
02-系统扩展、测试和监控
一、使用Mybatis-Plus对数据访问进行扩展
1、MyBatis-Plus开发模式
(1)为什么用Mybatis-Plus
Mybatis的问题:
通过原生SQL语句操作业务数据,自动化程度不高;通过繁杂的XML配置来映射字段和属性,影响开发效率;对字段名称的识别和校验不友好,易出错且不好排查。
Mybatis-Plus的功能特性:
不用SQL只用少量代码实现强大的CRUD操作;支持Lambda形式调用,字段名强校验;内置代码生成器,自动生成各层框架代码;内置分页、性能分析、全局拦截插件。
(2)MyBatis-Plus与Active Record模式
Active Record模式:是一种领域模型模式,一个模型类对应关系型数据库中的一个表,而模型类的一个实例 对应表中的一行记录。
这种方式就比较简单,例如拿到一个模型类,实际上就可以操作数据库中的具体一条数据,这种适合简单的领域需求,领域模型和数据库结构相似。
集成Model类:集成Mybatis-Plus提供的Mdel类,扩展了这个类之后,该实体类就自带了CRUD方法
@TableName("customer_staff")
public class CustomerStaff extends Model<CustomerStaff>{
//省略字段定义
}
实体类的CRUD:在使用时,就可以直接调用实体类的CRUD方法
public void insert() {
CustomerStaff customerStaff = new CustomerStaff ();
...
customerStaff.insert();
}
public void update() {
CustomerStaff customerStaff = new CustomerStaff ();
...
customerStaff.updateById();
}
这是一种使用方式,但是并不推荐这样使用,因为从架构设计上来说,应该是要做架构分层的,但是这种使用方式将实体层与数据访问层放在一起,没有进行解耦。
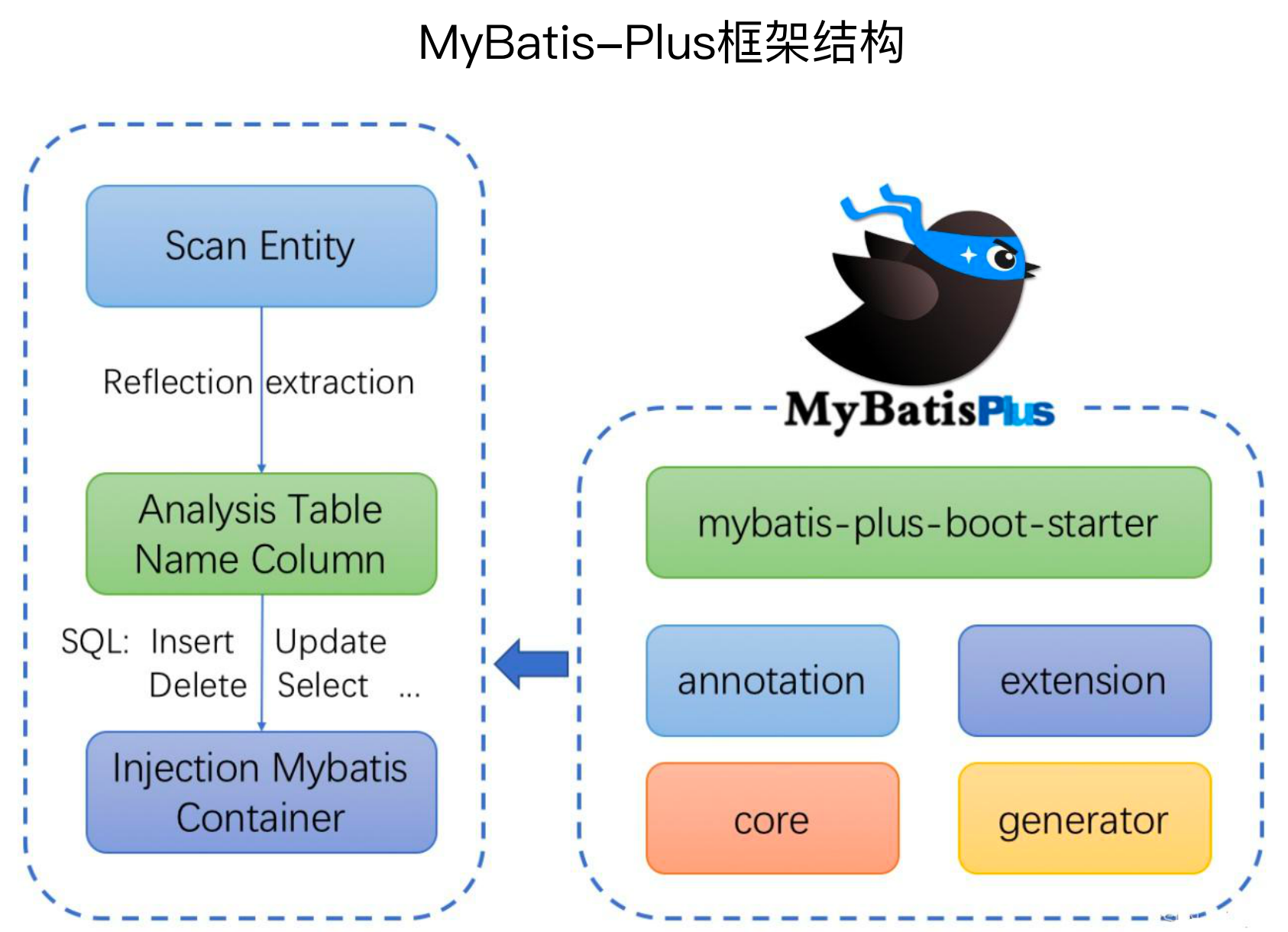
(3)Mybatis-Plus整体架构
Mybatis-Plus主要分为两部分,分别是对于Mybatis的继承(下图左侧部分),一部分是给开发者提供了API(下图右侧部分)
Mybatis-Plus整体还是基于Mybatis做的扩展,如下图左侧部分,扫描所有的Entity,里面会用到反射什么的,然后要分析表的名称、列的名称等,然后将增删改查语句注入到Mybatis容器中。
同时基于SpringBoot提供了mybatis-plus-boot-starter,提供了一些列的注解、扩展、代码生成器等等
(4)MyBatis-Plus条件查询
MyBatis-Plus将MyBatis中原本需要书写复杂的SQL查询条件进行了封装,使用 Java代码编程的形式完成查询条件的组合,也就是条件构造器Wrapper。
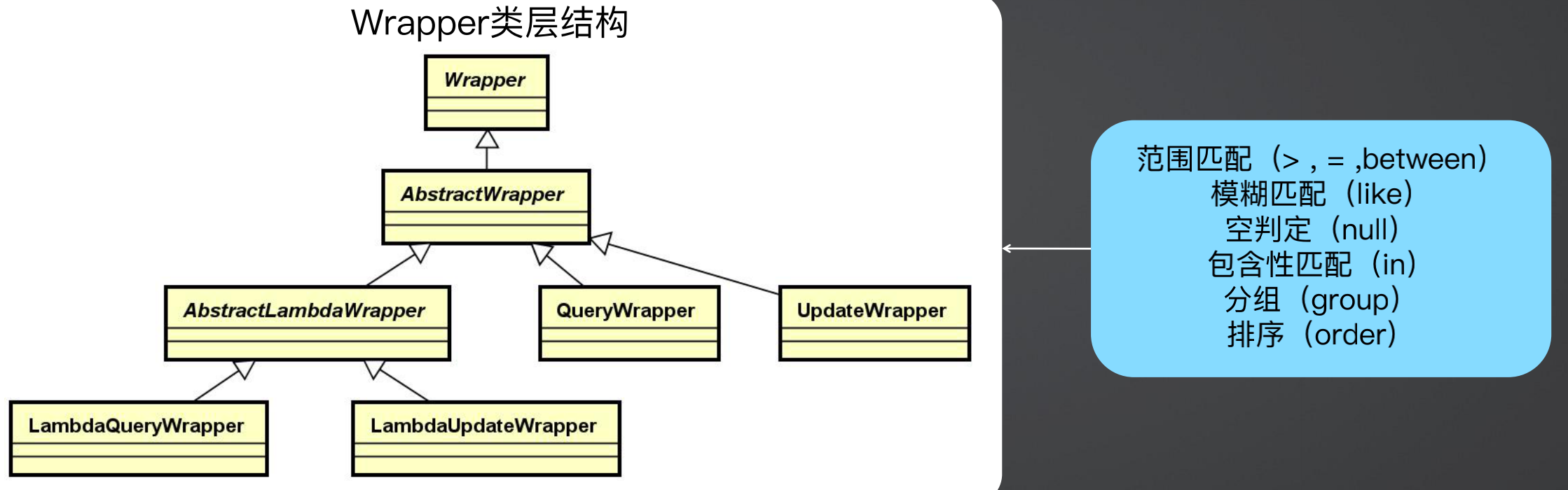
上图是Wrapper的类结构,使用时关注叶子节点的类即可,例如LambdaQueryWrapper和LambdaUdateWrapper,都是使用的Lambda来进行写和查操作的,如果不使用Lambda表达式,也可以使用QueryWrapper和UdateWrapper。
下面代码时使用LambdaQueryWrapper进行查询的使用方式,首先创建一个LambdaQueryWrapper,再调用 lt 和 gt 方法进行处理,参数是对象的具体属性,这样就可以不使用sql,直接使用代码编程的方式实现数据操作,可以避免写错(写错了编译都通不过)。
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>();
wrapper.lt(User::getAge, 30).gt(User::getAge, 10);
List<User> userList = userMapper.selectList(wrapper);
(5)MyBatis-Plus Id生成策略
MyBatis-Plus 除了可以像Mybatis一样在实体类的主键上设置主键生成策略(@TableId(value = "id", type = IdType.AUTO)),同时还提供了自己的策略,如:数据库自增Id(AUTO(0))、 不设置Id生成策略(NONE(1))、手工输入Id(INPUT(2))、雪花算法(ASSIGN_ID(3))、UUID生成算法(ASSIGN_UUID(4))
配置方式一:配置文件(全局配置)
# 全局配置文件设置
mybatis-plus: # 设置Mybatis-plus
global-config: # 全局配置
db-config: # 数据库配置
id-type: auto # 设置全局Id生成策略
配置方式二:实体注解
//代码设置
@TableName("customer_staff")
public class CustomerStaff implements Serializable {
//设置单个Entity Id生成策略
@TableId(value = "id", type = IdType.AUTO)
private Long id;
}
(6)MyBatis-Plus分页功能
MyBatis-Plus分页功能主要使用了内置的分页拦截器PaginationInnerInterceptor。
首先创建一个配置类,注入一个MybatisPlusInterceptor的Bean,添加拦截器列表,其中一个就是分页拦截器。
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
//1 创建MybatisPlusInterceptor拦截器对象
MybatisPlusInterceptor mpInterceptor=new MybatisPlusInterceptor();
//2 添加分页拦截器
mpInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mpInterceptor;
}
}
使用MyBatis-Plus分页
@Test
void testSelectPage(){
//1 创建IPage分页对象,设置分页参数
IPage<User> page=new Page<>(1,20);
//2 执行分页查询
userDao.selectPage(page,null);
//3 获取分页结果
System.out.println("当前页码值:"+page.getCurrent());
System.out.println("每页显示数:"+page.getSize());
System.out.println("总页数:"+page.getPages());
System.out.println("总条数:"+page.getTotal());
System.out.println("当前页数据:"+page.getRecords());
}
(7)MyBatis-Plus逻辑删除
全局配置
//全局配置文件设置
mybatis-plus:
global-config:
db-config:
# 逻辑删除字段名
logic-delete-field: deleted
# 逻辑删除字面值:未删除为0
logic-not-delete-value: 0
# 逻辑删除字面值:删除为1
logic-delete-value: 1
逻辑删除
@TableName("customer_staff")
public class CustomerStaff implements Serializable {
//设置单个Entity Id生成策略
@TableId(value = "id", type = IdType.AUTO) private Long id;
//逻辑删除标志位
@TableLogic
private Boolean isDeleted;
}
2、老系统Mybatis升级MyBatis-Plus
MyBatis-Plus升级后对于用MyBatis开发的老功能,完全可以保留继续使用。
升级策略主要分为五步:添加mybatis-plus依赖、设置mybatis-plus全局配置、定义Entity、定义和实现Mapper、定义和实现Service
(1)添加mybatis-plus依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
</dependency>
(2)设置mybatis-plus全局配置
主要是数据源的配置,MyBatis-Plus不再使用Spring的DataSource,而是自己封装了DataSource,因此就不能再使用Spring.datasource的配置。
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: Asia/Shanghai
datasource:
dynamic:
primary: master
druid:
initial-size: 3
min-idle: 3
max-active: 40
max-wait: 60000
datasource:
master:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.249.130:3306/customer_system?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
(3)定义Entity
更多时间是修改Entity,因为Entity已经有了,就需要加一些注解,可以让mybatis-plus识别并引用。
最主要的是在Entity上添加@TableName注解设置表名,然后使用@TableId注解设置主键,同时设置主键生成方式
@Data
@TableName("customer_staff")
public class CustomerStaff {
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
......
}
(4)定义和实现Mapper
不需要像Mybatis一样写@Repository注解,直接继承BaseMapper即可。
@Mapper
public interface CustomerStaffMapper extends BaseMapper<CustomerStaff> {
}
(5)定义和实现Service
MyBatis-Plus对Service层有一定的侵入,其希望Service层实现该框架内部提供的一些公共或者一些接口跟实现类。
Service需要继承Mybatis-Plus提供的ServiceImpl,需要填写Mapper和实体的泛型,那么操作数据库可以有三种方式:
和Mybatis一样,注入Mapper(不推荐)
在ServiceImpl已经注入了CustomerStaffMapper,在父类ServiceImpl中已经注入了baseMapper,因此可以使用baseMapper操作
父类ServiceImpl已经封装了部分方法,可以直接调用父类ServiceImpl中的方法
a、下面是对三种操作的实现。
@Service
public class CustomerStaffServiceImpl extends ServiceImpl<CustomerStaffMapper, CustomerStaff> implements ICustomerStaffService {
// 使用 CustomerStaffMapper 操作数据库
@Autowired
private CustomerStaffMapper customerStaffMapper;
public CustomerStaff findCustomerStaffById1(Long staffId) {
return customerStaffMapper.selectById(staffId);
}
// 使用 baseMapper 操作数据库
@Override
public CustomerStaff findCustomerStaffById(Long staffId) {
return baseMapper.selectById(staffId);
}
// 直接调用父类 ServiceImpl 中的方法
@Override
public List<CustomerStaff> findCustomerStaffs() {
return this.findCustomerStaffs();
}
@Override
public Boolean createCustomerStaff(CustomerStaff customerStaff) throws BizException {
return this.save(customerStaff);
}
@Override
public Boolean updateCustomerStaff(CustomerStaff customerStaff) {
return this.updateById(customerStaff);
}
@Override
public Boolean deleteCustomerStaffById(Long staffId) {
CustomerStaff customerStaff = new CustomerStaff();
customerStaff.setId(staffId);
customerStaff.setIsDeleted(true);
return this.updateById(customerStaff);
}
b、逻辑删除:
逻辑删除使用的仍然是更新,即将逻辑删除字段更新为已删除,再调用更新方法即可(一般不这么使用)。
public Boolean deleteCustomerStaffById(Long staffId) {
CustomerStaff customerStaff = new CustomerStaff();
customerStaff.setId(staffId);
customerStaff.setIsDeleted(true);
return this.updateById(customerStaff);
}
上面已经提过,使用MyBatis-Plus自带的逻辑删除,可以使用全局配置,也可以在实体类上加注解,这里比较推荐在实体类上加注解,因为使用全局配置可能会引起不可预知、不可控的问题。
@TableLogic
private Boolean isDeleted;
然后就可以调用真正的删除方法进行删除
public Boolean deleteCustomerStaffById(Long staffId) {
return this.removeById(staffId);
}
实际上执行的是更新SQL
JDBC Connection [HikariProxyConnection@370411890 wrapping com.mysql.cj.jdbc.ConnectionImpl@df47573] will not be managed by Spring
==> Preparing: UPDATE customer_staff SET is_deleted=1 WHERE id=? AND is_deleted=0
==> Parameters: 1(Long)
<== Updates: 1
c、分页查询:
分页查询首先需要定义分页拦截器
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
//1 创建MybatisPlusInterceptor拦截器对象
MybatisPlusInterceptor mpInterceptor=new MybatisPlusInterceptor();
//2 添加分页拦截器
mpInterceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return mpInterceptor;
}
}
使用分页主要分为四步,组装业务查询条件、组装分页条件、查询、转换为自定义分页对象。
组装业务查询条件:使用Wrapper子类,例如LambdaQueryWrapper
组装分页条件:使用Mybatis-Plus自带的IPage接口和Page实现类
查询:调用selectPage方法
@Override
public PageObject<CustomerStaff> findCustomerStaffs(Long pageSize, Long pageIndex) {
return this.getCustomerStaffsPageObject(null, pageSize, pageIndex);
}
@Override
public PageObject<CustomerStaff> findCustomerStaffsByName(String staffName, Long pageSize, Long pageIndex) {
return this.getCustomerStaffsPageObject(staffName, pageSize, pageIndex);
}
private PageObject<CustomerStaff> getCustomerStaffsPageObject(String staffName, Long pageSize, Long pageIndex) {
// 组装业务查询条件
LambdaQueryWrapper<CustomerStaff> queryWrapper = new LambdaQueryWrapper();
queryWrapper.eq(CustomerStaff::getIsDeleted, false);
if(StringUtils.isNotBlank(staffName)){
queryWrapper.like(CustomerStaff::getStaffName, staffName);
}
queryWrapper.orderByDesc(CustomerStaff::getCreateTime);
// 组装分页条件
IPage<CustomerStaff> page = new Page<>(pageIndex, pageSize);
// 查询
IPage<CustomerStaff> pageResult = baseMapper.selectPage(page, queryWrapper);
// 转换为自定义分页对象
PageObject<CustomerStaff> pageObject = new PageObject<CustomerStaff>();
pageObject.buildPage(pageResult.getRecords(), pageResult.getTotal(), pageResult.getCurrent(), pageResult.getSize());
return pageObject;
}
如果使用了MyBatis-Plus自带的逻辑删除,就不用拼装delete字段了,Mybatis-Plus已经拼装好了,执行SQL如下所示,可以看到其已经添加了删除字段的赋值。
==> Preparing: SELECT COUNT(*) AS total FROM customer_staff WHERE is_deleted = 0
==> Parameters:
<== Columns: total
<== Row: 2
<== Total: 1
==> Preparing: SELECT id,group_id,staff_name,nickname,account_id,system_id,avatar,phone,gender,good_at,is_auto_reply,welcome_message,status,remark,is_deleted,create_time,update_time FROM customer_staff WHERE is_deleted=0 ORDER BY create_time DESC LIMIT ?
==> Parameters: 4(Long)
<== Columns: id, group_id, staff_name, nickname, account_id, system_id, avatar, phone, gender, good_at, is_auto_reply, welcome_message, status, remark, is_deleted, create_time, update_time
<== Row: 5, 1, zhangsan, zhangsan, 100, null, 1.jpg, 13355667789, MALE, 擅长, 0, 你好,我是天涯兰, ONLINE, 这是客服天涯兰, 0, 2023-02-02 17:49:27, 2023-02-02 17:49:27
<== Row: 3, 1, tianyalan, tianyalan, 100, null, 1.jpg, 13355667789, MALE, 擅长, 0, 你好,我是天涯兰, ONLINE, 这是客服天涯兰, 0, 2023-02-02 17:48:53, 2023-02-02 17:48:53
<== Total: 2
d、自定义方法
上面都是调用了Mybatis-Plus内置的方法,如果要自定义方法,可以在Mapper接口中定义default方法对外提供数据访问。
同时也建议在Mapper层做数据访问操作的封装,Service层只做逻辑处理。
default CustomerStaff findCustomerStaffByPhoneNumber(String phoneNumber) {
LambdaQueryWrapper<CustomerStaff> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(CustomerStaff::getPhone, phoneNumber);
queryWrapper.eq(CustomerStaff::getIsDeleted, false);
return selectOne(queryWrapper);
}
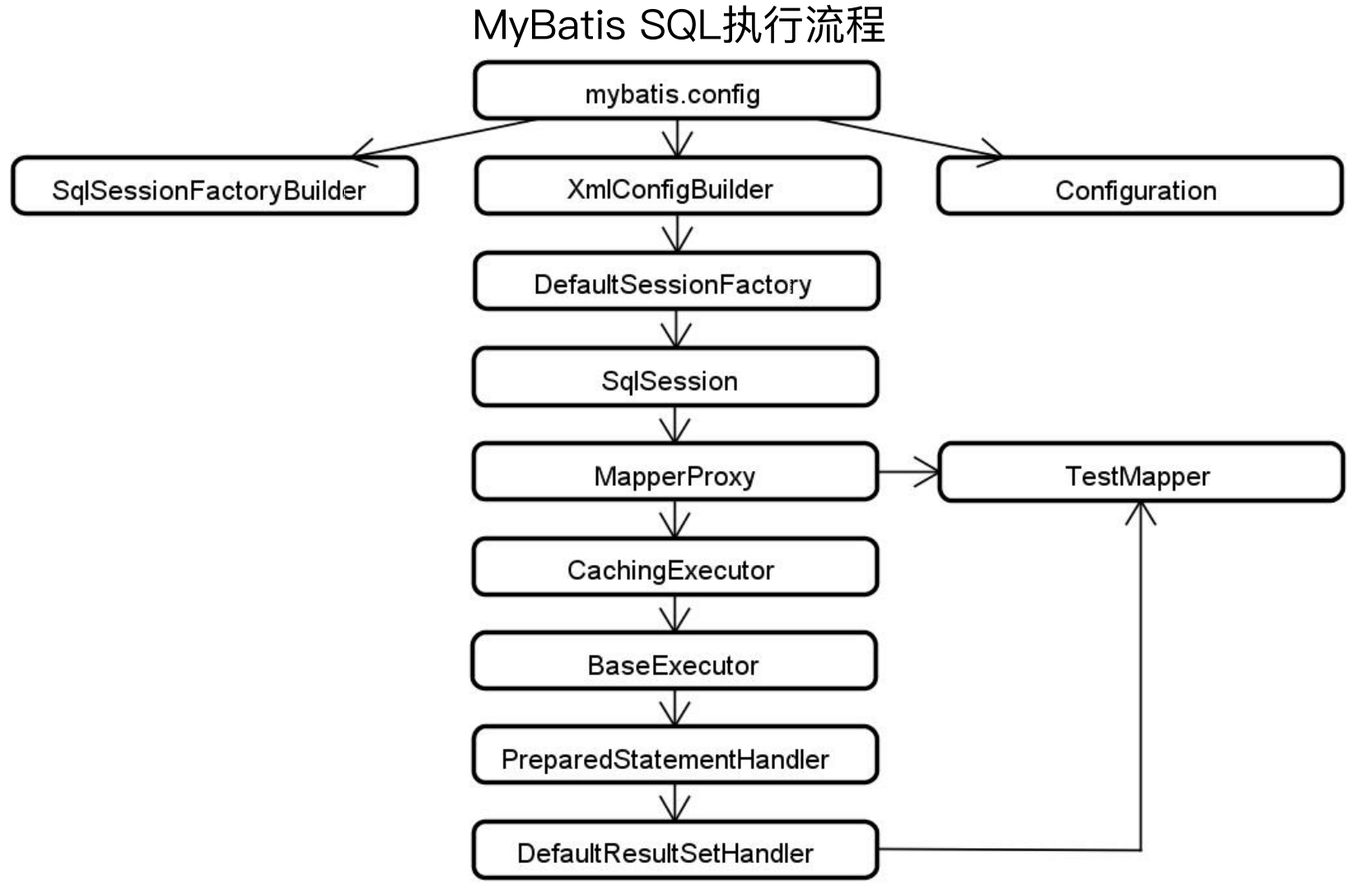
3、MyBatis-Plus SQL执行流程
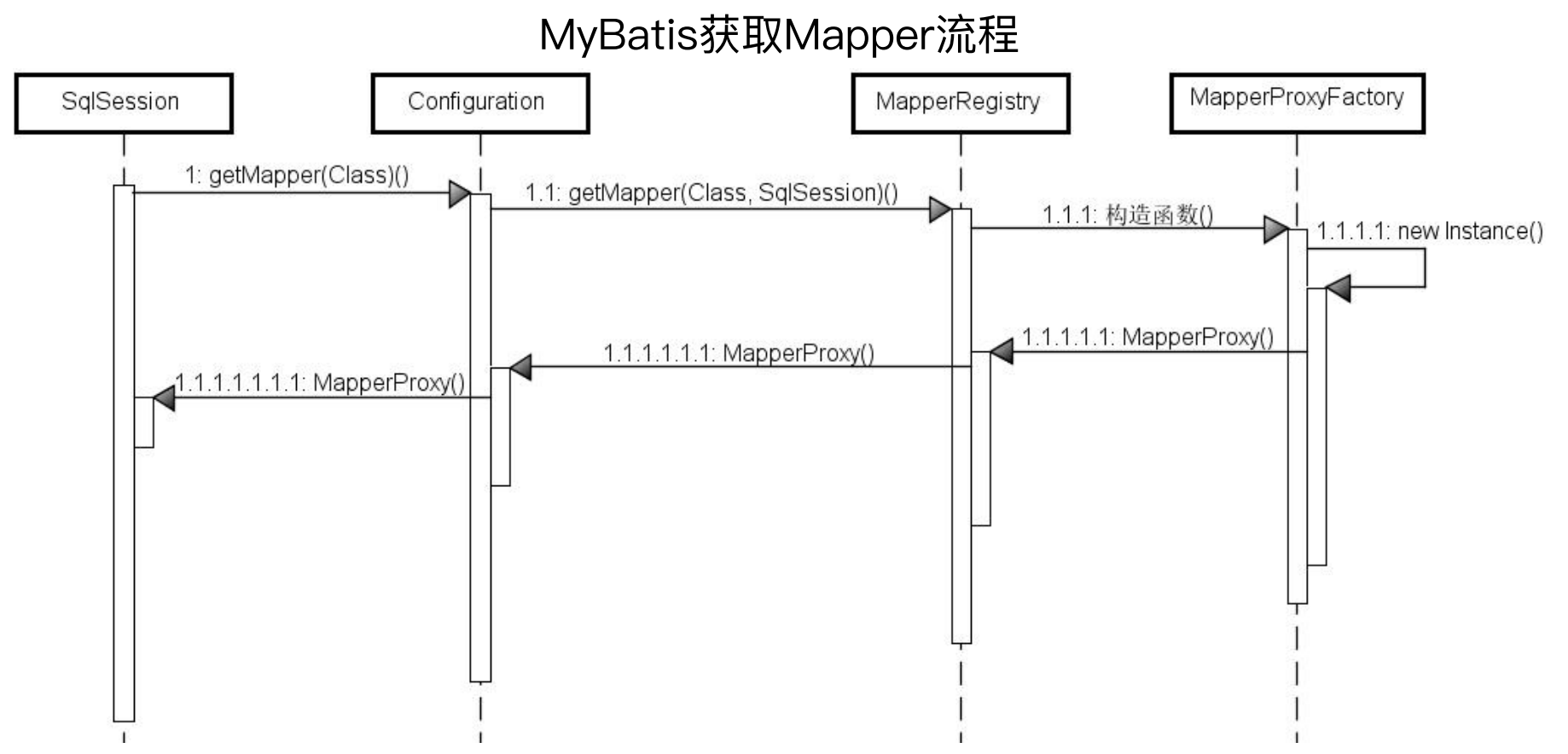
首先是Mybatis的执行流程,一个经常被提及的问题,为什么我们的Mapper接口没有实现类,却可以提供类似实现类的功能?
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
大体流程如下图所示:
调用sqlSession的getMapper方法获取
sqlSession从Configuration配置类中获取
Configuration从内存中的Mapper注册器MapperRegistory获取,该注册器中注册的是接口的实现类(该实现类是Mybatis自动生成的代理类)
MapperRegistory调用MapperProxyFactory的构造函数获取
MapperProxyFactory使用反射生成代理类
调用Mapper接口的制定方法,最终调用了代理类的该方法。
 对于上述流程,针对每个组件稍微看一下源码:
对于上述流程,针对每个组件稍微看一下源码:
(1)SqlSession的getMapper:调用Configuration的getMapper
@Override
public <T> T getMapper(Class<T> type) {
return configuration.<T>getMapper(type, this);
}
(2)Configuration的getMapper:调用MapperRegistry的getMapper
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
(3)MapperRegistry的getMapper:使用工厂模式,调用MapperProxyFactory的newInstance
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
(4)MapperProxyFactory的newInstance:根据sqlSession, mapperInterface, methodCache创建自定义InvocationHandler类mapperProxy,并使用其生成动态代理
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface }, mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
(5)MapperProxy:MapperProxy也是使用的JDK动态代理,实现类InvocationHandler接口并实现了其invoke方法,在该方法中,通过缓存获取到MapperMethod(Mapper的一个实现方法),拿到之后直接执行该方法即可。
public class MapperProxy<T> implements InvocationHandler, Serializable {
......
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}
(6)MapperMethod执行:根据不同的类型调用不同的方法,例如调用executeForMany方法,最终调用了sqlSession的selectList方法。
public class MapperMethod {
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
switch (command.getType()) {
case INSERT: {
......
}
case UPDATE: {
......
}
case DELETE: {
......
}
case SELECT:
if (method.returnsVoid() && method.hasResultHandler()) {
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
result = executeForMany(sqlSession, args);
......
return result;
}
private <E> Object executeForMany(SqlSession sqlSession, Object[] args) {
List<E> result;
Object param = method.convertArgsToSqlCommandParam(args);
if (method.hasRowBounds()) {
RowBounds rowBounds = method.extractRowBounds(args);
result = sqlSession.<E>selectList(command.getName(), param, rowBounds);
} else {
result = sqlSession.<E>selectList(command.getName(), param);
}
......
return result;
}
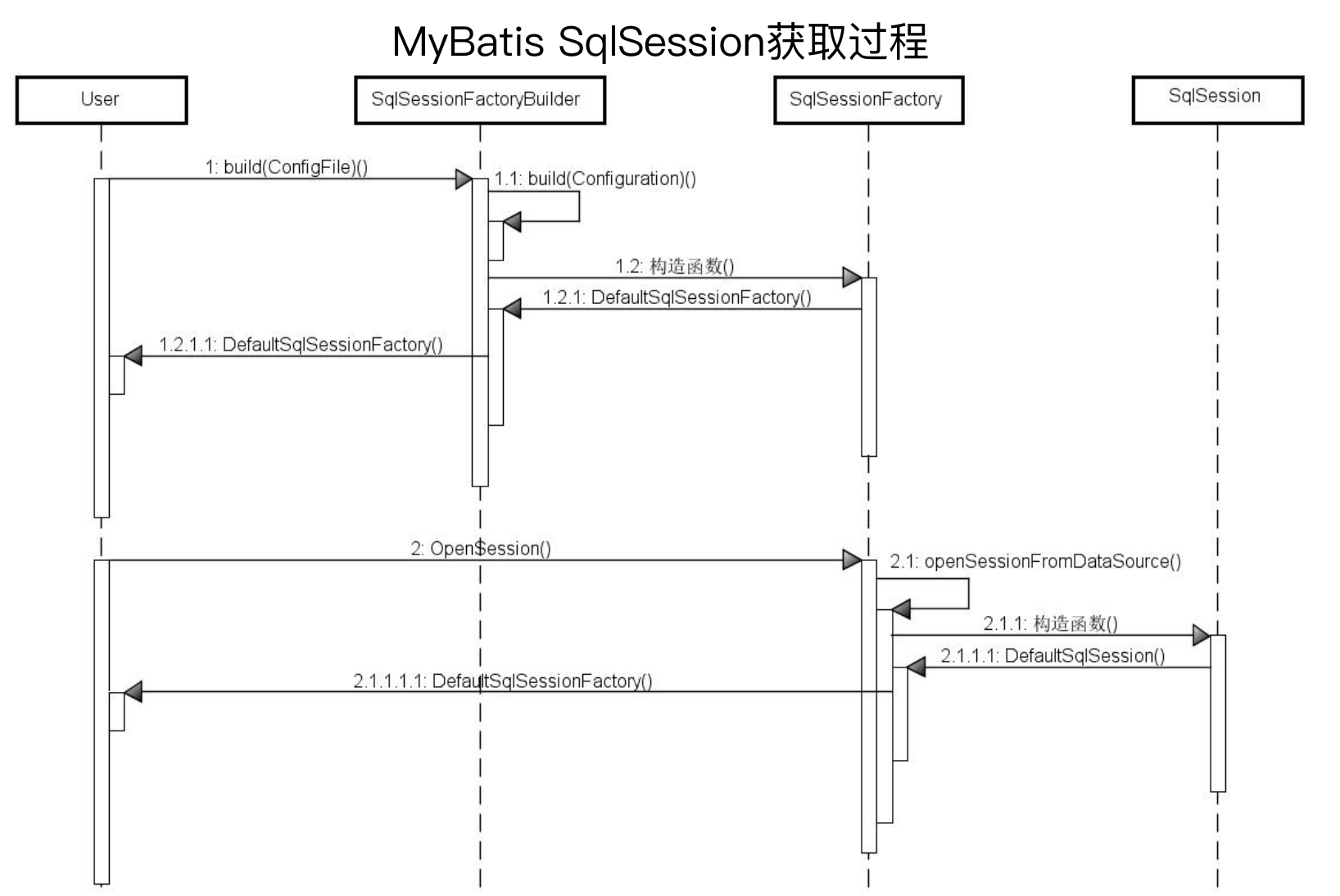
那么又有一个新的问题,SqlSession从哪来的呢
SqlSession的获取过程是有一系列固定套路的,结构清晰、步骤明确,可以算是初始化核心对象的范本。
其是通过Configuration配置文件来获取一个SqlSessionFactoryBuilder(使用了构造器模式)
SqlSessionFactoryBuilder调用SqlSessionFactory的构造函数,获取DefaultSqlSessionFactory对象(工厂类)
然后调用SqlSessionFactory的openSession方法来获取一个DefaultSqlSession
 (7)DefaultSqlSession的selectList:
(7)DefaultSqlSession的selectList:
根据statement获取MappedStatement,然后调用executor的query方法。
executor实际上是一个接口,其有两个实现类BaseExecutor(充当一级缓存,会话级别)和CachingExecutor(充当二级缓存,全局级别)
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
List var5;
try {
MappedStatement ms = this.configuration.getMappedStatement(statement);
var5 = this.executor.query(ms, this.wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception var9) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + var9, var9);
} finally {
ErrorContext.instance().reset();
}
return var5;
}
(8)BaseExecutor的queryFromDatabase方法:
上面调用了BaseExecutor的query方法,在query方法中,首先从localCache中获取,获取不到再调用queryFromDatabase方法从数据库中查询,localCache充当了本地缓存。
在queryFromDatabase方法中,调用了doQuery方法进行数据库查询。
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
CacheKey key = this.createCacheKey(ms, parameter, rowBounds, boundSql);
return this.query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
......
list = resultHandler == null ? (List)this.localCache.getObject(key) : null;
if (list != null) {
this.handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = this.queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
......
return list;
}
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
this.localCache.putObject(key, ExecutionPlaceholder.EXECUTION_PLACEHOLDER);
List list;
try {
list = this.doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
this.localCache.removeObject(key);
}
this.localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
this.localOutputParameterCache.putObject(key, parameter);
}
return list;
}
(9)doQuery
这里面实际上就是原生的 JDBC 代码了,查到结果后,将 JDBC 对象转换为实际想要的对象即可。
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
List var9;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this.wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = this.prepareStatement(handler, ms.getStatementLog());
var9 = handler.query(stmt, resultHandler);
} finally {
this.closeStatement(stmt);
}
return var9;
}
(10)MyBatis执行流程总结
流程总结:
首先有配置文件
基于配置文件来构建出一些Builder
Builder构建完成后可以拿到DefaultSessionFactory
使用SqlSessionFactory可以获得SqlSession
SqlSession通过反射机制获取MapperProxy
MapperProxy中使用Executor执行数据库操作,Executor有带二级缓存的CachingExecutor和带有一级缓存的BaseExecutor
在Executor执行时,采用了 JDBC 原生的方式,但是有PreparedStatementHandler和DefaultResultHandler对Statement和结果集进行处理
其中MapperProxy以下的是框架封装好的,以上的是需要用户处理的,在使用TestMapper时,获取到的是一个代理对象。
Mybatis-plus实际上是对于Mybatis的扩展:
MyBatis-Plus组件替换: 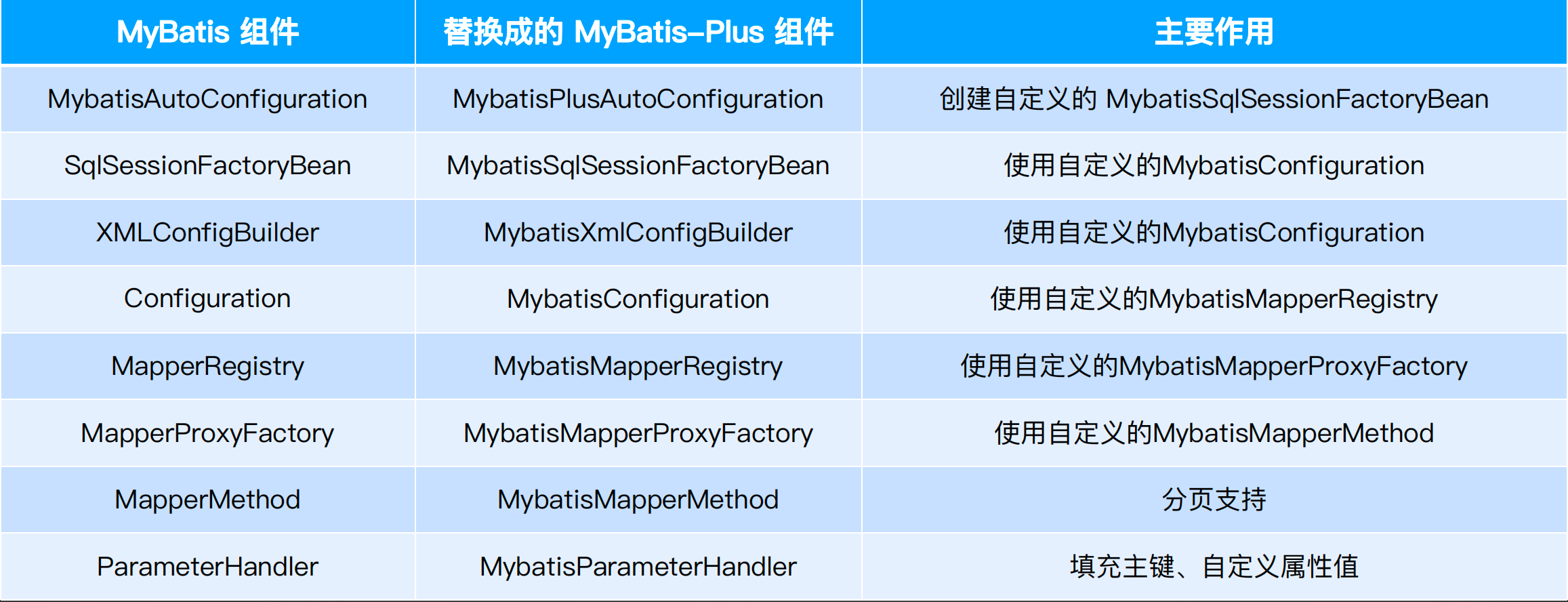
MyBatis-Plus组件执行流程:
(1)首先入口也是MybatisSqlSessionFactoryBean,其创建MybatisConfiguration
(2)继续调用会到MybatisMapperRegistry
(3)MybatisMapperRegistry调用MybatisMapperAnnotationBuilder,来构造一个基于注解的builder
public class MybatisMapperRegistry extends MapperRegistry {
public <T> void addMapper(Class<T> type) {
if (type.isInterface()) {
......
try {
this.knownMappers.put(type, new MybatisMapperProxyFactory(type));
MybatisMapperAnnotationBuilder parser = new MybatisMapperAnnotationBuilder(this.config, type);
parser.parse();
loadCompleted = true;
}
......
}
(4)在MybatisMapperAnnotationBuilder的parse方法中,将各种配置项引入进来,最终调用 ISqlInjector的inspectInject 方法进行动态sql的注入。
public class MybatisMapperAnnotationBuilder extends MapperAnnotationBuilder {
public void parse() {
String resource = this.type.toString();
if (!this.configuration.isResourceLoaded(resource)) {
......
if (GlobalConfigUtils.isSupperMapperChildren(this.configuration, this.type)) {
this.parserInjector();
}
......
}
void parserInjector() {
GlobalConfigUtils.getSqlInjector(this.configuration).inspectInject(this.assistant, this.type);
}
}
public interface ISqlInjector {
void inspectInject(MapperBuilderAssistant builderAssistant, Class<?> mapperClass);
}
(5)ISqlInjector的inspectInject方法最终调用getMethodList
public abstract class AbstractSqlInjector implements ISqlInjector {
public void inspectInject(MapperBuilderAssistant builderAssistant, Class<?> mapperClass) {
......
List<AbstractMethod> methodList = this.getMethodList(mapperClass, tableInfo);
......
}
public abstract List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo);
}
public class DefaultSqlInjector extends AbstractSqlInjector {
public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {
......
return (List)Stream.of(new Insert(), new Delete(), new DeleteByMap(), new Update(), new SelectByMap(), new SelectCount(), new SelectMaps(), new SelectMapsPage(), new SelectObjs(), new SelectList(), new SelectPage()).collect(Collectors.toList());
......
}
}
可以看到,其new了很多方法类,这也是为什么Mybatis-Plus可以直接使用BaseMapper中的这么多方法的原因。
public interface BaseMapper<T> extends Mapper<T> {
int insert(T entity);
int deleteById(Serializable id);
int deleteById(T entity);
int deleteByMap(@Param("cm") Map<String, Object> columnMap);
int delete(@Param("ew") Wrapper<T> queryWrapper);
int deleteBatchIds(@Param("coll") Collection<? extends Serializable> idList);
int updateById(@Param("et") T entity);
int update(@Param("et") T entity, @Param("ew") Wrapper<T> updateWrapper);
}
二、基于Spring Data实现数据访问
1、引入Spring Data
Spring Data完美实现了Respository架构模式,是ORM框架的典型代表
Repository架构模式:
在开发中,我们希望数据访问是面向业务的,而不是面向技术的,而实际上我们常用的一些框架,都是使用SQL进行处理的,这并不是从业务出发操作数据的,这样实体的存在感很弱,这种方式就是面向技术的,或者是面向特定存储媒介的数据操作。
Repository架构模式是将领域抽象出来,形成一种面向业务领域的数据访问,而不是面向技术的数据访问,这是Repository架构的核心思想 ,实际就是其将业务领域层和数据访问层做了一层衔接。
如下图所示,当我们使用Repository做数据访问时,Repository返回的是一个领域对象,而非数据对象。Repository架构模式将面向技术实现屏蔽掉了,而将领域对象做了抽象,我们写代码的时候就像操作具体数据一样,而不是在操作纯粹技术上的数据。

Spring Data 有一个基本的接口Repository(空接口),针对这个接口其做了一个简单的扩展,提供了CrudRepository接口并提供了一组相关数据操作接口。
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAllById(Iterable<? extends ID> ids);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}
从上面的代码看,好像也没有做太多的抽象,那么可以看下图的Spring Data 家族,Spring 提供了各式各样的Spring Data,也就是说上面的CrudRepository并不是面向关系型数据库的,其可以面向各种数据库。
也就是说这个框架能将业务对象和数据完整的结合,是因为提供了一组这样的抽象,当抽象完后,不管任何的数据库都可以操作,在此基础之上,其还提供了分页排序的接口PagingAndSortingRepository,这就是Spring Data的通用接口,对于关系型数据库,其又提供了一个JpaRepository,这是针对特定框架的特定技术,同时我们还可以定义业务定制化的Repository接口。
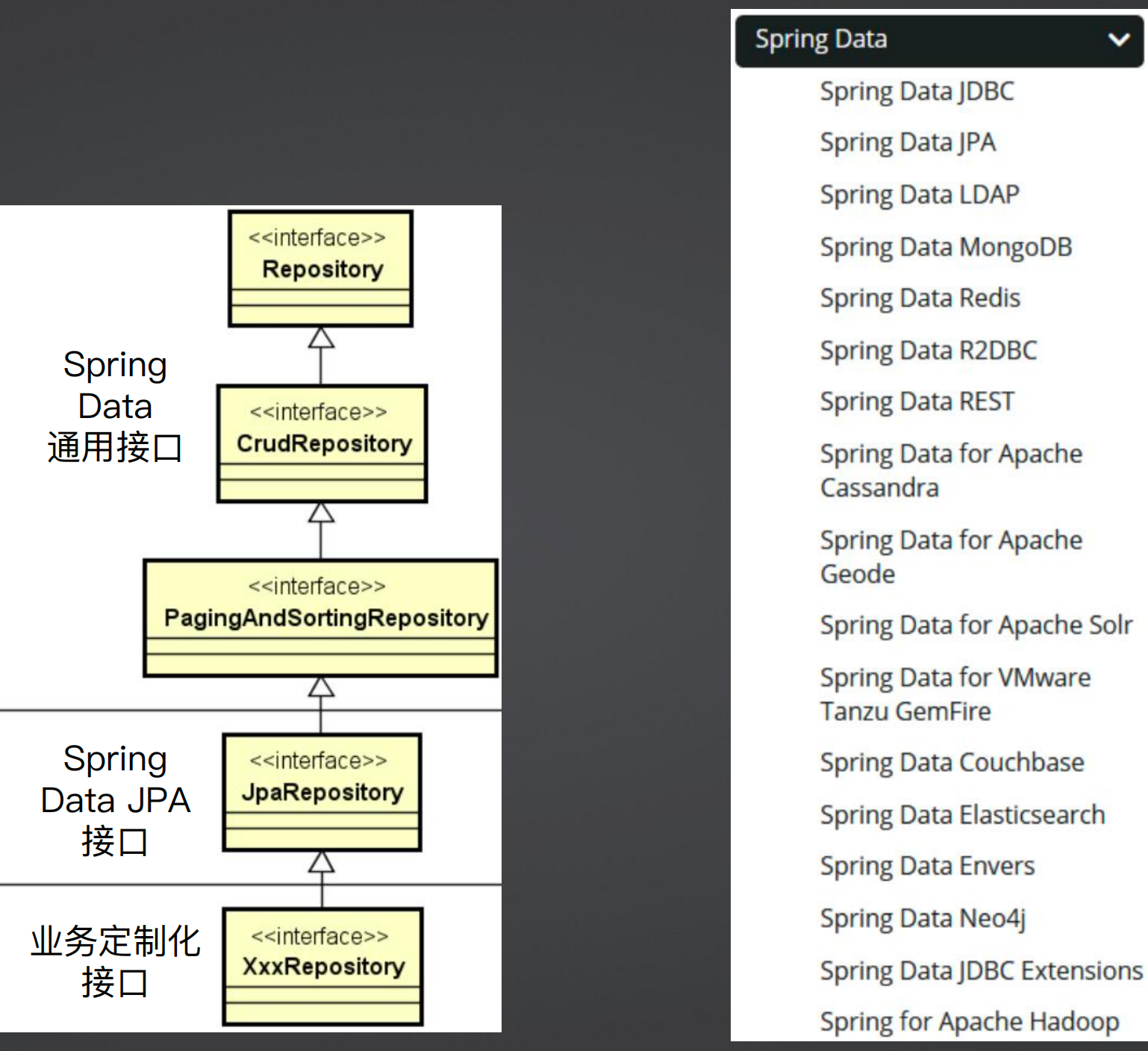
2、Spring Data JPA使用方式
JPA规范:JPA是一种规范,例如 JDBC,全称 JPA Persistence API,即Java持久化API,是一种Java应用程序接口规范,充当面向对象的领域模型和关系数据库系统之间的桥梁,所以属于一种ORM技术。
Mybatis也是一种ORM框架,但是其不是一种规范,而 JPA是一种规范,无论使用Hebernate还是TopLink或是SpringData JPA,都是遵循了 JPA 规范,使用 JPA 需要选择具体的技术实现。
JPA注解
@Entity:实体类映射到指定的数据库表
@Table:指定数据库中的表名
@Column:指定具体的列名
@Id:声明属性映射为数据库的主键列
@GeneratedValue:标注主键的不同生成策略
@Embeddable+@Embedded:将类嵌入为属性
Spring Data JPA多样化查询:@Query注解、方法名衍生查询、QueryByExample机制、Specification机制
(1)@Query注解:
优点类似Mybatis中的@Select注解,这里面的语句不是SQL语句,而是基于 JPA 规范的语句( JPQL语句)。
JPQL语句用法与SQL基本上一致:SELECT 子句 FROM 子句 [WHERE 子句] [GROUP BY 子句] [HAVING 子句] [ORDER BY 子句]
public interface OrderRepository extends JpaRepository<Order, Long>{
@Query("select o from Order o where o.orderNumber = ?1")
Order getOrderByOrderNumberWithQuery(String orderNumber);
}
Query注解有一组注解:@Query注解和@NamedQuery注解可以用来命名一个查询,@NamedQuery注解和@NamedQueries注解可以组合使用。如下所示,可以在类上直接写多个查询,这样就不需要在方法上写。
@Entity @Table(name = "`order`")
@NamedQueries({ @NamedQuery(name = "getOrderByOrderNumberWithQuery", query = "select o from Order o where o.orderNumber = ?1") })
public class Order implements Serializable { }
(2)方法名衍生查询:
通过在方法命名上直接使用查询字段和参数,Spring Data就能自动识别相应的查询条件并组装对应的查询语句
public interface AccouuntRepository extends JpaRepository<Account, Long>{
Order findByFirstNameAndLastname(String firstName, String lastName);
}
Spring Data JPA 提供的查询关键字
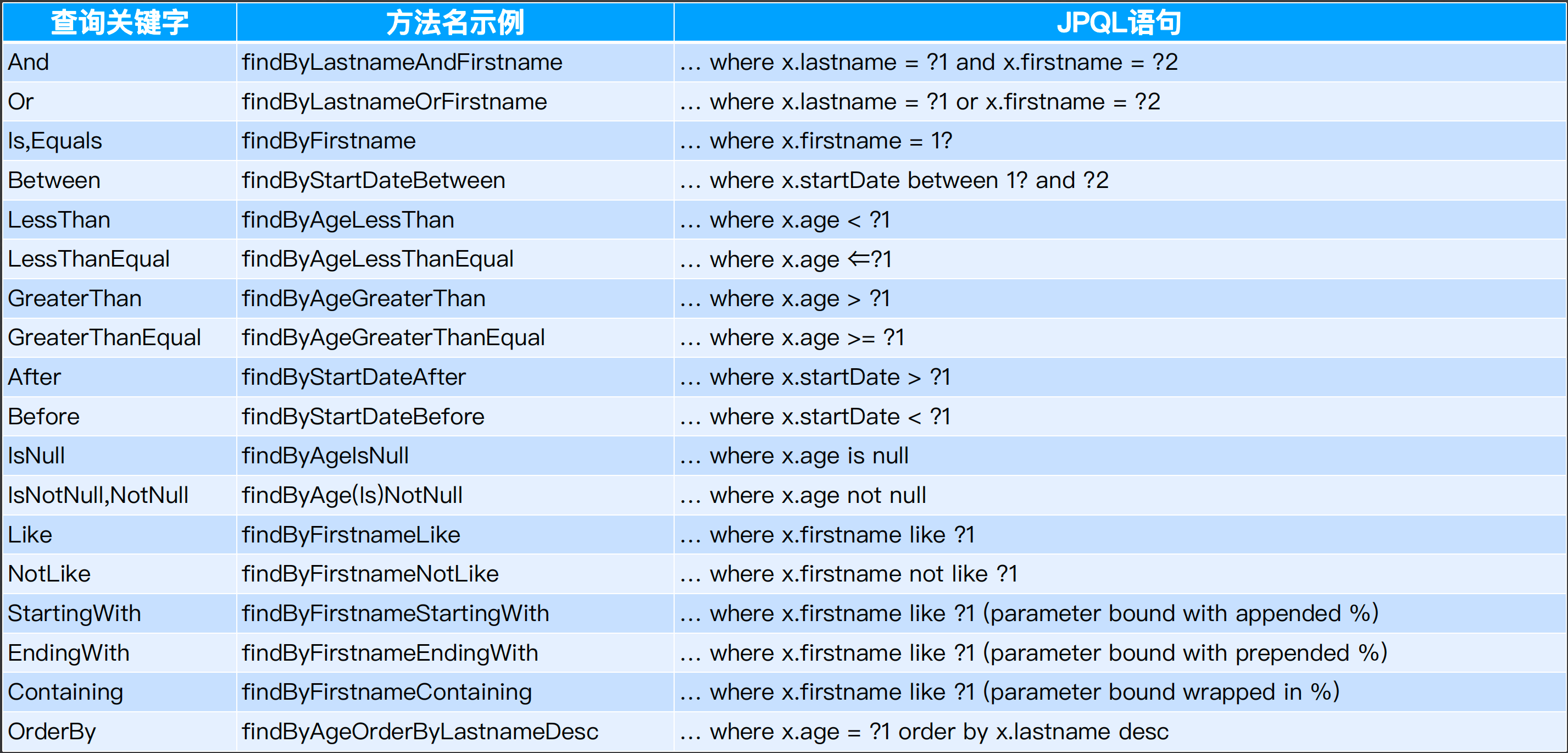
(3)QueryByExample机制
方法名衍生查询如果入参太多,泽会导致方法名冗长、必须填充所有参数、新的查询条件不易扩展等问题。QueryByExample可以翻译成按示例查询,是一种用户友好的查询技术。它允许动态创建查询,并且不需要编写包含所有字段名称的查询方法。
public interface OrderRepository extends JpaRepository<Order, Long>, QueryByExampleExecutor<Order> {
public Order getOrderByOrderNumberByExample(String orderNumber) {
Order order = new Order();
order.setOrderNumber(orderNumber);
//1.使用ExampleMatcher初始化匹配规则
ExampleMatcher matcher = ExampleMatcher.matching().withIgnoreCase()
.withMatcher("orderNumber", GenericPropertyMatchers.exact()).withIncludeNullValues();
//2.通过ExampleMatcher和业务对象构建Example对象
Example<Order> example = Example.of(order, matcher);
//3.通过QueryByExampleExecutor接口中的findOne方法实现了QueryByExample机制
return orderRepository.findOne(example).orElse(new JpaOrder());
}
}
(4)Specification机制:
考虑这样一种场景,我们需要查询某个实体,而给定的查询条件是不固定的,这时候就需要动态构建相应的查询语句。在Spring Data JPA中可以通过JpaSpecificationExecutor接口实现这类查询。相比JPQL,使用Specification机制的优势是类型安全。
Root对象代表所查询的根对象,可以通过Root获取实体中的属性;CriteriaQuery代表一个顶层查询对象,用来实现自定义查询;而 CriteriaBuilder显然是用来构建查询条件
public interface OrderRepository extends JpaRepository<Order, Long>, JpaSpecificationExecutor<Order>{}
public interface Specification {
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder);
}
public Order getOrderByOrderNumberBySpecification(String orderNumber) {
Order order = new Order(); order.setOrderNumber(orderNumber);
Specification<Order> spec = new Specification<Order>() {
@Override
public Predicate toPredicate(Root<Order> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
//从root对象中获取了orderNumber属性
Path<Object> orderNumberPath = root.get("orderNumber");
//将该属性与传入的orderNumber参数进行比对,从而完成查询条件的构建
Predicate predicate = cb.equal(orderNumberPath, orderNumber);
return predicate;
}
};
return orderRepository.findOne(spec).orElse(new Order());
}
项目实际
(1)导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
(2)实体类:添加@Entity注解让JPA识别,同时这是表名、主键和主键生成策略
@Entity
@Table(name = "hangzhou_customer_staff")
public class HangzhouCustomerStaff implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
/**
* 昵称
*/
private String nickname;
(3)Repository
public interface HangzhouCustomerStaffRepository extends JpaRepository<HangzhouCustomerStaff, Long> {
List<HangzhouCustomerStaff> findByIsDeletedFalse();
List<HangzhouCustomerStaff> findByUpdatedAtAfter(Date updatedTime);
}
JpaRepository中已经提供了很多基础方法,同时继承了PagingAndSortingRepository来做分页和排序。
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
(4)配置文件(选择 JPA 的实现)
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.249.130:3306/customer_hangzhou?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8
username: root
password: root
jpa:
properties:
hibernate:
dialect: org.hibernate.dialect.MySQLDialect
3、经典查询N + 1问题解析
类与类之间存在1对n或者n对1的关系。
1对N:当通过一条SQL查询一个对象, 还需要将关联集合里的对象查出。集合存在n个对象,所以需要发出n条SQL,这样就发出了1+n条SQL。
N对1:当通过一条SQL查询到了n个对象,由于关联的存在需要将关联的一方取出,也需要发出n条SQL,这样的话也发出了1+n条SQL。
如下面的代码,一个账号会有多个权限,一个权限也对应多个账号,就存在多对多的问题。
@Entity
@Table(name = "account")
public class Account {
@ManyToMany
@JoinTable(name = "account_authority", joinColumns = @JoinColumn(name = "account_id"), inverseJoinColumns = @JoinColumn(name = "authority_id"))
Set<Authority> authorities = new HashSet<>();
}
@Entity
@Table(name = "authority")
public class Authority {
@ManyToMany(mappedBy = "authorities")
private Set<Account> accounts = new HashSet<>();
}
那么在按照原本的Repository写法,就会导致 N+1 现象,例如现在有十个账号和十个权限,每个账号都有这十个权限,如果查询所有账号时,JPA 分两步查询,第一步,使用一个sql查询所有的账号,此时会查到十个账号,然后针对每一个账号查询其权限并组装到账号对象中,那么就又查询了十次,总共执行了十一次查询。
结局方案有很多,例如 JOIN FETCH机制,GraphSql等,这里说一下 JOIN FETCH 机制。
JOIN FETCH机制 :
Fetch则是抓取策略,它的作用就是指明Entity的哪些关联对象会在加载这个Entity时一同被加载出来。
@Query("SELECT obj FROM Account obj JOIN FETCH obj.authorities")
List<Account> findAccounts();
Fetch也不会在where子句对它们进行过滤,结果是通过返回的Entity导航得到的。
@Query("SELECT obj FROM Account obj JOIN FETCH obj.authorities WHERE obj IN :accounts")
List<Account> findAccounts(@Param(value = "accounts") List<Account> accounts);
JOIN FETCH机制的优缺点分析:
优点: 在一个查询SQL中获取所有数据,从性能的角度来看具备优势
缺点:需要编写额外的代码来执行查询,特别是实体之间关联关系非常复杂的场景下
如果需要JOIN FETCH的查询数较少,那么这个机制将是一种很好的解决方法,如果数据量较大,那么通过代码在内存层面操作也是可以的。
JOIN FETCH 实际上是为了性能,而违反了Repository架构。
4、数据访问优化策略
(1)优化Fetch Size
应用程序和数据库服务器之间的网络通信是影响性能的关键因素之一。
如果能够减少网络流量,就能帮助我们提高性能。这时候就可以使用Fetch Size属性。取决 于JDBC驱动程序,Fetch Size可以用来指定一次从数据库检索的行数。通过合理设置Fetch Size的大小,就可以通过降低网络通信的次数来提升系统性能。
注意:Fetch Size不应该硬编码,而需要确保它的可配置性,因为它取决于JVM堆内存大小,不同的环境会有所不同。如果Fetch Size设置过大,应用程序可能会遇到内存不足的问题。
JdbcTemplate jdbc = new JdbcTemplate(dataSource);
jdbc.setFetchSize(200);
(2)优化连接池配置
设置连接池大小:
initialSize:定义启动连接池时将建立的连接数。
maxActive:用于限制与数据库建立的最大连接数。
maxIdle:用于始终保持池中空闲连接的最大数量。
minIdle:用于始终保持池中空闲连接的最小数量。
timeBetweenEvictionRunsMillis:用于设置清理线程的触发周期
检查连接泄露:
removeBandonedTimeout:如果连接运行的时间超过这个属性,则认为该连接已被放弃
removeAbandoned:此标志应为true,意味着那些被放弃的连接会被自动删除
验证连接:
testOnBorrow:当该属性定义为true时,将在使用之前验证连接对象
validationInterval:该属性定义验证连接的频率
validationQuery:该属性通过发送 SELECT 1查询语句来验证池中的连接
(3)使用批处理和选择合适的提交模式
在大多数标准JDBC API中,默认的提交模式是自动提交(Auto Commit)。也就是说,数据库驱动程序在每个SQL语句操作之后向 数据库发送一个提交请求。这个请求需要一次网络调用。即使执行 SELECT这种没有对数据库进行任何更改的SQL语句也是如此。这显 然会影响性能,因为在提交事务时,数据库服务器必须将事务所做的 更改写入数据库,这一过程涉及到昂贵的磁盘输入/输出。因此,我 们可以把自动提交模式设置为OFF以提高应用程序的性能。
但是对于某些应用程序,将自动提交模式设置为关闭并执行手动提交也是不可取的。例如,考虑一个允许用户将钱从一个帐户转移到另一个帐户的银行应用程序。为了确保转账工作的数据完整性,需要在两个帐户都在新金额更新之后提交事务。
//不使用批处理的数据插入代码
PreparedStatement ps = conn.prepareStatement("INSERT INTO USER VALUES (?, ?)");
for(n=0;n<100;n++){
ps.setInt(userNumber[n]);
ps.setString(usertName[n]);
ps.executeUpdate();
}
//使用批处理的数据插入代码
PreparedStatement ps = conn.prepareStatement("INSERT INTO USER VALUES (?, ?)");
for(n=0;n<100;n++){
ps.setInt(userNumber[n]);
ps.setString(userName[n]);
ps.addBatch();
}
ps.executeBatch();
(4)通过统计找到数据访问瓶颈
//使用generate_statistics属性来收集数据访问过程数据
spring.jpa.properties.hibernate.generate_statistics=true
//配置延迟加载
spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
(5)使用延迟加载
//通过FetchType.LAZY配置项来启用延迟加载
@OneToMany(cascade = CascadeType.ALL,fetch = FetchType.LAZY)
@JoinColumn(name = "account_id")
private List<Authority> authorities;
(6)使用多级缓存提升数据访问性能
一级缓存就是指一次请求(Request)级别或者说会话(Session)级别的缓存,针对每次查询操作,一级缓存会把数据放在会话中。
二级缓存的范围则更大一点,它是一种全局作用域的缓存。只要应用程序处于运行状态,那么所有请求和会话都可以使用。
//MyBatis一级缓存默认开启级别配置项
<setting name="localCacheScope" value="SESSION"/>
//启用MyBatis二级缓存配置项
<setting name="cacheEnabled" value="true"/>
三、使用HATEOAS构建自解释Web API
1、从RESTful到HATEOAS
现在的应用基本上都是前后端分离架构,前后端分离架构需要:
尽量通过 WEB API 的设置,减少网络请求的负载
API 设计的灵活,增进客户端的灵活性
增进API的可探索性,也就是看了第一个 API,就知道第二个 API
RESTful风格的全称是Representational State Transfer,中文叫表述性状态转移,包含Resource(资源,即数据,比如User、Order等)、 Representation(某种表现形式,比如用JSON、XML、JPEG)和 State Transfer(状态变化,通过HTTP动词实现)
RESTful 风格有自己的成熟度模型(Richardson REST):
第一阶段:使用HTTP作为传输方式
第二阶段:使用资源,定义数据结构,可以做增删改查等操作
第三阶段:使用HTTP动词(使用get、post、put、delete)
第四阶段:使用超媒体控制
超媒体基本概念:超文本 + 超链接,在超文本中嵌入超链接,就是超媒体
超文本(Hypertext):HTTP(Hypertext Transfer Protocol)协议实际上是一种超文本传输协议
超链接(Hyperlink) :在HTTP协议中,我们会使用到用于表明资源地址的超链接
从 Web MVC 到 HATEOAS:
HATEOAS全称叫做 Hypermedia As The Engine Of Application State),中文叫超媒体应用状态引擎,代表了REST成熟度的最高级别,HATEOAS 的核心价值在于能够开发自解释的 Web API。
HATEOAS示例:
由于在响应中包含了链接地址,因此使用该API的客户端就能够自由选择要加载不同类型(精简的、正常的以及详细的)的用户信息。
如下面请求示例,从一个请求中,可以知道用户的基本信息接口地址、公共信息接口地址、详细信息接口地址,那么客户端就能够根据不同的场景来选择最适合自己的请求地址并进一步发起请求,而服务器端也就不需要一次同时返回所用三个不同版本的用户信息
GET https://api.example.com/profile
{
"name": "tianyalan",
"info": {
"simplified": "https://user.example.com/users/simplified",
"common": "https://user.example.com/users/common",
"details": "https://user.example.com/users/details"
}
}
HATEOAS 的优势:
传统模式下,客户端需要根据服务器提供的相关文档来了解所暴露的资源和对应的操作;HATEOAS 在一定程度上打破了客户端和服务器之间严格的契约,使得客户端可以更加智能和自适应。
客户端可以通过服务器提供的资源的表达来智能地发现可以执行的操作,也就是所谓的自解释 Web API。
HATEOAS 应用示例:Spring Boot Actuator
{
"_links":{
"self":{
"href":"http://localhost:8080/actuator",
"templated":false
},
"health-path":{
"href":"http://localhost:8080/actuator/health/{*path}",
"templated":true
},
"health":{
"href":"http://localhost:8080/actuator/health",
"templated":false
},
"info":{
"href":"http://localhost:8080/actuator/info",
"templated":false
}
}
}
HATEOAS 和 HAL:
HATEOAS更多只是一种概念,而HAL(Hypertext Application Language, 超文本应用语言)是HATEOAS的一种实现方式 ,其是使用 Json 来表示的,里面包含了很多链接以及资源。
使用HAL设计API :
传统风格请求和响应
GET http://api.example.com/users/tianyalan
Content-Type: application/json
{
"id": "1",
"name": "tianyalan",
"email": "tianyalan@email.com"
}
HAL风格请求和响应
GET http://api.example.com/users/tianyalan
Content-Type: application/json
{
_links: {
self: {
href: "/users/tianyalan"
}
}
"id": "1",
"name": "tianyalan",
"email": "tianyalan@email.com"
}
使用HAL描述API:
使用HAL+JSON来描述一个带有location属性的user信息,我们就可以很清晰的知道user信息和location信息的来源,这些信息都在子资源中有所体现
GET http://api.example.com/users/tianyalan
Content-Type: application/json
{
_links: {
self: {
href: "/users/tianyalan"
}
}
"id": "1",
"name": "tianyalan",
"email": "tianyalan@email.com"
_embedded: {
location: {
_links: {
self: {
href: 'http://api.locationservices.com/locations/1'
}
},
id: 1,
city: 'hangzhou'
}
}
}
前后端交互还是需要有文档的,HAL 对应的自动化工具是 HAL 浏览器。
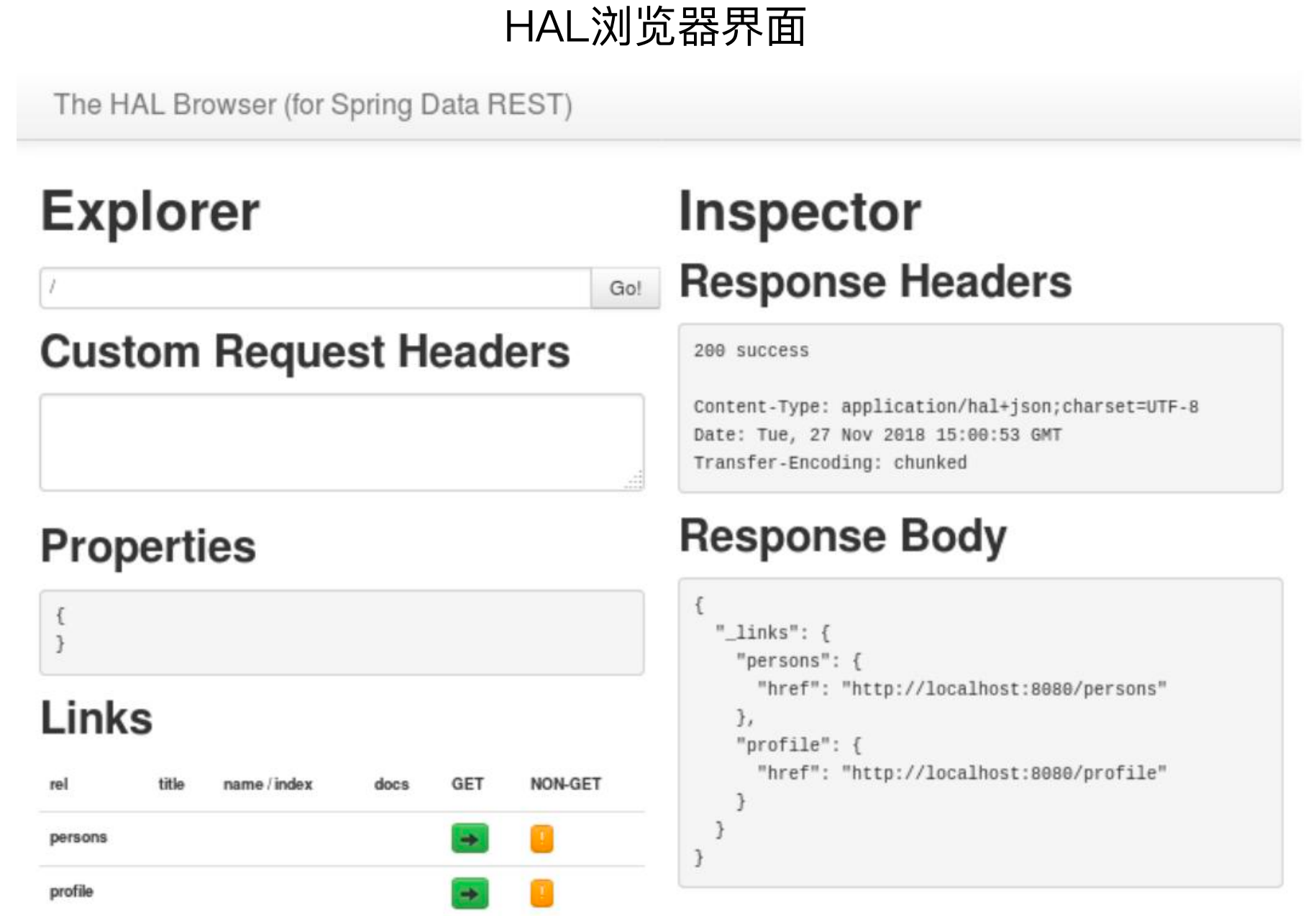
2、Spring HATEOAS框架
Spring HATEOAS提供了一组类和资源装配器(Assembler),当资源从Spring WebMVC控制器返回时,可以实现在这些资源之前添加对应的链接。
Spring HATEOAS试图解决链接的创建和表示的组装的问题,其他的开发和传统的Controller开发没太大区别。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-hateoas</artifactId>
</dependency>
Spring HATEOAS 开发步骤和核心组件:
创建资源和链接:EntityModel和CollectionModel 表示单个和多个资源,能够承载指向其他资源的链接
创建资源装配器:RepresentationModelAssembler 把各种Link、Affordance等对象进行有效的组合
Spring HATEOAS 核心方法:
methodOn:相当于为Controller创建了一个代理类,该代理类记录Controller 中指定方法的调用,也就是将Controller中制定方法添加为一个连接
linkTo:为methodOn方法指定的目标方法创建一个链接
afford:代表“功能可见性”,通过Affordances来展示Controller中所具备的其他功能,例如调用查询的时候,将Controller中的其他方法也返回,让客户端看到该Controller中还有删除等方法。
3、系统案例演进
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-hateoas</artifactId>
</dependency>
添加一个资源装配器
@Component
public class HypermediaCustomerStaffAssembler implements SimpleRepresentationModelAssembler<CustomerStaff> {
@Override
public void addLinks(EntityModel<CustomerStaff> resource) {
Long id = resource.getContent().getId();
resource.add(linkTo(methodOn(HypermediaCustomerStaffController.class).single(id)).withSelfRel());
resource.add(linkTo(methodOn(HypermediaCustomerStaffController.class).all()).withRel("customerStaffs"));
}
@Override
public void addLinks(CollectionModel<EntityModel<CustomerStaff>> resources) {
resources.add(linkTo(methodOn(HypermediaCustomerStaffController.class).all()).withSelfRel());
}
}
Controller编写
@RestController
@RequestMapping("/hypermedia/customerStaffs")
public class HypermediaCustomerStaffController {
@Autowired
ICustomerStaffService customerStaffService;
@Autowired
HypermediaCustomerStaffAssembler assembler;
@GetMapping("/{staffId}")
public EntityModel<CustomerStaff> single(@PathVariable("staffId") Long staffId) {
CustomerStaff customerStaff = customerStaffService.findCustomerStaffById(staffId);
// 为当前的请求创建一个Link
Link selfLink = linkTo(methodOn(HypermediaCustomerStaffController.class).single(staffId)).withSelfRel();
// 为CustomerStaff跟请求地址创建一个Link
Link rootLink = linkTo(methodOn(HypermediaCustomerStaffController.class).all()).withRel("customerStaffs");
return EntityModel.of(customerStaff, selfLink, rootLink);
}
@GetMapping("/")
public CollectionModel<EntityModel<CustomerStaff>> all() {
List<CustomerStaff> customerStaffs = customerStaffService.findCustomerStaffs();
return assembler.toCollectionModel(customerStaffs);
}
}
四、使用WebFlux构建响应式Web API
1、响应式编程及其应用场景
Web MVC使用的是Servlet容器,核心的Servlet容器是DispatcherServlet,Servlet是同步阻塞的。
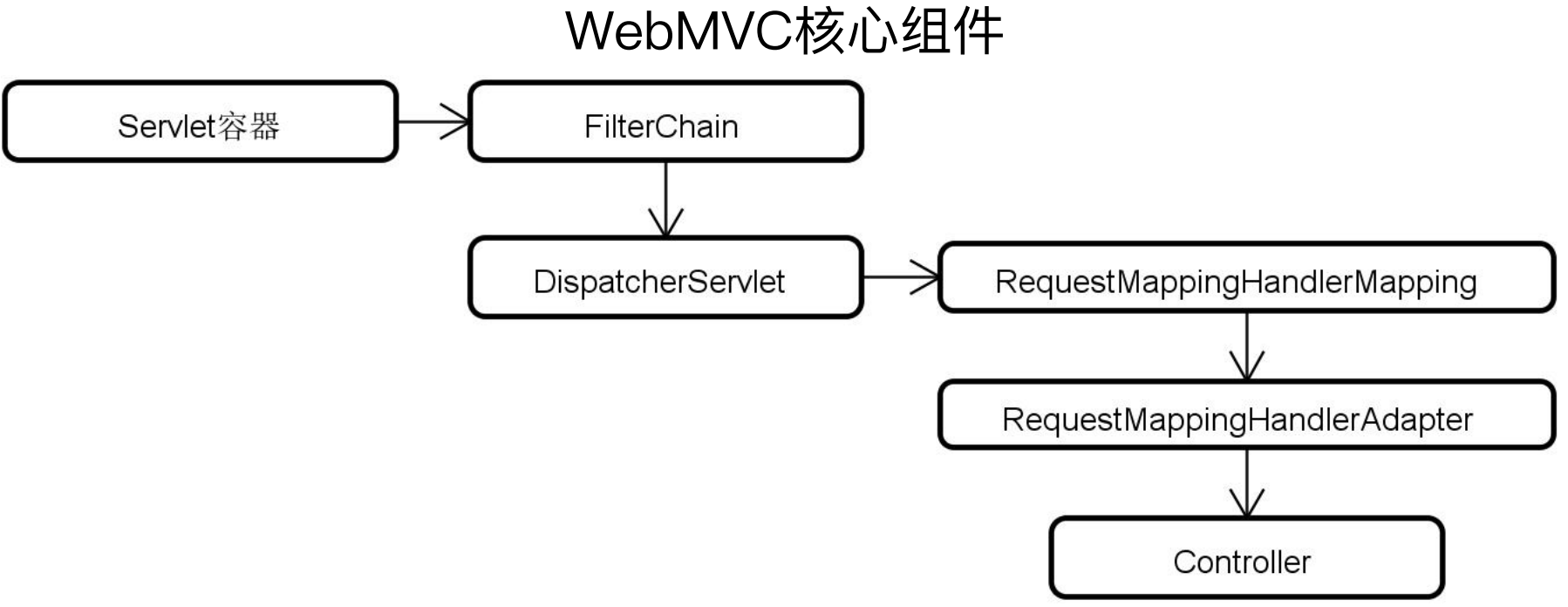
同步执行过程分析:当服务B向服务A发送HTTP请求时,线程B只有在发起请求和响应结果的一小部分时间内在有效使用 CPU,而更多的时间则只是在阻塞式地等待来自服务A中线程的处理结果。显然,整个过程的CPU利用效率是很低的,很多时间被浪费在了I/O阻塞上,无法执行其他的处理过程。
同步的传递性:沿着Web服务层->业务逻辑层->数据访问层整个调用链路中,每一步的操作过程都存在着前面描述的线程等待问题。也就是说,整个技术栈中的每一个环节都可能是同步阻塞的。
异步执行策略:
回调(Callback):一个线程执行完马上返回,如果有结果了进行回调处理,这样就可以做异步处理了。但是回调的核心问题在于如果回调过多,就会不停的回调,处理过程会形成一种嵌套结构,代码开上去很凌乱且难以调试,给代码的开发和调试带来很大的挑战,因为回调太多,一个请求发出后,请求走到哪里都很难定位,所以回调并不是一个很好的东西,简单的一两个环节进行回调是可以的,太多的回调就会陷入回调地狱,导致代码几乎无法维护。
Future机制:本质上是一种多线程技术,大量线程之间的相互协作需要频繁进行上下文切换,同样会导致资源利用效率低下。
由于回调机制和Future机制的问题,那么如何解决异步处理的问题呢,现在基本上都采用发布订阅模式和事件驱动架构。
发布订阅模式的本质是将所有的操作过程使用事件进行解耦,如下图所示,服务A是发布者,将事件发布到事件处理平台,服务B和服务X作为订阅者查看事件是否已经被响应或者响应结果是什么,各个响应者可以设定自己的响应过程,不用跟其他订阅者耦合在一起。那么响应式编程也是在这种理念下,将全链路使用事件进行传播,从而避免了同步阻塞。
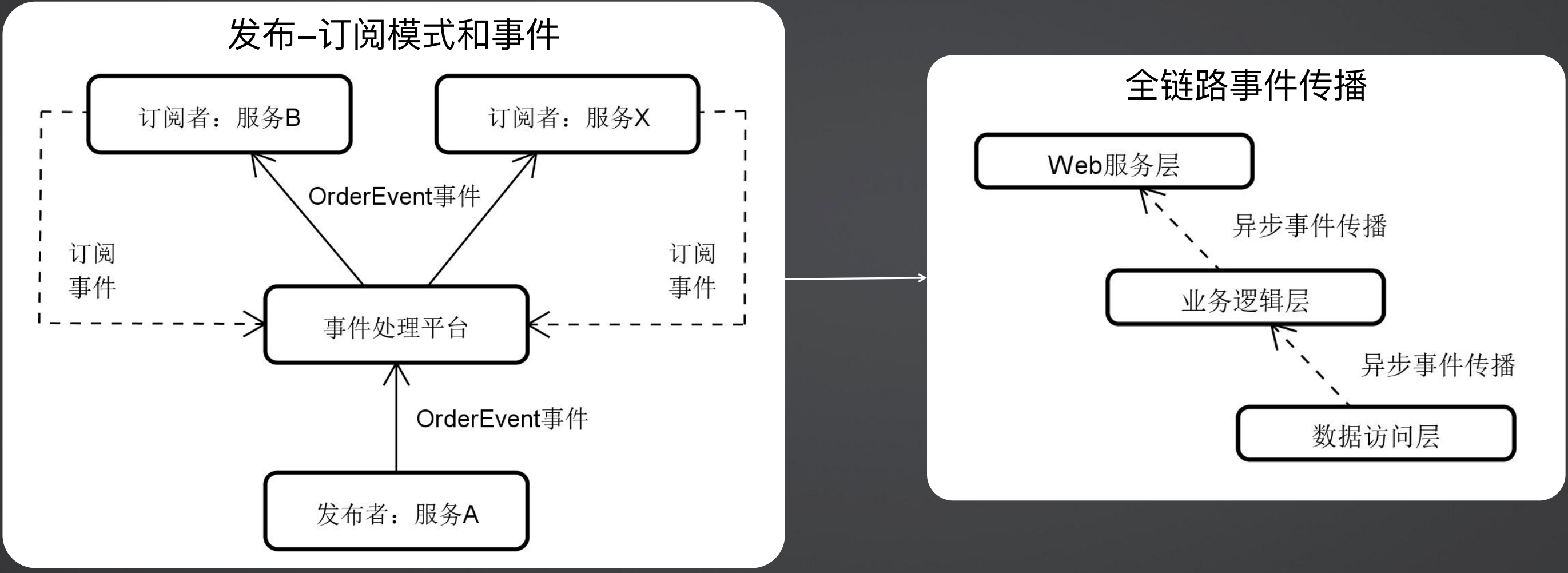
响应式编程的工作机制:围绕数据流,传统开发所普遍采用的“拉”模式,而“推”的工作方式生成事件和消费事件的过程是异步执行的,所以线程的生命周期都很短,也就意味着资源之间的竞争关系较少,服务器的响应能力也就越高。
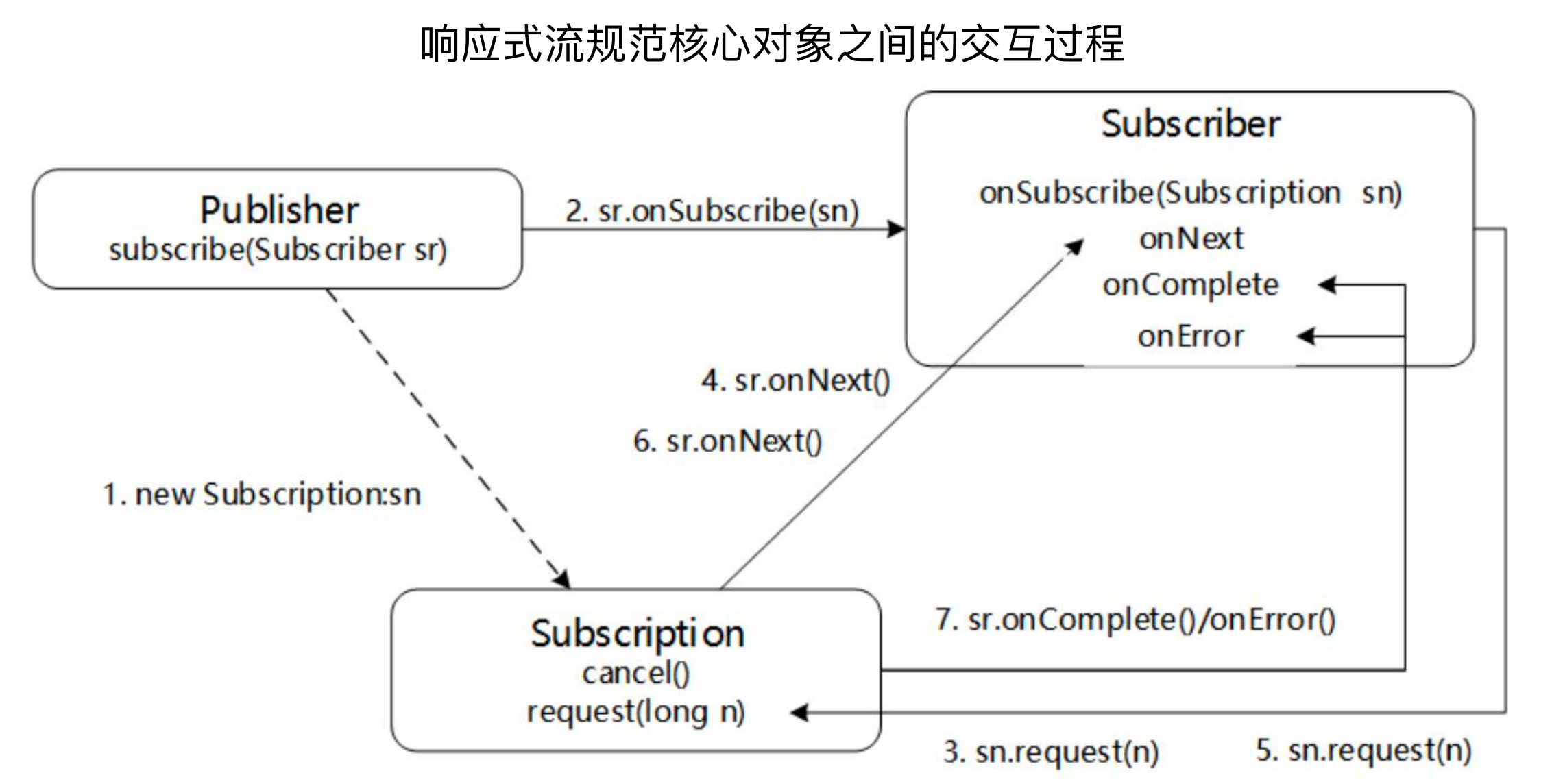
响应式流规范:
这是一个规范,和 JDBC 规范 JPA 规范一样,提供了一些接口,只要调用这些接口就可以做相应的处理。
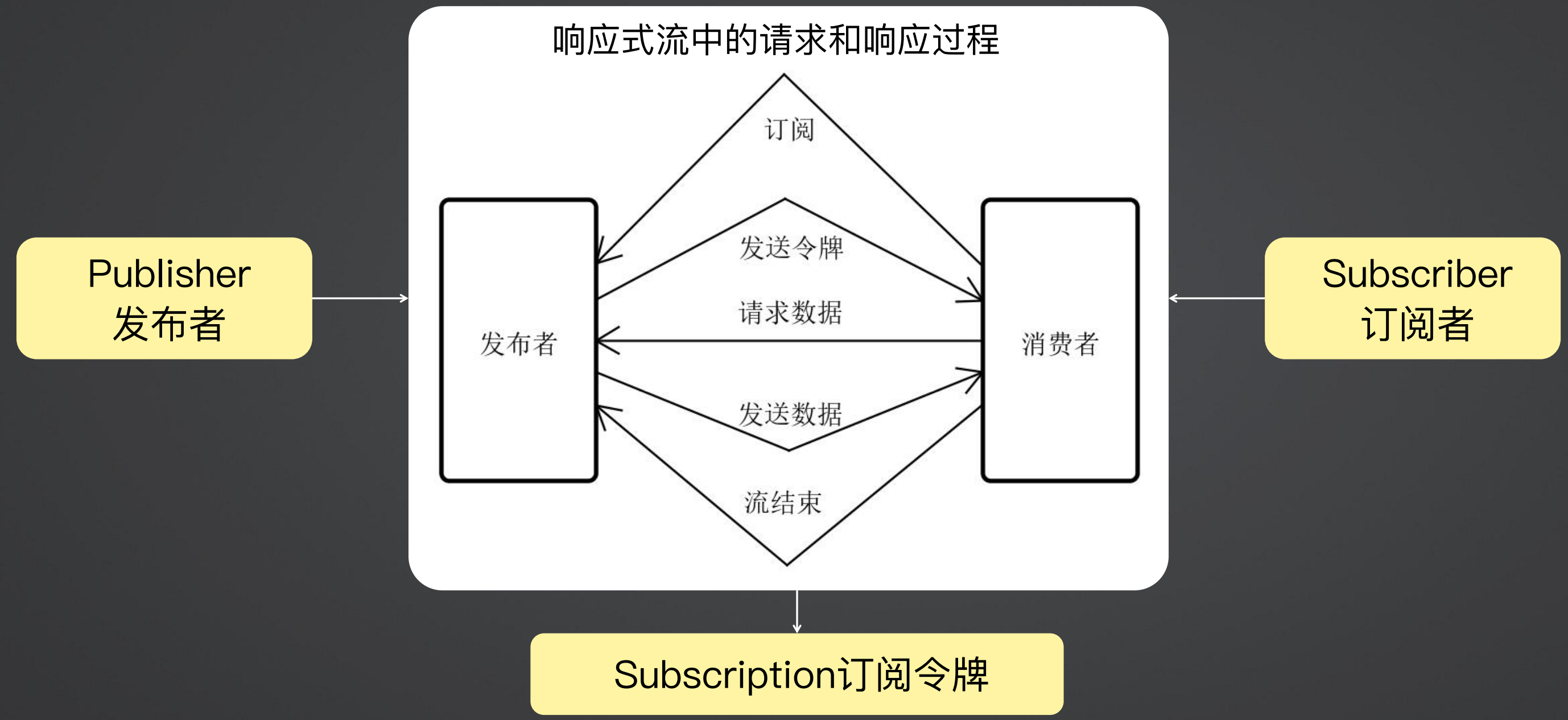
响应式规范定义了发布者、订阅者、订阅令牌三个对象,执行流程如下:
订阅者会去订阅发布者
发布者发送令牌,告诉订阅者其需要哪些数据
订阅者请求发布者获取数据
发布者将数据发送给消费者
结束流程,同时告诉发布者流程是成功还是失败
流量控制和背压机制:
纯推模式:订阅者通过subscription.request(Long.MAX_VALUE)请求无限数量元素,即发布者不关心消费者的消费能力,有数据就推送
纯拉模式:订阅者通过subscription.request(1)方法请求下一个元素,即消费者根据自身的消费能力进行消费
推-拉混合模式: 当订阅者有实时控制需求时,发布者可以适应所提出的数据消费速度
背压机制(Backpressure):响应式编程的核心,是对于推拉混合模式的优化,即下游能够向上游反馈流量请求的机制
响应式流程完整执行过程:
创建一个请求令牌,里面包含发布者需要多少数据
发布者与订阅者进行订阅绑定
订阅者请求数据,其中请求的条数N,是通过请求令牌设置的
发布者知道消费者可以消费的数量为N,那么就使用onNext不停的给消费者发送数据;消费者消费完N条数据后,重新请求,不断地循环
当所有的数据都处理完毕后,结束整个流程(完成或异常)
响应式编程的应用场景:
数据流处理:低延迟和高吞吐量需求,如Netflix Hystrix中的滑动窗口。Hystrix使用滑动窗口来收集当前系统运行时的一些动态数据,例如请求量多少、成功多少、失败多少、比例多少、滑动窗口的收集范围是多少等等,这些都是通过响应式流来做的,当系统中出现一个事件或者一个结果时,就会发布到滑动窗口,滑动窗口在一直滚动,收集相关数据并处理,最终形成统计。
微服务架构:涉及到大量的I/O操作 ,如Spring Cloud Gateway中的过滤器
高并发流量:异步非阻塞式的请求处理流程,如Spring WebFlux中的请求处理流程
2、Spring WebFlux编程组件
响应式流规范实现框架:
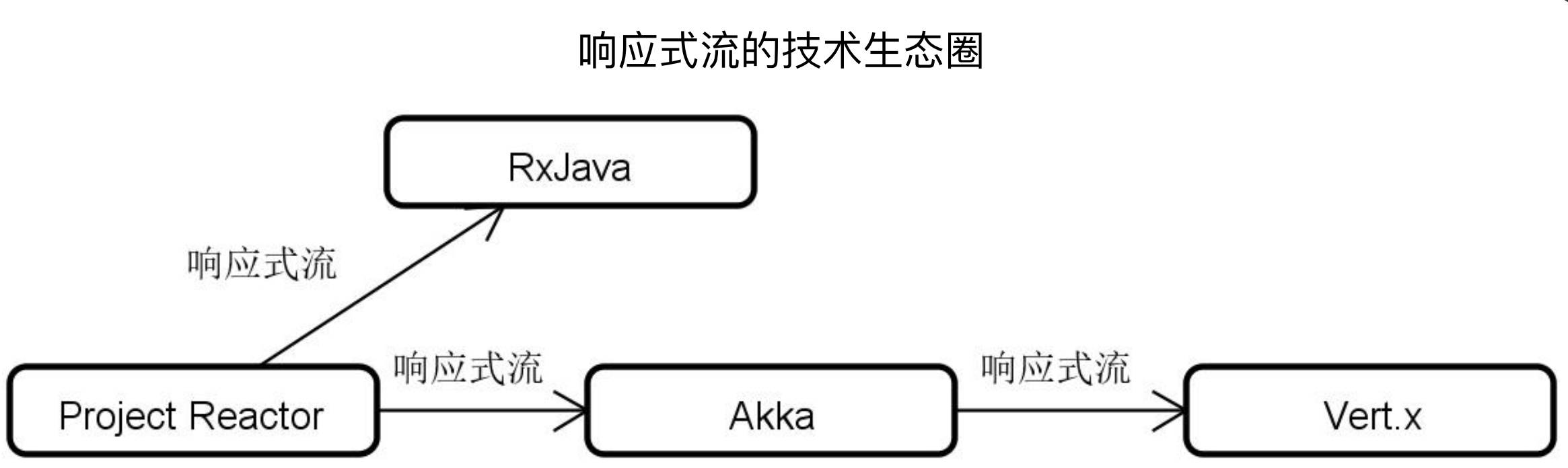
只有遵循响应式流规范,各个供应商都可以实现自己的响应式开发库,而这些开发库之间则可以做到互相兼容、相互交。上图是Java领域 使用响应式流实现的一些框架,例如 Project Reactor、RxJava(安卓,做客户端用的较多)、Akka、Vert.x等,由于这些框架都遵循了响应式流规范,因此相互之间是可以调用的,例如一些老的系统使用的是RxJava,然后新系统使用的是第三代响应式库Project Reactor,那么会有一些兼容性问题,那么就可以这样调用。
引入Project Reator:
在Project Reactor中将数据流进行了抽象成了三个部分,或者说三个类型,OnNext、OnError、OnComplete,用于判断当前流的状态。
数据流操作符:
在实际开发中,是不需要关心上面“引入Project Reactor”中描述的问题,我们一般是围绕一系列工具类或工具方法来处理的,其又最重要的两个工具类Flux和Mono,这两个的区别是一个或多个的问题,Flux表示包含0到n个元素的异步序列,而Mono表示0到1个元素的异步序列。然后可以使用这两个工具类创建一系列的响应式流。当一个响应式流到达后,开发人员需要根据不同的类型来选择合适的操作符进行处理,例如转换(对象的转换)、过滤(过滤哪些数据不往后传)、组合(数据合并)、日志(记录日志)等等
WebFlux:
Spring MVC是同步阻塞的,而Spring WebFlux是在Spring MVC的基础上做了一层封装,引入了响应式流,两者内部的命名还是比较想通的,例如类的命名,方法的命名等,包括开发模式也有很大的相似性,但是底层内核是完全不同的,Spring MVC内核是Servlet、Spring WebFlux内核是响应式流。
两者对于底层容器也是有区别的,Spring MVC容器可以使用阻塞式的容器,例如Tomcat,但是Spring WebFlux的容器只能用非阻塞式的容器,例如新版本的Tomcat、Jetty、Netty、Undertow等。
对于开发模式,Spring MVC使用的是@Controller、@RequestMapping这样的注解,而Spring WebFlux同样可以使用这样的开发模式,因为其底层做了很好的封装,同时Spring WebFlux还可以使用Router Functions(路由函数),在开发中还是比较建议使用老的开发模式,因为这种开发模式没有什么学习成本,可以和使用Spring MVC一样开发。
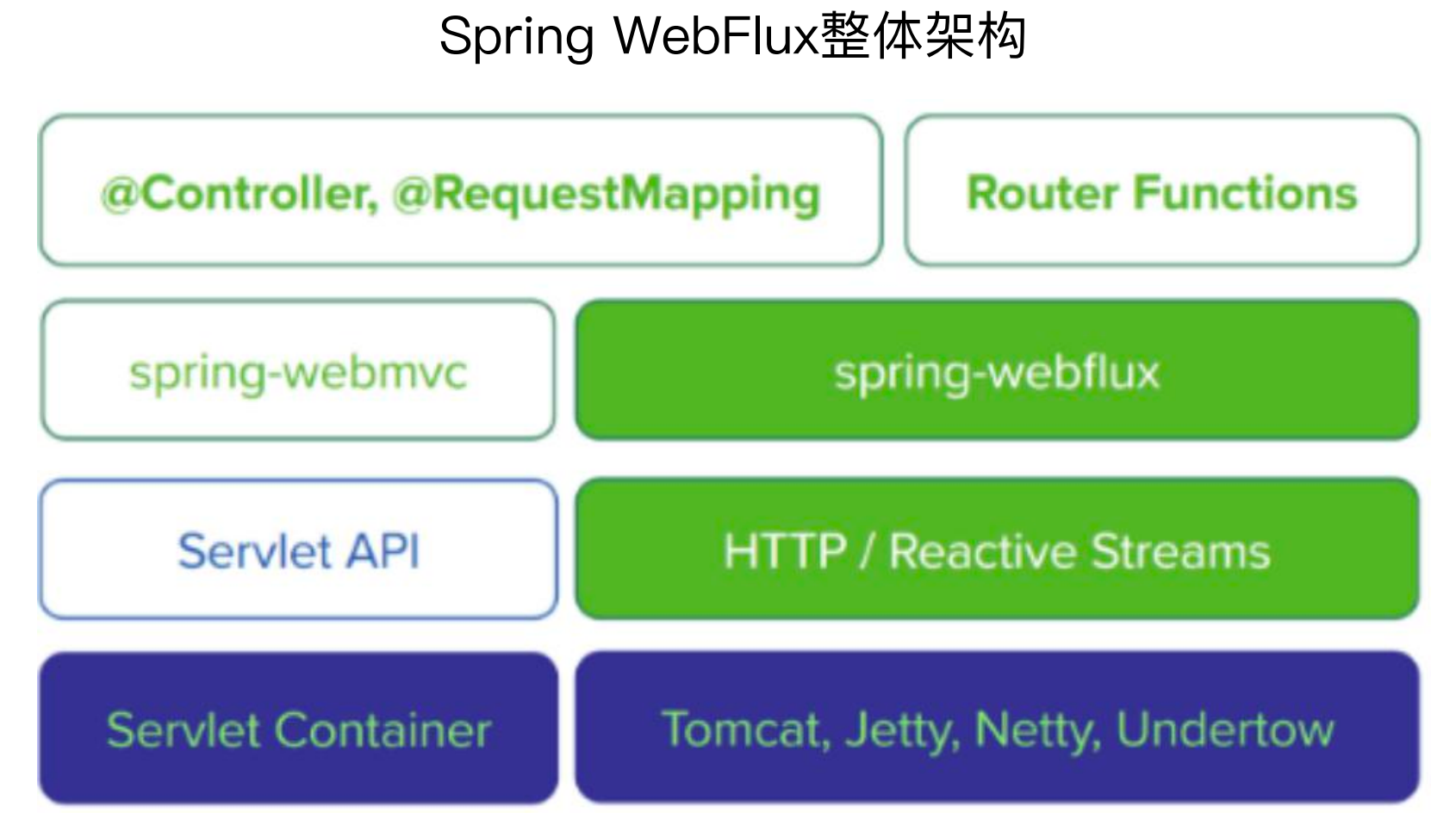
WebFlux的开发模式:函数式开发模式 + 传统注解开发模式
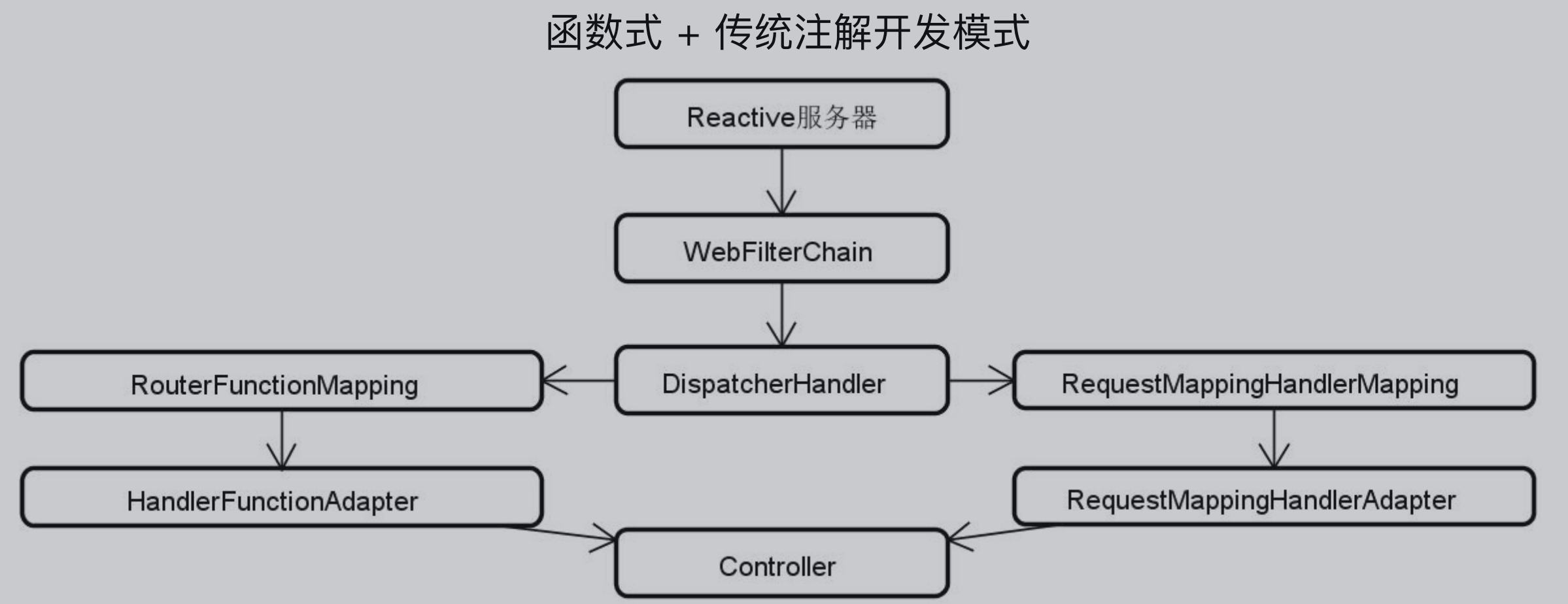
如上面说所说,WebFlux的开发模式有函数式开发模式和传统注解开发模式两种,下图是WebFlux的核心类,首先是一个Reactive服务器接收请求,然后将请求打到WebFilterChain过滤链进行过滤,再使用DispatcherHander进行请求转发,如果使用的是传统的开发方式,则走的是RequestMappingHandlerMapping和RequestMappingHandlerAdapter,如果是使用函数式开发模式,则走的是RouterFunctionMapping和HandlerFunctionAdapter,如论是函数式开发模式还是传统注解开发模式,最终都会将请求打入Controller。
传统的开发模式 VS 函数式开发模式:
@RestController、@GetMapping 、@PutMapping 、@PostMapping 、@DeleteMapping
ServerRequest 、ServerResponse、HandlerFunction、RouterFunction
WebFlux的开发模式 - 函数式示例 :
首先入口类不再是以Controller结束,而是以Handler结束,方法的返回值是带泛型的Mono或者Flulx。
@Configuration
public class UserHandler {
@Autowired
private UserService userService;
public Mono<ServerResponse> getUserById(ServerRequest request) {
Long userId = request.pathVariable("userId");
return ServerResponse.ok().body(this.userService.getUserById(userId), User.class);
}
......
}
有了上面的代码,还缺少请求路径,可以通过以下代码进行设置,将方法与请求路径绑定。
RouterFunction<ServerResponse> userRoute = route(GET("/users/{id}").and(accept(APPLICATION_JSON)), userHandler::getUserById)
.andRoute(GET("/users").and(accept(APPLICATION_JSON)), userHandler::getUsers)
.andRoute(POST("/users").and(contentType(APPLICATION_JSON)), userHandler::createUser);
3、系统案例演进
重构 customerStaffs 端点,嵌入响应式流。
首先要明白一点,使用响应式编程,整个链路都应该支持响应式编程,从Controller到Service,从Service到数据访问层,从数据访问层到数据库,再到数据库,都应该支持响应式编程,但是关系型数据库是不支持响应式编程的,这就导致如果使用关系型数据库就不能使用响应式编程。
为了解决这个问题,可以取一个巧,使用桩代码的方式进行演示。
引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
创建桩代码:
在桩代码中,使用Map集合模拟数据持久化操作,返回的对象都是带泛型的Mono或者Flux。
@Service
public class StubCustomerStaffService {
private final Map<Long, CustomerStaff> customerStaffMap = new ConcurrentHashMap<>();
public Mono<CustomerStaff> getCustomerStaffById(Long id){
return Mono.justOrEmpty(customerStaffMap.get(id));
}
public Flux<CustomerStaff> getCustomerStaffs(){
return Flux.fromIterable(customerStaffMap.values());
}
public Mono<Void> createOrUpdateCustomerStaff(Mono<CustomerStaff> customerStaffMono) {
return customerStaffMono.doOnNext(customerStaff -> {
customerStaffMap.put(customerStaff.getId(), customerStaff);
}).thenEmpty(Mono.empty());
}
public Mono<CustomerStaff> deleteCustomerById(Long id){
return Mono.justOrEmpty(customerStaffMap.remove(id));
}
}
Controller:编程方式和SpringMVC一样,但是返回值改为了Mono
@RestController
@RequestMapping("/reactive/customerStaffs")
public class ReactiveCustomerStaffController {
@Autowired
StubCustomerStaffService stubCustomerStaffService;
//新增CustomerStaff
@PostMapping("/")
public Mono<Void> addCustomerStaff(@RequestBody CustomerStaff customerStaff) {
//调用Service层完成操作
Mono<Void> result = stubCustomerStaffService.createOrUpdateCustomerStaff(Mono.just(customerStaff));
return result;
}
@PutMapping("/")
public Mono<Void> updateCustomerStaff(@RequestBody CustomerStaff customerStaff) {
Mono<Void> result = stubCustomerStaffService.createOrUpdateCustomerStaff(Mono.just(customerStaff));
return result;
}
@GetMapping("/{staffId}")
public Mono<CustomerStaff> findCustomerStaffById(@PathVariable("staffId") Long staffId) {
Mono<CustomerStaff> customerStaffMono = stubCustomerStaffService.getCustomerStaffById(staffId);
return customerStaffMono;
}
@GetMapping("/")
public Flux<CustomerStaff>findCustomerStaffs() {
Flux<CustomerStaff> customerStaffFlux = stubCustomerStaffService.getCustomerStaffs();
return customerStaffFlux;
}
@DeleteMapping("/{staffId}")
public Mono<CustomerStaff> deleteCustomerStaffById(@PathVariable("staffId") Long staffId) {
Mono<CustomerStaff> result = stubCustomerStaffService.deleteCustomerStaffById(staffId);
return result;
}
}
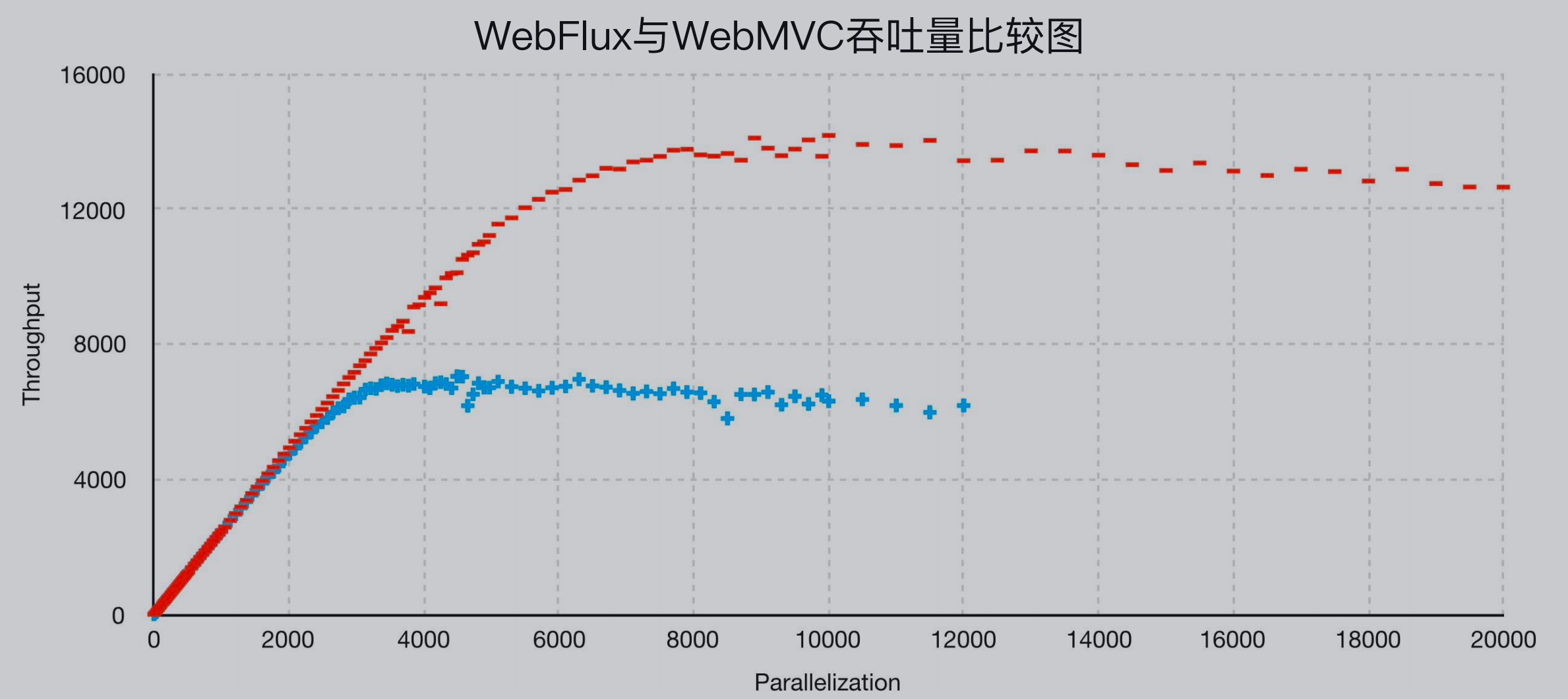
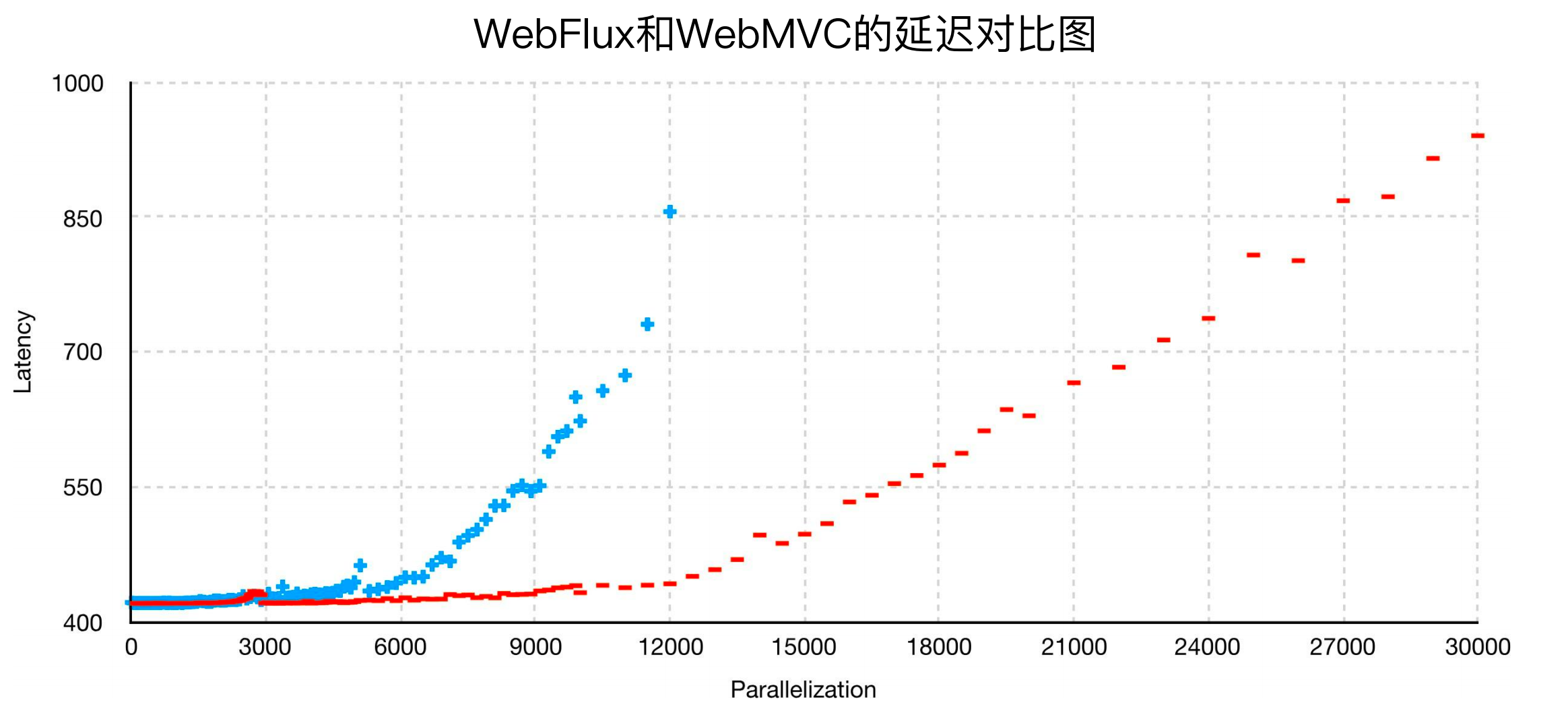
响应式编程的性能:
吞吐量对比:
延迟对比:
五、使用GraphQL开发前后端分离Web API
1、从RESTful到GraphQL
前后台分离架构的痛点:
后台开发人员修改了某一个字段的名称没有通知到前端
后台开发人员调整了返回值的类型和数量没有通知到前端
前端开发人员需要通过多个接口的拼接才能获取页面展示所需要的所有字段
前端开发人员无论想要多获取目标字段就需要与后台开发人员进行协商
RESTful API存在问题:
无法根据请求控制对应的返回结果
前端无法预判响应的数据格式
请求地址过多
多次请求
GraphQL是一种基于图(Graph)的查询语言(Query Language,QL),从根本上改变了前后端交互API的定义和实现方式能够解决传统RESTful API所存在的一系列问题。
GraphQL请求示例:
(1)除了在请求体中指定了目标Staff对象的参数id值之外,还额外指定了staffName和age这两个参数,也就是告诉服务器端这次请求所希望获取的数据字段
{
Staff(id: "1") {
staffName
age
}
}
(2)一方面指定了想要获取的Staff对象中的staffName、nickname和phone等字段,同时也可以指定该客服对应的客服分组字段group以及它的子字段groupName,从而做到数据的聚合,避免多次请求
{
staffs {
staffName
nickname
phone
group {
groupName
}
}
}
GraphQL如何解决RESTful API面临的问题
无法根据请求控制对应的返回结果:通过请求指定返回参数
前端无法预判响应的数据格式:响应数据格式和请求一致
请求地址过多:同一个端点可以传入不同的参数
多次请求:以图的方式聚合返回结果
2、GraphQL实现过程和框架
GraphQL实际上类似于一个规范,不限语言、工具、框架等,在Java领域,提供了GraphQL库,GraphQL Java 中有四大开发组件:Scheme、DataFetcher、RuntimeWiring、GraphQL对象
Scheme:
类比成RESTful API中的接口定义文档,定义前后端交互的数据结构和类型,定义根Query/Mutation来执行查询/更新操作。
如下的schema的定义,首先定义schema的类型是Query或Mutation,然后Query指向type为Query的定义
在Query中,定义了staffs和staff,staffs表示没有参数,返回一个CustomerStaff的数组;staff表示参数为int类型的id,返回一个CustomerStaff
CustomerStaff指向了type为CustomerStaff的定义,在CustomerStaff中定义了属性信息,其中group指向了CustomerGroup
schema {
query : Query
}
type Query {
staffs: [CustomerStaff]
staff(id: Int): CustomerStaff
}
type CustomerStaff {
id: Int
staffName: String
nickname: String
phone: String
goodAt: String
remark: String
group: CustomerGroup
}
type CustomerGroup {
id: Int
groupName: String
groupDescription: String
}
DataFetcher:
执行查询时获取输入字段对应的数据,通过DataFetchingEnvironment 获取传入的参数,数据查询操作的具体实现过程交由其他组件完成,例如Mapper,那么DataFetcher就有点类似Service层的组件。
public interface DataFetcher<T> {
T get(DataFetchingEnvironment dataFetchingEnvironment);
}
RuntimeWiring:
运行时组装把DataFetcher整合在GraphQL的运行环境中,例如下面的样例,将schema中Query定义的staffs和staff进行组装,组装的对象都是之前定义的DataFetcher。同时通过CustomerStaff运行组装group,形成了嵌套结构。
builder.type("Query", typeWiring -> typeWiring
.dataFetcher("staffs", allCustomerStaffsDataFetcher)
.dataFetcher("staff", customerStaffDataFetcher))
.type("CustomerStaff", typeWiring -> typeWiring
.dataFetcher("group", customerGroupDataFetcher));
GraphQL对象:
基于GraphQL对象完成具体的查询操作
String query = ......;
ExecutionResult result = graphQL.execute(query);
上面的样例使用的是偏底层的GraphQL,但是一般我们开发不使用这个,而是使用Spring集成GraphQL,其中GraphQL 是开发规范,GraphQL Java 是基础引擎和工具库 ,GraphQL Java Spring 是老一代Spring集成框架 ,Spring GraphQL 是 Spring顶级框架。
Spring GraphQL核心对象包括GraphQlSource 和 RuntimeWiringBuilderCustomizer,GraphQlSource 是Spring GraphQL中的核心抽象,用于访问 GraphQL实例以执行请求;RuntimeWiringBuilderCustomizer 是简化RuntimeWiring实现过程,根据具体业务场景进行设计并实现。
Spring GraphQL开发步骤:
设计领域对象
定义GraphQL Schema
实现数据访问层组件
定义DataFetcher
完成Data Wiring
获取GraphQL对象
实现查询
3、系统案例演进
系统查询需求:
能够以自定义字段的方式获取CustomerStaff列表
能够以自定义字段的方式获取单个CustomerStaff
所有获取的CustomerStaff中包含分组的GroupName属性
开发步骤
(1)设计领域对象:
也就是设计Entity,前面已经有了CustomerStaff,这次增加了分组信息,那么新建一个CustomerStaffCount,并创建表结构
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("customer_group")
public class CustomerGroup implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
/**
* 分组名称
*/
private String groupName;
/**
* 分组描述
*/
private String groupDescription;
}
CREATE TABLE `customer_group` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`group_name` varchar(45) NOT NULL COMMENT '分组名称',
`group_description` varchar(200) DEFAULT NULL COMMENT '分组描述',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='客服分组表'
(2)定义GraphQL Schema
schema {
query : Query
}
type Query {
staffs: [CustomerStaff]
staff(id: Int): CustomerStaff
}
type CustomerStaff {
id: Int
staffName: String
nickname: String
phone: String
goodAt: String
remark: String
group: CustomerGroup
}
type CustomerGroup {
id: Int
groupName: String
groupDescription: String
}
(3)实现数据访问层组件
之前也已经定义过Mapper,这次只需要新增CustomerGroupMapper即可
public interface CustomerGroupMapper extends BaseMapper<CustomerGroup> {
default CustomerGroup findCustomerGroupByName(String groupName) {
LambdaQueryWrapper<CustomerGroup> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(CustomerGroup::getGroupName, groupName);
return selectOne(queryWrapper);
}
}
(4)定义DataFetcher
引入依赖
<dependency>
<groupId>org.springframework.experimental</groupId>
<artifactId>graphql-spring-boot-starter</artifactId>
<version>1.0.0-M1</version>
</dependency>
这个依赖要从Spring仓库中拉取,因此要在pom.xml中配置Spring仓库
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
在Schema中定义的Query中有两个查询,同时在CustomerStaff中又引入了CustomerGroup,因此需要创建三个DataFetcher
创建CustomerStaffDataFetcher,数据从传入的dataFetchingEnvironment中获取,获取id的值,最终根据id进行查询并返回。
@Component
public class CustomerStaffDataFetcher implements DataFetcher<CustomerStaff>{
@Autowired
private CustomerStaffMapper customerStaffMapper;
@Override
public CustomerStaff get(DataFetchingEnvironment dataFetchingEnvironment) throws Exception {
String id = String.valueOf(dataFetchingEnvironment.getArguments().get("id"));
return customerStaffMapper.selectById(Long.valueOf(id));
}
}
创建AllCustomerStaffDataFetcher,这里没有入参,直接使用Mybatis-Plus的查询方式获取列表。
@Component
public class AllCustomerStaffDataFetcher implements DataFetcher<List<CustomerStaff>>{
@Autowired
private CustomerStaffMapper customerStaffMapper;
@Override
public List<CustomerStaff> get(DataFetchingEnvironment dataFetchingEnvironment) throws Exception {
LambdaQueryWrapper<CustomerStaff> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(CustomerStaff :: getIsDeleted, false);
return customerStaffMapper.selectList(queryWrapper);
}
}
创建CustomerGroupDataFetcher,这里和上面两个不同,上面的参数是直接传入的,这里的参数是关联了CustomerStaff,CustomerStaff的groupId与CustomerGroup的id是同一个值,因此需要使用dataFetchingEnvironment.getSource()获取传入的关联对象,然后再获取groupID进行查询。
@Component
public class CustomerGroupDataFetcher implements DataFetcher<CustomerGroup>{
@Autowired
private CustomerGroupMapper customerGroupMapper;
@Override
public CustomerGroup get(DataFetchingEnvironment dataFetchingEnvironment) throws Exception {
CustomerStaff customerStaff = dataFetchingEnvironment.getSource();
if(customerStaff != null){
return customerGroupMapper.selectById(customerStaff.getGroupId());
}
return null;
}
}
完成Data Wiring:这一步是将上面定义的schema和dataFetcher进行绑定,type里面的key是schema中定义的type,typeWiring是type中定义的值和对应的dataFetcher进行绑定,如下所示的Query类型的staffs和staff,分别与allCustomerStaffDataFetcher和customerStaffDataFetcher进行绑定,而类型CustomerStaff中的group则与customerGroupDataFetcher进行绑定。
@Component
public class CustomerStaffDataWiring implements RuntimeWiringBuilderCustomizer {
@Autowired
private AllCustomerStaffDataFetcher allCustomerStaffDataFetcher;
@Autowired
private CustomerStaffDataFetcher customerStaffDataFetcher;
@Autowired
private CustomerGroupDataFetcher customerGroupDataFetcher;
@Override
public void customize(RuntimeWiring.Builder builder){
builder.type("Query", typeWiring -> typeWiring
.dataFetcher("staffs", allCustomerStaffDataFetcher)
.dataFetcher("staff", customerStaffDataFetcher))
.type("CustomerStaff", typeWiring -> typeWiring
.dataFetcher("group", customerGroupDataFetcher));
}
}
获取GraphQL对象:
使用构造函数注入GraphQL,使用graphQL.execute(query)进行查询,获取的结果是ExecutionResult
@RestController
public class CustomerStaffGraphQLController {
private GraphQL graphQL;
@Autowired
public CustomerStaffGraphQLController(GraphQlSource graphQlSource) {
graphQL = graphQlSource.graphQl();
}
@PostMapping("/query")
public ResponseEntity<Object> query(@RequestBody String query) {
ExecutionResult result = graphQL.execute(query);
return ResponseEntity.ok(result.getData());
}
}
实现查询:
POST localhost:8081/query/
Content-Type: application/json
{
staff(id: 3) {
staffName
nickname
phone
}
}
###
POST localhost:8081/query/
Content-Type: application/json
{
staffs {
staffName
nickname
phone
group {
groupName
}
}
}
###
可视化界面:访问:http://localhost:8081/graphiql
可以在页面中直接输入查询内容,就可以执行。

4、GraphQL实施策略
GraphQL 适用场景:
适用于业务复杂度高、需求变化快、弱文档化管理等场景,不推荐在任何场景下都使用GraphQL。
谁来驱动:
一般场景下前端对于引入GraphQL的述求要大于服务端,但是实现GraphQL的工作量主要是在服务端,所以一般情况下由前端来驱动,但是有时也会是后端主动来完善,也就是后端驱动。
RESTful API 怎么办:
同时可以采用RESTful和GraphQL并存策略,对于复杂RESTful API ,前端直接请求API,对于单一RESTful API ,前端通过数据层(GraphQL) 请求。
六、Spring Boot测试解决方案和实践
1、测试的类型和实施策略
测试可以分为类级别的单元测试、组件级别的集成测试、系统级别的端到端测试、手工测试,对于开发人员而言,每一种类型的测试都需要关注。
单元测试(类级别):
对于系统中存在的依赖关系,那就很难单独做单元测试,那么就需要使用Mock和Stub来对类和组件进行隔离。Stub是桩代码,需要实现模拟类的所有逻辑,即使是不需要关注的方法也至少要给出空实现;而Mock只需要模拟被使用的方法,对于没有使用到的方法可以不实现。
集成测试(组件级别):
验证工作主要在于需要确保服务内部数据和复杂业务流程的正确性,数据来源一般有关系型数据库、各种Nosql或垂直化搜索引擎等,复杂业务流程则主要面向多个内部服务和数据访问组件之间的整合。
例如Controller、Service、Repository这样一层层调用,那么就需要使用Stub或者Mock从Repository开始测试,Repository没问题了,再验证Service,Service没问题了,再验证Controller。
端到端测试(系统级别):
服务测试的内容即为各个服务之间基于RESTful风格下的HTTP远程调用层,为了完成整个业务流程,服务测试不得不考虑的问题是如何管理服务与服务之间的数据和状态传递。
2、Spring Boot测试方案和流程
Spring Boot测试依赖包:从2.2.0版本开始,Spring Boot引入了JUnit 5作为默认的单元测试库,因此需要先屏蔽spring-boot-starter-test中自带的junit-vintage-engine,然后重新引入junit-platform-launcher。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.junit.platform</groupId>
<artifactId>junit-platform-launcher</artifactId>
<scope>test</scope>
</dependency>
spring-boot-starter-test组件包括检索或设置JSON数据、流式断言工具、执行比较的匹配器、JUnit 基础框架、主流Mock测试框架

Spring Boot应用程序的测试流程:初始化测试用例、使用@SpringBootTest注解、使用@ExtendWith注解、执行测试用例。
如下代码所示,@SpringBootTest和@ExtendWith是核心注解, @Test是集成Junit,assertNotNull(this.applicationContext)是一个断言,对ApplicationContext进行非空验证
import static org.junit.jupiter.api.Assertions.assertNotNull;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.context.ApplicationContext;
import org.springframework.test.context.junit.jupiter.SpringExtension;
@SpringBootTest
@ExtendWith(SpringExtension.class)
public class ApplicationContextTests {
@Autowired
private ApplicationContext applicationContext;
@Test
public void testContextLoads() {
assertNotNull(this.applicationContext);
}
}
@SpringBootTest注解:
@SpringBootTest(classes = UserApplication.class, webEnvironment = SpringBootTest.WebEnvironment.MOCK)
classes:指定SpringBoot的启动类,不指定时,默认为启动类
webEnvironment:是一个枚举值,用来指定当前的 web 环境。枚举值选项如下:
MOCK:加载WebApplicationContext并提供一个Mock的Servlet环境,内置的Servlet容器并没有真实的启动
RANDOM_PORT:加载EmbeddedWebApplicationContext并提供一个真实的Servlet环境,也就是说会启动内置容器,然后使用的是随机端口
DEFINED_PORT:加载EmbeddedWebApplicationContext并提供一个真实的Servlet环境,但使用配置的端口(默认8080)
NONE:加载ApplicationContext但并不提供任何真实的Servlet环境
@ExtendWith注解:
@ExtendWith(SpringExtension.class)
Spring自身有测试环境配置Spring TestContext,可以提供用于测试Spring Boot应用程序的各项通用的支持功能,而JUnit5可以基于业务场景和交互过程编写和运行可重复的测试,SpringExtension可以将两者结合起来。
执行测试用例(3A原则):
Arrange:测试用例执行之前需要准备测试数据
Act:通过不同的参数来调用接口,并拿到返回结果
Assert:执行断言,判断执行结果是否符合预期
@Test
public void testUsernameIsMoreThan5Chars() throws Exception {
//Arrange
User user = new User("001", USER_NAME, 39, new Date(), "China");
//Act + Assert
assertThat(user.getName()).isEqualTo(USER_NAME);
}
测试样例:
@SpringBootTest
@ExtendWith(SpringExtension.class)
public class ApplicationContextTests {
@Autowired
private ApplicationContext applicationContext;
@Test
public void testContextLoads() {
assertNotNull(this.applicationContext);
}
}
3、测试数据访问层
数据访问测试的述求:
环境依赖性:如果不想污染数据库造成脏数据,那么如何在不使用外部数据库的前提下实现数据访问,这种一般会使用内存数据库,例如关系型数据库H2
组件隔离性:只是为了验证数据访问层是否正确,和Controller层以及Service层都没有什么关系,那么如何在不启动其他组件的情况下实现数据访问,这种一般会使用隔离数据访问组件
基于以上两点,很多开源框架都有相应的解决方案,例如SpringBoot和MybatisPlus都提供了相应的解决方案:
@MybatisPlusTest注解:通过限制Spring Boot自动配置来加载特定的数据访问模块,使用@AutoConfigureTestDatabase 注解来指定特定的数据源,从而提供了一种数据与环境之间的隔离机制。
添加依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
在test目录下创建resource目录,并新建application.yaml文件,添加数据库配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.249.130:3306/customer_system?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: root
编写测试类,主要用到了@ExtendWith和@MybatisPlusTest两个注解,已经不再使用@SpringBootTest注解,同时增加了@AutoConfigureTestDatabase注解,用以设置数据库,这里设置的值为AutoConfigureTestDatabase.Replace.NONE,即用配置文件中的数据库。
@ExtendWith(SpringExtension.class)
@MybatisPlusTest
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
public class CustomerStaffTests {
@Autowired
private CustomerStaffMapper customerStaffMapper;
@Test
public void testQueryCustomerStaffById(){
CustomerStaff customerStaff = customerStaffMapper.selectById(3L);
assertNotNull(customerStaff);
assertNotNull(customerStaff.getNickname().equals("tianyalan"));
}
}
@DataJpaTest注解:会自动注入各种Repository类,并会初始化一个内存数据库及访问该数据库的数据源。 借助于TestEntityManager完成数据的持久化,从而提供了一种数据与环境之间的隔离机制。
这里演示使用内存数据库,因此需要引入H2数据库的依赖
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
测试代码:
使用@AutoConfigureTestDatabase注解,不需要设置replace,表示这个对象使用了内存数据库,在测试方法中,调用entityManager的persist方法进行插入数据。
@ExtendWith(SpringExtension.class)
@DataJpaTest
@AutoConfigureTestDatabase
public class CustomerStaffRepositoryTests {
@Autowired
private TestEntityManager entityManager;
@Autowired
private HangzhouCustomerStaffRepository customerStaffRepository;
@Test
public void testCustomerSaffCreateAndQuery(){
HangzhouCustomerStaff customerStaff = new HangzhouCustomerStaff();
customerStaff.setIsDeleted(false);
customerStaff.setCreatedAt(new Date());
customerStaff.setUpdatedAt(new Date());
customerStaff.setNickname("lcl");
customerStaff.setGender("MALE");
this.entityManager.persist(customerStaff);
List<HangzhouCustomerStaff> result = customerStaffRepository.findByIsDeletedFalse();
assertThat(result).isNotNull();
assertThat(result.size()).isEqualTo(1);
}
}
4、测试业务逻辑层
(1)测试配置信息
Service层通常会依赖于配置文件,可以通过Environment接口实现对配置信息的验证,Environment接口提供了以下方法:
public interface Environment extends PropertyResolver {
String[] getActiveProfiles();
String[] getDefaultProfiles();
boolean acceptsProfiles(String... profiles);
}
Environment 集成 PropertyResolver 接口
public interface PropertyResolver {
boolean containsProperty(String key);
String getProperty(String key);
String resolvePlaceholders(String text);
...
}
测试时,可以使用environment的指定方法进行测试:
@ExtendWith(SpringExtension.class)
@SpringBootTest
public class EnvironmentTests{
@Autowired
private Environment environment;
@Test
public void testEnvValue(){
String username = environment.getProperty("spring.datasource.username");
Assertions.assertEquals("root", username);
}
}
(2)Mock
@MockBean注解:使用@MockBean注解可以实现针对数据访问等各层组件的Mock。
首先在@SpringBootTest中引入Mock
然后在需要Mock的Bean上使用@MockBean注解,用以mock该Bean
最后使用指定的技术设置对应值,例如下面的代码样例,使用Mockito框架,并用其when和thenReturn设置userService.findUserById的值。
@ExtendWith(SpringExtension.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.MOCK)
public class UserServiceTests {
@MockBean //模拟UserRepository
private UserRepository userRepository;
@Autowired
private UserService userService;
@Test
public void testFindUserById() throws Exception {
String userId = "001";
User user = new User(userId, "tianyalan", new Date(), "China");
Mockito.when(userRepository.findUserById(userId)).thenReturn(user);
User actual = userService.findUserById(userId);
assertThat(actual.getId()).isEqualTo(userId);
}
}
测试Service层 - Mockito框架常用方法:
模拟和验证:mock + verify方法
执行操作设定:when方法
执行结果设定:doReturn + doThrow + doAnswer方法
执行次数设定:times + atLeast + atMost方法
5、测试Web API层
如要测试下面的Controller,有三种方式:使用TestRestTemplate、使用@WebMvcTest注解、使用@AutoConfigureMockMvc
@RestController
@RequestMapping("/users")
public class UserController {
private UserService userService;
@Autowired
public UserController(UserService userService) {
this.userService = userService;
}
@GetMapping(value = "/{id}")
public User getUserById(@PathVariable String id) {
return userService.findUserById(id);
}
}
(1)使用TestRestTemplate
TestRestTemplate和RestTemplate使用方式完全一致,就是模拟了远程调用
@ExtendWith(SpringExtension.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class UserControllerTestsWithTestRestTemplate {
@Autowired
private TestRestTemplate testRestTemplate;
@MockBean
private UserService userService;
@Test
public void test(){
Long staffId = 3L;
CustomerStaff customerStaff = new CustomerStaff();
customerStaff.setId(staffId);
customerStaff.setStaffName("lcl");
customerStaff.setIsDeleted(false);
given(customerStaffService.findCustomerStaffById(staffId)).willReturn(customerStaff);
// Result<CustomerStaffRespVO> customerStaffRespVOResult = restTemplate.getForObject("/customerStaffs/"+staffId, Result.class);
ResponseEntity<Result<CustomerStaffRespVO>> resultResponseEntity = restTemplate.exchange(
"/customerStaffs/" + staffId,
HttpMethod.GET, null, new ParameterizedTypeReference<Result<CustomerStaffRespVO>>() {}
);
CustomerStaffRespVO customerStaffRespVO = resultResponseEntity.getBody().getData();
assertThat(customerStaffRespVO.getId()).isEqualTo(customerStaff.getId());
}
}
(2)使用@WebMvcTest注解:
这里需要注意两点,一个是@SpringBootTest注解不能和@WebMvcTest注解同时使用,另外一个是使用@WebMvcTest不会注入数据源,导致 Mapper 创建失败,其可以作为验证Service逻辑的测试。
@ExtendWith(SpringExtension.class)
@WebMvcTest(UserController.class)
public class UserControllerTestsWithMockMvc {
@Autowired
private MockMvc mvc;
@MockBean
private UserService userService;
@Test
public void testGetUserById() throws Exception {
String userId = "001";
User user = new User(userId, "tianyalan", 38, new Date(), "China");
given(this.userService.findUserById(userId)).willReturn(user);
this.mvc.perform(get("/users/" + userId).accept(MediaType.APPLICATION_JSON)).andExpect(status().isOk());
}
}
@WebMvcTest注解常见方法:
perform方法:执行HTTP请求,触发MVC工作流程并映射到Controller进行处理
get/post/put/delete方法:定义一个HTTP请求并指定请求方式
andExpect方法:通过对返回的数据进行判断来验证Controller执行结果是否正确
andDo方法:添加ResultHandler结果处理器,比如调试时打印结果到控制台
andReturn方法:返回代表请求结果的MvcResult,然后执行自定义验证
(3)使用@AutoConfigureMockMvc:
@ExtendWith(SpringExtension.class)
@SpringBootTest
@AutoConfigureMockMvc
public class CustomerControllerWithAutoConfigureMockMvc {
@Autowired
private MockMvc mockMvc;
@MockBean
private ICustomerStaffService customerStaffService;
@Test
public void test() throws Exception{
Long staffId = 3L;
CustomerStaff customerStaff = new CustomerStaff();
customerStaff.setId(staffId);
customerStaff.setStaffName("lcl");
customerStaff.setIsDeleted(false);
given(customerStaffService.findCustomerStaffById(staffId)).willReturn(customerStaff);
mockMvc.perform(MockMvcRequestBuilders.get("/customerStaffs/"+staffId).accept(MediaType.APPLICATION_JSON)).andExpect(status().isOk());
}
}
Spring Boot常见测试注解列表:
@Test:JUnit中使用的基础测试注解,用来标明所需要执行的测试用例
@ExtendWit:JUnit框架提供的用于设置测试运行器的基础注解
@SpringBootTest:Spring Boot应用程序专用的测试注解
@DataJpaTest:专门用于测试基于JPA的关系型数据库的测试注解
@MybatisPlusTest:专门用于测试基于MyBatis-Plus的关系型数据库的测试注解
@MockBean:用于实现Mock机制的测试注解
@WebMvcTest:用于在Web容器环境中嵌入MockMvc的注解
七、用Spring Boot Admin监控服务运行
1、Spring Boot Actuator基本应用
引入Spring Boot Actuator组件
Spring Boot Actuator:承载Spring Boot应用监控功能的组件,通过一系列HTTP监控端点(Endpoint)提供系统监控的管理入口。该组件也为开发人员提供了高度的扩展性,一方面我们可以在现有监控端点的基础上进行扩展,另一方面也可以实现自定义的Actuator端点。
Spring Boot Actuator通过HATEOAS来暴露HTTP端点。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.hateoas</groupId>
<artifactId>spring-hateoas</artifactId>
</dependency>
项目启动后,访问http://localhost:8081/actuator,默认只显示health
{
"_links": {
"self": {
"href": "http://localhost:8081/actuator",
"templated": false
},
"health-path": {
"href": "http://localhost:8081/actuator/health/{*path}",
"templated": true
},
"health": {
"href": "http://localhost:8081/actuator/health",
"templated": false
}
}
}
可以设置开放全部端点:
management:
endpoints:
web:
exposure:
include: '*'
访问http://localhost:8081/actuator/health,显示结果为{"status":"UP"},如果想要展示端点明细:
management:
endpoint:
health:
show-details: always
监控端点类型和描述:
应用配置类:
/beans:该端点用来获取应用程序中所创建的所有JavaBean信息
/env:该端点用来获取应用程序中所有可用的环境属性,包括环境变量、 JVM属性、应用配置信息等。
/info:该端点用来返回一些应用自定义的信息,可以进行扩展。
/mappings:该端点用来返回所有Controller中RequestMapping所表示的映射信息
度量指标类:
/metrics:该端点用来返回当前应用程序的各类重要度量指标,如内存信息、线程信息、垃圾回收信息等。
/threaddump:该端点用来暴露应用程序运行中的线程信息。
/health:该端点用来获取应用的各类健康指标信息,这些指标信息由HealthIndicator 的实现类提供,可以进行扩展。
/trace:该端点用来返回基本的HTTP跟踪信息。
操作控制类:
/shutdown:该端点用来关闭应用程序,要求 endpoints.shutdown.enabled 设置为 true
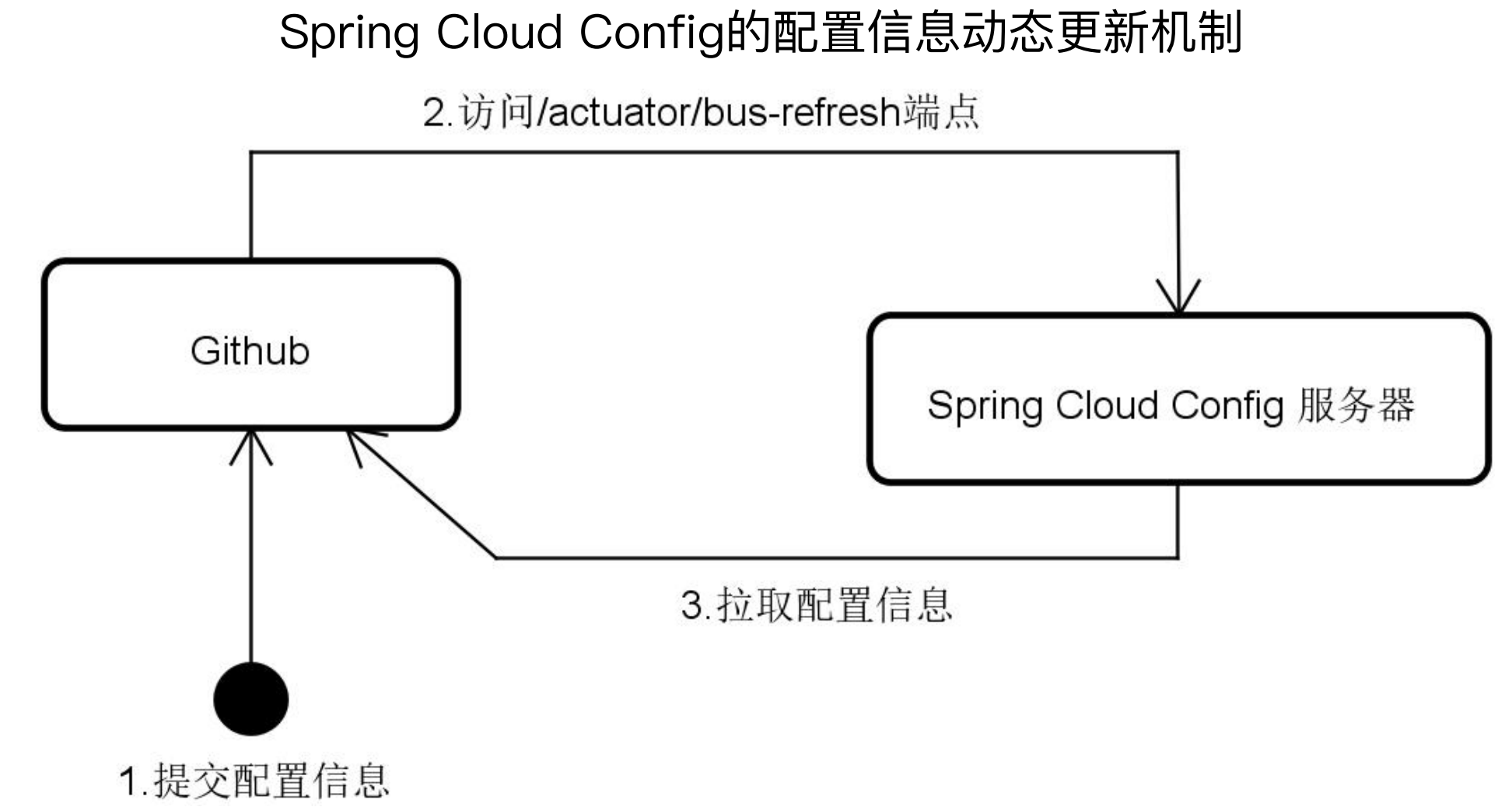
Actuator组件在Spring家族中的应用案例(Spring Cloud Config):
在Spring Cloud Config中,配置了Github的钩子函数,当Github的配置发生变更时会访问/actuator/bus-refresh端点,在该端点中会刷新Spring容器,刷新容器就会重新加载所有的Bean,那么就会从Github中重新获取配置项,从而保证项目中的配置项是最新的。
Spring Cloud Config的/actuator/bus-refresh端点:
@Endpoint(id = "refresh")
public class RefreshEndpoint {
private ContextRefresher contextRefresher;
public RefreshEndpoint(ContextRefresher contextRefresher) {
this.contextRefresher = contextRefresher;
}
@WriteOperation
public Collection<String> refresh() { //使用ContextRefresher完成刷新操作
Set<String> keys = contextRefresher.refresh();
return keys;
}
}
2、扩展和自定义Actuator端点
(1)Info 端点
每个端点的信息都不太一样,以 info 端点为例,主要是显示系统自定义的配置信息,他提供了一个Contributor接口,在Spring内部就实现了这个接口,提供了一系列的实现类,如:
EnvironmentInfoContributor:暴露Environment中key为info的所有key
GitInfoContributor:暴露git信息,如果存在git.properties文件
BuildInfoContributor:暴露构建信息,如果存在META-INF/build-info.properties文件
默认情况下,info 端点内容是空的,如果想定制化 info 端点内容,可以做一些定制化。
配置文件转端点:
在配置文件中做如下的配置,其中 info 开头 就代表是EnvironmentInfoContributor。
配置文件如下所示,这样在打包时就会将这些信息放入info配置中
info:
app:
encoding: @project.build.sourceEncoding@
java:
source: @java.version@
target: @java.version@
由于info的通过配置默认是关闭的,需要手动打开
management:
info:
env:
enabled: true
然后访问Info端点,就可以看到如下信息:
{
"app":{
"encoding":"UTF-8",
"java":{
"source":"1.8.0_31",
"target":"1.8.0_31"
}
}
}
这种从配置文件到端点的转变,是对Actuator扩展的最原始手段。
配置类转端点:
实现InfoContributor接口,在contribute方法中进行扩展:
@Component
public class CustomBuildInfoContributor implements InfoContributor {
@Override
public void contribute(Builder builder) {
builder.withDetail("build", Collections.singletonMap("timestamp", new Date()));
}
}
这样访问 info 端点就会输出 timestamp 信息。
{ "app":{
"encoding":"UTF-8",
"java":{
"source":"1.8.0_31",
"target":"1.8.0_31" }
},
"build":{
"timestamp":1604307503710
}
}
(2)Health端点:
其提供了一个Indicator接口,实现类包含几十个,例如:
DiskSpaceHealthIndicator:检查磁盘空间是否足够
DataSourceHealthIndicator:检查是否可以获得连接数据库
RedisHealthIndicator:检查Redis服务器是否启动
这么多的 Indicator,最终会使用HealthAggregator拼装成一个返回给前端。
{
"status":"UP",
"components":{
"db":{
"status":"UP",
"details":{
"database":"MySQL",
"result":1,
"validationQuery":"/* pin g */ SELECT 1"
}
},
"diskSpace":{
"status":"UP",
"details":{
"total":201649549312,
"free":3491287040,
"threshold":10485760
}
},
"ping":{
"status":"UP"
}
}
}
扩展Health端点:继承HealthIndicator接口,在实现中,远程连接三方地址,判断是否成功,如果成功,返回Up,不成功返回 Down,使用Health的构造器生成Health对象并返回。
@Component
public class CustomerServiceHealthIndicator implements HealthIndicator {
@Override
public Health health() {
try {
URL url = new URL("http://localhost:8083/health/");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
int statusCode = conn.getResponseCode();
if (statusCode >= 200 && statusCode < 300) {
return Health.up().build();
} else {
return Health.down().withDetail("HTTP Status Code", statusCode).build();
}
} catch (IOException e) {
return Health.down(e).build();
}
}
}
访问结果
{
"status": "DOWN",
"components": {
"customerService": {
"status": "DOWN",
"details": {
"error": "java.net.ConnectException: Connection refused (Connection refused)"
}
},
"db": {
"status": "UP",
"details": {
"database": "MySQL",
"validationQuery": "isValid()"
}
},
"diskSpace": {
"status": "UP",
"details": {
"total": 1000240963584,
"free": 68427735040,
"threshold": 10485760,
"exists": true
}
},
"ping": {
"status": "UP"
}
}
}
(3)自定义Actuator端点:
上面都是在已有端点上做的扩展,如果想新增一个自定义端点, 可以在定义类上添加@Configuration注解和@Endpoint,其中@Endpoint注解的id是端点的访问路径,enableByDefault表示是否默认可见,如果设置为true就表示不需要设置,直接就有这个端点,如果为false,则需要在配置文件中放开,@ReadOperation表示该端点可以读取,也就是可以查看相关信息。
@Configuration
@Endpoint(id = "mysystem", enableByDefault = true)
public class MySystemEndpoint {
@ReadOperation
public Map<String, Object> getMySystemInfo() {
Map<String, Object> result = new HashMap<>();
Map<String, String> map = System.getenv();
result.put("username", map.get("USERNAME"));
result.put("computername", map.get("COMPUTERNAME"));
return result;
}
}
访问:http://localhost:8080/actuator/mysystem
{
"computername":"LAPTOP-EQB59J5P",
"username":"user"
}
@Selector注解:上面是获取已有的信息,如果需要动态传递参数,就需要使用@Selector注解,这里需要注意一下,参数形参必须是arg0,否则不生效,然后访问 http://localhost:8081/actuator/account/3 即可。
@Configuration
@Endpoint(id = "account", enableByDefault = true)
public class AccountEndpoint {
@Autowired
private AccountRepository accountRepository;
@ReadOperation
public Map<String, Object> getMySystemInfo(@Selector String arg0) {
Map<String, Object> result = new HashMap<>();
result.put(accountName, accountRepository.findAccountByAccountName(arg0));
return result;
}
}
3、构建Admin Server
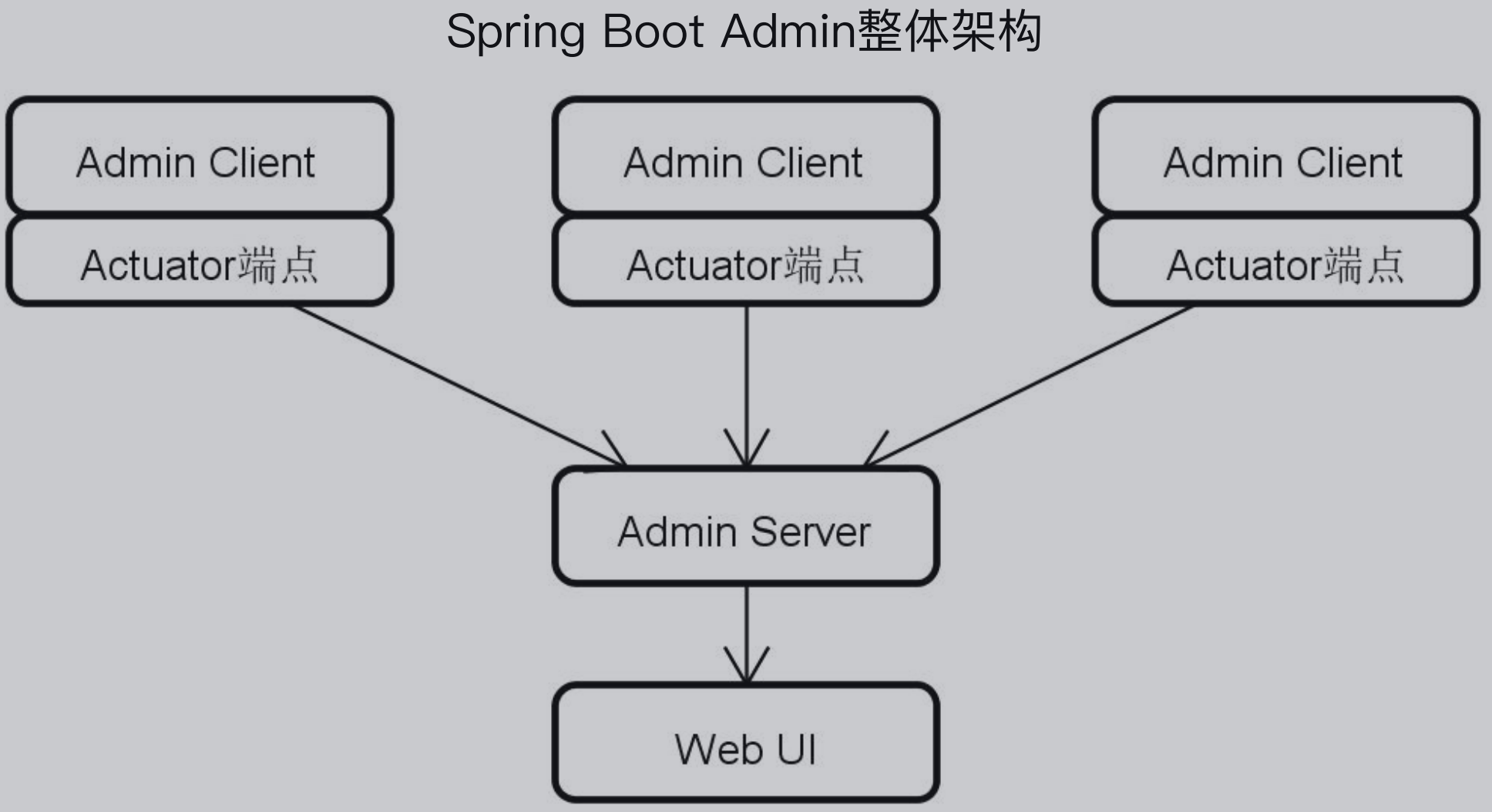
Spring Boot Admin是Springboot的监控组件,包括了Admin Service、Web UI、Admin Client。
(1)配置Admin Service
Admin Service 是一个Springboot项目,创建一个空的Springboot项目后,导入Admin依赖,spring-boot-starter-security依赖非必须,但是一般都会加
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-server</artifactId>
<version>2.6.8</version>
</dependency>
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-server-ui</artifactId>
<version>2.6.8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
启动类:在启动类添加@EnableAdminServer注解
@SpringBootApplication
@EnableAdminServer
public class AdminApplication {
public static void main(String[] args) {
SpringApplication.run(AdminApplication.class, args);
}
}
暂时关闭登录功能:这里就用到了Security
@Configuration
public class SecurityPermitAllConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
//关闭用户登录效果
http.authorizeRequests().anyRequest().permitAll()
.and().csrf().disable();
}
}
(2)客户端配置
配置依赖:这里需要保证客户端和服务端的版本要保持一致,否则可能会出现一些奇奇怪怪的报错。
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-client</artifactId>
<version>2.6.8</version>
</dependency>
然后在配置文件中配置 Admin Server的地址:这里采用了硬编码的方式配置,实际生产要使用注册中心。
spring:
boot:
admin:
client:
url: http://localhost:9000
(3)UI 控制台
访问
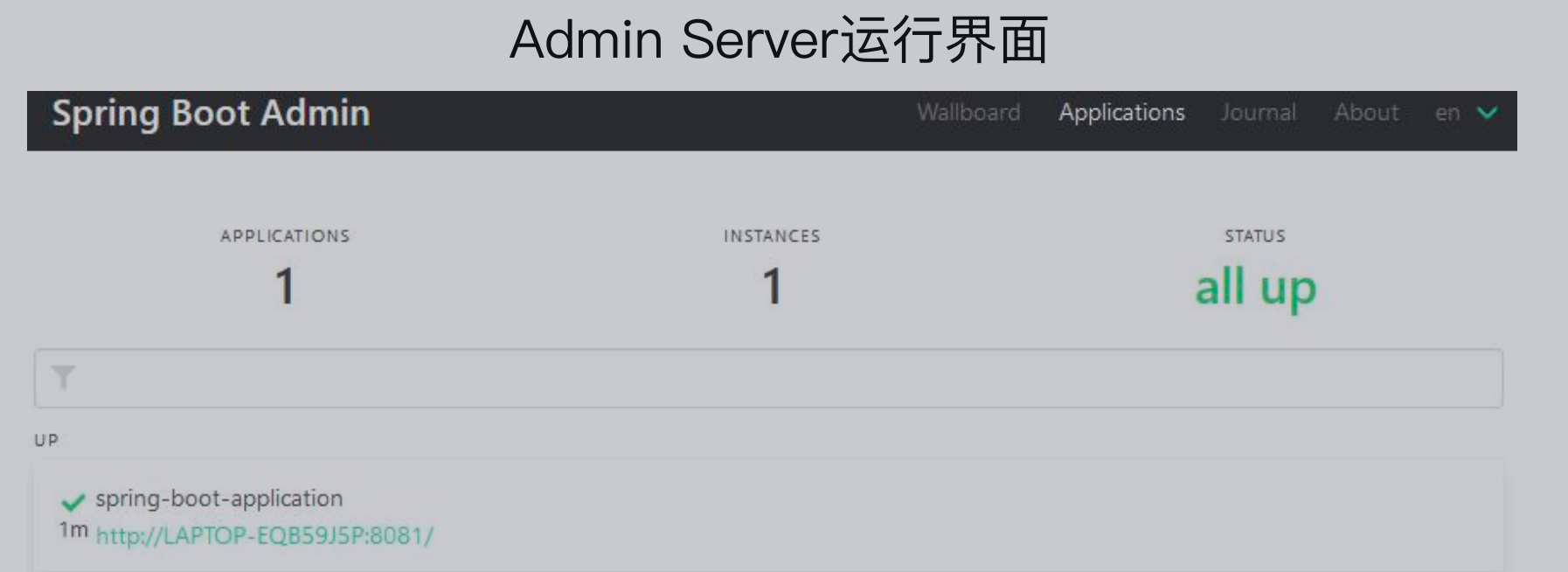
(4)配置登录账号密码
可以使用Spring Security
配置文件
spring:
security:
user:
name: "lcl"
password: "lcl"
4、实现自定义性能度量指标
不同的公司,不同的场景下,可能会很多定制化的性能度量指标,所以定制化内容也是非常重要的。
(1)PerformanceMonitorInterceptor
PerformanceMonitorInterceptor是spring 框架自带的一个拦截器,它通过 AOP 切面的机制来进行一个拦截。它本质上就是一个 AOP 的实现。如下代码所示,通过一个配置类进行配置,首先要指定一个Pointcut,同时new一个PerformanceMonitorInterceptor,然后把切点跟 intercept 里面的一些方法跟大家这样关联起来。
这种通过编码的方式让起点与拦截式联系起来,是很多时候我们做这种性能监控或者日志监控的一个常规的做法。
@Configuration
public class PerformanceMonitorConfiguration {
@Pointcut("execution(*com.springboot.aop.service.AccountService.doAccountTransaction(..))")
public void monitor() {
}
@Bean
public PerformanceMonitorInterceptor performanceMonitorInterceptor() {
return new PerformanceMonitorInterceptor();
}
@Bean
public Advisor performanceMonitorAdvisor() {
//通过编码的方式将切点与PerformanceMonitorInterceptor关联起来
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression("com.springboot.aop. PerformanceMonitorConfiguration.monitor()");
return new DefaultPointcutAdvisor(pointcut, performanceMonitorInterceptor());
}
}
拦截器 PerformanceMonitorInterceptor 内部是使用了 stop watch 来进行时间的控制并计时的,通过这种方式,我们可以拿到很多明细的信息,最最基本的信息,至少可以拿到切点指定方法的一个执行时间。
StopWatch:相当于有秒表一样的定时器一样,计时器一样的东西。如下代码,开始时创建一个 StopWatch,执行一个任务休眠一段时间,再执行任务,再睡一段时间再停止它。
StopWatch sw = new StopWatch("test");
sw.start("task1");
//执行操作
Thread.sleep(100);
sw.stop();
sw.start("task2");
//执行操作
Thread.sleep(200);
sw.stop();
System.out.println(sw.prettyPrint());
打印出 stop work 里面的一些日志信息:可以看到输出了每一段执行的时间,以及全部的时间。
sw.prettyPrint()~~~~~~~~~~~~~~~~~
StopWatch 'test': running time (millis) = 308
-----------------------------------------
ms % Task name
-----------------------------------------
00104 034% task1
00204 066% task2
o.s.a.i.PerformanceMonitorInterceptor : StopWatch 'com.springboot.aop.service.AccountService.doAccountTransaction': running time (millis) = 11
因此PerformanceMonitorInterceptor使用了AOP切入了对应的方法,切入进去之后,每行代码的执行的时间都可以通过拦截的方式把它给打印起来,这对有时候做一些统计分析还是有明显的帮助的。
(2)Micrometer库和组件:
Micrometer 是 比较新版本的 spring boot 内置的一个第三方库,把内核里面做计量、统计、计时的一些组件换了一下,换成了这个框架。
Micrometer 作为一个度量的类库,提供了很多的组件,最重点的是Meter。
Meter 又分为计数器 Counter、计量器 Gauge、计时器 Timer,这些计量可以注册到计量器计量注册表 MeterRegister中,MeterRegister 里面维护的一组计量器。
系统启动的时候,可以实现一个计量器注册表,然后把各种计量器放入计量器注册表中,然后就可以使用 Metar 中产生的一些数据放到监控系统里面,这就是micrometer提供的能力。
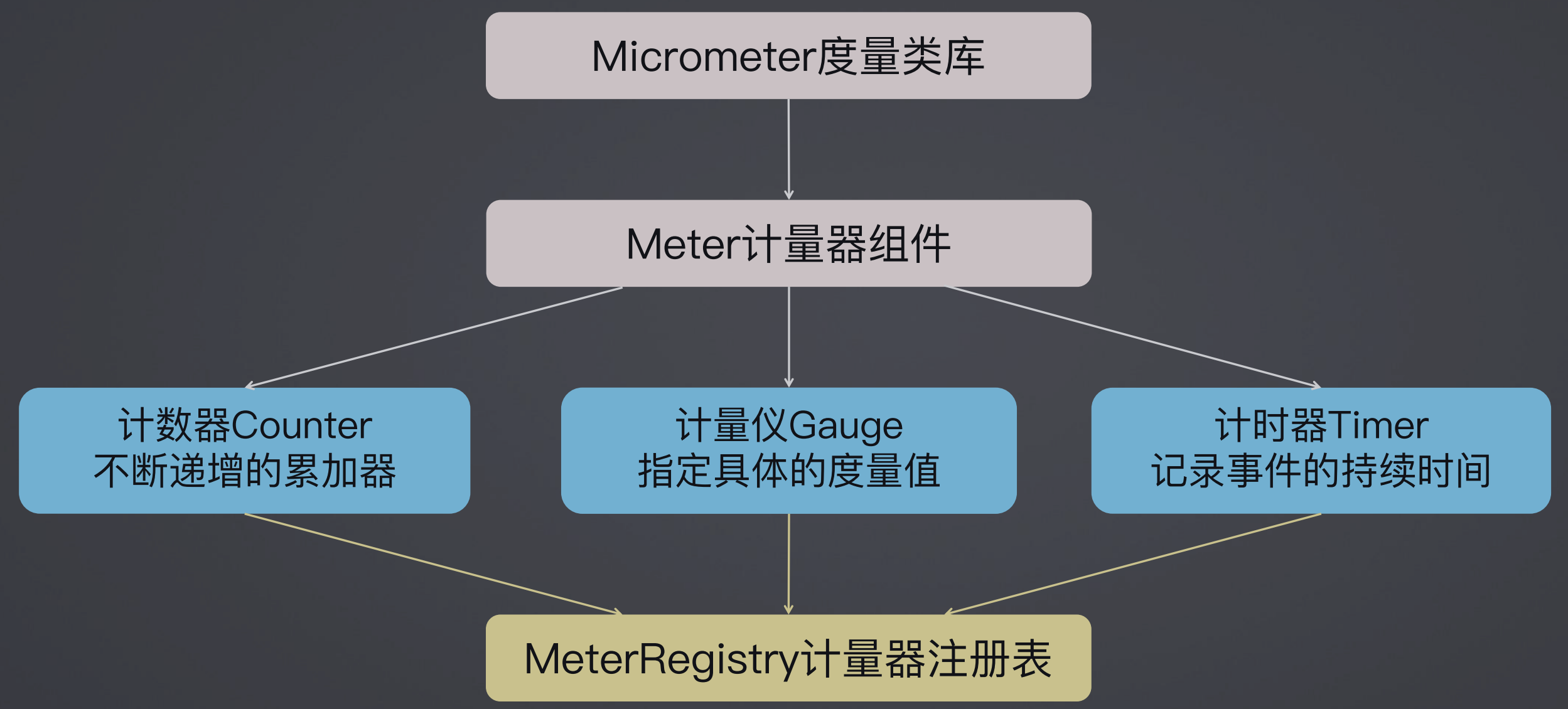
计量仪和计时器平时不大常见,因为计时器的实现方式有很多,而计量仪只是记住当前的某个度量值,往往通过数据库或者日志来做这个事情就可以了,因为它只关注于某个点的数据。
统计的关键其实是 Counter,如果一个数据一直在累加,想要拿到累加后的数据,Counter是一个比较好的方法。
如下代码所示:
第一种方式:首先创建一个注册器,然后通过注册器创建一个计数器,入参是这个Counter的名字,然后调用 counter.increment()方法进行累加
第二种方法:使用全局计数器,其是通过 Metrics 的工具类来实现的。创建 Counter 的参数有三个,第一个是Counter的名字,第二个参数是tag,表示要维度的名称,第三个参数是该维度的一个key。
//创建MeterRegistry和Counter
MeterRegistry registry = new SimpleMeterRegistry();
Counter counter = registry.counter("counter.user"); // 命名:使用.分隔单词
counter.increment();
//使用全局MeterRegistry
Metrics.addRegistry(new SimpleMeterRegistry());
Counter counter = Metrics.counter("database.calls", "db", "users"); // 标签:多维度度量数据收集和分组
counter.increment();
实际的应用案例:
(1)定义通用Counter
使用Map来存储 Counter 集合,key 为 Counter的名字,value 为具体的Counter,并重写 increment 方法和 getCount 方法
public class CustomerCounter {
private String name;
private String tagName;
private MeterRegistry meterRegistry;
public CustomerCounter(String name, String tagName, MeterRegistry meterRegistry){
this.name = name;
this.tagName = tagName;
this.meterRegistry = meterRegistry;
}
private Map<String, Counter> counterMap = new HashMap<>();
public void increment(String tagValue){
Counter counter = counterMap.get(tagValue);
if(counter == null){
counter = Counter.builder(name).tag(tagName, tagValue).register(meterRegistry);
counterMap.put(tagValue, counter);
}
counter.increment();
}
public double getCount(String tegValue){
return counterMap.get(tegValue).count();
}
}
(2)定义一个指定业务的Counter
在该 Counter 中调用通用Counter类来构建一个Counter,然后根据电话号码累加,并提供两个静态方法用作累加和获取累加的值。
public class CustomerStaffCounter {
private static SimpleMeterRegistry registry = new SimpleMeterRegistry();
private static CustomerCounter customerCounter = new CustomerCounter("customerStaff", "phone", registry);
public static void countPhoneNumber(String phoneNumber){
customerCounter.increment(phoneNumber);
}
public static double getCount(String phoneNumber) {
return customerCounter.getCount(phoneNumber);
}
}
(3)测试
直接调用业务Counter的累加操作,然后验证获取的累加的结果与预期是否一致。
public class CustomerStaffCounterTests {
@Test
public void testFindCustomerStaffById(){
CustomerStaffCounter.countPhoneNumber("123");
CustomerStaffCounter.countPhoneNumber("123");
CustomerStaffCounter.countPhoneNumber("456");
Assertions.assertEquals(CustomerStaffCounter.getCount("123"), 2);
}
}
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号