系以及与ClientHttpRequest接口的关系如下所示。
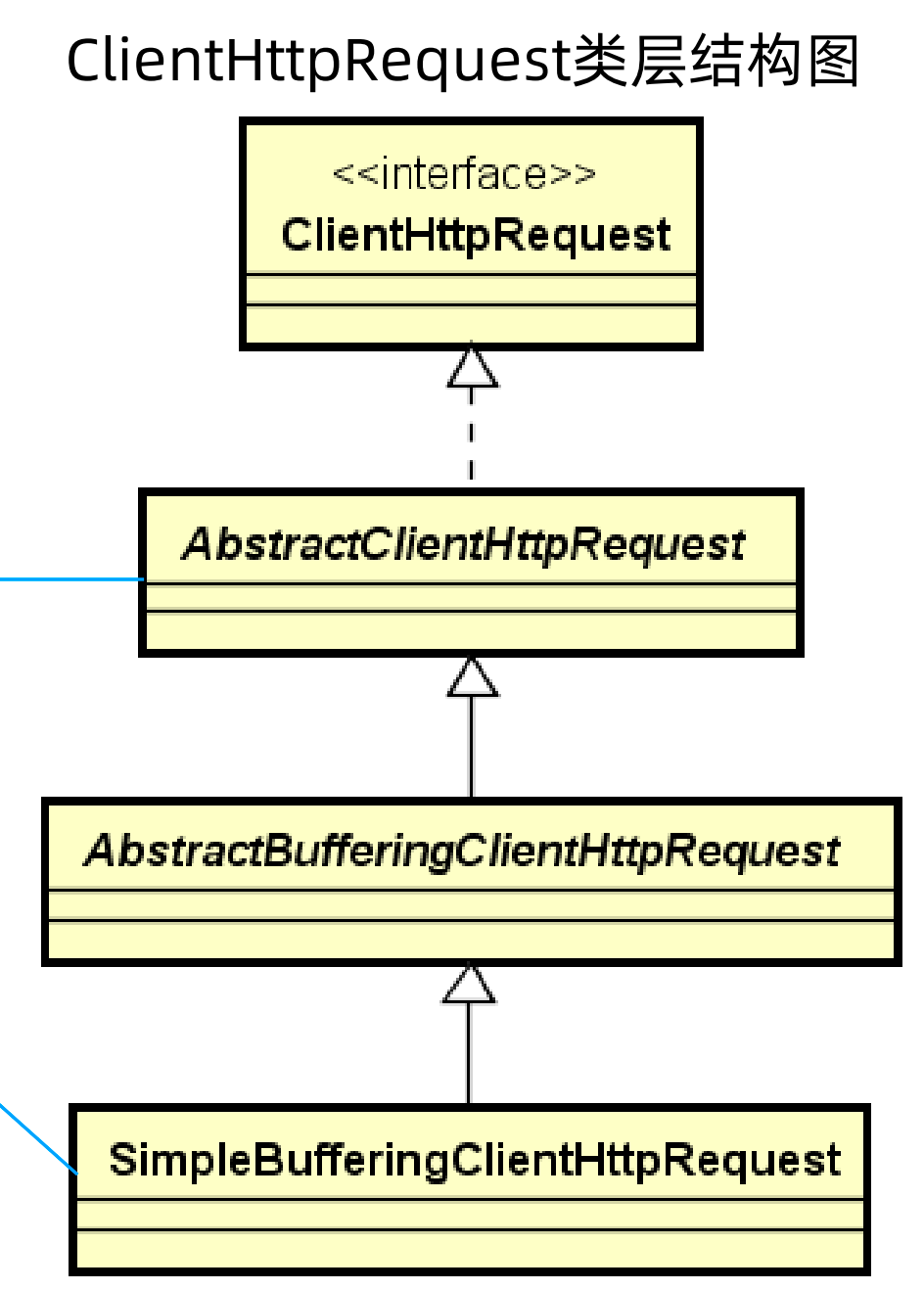
execute方法最终会调用到executeInternal方法,在该方法中使用了JDK自带的HttpURLConnection进行远程访问,访问后通过FileCopyUtils.copy()工具方法将响应结果写入到输出流
ClientHttpResponse response = null;
try{
......
//2.获取调用结果
response=request.execute();
......
}
@Override
protected ClientHttpResponse executeInternal(HttpHeaders headers,byte[]bufferedOutput)throws IOException{
addHeaders(this.connection,headers);
if(getMethod()==HttpMethod.DELETE&&bufferedOutput.length==0){
this.connection.setDoOutput(false);
}
if(this.connection.getDoOutput()&&this.outputStreaming){
this.connection.setFixedLengthStreamingMode(bufferedOutput.length);
}
this.connection.connect();
if(this.connection.getDoOutput()){
// 通过FileCopyUtils.copy()工具方法将响应结果写入到输出流
FileCopyUtils.copy(bufferedOutput,this.connection.getOutputStream());
}
else{
this.connection.getResponseCode();
}
return new SimpleClientHttpResponse(this.connection);
}
(3)处理响应结果:
handleResponse(url, method, response)方法用来处理错误并抛出异常,而下面的extractData方法是通过ResponseExtractor解析去请求结果。
ClientHttpResponse response = null;
try{
......
//3.处理调用结果,并使用结果提取从结果中提取数据
handleResponse(url,method,response); // 处理错误并抛出异常
// 通过ResponseExtractor解析去请求结果
return(responseExtractor!=null?responseExtractor.extractData(response):null);
......
}
在extractData方法中,通过HttpMessageConverter转换数据结构
private class ResponseEntityResponseExtractor<T> implements ResponseExtractor<ResponseEntity<T>> {
@Nullable
private final HttpMessageConverterExtractor<T> delegate;
......
// 通过ResponseExtractor解析去请求结果
// 通过HttpMessageConverter转换数据结构
@Override
public ResponseEntity<T> extractData(ClientHttpResponse response) throws IOException {
if (this.delegate != null) {
T body = this.delegate.extractData(response);
return ResponseEntity.status(response.getRawStatusCode()).headers(response.getHeaders()).body(body);
}
......
}
}
下面是常用的HttpMessageConverter名称以及其支持的MediaType:
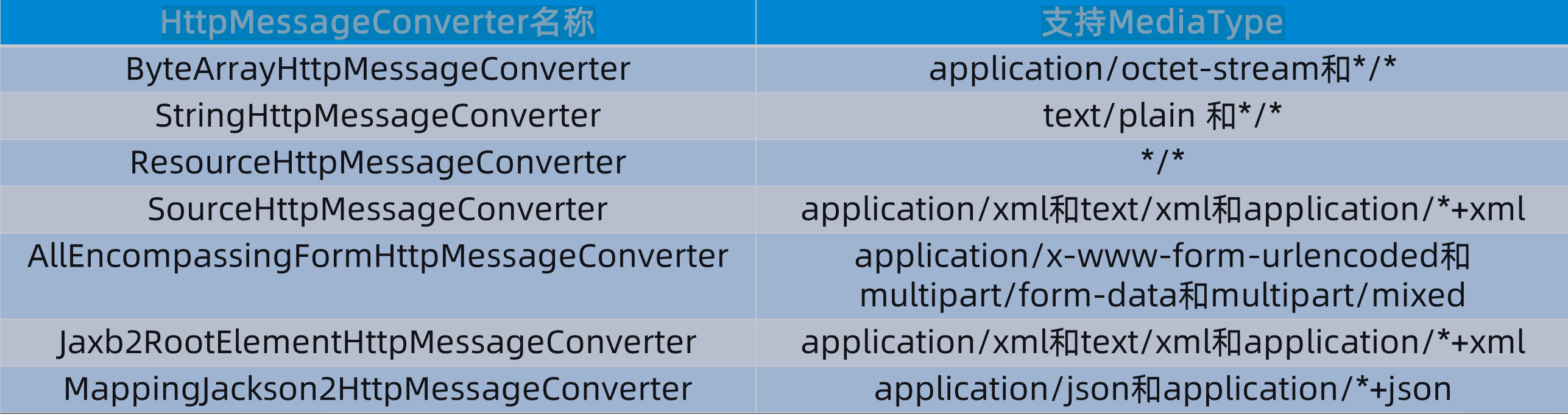
例如下面是StringHttpMessageConverter,内容就是将信息转换为String并返回。实际上我们也可以使用自定义的MessageConverter,但是一般情况下我们不需要自定义,因为RestTemplate已经帮我们定义好了。
@Override
protected String readInternal(Class<? extends String> clazz, HttpInputMessage inputMessage) {
Charset charset = getContentTypeCharset(inputMessage.getHeaders().getContentType());
// StringHttpMessageConverter
return StreamUtils.copyToString(inputMessage.getBody(), charset);
}
基于以上分析,在RestTemplate中,涉及的设计模式包括工厂模式(创建请求对象)、回调机制(执行对请求的回调)、模板方法模式(获取调用结果)
四、基于xxl-job实现数据同步机制
(一)任务调度的基本概念
任务调度的场景:
时间驱动的场景:某个时间点发送优惠券等
批量处理数据的场景:批量统计上个月报表数据等
固定频率的场景:每隔一天执行一次(T+1)等
任务调度(定时任务),是指系统中基于给定时间点,给定时间间隔或者给定执行次数自动执行任务,系统是指我们的业务系统,集群一般是集群化的,同时要具备容错性、管理性,而时间点、执行间隔、执行次数要做到可配置和热更新。
任务调度的开源方案包括单体架构和分布式集群架构,单体架构包括Quartz 和 Spring Task,其中Quartz通过独占锁来保证只有一个节点执行,而Spring Task 是 Spring自带任务调度器,容易上手;分布式集群架构目前流行的有Elastic-job和xxl-job,其中Elastic-job是一个重量级的框架,依赖Zookeeper,xxl-job是一个轻量级的框架,主打开箱即用。
Java自带的执行器:
Executor:启动新任务的简单接口,不要求执行过程异步执行
ExecutorService:允许我们传递一个异步执行任务,返回Future对象
ScheduledExecutorService:通过各种方法将任务调度到给定延迟或周期后执行
Spring任务调度器:
使用 @EnableScheduling注解 + @Scheduled注解,Spring将自动注册一个内部后置处理器BeanPostProcessor,它将在Spring容器管理的Bean上找到添加了@Scheduled注解的方法,找到后会启动一个ExecutorService来实现定时任务调度。
@Configuration
@EnableScheduling
public class SpringSchedulingApplication
@Scheduled(fixedDelay = 2000)
public void scheduledTask() {
LOGGER.info("Execute task " + new Date());
}
Cron表达式
*/5 * * * * ? 每隔5秒执行一次
0 */1 * * * ? 每隔1分钟执行一次
0 0 5-15 * * ? 每天5-15点整点触发
0 0/3 * * * ? 每三分钟触发一次
0 0/30 9-17 * * ? 朝九晚五工作时间内每半小时
0 0 10,14,16 * * ? 每天上午10点,下午2点,4点
\* 表示所有值;
? 表示未说明的值,即不关心它为何值;
\- 表示一个指定的范围;
, 表示附加一个可能值;
/ 符号前表示开始时间,符号后表示每次递增的值;
(二)xxl-job应用方式
xxl-job是一个轻量级的分布式任务调度框架,通过一个中心式的调度平台,调度多个执行器执行任务,并提供可视化监控界面。

任务调度中心数据模型(数据表):
xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息
xxl_job_group:任务分组表,维护任务执行器信息
xxl_job_info:任务信息表: 用于保存任务扩展信息,如执行参数等
xxl_job_log:调度日志表: 用于保存任务调度的日志信息,如调度结果等
xxl_job_lock:任务调度锁表:用于实现任务执行的一致性
xxl_job_user:系统用户表:用于保存系统用户信息
使用xxl-job主要分为三步:搭建任务调度中心、客户端配置、在调度中心配置定时任务,具体的步骤详见:xxl-job搭建、部署、SpringBoot集成xxl-job
但是新版本的 xxl-job 和 老版本的 xxl-job 在使用上还是有一些差别的
(1)差别一:执行任务的配置
老版本:在类上使用@JobHandler直接标记一个任务,该类集成 IJobHandler 类,重写 execute 方法即可。
@JobHandler(value = "demoHandler")
@Component
@Slf4j
public class Demo1Handler extends IJobHandler {
@Override
public ReturnT<String> execute(String s) throws Exception {
XxlJobLogger.log("xxl-job测试任务开始执行。【args: {}】", s);
try {
log.info("========demo");
XxlJobLogger.log("xxl-job测试任务执行结束。");
return SUCCESS;
} catch (Exception e) {
XxlJobLogger.log("xxl-job测试任务执行出错!", e);
return FAIL;
}
}
}
新版本:在方法上使用@XxlJob注解标记一个任务
@Component
@Slf4j
public class Demo2Handler {
@XxlJob("demoHandler")
public ReturnT<String> execute(String s) throws Exception {
try {
log.info("========demo");
return ReturnT.SUCCESS;
} catch (Exception e) {
return ReturnT.FAIL;
}
}
}
(2)差别二:配置类appname字段的变更
老版本叫appName,新版本叫appname
(三)客服系统案例演进
客服数据同步场景分析:通过定时任务拉取外包客服系统数据
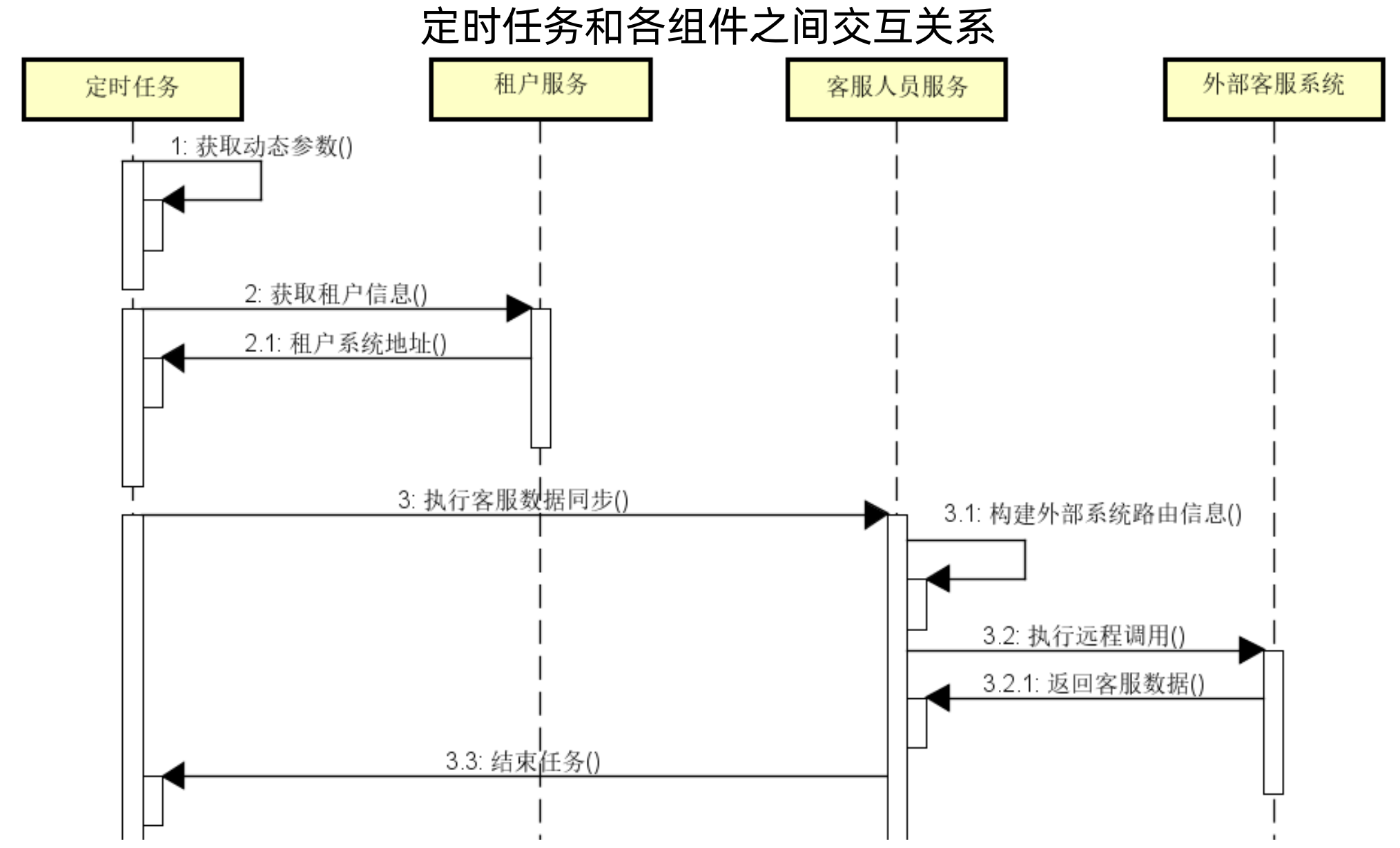
(1)引入依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>
(2)添加配置
xxl:
job:
accessToken: lcl-token
executor:
appname: customer-system
ip:
logpath: /workspace/customer-system/customer-system-monolith/logs
logretentiondays: -1
port: 9999
admin:
addresses: http://localhost:8888/xxl-job-admin
(3)注册类
@Configuration
@Slf4j
public class XXlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean(initMethod = "start", destroyMethod = "destroy")
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appName);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
(4)调度任务
@Component
@Slf4j
public class CustomerStaffSyncJobHandler {
@Autowired
private ICustomerStaffService customerStaffService;
@XxlJob("syncCustomerStaffJob")
public ReturnT<String> syncCustomerStaff() throws Exception{
log.info("{} ====== syncCustomerStaffJob ====== 同步客服信息");
// 使用钩子函数获取参数
String param = XxlJobHelper.getJobParam();
Long systemId = Long.parseLong(param);
// 远程调用,获取客服信息并保存
customerStaffService.syncGetOutsourcingCustomerStaffBySystemId(systemId);
return ReturnT.SUCCESS;
}
}
五、xxl-job高级特性和执行原理解析
(一)任务调度的设计方法
如果让我们自己设计一个任务调度框架,那么就要知道任务调度的流程:首先执行器要在调度器上注册,注册完成后,调度器按照时间设置进行调度,然后调用执行器执行任务,任务执行完成后,执行器返回调度器执行结果,调度器处理调度结果。
如何实现任务调度过程和业务代码之间的解耦?
(2)如果确保在集群环境下不会重复多次支持同一个调度任务?
(3)如何确定具体由哪一个服务实例来执行调度任务?
(4)如果同一个调度任务在短时间内被重复触发,应该怎么办?
(5)如果调度任务执行失败了,应该怎么办?
针对以上五个问题,分别对应以下五点设计原则:
(1)职责分离原则:也就是如何将任务调度过程和业务代码解耦
(2)执行一致性:也就是如何确保在集群环境下不会重复多次支持同一个调度任务
(3)调用路由策略:如何确定具体由哪一个服务实例来执行调度任务
(4)阻塞处理策略:如果同一个调度任务在短时间内被重复触发,应该怎么办?
(5)容错策略:如果调度任务执行失败了,应该怎么办
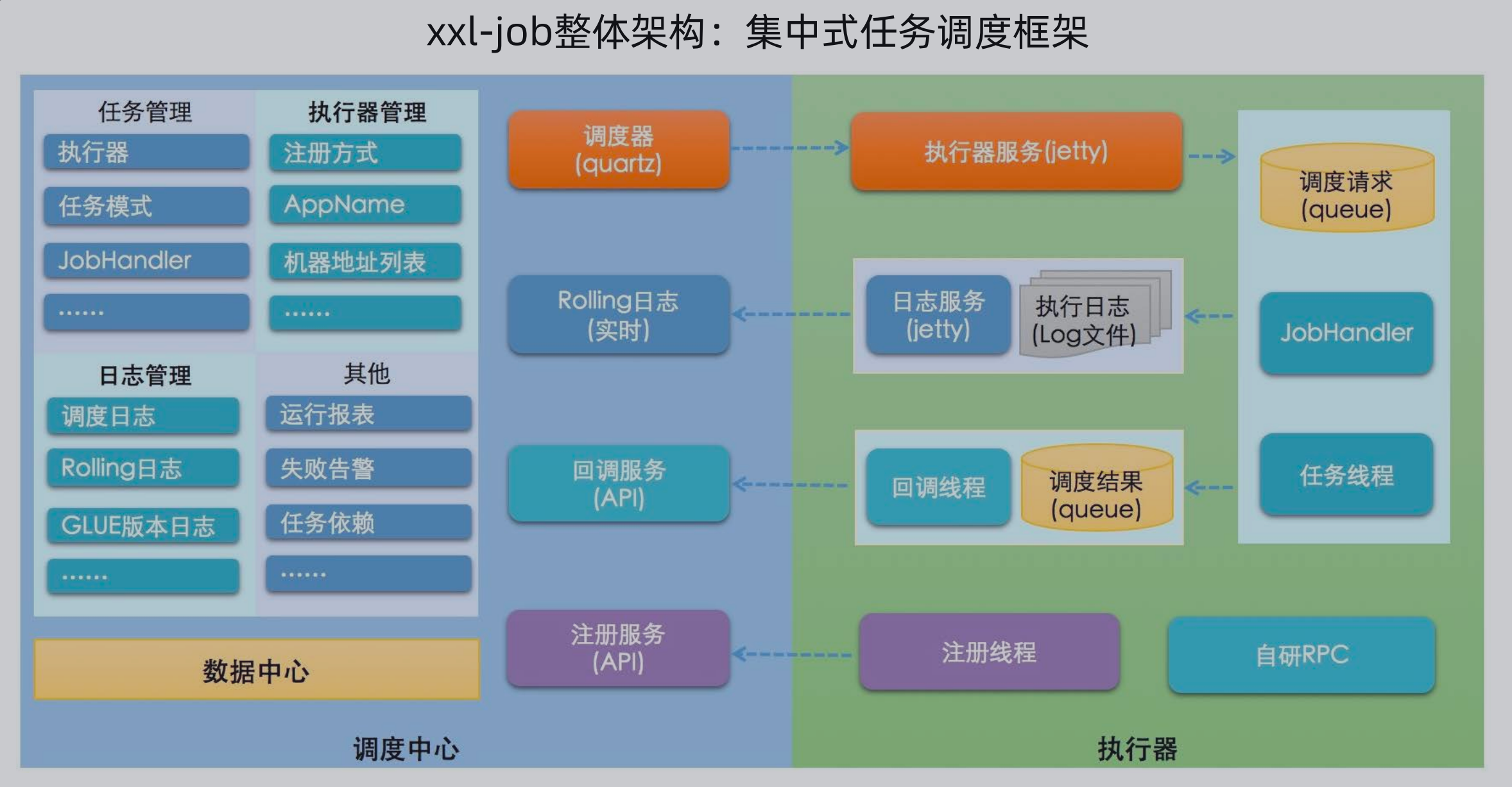
下图 xxl-job 整体架构:
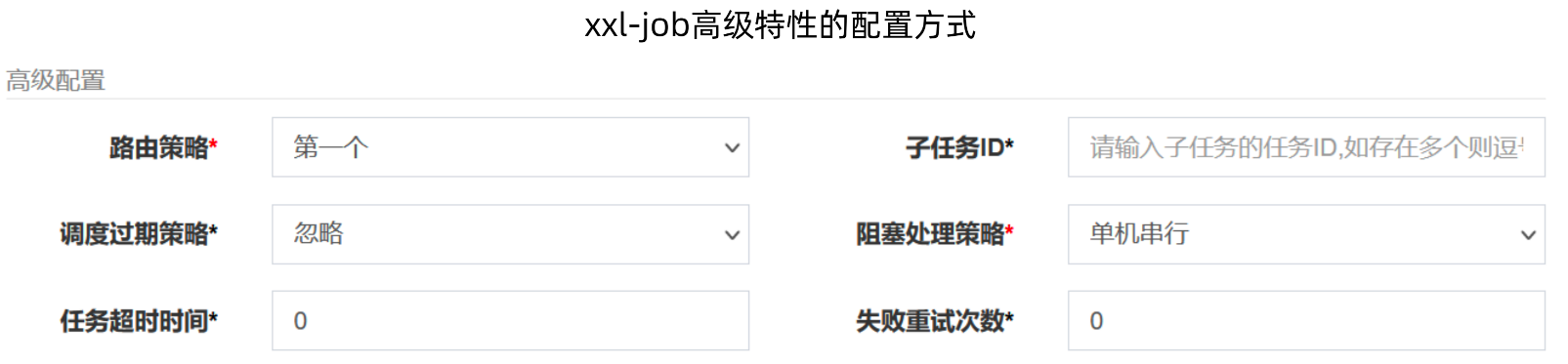
(二)xxl-job调度和执行机制
xxl-job在配置任务时,有高级配置的选项,其实这个选项中的内容,就是xxl-job对于以上问题的解决方案。
(1)职责分离
xxl-job调度是采用典型的分层架构(三层架构),首先有调度中心,也就是xxl-job的服务器端,然后有多个执行器,每个执行器对应一个服务,每个服务又有多个实例,每个实例中又有多个任务。
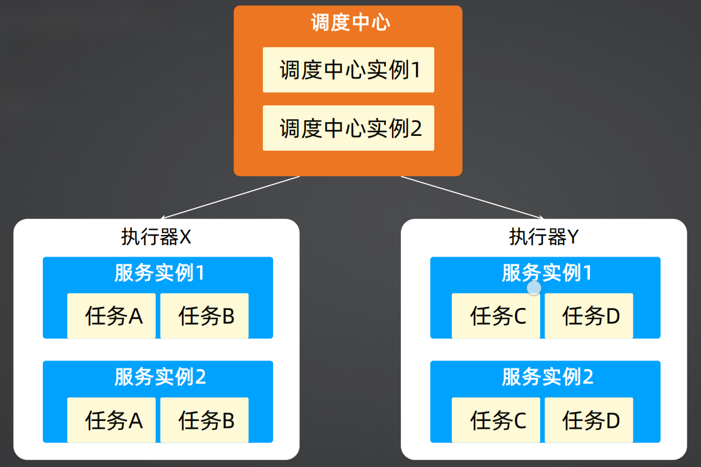
(2)三层架构协作流程:
调度中心(服务端)暴露HTTP接口让执行器调用,执行器在启动时,通过调度中心提供的接口进行注册,注销的时候通过接口进行注销,同时执行器维护一个30秒的心跳,没30秒调用一次调度中心的心跳接口。
调用中心中有一个调度器,会接受客户端的注册和注销请求,并调用执行器管理线程处理,最终将数据存入xxl_job_registry表,同时还维护了一个探活线程,每30秒扫描一次xxl_job-registry表,查看有哪些执行器已经超过了心跳时间,如果已经超过心跳检测阈值,则剔除该执行器。

上面提到的是任务的注册和注销流程,关于任务的调度,可以有三种方案:
方案一:启动线程,计算任务执行时间到当前时间的秒数,直接sleep。这种方式每一个任务都需要启动一个线程,造成资源的浪费
方案二:只用一个守护线程循环扫描任务数据,拿执行时间距离当前最近的任务,判断是否已到执行时间。这种方式如果某一个任务执行时间太长,会阻塞其他任务的正常执行
方案三:一个线程为调度线程,另外有一个线程池为执行线程池,可以一定程度避免长任务阻塞的问题。这种方式循环查询数据比较简单粗暴,不够优雅
而xxl-job采用了时间轮的设计思路,以刻度为依据,然后每个刻度对应要执行的任务。
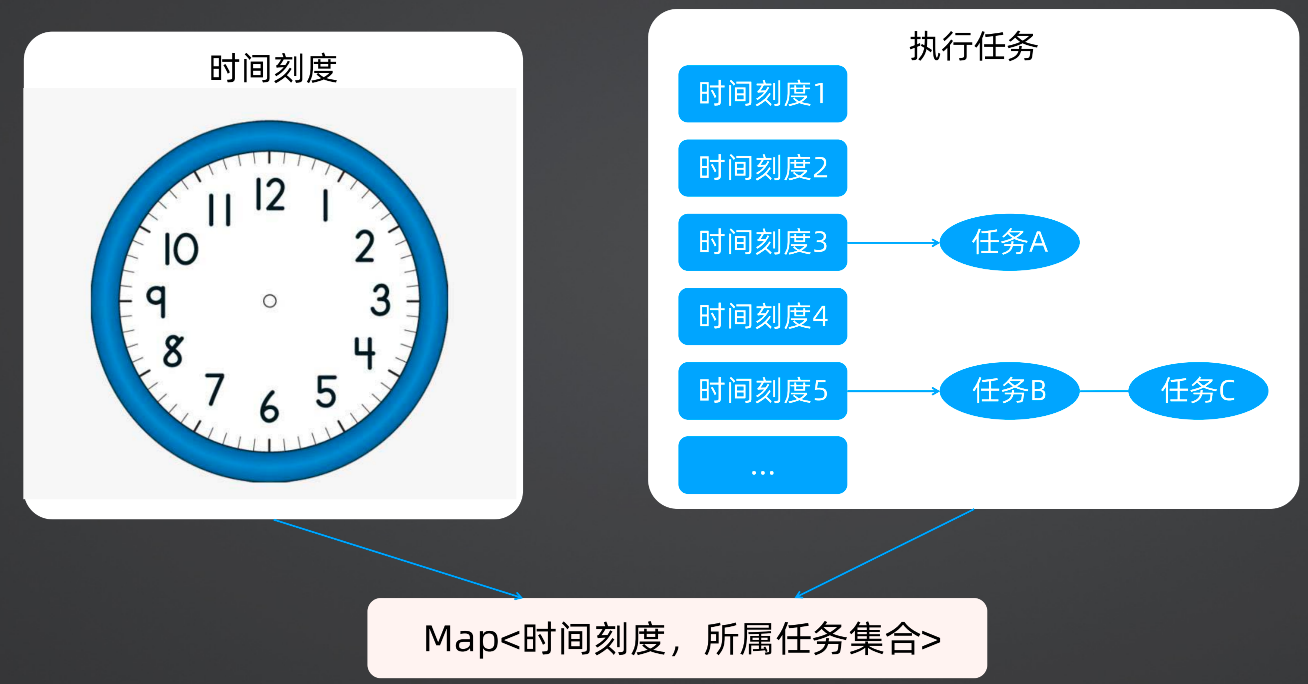
xxl-job实现的是一个5秒一次的定时任务调度,同时对未来5秒将被执行的任务,使用一个范围为一分钟、刻度为秒的时间轮算法来执行。Map<Integer, List<Integer>>,其中key是秒数(1-60) ,value是任务id列表。
每一个任务都有一个TriggerNextTime属性,用于刷新下一次触发调度的时间。
(3)执行一致性:如何确保在集群环境下不会重复多次支持同一个调度任务,也就是一个任务不被多个实例执行
xxl-job使用了数据库作为分布式锁,第一个触发的实例,会拿到锁,后续的其他实例不会拿到锁。
分布式锁的实现方案:
首先使用setAutoCommit(false)关闭隐式自动提交事务,对应数据库的set autocommit=0;
启动事务,对应数据库的begin;
select lock for update开启显式排他锁,对应数据库 select ... for update;
读取数据库任务、拉任务到时间轮、更新数据库任务,这一步是上一步查询成功(拿到锁)后,开始执行调度逻辑
commit提交事务,释放for update的排他锁,对应数据库的 commit;
(4)调用路由策略:
xxl-job支持的路由策略有第一个、最后一个、轮询、随机、一致性hash、最不经常使用、最近最久未使用、故障转移、忙碌转移、分片广播
这里简单看一下第一个和随机这两个策略,相对都是比较简单的,第一个策略直接返回了地址列表的第一个,随机策略使用 JDK 自带的随机数获取一个随机值,该随机值就是地址列表的下标。
//第一个策略
public class ExecutorRouteFirst extends ExecutorRouter {
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
return new ReturnT<String>(addressList.get(0));
}
}
//随机策略
public class ExecutorRouteRandom extends ExecutorRouter {
private static Random localRandom = new Random();
@Override
public ReturnT route(TriggerParam triggerParam, List addressList) {
String address = addressList.get(localRandom.nextInt(addressList.size()));
return new ReturnT(address);
}
}
(5)阻塞处理策略:
xxl-job提供了三种阻塞处理策略,单机串行、丢弃后继续调度、覆盖之前调度,其中单机串行吃默认的,但是推荐的使用方式的丢弃后继续调度,而覆盖之前的调度是不推荐是用的。
单机串行(Serial execution,默认):调度进入单机执行器后,调度请求进入FIFO队列中并以串行方式运行。通常不建议使用这种方式,有可能会导致阻塞的任务越来越多。
丢弃后续调度(Discard Later,推荐):调度请求进入单机执行器,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败
覆盖之前调度(Cover Early,不推荐):调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度
下面是阻塞处理策略的代码,首先从执行参数中获取阻塞策略,如果是单机串行就什么也不做,如果是丢弃后续调度策略,判断如果任务正在执行,直接返回异常结果,不再往下执行任务,如果是覆盖之前调度策略,会将当前执行的线程置位null,让其不再执行。
public ReturnT<String> run(TriggerParam triggerParam) {
......
if (jobThread != null) {
//从执行参数中获取阻塞策略
ExecutorBlockStrategyEnum blockStrategy =
ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);
//丢弃后续调度策略
if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {
// discard when running 如果任务正在执行,直接返回结果,不再往下执行任务
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:
"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}
} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {
//覆盖之前调度策略
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:" +
ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
//直接释放线程引用
jobThread = null;
}
} else {
// 单机串行策略,什么都不用做
}
}
}
(6)容错策略
一次完整任务调度过程包括调度阶段和执行阶段,这两个阶段肯定都会发生超时和重试,但是对于调度阶段,会有故障转义的处理。
容错策略有Failove、FailFast、FailSafe、FailBack等等,下面代码是Failover的代码,failover就是故障转移,循环所有的执行器,逐个调用,如果有一个调用成功,则返回成功,如果调用失败,则换下一个继续调用,如果轮询一遍后还没有调用成功,则最终返回调用失败。
public class ExecutorRouteFailover extends ExecutorRouter {
@Override
public ReturnT<String> route(TriggerParam triggerParam, List<String> addressList) {
StringBuffer beatResultSB = new StringBuffer();
for (String address : addressList) {
//按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度
ReturnT<String> beatResult = null;
try {
ExecutorBiz executorBiz = XxlJobScheduler.getExecutorBiz(address);
beatResult = executorBiz.beat();
} catch (Exception e) {
logger.error(e.getMessage(), e);
beatResult = new ReturnT<String>(ReturnT.FAIL_CODE, ""+e );
}
......
// beat success
if (beatResult.getCode() == ReturnT.SUCCESS_CODE) {
......
return beatResult;
}
}
return new ReturnT<String>(ReturnT.FAIL_CODE, beatResultSB.toString());
}
}
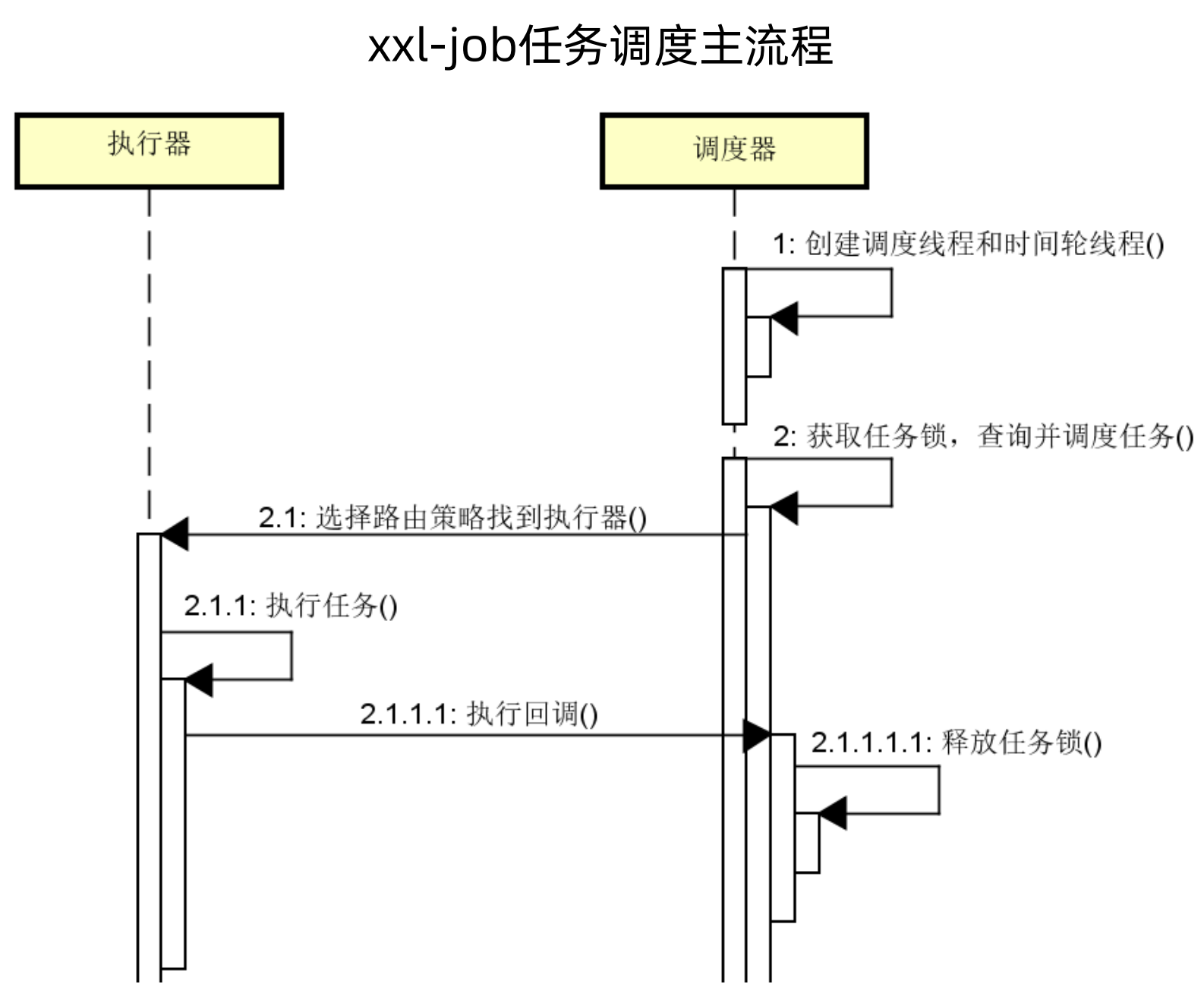
基于上面xxl-job对于一些常见问题的解决,xxl-job任务调度整体流程如下图所示:
(1)首先调度器创建调度线程和时间轮线程
(2)然后获取任务锁,查询并调度任务
(3)选择路由策略找到对应的执行器
(4)任务执行
(5)执行完成后做回调
(6)调度器释放任务锁
六、基于总线机制重构集成系统
(一)企业集成模式
系统集成(数据传输)的基本方式有文件传输(File Transfer) 、共享数据库(Shared DB) 、远程过程调用(RPC) 、消息传递(Messaging)
系统集成的核心需求:
(1)数据如何到达目标应用系统?
(2)如何基于业务场景对数据进行过滤?
(3)如何消除数据格式所导致的集成依赖?
(4)业务系统如何与集成机制实现交互解耦?
下图是企业集成的一个通用模式,消息提供方通过通道进行推送,然后经过路由器,路由到指定系统,该系统通过转换器将消息转换为自己想要的数据结构。
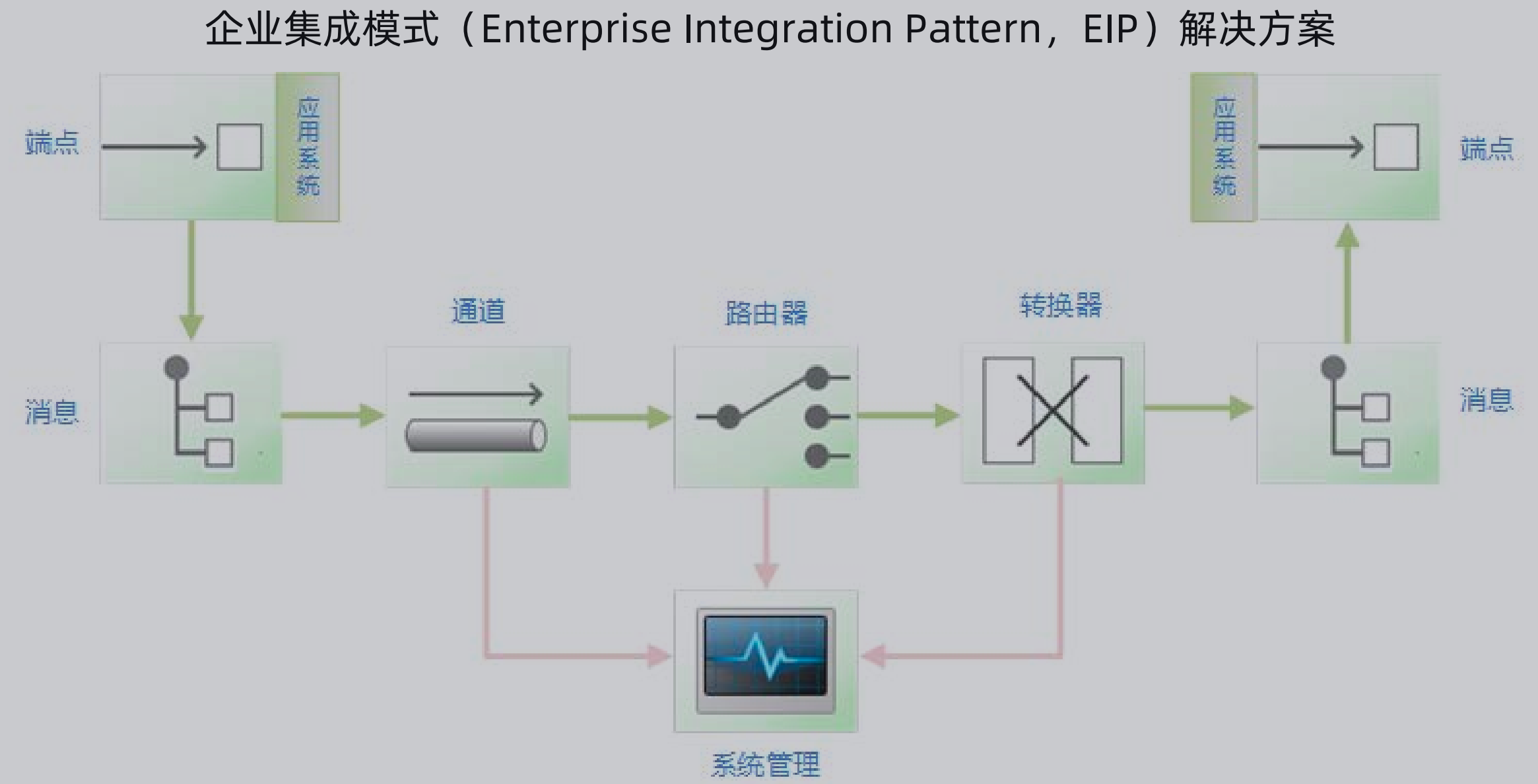
通道:通道有生产者和消费者,生产者大宋数据,消费者接收数据
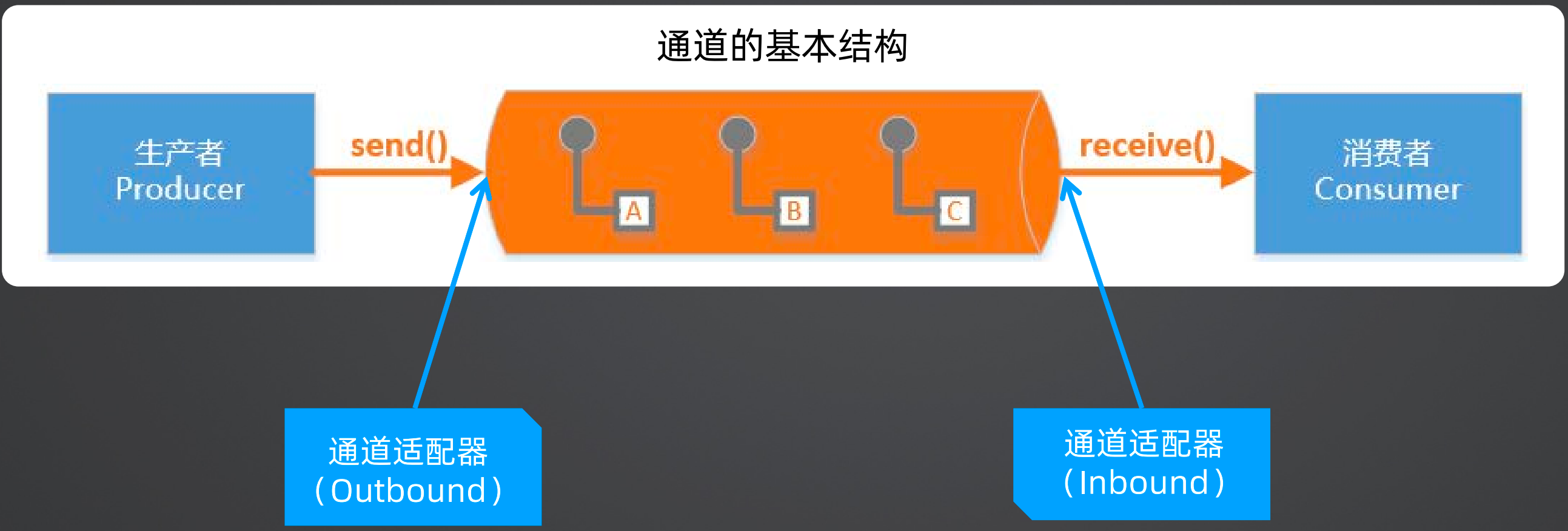
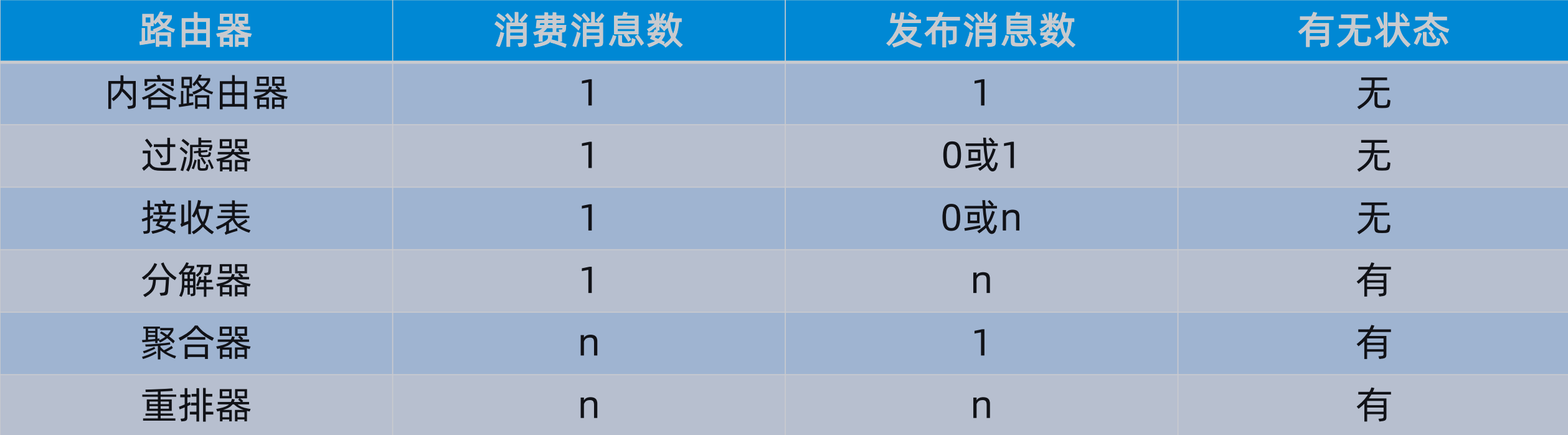
路由:路由器可以有多种方式,例如内容路由器、过滤器、接收器、分解器、聚合器、重排器等,这里单独说一下内容路由器和过滤器。
内容路由器(Content-based Router):最简单的路由器,即通过消息的内容决定路由结果,这里的消息内容包括输入消息的消息头属性值、消息体类型以及各种对消息体内容的自定义的业务规则,通过内容路由器可以产生一对一的路由效果。
过滤器(Filter):目的是决定是否将消息流转到下一个环节,如果满足一定过滤条件,则该消息将不会产生任何路由结果,过滤条件同样可以包括复杂的业务流程性内容。
数据转换:
转换器(Transformer):完成异构系统数据适配,最基本的转换思路就是通过一种自定义转换机制进行两种数据结构之间的映射
数据转换的思路包括:自定义转换、信息包装、内容扩充、内容过滤
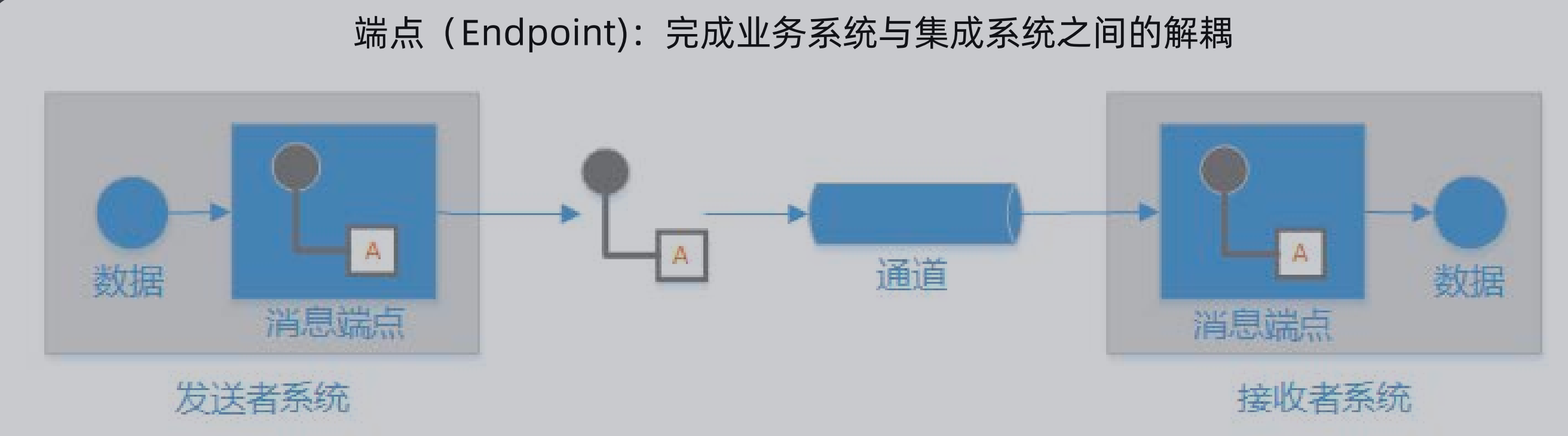
端点:
实际上就是提供的接口,完成业务系统与集成系统之间的解耦
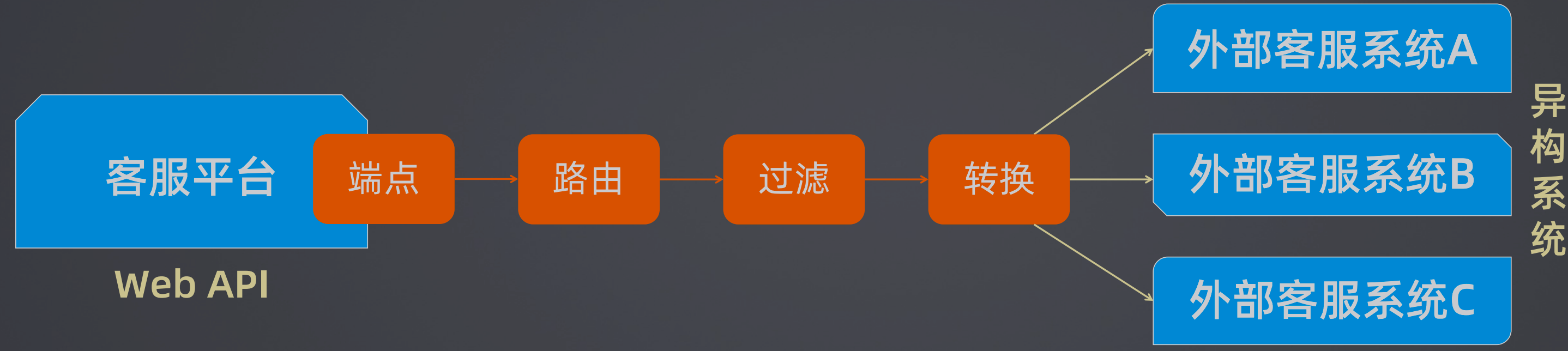
主流实现框架有Spring Integration 和 Apache Camel,例如Spring Cloud Stream就是基于Spring Integration来实现的,也有成套的解决方案,例如企业服务总线(Enterprise Service Bus,ESB)。
(二)自定义服务总线组件
这里不使用已有的相关技术,而是自定义一个服务总线来完成客服系统和外部客服系统的数据交互,设计思路是客户系统通过端点处理,然后经过路由、过滤、转换,达到外部客服系统。
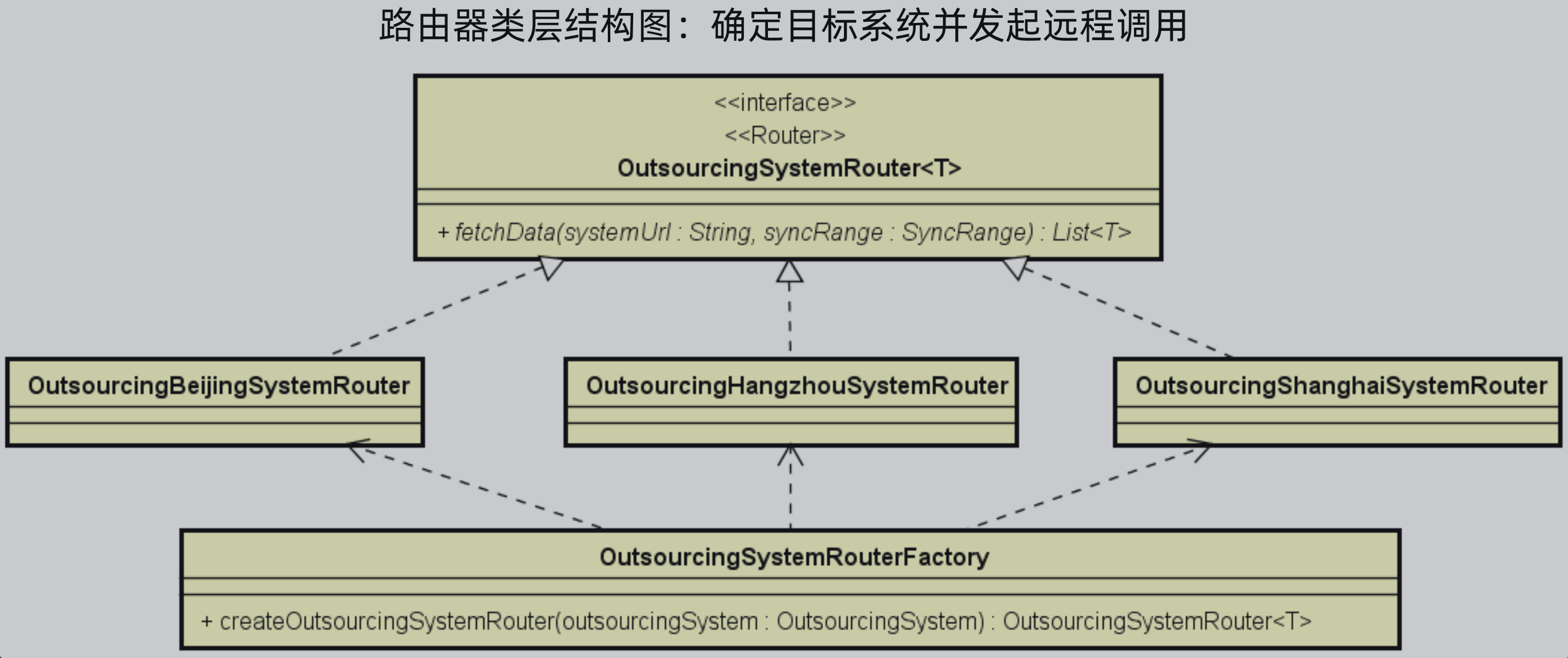
路由器:确定目标系统并发起远程调用
路由器类层结构图如下所示,首先有一个路由器接口OutsourcingSystemRouter,内部有一个获取数据的方法fetchData,方法的入参是系统访问地址等信息,返回值是一个带泛型的List,因为每个系统返回的数据类型都可能不一样。
那么针对每个异构系统都需要有一个针对OutsourcingSystemRouter接口的实现类,用以确定具体怎么获取的实现。
然后为了便于创建对应的实现类,可以使用工厂模式来创建对应的实现类。
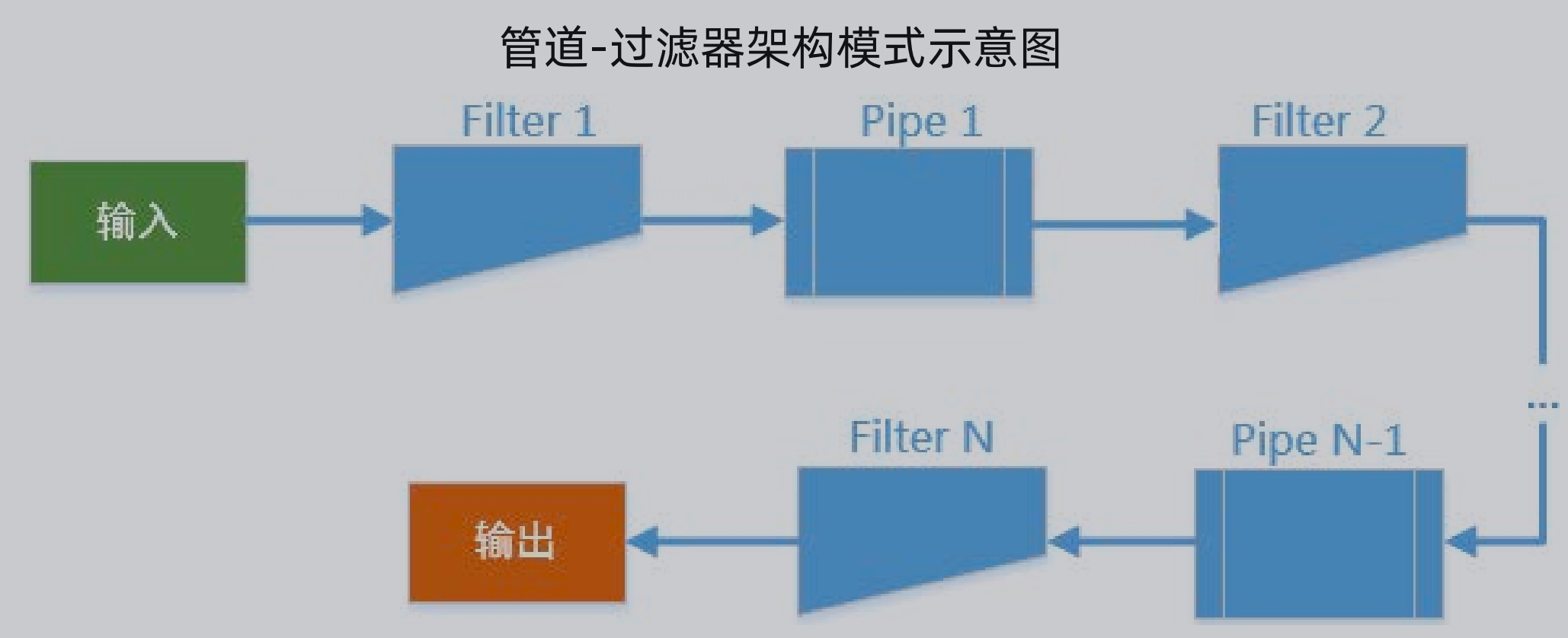
过滤器:
过滤器实际上就是使用管道-过滤器架构模式,从而提供集成扩展性,从设计模式上讲可以算是责任链模式。
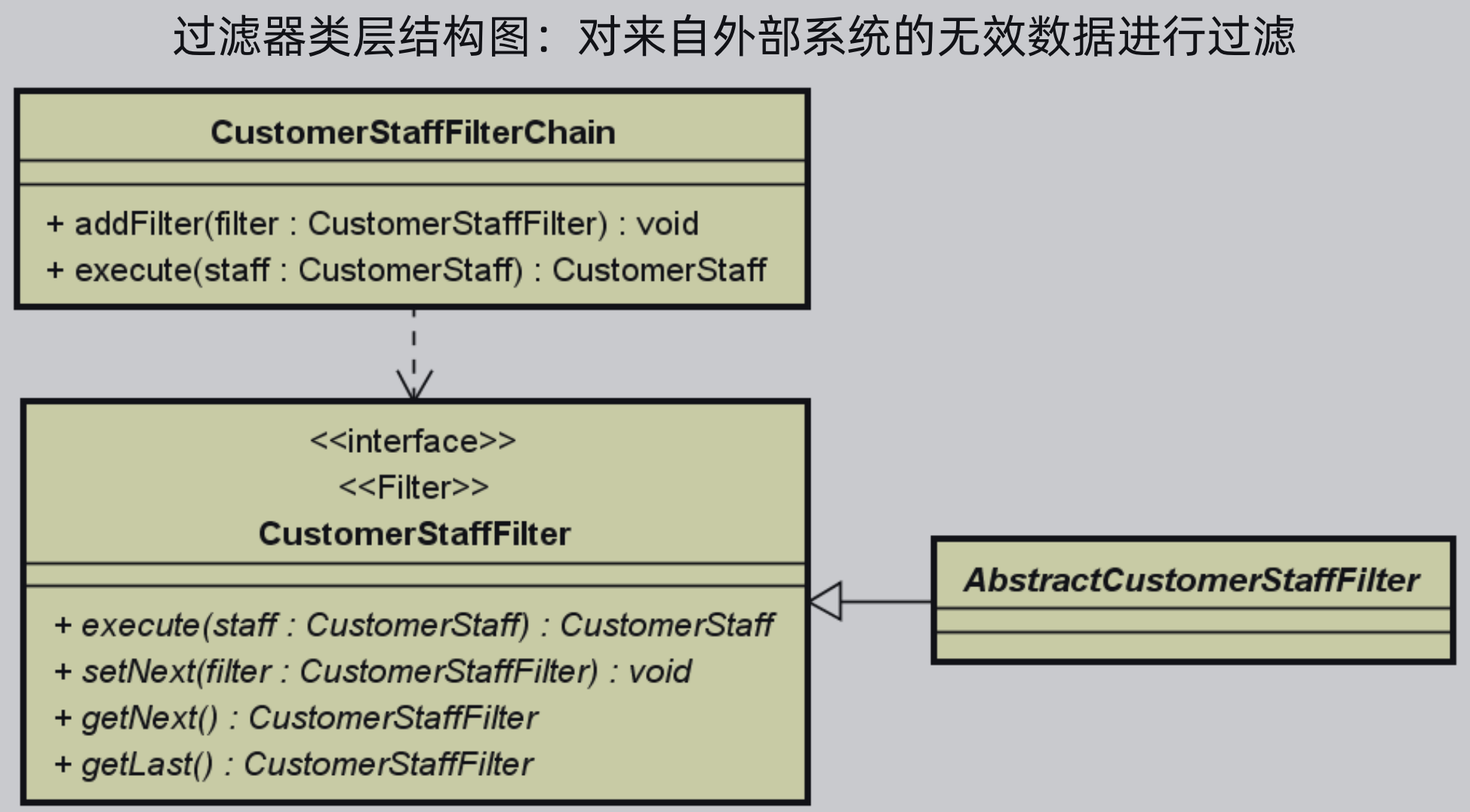
过滤器类层结构图如下所示,首先有一个过滤链,提供了添加过滤器的方法和执行的方法,过滤器是一个接口,提供了执行、设置下一个过滤器、获取下一个过滤器、获取最后一个过滤器等方法,然后提供了一个抽象的过滤器方法,用于实现一些通用的方法。
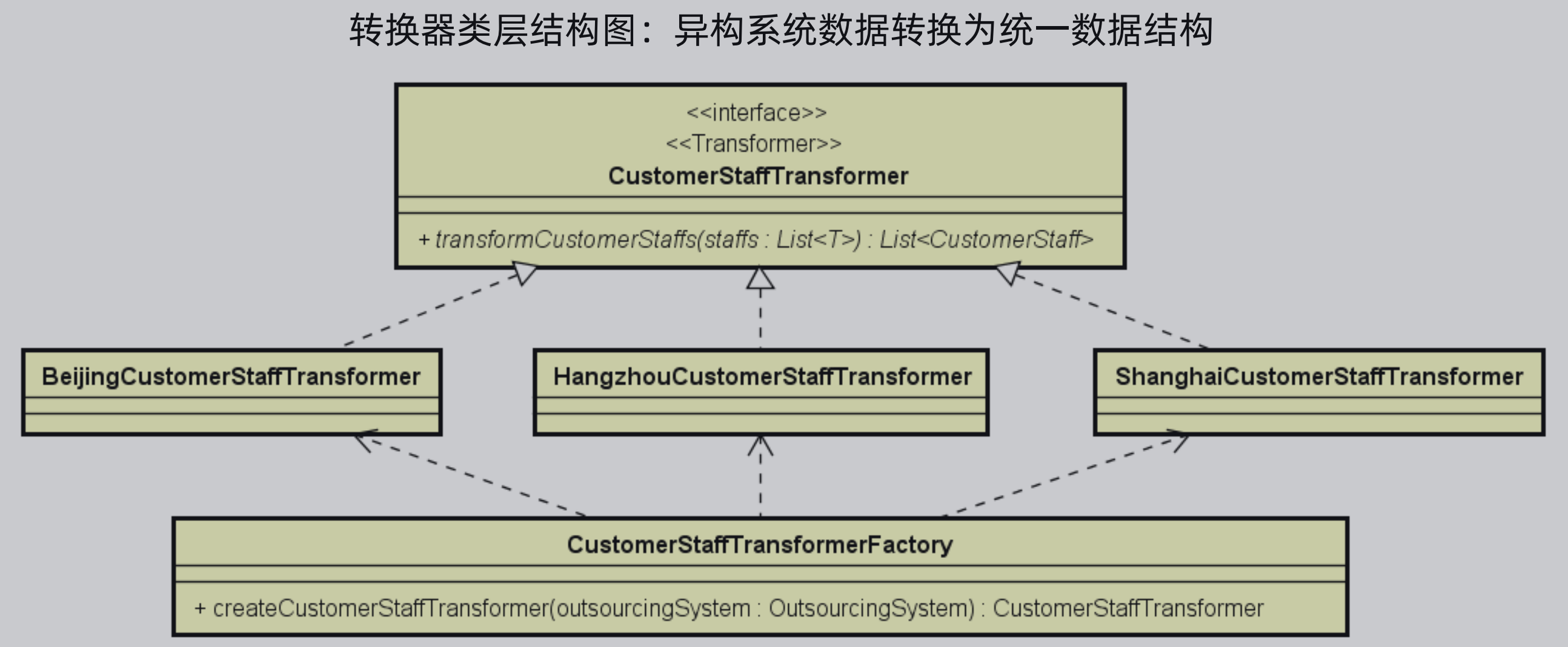
转换器:异构系统数据转换为统一数据结构
转换器类层结构图如下所示,类似于路由器,提供一个转换器接口,针对每一个异构系统有自己对于转换器的实现,同时提供一个转换器的工厂类,让其创建对应的转换器实现类
端点:提供入口和统一流程,用于解耦对于不同异构系统的处理
端点类层结构图如下所示,首先提供一个端点接口,该接口提供一个获取数据的方法,同时有该接口的实现类,在该实现类中,组装执行流程,即组装Router、Filter和Transformer,组装过程都是使用的接口进行组装,从而做到解耦。
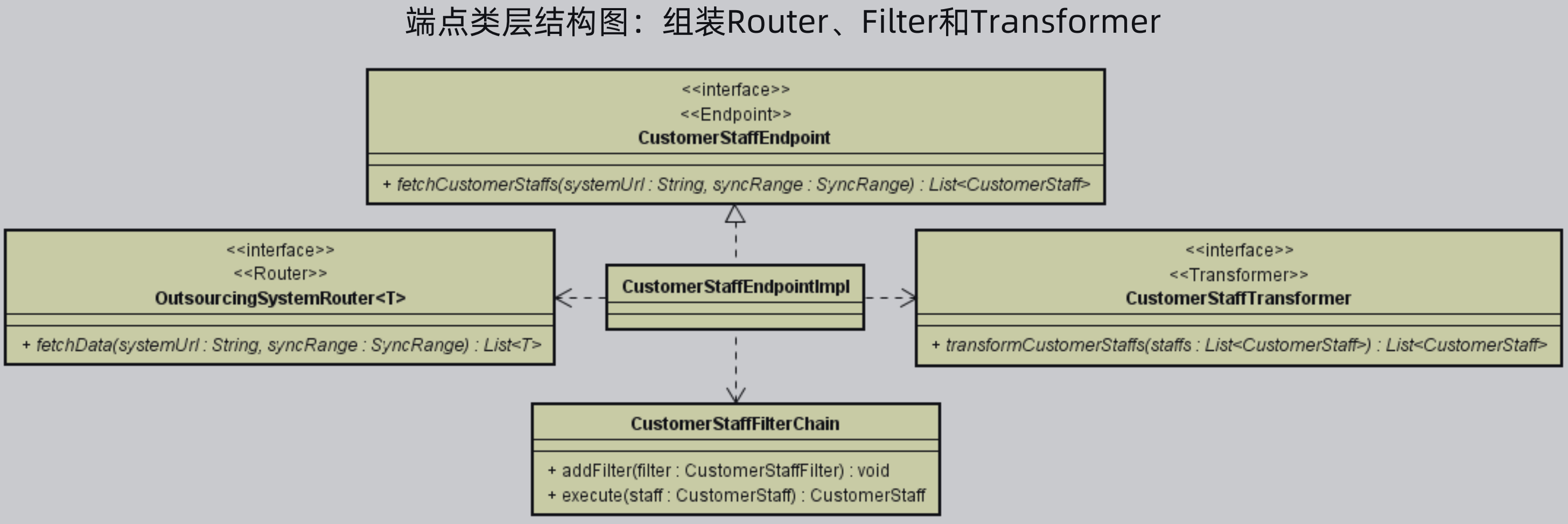
(三)客服系统案例演进
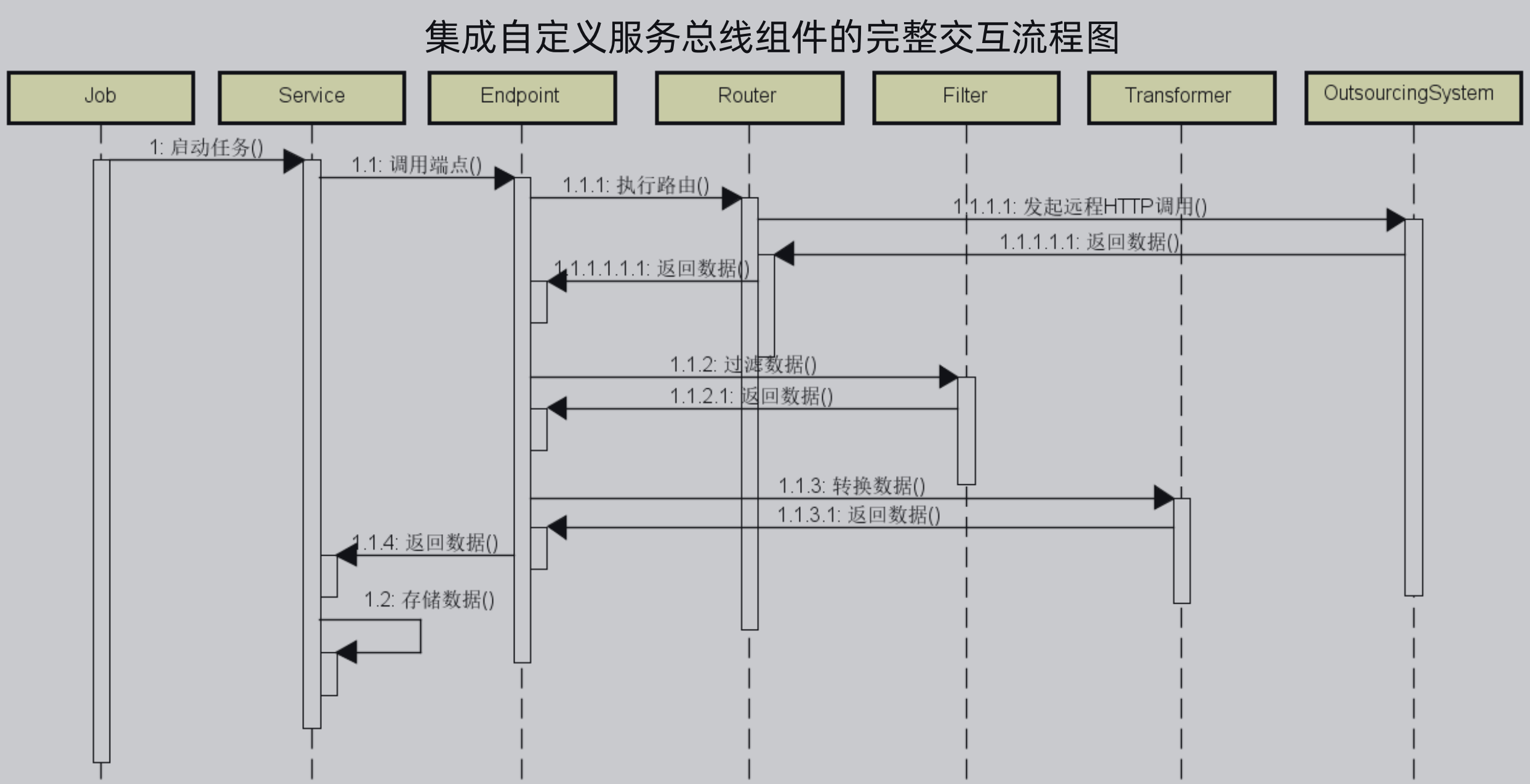
集成自定义服务总线组件的后,完整交互流程图如下所示:
定时任务调用Service,Service调用端点,端点调用Router执行路由,在该路由中根据不同的系统代码调用不同的异构系统,返回数据后,端点再调用对应的过滤器将数据进行过滤,,然后端点再调用指定的数据转换器进行数据转换。
(1)路由器
接口
public interface OutsourcingSystemRouter<T> {
List<T> fetchOutsourcingCustomerStaffs(String systemUrl);
}
由于每一个异构系统返回的对象都不相同,因此针对每个异构系统都要创建一个与异构系统返回对象一模一样的对象,这里模式一个对象
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
public class HangzhouCustomerStaff implements Serializable {
private Long id;
private String nickname;
private String avatar;
private String phone;
private String gender;
private String goodAt;
private String remark;
private Date createTime;
}
针对于其中一个异构系统的实现类,主要就是通过远程调用获取原始返回数据对象
public class HangzhouOutsourcingSyetemRouter implements OutsourcingSystemRouter<HangzhouCustomerStaff> {
@Autowired
private RestTemplate restTemplate;
@Override
public List<HangzhouCustomerStaff> fetchOutsourcingCustomerStaffs(String systemUrl) {
// 通过 RestTemplate 发起远程调用
ResponseEntity<Result> result = restTemplate.exchange(systemUrl, HttpMethod.GET, null,Result.class);
List<HangzhouCustomerStaff> customerStaffs = (List<HangzhouCustomerStaff>) result.getBody().getData();
return customerStaffs;
}
}
工厂类,根据不同的异构系统获取对应的实现类
@Component
public class OutsourcingSystemRouterFactory {
private static final String OUTSOURCING_SYSTEM_BEIJING = "beijing";
private static final String OUTSOURCING_SYSTEM_SHAGNHAI = "shanghai";
private static final String OUTSOURCING_SYSTEM_HANGZHOU = "hangzhou";
public OutsourcingSystemRouter createRouter(String sysTemCode){
if(OUTSOURCING_SYSTEM_SHAGNHAI.equals(sysTemCode)) {
return new ShangHaiOutSourcingSystemRouter();
} else if(OUTSOURCING_SYSTEM_HANGZHOU.equals(sysTemCode)) {
return new HangzhouOutsourcingSyetemRouter();
} else if(OUTSOURCING_SYSTEM_BEIJING.equals(sysTemCode)) {
return new BeijingOutsourcingSystemRouter();
}
return null;
}
}
(2)过滤器
过滤器接口:
提供execute执行方法,这个方法主要执行过滤器中的内容进行过滤
获取最后一个节点getLast方法和设置下一个节点setNext方法,这两个方法组合起来用于在添加过滤器时,在最后一个节点后设置一个新的过滤器
获取下一个节点getNext方法,该方法用于执行过滤器链时,一直往后执行
public interface CustomerStaffFilter {
CustomerStaff execute(CustomerStaff customerStaff);
void setNext(CustomerStaffFilter customerStaffFilter);
CustomerStaffFilter getNext();
CustomerStaffFilter getLast();
}
过滤器抽象类:
对于上述过滤器接口来说,只有execute方法是每个过滤器不一样的,但是对于另外三个方法,实现逻辑是一样的,因此使用一个抽象方法来实现这三个方法。
具体的实现逻辑:定义一个类型为CustomerStaffFilter的next属性,设置next节点时,就将该next属性设置为入参的过滤器;获取next节点时就返回该next属性值;获取最后一个节点时,使用当前过滤器一直向下获取next,直到没有下一个节点为止。
public abstract class AbstractCustomerStaffFilter implements CustomerStaffFilter{
private CustomerStaffFilter next;
@Override
public void setNext(CustomerStaffFilter filter) {
this.next = filter;
}
@Override
public CustomerStaffFilter getNext() {
return this.next;
}
@Override
public CustomerStaffFilter getLast(){
CustomerStaffFilter last = this;
while (last.getNext() != null) {
last = last.getNext();
}
return last;
}
}
定义一个特定场景的过滤器:这里主要是过滤staffName为空的对象,如果staffName为空,则直接返回空,如果不为空,就获取下一个过滤器进行过滤,如果是最后一个过滤器,则返回对象。
public class CustomerStaffEmptyFilter extends AbstractCustomerStaffFilter {
@Override
public CustomerStaff execute(CustomerStaff customerStaff) {
if(Objects.isNull(customerStaff.getStaffName())){
return null;
}
if(getNext() != null){
return getNext().execute(customerStaff);
}
return customerStaff;
}
}
定义过滤器链:提供添加过滤器方法和执行方法,在addFilter方法中,如果过滤器链为空,则设置过滤器链为入参的过滤器,即设置过滤器链的头结点,如果过滤器链不为空,则获取最后一个过滤器,并设置其next节点;执行方法中,如果过滤器链不为空,则调用过滤器链的执行方法,因为过滤器链就是整个链的第一个过滤器,那么实际上调用的就是过滤器的执行方法,当第一个节点的过滤器执行完毕后,就会调用下一个过滤器的执行方法,这段逻辑是在上面的过滤器代码中实现的。
public class CustomerStaffFilterChain {
private CustomerStaffFilter chain;
public void addFilter(CustomerStaffFilter filter) {
if(chain == null) {
chain = filter;
}else {
chain.getLast().setNext(chain);
}
}
public CustomerStaff execute(CustomerStaff customerStaff){
if(chain != null){
return chain.execute(customerStaff);
}else {
return null;
}
}
}
(3)转换器
定义转换器接口:
public interface CustomerStaffTransformer<T> {
List<CustomerStaff> transformerCustomerStaff(List<T> list);
}
定义不同的转换器实现
public class HangzhouCustomerStaffTransformer implements CustomerStaffTransformer<HangzhouCustomerStaff> {
@Override
public List<CustomerStaff> transformerCustomerStaff(List<HangzhouCustomerStaff> hangzhouCustomerStaffList) {
List<CustomerStaff> customerStaffList = new ArrayList<>();
// 把LinkedHashMap转换为List<HangzhouCustomerStaff>
List<HangzhouCustomerStaff> hangzhouCustomerStaffs = JSON.parseArray(JSON.toJSONString(hangzhouCustomerStaffList), HangzhouCustomerStaff.class);
for (HangzhouCustomerStaff hangzhouCustomerStaff : hangzhouCustomerStaffs) {
CustomerStaff customerStaff = new CustomerStaff();
BeanUtils.copyProperties(hangzhouCustomerStaff, customerStaff);
//填充StaffName
customerStaff.setStaffName(hangzhouCustomerStaff.getNickname());
//转换性别
if(hangzhouCustomerStaff.getGender() != null) {
customerStaff.setGender(Gender.valueOf(hangzhouCustomerStaff.getGender()));
}
//转换时间
if(hangzhouCustomerStaff.getCreateTime() != null) {
ZoneId zone = ZoneId.systemDefault();
Instant createdTimeInstance = hangzhouCustomerStaff.getCreateTime().toInstant();
LocalDateTime createdTimeLocalDateTime = LocalDateTime.ofInstant(createdTimeInstance, zone);
customerStaff.setCreateTime(createdTimeLocalDateTime);
}
//初始化AccountId和Status
customerStaff.setAccountId(-1L);
customerStaff.setStatus(Status.OFFLINE);
customerStaffList.add(customerStaff);
}
return customerStaffList;
}
}
定义转换器工厂类
public class CustomerStaffTransformerFactory {
private static final String OUTSOURCING_SYSTEM_BEIJING = "beijing";
private static final String OUTSOURCING_SYSTEM_SHAGNHAI = "shanghai";
private static final String OUTSOURCING_SYSTEM_HANGZHOU = "hangzhou";
public CustomerStaffTransformer createTransformer(String sysTemCode){
if(OUTSOURCING_SYSTEM_SHAGNHAI.equals(sysTemCode)) {
return new ShanghaiCustomerStaffTransformer();
} else if(OUTSOURCING_SYSTEM_HANGZHOU.equals(sysTemCode)) {
return new HangzhouCustomerStaffTransformer();
} else if(OUTSOURCING_SYSTEM_BEIJING.equals(sysTemCode)) {
return new BeijingCustomerStaffTransformer();
}
return null;
}
}
(4)端点
接口:提供根据系统对象获取外包客服信息的入口
public interface CustomerStaffEndpoint {
List<CustomerStaff> fetchCustomerStaffs(OutsourcingSystem outsourcingSystem);
}
实现:在构造函数中构建过滤器链,然后在实现中,就是既定的步骤:
根据系统代码使用路由器工厂获取对应的路由器,根据调用地址使用路由器获取原始数据
根据系统代码使用数据转换器工厂获得数据转换器,通过数据转换器将原始数据转换为想要的数据
执行过滤器链,获得最终的数据
@Service
public class CustomerStaffEndpointImpl implements CustomerStaffEndpoint {
private CustomerStaffFilterChain customerStaffFilterChain;
/**
* 在构造函数中创建过滤链
*/
public CustomerStaffEndpointImpl(){
customerStaffFilterChain = new CustomerStaffFilterChain();
customerStaffFilterChain.addFilter(new CustomerStaffEmptyFilter());
}
@Override
public List<CustomerStaff> fetchCustomerStaffs(OutsourcingSystem outsourcingSystem) {
// 定义最终返回的结果集
List<CustomerStaff> finalCustomerStaffs = new ArrayList<>();
// 获取路由器
OutsourcingSystemRouter outsourcingSystemRouter = OutsourcingSystemRouterFactory.createRouter(outsourcingSystem.getSystemCode());
// 使用路由器进行远程调用,获取原始数据
List list = outsourcingSystemRouter.fetchOutsourcingCustomerStaffs(outsourcingSystem.getSystemUrl());
// 创建数据转换器
CustomerStaffTransformer customerStaffTransformer = CustomerStaffTransformerFactory.createTransformer(outsourcingSystem.getSystemCode());
// 使用转换器转换数据
List<CustomerStaff> customerStaffs = customerStaffTransformer.transformerCustomerStaff(list);
// 执行过滤链
customerStaffs.forEach(customerStaff -> {
CustomerStaff filterCustomerStaff = customerStaffFilterChain.execute(customerStaff);
if(filterCustomerStaff != null) {
finalCustomerStaffs.add(filterCustomerStaff);
}
});
return finalCustomerStaffs;
}
}
那么基于以上的处理,最终的实现调用可以改为
@Override
public void syncGetOutsourcingCustomerStaffBySystemId(Long systemId) {
// 获取租户信息
OutsourcingSystem outsourcingSystem = outsourcingSystemService.findOutsourcingSystemById(systemId);
// 根据租户信息远程获取客服信息
List<CustomerStaff> customerStaffs = customerStaffEndpoint.fetchCustomerStaffs(outsourcingSystem);
// 批量保存
this.saveBatch(customerStaffs);
}
这样后续如果有新的对接系统加入,只需要新增转换器和路由器即可,不需要对主流程做改造。
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号