
JVM-对象的创建、内存分配及访问
一、对象创建流程与内存分配
1、创建对象
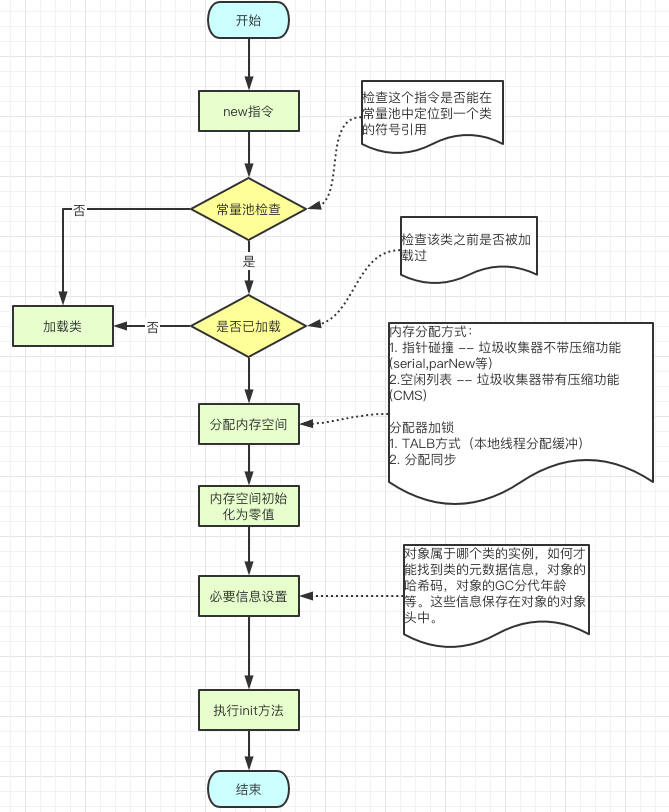
2、堆的内存分配方式
堆的内存分配方式有指针碰撞和空闲列表两种方式:
指针碰撞:内存是连续的,年轻代使用,使用该种分配方式的垃圾回收器:Serial和ParNew收集器
空闲列表:内存地址不连续,老年代使用,使用该种分配方式的垃圾回收器:CMS和Mark-Sweep收集器
3、内存分配安全
在进行内存分配时,存在线程安全的问题,JVM的解决方案是通过TLAB和CAS来解决的。
TLAB(本地线程分配缓存):为每一个线程预先分配一块内存,JVM在给线程中的对象分配内存时,先在TLAB上分配,如果内存不够,再使用CAS进行分配。
CAS(比较和交换):CAS是乐观锁的一种实现方式,即每一次申请内存都不加锁,如果出现冲突进行重试,知道成功为止。
JVM在第一次给线程中的对象分配内存时,首先使用CAS进行TLAB的分配。当对象大于TLAB中的剩余内存或TLAB的内存已用尽时,再采用上述的CAS进行内存分配。
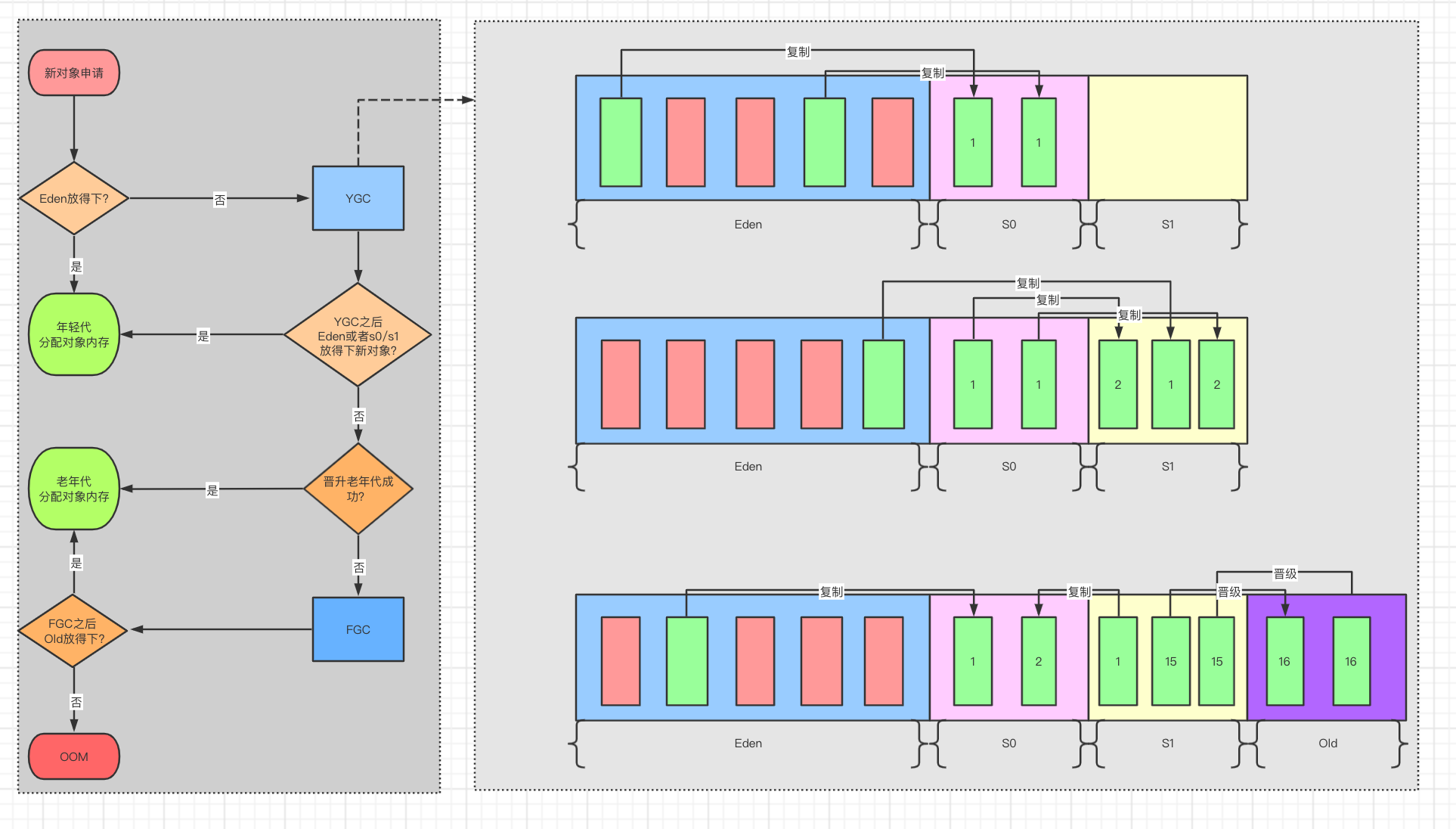
4、对象怎样才会进入老年代
对象内存分配:
新生代:新对象大多数都默认进入新生代的Eden区
进入老年代的条件:四种情况
(1)存活年龄太大,默认超过15次【-XX:MaxTenuringThreshold】
(2)动态年龄判断:MinorGC之后,发现Survivor区中的一批对象的总大小大于了这块Survivor区的50%,那么就会将此时大于等于这批对象年龄最大值的所有对象,直接进入老年代。举个栗子:Survivor区中有一批对象,年龄分别为年龄1+年龄2+年龄n的多个对象,对象总和大小超过了Survivor区域的50%,此时就会把年龄n及以上的对象都放入老年代。(-XX:TargetSurvivorRatio可以指定)
(3)大对象直接进入老年代:前提是Serial和ParNew收集器。举个栗子:字符串或数组-XX:PretenureSizeThreshold 一般设置为1M,为什么会这样?为了避免大对象分配内存时的复制操作降低效率。避免了Eden和Survivor区的复制
(4)MinorGC后,存活对象太多无法放入Survivor
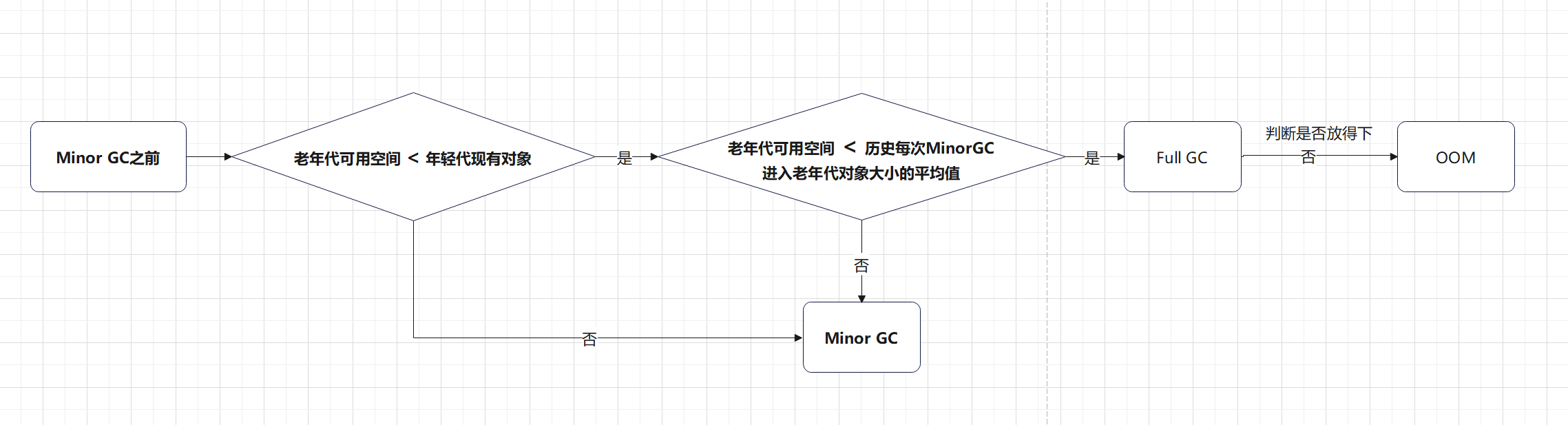
空间担保机制:当新生代无法分配内存的时候,我们想把新生代的对象转移到老年代,然后把新对象放入腾空的新生代。此时就需要内存担保机制。
MinorGC前,判断老年代可用内存是否小于新时代对象全部对象大小,如果小于则继续判断
判断老年代可用内存大小是否小于之前每次MinorGC后进入老年代的对象平均大小
如果是,则会进行一次FullGC,判断是否放得下,放不下OOM
如果否,则会进行一些MinorGC:
MinorGC后,剩余存活对象小于Survivor区大小,直接进入Survivor区
MinorGC后,剩余存活对象大于Survivor区大小,但是小于老年代可用内存,直接进入老年代
MinorGC后,剩余存活对象大于Survivor区大小,也大于老年代可用内存,进行FullGC
FullGC之后,任然没有足够内存存放MinorGC的剩余对象,就会OOM
老年代的担保示意图:
5、案例演示:对象分配过程
/*** 测试:大对象直接进入到老年代
* -Xmx60m -Xms60m -XX:NewRatio=2 -XX:SurvivorRatio=8 -XX:+PrintGCDetails
* -XX:PretenureSizeThreshold
*
*/
public class YoungOldArea {
public static void main(String[] args) {
byte[] buffer = new byte[1024*1024*20]; //20M
}
}
-XX:NewRatio=2 新生代与老年代比值;-XX:SurvivorRatio=8 新生代中,Eden与两个Survivor区域比值;-XX:+PrintGCDetails 打印详细GC日志;-XX:PretenureSizeThreshold 对象超过多大直接在老年代分配,默认值为0,不限制
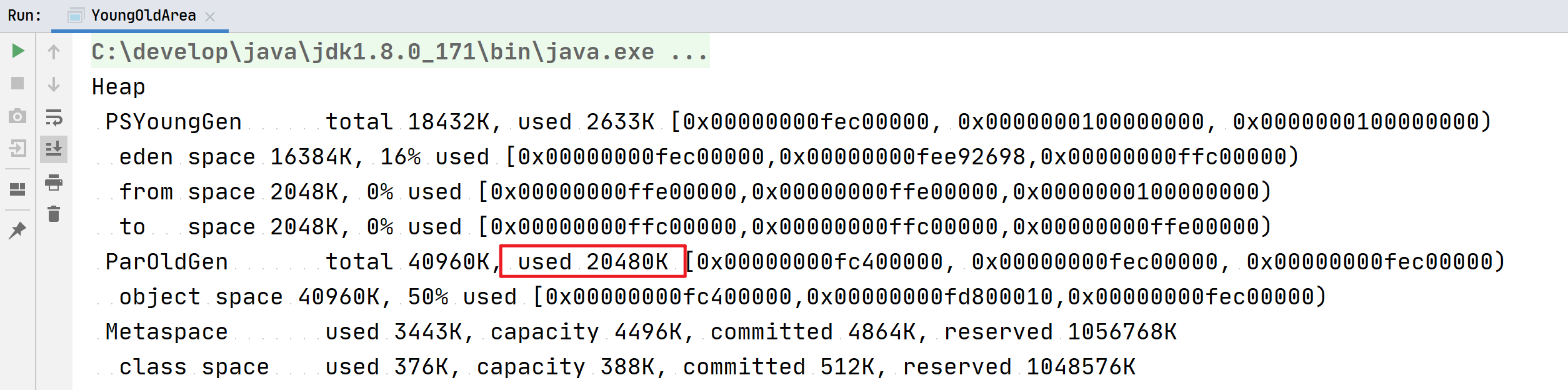
对象内存分配过程
/*
-Xmx600m -Xms600m -XX:+PrintGCDetails
*/
public class HeapInstance {
public static void main(String[] args) {
List<Picture> list = new ArrayList<>();
while (true){
try {
Thread.sleep(20);
}
catch (InterruptedException e) {
e.printStackTrace();
}
list.add(new Picture(new Random().nextInt(1024 * 1024))); //4K + 12K =16K
}
}
}
class Picture{
private byte[] pixels;
public Picture(int length){
this.pixels = new byte[length];
}
}
6、案例演示:内存担保机制
案例准备JVM参数: -Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:+UseSerialGC;分配三个1MB的对象和一个5MB的对象;-Xmn10M新生代内存的最大值:包括Eden区和两个Survivor区的总和
/**
* 内存分配担保案例
*/
public class MemoryAllocationGuarantee {
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) {
memoryAllocation();
}
public static void memoryAllocation() {
byte[] allocation1, allocation2, allocation3, allocation4;
allocation1 = new byte[1 * _1MB]; //1M
allocation2 = new byte[1 * _1MB]; //1M
allocation3 = new byte[1 * _1MB]; //1M
allocation4 = new byte[5 * _1MB]; //5M
System.out.println("完毕");
}
}
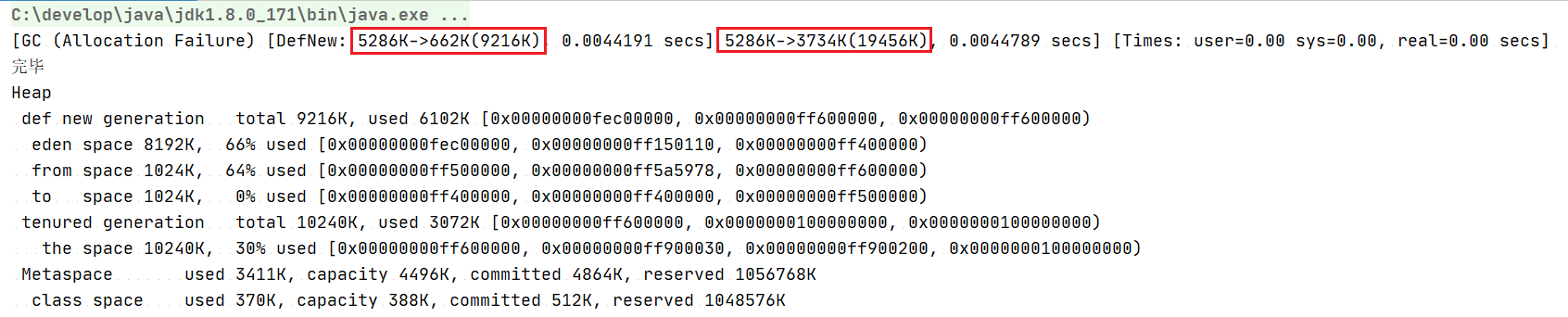
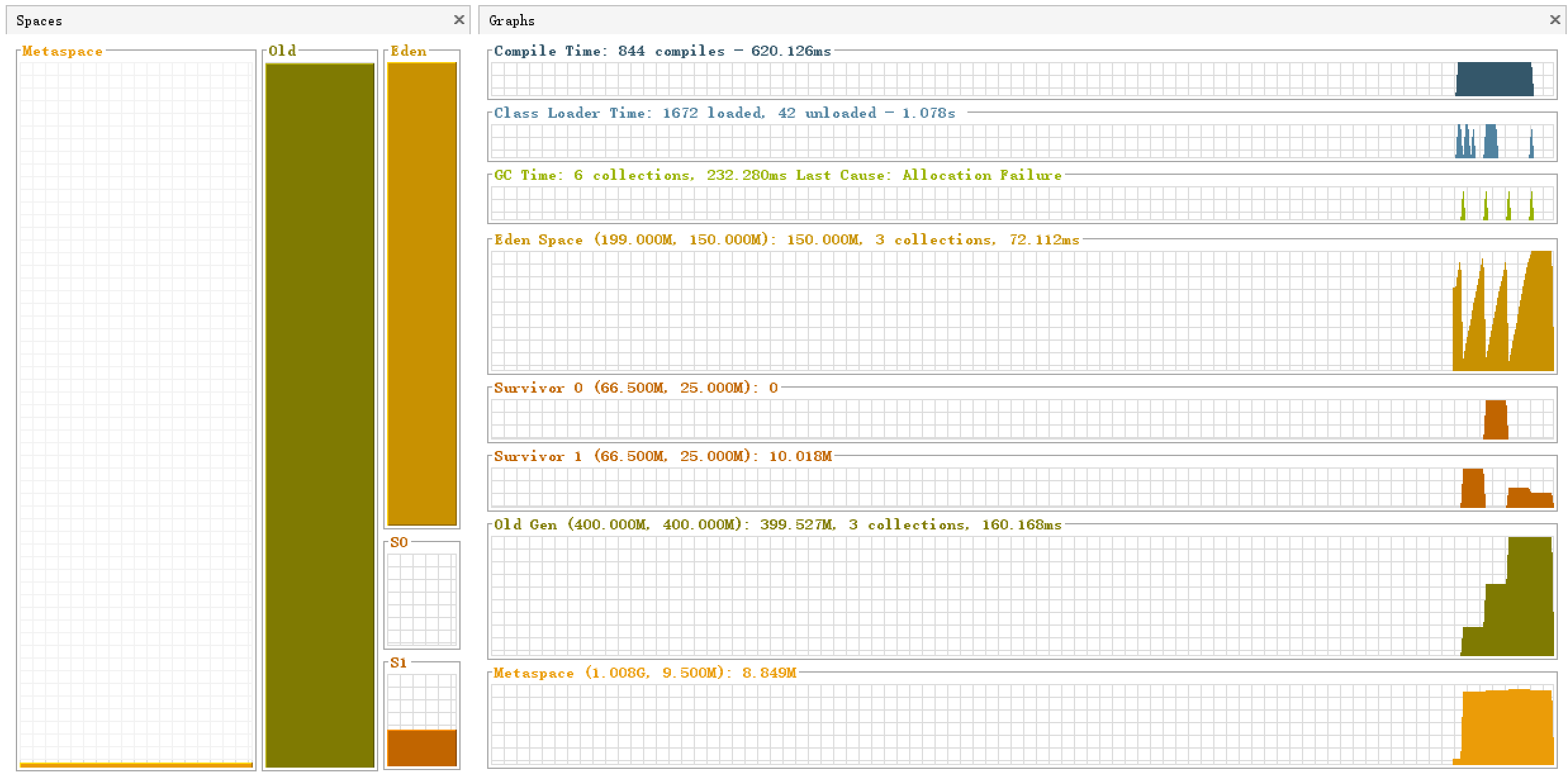
堆内存分配如下:

设置JVM参数:
-Xms20M -Xmx20M -Xmn10M -XX:+PrintGCDetails -XX:SurvivorRatio=8 -XX:+UseSerialGC
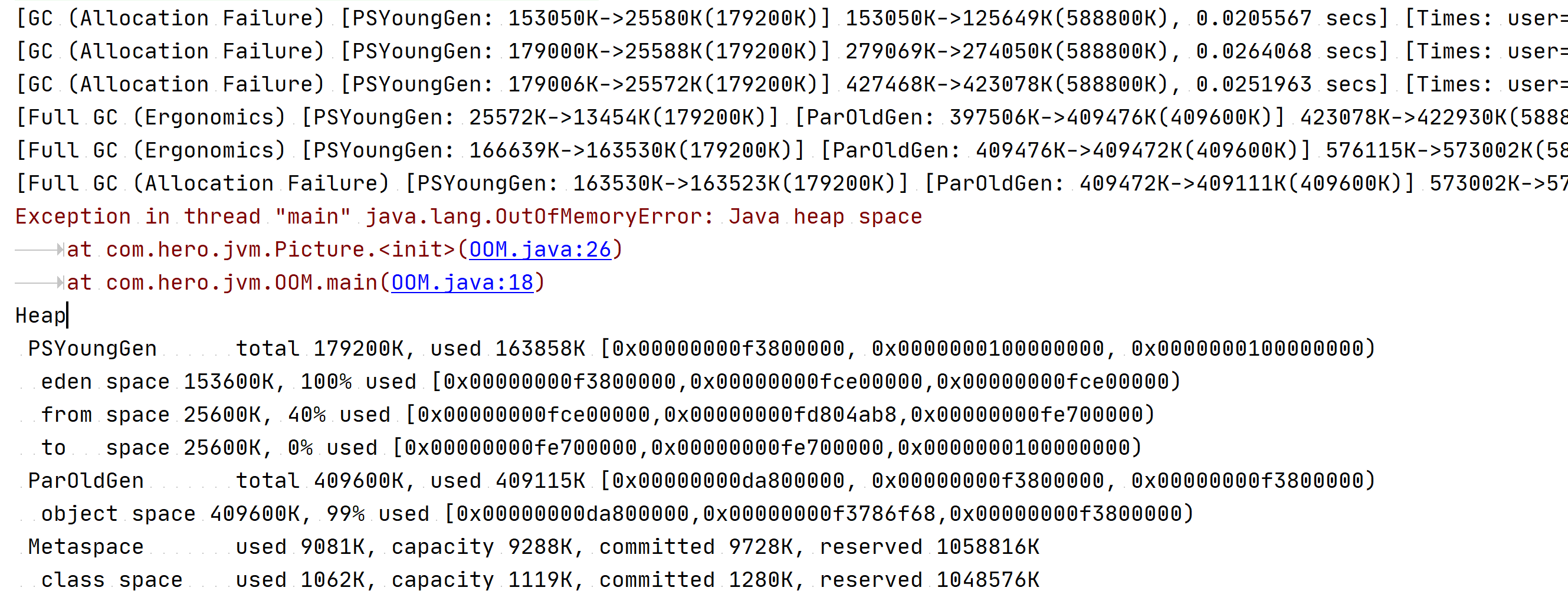
查看GC日志:
通过GC日志我们发现:在分配allocation4的时候,发生了一次Minor GC,新生代从5268K变为了662K,但是你发现整个堆的占用并没有很大变化。
分析过程:
担保前的堆空间:
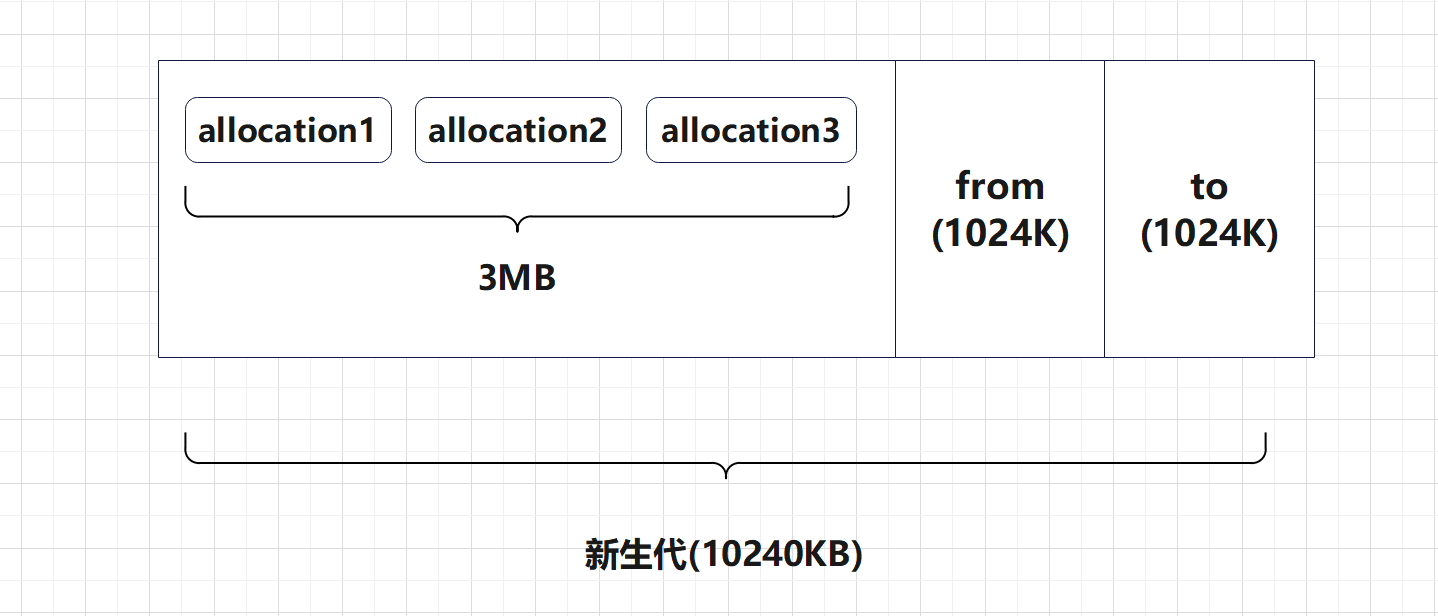
发生Minor GC,触发担保机制:
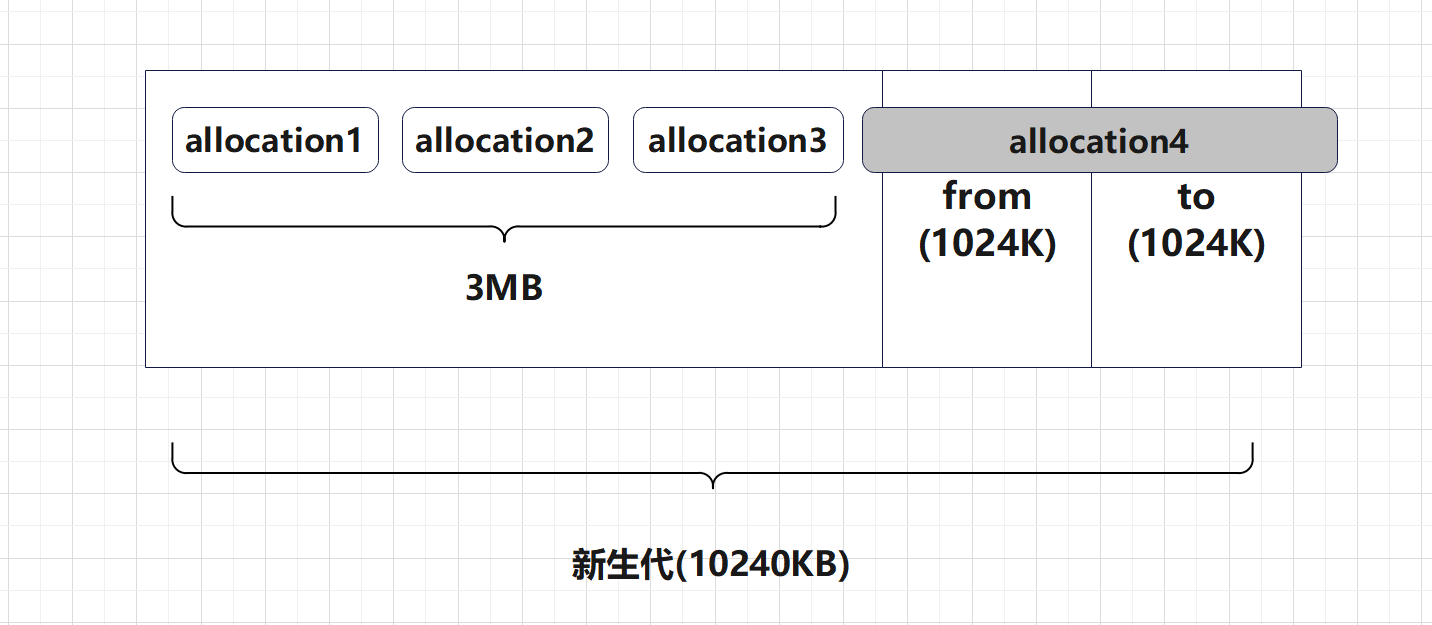
担保后的新生代和老年代:
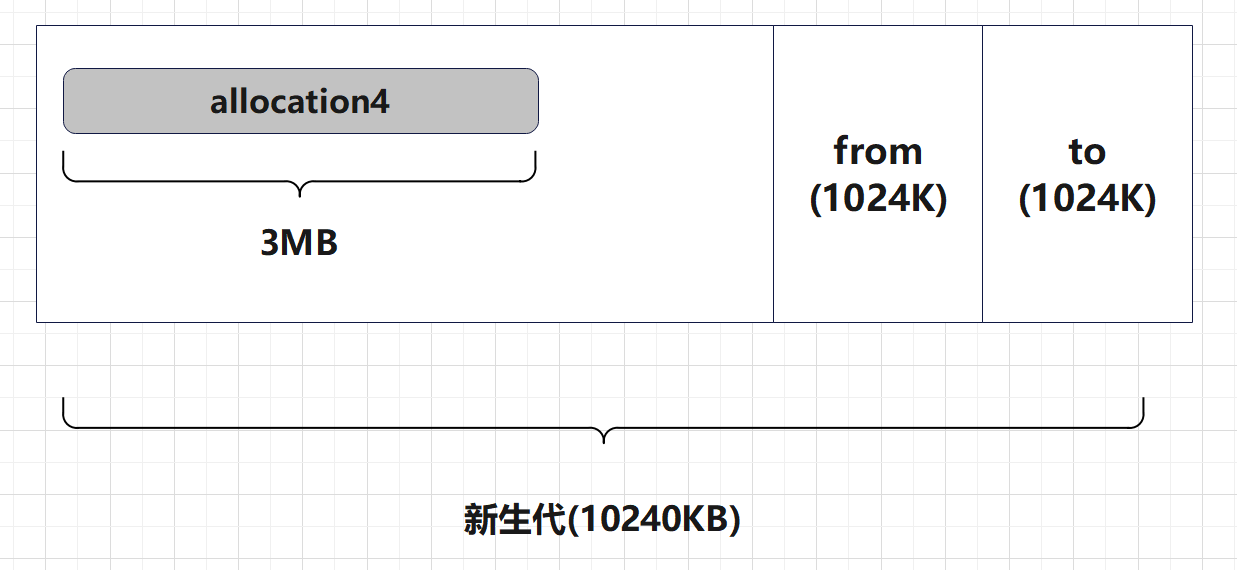

综上:
当Eden区存储不下新分配的对象时,会触发minorGC
GC之后,还存活的对象,按照正常逻辑,需要存入到Survivor区。
当无法存入到幸存区时,此时会触发担保机制
发生内存担保时,需要将Eden区GC之后还存活的对象放入老年代。后来的新对象或者数组放入Eden区。
二、对象内存布局及访问方式
(一)对象的内存布局
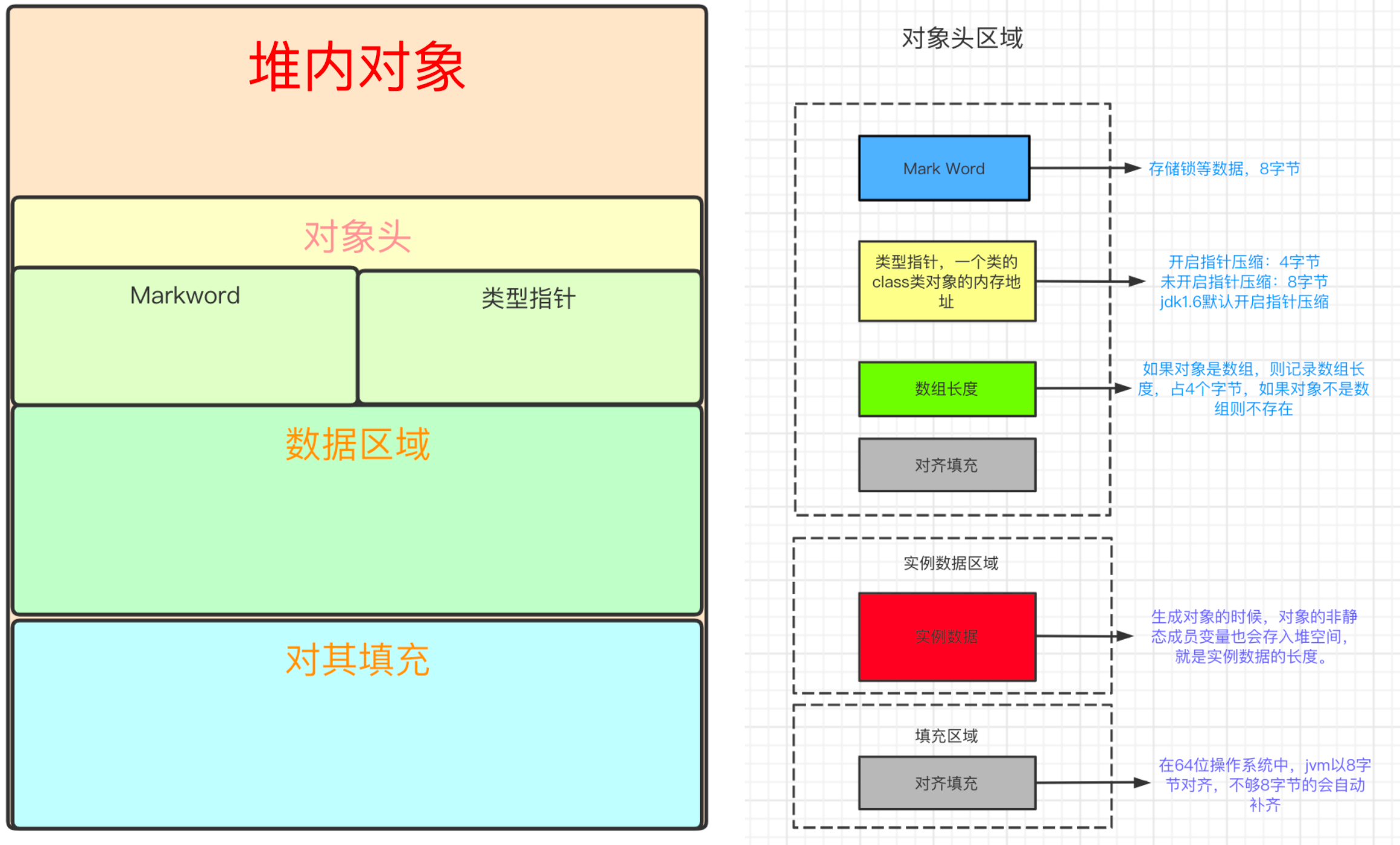
对象在堆内存中的布局可以分为对象头、实例数据、对齐填充三个部分。
对象头:Java对象头占8byte。如果是数组则占12byte。因为JVM里数组size需要使用4byte存储。
标记字段MarkWord:用于存储对象自身的运行时数据,它是synchronized实现轻量级锁和偏向锁的关键。默认存储:对象HashCode、GC分代年龄、锁状态等等信息。为了节省空间,也会随着锁标志位的变化,存储数据发生变化。
类型指针KlassPoint:是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例开启指针压缩存储空间4byte,不开启8byte。JDK1.6+默认开启数组长度:如果对象是数组,则记录数组长度,占4个byte,如果对象不是数组则不存在。
对齐填充:保证数组的大小永远是8byte的整数倍
实例数据:生成对象的时候,对象的非静态成员变量也会存入堆空间
对齐填充:在JVM中对象的大小必须是8字节的整数倍,对象头已经确定了是8字节的倍数,但是实例数据不一定是8个字节的倍数,因此如果最终对象头+实例数据的大小不是8字节的倍数,则需要对齐填充来对其进行填充。
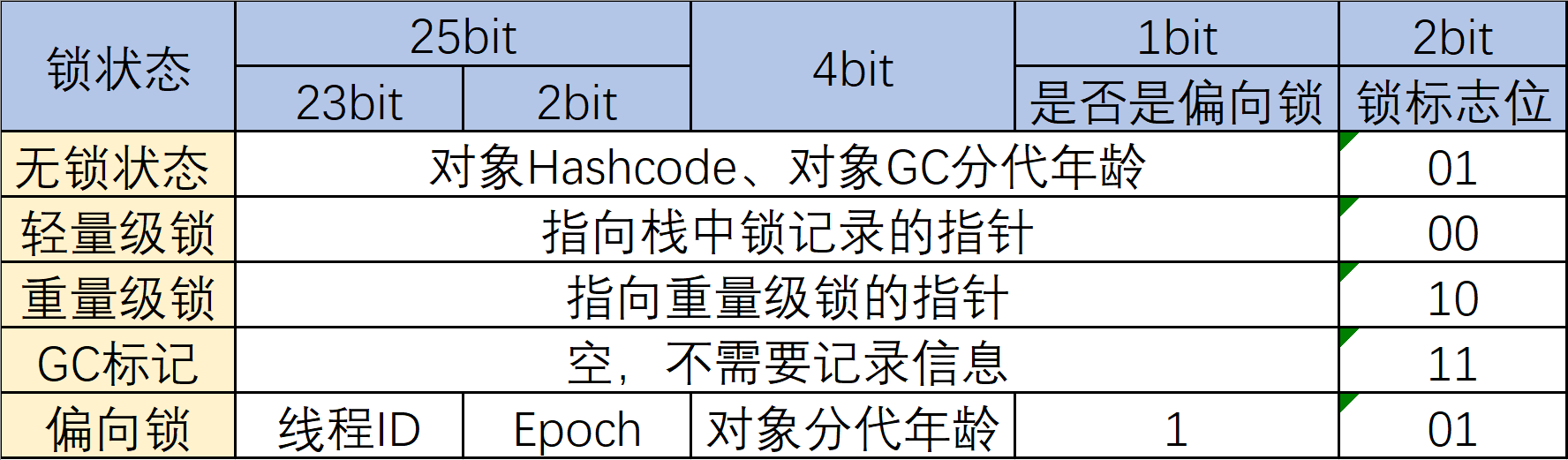
对象头的大小:对象头信息是与对象自身定义的数据无关的额外存储成本。考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构,以便在极小的空间内,尽量多的存储数据,它会根据对象的状态复用自己的存储空间,也就是说,Mark Word会随着程序的运行发生变化,变化状态如下(JDK1.8)。
案例01:打印空对象的内存布局信息
代码和控制台输出:
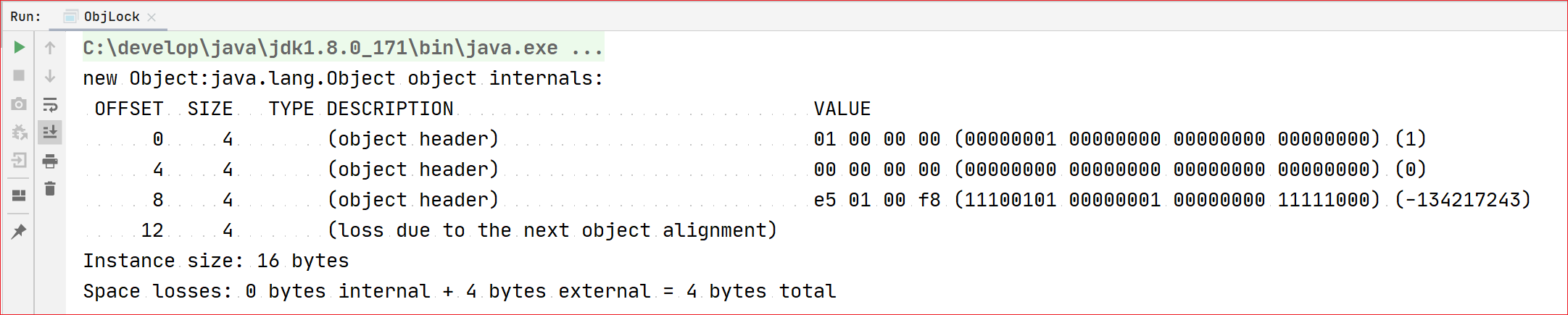
分析:首先对象头是包含MarkWord和类型指针这两部分信息的;开启指针压缩的情况下,存放Class指针的空间大小是4字节,MarkWord是8字节,对象头为12字节;新建Object对象,会在内存占用16个字节,其中Header占12个(MarkWord占8个+KlassPoint占4个),没有实例数据,补充对齐4个。
结论:对象大小 = 对象头12 + 实例数据0 + 对齐填充4 = 16 bytes
案例02:打印空对象和赋值后的对象内存布局信息
代码:
public class ObjLock02 { public static void main(String[] args) { Hero a = new Hero(); System.out.println("new A:" + ClassLayout.parseInstance(a).toPrintable()); a.setFlag(true); a.setI(1); a.setStr("ABC"); System.out.println("赋值 A:" + ClassLayout.parseInstance(a).toPrintable()); } static class Hero { private boolean flag; private int i; private String str; public void setFlag(boolean flag) { this.flag = flag; } public void setStr(String str) { this.str = str; } public void setI(int i) { this.i = i; } } }
控制台输出
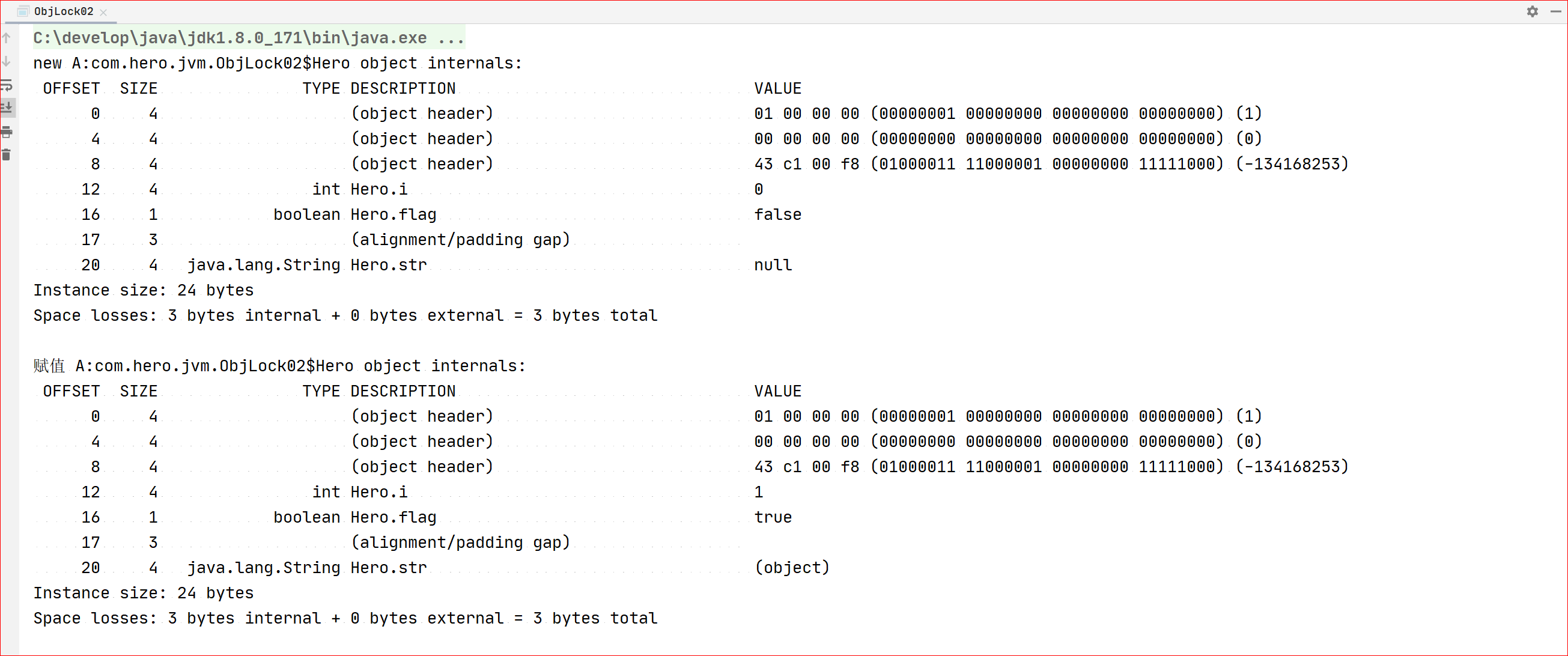
分析:新建对象Hero时,对象头占12个(MarkWord占8个+KlassPoint占4个);实例数据中 boolean占一个字节,会补齐三个,int占4个,String占4个,无需补充对齐。
结论:对象的大小 = 12对象头 + 4*3的实例数据 + 0的填充 = 24bytes
(二)对象的访问方式:
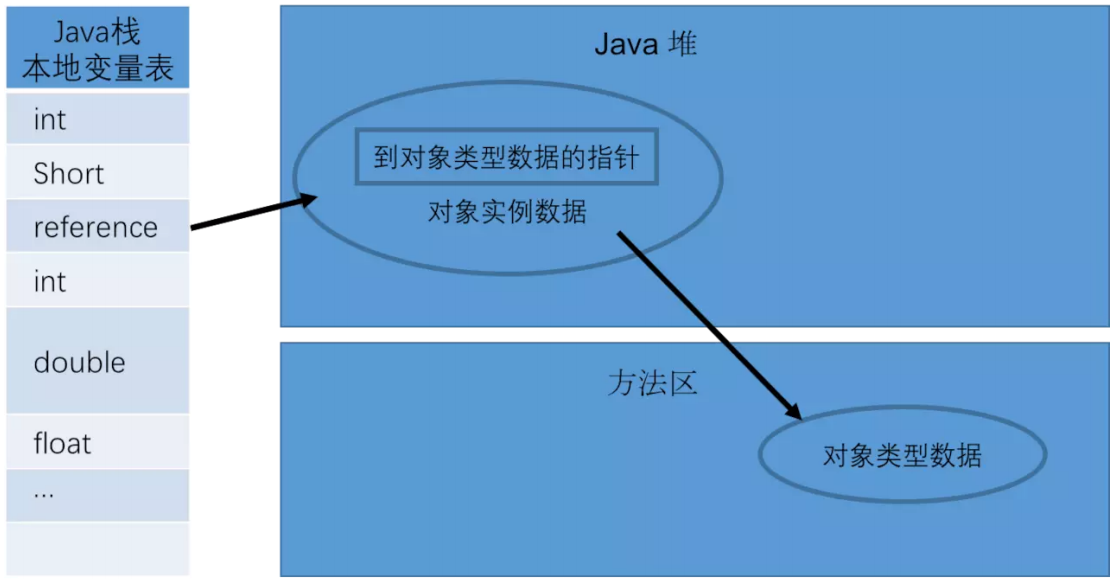
对象的访问方式分为句柄访问和直接指针访问。
句柄访问:虚拟机栈中本地变量表中存储的是句柄池中句柄的指针,而句柄中有一个指向堆中对象实例数据的指针和一个指向方法区中对象类型的指针。句柄访问的优点是稳定,因为如果对象发生移动,则只需要改变句柄中指向堆中实例数据的指针即可。
直接指针访问:虚拟机栈中本地变量表存储的是直接指向堆中对象的指针,对象中又包含实例数据和类型指针等信息。直接指针访问的优点是,访问速度快,节省了一次指针定位的开销。
在Hotspott中,使用的是直接指针访问的方式。

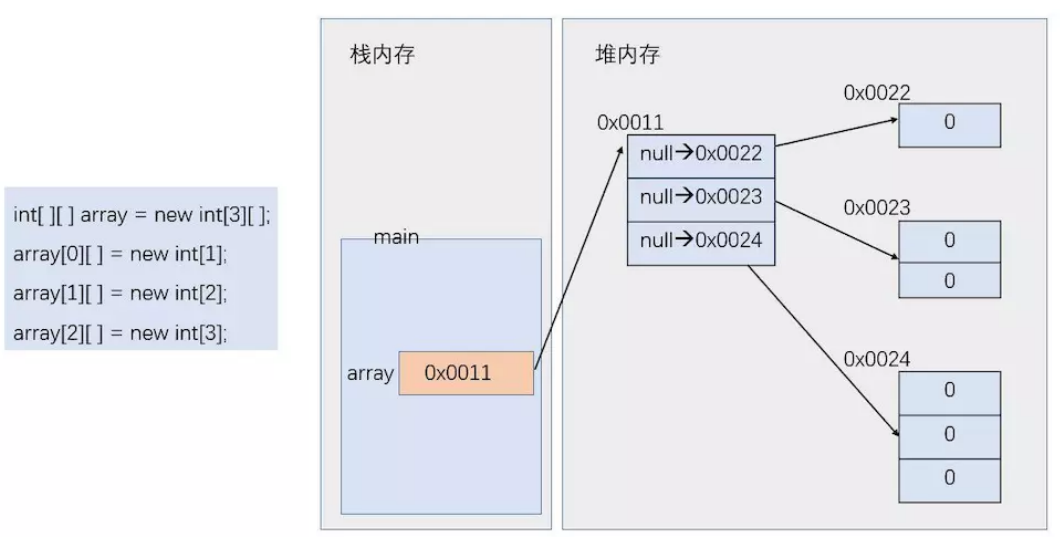
(三)数组内存分析
对于数组,其在内存中的地址是连续的,变量对应的指针指向的是堆中连续空间的开始地址。
一维数组:
int[] arr = new int[3]:这行代码首先会将arr压入栈,然后在堆中开辟一个空间,然后将其赋上默认值,由于数组类型是int,因此被赋上默认值0
int[] arr1 = arr:这行代码会将arr中的地址赋值给arr2,此时arr和arr2指向了同一块内存地址。
arr[0] = 20:这行代码,将arr指针对应地址的第一个值更新为20
二维数组:
int[][] arr = new int[3][]:这样代码首先将arr压入栈,然后再堆中开辟一个内存空间,并附上默认值,由于是二维数组,因此其默认值为null,然后把该内存空间的地址赋值给arr
int[0][] = new int[1]:这行代码将在对中开辟一个内存空间,然后赋上默认值(由于是int类型,默认值为0),并将该内存空间的地址赋值给一维数组的第一个数据。
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号